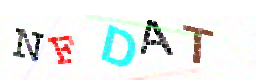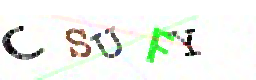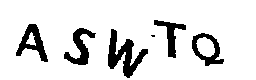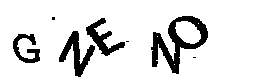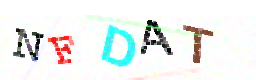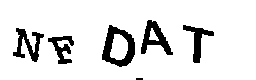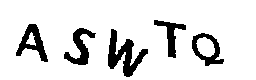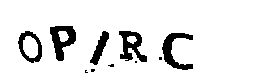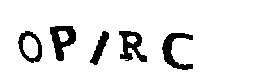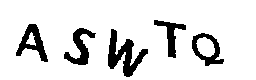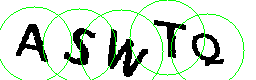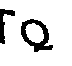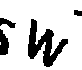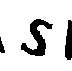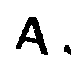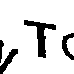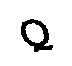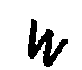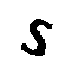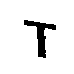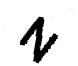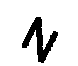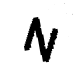Como quebrar captcha
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
Usados por alguns sites para dificultar a ação de robôs
Eu preciso preencher vários formulários de forma automática e um captcha está me atrapalhando
Python3
Tesseract
OpenCV
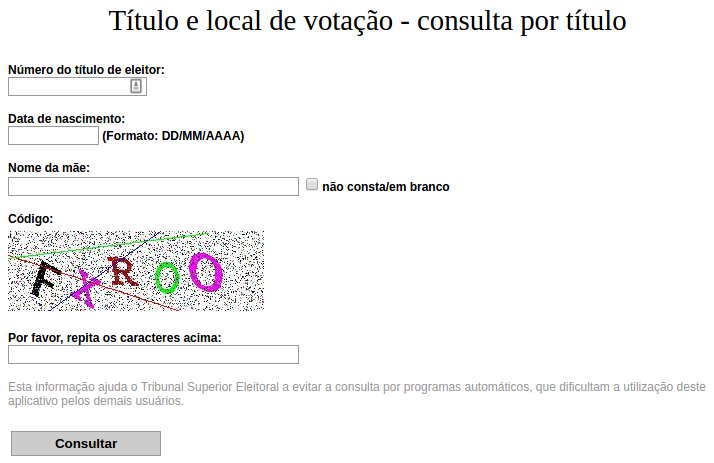
Como estudo de caso, usarei o captcha do site do Tribunal Superior Eleitoral
1º Passo: F5
2º Passo: Ruídos
img = cv.morphologyEx(img, cv.MORPH_CLOSE, np.ones((3, 3), np.uint8))3º Passo: Preto e branco
img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
img = cv.cvtColor(img, cv.COLOR_GRAY2BGR)
for i in img:
for i2 in i:
if (np.array([230, 230, 230]) >= i2).any():
i2[...] = 0
else:
i2[...] = 2554º Passo: Reconhecer as regiões
4.1º Passo: Apagar os ruídos
im2, contours, hierarchy =\
cv.findContours(
cv.cvtColor(img, cv.COLOR_BGR2GRAY), cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE
)for i in contours:
(x, y), radius = cv.minEnclosingCircle(i)
if radius <= 6:
cv.drawContours(img, [i], -1, (255, 255, 255), -1)4.2º Passo: Isolar as letras
letters = []
for i2 in contours:
(x, y), radius = cv.minEnclosingCircle(i2)
if radius > 16 and radius < 30:
center = (int(x), int(y))
radius_int = int(radius + 15)
x_min = x - radius_int
y_min = y - radius_int
if x_min < 0:
x_min = 0
if y_min < 0:
y_min = 0
letters.append((x, img[y_min : y + radius_int, x_min : x + radius_int]))
letters_out = []
if len(letters) > 0:
loop = 0
text = ''
for i in letters:
current_letter = i[1]
# Salvar para tesseraczar
cv.imwrite('letter' + str(loop) + '.png', current_letter)
# Pegar o valor ASCII da letra
new_char = rotate('letter' + str(loop) + '.png')[0]
if len(new_char) and new_char[0] != ' ':
text += new_char[0]
else:
text += '?'
loop += 1
letters_out.append((i[0], new_char[0]))
letters_out = sorted(letters_out)
letters_only = [i[1] for i in letters_out]
solution = ''.join(letters_only), title=file_name)5º Passo: Girar as letras para ler com o Tesseract e usar a resposta com mais confiança
import pyslibtesseract
tesseract_config =\
pyslibtesseract.TesseractConfig(psm=pyslibtesseract.PageSegMode.PSM_SINGLE_CHAR)
tesseract_config.add_variable('tessedit_char_whitelist', 'QWERTYUIOPASDFGHJKLZXCVBNM')
def rotate(file_name):
img = cv.imread(file_name)
rows, cols = img.shape[:2]
most_confidence = [' ', 0]
again = False
for i in range(-1, 2):
M = cv.getRotationMatrix2D((cols/2,rows/2), 10 * i, 1)
dst = cv.warpAffine(img,M,(cols,rows))
letter_height, letter_width = dst.shape[:2]
mask = np.zeros((letter_height + 2, letter_width + 2), np.uint8)
mask[:] = 0
for h in range(letter_height):
cv.floodFill(dst, mask, (letter_width - 1, h), (255, 255, 255), upDiff=(200, 200, 200))
cv.floodFill(dst, mask, (0, h), (255, 255, 255), upDiff=(200, 200, 200))
for w in range(letter_width):
cv.floodFill(dst, mask, (w, 0), (255, 255, 255), upDiff=(200, 200, 200))
cv.floodFill(dst, mask, (w, letter_height - 1), (255, 255, 255), upDiff=(200, 200, 200))
cv.imwrite(str(i) + file_name, dst)
#print(str(i) + file_name)
x = pyslibtesseract.LibTesseract.read_and_get_confidence_char(tesseract_config, str(i) + file_name)
if len(x) == 0:
continue
new_char = x[0]
if most_confidence[1] - 3 <= new_char[1] <= most_confidence[1] + 3:
again = False
else:
again = True
if new_char[0] != ' ' and most_confidence[1] < new_char[1]:
most_confidence[0] = new_char[0]
most_confidence[1] = new_char[1]
#print(new_char)
#print('--------------------------------')
if most_confidence[1] < 60 or again:
for i in range(-5, 6):
M = cv.getRotationMatrix2D((cols/2,rows/2), 10 * i, 1)
dst = cv.warpAffine(img,M,(cols,rows))
letter_height, letter_width = dst.shape[:2]
mask = np.zeros((letter_height + 2, letter_width + 2), np.uint8)
mask[:] = 0
for h in range(letter_height):
cv.floodFill(dst, mask, (letter_width - 1, h), (255, 255, 255), upDiff=(200, 200, 200))
cv.floodFill(dst, mask, (0, h), (255, 255, 255), upDiff=(200, 200, 200))
for w in range(letter_width):
cv.floodFill(dst, mask, (w, 0), (255, 255, 255), upDiff=(200, 200, 200))
cv.floodFill(dst, mask, (w, letter_height - 1), (255, 255, 255), upDiff=(200, 200, 200))
cv.imwrite(str(i) + file_name, dst)
#print(str(i) + file_name)
x = pyslibtesseract.LibTesseract.read_and_get_confidence_char(tesseract_config, str(i) + file_name)
if len(x) == 0:
continue
new_char = x[0]
if new_char[0] != ' ' and most_confidence[1] < new_char[1]:
most_confidence[0] = new_char[0]
most_confidence[1] = new_char[1]
#print(new_char)
#print('--------------------------------')
return most_confidence
-10 graus
[(' ', 1.4195556640625)]
0 graus
[('W', 54.763671875)]
+10 graus
[('N', 77.95476531982422), ('M', 70.48933410644531)]
6º Passo? Histogramar?
Há casos que seria útil histogramar, para dividir a imagem de acordo com as cores, assim separando as letras coladas
Mas isso não resolveria casos com letras coladas e das mesmas cores
Como não ajudaria lá tanto, decidi simplificar o código e não usar histograma
Após vários testes, obtive uma taxa de sucesso de uns 35%
Antes de submeter o formulário, em várias vezes da para saber se houve sucesso em decifrar o captcha ou não, pois basta verificar se reconheceu 5 letras. Se não tiver reconhecido 5 letras, nem chega a submeter o formulário, assim diminui a taxa de erros submetidos.
Logo, obteve-se sucesso no estudo de caso
Conclusão do estudo de caso
Whois do registro.br
Captcha da sepro
reCAPTCHA
Captcha do site hedgewars
Há sites (russos) que vendem serviço de quebra de captcha