DataFusion: Embeddable Query Engine Written in Rust
Who Am I?
Boaz Berman, 29, Software Engineer for 8 years



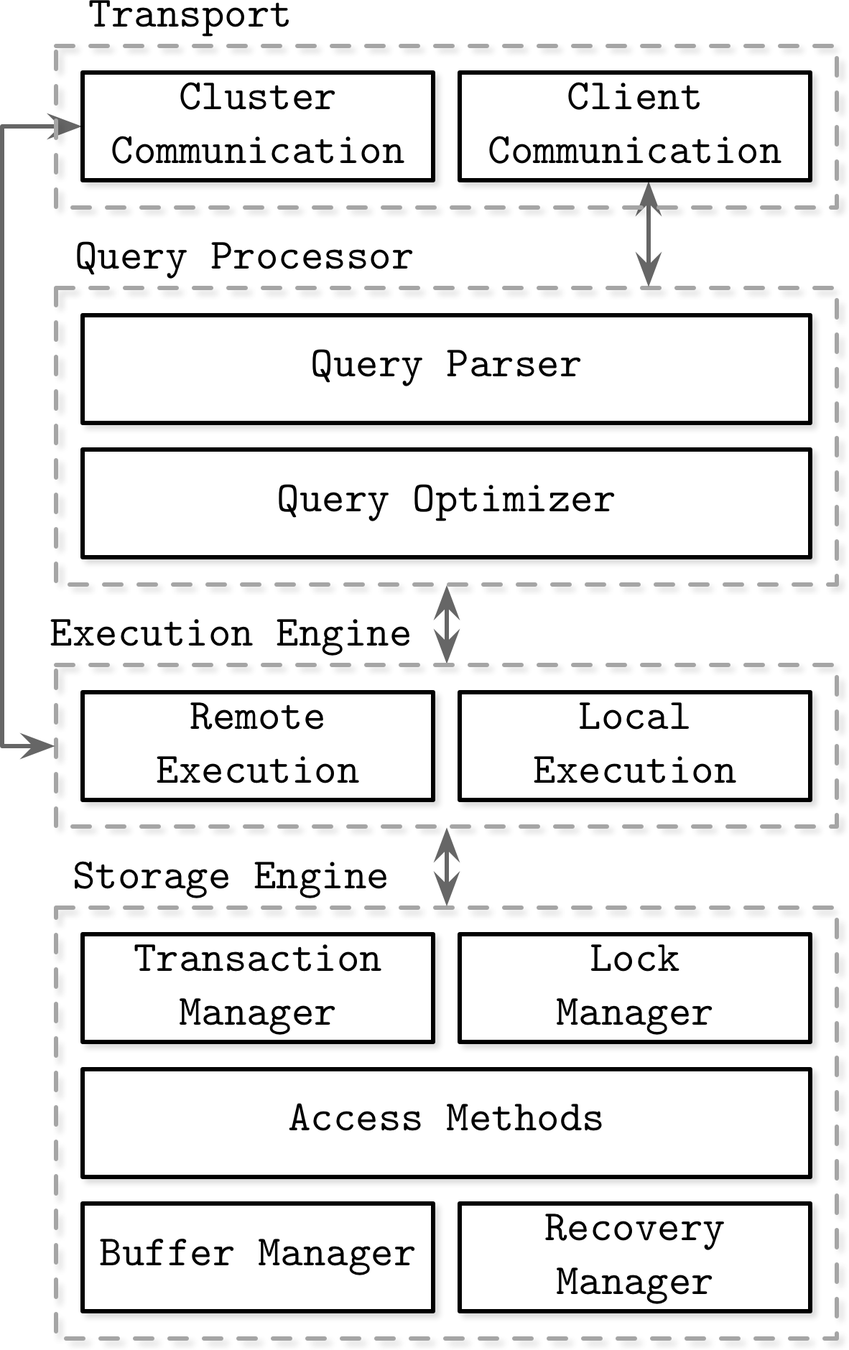
DataFusion is an extensible query planning, optimization, and execution framework, written in Rust, that uses Apache Arrow as its in-memory format.
Purpose of this talk
- Background
- DataFusion Ingenuity
- How Query Engines Work 101
- DataFusion's Implementation
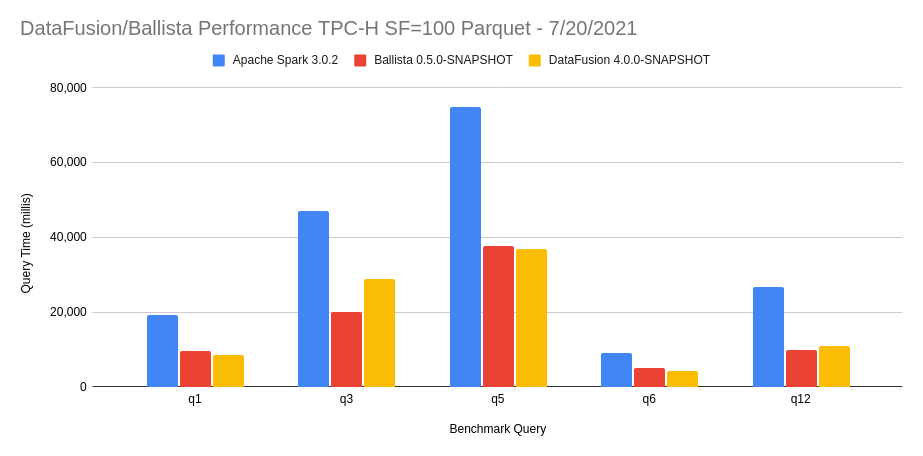
- Benchmarks
https://www.oreilly.com/library/view/database-internals/9781492040330/ch01.html
Database Internals
Online Analytics Processing
No transactions, just data processing









Why Another Solution?
- Embeddability
- Cross-platform
- Speed
- Start time
- GC pauses
- Single binary
- Ease of development
- Predictable cost

- Infinite(ish) horizontal scale
- Scale up & down on request
- Cost-effectiveness is in data locality and resource efficiency (No YARN)
Data IS Everywhere
- KB to PB
- Pandas good for local machine, Spark good for servers.
- Write once, run at whatever scale (Using Ballista)
- Every engine rewrites the entire thing
- Multiple origins and formats
- Presto leading the way
- Arrow Flight
Language-independent columnar memory format, organized for efficient analytic operations on modern hardware like CPUs and GPUs. Supports zero-copy reads for lightning-fast data access without serialization overhead.
-
Storage <-> Memory parsing time
-
SIMD (Same Instruction Multiple Data)
-
GPUs are everywhere
-
Columnar formats (e.g. Parquet, ORC)
How Query Engines Work
&
DataFusion's Implementation
SQL
DataFrame
LogicalPlan
Optimizer
PhysicalPlan
Optimizer
async fn main() -> Result<()> {
let ctx = SessionContext::new();
// SQL API
ctx.register_csv("titanic", data_file).await?;
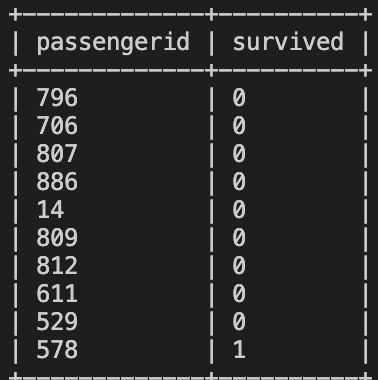
let df = ctx.sql(
"SELECT passengerid, survived FROM titanic \
WHERE (age > 20 AND age < 40) OR 1 != 1\
ORDER BY age DESC, survived",
).await?;
df.show().await?;
// DataFrame API
let df = ctx
.read_csv(data_file, CsvReadOptions::default())
.await?
.select_columns(&["passengerid", "survived"])?
.filter(
col("age")
.gt(lit(20))
.and(col("age").lt(lit(40)))
.or(lit(1).not_eq(lit(1))),
)?
.sort(vec![
col("age").sort(false, true),
col("survived").sort(true, false),
])?;
df.show().await?;
Ok(())
}
pub async fn sql(&self, sql: &str) -> Result<Arc<DataFrame>> {
// ----------
// ----------
let plan = self.create_logical_plan(sql)?;
// ----------
// ----------
match plan {
...
plan => Ok(Arc::new(DataFrame::new(self.state.clone(), &plan))),
}
}
...
pub fn create_logical_plan(&self, sql: &str) -> Result<LogicalPlan> {
// ----------
// ----------
let mut statements = DFParser::parse_sql(sql)?;
// ----------
// ----------
...
SqlToRel::new(&state).statement_to_plan(statements)
}SQL Parser
https://github.com/sqlparser-rs/sqlparser-rs
Open source standalone library extracted from DataFusion, in use by other projects
Parses SQL string and creates an SQL AST
DFParser::parse_sql(sql)pub(crate) async fn main() -> Result<()> {
let ctx = SessionContext::new();
let data_file = ...
ctx.register_csv("titanic", data_file, CsvReadOptions::new()).await?;
let df = ctx
.sql("SELECT * FROM titanic")
.await?
.select_columns(&["c1", "c12"])?
.filter(
col("c1")
.gt(lit(0.1))
.and(col("c1").lt(lit(0.9)))
.or(lit(1).not_eq(lit(1))),
)?
.sort(vec![
col("c12").sort(false, true),
col("c1").sort(true, false),
])?;
df.show().await?;
Ok(())
}DataFrame
Data structure that organizes data into a 2-dimensional table of rows and columns, much like a spreadsheet.
Originally “data frame”, emerged in the S programming language at Bell Labs. Released in 1990.
R, the open-source version of S, had its first stable release in 2000. In 2009, pandas was released to bring R dataframe semantics to Python.
pub async fn read_csv(
&self,
table_path: impl AsRef<str>,
options: CsvReadOptions<'_>,
) -> Result<Arc<DataFrame>> {
...
self.read_table(Arc::new(provider))
}
pub fn read_table(
&self,
provider: Arc<dyn TableProvider>
) -> Result<Arc<DataFrame>> {
Ok(Arc::new(DataFrame::new(
self.state.clone(),
// ----------
&LogicalPlanBuilder::scan(
UNNAMED_TABLE,
provider_as_source(provider),
None
)?.build()?,
// ----------
)))
}pub fn scan(
table_name: impl Into<String>,
table_source: Arc<dyn TableSource>,
projection: Option<Vec<usize>>,
) -> Result<Self> {
let schema = table_source.schema();
let projected_schema = ...;
Ok(Self::from(LogicalPlan::TableScan(TableScan {
table_name,
source: table_source,
projected_schema,
projection,
filters: vec![],
fetch: None,
})))
}pub enum LogicalPlan {
Projection(Projection),
Filter(Filter),
Window(Window),
Aggregate(Aggregate),
Sort(Sort),
Join(Join),
CrossJoin(CrossJoin),
Repartition(Repartition),
Union(Union),
TableScan(TableScan),
EmptyRelation(EmptyRelation),
Subquery(Subquery),
SubqueryAlias(SubqueryAlias),
Limit(Limit),
CreateExternalTable(CreateExternalTable),
CreateMemoryTable(CreateMemoryTable),
CreateView(CreateView),
CreateCatalogSchema(CreateCatalogSchema),
CreateCatalog(CreateCatalog),
DropTable(DropTable),
Values(Values),
Explain(Explain),
Analyze(Analyze),
Extension(Extension),
Distinct(Distinct),
}Logical Plan
Describes conceptually what operation needs to be performed.
Physical Plan
Describes practically what operation will be performed.
EXPLAIN SELECT * FROM titanic+---------------+-----------------------------------------------------------------------------+
| plan_type | plan |
+---------------+-----------------------------------------------------------------------------+
| logical_plan | TableScan: titanic |
| physical_plan | CsvExec: files=[Users/boazbe/IdeaProjects/RustMeetup/src/data/titanic.csv], |
| | has_header=true, limit=None, projection=None |
| | |
+---------------+-----------------------------------------------------------------------------+TableScan
Projection
Filter
Projection: #titanic.passengerid, #titanic.survived
Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST
Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) OR Int32(1) != Int32(1)
Projection: #titanic.passengerid, #titanic.survived, #titanic.age
Projection: #titanic.passengerid, #titanic.survived, #titanic.pclass,
#titanic.name, #titanic.sex, #titanic.age, #titanic.sibsp,
#titanic.parch, #titanic.ticket, #titanic.fare, #titanic.cabin,
#titanic.embarked
TableScan: titanicProjection
Sort
Projection
OptimizerS
| initial logical_plan | Projection: #titanic.passengerid, #titanic.survived |
| | Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST |
| | Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) OR Int32(1) != Int32(1) |
| | Projection: #titanic.passengerid, #titanic.survived, #titanic.age |
| | Projection: #titanic.passengerid, #titanic.survived, #titanic.pclass, #titanic.name, #titanic.sex, #titanic.age, #titanic.sibsp, #titanic.parch, #titanic.ticket, #titanic.fare, #titanic.cabin, #titanic.embarked |
| | TableScan: titanic |
| after simplify_expressions | Projection: #titanic.passengerid, #titanic.survived |
| | Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST |
| | Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) AS titanic.age > Int32(20) AND titanic.age < Int32(40) OR Int32(1) != Int32(1) |
| | Projection: #titanic.passengerid, #titanic.survived, #titanic.age |
| | Projection: #titanic.passengerid, #titanic.survived, #titanic.pclass, #titanic.name, #titanic.sex, #titanic.age, #titanic.sibsp, #titanic.parch, #titanic.ticket, #titanic.fare, #titanic.cabin, #titanic.embarked |
| | TableScan: titanic |
| after decorrelate_where_exists | SAME TEXT AS ABOVE |
| after decorrelate_where_in | SAME TEXT AS ABOVE |
| after decorrelate_scalar_subquery | SAME TEXT AS ABOVE |
| after subquery_filter_to_join | Projection: #titanic.passengerid, #titanic.survived |
| | Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST |
| | Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) |
| | Projection: #titanic.passengerid, #titanic.survived, #titanic.age |
| | Projection: #titanic.passengerid, #titanic.survived, #titanic.pclass, #titanic.name, #titanic.sex, #titanic.age, #titanic.sibsp, #titanic.parch, #titanic.ticket, #titanic.fare, #titanic.cabin, #titanic.embarked |
| | TableScan: titanic |
| after eliminate_filter | SAME TEXT AS ABOVE |
| after common_sub_expression_eliminate | SAME TEXT AS ABOVE |
| after eliminate_limit | SAME TEXT AS ABOVE |
| after projection_push_down | Projection: #titanic.passengerid, #titanic.survived |
| | Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST |
| | Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) |
| | TableScan: titanic projection=[passengerid, survived, age] |
| after rewrite_disjunctive_predicate | SAME TEXT AS ABOVE |
| after reduce_outer_join | SAME TEXT AS ABOVE |
| after filter_push_down | Projection: #titanic.passengerid, #titanic.survived |
| | Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST |
| | Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) |
| | TableScan: titanic projection=[passengerid, survived, age], partial_filters=[#titanic.age > Int32(20), #titanic.age < Int32(40)] |
| after limit_push_down | SAME TEXT AS ABOVE |
| after SingleDistinctAggregationToGroupBy | SAME TEXT AS ABOVE |
| logical_plan | Projection: #titanic.passengerid, #titanic.survived |
| | Sort: #titanic.age DESC NULLS FIRST, #titanic.survived ASC NULLS LAST |
| | Filter: #titanic.age > Int32(20) AND #titanic.age < Int32(40) |
| | TableScan: titanic projection=[passengerid, survived, age], partial_filters=[#titanic.age > Int32(20), #titanic.age < Int32(40)] |
impl SessionContext {
pub fn new() -> Self {
Self::with_config(...)
}
pub fn with_config(config: SessionConfig) -> Self {
Self::with_config_rt(...)
}
pub fn with_config_rt(config: SessionConfig, runtime: Arc<RuntimeEnv>) -> Self {
let state = SessionState::with_config_rt(...);
...
}
}impl SessionState {
pub fn with_config_rt(config: SessionConfig, runtime: Arc<RuntimeEnv>) -> Self {
...
let mut rules: Vec<Arc<dyn OptimizerRule + Sync + Send>> = vec![
Arc::new(SimplifyExpressions::new()),
Arc::new(DecorrelateWhereExists::new()),
Arc::new(DecorrelateWhereIn::new()),
Arc::new(DecorrelateScalarSubquery::new()),
Arc::new(SubqueryFilterToJoin::new()),
Arc::new(EliminateFilter::new()),
Arc::new(CommonSubexprEliminate::new()),
Arc::new(EliminateLimit::new()),
Arc::new(ProjectionPushDown::new()),
Arc::new(RewriteDisjunctivePredicate::new()),
];
if config.config_options.get_bool(OPT_FILTER_NULL_JOIN_KEYS) {
rules.push(Arc::new(FilterNullJoinKeys::default()));
}
rules.push(Arc::new(ReduceOuterJoin::new()));
rules.push(Arc::new(FilterPushDown::new()));
rules.push(Arc::new(LimitPushDown::new()));
rules.push(Arc::new(SingleDistinctToGroupBy::new()));
// Physical Plan Optimization Rules
let mut physical_optimizers: Vec<Arc<dyn PhysicalOptimizerRule + Sync + Send>> = vec![
Arc::new(AggregateStatistics::new()),
Arc::new(HashBuildProbeOrder::new()),
];
if config.config_options.get_bool(OPT_COALESCE_BATCHES) {
physical_optimizers.push(Arc::new(CoalesceBatches::new(...)));
}
physical_optimizers.push(Arc::new(Repartition::new()));
physical_optimizers.push(Arc::new(AddCoalescePartitionsExec::new()));
...
}
}let df = ctx
.read_csv(data_file.to_str().unwrap(), CsvReadOptions::default())
.await?
.filter(lit(true).eq(lit(false)))?;+---------------+----------------------------------+
| plan_type | plan |
+---------------+----------------------------------+
| logical_plan | EmptyRelation |
| physical_plan | EmptyExec: produce_one_row=false |
| | |
+---------------+----------------------------------++------------------------------------------+----------------------------------------------------------+
| plan_type | plan |
+------------------------------------------+----------------------------------------------------------+
| initial_logical_plan | Filter: Boolean(true) = Boolean(false) |
| | TableScan: ?table? |
| after simplify_expressions | Filter: Boolean(false) AS Boolean(true) = Boolean(false) |
| | TableScan: ?table? |
| after decorrelate_where_exists | SAME TEXT AS ABOVE |
| after decorrelate_where_in | SAME TEXT AS ABOVE |
| after decorrelate_scalar_subquery | SAME TEXT AS ABOVE |
| after subquery_filter_to_join | Filter: Boolean(false) |
| | TableScan: ?table? |
| after eliminate_filter | EmptyRelation |
| after common_sub_expression_eliminate | SAME TEXT AS ABOVE |
| after eliminate_limit | SAME TEXT AS ABOVE |
| after projection_push_down | SAME TEXT AS ABOVE |
| after rewrite_disjunctive_predicate | SAME TEXT AS ABOVE |
| after reduce_outer_join | SAME TEXT AS ABOVE |
| after filter_push_down | SAME TEXT AS ABOVE |
| after limit_push_down | SAME TEXT AS ABOVE |
| after SingleDistinctAggregationToGroupBy | SAME TEXT AS ABOVE |
| logical_plan | EmptyRelation |
| | |
| | |
| initial_physical_plan | EmptyExec: produce_one_row=false |
| | |
| after aggregate_statistics | SAME TEXT AS ABOVE |
| after hash_build_probe_order | SAME TEXT AS ABOVE |
| after coalesce_batches | SAME TEXT AS ABOVE |
| after repartition | SAME TEXT AS ABOVE |
| after add_merge_exec | SAME TEXT AS ABOVE |
| physical_plan | EmptyExec: produce_one_row=false |
+------------------------------------------+----------------------------------------------------------+impl OptimizerRule for EliminateFilter {
fn optimize(
&self,
plan: &LogicalPlan,
optimizer_config: &mut OptimizerConfig,
) -> Result<LogicalPlan> {
match plan {
LogicalPlan::Filter(Filter {
predicate: Expr::Literal(ScalarValue::Boolean(Some(v))),
input,
}) => {
if !*v {
Ok(LogicalPlan::EmptyRelation(EmptyRelation {
produce_one_row: false,
schema: input.schema().clone(),
}))
} else {
...
}
}
_ => {
// Apply the optimization to all inputs of the plan
...
}
}
}
fn name(&self) -> &str {
"eliminate_filter"
}
}Physical Plan
// ---------
// Calling any terminal operation, will do roughly this
// ---------
df.show().await?;
// ---------
pub async fn show(&self) -> Result<()> {
let results = self.collect().await?;
Ok(pretty::print_batches(&results)?)
}
pub async fn collect(&self) -> Result<Vec<RecordBatch>> {
let plan = self.create_physical_plan().await?;
...
collect(plan, ...).await
}impl PhysicalOptimizerRule for AddCoalescePartitionsExec {
fn optimize(
&self,
plan: Arc<dyn crate::physical_plan::ExecutionPlan>,
config: &crate::execution::context::SessionConfig,
) -> Result<Arc<dyn crate::physical_plan::ExecutionPlan>> {
if plan.children().is_empty() {
Ok(plan.clone())
} else {
let children = ...
match plan.required_child_distribution() {
Distribution::UnspecifiedDistribution => {
with_new_children_if_necessary(plan, children)
}
Distribution::HashPartitioned(_) => {
with_new_children_if_necessary(plan, children)
}
Distribution::SinglePartition => with_new_children_if_necessary(
plan,
...
),
}
}
}
fn name(&self) -> &str {
"add_merge_exec"
}
}
ProjectionExec: expr=[passengerid@0 as passengerid, survived@1 as survived]
SortExec: [age@2 DESC,survived@1 ASC NULLS LAST]
CoalescePartitionsExec
CoalesceBatchesExec: target_batch_size=4096
FilterExec: age@2 > CAST(20 AS Float64) AND age@2 < CAST(40 AS Float64)
RepartitionExec: partitioning=RoundRobinBatch(10)
CsvExec: files=[Users/boazbe/IdeaProjects/RustMeetup/src/data/titanic.csv],
has_header=true, limit=None, projection=[passengerid, survived, age]


Thank You