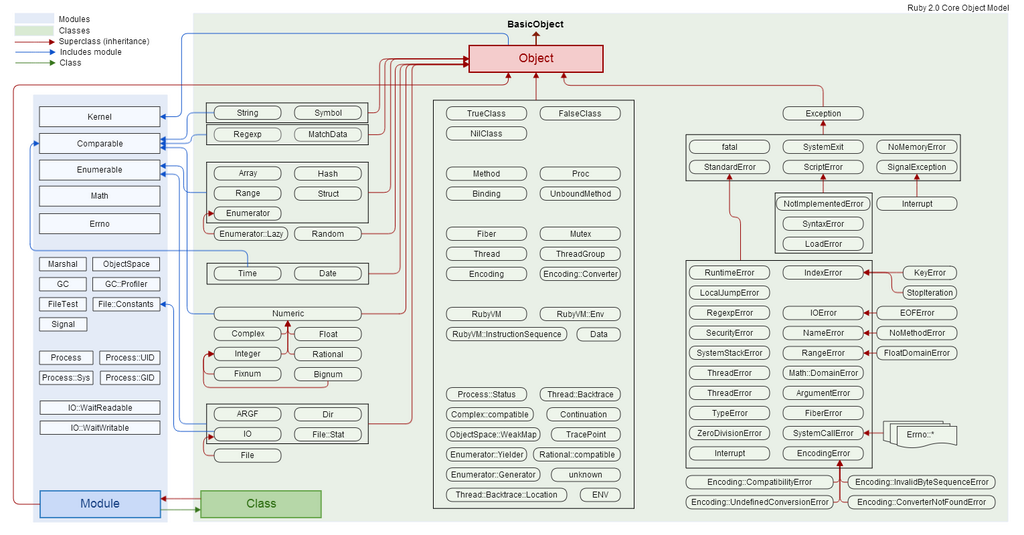
Practical Data Science in Ruby
#FF0000 Leather Pants.
ybur-yug == Developer
# => true
@yburyug - Twitter
ybur-yug - GithubPS: This will be my last CRB talk for a long while. Thank you for the support & allowing me to geek out
<3
"Data-Driven"

Data Infrastructure
- Distributed Systems
- ETL
- MapReduce
- Data Warehousing
- High Availability
- PubSub (live analysis)
- A means of experimentation
Can We Do It Without This?
Yes. Sorta.
Where to Start?
Web Application Datapoints
- Comments/Feedback
- Traffic Patterns/Analysis
- Navigation Recommendation (Netflix recommended content)
The Complicated Stuff
- Recommender Models
Potential
Easy
Starts
Natural Language Analysis!
These generally are very linear algebra heavy, and require modern research
This too requires a lot of modern reading. Everything from K-Nearest Neighbors to Random Forest algorithms can be used and will be mentioned
- Site Traversal
NLP
A field of computer science, artificial intelligence, and computational linguistics concerned with the interactions between computers and human (natural) languages. As such, NLP is related to the area of human–computer interaction.
Simple NLP In Ruby
Sentiment Analysis
Sentimental
A simple gem to get us started
https://github.com/ybur-yug/CRB_ruby_data
$ gem install sentimental
A Simple Start
Sentimental is a simple gem for analyzing the sentiment, or positive/negative/neutral inflection of a string or corpus
Let's say we have a JSON block of all our comments...
# analyzer.rb
require 'sentimental'
class Analyzer
def initialize(comments, threshold)
@ comments = comments
Sentimental.load_defaults # load the default training model
Sentimental.threshold = threshold # set threshold
@analyzer = Sentimental.new
end
def sentiments
@sentiments = @comments.map do |comment|
{ comment: comment['body'],
score: @analyzer.get_score(comment['body']),
sentiment: @analyzer.get_sentiment(comment['body']) }
end
end
endA Simple Analysis Class
18 Lines of Code
Using It
- Prepare our data
- Prepare output destination
- Run
So now we do that...
$ ls data
jan feb mar apr may jun jul aug sep oct nov dec
$ ls data/jan
month.json
# lib/prep.rb
SPLIT_SIZE = 50000
Dir.foreach("../data/") do |dir|
if dir != '.' && dir != '..' # Dir.pwd lists these
Dir.mkdir "../data/#{dir}/split"
`split -l #{SPLIT_SIZE} ../data/#{dir}/month.json ../data/#{dir}/split/data-`
end
endRun the provided setup script...
And now the sentiment analysis...
#lib/run.rb
require 'json'
require_relative 'analyzer'
all_data = []
Dir.foreach('../data') do |month|
if month != '.' && month != '..'
Dir.foreach("../data/#{month}/split") do |part|
if part != '.' && part != '..'
comments = File.open("../data/#{month}/split/#{part}").read.split("\n").map do |line|
JSON.parse(line)
end
data = Analyzer.new(comments, 0.4).sentiments
data.each { |s| s[:month] = month }
all_data << data
end
end
end
end
all_data.flatten!Sample
$ ruby analyze.rb data_sample.json
# =>
Comment Set Size: 10000
Result One Avg (threshold 0.6): 0.12837111622858283
Result One Positive Sentiment Count: 6001
Result One Negative Sentiment Count: 1663
Result One Neutral Sentiment Count: 6001
Result Two Avg (threshold 0.8): 0.12837111622858283
Result Two Positive Sentiment Count: 7006
Result Two Negative Sentiment Count: 1199
Result Two Neutral Sentiment Count: 7006
Result Three Avg (threshold 0.4): 0.12837111622858283
Result Three Positive Sentiment Count: 4983
Result Three Negative Sentiment Count: 2097
Result Three Neutral Sentiment Count: 4983
Next:
Building It Into Rails
Sentimentalizer
A Rails Engine

$ cd my_rails_app
$ editor Gemfile # add `gem 'sentimentalizer'`
$ bundle
$ rails g sentimentalizer:install
`after_initialize` hook loading default training model
Now...
- Create a 'Sentiment' model that belongs to what you are analyzing
- Give it text, probability, and sentiment attributes
- Create an `after_create :find_sentiment`
- Persist
Usefulness
- Understand positivity/negativity in comments/chat
- Have a means to detect 'flame wars'
- Detect changes in positive talk towards negative talk or vice-versa over time with simple analysis
Will This Change Your Life?
Nope.
Diving Deeper:
Bayesian Classifiers
What? Math Is Hard.
In machine learning, naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes' theorem with strong (naive) independence assumptions between the features.
Naive Bayes Classifier:
Why?
FIND ALL THE SPAM

Back When Spam Email Was REALLY Bad

A Gem, So That We Don't Have To Do The Math
$ gem install classifier
And now, we grab our spam

Training
spam = File.open('our_spam.txt').read
good_comments = File.open('our_comments.txt').read
require 'classifier'
classifier = Classifier::Bayes.new('Spam', 'Ham')
# single input example
classifier.train_spam 'BUY THIS SHIT'
classifier.train_ham 'that was an interesting and thought provoking piece'
classifier.classify "I enjoyed this article"
# => ham
# Train on a large set
spam.each_line { |spam| classifier.train_spam spam }
ham.each_line { |ham| classifier.train_ham ham }
# Classify Away!
Takeaways
Call on God, but row away from the rocks.
- Hunter S. Thompson

Statistics

Foundations of Machine Learning

Advanced Calculus
The Tools Are There
- Bayesian Classifiers
- Term-Frequency Inverse-Document Frequency
- Vector Space Models
- Neural Networks
Commonality: All of these have robust, open source tools easily available to utilize
BUT
The Best Tools Are In Python
One Last Example (In Python + RestMQ)
# Simple word frequency counter
# Clone RestMQ (https://www.github.com/gleicon/restmq)
$ git clone https://www.github.com/gleicon/restmq.git
$ cd examples/mapreduce
# Download a huge text file (E.g Bible, some Gutenberg books)
$ mkdir files
$ split -l 1000 yourebook.txt files/bookfrag-
# In another terminal run our consumer
$ python reduce.py
# Now, run the producer:
$ for a in `ls files`; do python map.py files/$a; done
BONUS ROUND:
Live Editable & Updating Page w/no JS in < 20 lines
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Whoa</title>
</head>
<body>
<p>Edit for live preview</p>
<style contenteditable="true">
style { font-family: open-sans; }
div { color: red; background: black; }
</style>
<div>Hello World</div>
</body>
</html>