spyck
framework
@brunomacabeusbr
#pylestras
autores

Macabeus
Aquino
Paolo
Oliveira

de onde?

coletar informações
Há uma abundância de informações coletáveis na Internet e no mundo real
Uma informação coletada possibilita conseguir coletar uma nova informação numa outra fonte
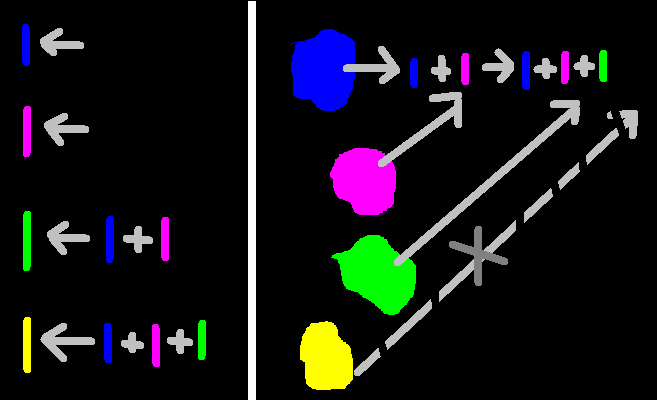
Informações dispersas não são úteis, portando, devemos agrega-las em um contexto em comum, assim organizando-as
Após organizá-las, devemos carregá-las para fazermos análises
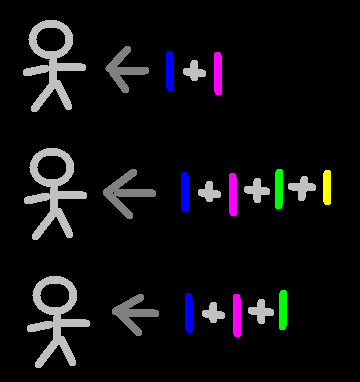
jargão
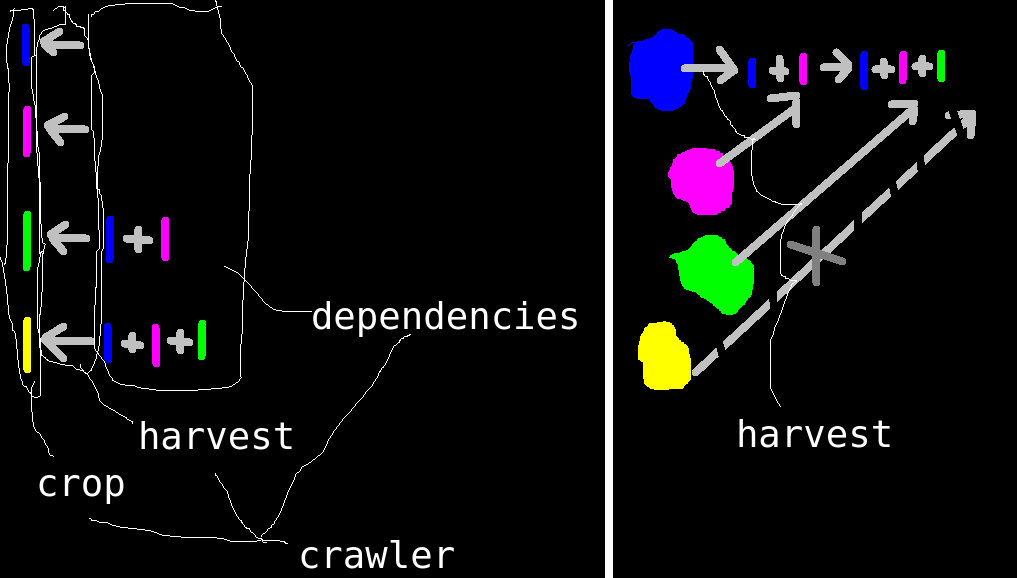
O coletor de informação é chamado de crawler. A execução é chamada de harvest. Para colhermos, pode ser que precisemos de dados prévios, chamados de dependencies. Cada crawler tem seu crop possível de se conseguir após a colheita. Cada crawler trabalha em um ou mais entity diferentes, para onde contextualizará e armazenará as informações coletadas.
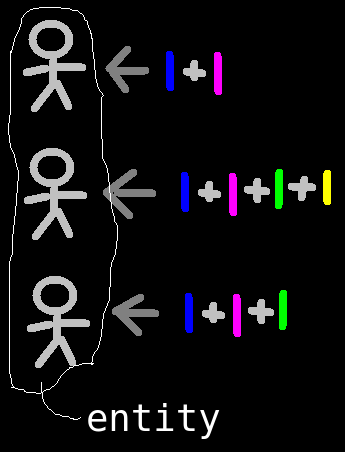
em síntese...
então... podemos criar um framework...
que facilitará a criação e integração de diversos crawlers!
unem-se através do crop e dependencies
podemos automatizar o harvest
cada fonte é funciona independentemente
exemplos de uso
Antes de contratarmos um funcionário, poderemos fazer uma busca no histórico dele
Podemos fazer uma análises de preços e produtos comprados por um funcionário de uma empresa, para sabermos se ele está favorecendo familiares
implementação
crawler
Cada crawler é independente um do outro, porém, todos fazem algumas tarefas parecidas, tais como atualizar suas tabelas no banco de dados e recolher as dependências do banco
Então, criei uma classe com métodos abstratos para servir de base para todos os crawlers, chamada de Crawler
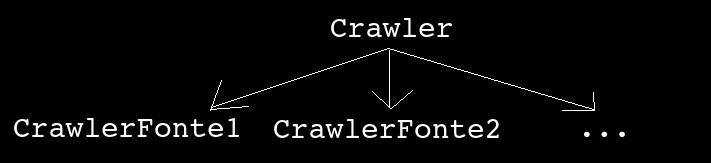
Todos os crawlers ficam na pasta /crawler e são herdeiros de Crawler
import os
import importlib
my_path = os.path.dirname(__file__)
for i in os.listdir(my_path):
if not os.path.isfile(os.path.join(my_path, i)):
continue
py_name = os.path.splitext(i)[0]
importlib.import_module('crawler.' + py_name)Então, podemos carrega-los automaticamente
Carregar crawlers
e torna-lo acessível
for cls in Crawler.__subclasses__(): # lista os crawlers
setattr(self, 'crawler_' + cls.name(), cls())
# criará métodos com nomes tais como "crawler_foo"
# que se referenciará para o objeto da classe CrawlerFoo# Retorna uma string com o nome do crawler
def name(): ...
# Retorna uma tupla contendo os nomes das dependências
def dependencies(): ...
# Retorna uma tupla contendo os nomes dos dados colhíveis
def crop(): ...
# Retorna uma tupla contendo as primitives requeridas
def entity_required(): ...
# Executa a colheita
def harvest(cls): ...Alguns métodos abstratos de Crawler
Os parâmetros do método harvest variam de crawler para crawler, conforme o funcionamento dele
Exemplos
# Não requer primitive, portando, não tem o parâmetro dependencie
def harvest(cls): ...
# Requer uma entity do tipo person
# desse modo, recolherá as dependências dela e a editará
def harvest(cls, entity_person=None, dependencies=None): ...
# Requer uma entity do tipo person ou então do tipo firm
# ou seja, o crawler pode tanto editar uma entity firm como person
def harvest(cls, entity_person=None, primitive_firm=None, dependencies=None): ...
# Requer uma entity do person, ou então
# podemos fornecer os parâmetros specific_name
def harvest(cls, entity_person=None, dependencies=None, specific_name=None): ...Parâmetros de harvest
A criação de novos crawlers (infelizmente) ficou complexa, e desejo facilitar a criação
Felizmente, todos os crawlers seguem um padrão específico nas implementações dos métodos (exceto o harvest)
Então, podemos usar um XML que gerará o esqueleto de um crawler
Criação de novos crawlers com XML
import ...
class CrawlerFazendaReceita(Crawler):
def create_my_table(self):
self.db.execute(
'CREATE TABLE IF NOT EXISTS %s('
'entity_person_id INTEGER,'
'death_year INTEGER'
');' % self.name())
@staticmethod
def name():
return 'fazenda_receita'
@staticmethod
def dependencies():
return 'cpf', 'birthday_year',
@staticmethod
def crop():
return 'name', 'death_year',
@staticmethod
def entity_required():
return 'entity_person',
@classmethod
def harvest(cls, entity_person=None,
dependencies=None,
specific_siteid=None):
...<crawler>
<primitive_required>
<entity type_requirement="harvest">
person
</entity>
</primitive_required>
<database>
<table_main>
<column>
<name>death_year</name>
<type>INTEGER</type>
</column>
</table_main>
</database>
<dependencies>
<route>
<dependence>cpf</dependence>
<dependence>birthday_year</dependence>
</route>
</dependencies>
<crop>
<info>name</info>
<info>death_year</info>
</crop>
<harvest>
<param_additional>
specific_siteid
</param_additional>
</harvest>
</crawler>Formas de implementar o harvest
Ele pode ser implementado para colher dados de qualquer fonte, como por meio da Internet, no disco rígido, no mundo real a partir de sensores...
Exemplo para colher dados numa página da Internet
# usando selenium + phantomjs
from selenium import webdriver
phantom = webdriver.PhantomJS()
phantom.get('http://pudim.com.br/')
info = phantom.find_element_by_tag_name('a').text
# o mesmo que o acima, mas usando requests + regexp
import requests
import re
r = requests.get('http://pudim.com.br/')
regexp = re.compile('<a.*?>(.*)</a>')
info = regexp.search(r.text).group(1)
# salvar info no banco
cls.db.update_entity_row({'info': info})implementação
entity
Entities são usadas para agregar informações sobre um contexto em comum
Um crawler pode requerer uma entity por três razões:
- escrever um novo elemento de entity
- editar um já existente
- se referenciar a algum
<entity>
<column>
<name>cnpj</name>
<type>TEXT</type>
</column>
<column>
<name>razao_social</name>
<type>TEXT</type>
</column>
<column>
<name>nome_fantasia</name>
<type>TEXT</type>
</column>
<column>
<name>porte_empresa</name>
<type>TEXT</type>
</column>
<column>
<name>administration</name>
<type>TEXT</type>
</column>
</entity>Novas entities podem ser criadas a medida que for necessário e, tal como os crawlers, são através de XML
Códigos
Traduzir o XML para tabelas
import xml.etree.ElementTree as ET
for current_xml in os.listdir(path_spyck + '/entities/'):
xml_root = ET.parse('entities/' + current_xml).getroot() # carregar xml
columns = [ # criar array de tuplas com (<nome da coluna>, <tipo da coluna>)
(current_xml.find('name').text, current_xml.find('type').text)
for current_xml in xml_root.findall('column')
]
entity_name = current_xml[:-4] # nome da primitive será o mesmo nome do xml
self.execute( # criar sql e executa-la, para gerar a tabela da primitive
'CREATE TABLE IF NOT EXISTS {}('
'id INTEGER PRIMARY KEY AUTOINCREMENT,'
'{}'
');'.format('entity_' + entity_name,
','.join([i[0] + ' ' + i[1] for i in columns]))
)
self.execute( # criar sql e executa-la, para gerar a tabela de crawlers executados
'CREATE TABLE IF NOT EXISTS {}('
'id INTEGER,'
'FOREIGN KEY(id) REFERENCES {}(id)'
');'.format('entity_' + primitive_name + '_crawler',
'entity_' + primitive_name)
)Códigos
implementação
banco de dados
Novas entity e crawlers vão sendo criadas dias após dia, e eles precisam salvar dados no banco
Logo, o banco de dados precisa ser dinâmico - novas tabelas vão sendo criadas
Cada elemento de uma entity tem um id. Esse id é usado como chave estrangeira para ligar às tabelas dos crawlers
<database>
<table_main>
<column>
<name>cia</name>
<type>INTEGER</type>
</column>
</table_main>
<table_secondary>
<name>records_school</name>
<column>
<name>timestamp</name>
<type>TEXT</type>
</column>
<column>
<name>school</name>
<type primitive="">firm</type>
</column>
<column>
<name>course</name>
<type>TEXT</type>
</column>
<column>
<name>turn</name>
<type>TEXT</type>
</column>
</table_secondary>
</database>class CrawlerEtufor(Crawler):
def create_my_table(self):
self.db.execute(
'CREATE TABLE IF NOT EXISTS %s('
'entity_person_id INTEGER,'
'cia INTEGER'
');' % self.name()
)
self.db.execute(
'CREATE TABLE IF NOT EXISTS %s('
'entity_person_id INTEGER,'
'timestamp TEXT,'
'entity_firm_id_school INTEGER,'
'course TEXT,'
'turn TEXT,'
'FOREIGN KEY(entity_firm_id_school)'
' REFERENCES entity_firm(id)'
');' % (self.name() + '_records_school')
)
Nos crawlers definimos que tabelas eles criarão
fieldnames = self.select_column_and_value( # esse método executa uma query
# e retorna dicionário sendo a chave
# o nome da coluna e o valor o conteúdo dela
'SELECT * FROM entity_{} '.format(entity_name) +
' '.join([
'INNER JOIN {} ON {}.entity_{}_id == {}'.format(
i.name(), i.name(), entity_name, entity_id
)
for i in crawler_list_success_cls
]) +
' WHERE entity_{}.id == {}'.format(entity_name, entity_id)
)Código para recolher do banco os dados de uma entity e nas tabelas principais do crawler
implementação
dependências
A primeira ideia em mente para mim foi fazer um grafo de dependências... e assim foi feito
Resultou em 200 linhas, muito pesado e péssimo de se manter
Depois, decidi simplificar tudo usando um dicionário. Fico bem mais leve e precisando só de 8 linhas
from collections import defaultdict
dict_info_to_crawlers = defaultdict(list)
# a chave de dict_info_to_crawlers será o nome da info e
# o value uma lista com os crawlers em que pode-se consegui-la
[
dict_info_to_crawlers[current_crop].append(cls)
for cls in Crawler.__subclasses__()
if cls.have_dependencies() is True
for current_crop in cls.crop()
]
Recolher dependências
Um decorator é adicionado de forma implícita ao método harvest
Se for fornecido um id de entity, automaticamente puxará as dependências do banco e as colocarão no parâmetro dependencies
class GetDependencies:
def __init__(self, f):
self.f = f
...
def __call__(self, *args, **kwargs):
... # Recolhe as dependências e salvar em dict_dependencies
# Colher
self.harvest(*args, dependencies=dict_dependencies, **kwargs)
...
for i in Crawler.__subclasses__():
if i.have_dependencies():
i.harvest = GetDependencies(i) # adicionar o decorator
Decorator
class CrawlerEtufor(Crawler):
...
@staticmethod
def dependencies():
return 'name', 'birthday_month', 'birthday_year',
...
@classmethod
def harvest(cls, entity_person=None, dependencies=None):
phantom = webdriver.PhantomJS()
phantom.get('http://www.etufor.ce.gov.br/index_novo.asp?pagina=sit_carteira2007.asp')
form_consultation = phantom.find_element_by_name('Nome')
form_consultation.send_keys(
dependencies['name'] + Keys.TAB +
'{:02}'.format(dependencies['birthday_month']) +
'{:02}'.format(dependencies['birthday_year'])
)
phantom.find_element_by_name('btnpesq').click()
...Nos crawlers, precisamos apenas especificar os dados dependentes
O parâmetro dependencies receberá o dicionário com os valores providos do decorator
futuro
Simplificar o código e facilitar o desenvolvimento do Spyck
Criar interface gráfica para ser acessível para leigos, tanto para escrever novos crawlers como para usar
Implementar análises e inferências a respeito dos dados colhidos