DEEP LEARNING AND ARTIFICIAL INTELLIGENCE
Andrew Beam, PhD
Postdoctoral Fellow
Department of Biomedical Informatics
Harvard Medical School
April 17th, 2017
twitter: @AndrewLBeam
ADDITIONAL MATERIAL
Deep Learning 101 companion series of blog posts:
http://beamandrew.github.io
Previous Talk:
https://www.youtube.com/watch?v=xuIKzt5G21c
DEEP LEARNING BREAKTHROUGHS
DEEP LEARNING HAS MASTERED GO




DEEP LEARNING CAN PLAY VIDEO GAMES

DEEP LEARNING CAN PLAY VIDEO GAMES

DEEP LEARNING CAN IMITATE STYLE
DEEP LEARNING CAN TRANSLATE

https://www.nytimes.com/2016/12/14/magazine/the-great-ai-awakening.html?_r=0
DEEP LEARNING CAN TRANSLATE
Image credit: https://research.googleblog.com/2016/09/a-neural-network-for-machine.html

EVERYONE IS USING DEEP LEARNING


WHAT IS A NEURAL NET?
NEURAL NETWORKS ARE AN OLD IDEA
One of the very first ideas in machine learning and artificial intelligence
- Date back to 1940s
- Many cycles of boom and bust
- Repeated promises of "true AI" that were unfulfilled followed by "AI winters"

Are today's neural nets any different than their predecessors?
"[The perceptron is] the embryo of an electronic computer that [the Navy] expects will be able to walk, talk, see, write, reproduce itself and be conscious of its existence." - Frank Rosenblatt, 1958
MILESTONES

IN THE BEGINNING... (1940s-1960s)

Warren McCulloch and Walter Pitts (1943)
Thresholded logic unit with hardcoded weights
Intended to mimic "integrate and fire" model of neurons
IN THE BEGINNING... (1940s-1960s)
Rosenblatt's Perceptron, 1957

- Initially very promising
- Came with provably correct learning algorithm
- Could recognize letters and numbers
THE FIRST AI WINTER (1969)


Minsky and Papert show that the perceptron can't even solve the XOR problem
Kills research on neural nets for the next 15-20 years
THE BACKPROPAGANDISTS EMERGE (1986)

Rumelhart, Hinton, and Willams show us how to train multilayered neural networks

REBRANDING AS 'DEEP LEARNING' (2006)
Unsupervised pre-training of "deep belief nets" allowed for large and deeper models

Image credit: https://www.toptal.com/machine-learning/an-introduction-to-deep-learning-from-perceptrons-to-deep-networks
THE BREAKTHROUGH (2012)
Imagenet Database
- Millions of labeled images
- Objects in images fall into 1 of a possible 1,000 categories
- Relatively high-resolution
- Bounding boxes giving exact location of object - useful for both classification and localization
Large Scale Visual
Recognition Challenge (ILSVRC)
- Annual Imagenet Challenge starting in 2010
- Successor to smaller PASCAL VOC challenge
- Many tracks including classification and localization
- Standardized training and test set. Competitors upload predictions for test set and are automatically scored
THE BREAKTHROUGH (2012)
Pivotal event occurred in an image recognition contest which brought together 3 critical ingredients for the first time:
- Massive amounts of labeled images
- Training with GPUs
- Methodological innovations that enabled training deeper networks while minimizing overfitting
THE BREAKTHROUGH (2012)
In 2011, a misclassification rate of 25% was near state of the art on ILSVRC
In 2012, Geoff Hinton and two graduate students, Alex Krizhevsky and Ilya Sutskever, entered ILSVRC with one of the first deep neural networks trained on GPUs, now known as "Alexnet"
Result: An error rate of 16%, nearly half what the second place entry was able to achieve.
The computer vision world immediately took notice
THE ILSVRC AFTERMATH (2012-2014)

Alexnet paper has ~ 10,000 citations since being published in 2012!
NETS KEEP GETTING DEEPER (2012-2016)

WHAT'S CHANGED? WHY NOW?
Several key advancements has enabled the modern deep learning revolution
WHAT'S CHANGED? WHY NOW?
Several key advancements have enabled the modern deep learning revolution

Availability of massive datasets
with high-quality labels
Standardized benchmarks of progress and open source tools
Community acknowledgment that
open data -> everyone gets better
WHAT'S CHANGED? WHY NOW?
Several key advancements have enabled the modern deep learning revolution
Advent of massively parallel computing by GPUs. Enabled training of huge neural nets on extremely large datasets
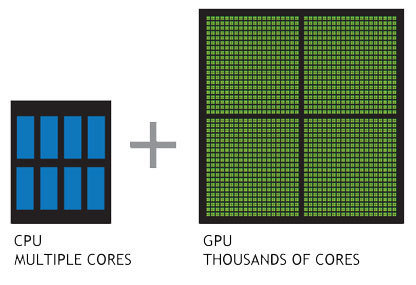


WHAT'S CHANGED? WHY NOW?
Several key advancements have enabled the modern deep learning revolution
Methodological advancements have made deeper networks easier to train

Architecture

Optimizers

Activation Functions
WHAT'S CHANGED? WHY NOW?
Several key advancements have enabled the modern deep learning revolution
Robust frameworks and abstractions make iteration faster and less error prone
Automatic differentiation allows easy prototyping




WHAT'S CHANGED? WHY NOW?
This all leads to the following hypothesis
Deep Learning Hypothesis: The success of deep learning is largely a success of engineering.
Personal belief: Things are different with neural nets this time around
WHAT'S CHANGED? WHY NOW?
These advancements have been transferred to other fields




Doctors were crucial... in creating the labeled dataset!
WHAT'S CHANGED? WHY NOW?
These advancements have been transferred to other fields


Off the shelf, pre-trained deep neural network + 130,000 images = expert level diagnostic accuracy
Introduction to Deep Learning Models
MULTILAYER PERCEPTRONS (MLPs)
- Most generic form of a neural net is the "multilayer perceptron"
- Input undergoes a series of nonlinear transformation before a final classification layer

MULTILAYER PERCEPTRONS (MLPs)
- MLPs are the easiest entry point to understand what's going on in a deep learning model
- Closely related to logistic regression
LOGISTIC REGRESSION REFRESHER
Pretend we just have one variable:
... and a class label:
LOGISTIC REGRESSION REFRESHER
Pretend we just have one variable:
... and a class label:
... we construct a function to predict y from x:
LOGISTIC REGRESSION REFRESHER
Pretend we just have one variable:
... and a class label:
... we construct a function to predict y from x:
... and turn this into a probability using the logistic function:
LOGISTIC REGRESSION REFRESHER
Pretend we just have one variable:
... and a class label:
... we construct a function to predict y from x:
... and turn this into a probability using the logistic function:
... and use Bernoulli negative log-likelihood as loss:
LOGISTIC REGRESSION REFRESHER
Pretend we just have one variable:
... and a class label:
... we construct a function to predict y from x:
... and turn this into a probability using the logistic function:
This is good old-fashioned logistic regression
... and use Bernoulli negative log-likelihood as loss:
LOGISTIC REGRESSION REFRESHER
How do we learn the "best" values for ?
LOGISTIC REGRESSION REFRESHER
How do we learn the "best" values for ?
Gradient Decscent
- Give weights random initial values
- Evaluate partial derivative of each weight with respect negative log-likelihood at current weight value
- Take a step in direction opposite to the gradient
- Rinse and repeat
LOGISTIC REGRESSION REFRESHER
This in essence is the entire "learning" algorithm
behind modern deep learning. Keep this in mind.

Gradient Decscent
- Give weights random initial values
- Evaluate partial derivative of each weight with respect negative log-likelihood at current weight value
- Take a step in direction opposite to the gradient
- Rinse and repeat
How do we learn the "best" values for ?
LOGISTIC REGRESSION -> NEURAL NET
With a small change, we can turn our logistic regression model into a neural net
- Instead of just one linear combination, we are going to take several, each with a different set of weights (called a hidden unit)
- Each linear combination will be followed by a nonlinear activation
- Each of these nonlinear features will be fed into the logistic regression classifier
MLPs learn a set of nonlinear features directly from data
"Feature learning" is the hallmark of deep learning approachs
DEEP LEARNING FOR UNDERSTANDING HUMAN LANGUAGE
NATUAL LANGUAGE PROCESSING
Computers struggle to understand human language
- Computers are built to process numbers
- Language isn't easily represented by numbers
Natural Language Processing: A field of computer science studying how to get computers to understand human language
NATUAL LANGUAGE PROCESSING
Humans use language in a very fluid manner
Imagine the following hypothetical human-computer dialog
NATUAL LANGUAGE PROCESSING
Humans use language in a very fluid manner
Human: Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo
Imagine the following hypothetical human-computer dialog
NATUAL LANGUAGE PROCESSING
Humans use language in a very fluid manner
Human: Buffalo buffalo Buffalo buffalo buffalo buffalo Buffalo buffalo
Imagine the following hypothetical human-computer dialog
Computer:

https://en.wikipedia.org/wiki/Buffalo_buffalo_Buffalo_buffalo_buffalo_buffalo_Buffalo_buffalo
NATUAL LANGUAGE PROCESSING
Computers struggle to understand human language
Example question in NLP: How do we "measure" how "similar" two words are?
- cat vs dog?
- hotdog vs frank?
- near vs far?
- cancer vs metastatic?
- jupiter vs hot chocolate?
NATUAL LANGUAGE PROCESSING
Computers struggle to understand human language

"You shall know a word by the company it keeps"
Papers in Linguistics 1934–1951 (1957) London: Oxford University Press.
Similar Contexts -> Similar Meaning
WORD VECTORS
Word vectors encode semantic similarity between words
Introduced by neural net community to tackle hard problems in NLP
Key Idea: Represent a word as a point in space
- Each word is a vector in this space
- Words that are close to each other are "similar"
- Works on large collections of "unlabeled" text
WORD VECTORS
Key Idea: Represent a word as a point in space
- Each word is a vector in this space
- Words that are close to each other are "similar"
- Works on large collections of "unlabeled" text
Neural Net's Goal: Construct vectors such that two vectors are similar if the corresponding words occur in similar contexts and are dissimilar otherwise.
Text collection in -> vector for each word out
Word vectors encode semantic similarity between words
WORD VECTORS

WORD VECTORS
Word vectors encode certain properties of words

WORD VECTORS
MEDICAL CONCEPT VECTORS DEMO
DEEP LEARNING FOR MEDICAL NLP
Word vectors are the building blocks for deep learning
Using word vectors, we can construct a neural network analyzes large amount of medical data and:
- Takes in a patient description and produces a diagnosis
- Reads a medical question and selects the right answer
- Retrieves the most relevant piece of text for a users query
DEEP LEARNING FOR MEDICAL NLP

DEEP LEARNING FOR MEDICAL NLP

DEEP LEARNING FOR HEALTHCARE
Huge potential for improving medicine and healthcare
- Can analyze and integrate all available medical knowledge
- Help doctors be smarter and faster when seeing patients - automate "tedious" parts of their job
- Improve access to high-quality medical information for underserved patients