Listen Up:
The Web Speech APIS Part Deux
Speech Recognition
Stuff we discussed
- Long history, lots of fails trying to standardize
- Windy path, but we wound up with
(buggy/imperfect) TTS support in all modern
browsers -
That isn't a standard, it's from an unofficial
draft that contained stuff about voice
recognition too...
Not nearly as widely implemented...
let voiceRecognition = new webkitSpeechRecognition()
Constructor...
It's not listening.

and you don't know if it ever will.
You have to ask for permission

Watch it, Fokker...

voiceRecognition.start()

The draft says at this point it needs to check...
do you have permission?
The draft says that the browser has to tell you
when it's listening...
Sometimes you might see this in Chrome on the Desktop.
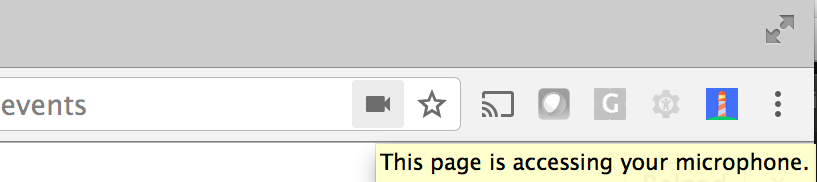
It's not listening.
The draft says that the browser has to tell you
when it's actually listening
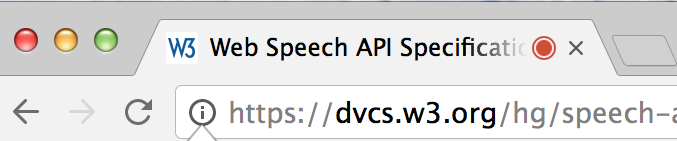
Now it's listening
You have to be able to revoke/manage that easily.

In fact, you have to be able to revoke/manage all permissions easily.

Tough problem.
YMMV.
User-Agent
Standards and browsers are very sensitive to this.
Let's get back on track..
Assuming you have permission, after
.start() it is listening.
Now what?
The voiceRecognition object pumps lots of events,
let's start with these..
voiceRecognition.onstart = (evt) => {
// Congratulations, you have permission.
}
draft: "Fired when the recognition service has begun to listen to the audio with the intention of recognizing"
start
voiceRecognition.onerror = (evt) => {
// What could possibly go wrong?
}
draft: "Fired when a speech recognition error occurs"
error
voiceRecognition.result = (evt) => {
// YAY!!!
}
draft: "Fired when the speech recognizer returns a result"
result
Ok... wow... That's a lot simpler than I expected.
So.. how do I get the text transcript
of the sound? Is it the event?

voiceRecognition.onresult = (evt) => { console.log(` here's what I heard: ${evt.results[0][0].transcript} `) }
Wait...
.results is a multi-dimensional array?
evt.results[0][0].transcript

Array-likes.
The good news is, for most use cases,
there will only be one in each collection,
and you want the 0'th one.
Wait... why is evt.results an array-like?
voiceRecognition.continuous = true;
voiceRecognition.onresult = (evt) => {
// evt.results.length is one greater
// with each recognition in
// continuous mode.
}
Implementations buggy, possibly contentious.
This means that voiceRecognition will stop listening after some recognition occurs.
Of course, you can restart it again.
♬ ding
You: It was the best of times, it was the worst of times, bleep ♬
it was ♬ ding the age of wisdom, it was the age of foolishness, bleep ♬
it was the ♬ ding epoch of belief, it was the epoch of incredulity bleep ♬
it was the season of ♬ ding Light, it was the season of Darkness
Mobile tho...
♬ ding
You: It was the best of times, it was the worst of times, bleep ♬
{computer speaks 'I heard it was the best of times it was the worst of times while you are saying
it was the age of wisdom, it was the age of foolishness}
♬ ding
{computer speaks 'I heard I heard it was the age of best of wisdom at times of foolishness' while you are
saying the next bit... even if you stop talking.. }
bleep ♬
{potentially infinite ♬ ding bleep ♬ loop of 'I heards' hearing 'itself'}
Add an 'I heard' confirmation for extra lolz and talk over each other..
let speechRecognitionResult = evt.results[0] // also not an Array, also will usually have // exactly 1 item. Why?
Ok... Let's talk about this thing..
voiceRecognition.maxAlternatives = 10
voiceRecognition.onresult = (evt) => {
let alternatives = evt.results[0]
...
}
alternatives.length can be 1...10
each of these also has a
.confidence attribute (float 0...1)
Let's play a game....
What are they wearing?

What is bruce wearing today?
A psychedelic rhinestone encrusted t-shirt depicting a cat in a sailor's cap
recognition hears something like...

What is bruce wearing today?
A pink tye-dyed t-shirt depicting a cats and a long ringlets wig
recognition hears something like...

What is he wearing?
A unicorn costume
recognition hears something like...
Bruce is wearing a ________

822
(confidence: 0.9483599662780762)
and recognition hears something like...
Fill in the blanks...
The _____ Lama and Bishop Desmond _____?

The dolly Lama and Bishop Desmond 22?
If we listen for just those two values...
Context matters.
Confidence/Quality are a little arbitrary.
If I read "This is a photo of the Dali Lama and Bishop Desmond Tutu" there's more context that can be used
... if the service can do that
So, that's why alternatives... It's one way you can maybe deal with this problem of ambiguity.
-
.results is a SpeechRecognitionResultList
-
It's not an Array
-
It probably contains exactly 1 item
-
That item is a SpeechRecognitionResult
-
It's not an Array either
-
Unless you set maxResults, it will contain exactly 1 item
-
That item is a SpeechRecogntionAlternative
-
It has a .transcript property and a .confidence property
To Recap...

Text