RNN's
Ordem importa
Ao trabalharmos com redes convencionais, não fornecemos nenhuma informação sobre ordem ou sequência dos tokens.
Mas sabemos que a ordem das palavras em uma frase possui significado.
Redes Recorrentes
Ao invés de utilizarmos camadas sequenciais que recebem uma frase inteira de uma vez podemos criar redes que recebem uma palavra por vez e se “realimentam” a cada nova palavra.
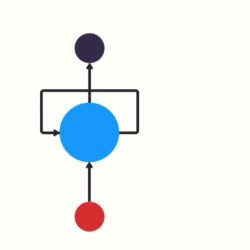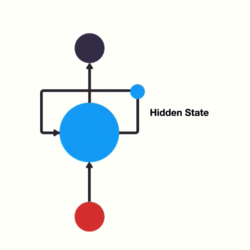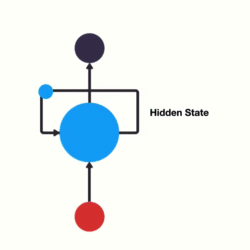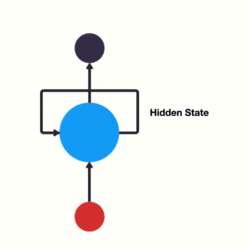
Redes Recorrentes
Deixamos de necessitar padding e conseguimos fornecer informação posicional sobre cada palavra através da própria arquitetura da rede.
Redes Feed Forward
-
Cada iteração é independente.
-
Facilmente paralelizável.
-
Alimentamos toda uma sequência de tokens de uma vez.
Redes Recorrentes
-
Cada iteração depende da anterior.
-
Sequencial por natureza, poucas oportunidades de paralelização.
-
Alimentamos um token de cada vez de maneira sequencial
Redes Feed Forward
Redes Recorrentes
Representação “desenrolada”

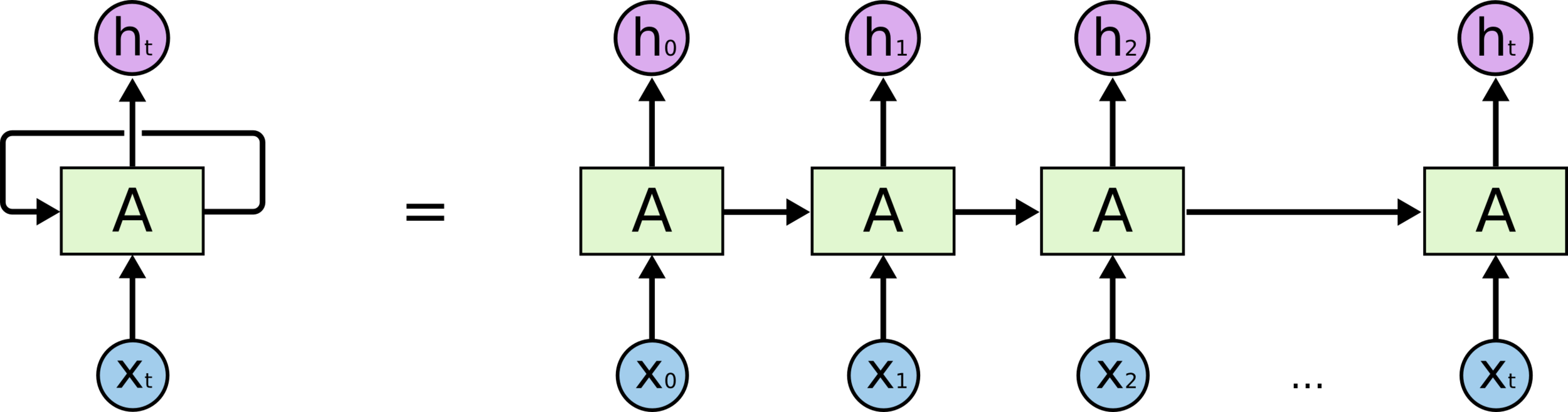
Representação “desenrolada”
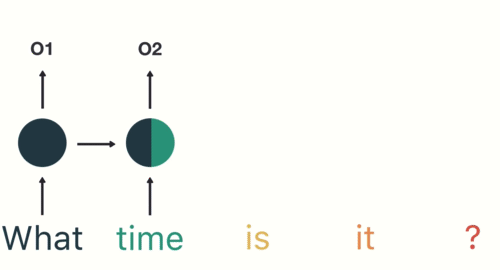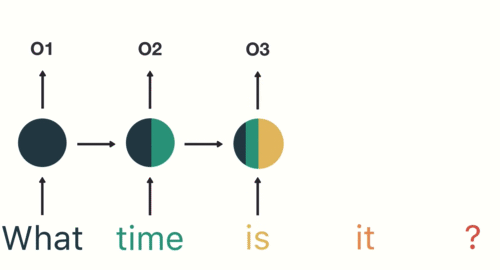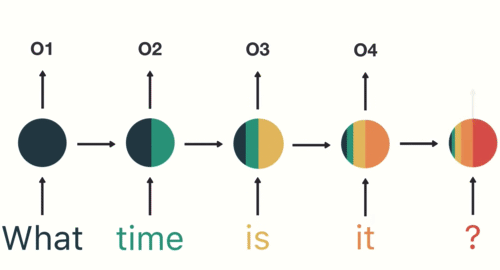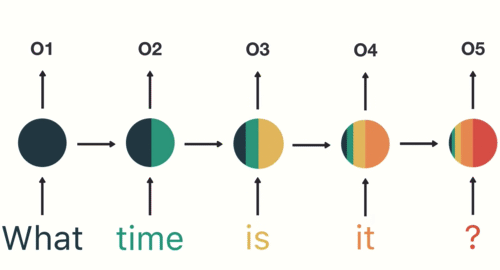
Representação “desenrolada”
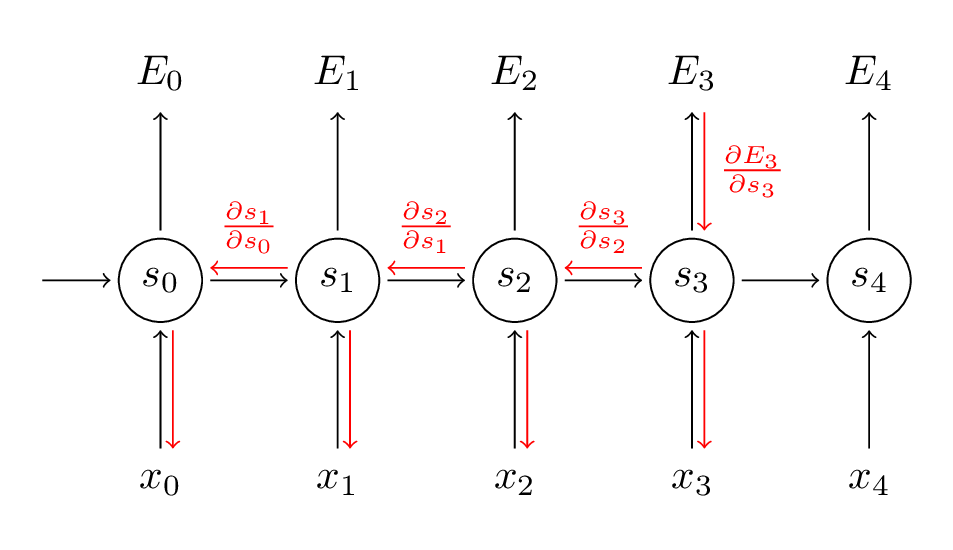
Back Propagation Through Time (BPTT)
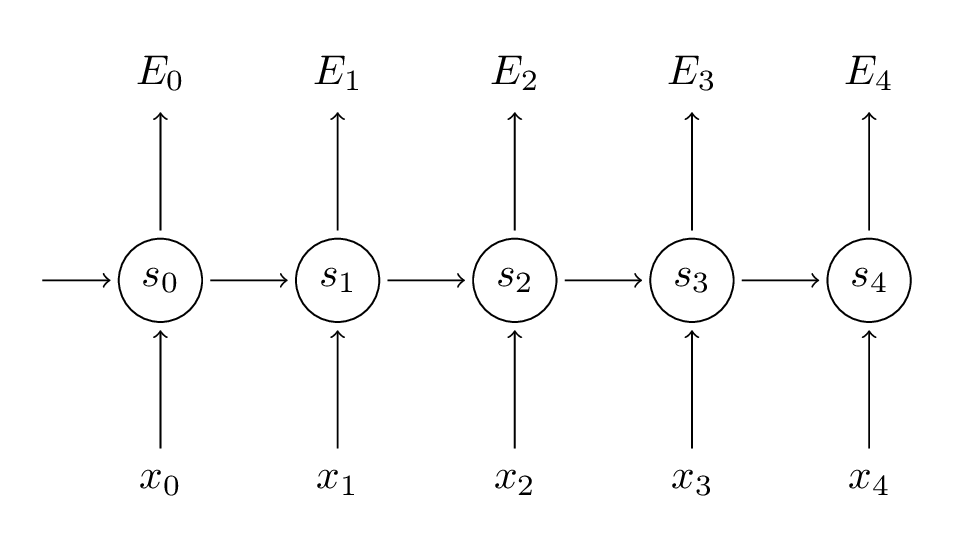
Back Propagation Through Time (BPTT)
Seq2Seq
Diversas tarefas de PLN lidam com sequências:
-
Tradução (Machine Translation)
-
Responder perguntas (Q&A)
-
Reconhecimento de fala (Speech Recognition)
Seq2Seq
RNN’s são capazes não somente de processar sequências como também de gerar sequências.
Uma arquitetura popular para tarefas Seq2Seq é a arquitetura Encoder Decoder.
Encoder Decoder
Redes Encoder Decoder possuem 2 partes:
-
Uma RNN chamada encoder que recebe uma sequência de tamanho qualquer e gera um vetor C de tamanho fixo.
-
Uma RNN chamada decoder que recebe o vetor C e gera uma sequência de tamanho qualquer.
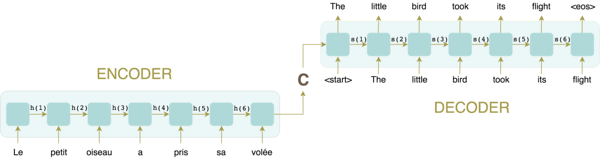
Redes Encoder Decoder possuem 2 partes:
-
Uma RNN chamada encoder que recebe uma sequência de tamanho qualquer e gera um vetor C de tamanho fixo.
-
Uma RNN chamada decoder que recebe o vetor C e gera uma sequência de tamanho qualquer.
Encoder Decoder
Redes Encoder Decoder possuem 2 partes:
-
Uma RNN chamada encoder que recebe uma sequência de tamanho qualquer e gera um vetor C de tamanho fixo.
-
Uma RNN chamada decoder que recebe o vetor C e gera uma sequência de tamanho qualquer.
Redes Encoder Decoder possuem 2 partes:
-
Uma RNN chamada encoder que recebe uma sequência de tamanho qualquer e gera um vetor C de tamanho fixo.
-
Uma RNN chamada decoder que recebe o vetor C e gera uma sequência de tamanho qualquer.
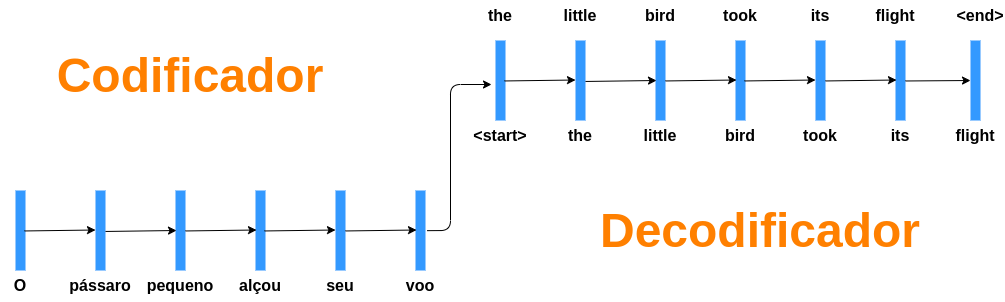
Encoder Decoder
O decoder recebe o último token gerado até prever um token especial <eos> que representa o fim de uma frase.
Possibilita a geração de um modelo neural de linguagem
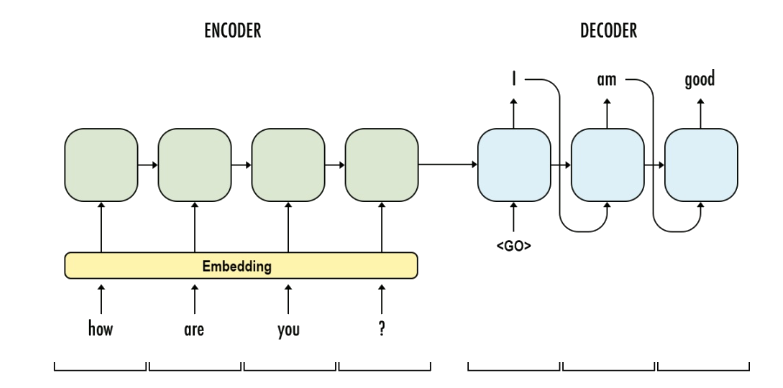
Auto-Alimentação do Decoder
Encoder
Decoder
Multiplicidade de Inputs e Outputs
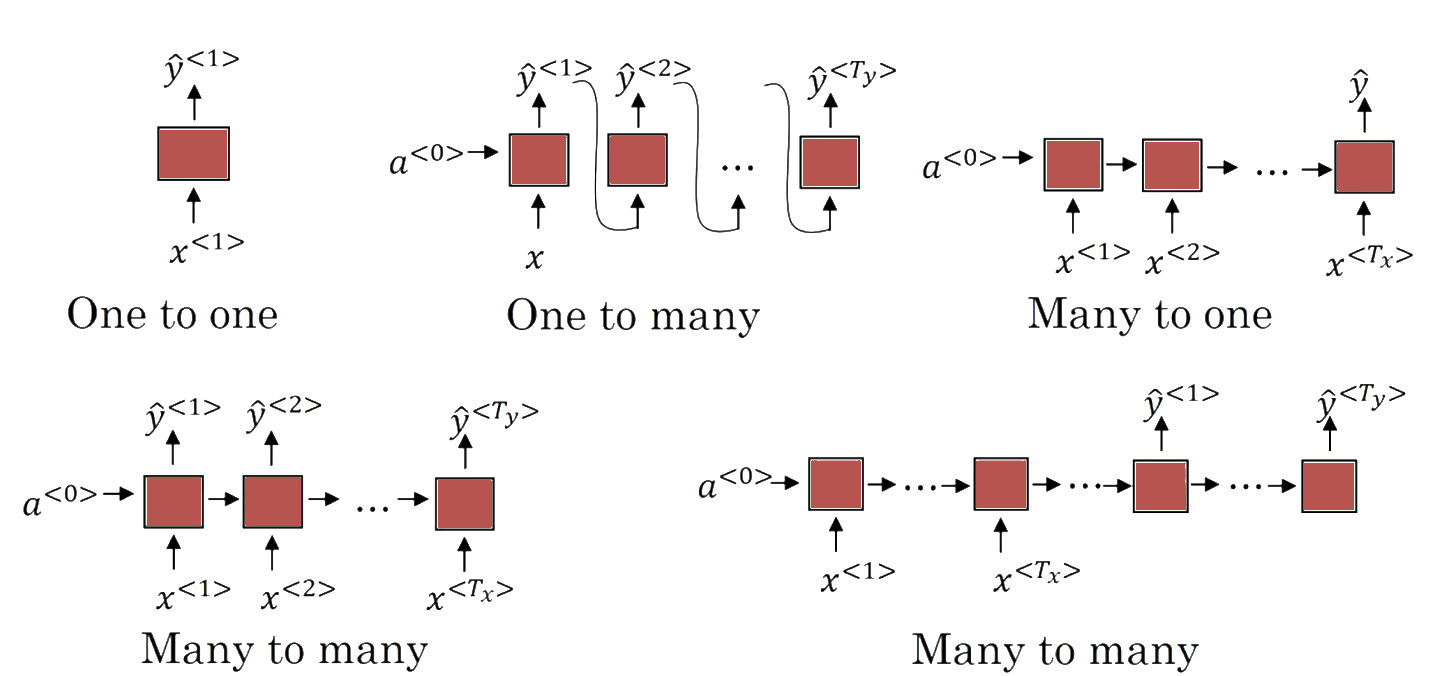
\(T_x \neq T_y\) (Encoder-Decoder)
\(T_x=T_y\)
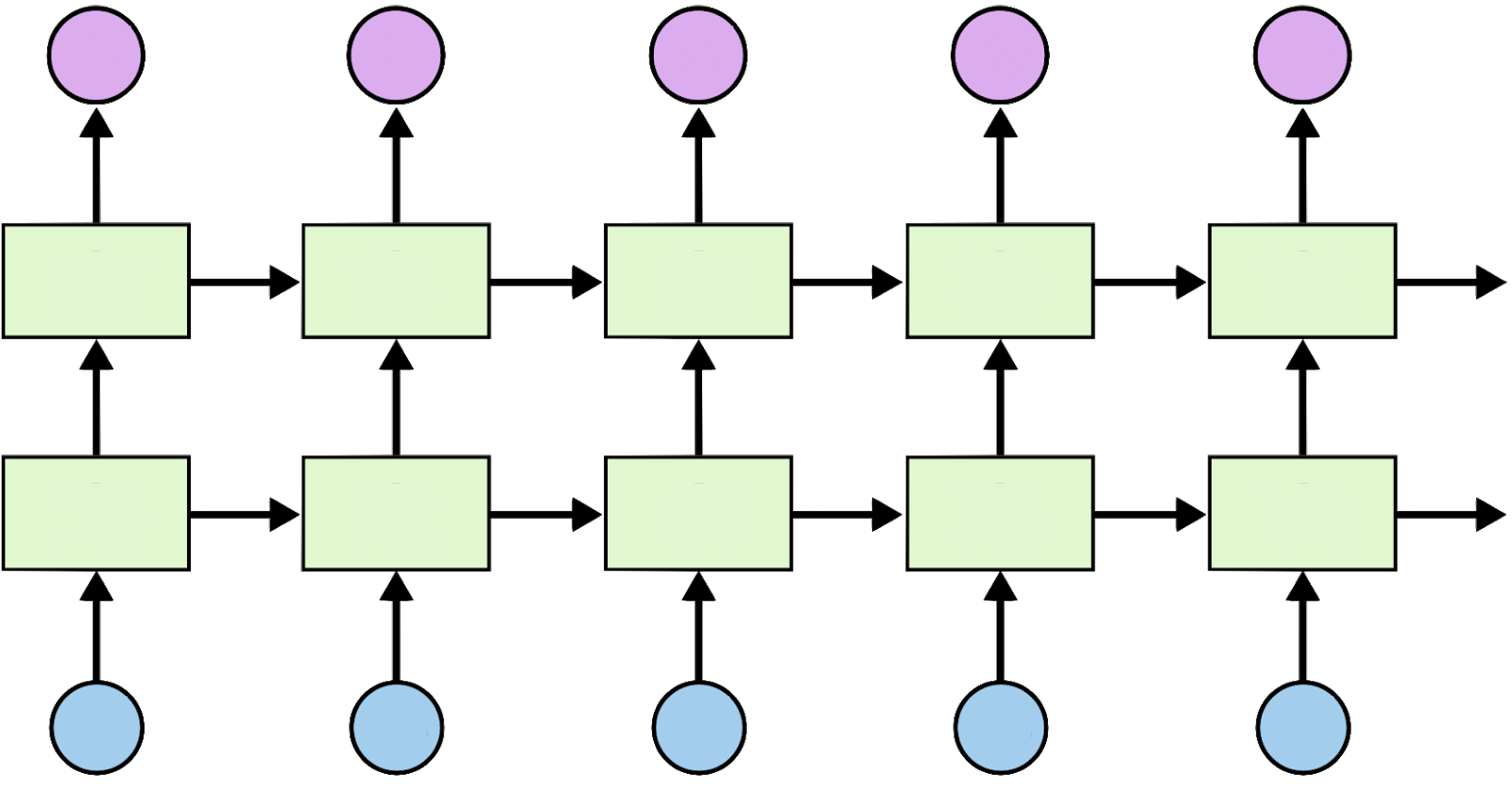
Ainda podemos adicionar camadas extras
Problemas de redes profundas
Vanishing & Exploding Gradient
O gradiente de uma camada é calculado pela regra da cadeia e portanto é um produto do gradiente de todas as camadas anteriores.
Vanishing & Exploding Gradient
O que acontece com uma camada se alguma das camadas anteriores possuir um gradiente muito pequeno? E se ele for muito grande?
Exploding Gradient
Com um gradiente muito elevado é possível que ao realizarmos uma etapa de backpropagation tomemos um passo muito grande que gere um update ruim (aumente a Loss).
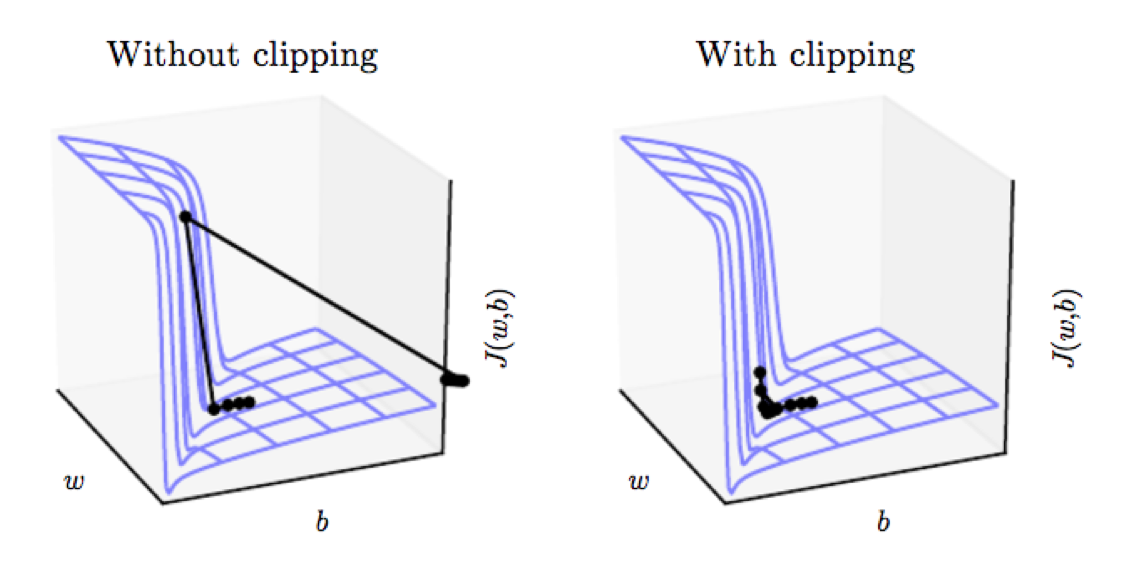
Se o passo for acima de um limite definido, nós diminuímos a magnitude do passo e mantemos a direção.
Gradient Clipping
from tensorflow import keras
keras.optimizers.SGD(lr=0.01, momentum=0.9, clipnorm=1.0)
Vanishing Gradient
O gradiente pode ser visto como uma medida da influência do passado no futuro.
Com um gradiente baixo a influência passa a ser baixa. Impossível capturar relações distantes.
Vanishing Gradient
Isso é um problema apenas de redes recorrentes?
Não! Toda rede profunda sofre destas questões, mas redes recorrentes são especialmente instáveis devido a utilização da mesma matriz de pesos.
Como combater Vanishing Gradient?
ReLu
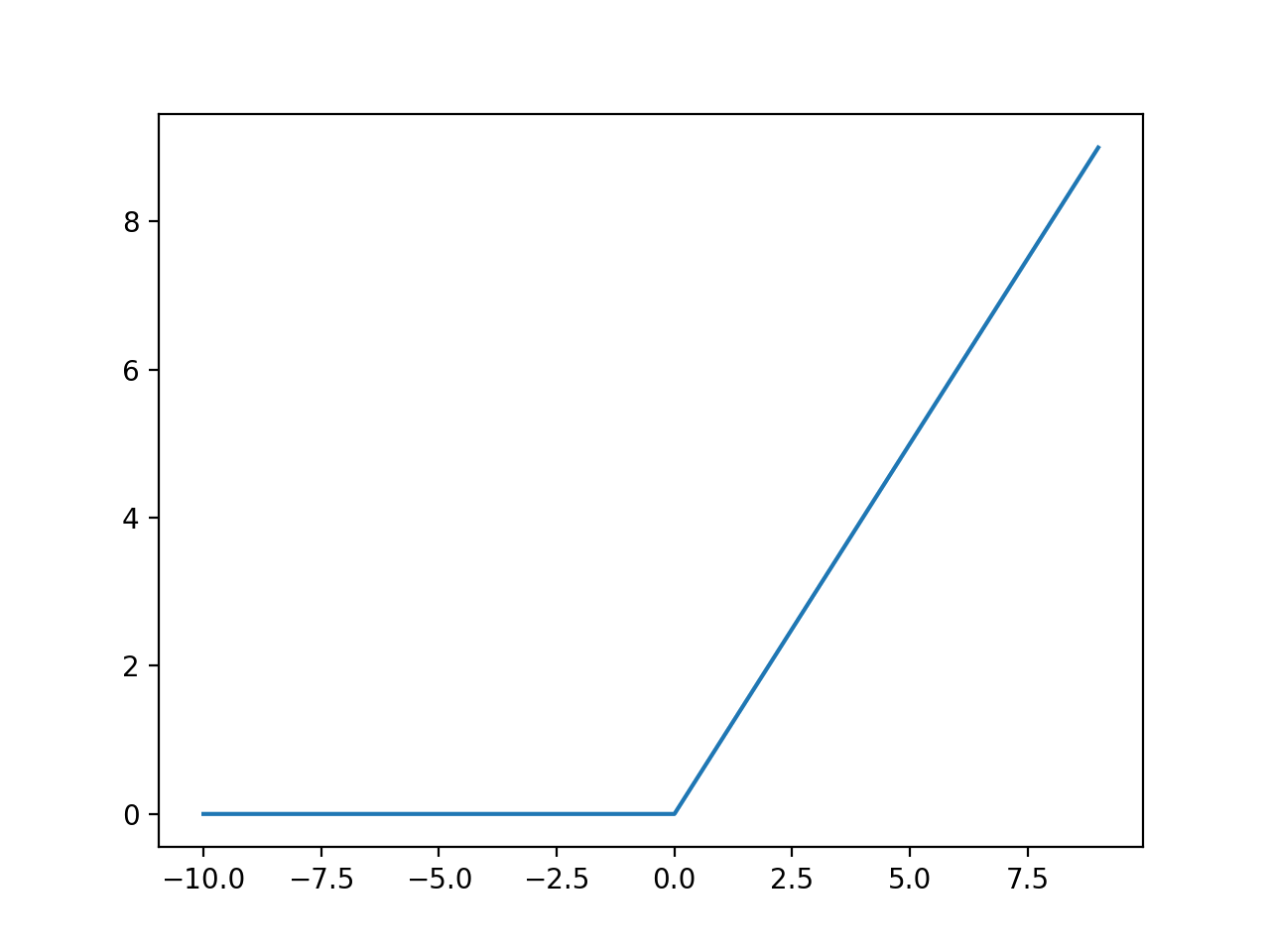
ReLu
Gradiente não fica saturado como \(tanh(x)\)
Como combater Vanishing Gradient?
Conexões Densas
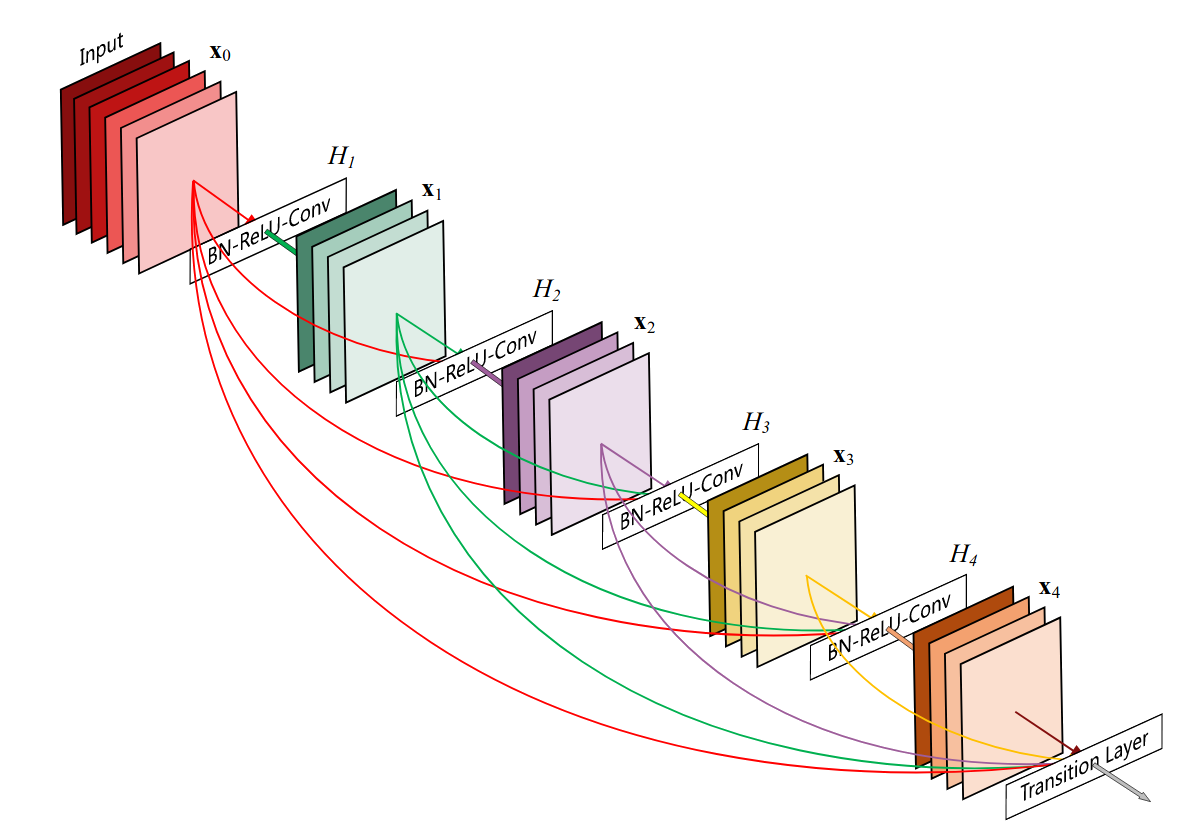
Conecte tudo com tudo
Como combater Vanishing Gradient?
Residual Connections
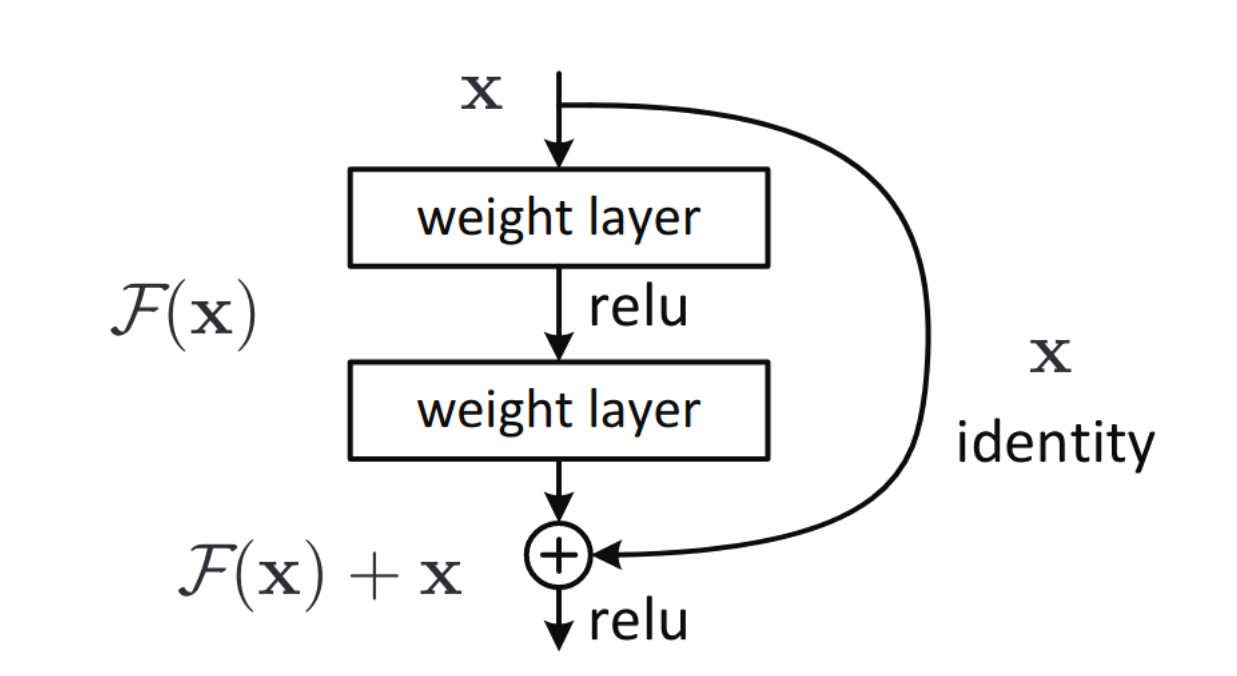
Também conhecidas como Skip-Connections.
São utilizadas no modelo Transformer
Como combater Vanishing Gradient?
Batch Normalization
Normalizar ajuda a impedir que as ativações saturem ao confiná-las em uma região.
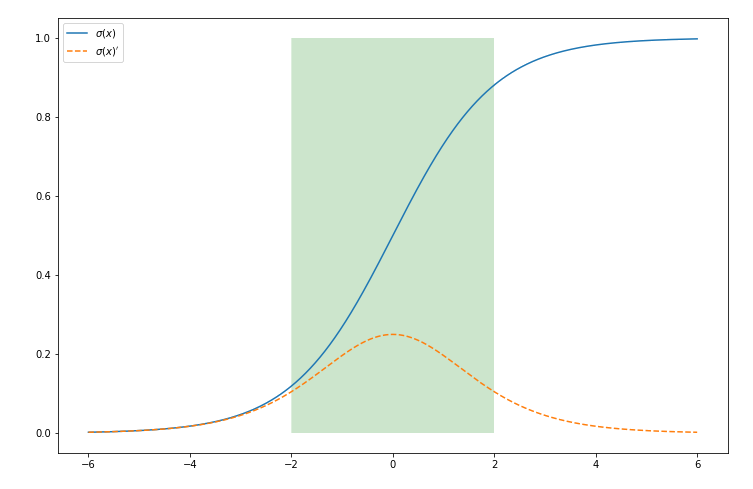
Como combater Vanishing Gradient?
Uma inicialização muito baixa nos leva a vanishing gradient e uma inicialização muito grande nos leva a exploding gradient.
Como podemos inicializar os pesos de uma maneira apropriada?
- Inicialização de Xavier Glorot para ativações simétricas (como a tanh)
- Inicialização de Kaiming He para ativações assimétricas (como a ReLu)