Attention & Transformers
Benjamin Akera
With applications in NLP
SLIDES
LAB


PART 0
WhoAmI ?
McGill University | Mila - Quebec AI Inst.
Sunbird AI
IBM Research Africa - Kenya
DSA Since 2017
NLP
What is it?
Who has used it?
A few Examples ?
Why I find it exciting
What this talk is Not
A complete introduction to NLP
Does not cover all models, aspects, papers, architectures
Not preaching, should be interactive: Ask
What this talk is:
An overview of recent simple architectural tricks that have influenced NLP as we know it now, with Deep Learning
Interactive
Ask as many questions
Let's Consider: You're at The Border
Jina yako ni nani?
Unaitwa nani?
How???
PART 1
Attention
〞
Attention; What is it?
– Question
Scenario: A Party
Relates elements in a source sentence to a target sentence
Attention
Source Sentence
Target Sentence
H
a
b
a
r
i
H
e
l
l
o

BERT
T4
ELMo
GPT3
Neural MT
DALL.E
Sunbird translate
FB Translate
multimodal learning
Speech Recognition
Relates elements in a source sentence to a target sentence
Attention
Source Sentence
Target Sentence
H
a
b
a
r
i
H
e
l
l
o
Relates elements in a source sentence to a target sentence
Attention
H
a
b
a
r
i
H
e
l
l
o
Self Attention
Multi-Head attention
Types of Attention Mechanisms
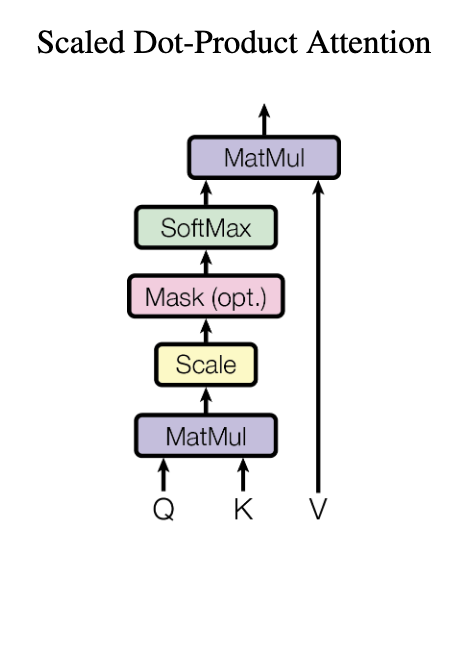
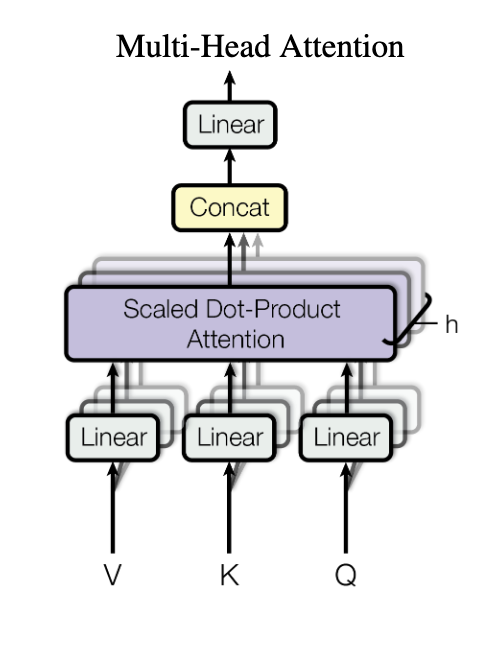
Self Attention
Is when when your source and target sentences are the same
G
n
i
a
H
a
b
a
r
i
?
Multi headed Attention
Compute K Attention in Parallel
Allows more than one relation
Attention Head 1
Attention Head 2
Attention Head 3
Attention Head 4
1.Habari gani? 2.Jina yako ni nani? 3.Una toka wapi? 4.Unaitwa nani?
1.How are you? 2.What is your name? 3.Where do you come from? 4.What is your name ?
Attention Head
PART 2
Transformers
〞
Transformers
What are they?

Transformers?

Transformers?
Transformers
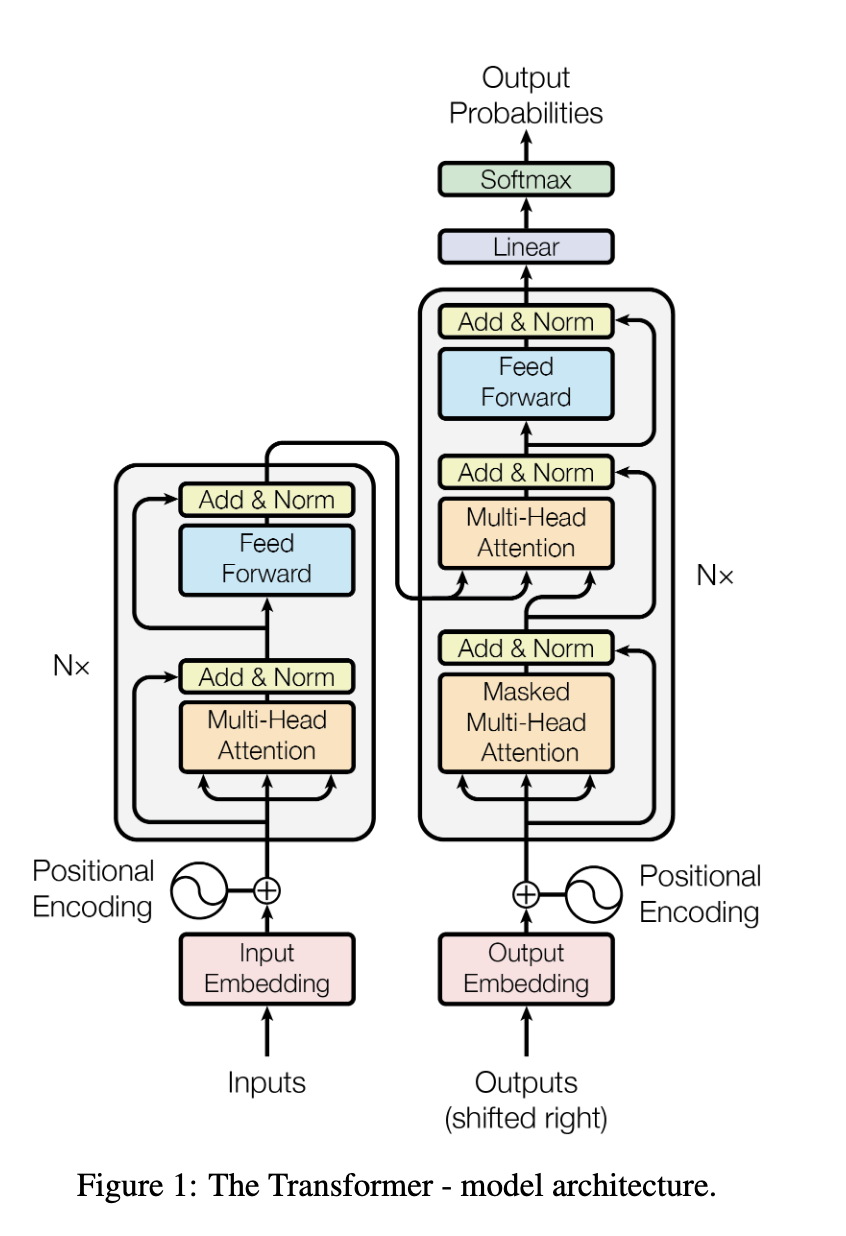
Transformers
Sequence
Attention
Positional
Encoding
Decoders
1. Self Attention + Multi-Head attention
Multi-head attention
Self Attention
2. Encoder
Positional Encoding
Positional Encoding
When we compare two elements of a sequence together (like in attention)
we don’t have a notion of how far apart they are or where one is relative to the other
\( PE_{(pos, 2_i)} = sin (pos/10000^{{2i}/d_{model}}) \)
\( PE_{(pos, 2_i + 1)} = sin (pos/10000^{{2i}/d_{model}}) \)
Positional Encoding
When we compare two elements of a sequence together (like in attention)
we don’t have a notion of how far apart they are or where one is relative to the other
\( PE_{(pos, 2_i)} = sin (pos/10000^{{2i}/d_{model}}) \)
\( PE_{(pos, 2_i + 1)} = sin (pos/10000^{{2i}/d_{model}}) \)
Using a linear combination of these signals we can “pan” forwards or backwards in the sequence.
Decoder
Decoder
Fast Auto-regressive Decoding
Sequence generation
Learn a map from input sequence to output sequence:
\( y_o, . . ., y_T = f(x_0,....x_N) \)
In reality tend to look like this:
\( \hat y_o, . . ., \hat y_T = decoder(encoder(x_0,....x_N)) \)
Fast Auto-regressive Decoding
Autoregressive Decoding
Condition each output on all previously generated outputs
\( \hat y_o = decoder(encoder(x_0,....x_N)) \)
\( \hat y_1 = decoder(\hat y_0, encoder(x_0,....x_N)) \)
\( \hat y_2 = decoder(\hat y_0, y_1, encoder(x_0,....x_N)) \)
\( \hat y_{t+1} = decoder(\hat y_0, y_1...y_t, encoder(x_0,....x_N)) \)
.
.
Fast Auto-regressive Decoding
Autoregressive Decoding
At train time, we have access to all the true targets outputs
\( \hat y_o = decoder(encoder(x_0,....x_N)) \)
\( \hat y_1 = decoder(\hat y_0, encoder(x_0,....x_N)) \)
\( \hat y_{t+1} = decoder(\hat y_0, y_1...y_t, encoder(x_0,....x_N)) \)
.
Question: How do we squeeze all of these into one call of our decoder?
Attention
If we feed all our inputs and targets, it is easy to cheat using Attention
<pad> What is your name?
<pad> Jina lako ni nani?
?
Jina
lako
ni
nani
?
what
is
your
name
<PAD>
<pad> Jina lako ni nani?
If we feed all our inputs and targets, it is easy to cheat using Attention
what
is
your
name
?
Jina
lako
ni
nani
?
<PAD>
When we apply this triangular mask, the attention can only look into the past instead of being able to cheat and look into the future.
If we feed all our inputs and targets, it is easy to cheat using Attention
what
is
your
name
?
Jina
lako
ni
nani
?
<PAD>
\( \hat y_o = decoder(encoder(x_0,....x_N)) \)
\( \hat y_1 = decoder(\hat y_0, encoder(x_0,....x_N)) \)
\( \hat y_2 = decoder(\hat y_0, y_1, encoder(x_0,....x_N)) \)
\( \hat y_{t+1} = decoder(\hat y_0, y_1...y_t, encoder(x_0,....x_N)) \)
.
.
If we feed all our inputs and targets, it is easy to cheat using Attention
Jina yako ni [MASK]?
[MASK] is your name?
We Call this Masked Language Models
PART 4
Applications,
Labs,
Questions
Neural Machine Translation
Text Generation
Image Classification
Multi-modal learning
....
Applications
Attention
Transformers
Encoder Block
Decoder Block
Positional Encoding
Summary
End to End Neural Machine Translation with Attention
Take Home: Reproduce a model using SALT Dataset
LAB