SubWord Tokenizers
Overview
- Motivação
- Usando caracteres
- Redes Convolucionais
- Byte Pair Encoding (BPE)
- WordPiece
- Unigram
Motivação
Nem todas as línguas utilizam espaços para delimitar palavras, como o japonês:
アラン katakana
がいのはです hiragana
背高外国人 kanji
アランは背が高いの外国人です。
Aran wa se ga takai no gaikokujin desu.
Alan é um estrangeiro alto.
Motivação
Frauenfußball-Weltmeisterschaft
Copa do Mundo de Futebol Feminino
No alemão é comum contrair palavras para formarmos outras palavras:
Motivação
Frauenfußball-Weltmeisterschaft
Frauen = Mulheres
Fußball = Futebol
Welt = Mundo
Meisterschaft = Meister + Schaft = Campeonato
Meister = Campeão
Schaft = "Conjunto de"
Motivação
Mesmo sem impormos limitações ao tamanho de nosso vocabulário, sempre encontraremos palavras Out-Of-Vocabulary. Línguas reais possuem um vocabulário potencialmente infinito.
Motivação
Pares de palavras semelhantes onde uma estava presente no treinamento e outra não são incapazes de compartilhar informação:
"companheiro" : Presente em treinamento, <companheiro>
"companheiros": Ausente em treinamento, <OOV>
E se usarmos os caracteres diretamente ao invés de palavras?
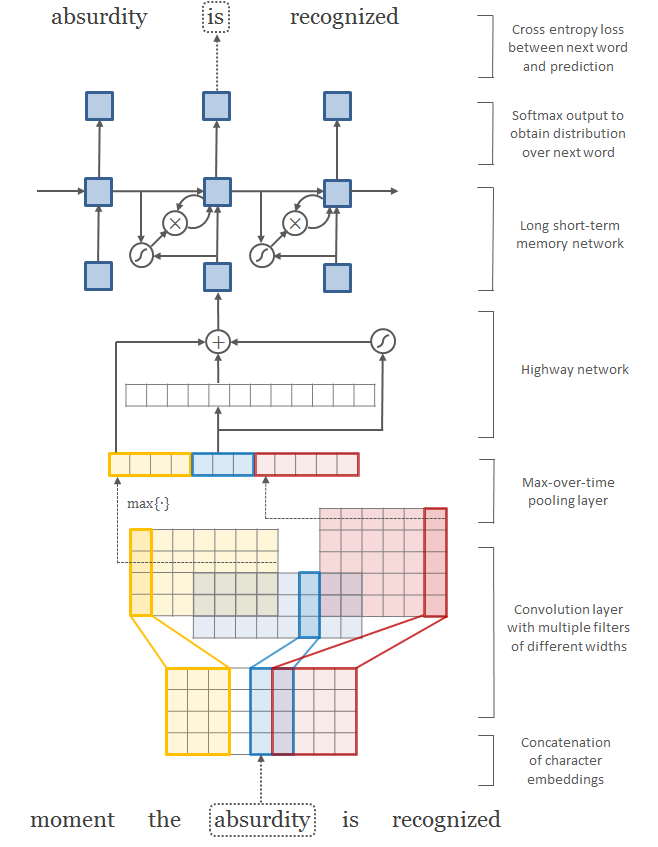
Character embeddings
Redes Convolucionais
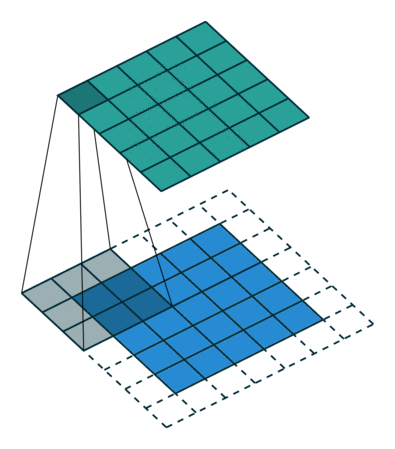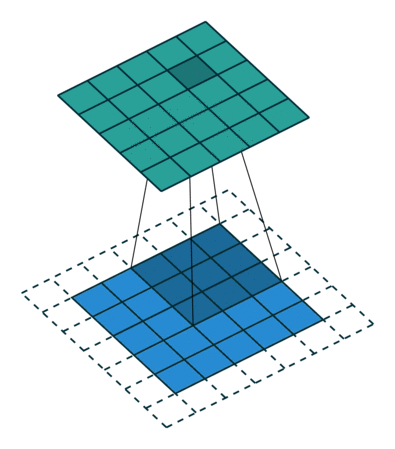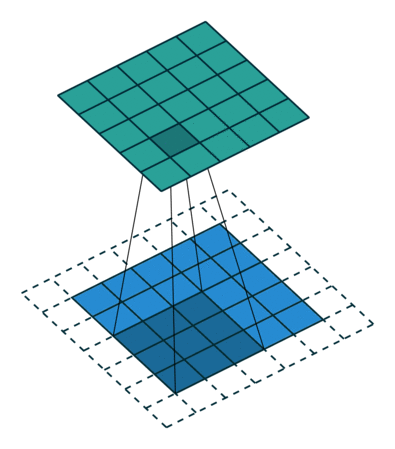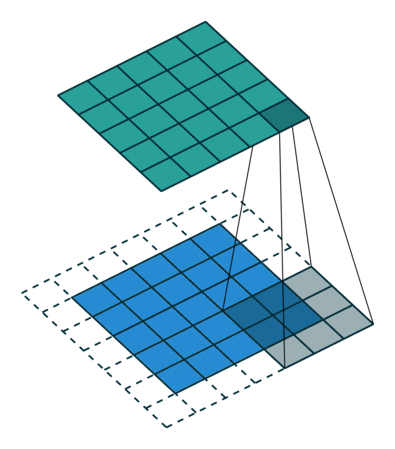
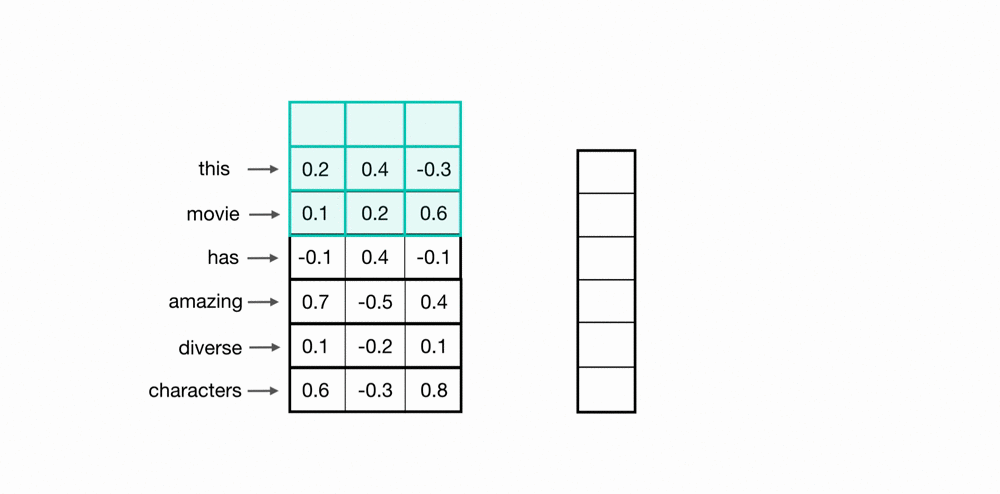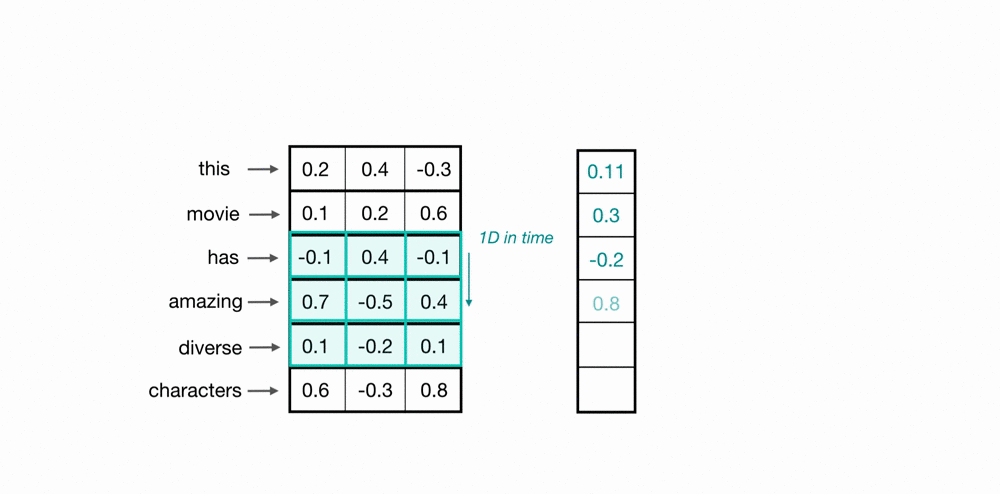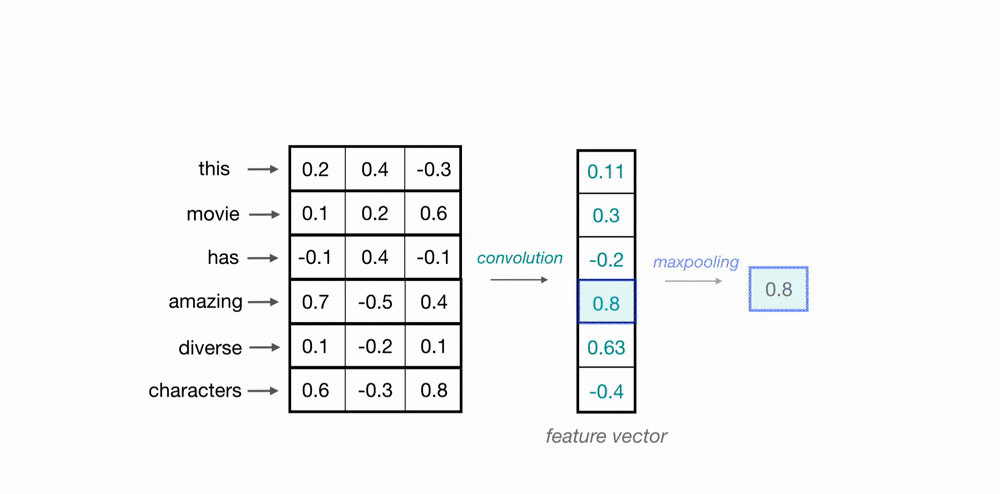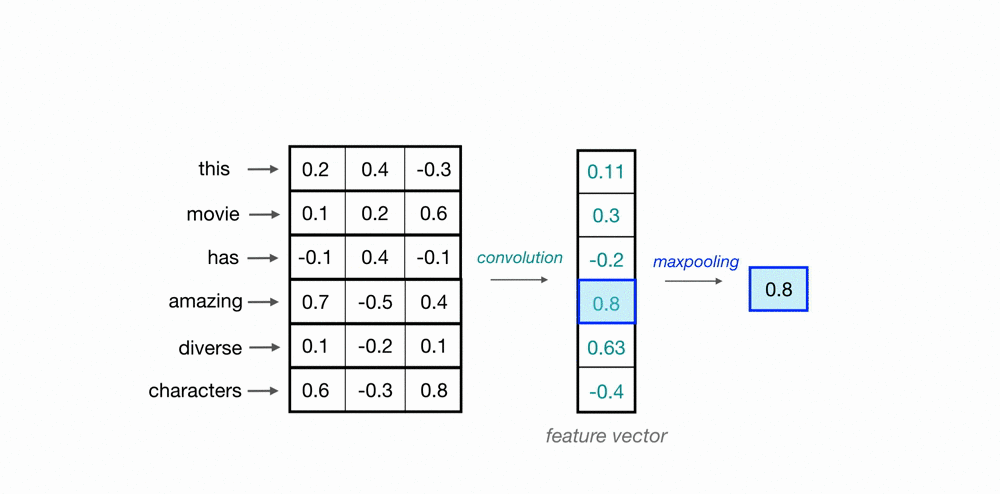
Redes Convolucionais
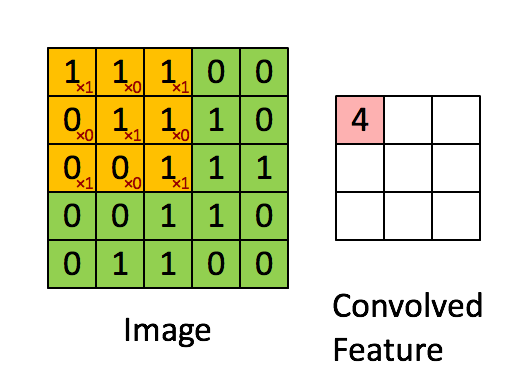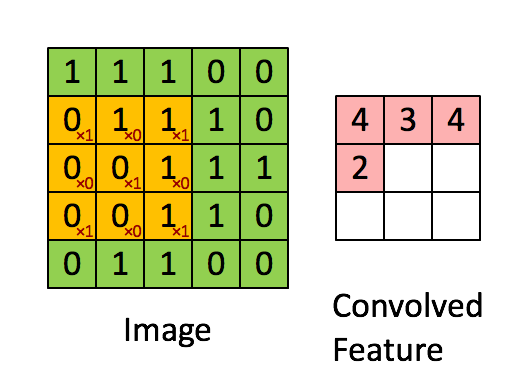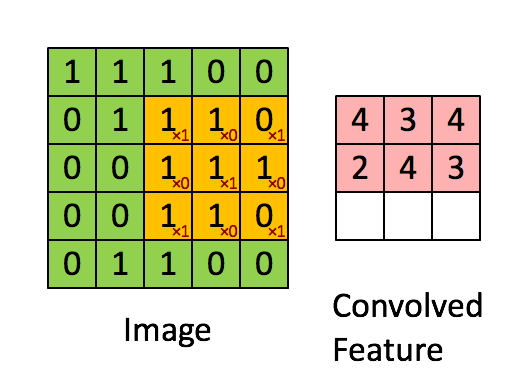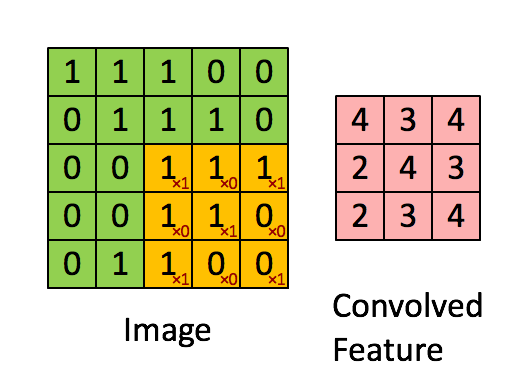

Max Pooling
Convoluções 1D
tf.keras.layers.Conv1D(
filters,
kernel_size,
strides=1,
padding="valid",
data_format="channels_last",
dilation_rate=1,
groups=1,
activation=None,
use_bias=True,
kernel_initializer="glorot_uniform",
bias_initializer="zeros",
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
Character embeddings
Inspirada por LSTM's e similares a conexões residuais, mais uma forma de combater vanishing gradient.
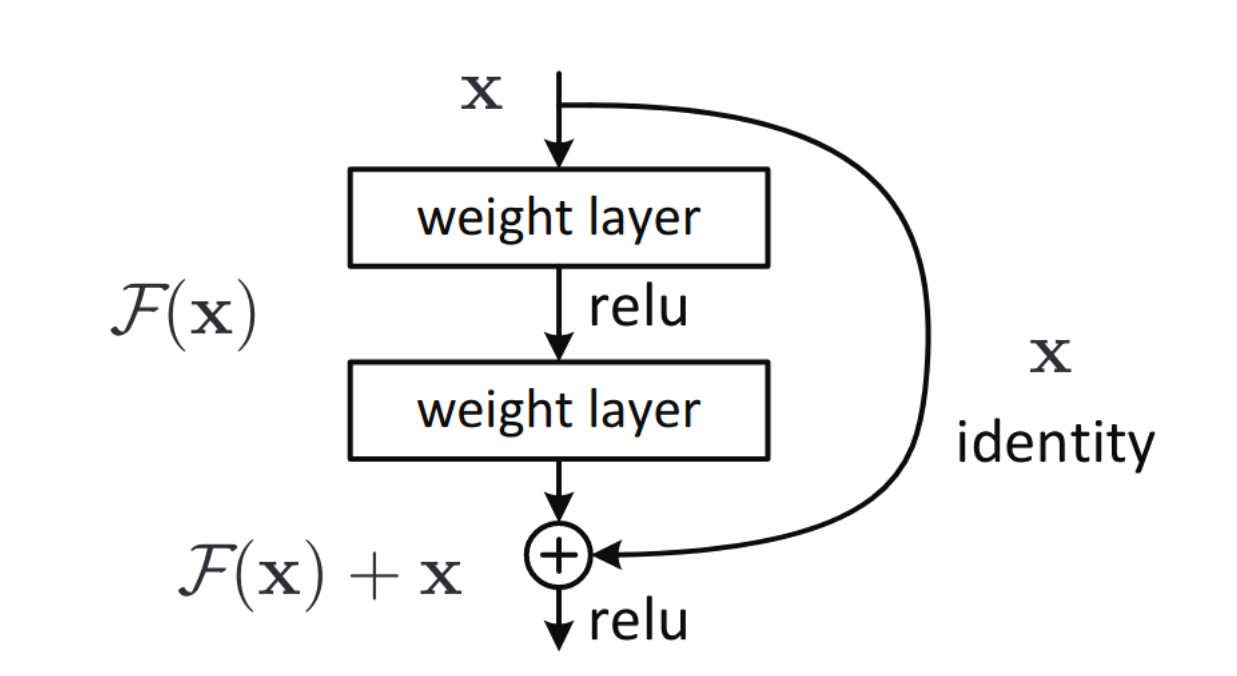
Introduz um gate que serve como "atalho" na sua rede. Uma espécie de conexão residual chaveada.
(Conexão
residual)
Ok, e se tentarmos algo intermediário?
Morfemas
Menor unidade, dotada de significado, de uma língua.
Junção de morfemas formam palavras:
Infelizmente: In- (prefixo)
-feliz- (radical)
-mente (sufixo)
Originalmente um algoritmo para compressão de dados, foi adaptado em 2016 para aglomerar caracteres e gerar tokens a nível de sub-palavras (um tipo de stemming que não descarta sub-palavras).
Vamos tomar as seguintes palavras como nosso vocabulário (junto com a frequencia com que aparecem em nosso corpus):
('hug', 10), ('pug', 5), ('pun', 12), ('bun', 4), ('hugs', 5)
Comece a partir da lista de todos os caracteres possíveis como seu conjunto de tokens iniciais:
[h,u,g,n,p,b,s]
Então vá definindo regras para concatenar tokens e até atingir um número máximo pré-definido de tokens.
('h' 'u' 'g', 10),
('p' 'u' 'g', 5),
('p' 'u' 'n', 12),
('b' 'u' 'n', 4),
('h' 'u' 'g' 's', 5)
Qual par de tokens aparece com maior frequência?
‘hu’ aparece 10 + 5 = 15 vezes enquanto ‘ug’ aparece 10 + 5 + 5 = 20 vezes.
('h' 'u' 'g', 10),
('p' 'u' 'g', 5),
('p' 'u' 'n', 12),
('b' 'u' 'n', 4),
('h' 'u' 'g' 's', 5)
Primeira concatenação de tokens: 'ug'
Novo vocabulário: ['b', 'g', 'h', 'n', 'p', 's', 'u', 'ug']
('h' 'ug', 10),
('p' 'ug', 5),
('p' 'u' 'n', 12),
('b' 'u' 'n', 4),
('h' 'ug' 's', 5)
Primeira concatenação de tokens: 'ug'
Novo vocabulário: ['b', 'g', 'h', 'n', 'p', 's', 'u', 'ug']
# Source: https://arxiv.org/pdf/1508.07909.pdf
import re, collections
def get_stats(vocab):
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in):
v_out = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
vocab = {'l o w </w>' : 5,
'l o w e r </w>' : 2,
'n e w e s t </w>':6,
'w i d e s t </w>':3}
num_merges = 10
for i in range(num_merges):
pairs = get_stats(vocab)
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print(best)E se utilizarmos outra regra para concatenar tokens?
Funciona de maneira análoga ao BPE, porém decide quais tokens concatenar de maneira a maximizar a verossimilhança de um dado corpus após a concatenação.
No exemplo anterior, nós apenas concatenaríamos 'u' e 'g' se a probabilidade de termos 'ug' divida pela probabilidade de termos 'u' e depois 'g' seja maior do que para qualquer outro par de tokens.
Ao invés de partir dos caracteres individuais e ir construindo novos tokens, partimos de um vocabulário maior do que o desejado composto por: palavras, substrings mais comuns e os caracteres individuais.
A cada passo calculamos qual seria a loss de retirar uma token do vocabulário e excluímos aquelas que trariam o menor aumento da loss, repetimos esse processo até atingir um tamanho de vocabulário definido previamente