Parallel implementation of Particle-Mesh mapping using CUDA enabled GPU
@brijesh68kumar
Git hub : bit.ly/brijesh_gpu_git
Slides : bit.ly/slide_gpu_indicon2015
A little about me
- ICT graduate, class of 2015
- Past IAS IEEE chair sb DAIICT Guj | Mercedes Benz
- Now SRF at NGO | IEEE YP
- @brijesh68kumar| github.com/brijesh68kumar
- Community growing (sponsors, speakers)
- Previous
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Introduction
Do you like series/manga
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar



Download
How


http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
⬇ CPU ⬇ GPU
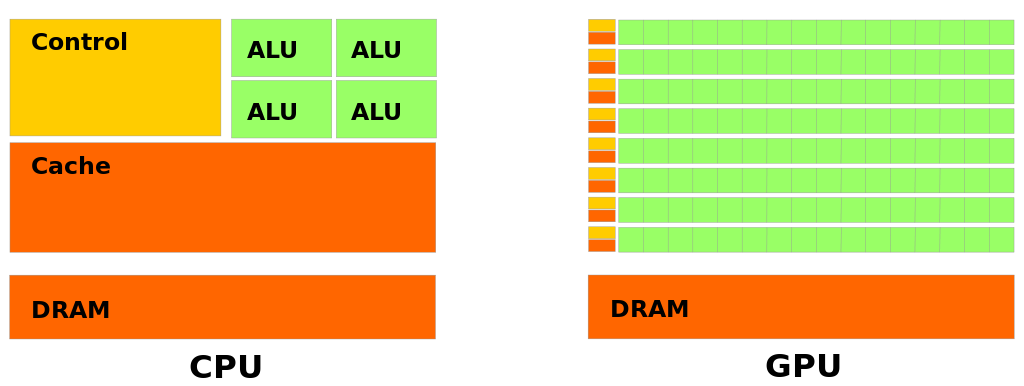
Architecture
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Latency oriented approach
Throughput oriented approach
Overhead
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Application code
Rest of
sequential
cpu code
CPU
GPU
computer intensive
5%
of code
// Algorithm to launch the kernel from CPU
Int main()
{
Variable hostGrid, hostParticle;
Variable deviceGrid, deviceParticle;
// initialize host variable using Algorithm 1.
cudaMalloc(device variable space in GPU);
cudaMemcpy( host to device );
// define block dimension
Dim3 bD; //block dimension;
Dim3 gD; //grid dimension;
// bD x gD = total number of particles;
Launch kernel<< bD, gD>>(parameters);
cudaMemcpy(from device to host);
Store data into file;
Free memory;
}Example: Matrix multiplication
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
#include <stdlib.h>
#include <stdio.h>
#include <sys/time.h>
/* change dimension size as needed */
const int dimension = 4096;
struct timeval tv;
double timestamp()
{
double t;
gettimeofday(&tv, NULL);
t = tv.tv_sec + (tv.tv_usec/1000000.0);
return t;
}
int main(int argc, char *argv[])
{
int i, j, k;
double *A, *B, *C, start, end;
A = (double*)malloc(dimension*dimension*sizeof(double));
B = (double*)malloc(dimension*dimension*sizeof(double));
C = (double*)malloc(dimension*dimension*sizeof(double));
srand(292);
for(i = 0; i < dimension; i++)
for(j = 0; j < dimension; j++)
{
A[dimension*i+j] = (rand()/(RAND_MAX + 1.0));
B[dimension*i+j] = (rand()/(RAND_MAX + 1.0));
C[dimension*i+j] = 0.0;
}
start = timestamp();
for(i = 0; i < dimension; i++)
for(j = 0; j < dimension; j++)
for(k = 0; k < dimension; k++)
C[dimension*i+j] += A[dimension*i+k] *
B[dimension*k+j];
end = timestamp();
printf("\nsecs:%f\n", end-start);
free(A);
free(B);
free(C);
return 0;
}#include <stdlib.h>
#include <stdio.h>
#include <sys/time.h>
/* change dimension size as needed */
const int dimension = 512 ;
const int blocksize = 10;
const int K = 1;
struct timeval tv;
__global__ void gpuMM(float *A, float *B, float *C, int N)
{
// Matrix multiplication for NxN matrices C=A*B
// Each thread computes a single element of C
int row = blockIdx.y*blockDim.y + threadIdx.y;
int col = blockIdx.x*blockDim.x + threadIdx.x;
float sum = 0.f;
for (int n = 0; n < N; ++n)
sum += A[row*N+n]*B[n*N+col];
C[row*N+col] = sum;
}
int main(int argc, char *argv[])
{
cudaEvent_t start_i, stop_i,start_mc_h2d, stop_mc_h2d,start_mc_d2h, stop_mc_d2h,start_pl, stop_pl;
float time_i,time_mc_h2d,time_mc_d2h,time_pl;
cudaEventCreate(&start_i);
cudaEventCreate(&stop_i);
cudaEventCreate(&start_mc_h2d);
cudaEventCreate(&stop_mc_h2d);
cudaEventCreate(&start_mc_d2h);
cudaEventCreate(&stop_mc_d2h);
cudaEventCreate(&start_pl);
cudaEventCreate(&stop_pl);
int i, j;
float *A, *B, *C;// start, end;
float *Ad, *Bd, *Cd;
cudaEventRecord( start_i, 0 );
A = (float*)malloc(dimension*dimension*sizeof(float));
B = (float*)malloc(dimension*dimension*sizeof(float));
C = (float*)malloc(dimension*dimension*sizeof(float));
srand(292);
for(i = 0; i < dimension; i++)
for(j = 0; j < dimension; j++)
{
A[dimension*i+j] = (rand()/(RAND_MAX + 1.0));
B[dimension*i+j] = (rand()/(RAND_MAX + 1.0));
C[dimension*i+j] = 0.0;
}
cudaEventRecord( stop_i, 0 );
cudaEventSynchronize( stop_i );
cudaEventElapsedTime( &time_i, start_i, stop_i );
cudaEventRecord( start_mc_h2d, 0 );
cudaMalloc( (void**)&Ad, dimension*dimension*sizeof(float) );
cudaMemcpy( Ad, A, dimension*dimension*sizeof(float), cudaMemcpyHostToDevice );
cudaMalloc( (void**)&Bd, dimension*dimension*sizeof(float) );
cudaMemcpy( Bd, B, dimension*dimension*sizeof(float), cudaMemcpyHostToDevice );
cudaMalloc( (void**)&Cd, dimension*dimension*sizeof(float) );
cudaEventRecord( stop_mc_h2d, 0 );
cudaEventSynchronize( stop_mc_h2d );
cudaEventElapsedTime( &time_mc_h2d, start_mc_h2d, stop_mc_h2d );
//start = timestamp();
cudaEventRecord( start_pl, 0 );
dim3 threadBlock(blocksize,blocksize);
dim3 grid(K,K);
gpuMM<<<grid,threadBlock>>>( Ad,Bd,Cd,dimension);
//end = timestamp();
cudaEventRecord( stop_pl, 0 );
cudaEventSynchronize( stop_pl );
cudaEventElapsedTime( &time_pl, start_pl, stop_pl );
cudaEventRecord( start_mc_d2h, 0 );
cudaMemcpy(C,Cd,dimension*dimension*sizeof(float),cudaMemcpyDeviceToHost);
cudaEventRecord( stop_mc_d2h, 0 );
cudaEventSynchronize( stop_mc_d2h );
cudaEventElapsedTime( &time_mc_d2h, start_mc_d2h, stop_mc_d2h );
printf("\n IT : %f ", time_i);
printf(" MCT : %f", ( time_mc_d2h + time_mc_h2d ) );
printf(" PLT:%f ", time_pl);
printf(" Total:%f.... \n\n", (time_pl + time_mc_d2h + time_mc_h2d+time_i));
cudaEventDestroy( start_i );
cudaEventDestroy( stop_i );
cudaEventDestroy( start_mc_d2h );
cudaEventDestroy( stop_mc_d2h );
cudaEventDestroy( start_mc_h2d );
cudaEventDestroy( stop_mc_h2d );
cudaEventDestroy( start_pl );
cudaEventDestroy( stop_pl );
free(A);
free(B);
free(C);
cudaFree(Ad);
cudaFree(Bd);
cudaFree(Cd);
return 0;
}
Performance analysis
http://bit.ly/slide_gpu_indicon2015 @brijesh68kumar
Basic Stream

----0----1----2----3----> rx.interval(5000)
$scope.counter = 0;
rx.Observable
.interval(5000)
.take(3)
.safeApply($scope, function(x) {
$scope.counter = x;
})
.subscribe(); // shows 0, 1, 2http://bit.ly/introduction-to-rxjs @angularjs_labs
Observable
Operations
Subscribe
Basic Stream
http://bit.ly/introduction-to-rxjs @angularjs_labs
- Observable
- Operations
- merge, concat, map and more!
- Observer
- onNext, onError, onCompleted
- Subscribe/Unsubscribe
Key concepts
Basic Stream
observable.subscribe(
function onNext(value){
console.log(value);
},
function onError(error){
console.log(error);
},
function onCompleted(){
console.log('Completed');
});
http://bit.ly/introduction-to-rxjs @angularjs_labs
var observer = rx.Observer.create(
function onNext(result){
console.log(result);
},
function onError(err){
console.log(err);
},
function onCompleted(){
console.log('Completed');
}
);
observable.subscribe(observer);Observer
Basic Stream
http://bit.ly/introduction-to-rxjs @angularjs_labs
var subscriber = observable.subscribe(observer);
$scope.$on("$destroy", function() {
subscriber.dispose();
});Unsubscribe
Thanks!
@angularjs_labs