Humanités numériques
Données et traitement(s)
Benjamin Hervy
Ingénieur de recherche - Nantes Université
benjamin.hervy@univ-nantes.fr

10/03/26 - École Centrale de Nantes
Informatique et numérique
Qu'est-ce que le numérique ? Milad Doueihi, 2013
Informatique comme science
Informatique comme industrie
Informatique comme culture
Humanités numériques
Humanités numériques
(Tentative de) définition : ThatCamp 2010- Manifeste
« Pour nous, les digital humanities concernent l’ensemble des Sciences humaines et sociales, des Arts et des Lettres. Les digital humanities ne font pas table rase du passé. Elles s’appuient, au contraire, sur l’ensemble des paradigmes, savoir-faire et connaissances propres à ces disciplines, tout en mobilisant les outils et les perspectives singulières du champ du numérique. Les digital humanities désignent une transdiscipline, porteuse des méthodes, des dispositifs et des perspectives heuristiques liés au numérique dans le domaine des sciences humaines et sociales. »

Champs disciplinaires
- Littérature : l’Index Thomisticus (Roberto Busa) de la Somme théologique de Thomas d’Aquin
- Linguistique computationelle : TAL, lexicométrie
- Linguistique de corpus : Frantext, 4250 textes, base pour le Trésor de la Langue Française
- Histoire (quantitative), Archéologie, Anthropologie
- Géographie et Sociologie : SIG, Gephi
Humanités numériques
Père Roberto Busa, jésuite et spécialiste de Thomas d'Aquin
Index Thomisticus en collaboration avec IBM
Première enquête philologique, 1949
→ Sciences du texte et de l'interprétation, science informatique
Éclatement de l'idée de texte
Numérisation patrimoniale
Lecture érudite et savante → conception quantitative de la preuve

Humanités numériques
Alan Turing et sa machine apprenante/pensante

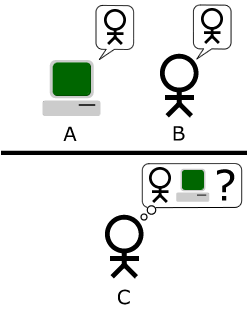
Turing test, by Bilby - Own work, Public Domain
Article proposant un modèle humain et social aux machines et à leurs apprentissages
(≠ apprentissage automatique)
→ aléas et imprévus
Humanités numériques
PÉRIODISATIONS
Berry 2011, en 2 vagues:
- Les humanités se servent de l’efficacité des machines
- 1980+ (selon digital manifesto 2.0)
- transdisciplinarité
- base de données et textes
- close reading
- Les humanités numériques génèrent et interprètent des données
- computational turn
- mesurer la qualité des résultats
- distant reading
2010+
1980+
Humanités numériques
PÉRIODISATIONS
Burnard 2012, en 3 périodes:
- Litterary and Linguistic Computing (LCC):
- index, analyse quantitative
- histoire quantitative
- Humanities Computing (HC):
- réflexion sur les pratiques numériques en humanités
- grands débats et structuration en discipline
- standardisation
- Digital Humanities (HN):
- naissance du web
- distribution / captation
60-80
80-90
90+
« L’historien de demain sera programmeur ou ne sera plus »
Emmanuel Leroy-Ladurie, 1968
Ladurie (1973)
→ transformation de l'acte même de lire
Humanités numériques
L'ESPOIR ET LE FUTUR ÉTERNEL
Rappel: « impératif philologique » (Vico, 1725): la nécessité de restituer les conditions de production des savoirs dans leurs variations et leur inévitable fragilité
Assurer la qualité avant la quantité
Humanités numériques
L'ESPOIR ET LE FUTUR ÉTERNEL
Les optimistes, « le meilleur est à venir »:
- accompagner l'historien vers la programmation
- des APIs pour tout
- une humanité cognitivement augmentée
- l'expertise neutre dépendante de la machine
Rosnay (1995), Clavert (2013), Le Deuff (2014)...
Humanités numériques
CRITIQUES
Société présentiste (Hartog, 1993), soumise à la technologie
- "Computer- aided literature studies have failed to have a significant impact on the field as a whole" (Olsen, 1993)
- "fantasme récurrent de la bibliothèque universelle" (Welger-Barboza, 2001)
- "une rencontre ratée entre une technique et une discipline" (Genet et Zorzi, 2011)
- "tarte à la crème des discours sur l’innovation à l’Université" (Mounier, 2017)
Humanités numériques
CRITIQUES
Société présentiste (Hartog, 1993), soumise à la technologie
- boite noire (Drucker, 2011)
- biais épistémologiques (Drucker, 2011)
- difficulté de sourcer
- faibles interactions avec l'historien
Humanités numériques
CRITIQUES - Et l'"IA" dans tout ça ?
De quoi on parle ?
- John McCarty (1956), fondement d'une discipline
- Simuler des capacités humaines (apprentissage, raisonnement, logique, perception)
- Abus de langage ? Aujourd'hui = "Apprentissage automatique"
- "Apprentissage profond" : CNN, RNN, etc.
- Architecture Transformers (2017) puis LLMs (ChatGPT, 2022) et RAG (Retrieval-Augmented-Generation, 2020) pour prise en compte du contexte
Humanités numériques
CRITIQUES - Et l'"IA" dans tout ça ?
Nouvelles possibilités techniques et épistémologiques ?
- explorer rapidement des corpus massifs
- mettre en évidence des connexions conceptuelles
- automatiser la transcription d'archives textes/orales
Humanités numériques
CRITIQUES - Et l'"IA" dans tout ça ?
Nouvelles possibilités techniques et épistémologiques ?
- explorer rapidement des corpus massifs
- mettre en évidence des connexions conceptuelles
- automatiser la transcription d'archives textes/orales
MAIS ?
- opacité algorithmique
- reproduction de biais (données d'entraînement)
- perte de contexte humain propre à l'analyse historique
Humanités numériques
CRITIQUES - Et l'"IA" dans tout ça ?
Débats
- reconstruction/complétion d'archives lacunaires/fragmentées ? (Risque de fabriquer de fausses preuves)
- comment garantir la responsabilité scientifique dans l’usage des modèles d’IA ?
- 2024, Gemini et le tollé des images historiques générées → "sur-correction" de biais
- Exemples d'hallucinations / références inventées/inexactes
- problème des données/corpus spécifiques sous-représentés
Humanités numériques
CRITIQUES - Et l'"IA" dans tout ça ?
Exemple d'hallucinations (modèle GPT5)
Bonjour, j'ai un modèle numérique de terrain/surface d'une zone littorale généré à partir d'un levé LiDAR aéroporté, avec une résolution de l'ordre de 10cm. Le fichier disponible est au format geotiff. Pour que je puisse l'exploiter correctement pour l'analyse du trait de côte, j'ai besoin de supprimer les zones d'eau (océan) présentes dans l'image raster. Pour l'instant, je n'arrive pas à trouver une méthode automatique pour l'appliquer sur une grande zone littorale complexe (plusieurs centaines de kilomètres). Est-ce que tu as des publications scientifiques de référence que je pourrais consulter, des pistes méthodologiques, ou encore des outils existants qui conviendraient ?
Exemple d'hallucinations (modèle GPT5)
Voici des références, pistes méthodologiques et outils pratiques pour automatiser la suppression / masquage des zones d’eau dans un MNT/DSM LiDAR (GeoTIFF) en vue d’analyse du trait de côte.
Références scientifiques clés
- Passalacqua, P., et al. (2015). "A geometric framework for channel network extraction from lidar." Water Resources Research. — méthodes d’extraction de réseaux hydrauliques et segmentation lit hydraulique/terrestre.
Brasington, J., Vericat, D., & Rychkov, I. (2012). "Monitoring river morphodynamics with remote sensing: The pros and cons of laser scanning and structure-from-motion." Earth Surface Processes and Landforms. — critères pour distinguer eau vs. substrat selon rugosité et retour LiDAR.Lane, S. N., et al. (2003). "The use of airborne LiDAR to quantify channel bathymetry and identify water surface." Earth Surface Processes and Landforms. — détection de surface libre et limitations.Mandlburger, G., et al. (2019). "Airborne lidar bathymetry and topographic lidar for coastal environments: A review." Remote Sensing. — revue pratique dédiée aux zones littorales.D. R. Greenberg & A. M. Hurst (2019). "Automated shoreline extraction from digital elevation models using morphological operators." Coastal Engineering. — méthodes morphologiques pour trait de côte.
Qu'est-ce qu'une donnée ?
Interprétable par l'humain vs. compréhensible par la machine

non-structurée vs. structurée (ex: csv)
Mastcam 100, NASA

Les données ou plutôt:
les « construits » (Bruno Latour)
vs.
les « capta » (Johanna Drucker).
Parce que ce sont les sciences humaines qui
captent et construisent ces données
Qu'est-ce qu'une donnée ?


Nous identifions et interprétons les informations,
les machines non!

Qu'est-ce qu'une donnée ?
Qu'est-ce qu'une donnée ?
De l'importance de créer des chaînes de traitement de données
Traitement des données
- Captation/Numérisation
- Stockage
- Nettoyage/Pré-traitement
- Traitement (intégration/fusion)
- Analyse
- Visualisation / publication

Co-authorship network map of physicians publishing on hepatitis C, CC BY Andy Lamb


Captation/Numérisation
Captation/Numérisation

Creative Tools from Halmdstad, Sweden
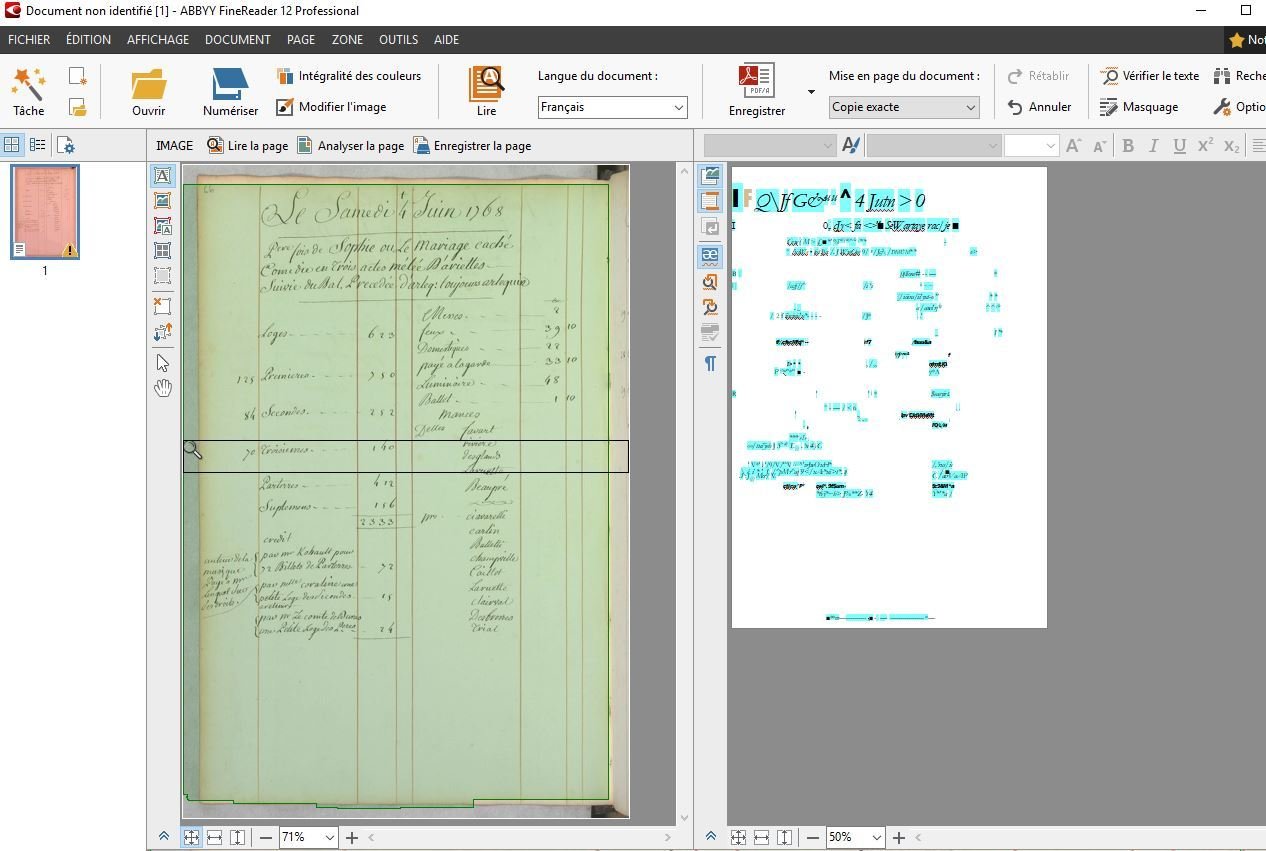
Stockage
Stockage

Format libre vs. propriétaire
format de données interopérable et dont les spécifications techniques sont publiques et sans restriction d’accès ni de mise en œuvre
Loi pour la confiance dans l'économie numérique, 2004
Nommage
- Environnement technique (caractères)
- Document connu et identifiable
- Règle de nommage
Stockage
3 niveaux pour le stockage de donnée:
- Conserver → physique (train de bits)
- Assurer l'accès → format ouverts,
- Preserver l'intelligibilité → métadonnées


Accès aux données
Et pour la diffusion ? Normes et conventions !
- FAIR
- DOIs
- Moissonnage (OAI-PMH, APIs)
- Open Data
- Web des données ?
Importance des métadonnées et de l'indexation !
Quelques mot-clés !


Crédits : Matthieu Quantin
Accès aux données
Pré-traitement/Nettoyage

Open refine non blank cells, CC BY Tony Hirst
Pré-traitement/Nettoyage
Analyse
- Knowledge discovery
- Apprentissage machine
- Deep Learning



Tasks, CC BY NC xkcd
@tifa2up / medium.com / Image Classification using Deep Neural Networks

Marvin Minsky (~1960)
Visualisation


Des objets d'étude hétérogènes



Des objectifs variés





Des approches adaptées

Des approches adaptées

Des ressources inégales

(LREC map 2010)
Quelques projets
- Nantes1900 : histoire du port de Nantes
- Haruspex : analyse d'un corpus d'entretiens
- Recital : crowdsourcing et analyse de registres comptables du XVIIIe
Mots-clés : fouille de textes, intégration de données, visualisation d'informations, gestion de connaissances
Nantes1900


Nantes1900


Numérisation 3D
Rétro-ingénierie
Archivistique
Ingénierie des connaissances
Bases de données
IHM
Réalité augmentée
Nantes1900

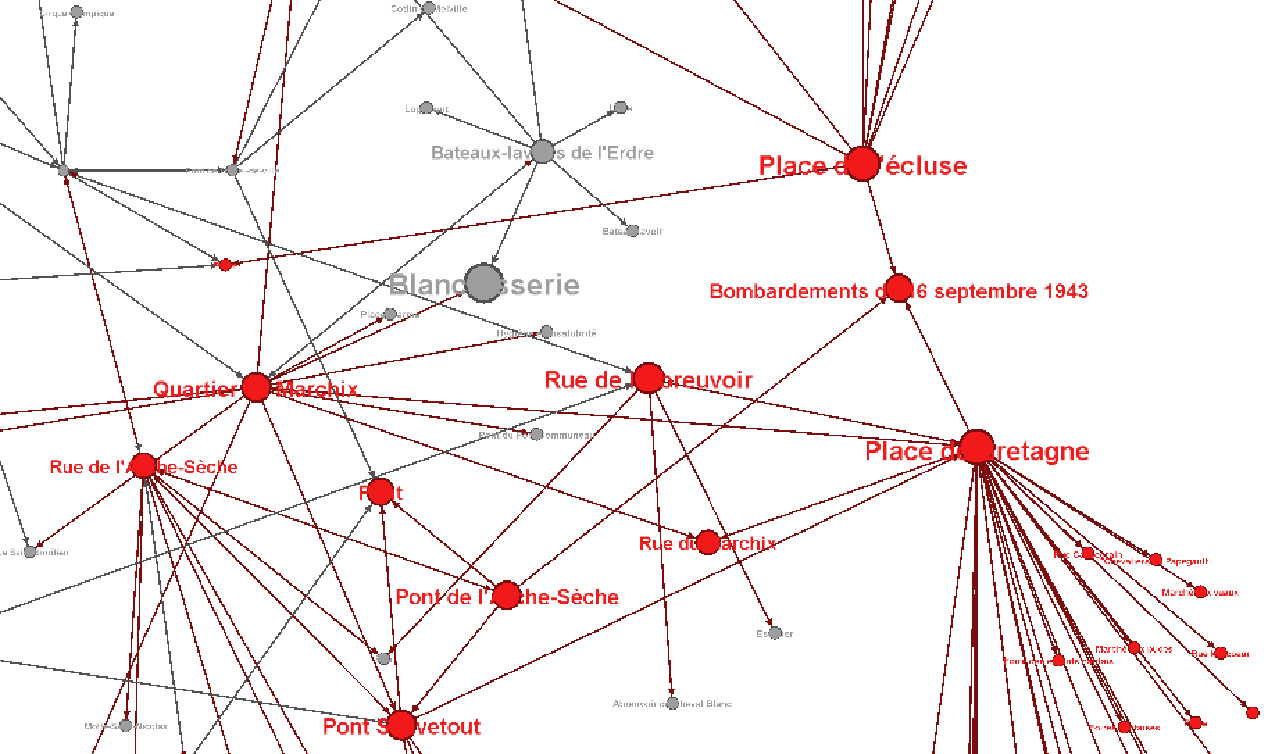

Haruspex




Haruspex
Du discours aux données...
... et inversement
Objectifs d'analyses:
- Proximité multi-échelle
- Intra/inter-corpus
- Multi-dimensionnel
- Contenu
- Co-occurrences
- Connectivité
- Anomalies
Ce n'est pas:
- du web sémantique
- un outil de formalisation des connaissances
- un outil de stockage
- ...
Haruspex
Entrée:
texte (brut/pdf, office, LateX, ...)
Sortie:
Multigraphe pondéré
- nœud = texte
- arc = occurrence

Haruspex
Fonctionne en 4 étapes

Haruspex
Topic modeling (bi-clustering)

Haruspex
Topic modeling (bi-clustering): le corpus UNESCO

Haruspex
Topic modeling (bi-clustering): le corpus UNESCO


Haruspex
Topic modeling (bi-clustering): le corpus UNESCO


Haruspex
Topic modeling (bi-clustering): le corpus UNESCO


Haruspex
Le corpus de Pierre Teissier
- Entretiens
- Chimie du solide / Materials Research
- Thèse (2007), livre(2013), articles.
| format de fichier | odt |
| structure interne (titre, sous-titre, etc.) | non |
| nombre de documents | 41 |
| nombre de mots | 339k |
| nombre de mots après filtre | 87 316 |
| nombre de lemmes différents | 9 884 |
| moyenne du nb de mots par document | 8 268 |
| écart-type du nb de mots par document | 4 837 |
Problématique générale
Identifier la naissance et la dispersion d’une
communauté scientifique.
Haruspex
Le corpus de Pierre Teissier
| Forme extraite (exemples) | Nb d’occ. |
docs concernés | Thématique |
|---|---|---|---|
| Bronzes de vanadium | 26 | 5 | Chimie |
| Chimie de coordination | 22 | 8 | Chimie |
| Thèse de troisième cycle | 16 | 7 | France, Éducation |
| Microscopie électronique | 63 | 20 | Physique |
| Microscopie électronique à transmission à haute résolution | 3 | 2 | Physique |
| Four solaire d’Odeillo | 3 | 4 | Industrie, Sciences |
Repêchage : Si non-homogène // Si trop commun // Si en disparition
Haruspex
Équivalence entre mots ou expressions

Haruspex
Équivalence entre mots ou expressions

Haruspex

Haruspex

C’est l’hypothèse qu’émet l’atlas : qu’un lien existe entre ce qui apparemment diffère au plus haut point. »
Georges Didi-Huberman (2011)
Atlas ou le gai savoir inquiet
Haruspex
Générer un point d'entrée

Haruspex
Point surprenant
| Mot-clé | Poids | tot | A | B |
|---|---|---|---|---|
| alumine | 0.414 | 30 | 4 | 4 |
| mat. réfractaires | 0.197 | 23 | 3 | 3 |
| Daniel Vivien | 0.093 | 28 | 2 | 2 |
| Vitry-sur-Seine | 0.062 | 50 | 3 | 6 |
| Perez | 0.052 | 11 | 1 | 1 |
| ferrites | 0.052 | 10 | 1 | 1 |
| Mot-clé | Poids | tot | A | B |
|---|---|---|---|---|
| vanadium | 0.606 | 23 | 6 | 8 |
| bronzes de tungstène | 0.511 | 9 | 5 | 4 |
| John Goodenough | 0.509 | 19 | 4 | 5 |
| verres fluorés | 0.421 | 55 | 2 | 19 |
| bronzes de vanadium | 0.395 | 22 | 2 | 12 |
| octaèdres | 0.375 | 19 | 2 | 12 |
Haruspex
Haruspex

Haruspex
Le corpus de Pierre Teissier

Haruspex
Le corpus de Pierre Teissier



Haruspex
Épistémologie pratique

Épistémologie pratique

Autres applications
Haruspex



Recital

http://recital.univ-nantes.fr

{RE}gistres de la {C}omédie-{ITAL}ienne
- Économie du spectacle

La Comédie-Italienne : [dessin] / [Jean Baptiste Lallemand]. src: gallica.bnf.fr
Dans une étude longitudinale, que nous enseigne la comptabilité du théâtre sur :
- la structure sociale du public ?
- la popularité du répertoire et des auteurs ?
- la circulation des acteurs, ouvriers, danseurs,etc.?
- les décors et la mise en scène (accessoires) ?
Le fonds documentaire
- conservé sous les toits de la Bibliothèque-Musée de l’Opéra
- numérisé dans le cadre d’un précédent projet du CETHEFI convention avec la BnF pour un droit d’exploitation
- fac-similés disponibles sur gallica.bnf.fr

69 registres, 27544 pages
Extraction des données
Que faire avec les 25.250 pages d’archives numérisées ?
Du fac-similé à la donnée :
- numérique, par ex. un montant de recette
- et symbolique, par ex. une catégorie de dépense, ou un titre de pièce
Deux sous-projets en informatique, menés conjointement :
- Reconnaissance automatique d’écriture manuscrite
- Transcription participative avec RECITAL
Crowdsourcing
"Science participative"

Le problème :
Une tâche colossale et complexe d’annotation et de transcription des registres
La (notre) solution :
- Scinder cette tâche en une myriade de micro-tâches indépendantes,
- exposées instantanément et disponibles 24/7 via le Web,
- exploitant une ressource
inépuisable: le citoyen-bénévole !
Estimation temps expert : 7400 heures (pour les comptes quotidiens = 70% du corpus)
« labeling and transcription are well-suited HITs (Human IntelligenceTasks) for crowdsourcing » (Chittilappilly et al., 2016)
Crowdsourcing
"Science participative"
Pourquoi ne peut-on pas automatiser l’extraction de données ?...
autrement dit
Pourquoi la reconnaissance de formes est-elle peu performante ?
- écriture manuscrite irrégulière
- 2 langues : Italien et Français
- monnaie duodécimale de l’Ancien Régime : Livre-Sou-Denier
- 7+ « caissiers » : de Alborghetti à Linguet (à partir de 1741)
-
au cours du siècle :
- évolution formelle des bilans comptables
- évolution des règles comptables
Crowdsourcing

"Science participative"
http://recital.univ-nantes.fr
Sciences participatives
- Co-production de connaissance par l’expert et le citoyen
- Le crowdsourcing (ou production participative) comme accélérateur de projets et vecteur du passage à l’échelle
- Une communauté très active autour des projets pour la santé,l’environnement et la biodiversité, l’astronomie

Sciences participatives
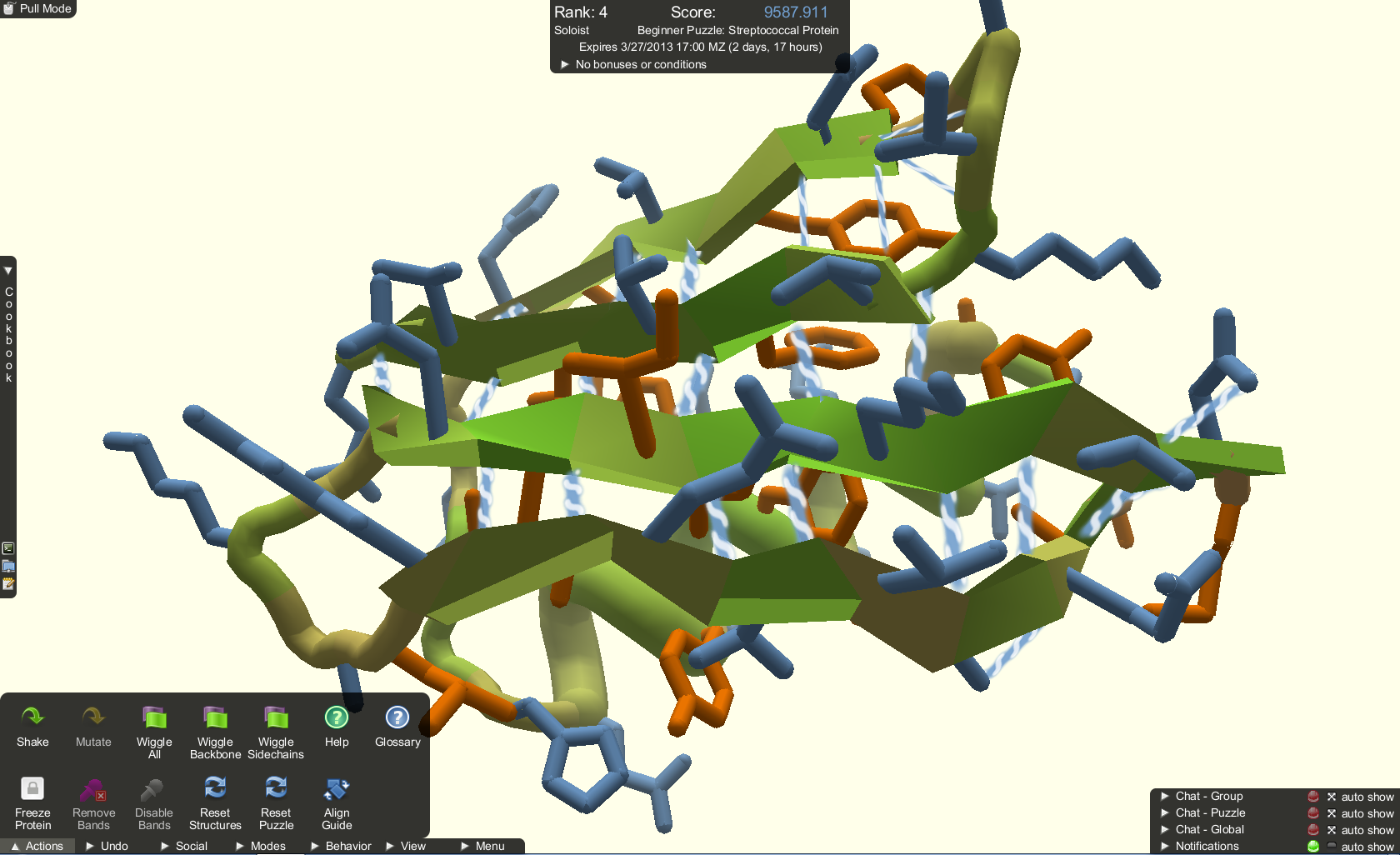
Fold It
Sciences participatives
Pour aller plus loin :Les sciences participatives en France : État des lieux, bonnes pratiques et recommandations par François Houllier, PDG de l’Inra, Fév. 2016.

Galaxy Zoo
Sciences participatives
Pour la transcription d’archives principalement
Popularité grandissante des plate-formes participatives
Quelques projets emblématiques :
- Testaments de Poilus: 354 documents en TEI pour l’édition électronique.
- Transcribe Bentham: 21 609 pages (partiellement) transcrites dont 20 779 (96%) ont été approuvées.
- Transcribathon : 51 652 documents dont 15 187 en cours de transcription et 14 132 achevés
Et les humanités ?
Sciences participatives
- Global Impact Award de Google ($1,8M)
- Vaste communauté de volontaires (essentiellement anglophones)
Zooniverse

Sciences participatives
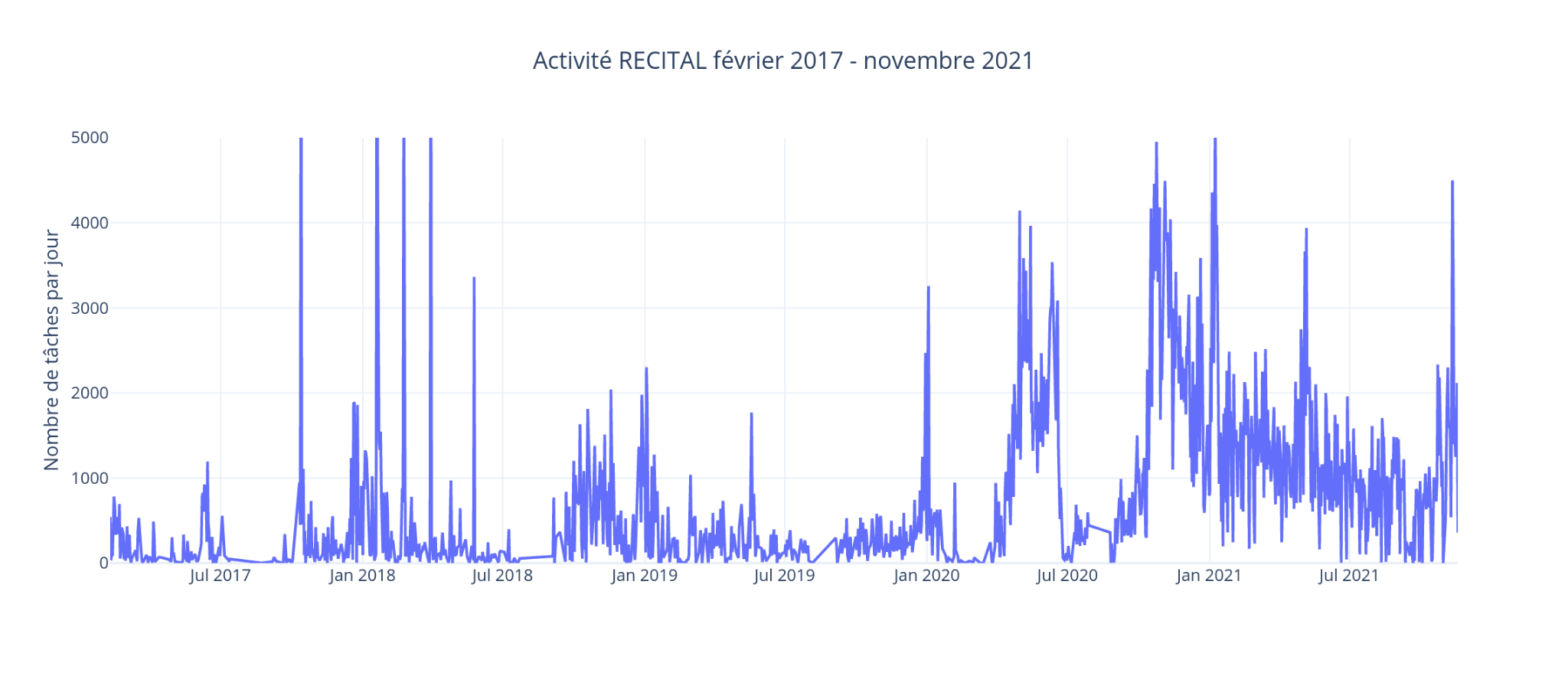
projet démarré en 2016
- CS pour la transcription participative de 25 000 pages de registres
- comportant 8 types de documents et 133 catégories d’information
-
3+1 familles de tâches et un workflow complexe incluant :
- indexation des pages
- annotation graphique des pages
- indexation des marques
- transcription des marques
- évaluation collaborative des transcriptions
Et RECITAL ?
Sciences participatives
Avancement : >1M tâches réalisées par +1800 bénévoles
Et RECITAL ?
Crowdsourcing
"Science participative"
http://recital.univ-nantes.fr
À vous de jouer !
Données fiables ?
(1) Recherche de consensus
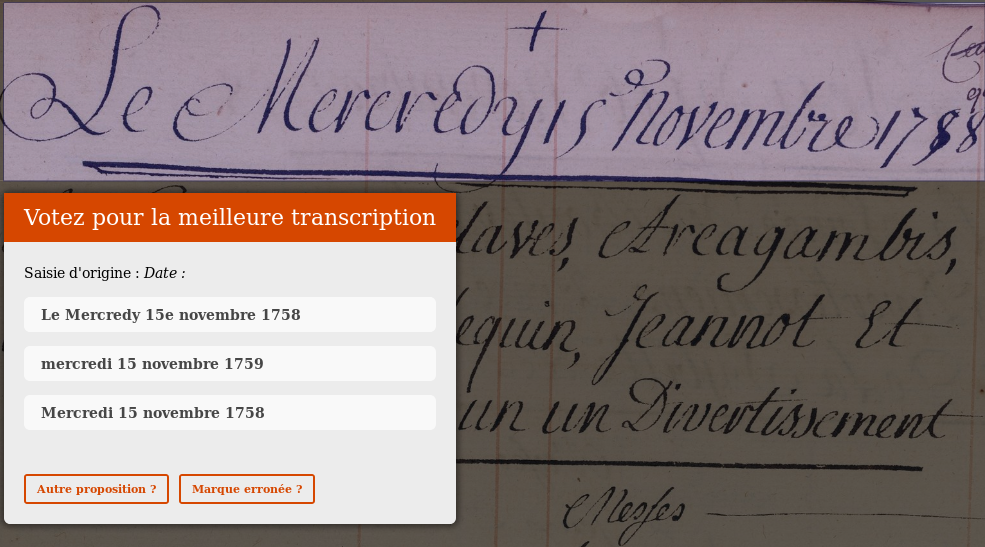
| Propositions | Votes |
|---|---|
| Le mercredy 15e novembre 1758 | 2 |
| mercredi 15 novembre 1759 | 1 |
| Mercredi 15 novembre 1758 | 3 |
(2) Élimination des doublons


Données fiables ?
Le CS génère de l’incertitude (et donc du stress !)
1. Les facteurs endogènes :
- Compétence et intention des bénévoles a priori inconnues
2. Les choix de conception de RECITAL :
- Découpage, enchaînement et difficulté des tâches
- Stratégie d’affectation aléatoire des tâches
- Mode de transcription libre (diplomatique vs. modernisée)
- Règle du consensus à la majorité
Nettoyage des données

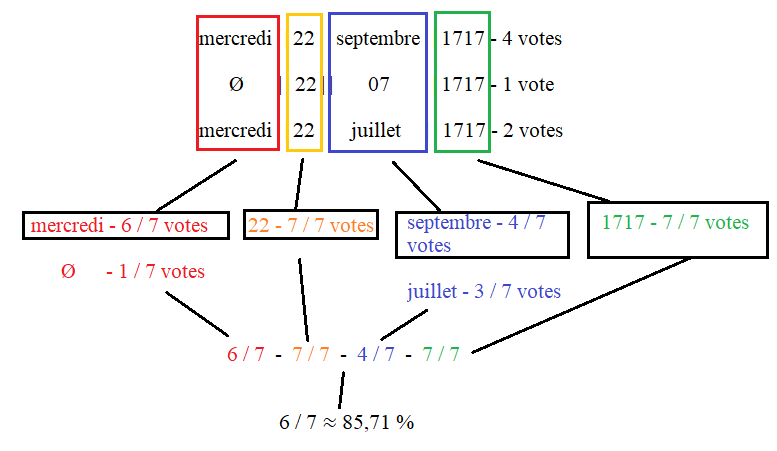
| Propositions | Votes |
|---|---|
| Arlecchino Mutto | 2 |
| Arlicn. Mutto | 1 |
| Arlequin Mutto | 1 |
La recette
- Simplification (Maj, ponctuation, ...)
- Racinisation, lemmatisation
- Segmentation, alignement
- Calcul de similarité
Résolution d'entités
Soit un ensemble de titres de pièces tiré de sources fiables et variées (Gueulette, Repertorio, etc.)
Comment aligner des fragments de titres de soirée sur les titres de pièces ?
- distance 3-Grams et taux de couverture
- perspectives : clustering

- "Le père de famille"
- "Paysans de qualité"
Et maintenant ?
Une base de données « intermédiaire » de 64 979 fragments de transcription :
- indexés :task_key et field
- tracés et validés :status et confidence
- repérés :mark_id
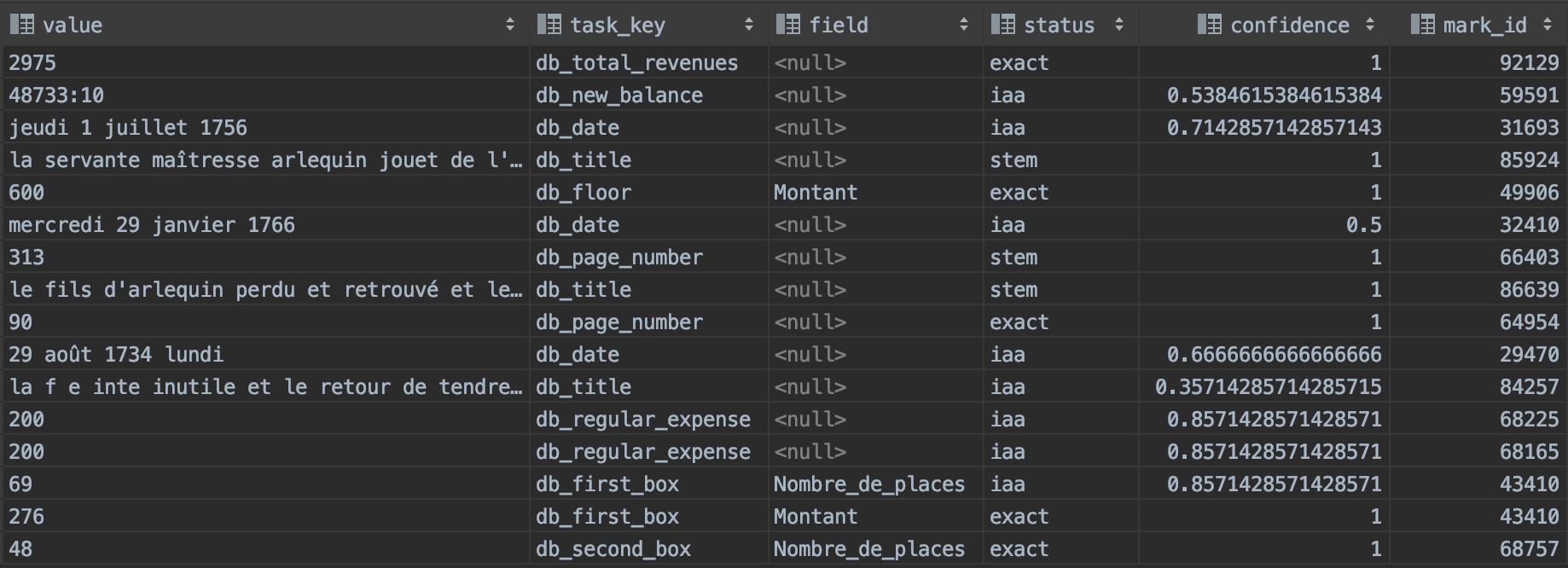
Et maintenant ?
Consensus sur un titre : 13 opinions !
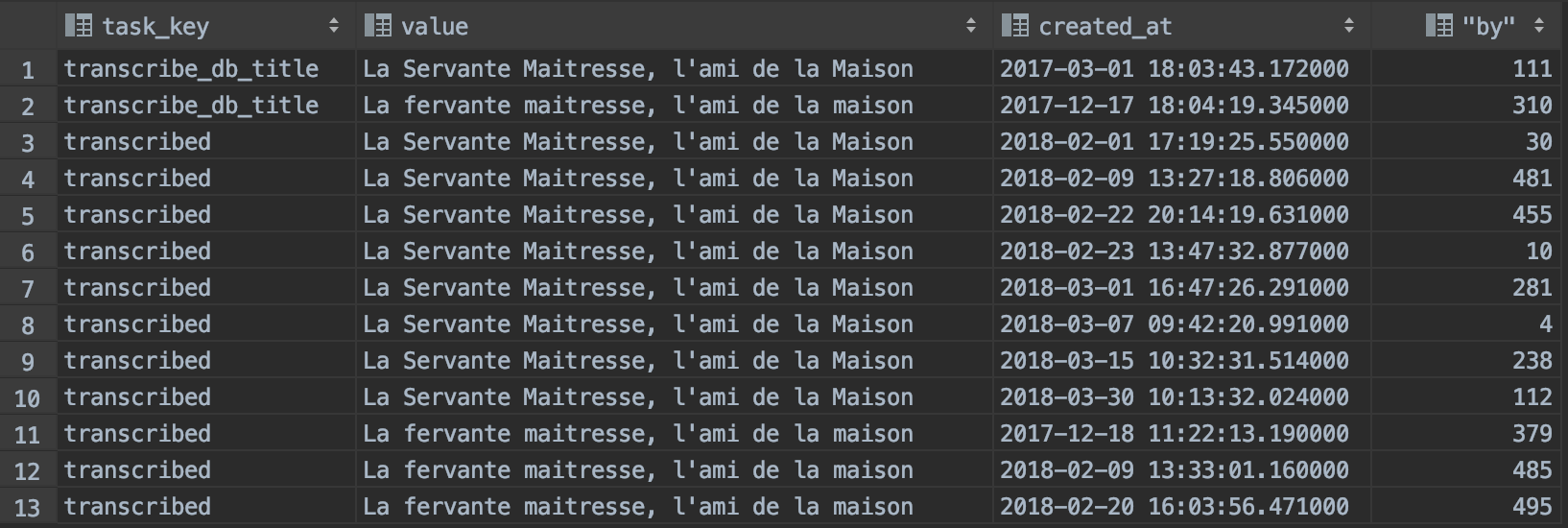
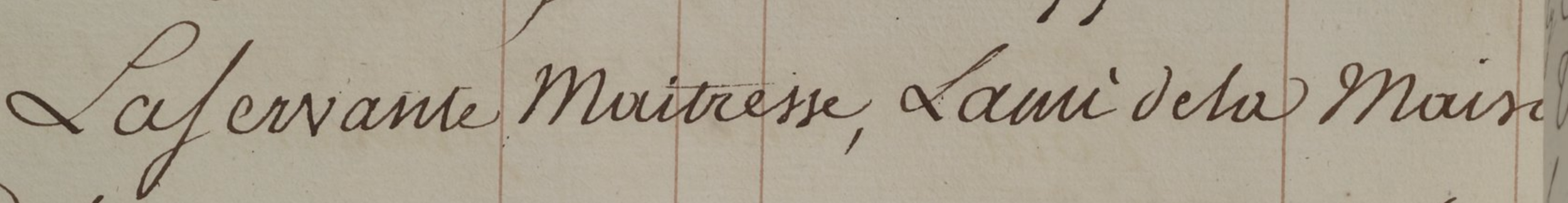
A noter !
- Comment est caractérisée la donnée ? status, confidence, mark_id
- Quelle signification des indicateurs pour l’expert ?
Pour quelles finalités ?
- Créer des productions numériques « fiables »complémentaires car nécessairement limitées : c’est l’historien qui connaît le contexte !
- Représentation des données : multiplier les échelles d’observation !
- Mise en évidence d’"éléments de surprise" amenant de nouvelles connaissances (dépense du « Lion »)
Recital

Quelles productions numériques?

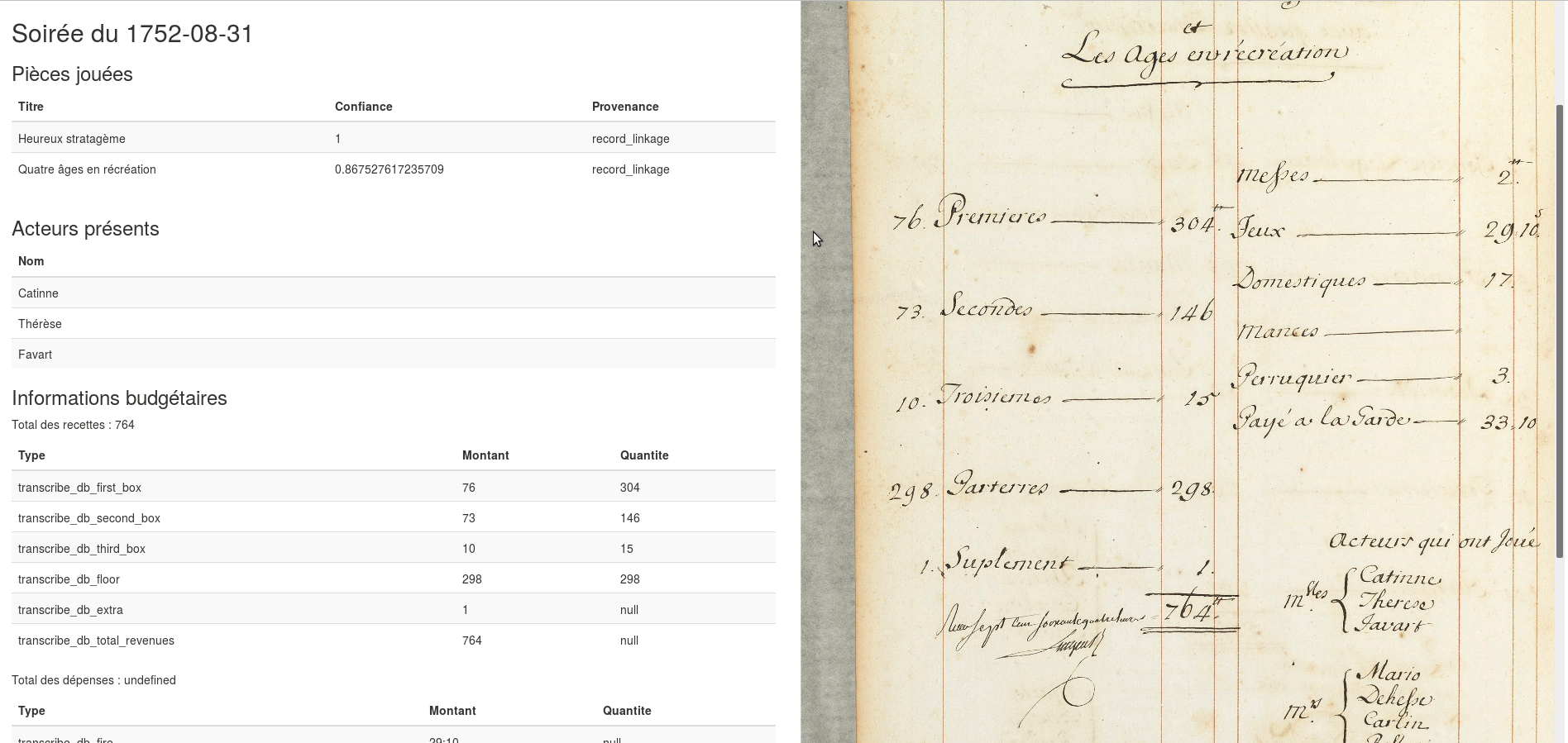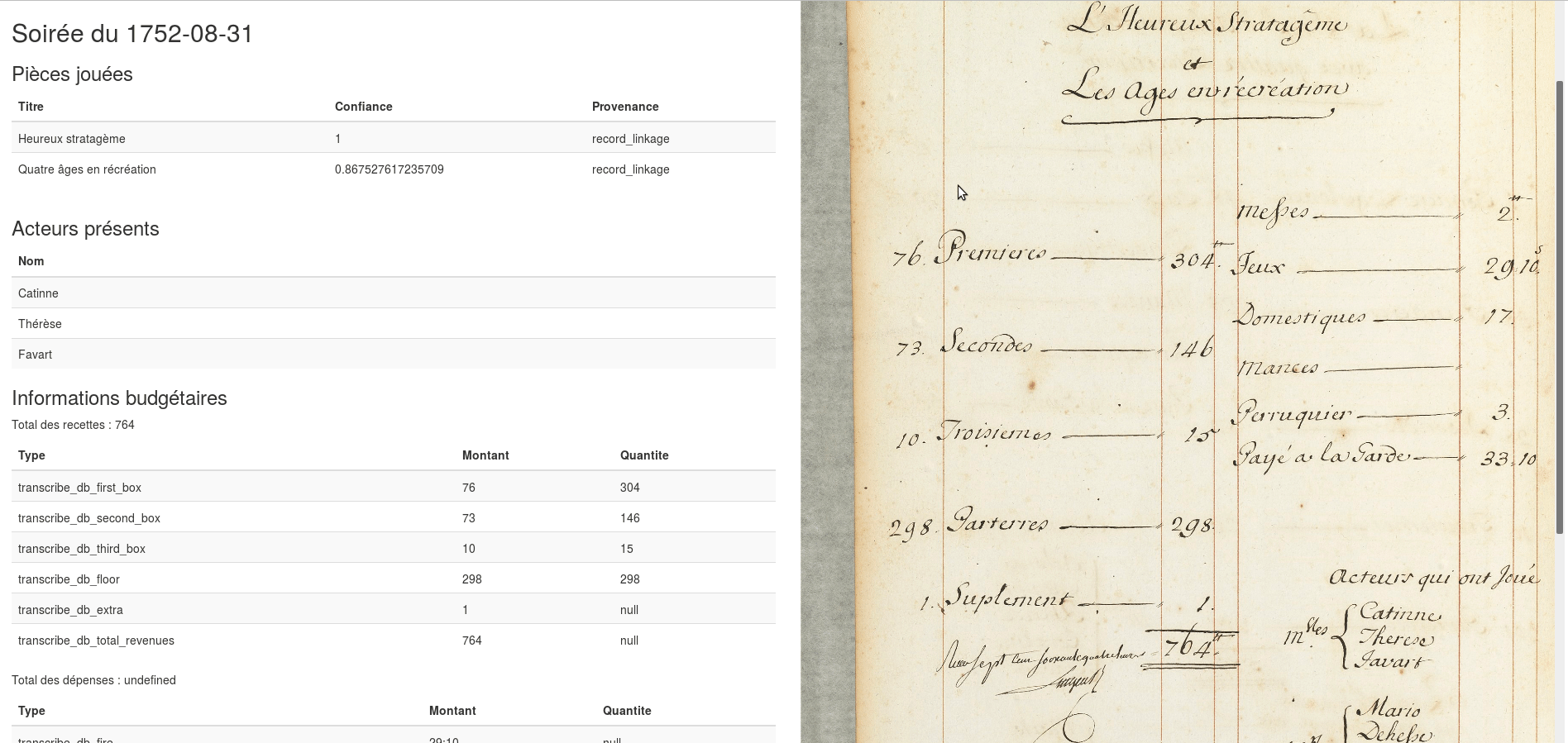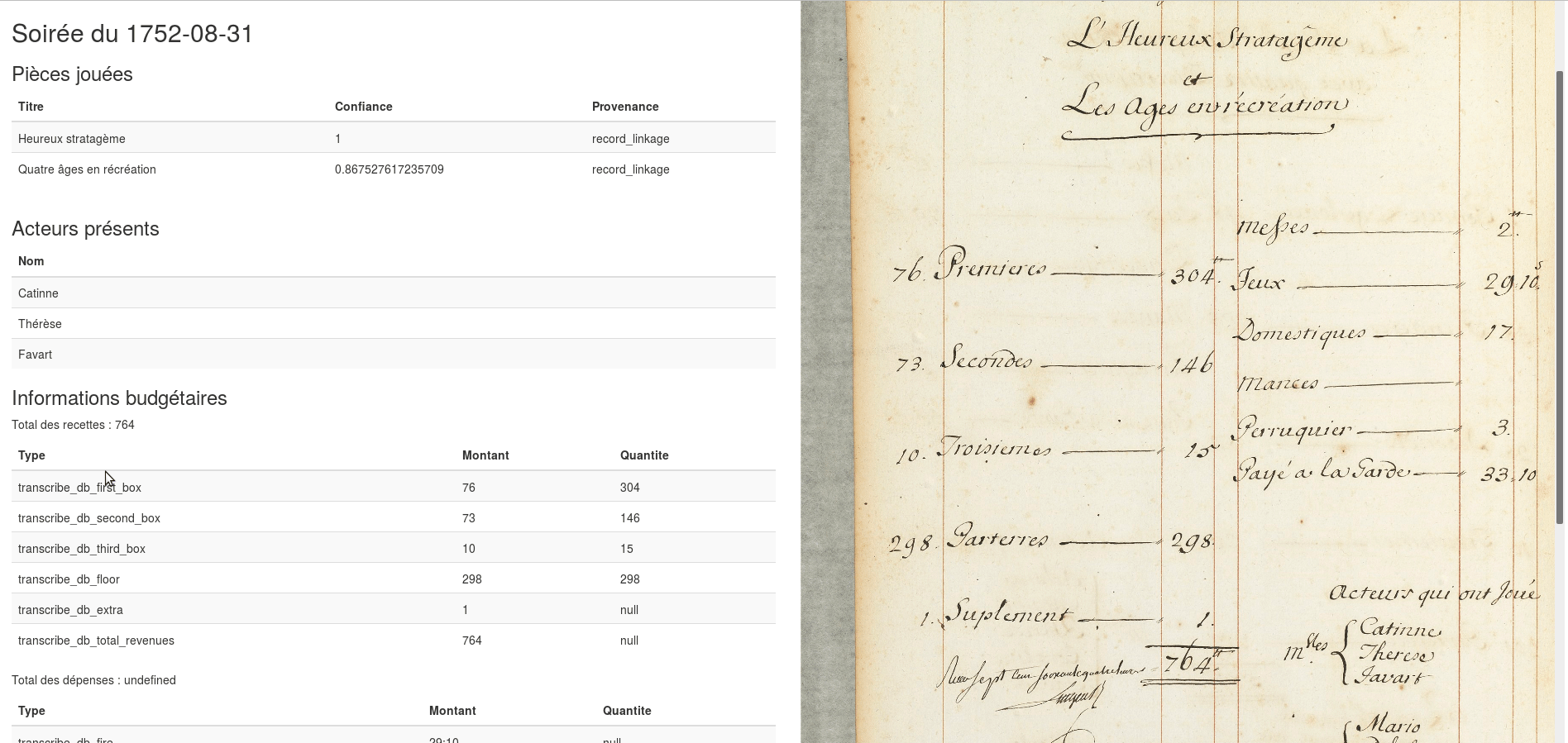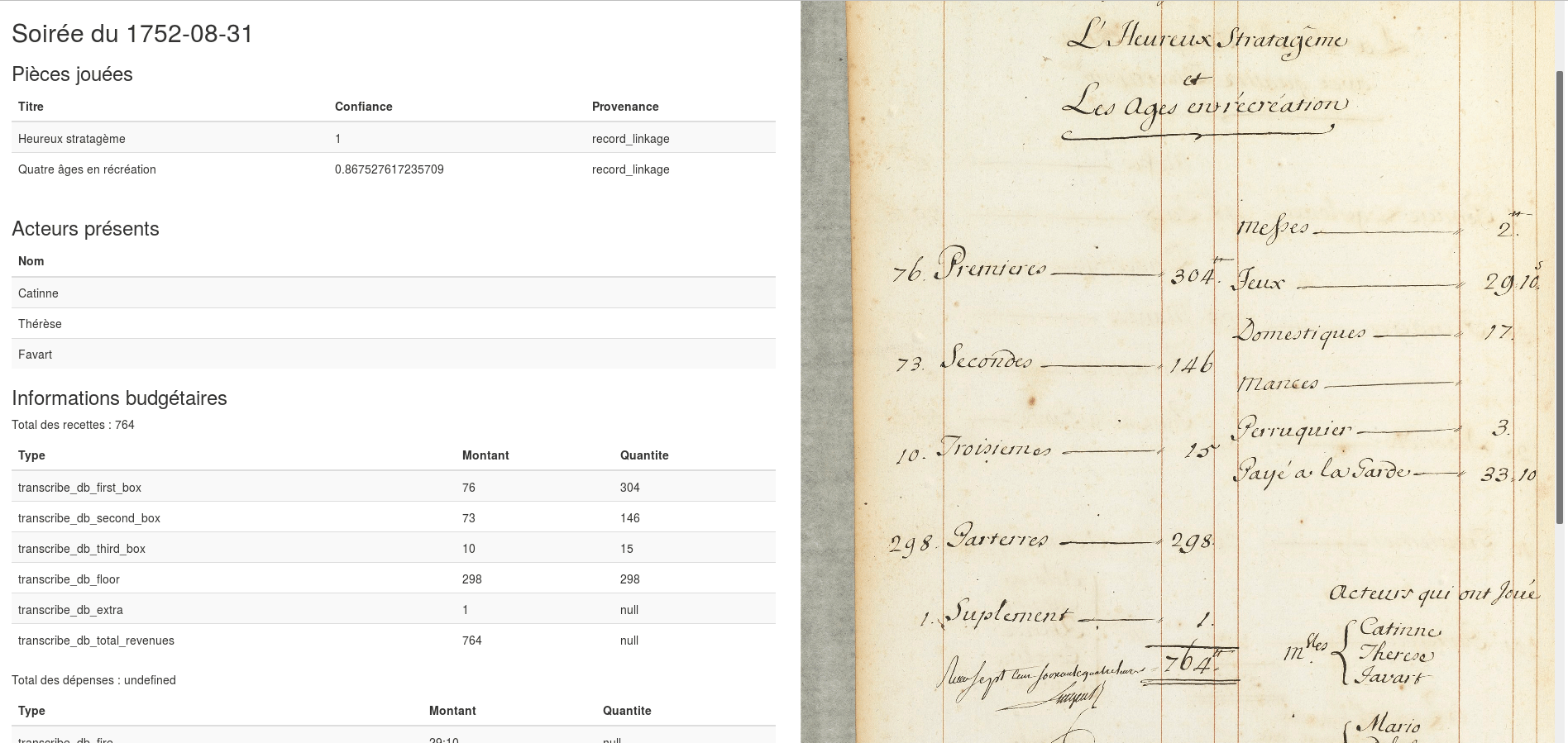





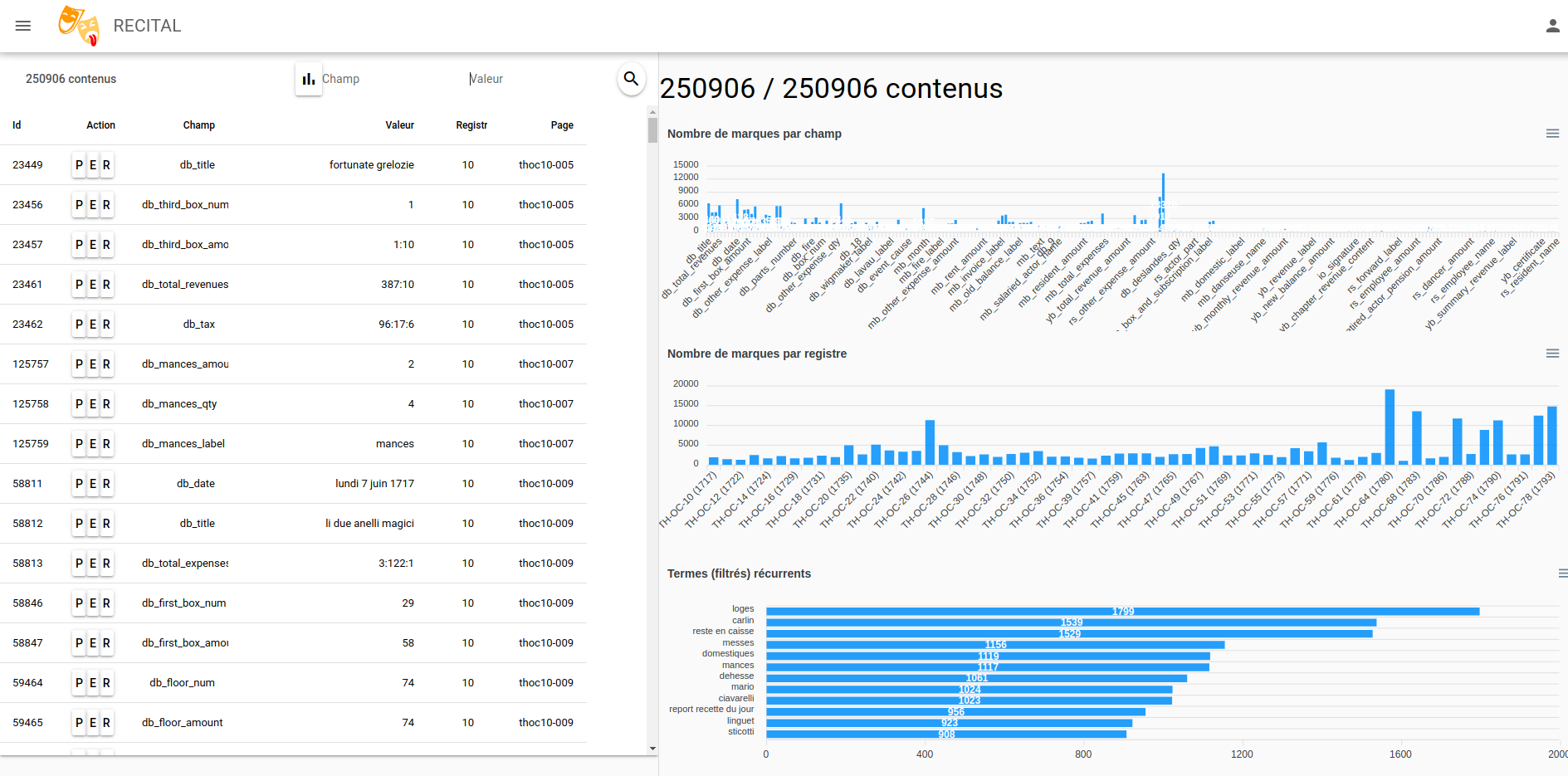

https://recital.univ-nantes.fr/dashboard/#/
Conclusion
- Objectif : disposer d’une BdD fiable, documentée et fidèle au corpus original augmentée de mécanismes d’exploration et d’analyse
- Moyen :pallier les limites des techniques de reconnaissance automatique d’écriture par le crowdsourcing
- Difficultés :la nature du corpus et les choix de conception de la plateforme induisent des problématiques de qualité des données
- Solution partielle n°1 : les techniques de correction des données permettent de résoudre la très grande majorité des dissensus
- Solution partielle n°2 : les techniques pour la résolution d’entités permettent d’opérer des rapprochements et donc, de consolider les données
Quelques questionnements
Pour le crowdsourcing, réduction du bruit et de l'incertitude par :
- Évaluation des bénévoles
- Évaluation de la difficulté des tâches
- Recherche de consensus : appariement et réconciliation
- Stratégie d'affectation des tâches aux bénévoles
- Détection/prévention des contributions indésirables
Pour la valorisation du fonds documentaire :
- Intégration de données avec des sources externes
- Statistiques et visualisation
- Recherche d'information
- Analyse de données


Peut-on automatiser cette tâche ???
oui ! mais ... les algorithmes ont besoin de beaucoup de données pour apprendre !
Pour délimiter les zones, on peut :
- Utiliser les données des annotations
- Utiliser des données artificielles


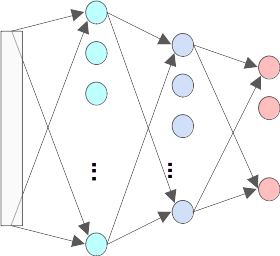
Réseau de neurones
Apprentissage
Reconnaissance
Peut-on automatiser cette tâche ???
Réseau de neurones
Apprentissage
Reconnaissance
Arlicchino Mutto
Le 22 septembre 1717 Mercredi

je suis sans nouvelles
oui ! mais ... les algorithmes ont besoin de beaucoup de données pour apprendre !
Pour reconnaitre le texte, on peut :
- Utiliser les données des annotations
- Utiliser d'autres textes déjà annotés (fr, en, es, ...)
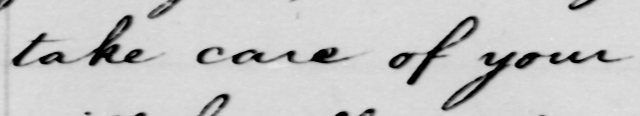
take care of you
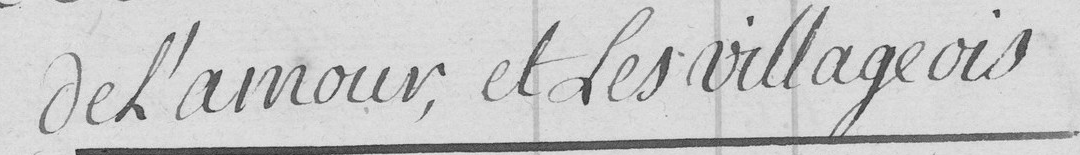
de l'amour, et les villageois
Et en 2025 ?!
Les grands modèles de langage (LLM) ont-ils révolutionné le problème ?

https://recital.univ-nantes.fr/dashboard/#/pages/thoc42-012
Top Left:
Le Study 15 awit 1760:
Center:
fois, La rentrée des Théatres &c. Suivie du Ballet du Sultan Généreux, Précedé dela fausse Suivante,
Alecover- feux Damestiquco
ss premiereo- to manies
Right Side (Columns):
Payé alagude acteurs quu ont joués. -
3310
Dollas berare favart camille Calinon
73 secondes.
219
carlin
21 Croissemen
42
Balletti Champville Lejeune
40 parterre.
343
954
Gemini, peux-tu me transcrire l'image ci-contre provenant d'un document manuscrit du 18e ?
Et en 2026 ?!
Du Sunday 10 8bre 1776
Lafervante Maitresse, Dame de la Maison
[ill.] autre part
Luger 99
Cheatre 1080
Second 537
Sans contexte
Du Sunday 10 8bre (octobre) 1776
La Servante Maitresse, Dame de la Maison
Recette :
Loyer : 99
Théâtre : 1080
Second (probablement une catégorie de recette ou de poste) : 537
Explications :
- "8bre" est une abréviation courante pour "octobre" dans les documents anciens.
- "La Servante Maitresse" pourrait désigner une pièce de théâtre ou une catégorie de recettes/dépenses liée à une production spécifique.
- "Loyer" et "Théâtre" sont clairement des postes de recettes ou de dépenses.
- "Second" pourrait faire référence à une catégorie secondaire de recettes ou de coûts (par exemple, recettes secondaires ou frais annexes).
Avec contexte
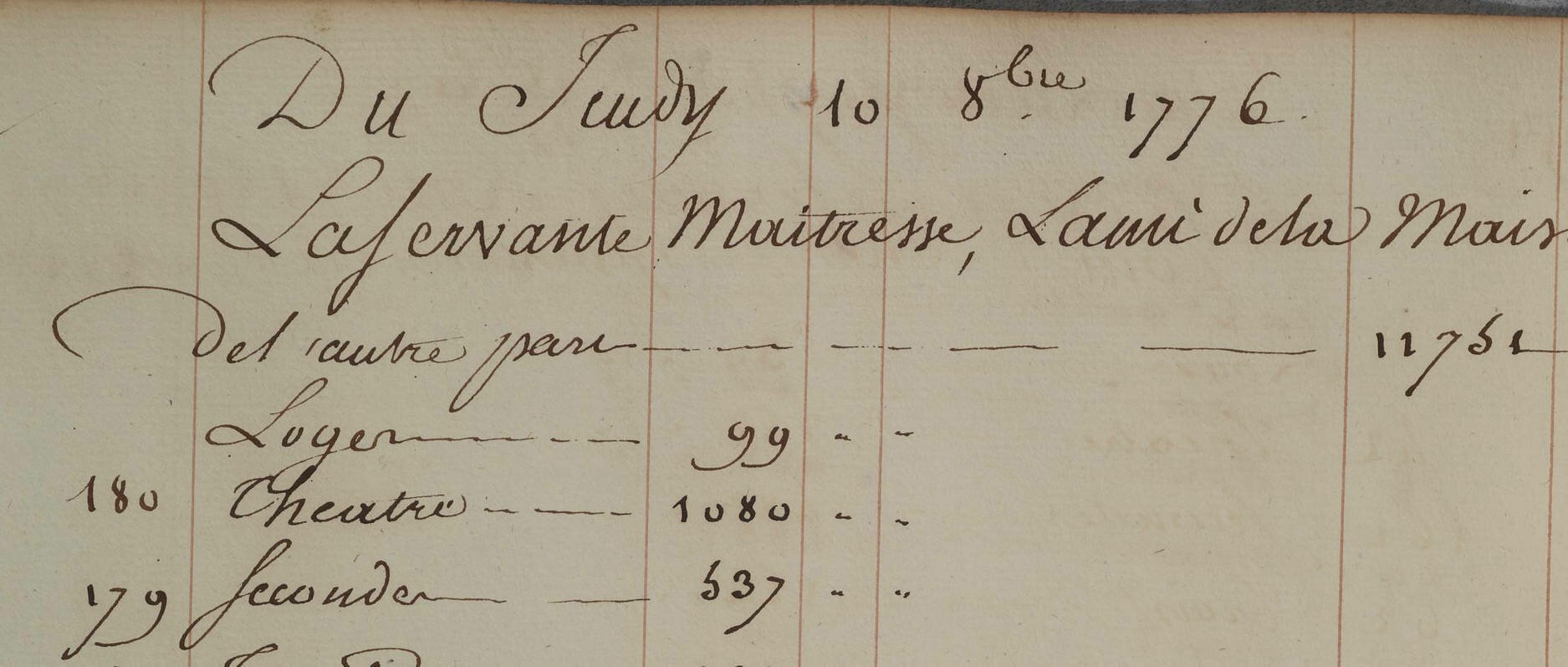
Et en 2026 ?!
Du Sunday 10 8bre (octobre) 1776
La Servante Maitresse, Dame de la Maison
Recette :
Loyer : 99
Théâtre : 1080
Second (probablement une catégorie de recette ou de poste) : 537
Explications :
- "8bre" est une abréviation courante pour "octobre" dans les documents anciens.
- "La Servante Maitresse" pourrait désigner une pièce de théâtre ou une catégorie de recettes/dépenses liée à une production spécifique.
- "Loyer" et "Théâtre" sont clairement des postes de recettes ou de dépenses.
- "Second" pourrait faire référence à une catégorie secondaire de recettes ou de coûts (par exemple, recettes secondaires ou frais annexes).
Avec contexte
Du Sunday 10 8bre 1776
Lafervante Maitresse, Dame de la Maison
[ill.] autre part
Luger 99
Cheatre 1080
Second 537
Sans contexte
Et en 2026 ?!
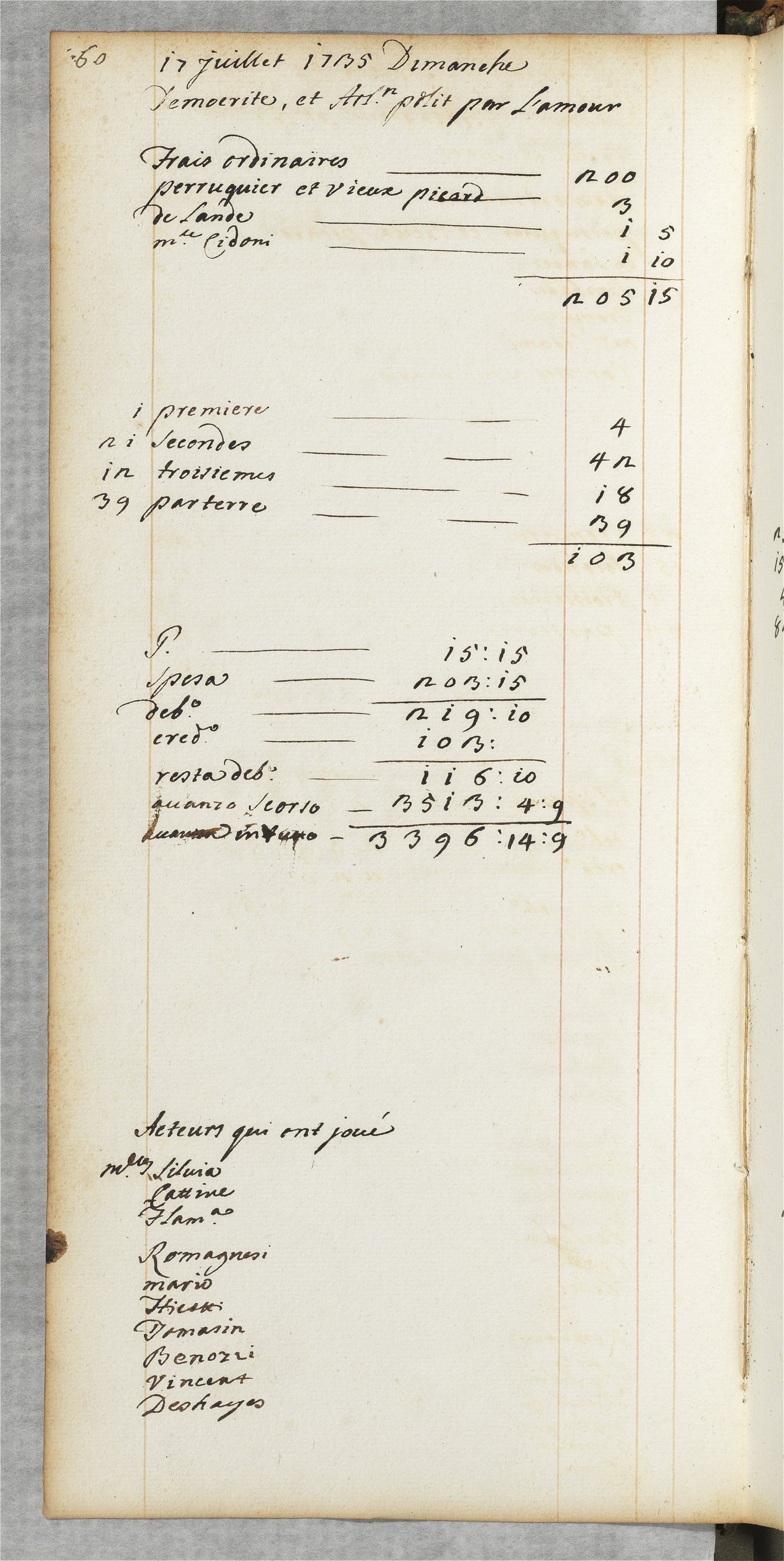
Le Jeudy 17 Avril 176[0]
2e fois, La rentrée des Théâtres etc. Suivie du Ballet du Sultan Généreux, Précédé de la fausse Suivante,
Poste / CatégorieMontant (en livres)
| 55 premiers | 3 7 0 |
| 75 secondes | 2 19 [livres] |
| 21 troisièmes | 4 2 |
| 74 partenaires | 3 4 3 |
| Total | 9 7 4 |
Explications supplémentaires :
- "La rentrée des Théâres etc. Suivie du Ballet du Sultan Généreux, Précédé de la fausse Suivante" : Il s'agit probablement du titre des pièces jouées ce jour-là.
- "55 premiers", "75 secondes", "21 troisièmes" : Ces termes désignent probablement des catégories de places ou de recettes (premiers, seconds, troisièmes rangs ou types de billets).
- "Payé à Lagarde, acteurs qui sont joués" : Liste des acteurs ayant reçu un paiement pour leur participation.
- Les montants sont exprimés en livres, sous et deniers (système monétaire d'Ancien Régime).
Demande de transcription à Mistral avec précision du contexte
https://recital.univ-nantes.fr/dashboard/#/pages/thoc42-012
Recital

Titres :
- carnaval d'été
- amours champestres
- (divertissement)
Liste de "référence" :
Repertorio
Clarence D. Brenner
(fautes/doublons)
4e Du Carnaval d'Été et Le Divertissement Precedé dés amours champestres
Nettoyage
Résolution d'entités (N-grams + position)
Recital
Résultats (sur un échantillon vérifié) :
70% de précision
Les deux jumeaux de Bergame Werther et Charlotte Le Comte d'albert
- 'Le Comte d'Albert', 0.56
- 'Deux Jumeaux de Bergame', 0.55
- 'Werther et Charlotte', 0.52
Couverture : 90%, Sim. moy. : 0.54
[('les', 0.13), ('esd', 0.13), ('sde', 0.13), ('deu', 0.13) [...] ('alb', 0.13), ('lbe', 0.13), ('rt', 0.13), ('t', 0.13)]
- Calcul de similarité (cos) avec chaque titre de référence
- Position approximative dans la chaîne originale
- Vérification de la couverture totale
[Kondrak, 2005]
Outils et services
TGIR Huma-Num

Outils et services
https://www.huma-num.fr/les-services-par-etapes/#traitement
- Traitement de textes
- Bases de données
- SIG
- 2D, 3D
- Calcul intensif