PRM-RL: Long-range Robotic Navigation Tasks by Combining Reinforcement Learning and Sampling-based Planning
Aleksandra Faust, Oscar Ramirez, Marek Fiser, Kenneth Oslund, Anthony Francis, James Davidson, and Lydia Tapia
Presented by Breandan Considine
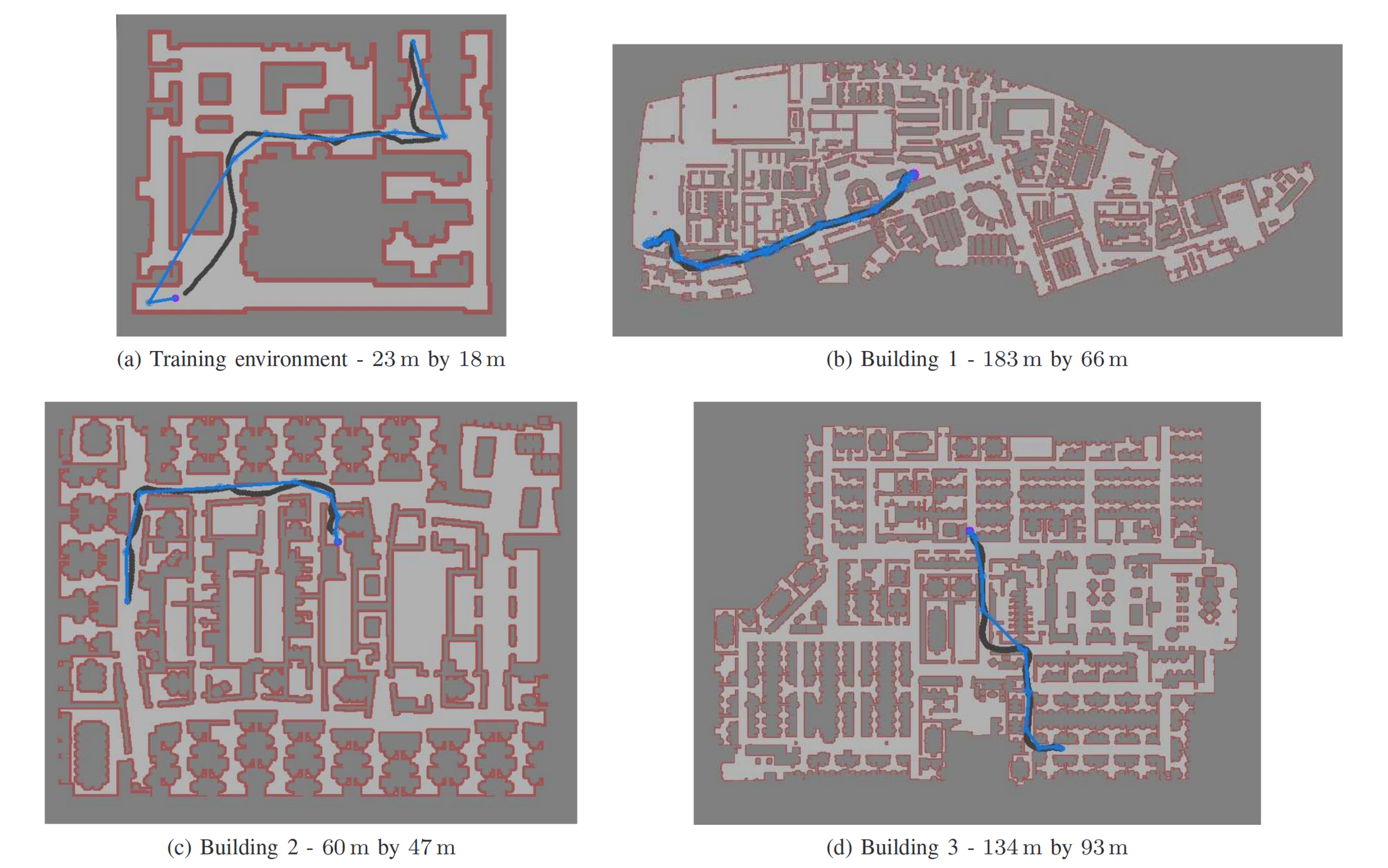
Workspace
Configuration space
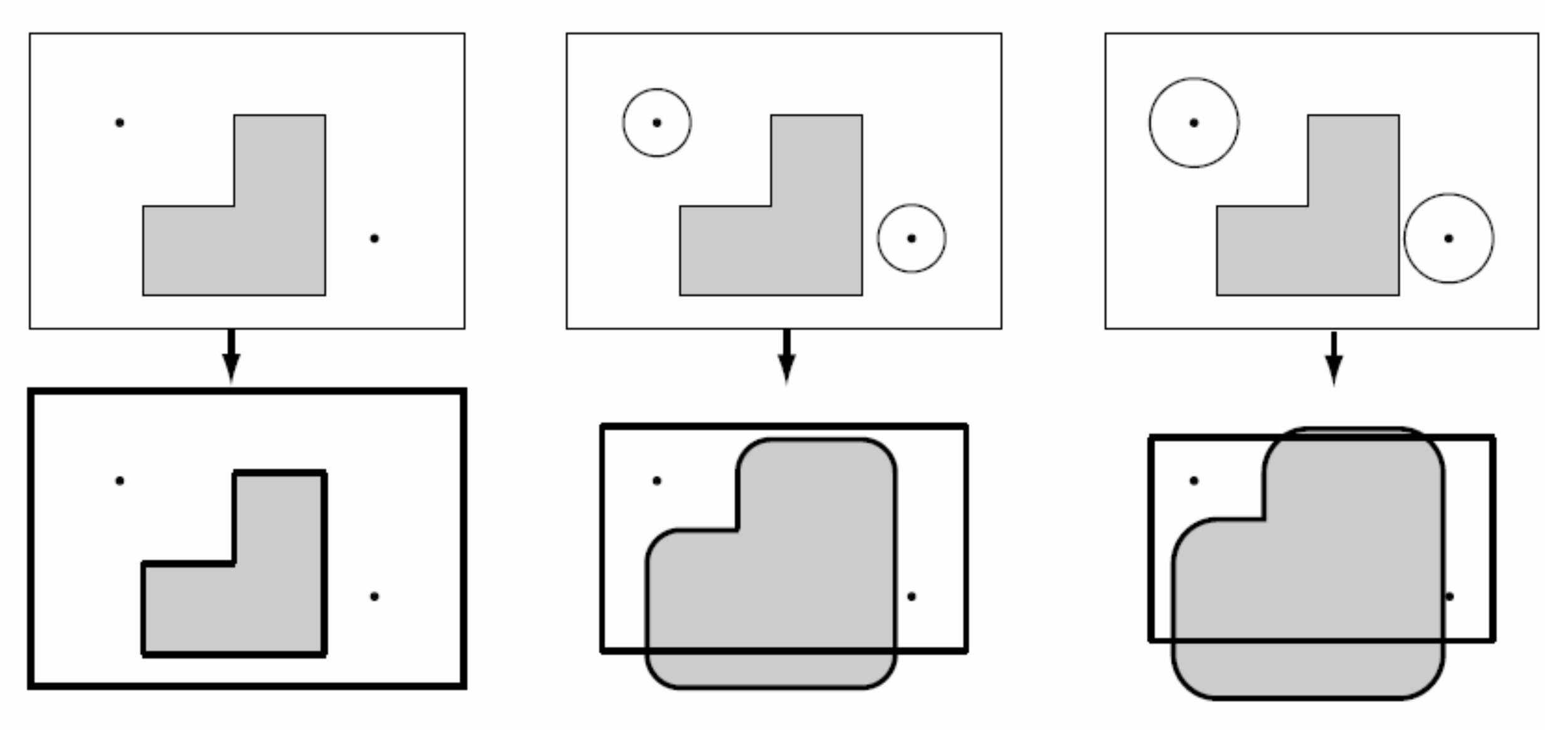

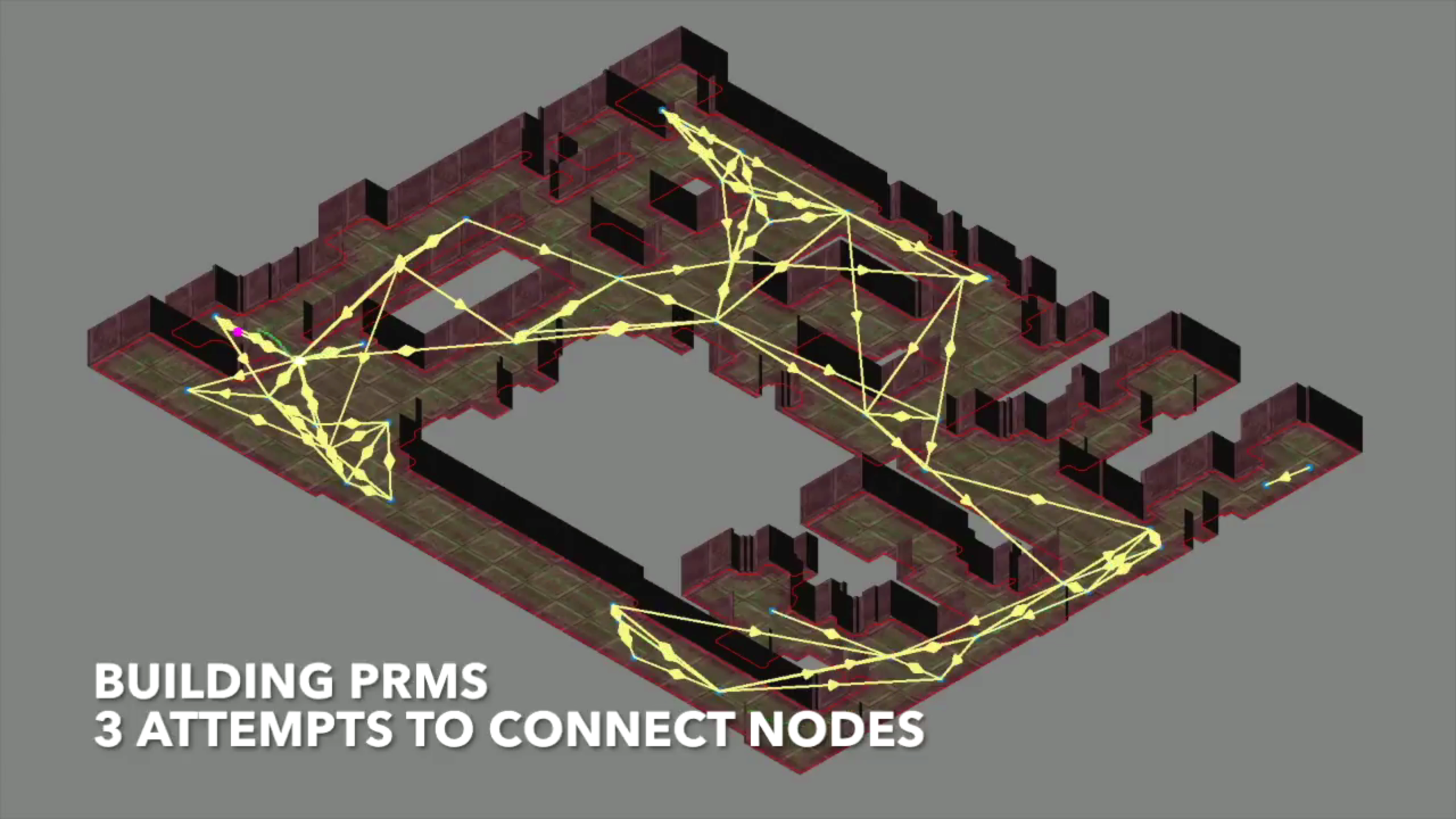
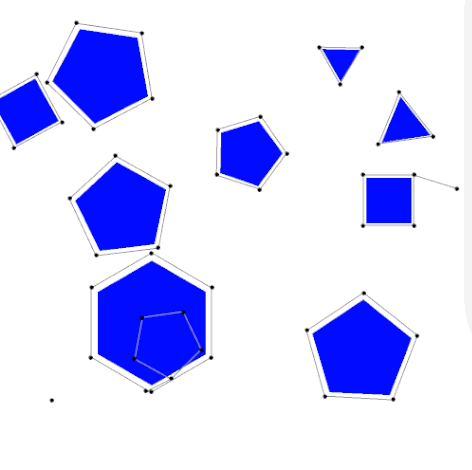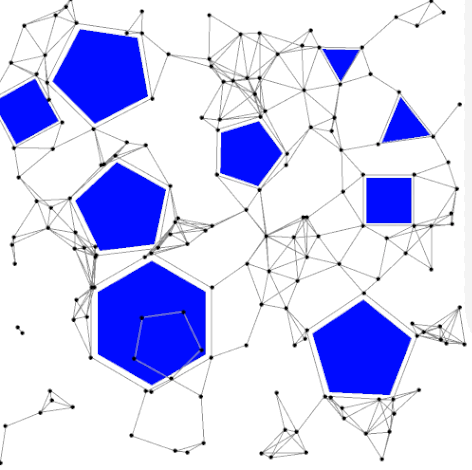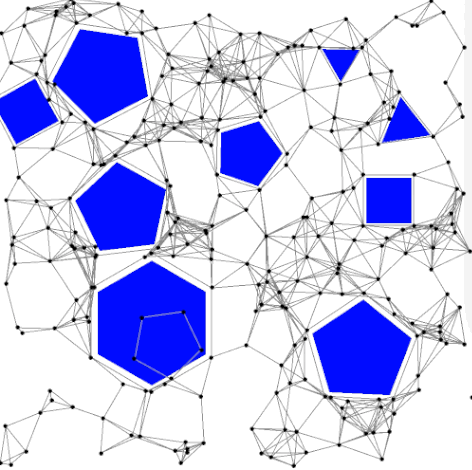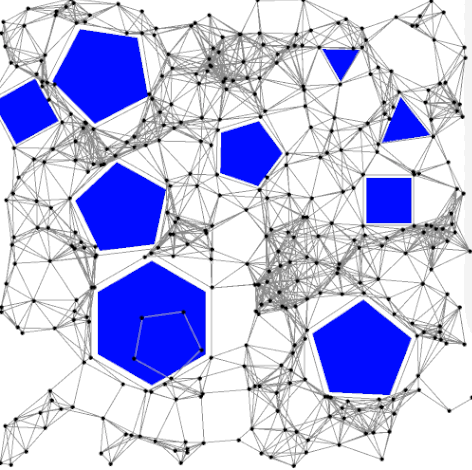
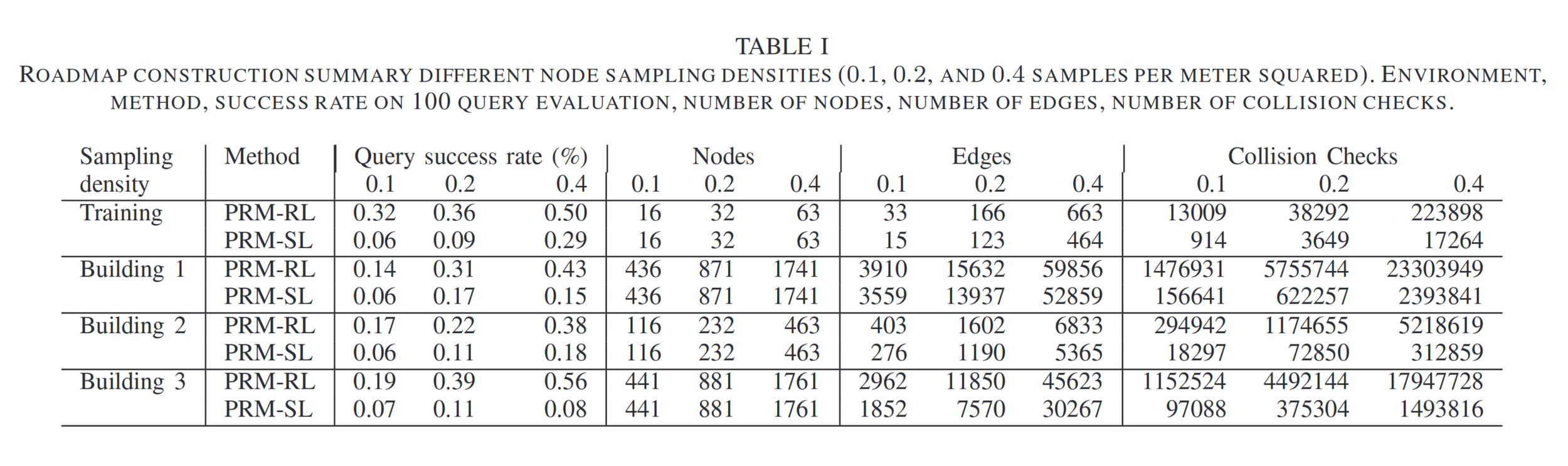
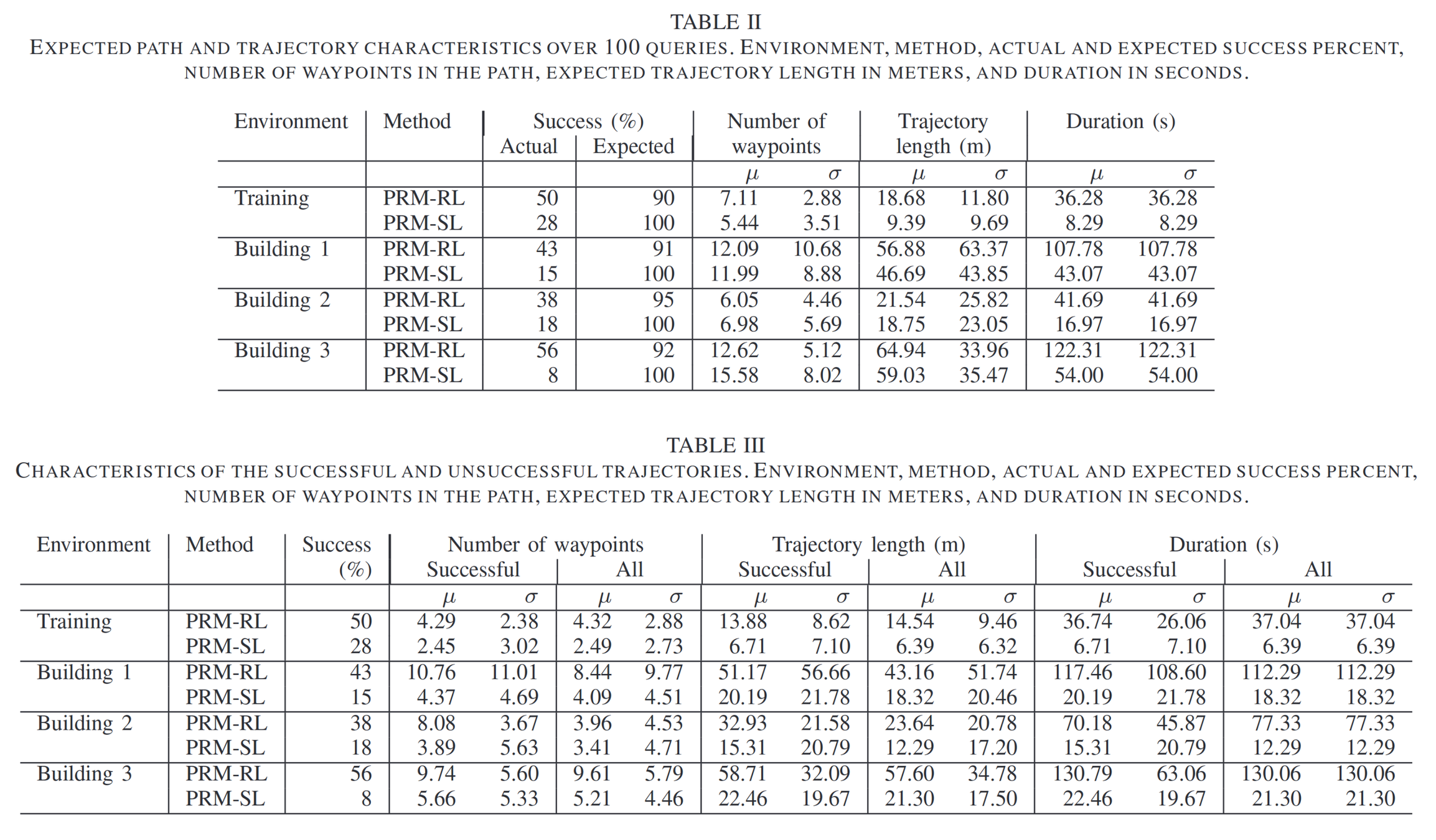
Probabilistic roadmaps
Advantages
- Very efficient planning representation
- Provably probabilistically complete
- Guaranteed to find a path if one exists, given enough samples
Disadvantages
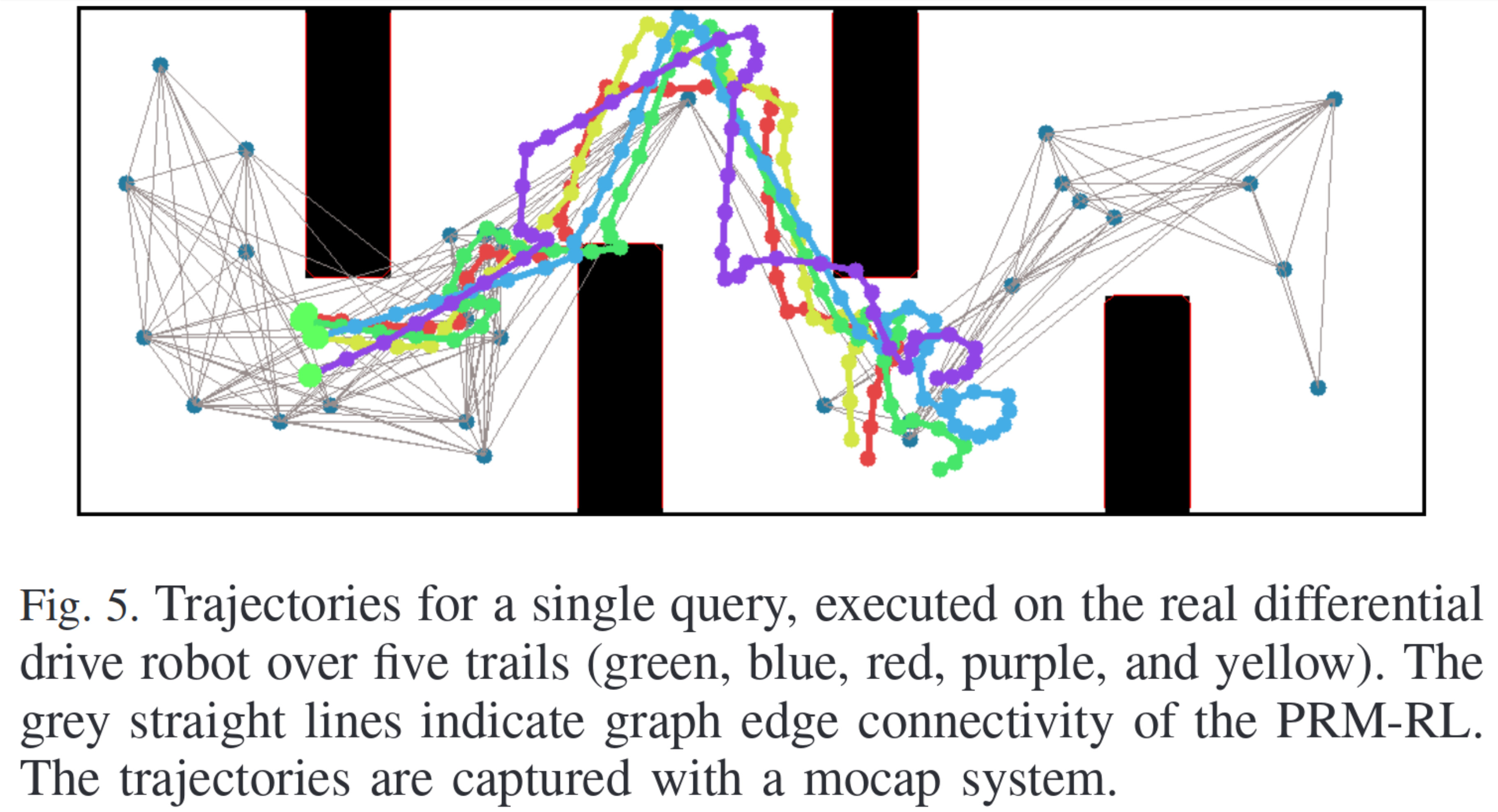
- Executing reference trajectories
- Typically unaware of task constraints
- Can suffer from noise in perception and motor control
- Does not perform well under uncertainty
RL Planners
Advantages
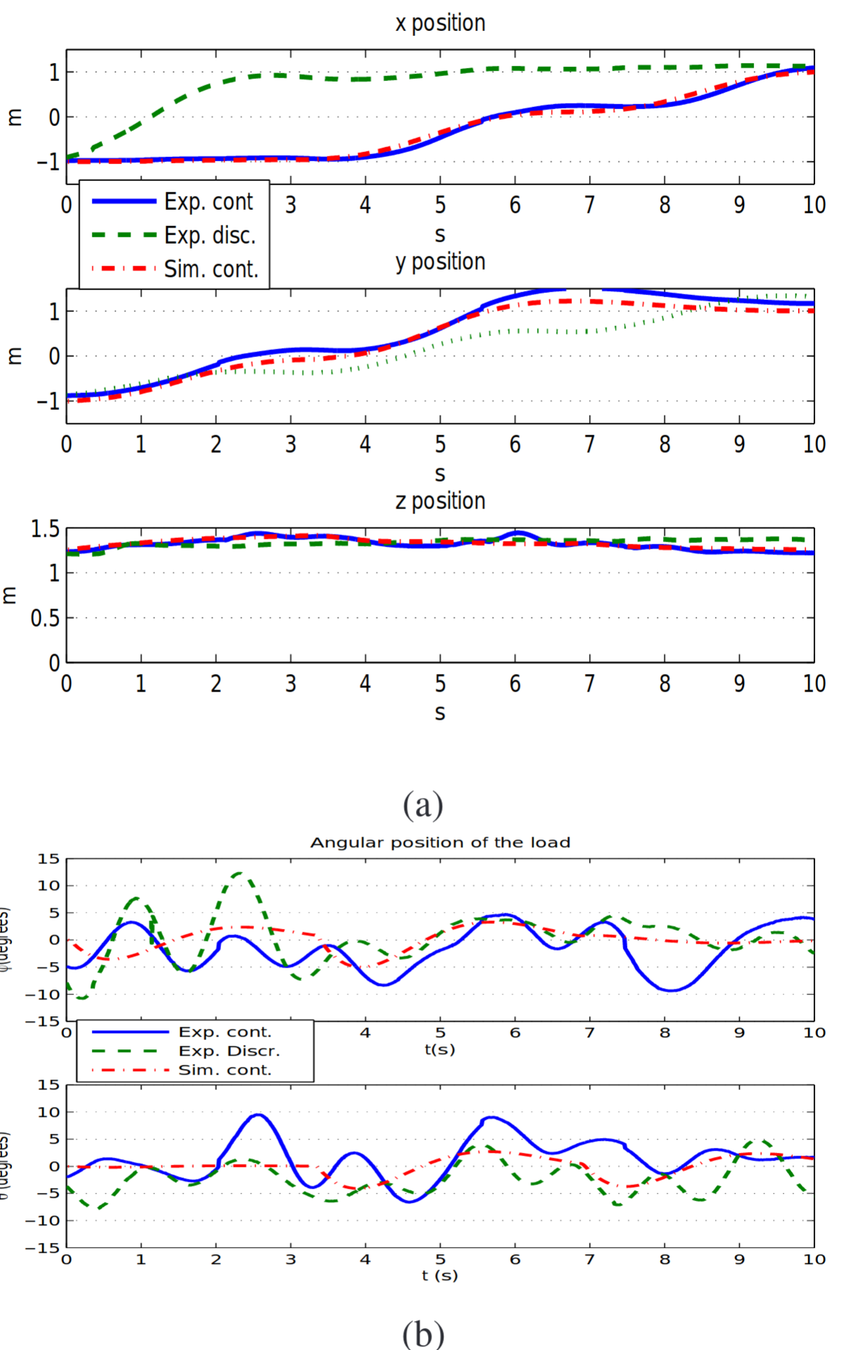
- Robust to noise and errors
- Can obey robot dynamics and other task constraints
- Handles moderate changes to the environment
- Not as computationally complex to execute as other approaches (e.g. MPC, action filtering, hierarchical policy approximation)
Disadvantages
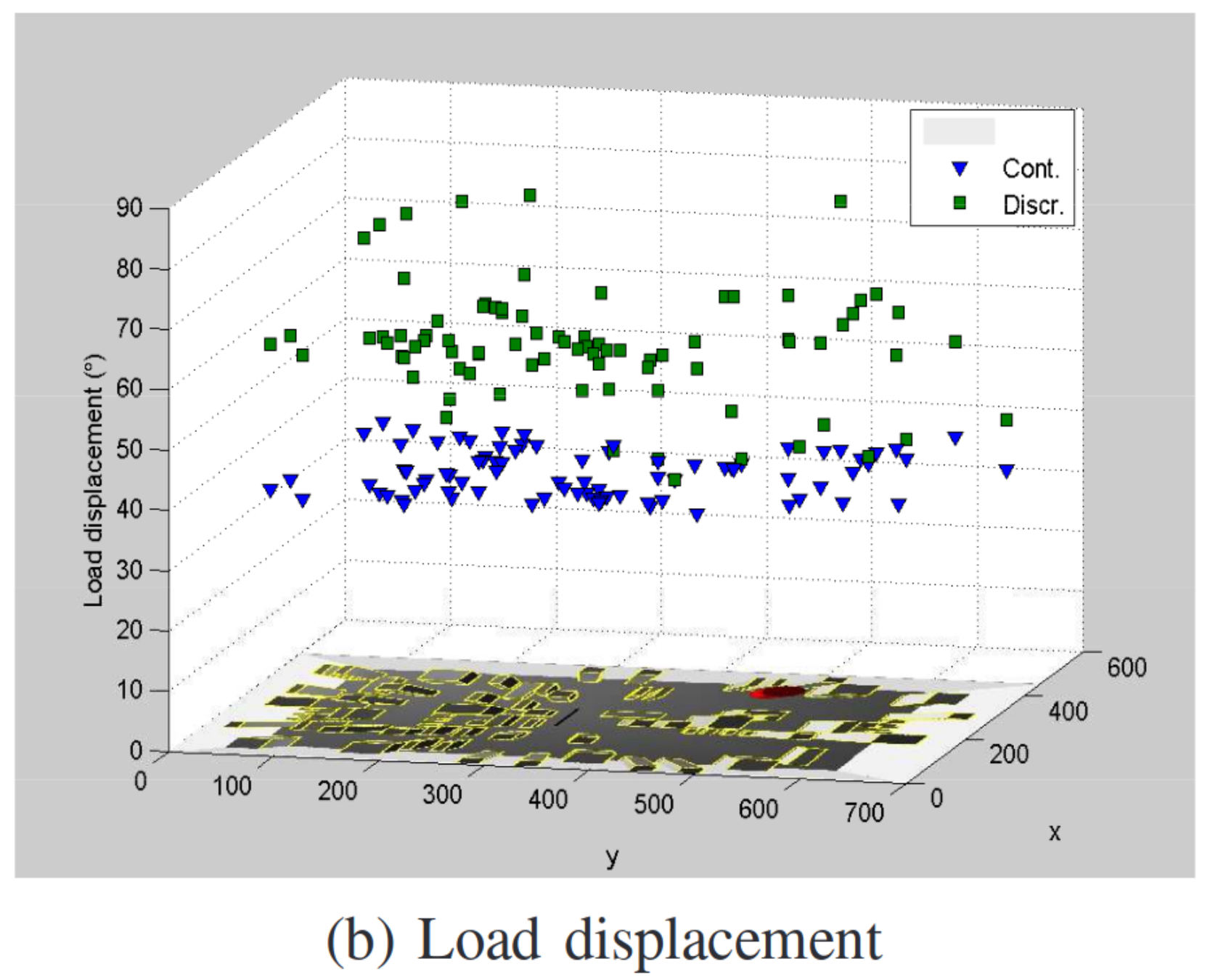
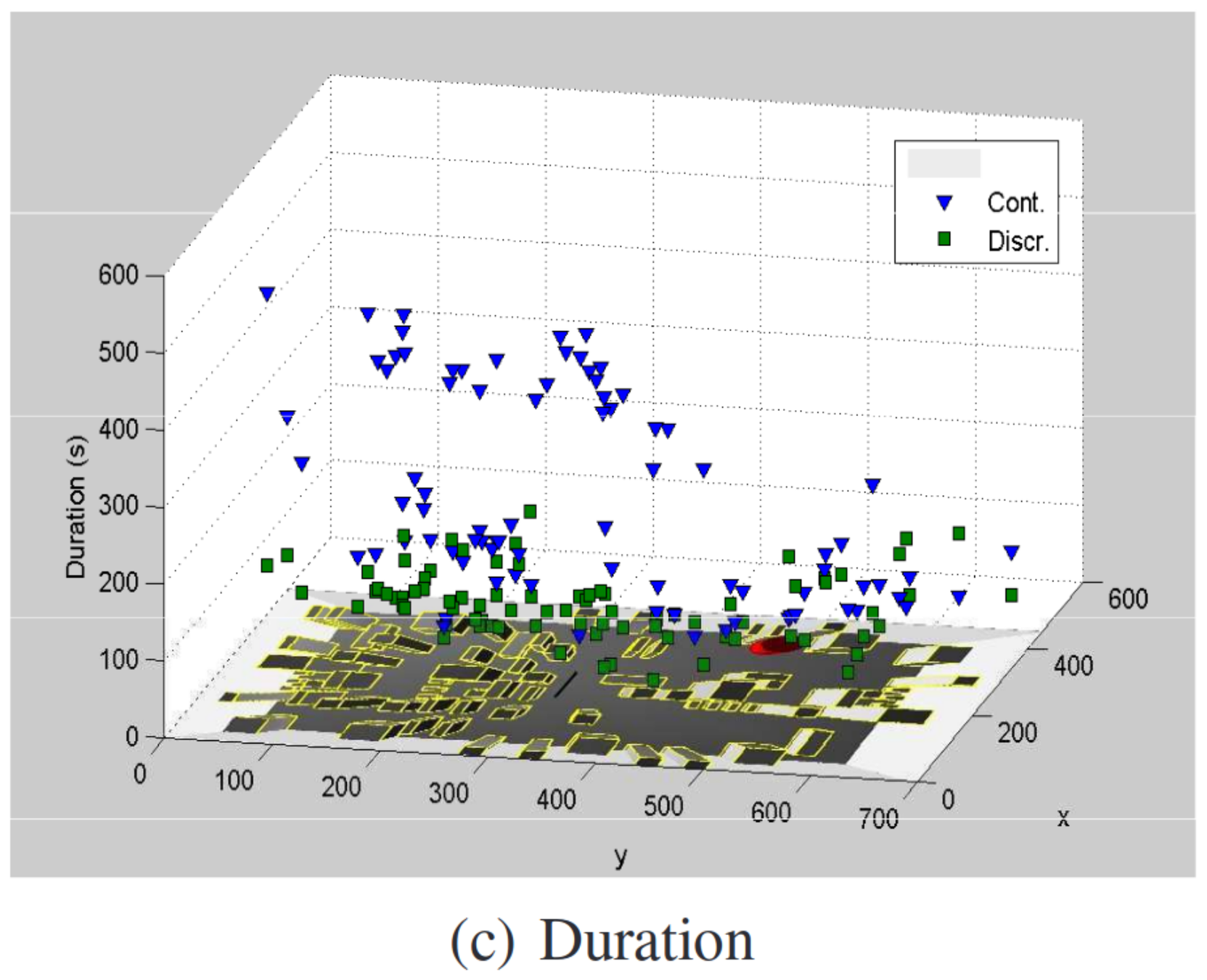
- Long range navigation on complex maps has a sparse reward structure
- Can be difficult to train
- Prone to converge on poor local minima
- Need to carefully select the control and action space
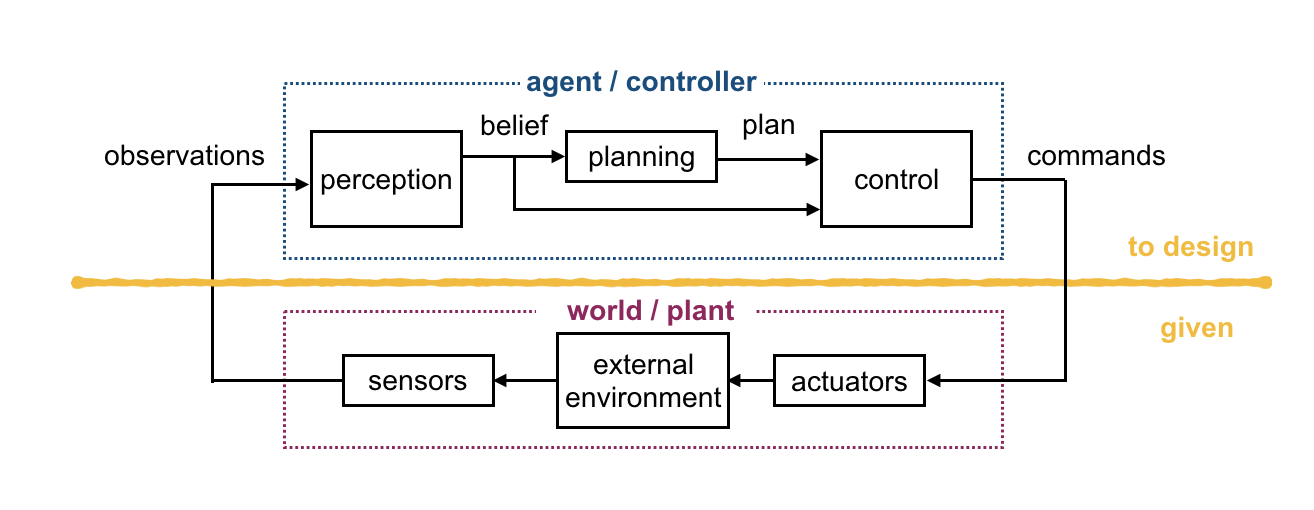
How can we synthesize these two approaches?
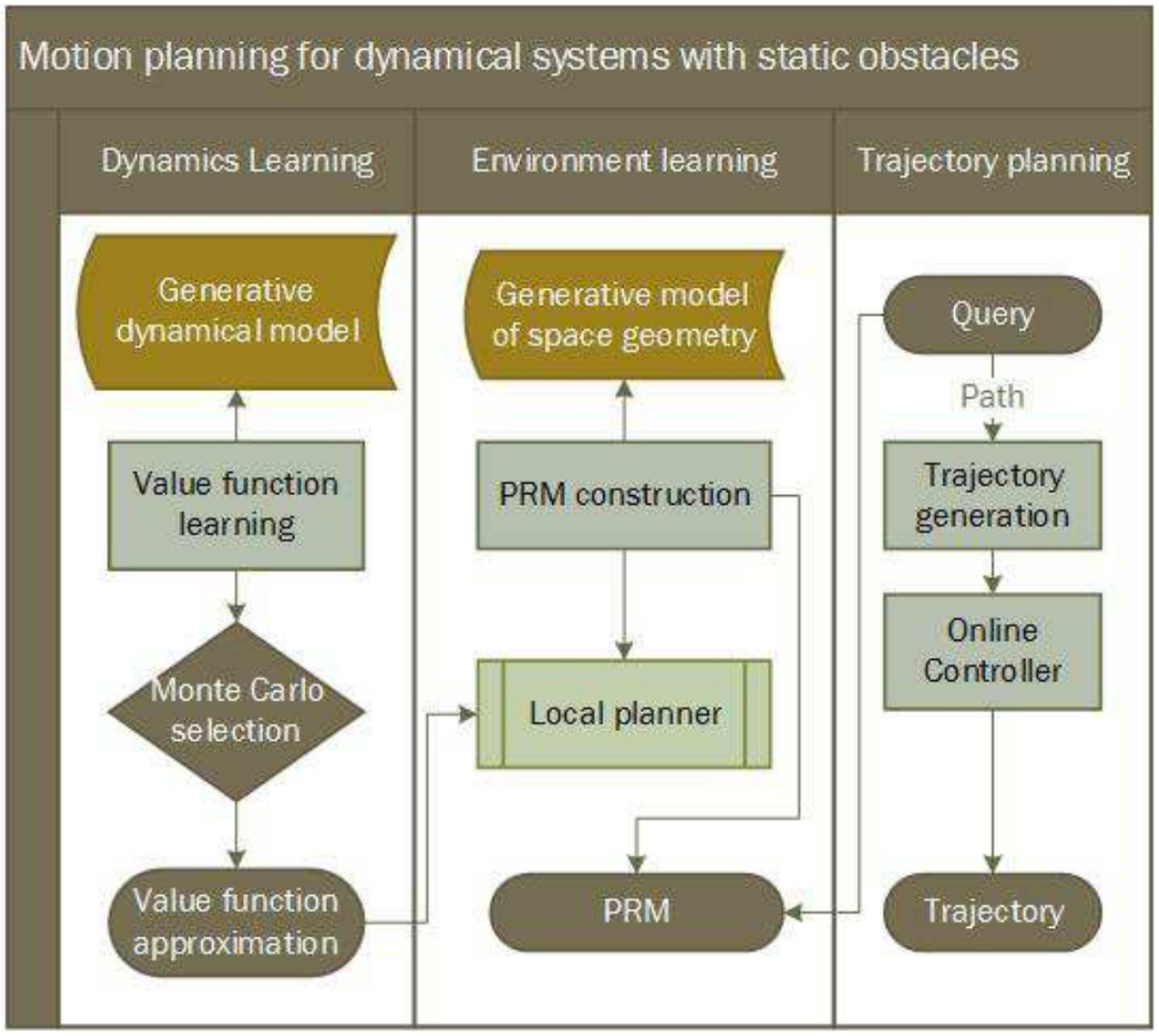
How do we train the dynamics model?