Foundation Models
for Decision Making
MIT 6.4210/6.4212 Lec 22
Boyuan Chen
Slide: https://slides.com/d/EyfmqBY/live

Agenda today
- LLM & Embodied AI
- Challenges and Opportunities
- Vision Foundation Models
Task Planning with LLM
Connect unstructured world with structured algorithms

MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
What human wants:
How robot algorithms work:

Segmentation, Point Cloud -> Grasp
Finite State Machine
....
These are all very structured!
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Question: how can we connect unstructured with structured
Task: clean up the spilled coke
- Set the coke can into an upright position
- Find some napkins
- Pick up napkins
- Wipe the spilled coke with napkins
- Wipe the coke can
- Throw away the used napkins
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Humans: Language as tasks
Language as plans!

MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Can we use human priors & knowledges
It turns out humans activities on the internet produces a massive amount of knowledge in the form of text that are really useful!

MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Background:
Large Language Models


Text

Highlight
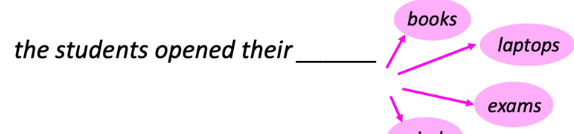
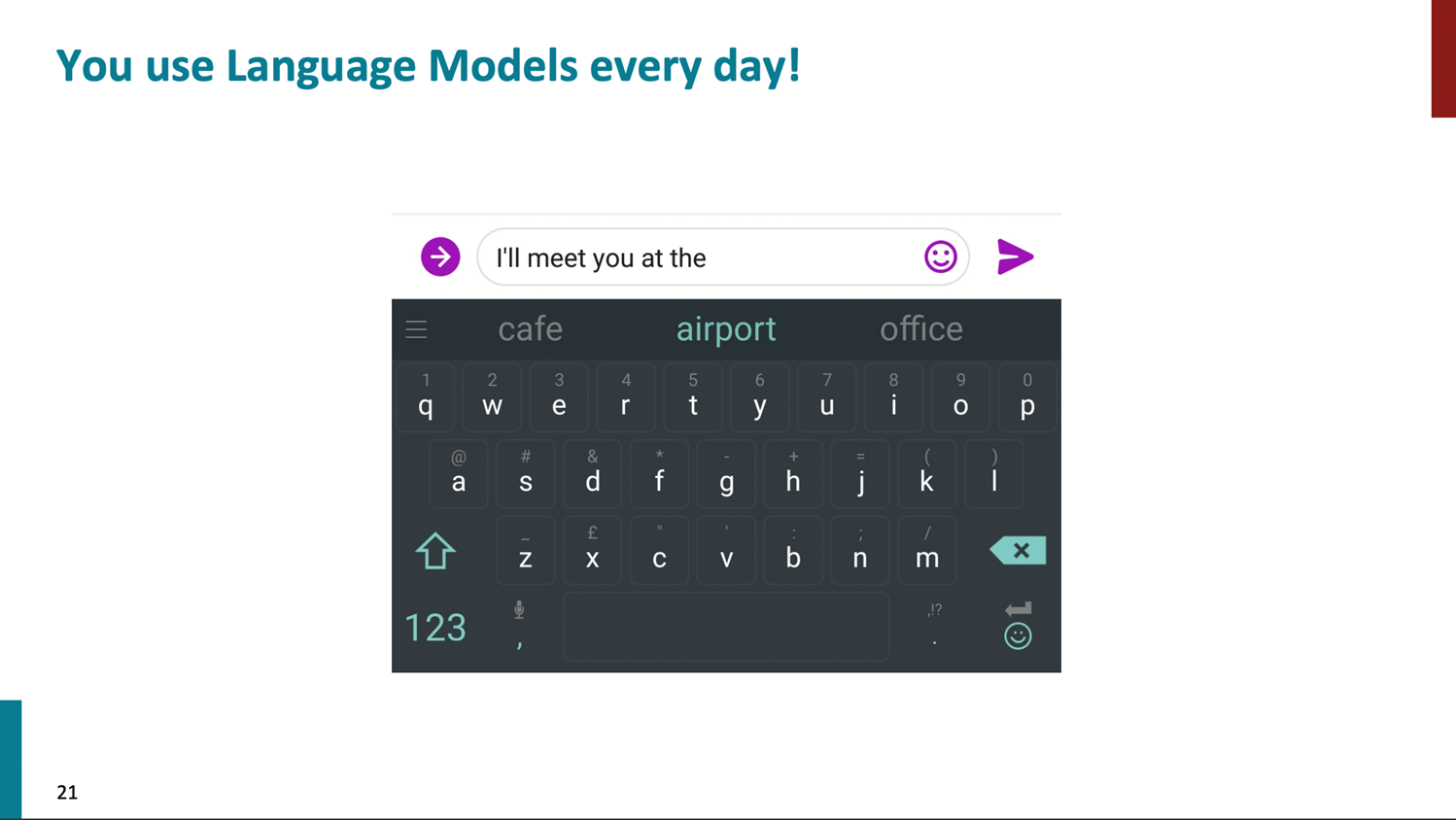
- Given a fixed list of options, can evaluate likelihood with LM
- Given all vocabularies, can sample with likelihood to generate
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Text
Large Language Models
can complete essays

Large Language Models
can complete essays

GPT 3 writing MIT 24.09 Essay
Large Language Models
can code!
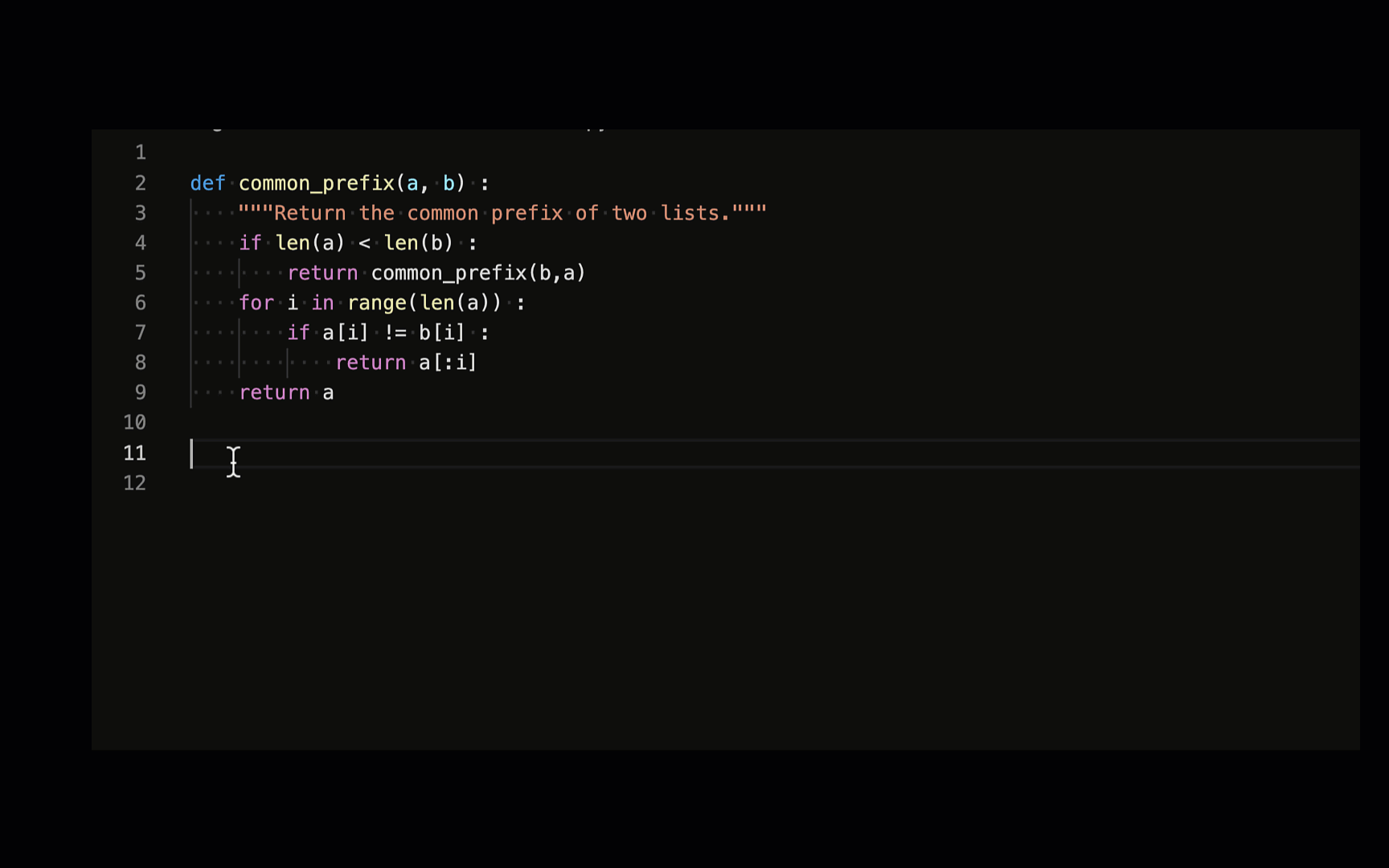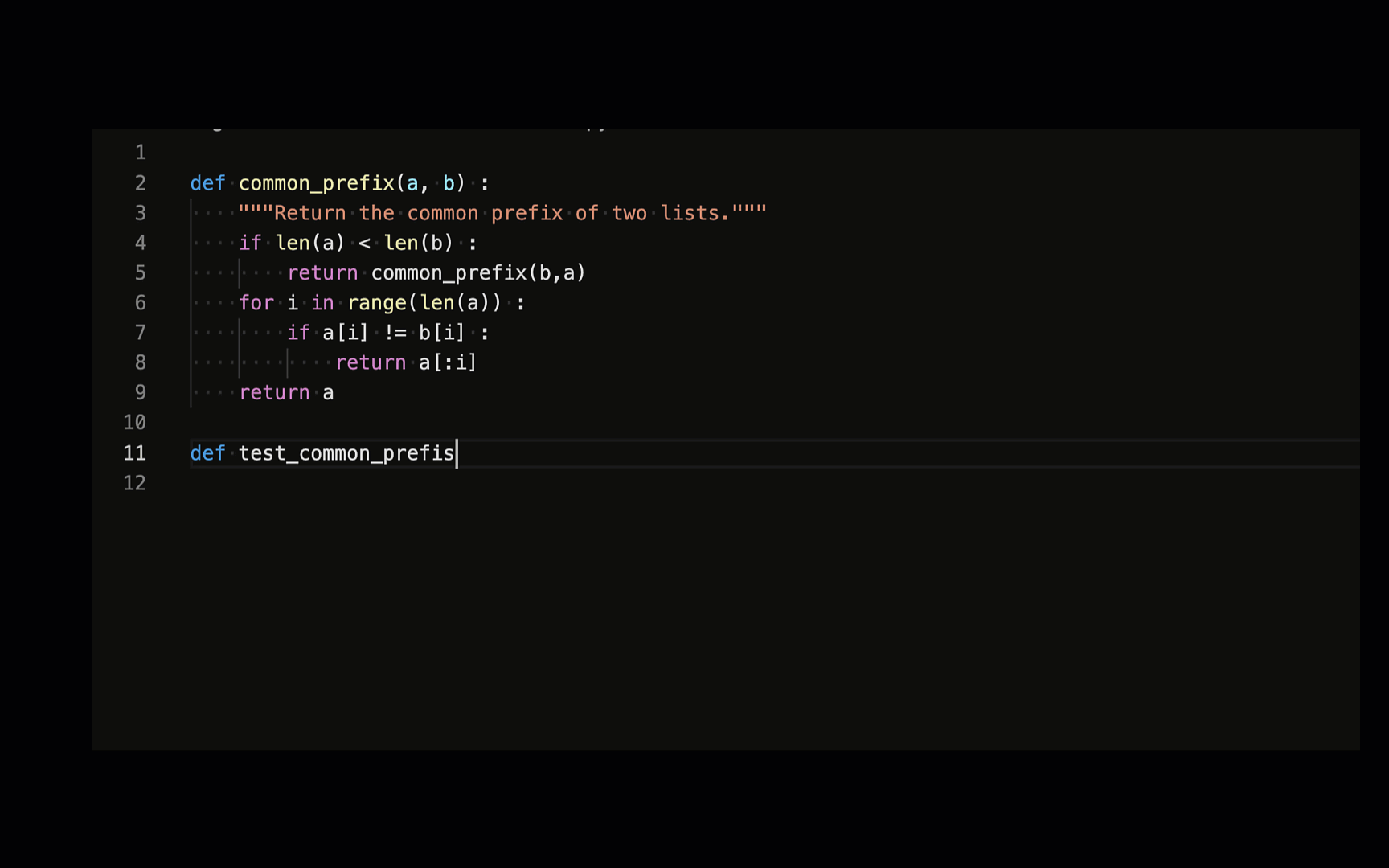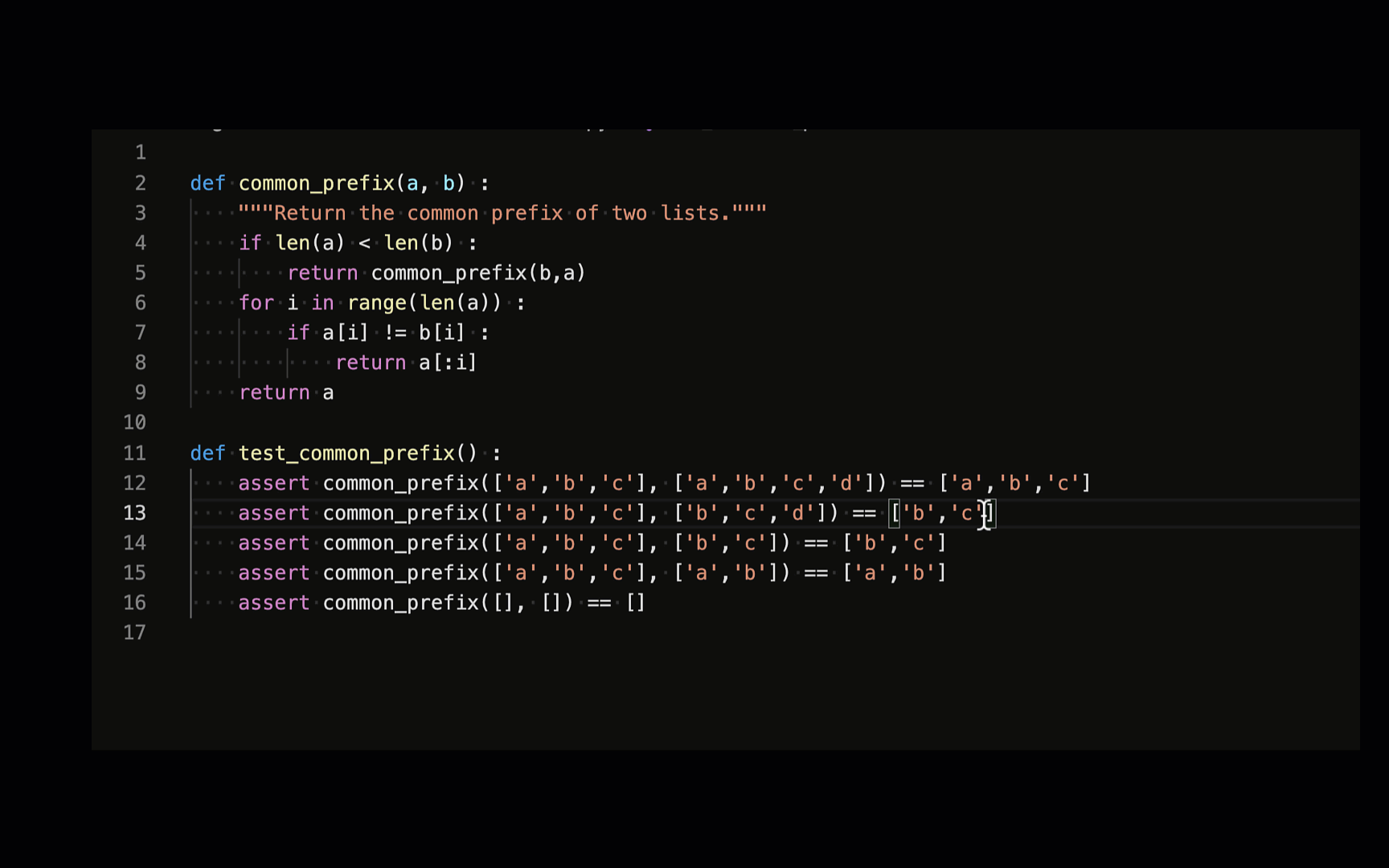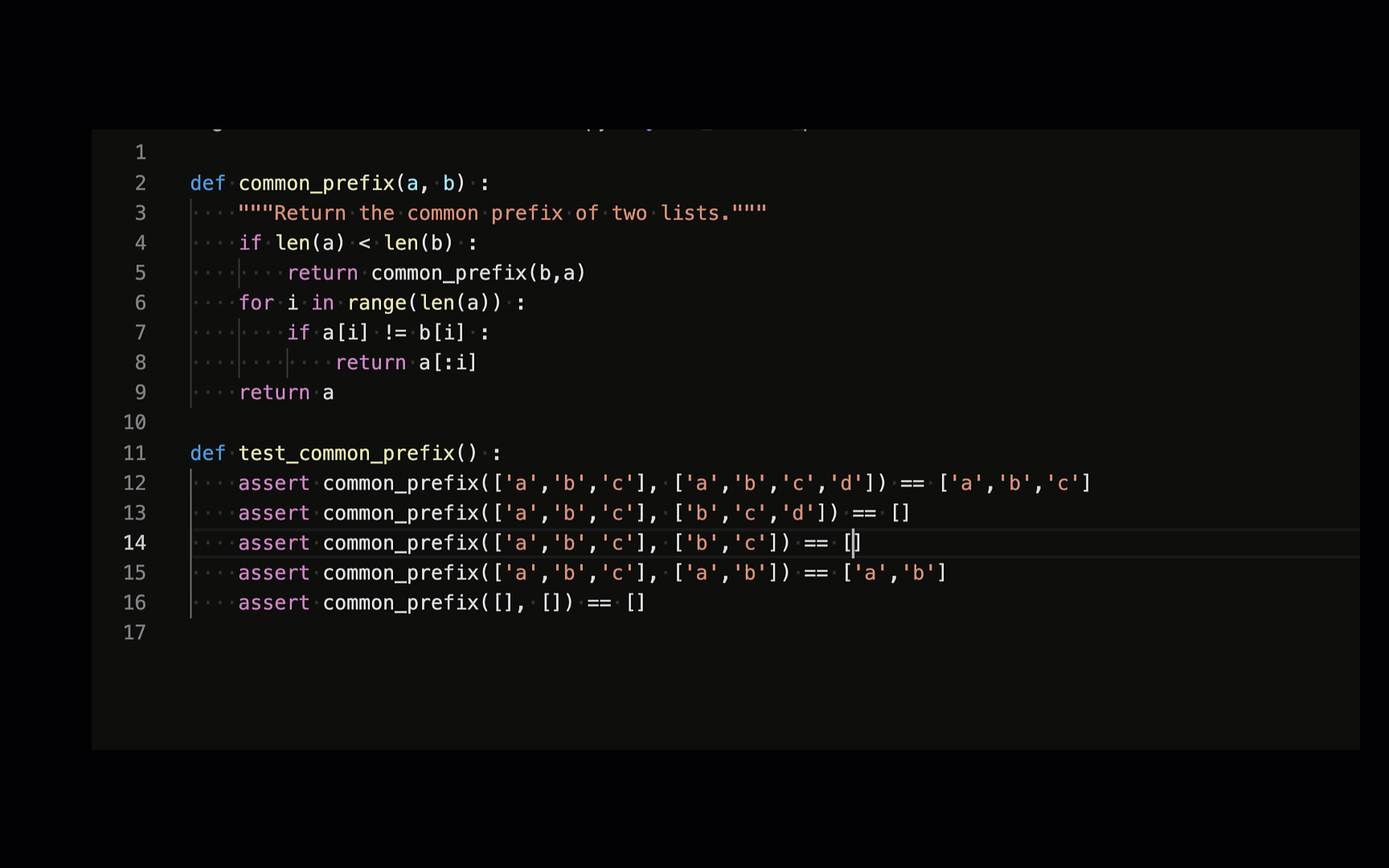
This is really powerful
for planning!
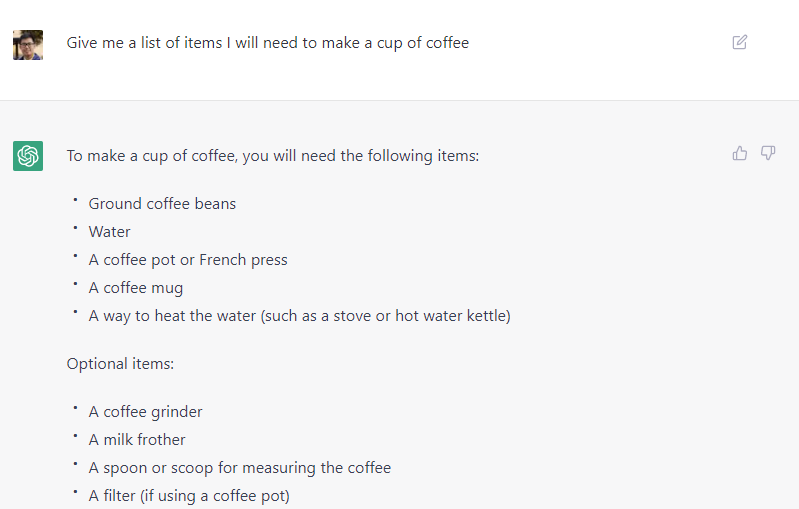
This is really powerful
for planning!
LLMs for robotics
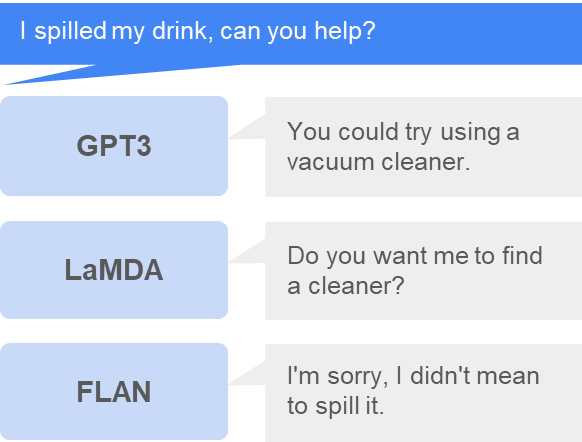
Problem:
Our robots can only do a fixed number of commands and need the problem broken down in actionable steps. This is not what LLMs have seen.
We need to get LLMs to speak “robot language”!
Ingredient 1
- Bind each executable skill to some text options
- Have a list of text options for LM to choose from
- Given instruction, choose the most likely one
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
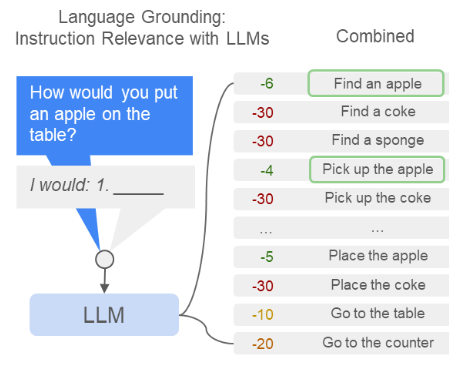
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Ingredient 2
- Prompt LLM to output in a more structured way
- Parse the structure output
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Few-shot prompting of Large Language Models

LLMs can copy the logic and extrapolate it!
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Prompt Large Language Models to do structured planning

MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website

Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
LLMs for robotics
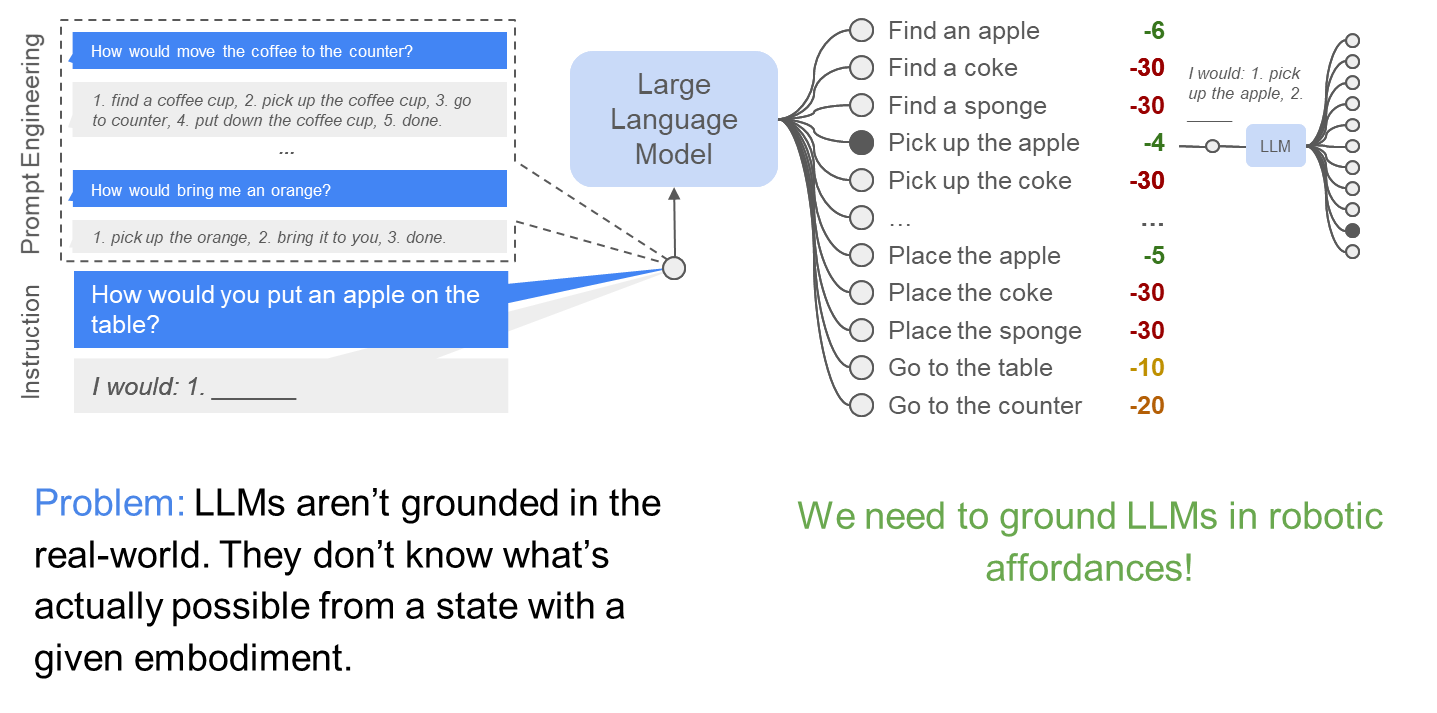
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022

Reinforcement learning already provides task-based affordances.
They are encoded in the value function!
[Value Function Spaces, Shah, Xu, Lu, Xiao, Toshev, Levine, Ichter, ICLR 2022]
Robotic affordances
Combine LLM and Affordance
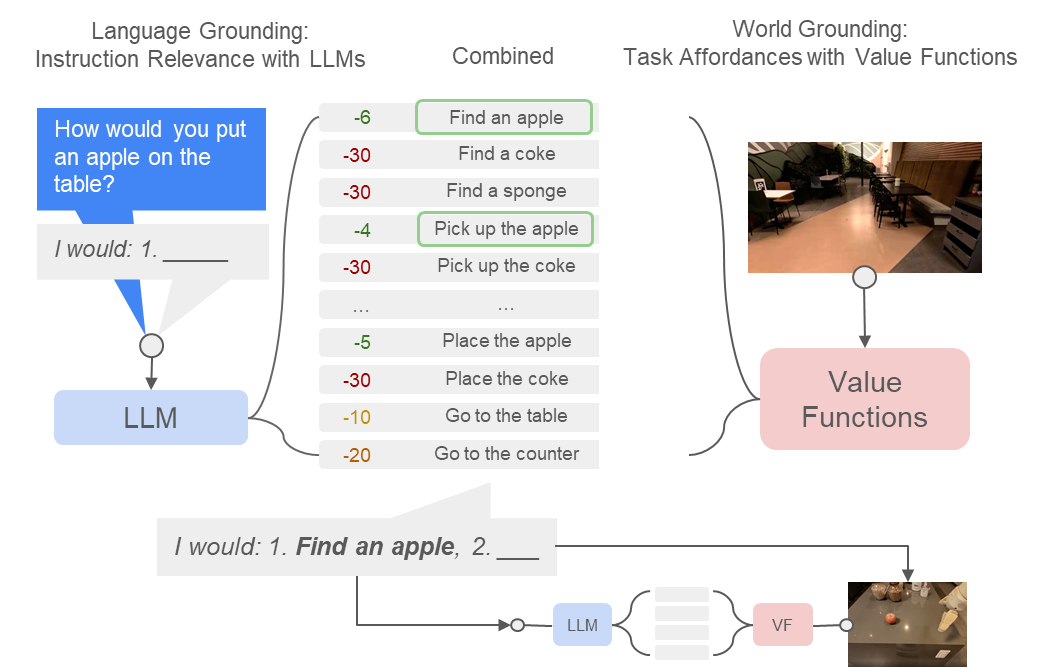
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
LLM x Affordance

Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
SayCan on robots
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances, Ahn et al. , 2022
- Language Models as Zero-Shot Planners:
Extracting Actionable Knowledge for Embodied Agents - Inner Monologue: Embodied Reasoning through Planning with Language Models
- PaLM-E: An Embodied Multimodal Language Model
- Chain-of-thought prompting elicits reasoning in large language models
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Extended readings in
LLM + Planning
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
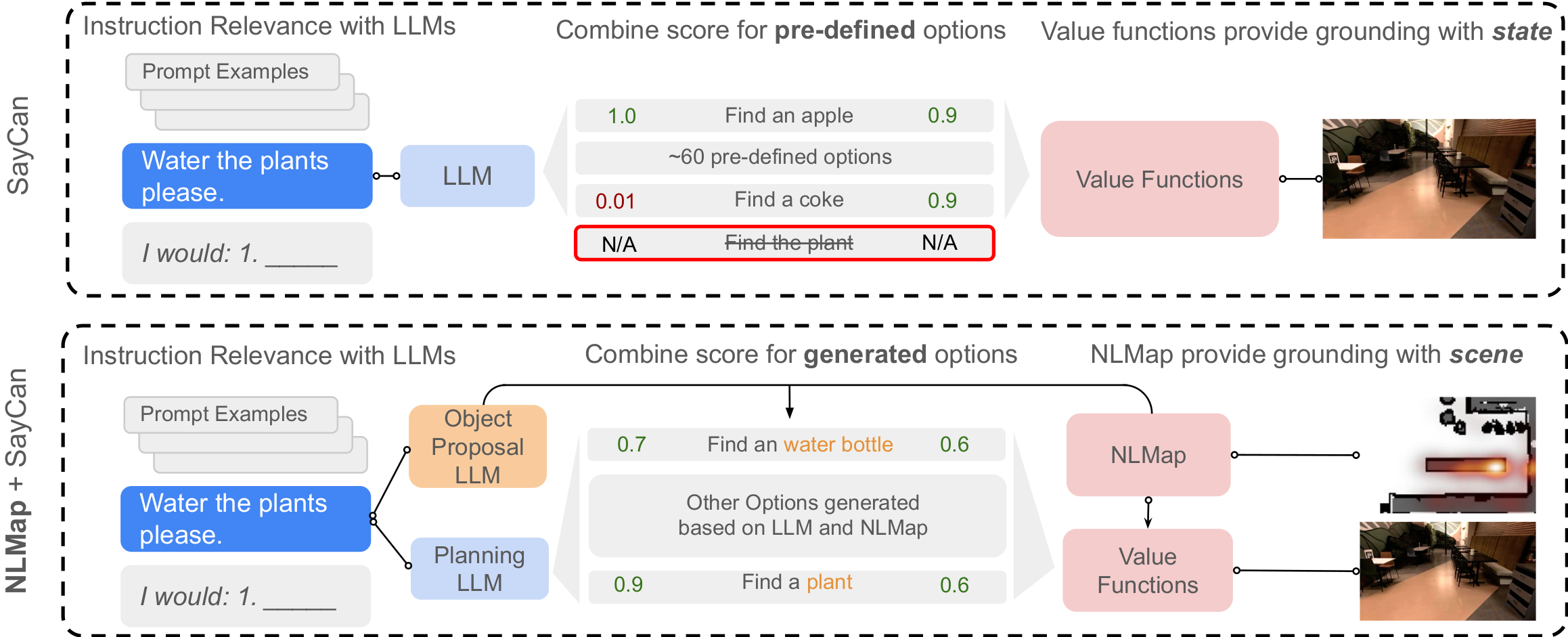
Vanilla SayCan has issues...
- Object lists are hard-coded
- Object locations are hard-coded
- Assume all objects are available in the scene
- A small, finite list of executable options
- No perception
- Only ~30 objects
Vanilla Saycan is not grounded by scene!
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
NLMap: Open-vocabulary Queryable Scene Representations for Real World Planning
Open-vocabulary Queryable Scene Representations for Real World Planning, Chen et al. 2022
Open Vocabulary Detection
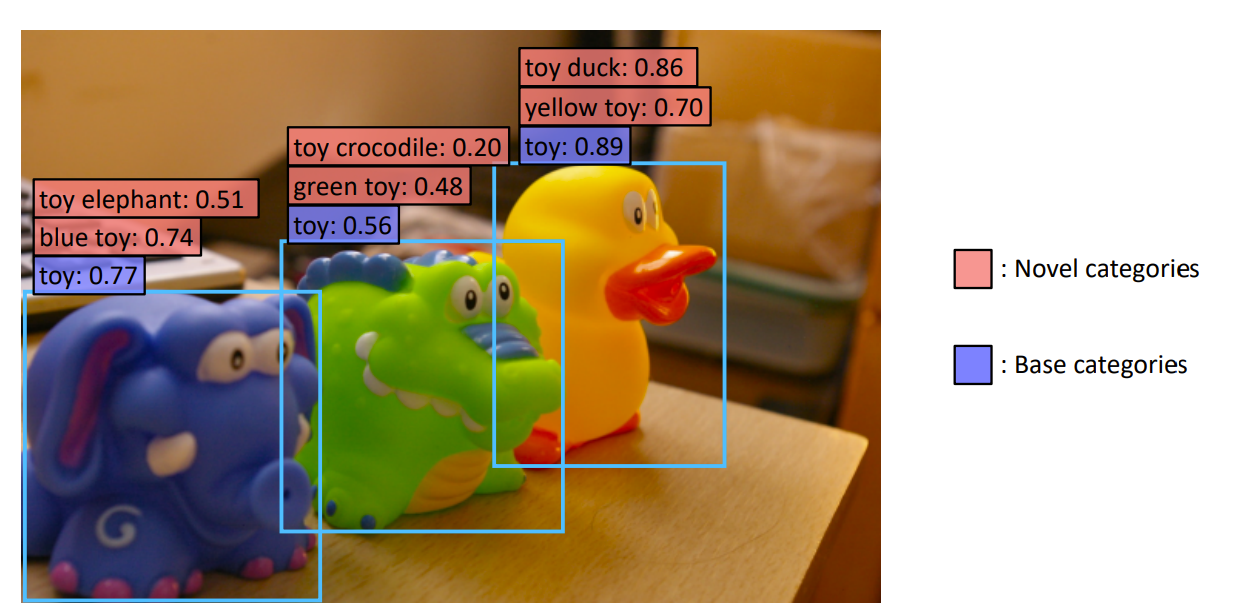
Open-vocabulary object detection via vision and language knowledge, Gu et al. 2021

Ground planning with vision
Open-vocabulary Queryable Scene Representations for Real World Planning, Chen et al. 2022
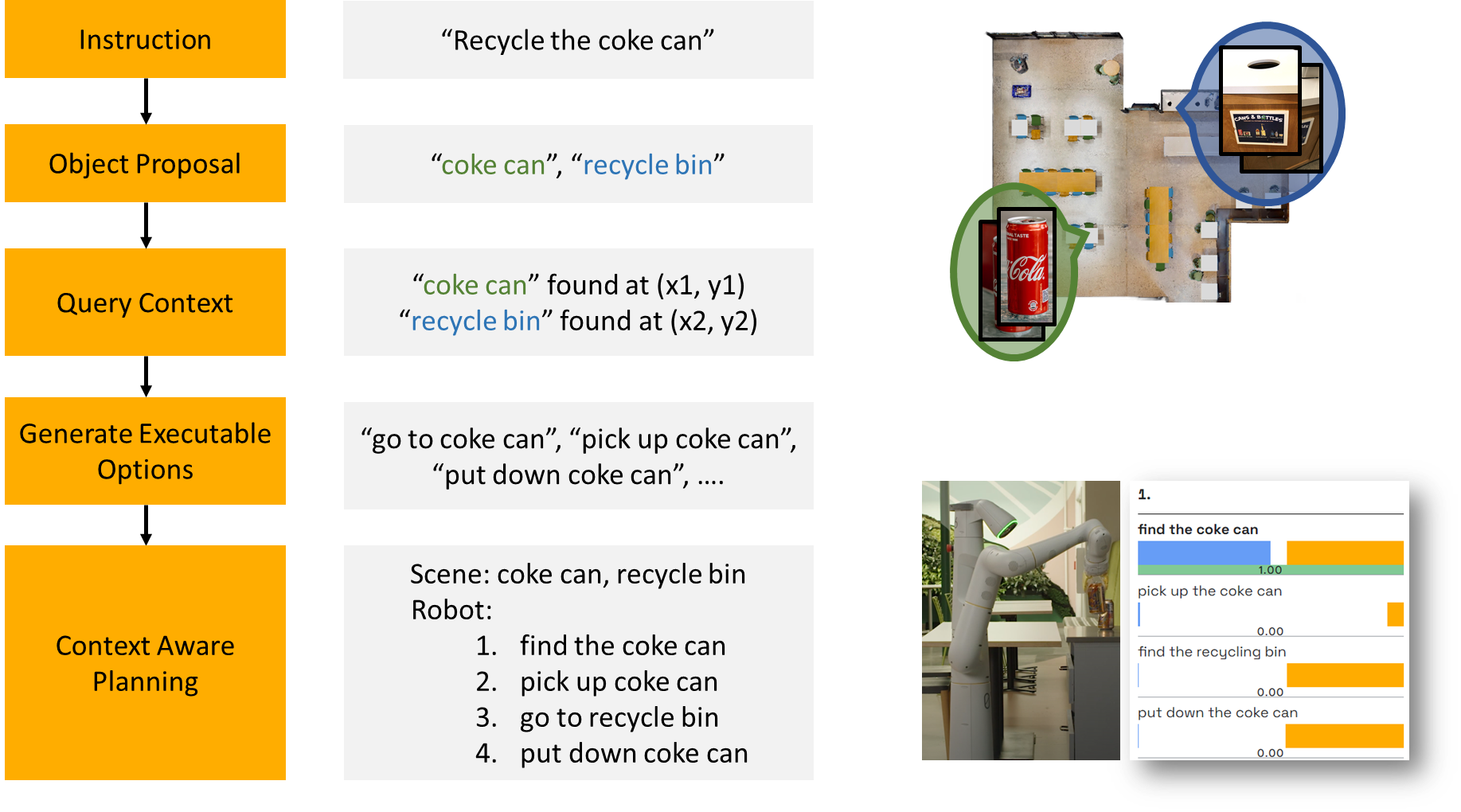
Ground planning with scene
Open-vocabulary Queryable Scene Representations for Real World Planning, Chen et al. 2022
Propose options instead of choose from a fixed list!
Open-vocabulary Queryable Scene Representations for Real World Planning, Chen et al. 2022
NLMap + SayCan
Open-vocabulary Queryable Scene Representations for Real World Planning, Chen et al. 2022
Extended readings in
LLM + Vision + Robotics
- LM-Nav: "Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action"
- NLMap: Open-vocabulary Queryable Scene Representations for Real World Planning
- VLMaps: "Visual Language Maps for Robot Navigation"
- Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language"
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Now LLM can use maps/vision.
What about using other hardware/algorithms?
Tool use

Toolformer: Language Models Can Teach Themselves to Use Tools, Schick et al. 2023
Ask LLM to coordinate other tools by writing code!
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Recall that LLM can code
Prompt LLM with APIs and ask it to write code as a response
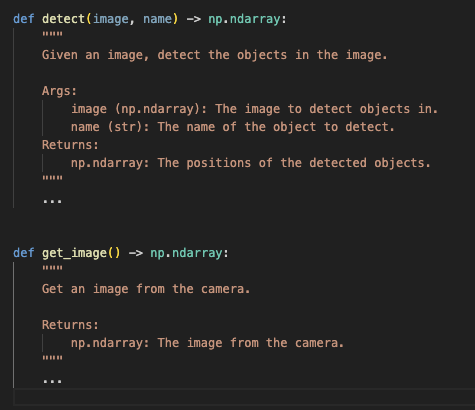

Human: help me put the apple on the book
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Robot:
img = get_image() book_pos = detect(img, "book")[0] apple_pos = detect(img, "apple")[0] pick(apple_pos) place(book_pos + np.array([0, 0, 0.1]))

Code as Policie: Language Model Programs for Embodied Control, Liang et al. , 2022
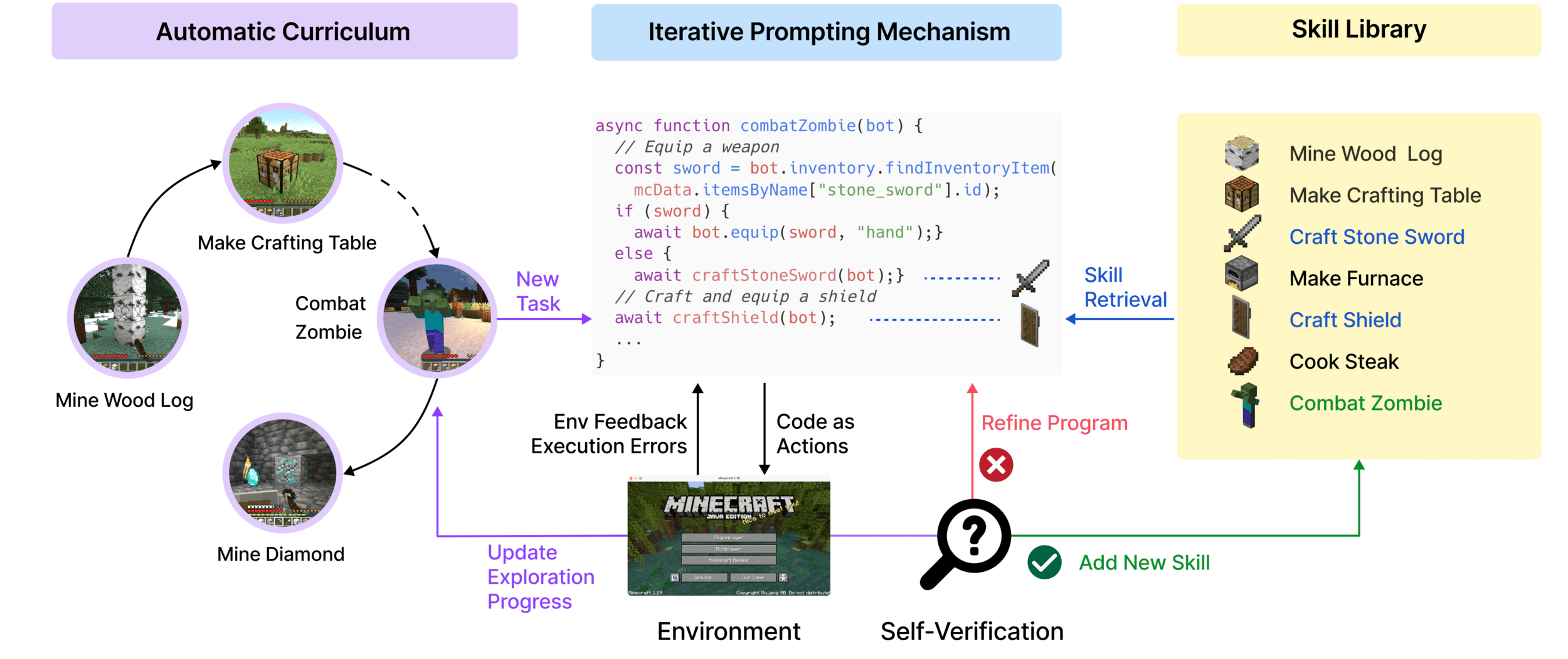
Create complex open-world agents with API of basic skills
Voyager: An Open-Ended Embodied Agent with Large Language Models, Wang et al. , 2023
Create complex open-world agents with API of basic skills
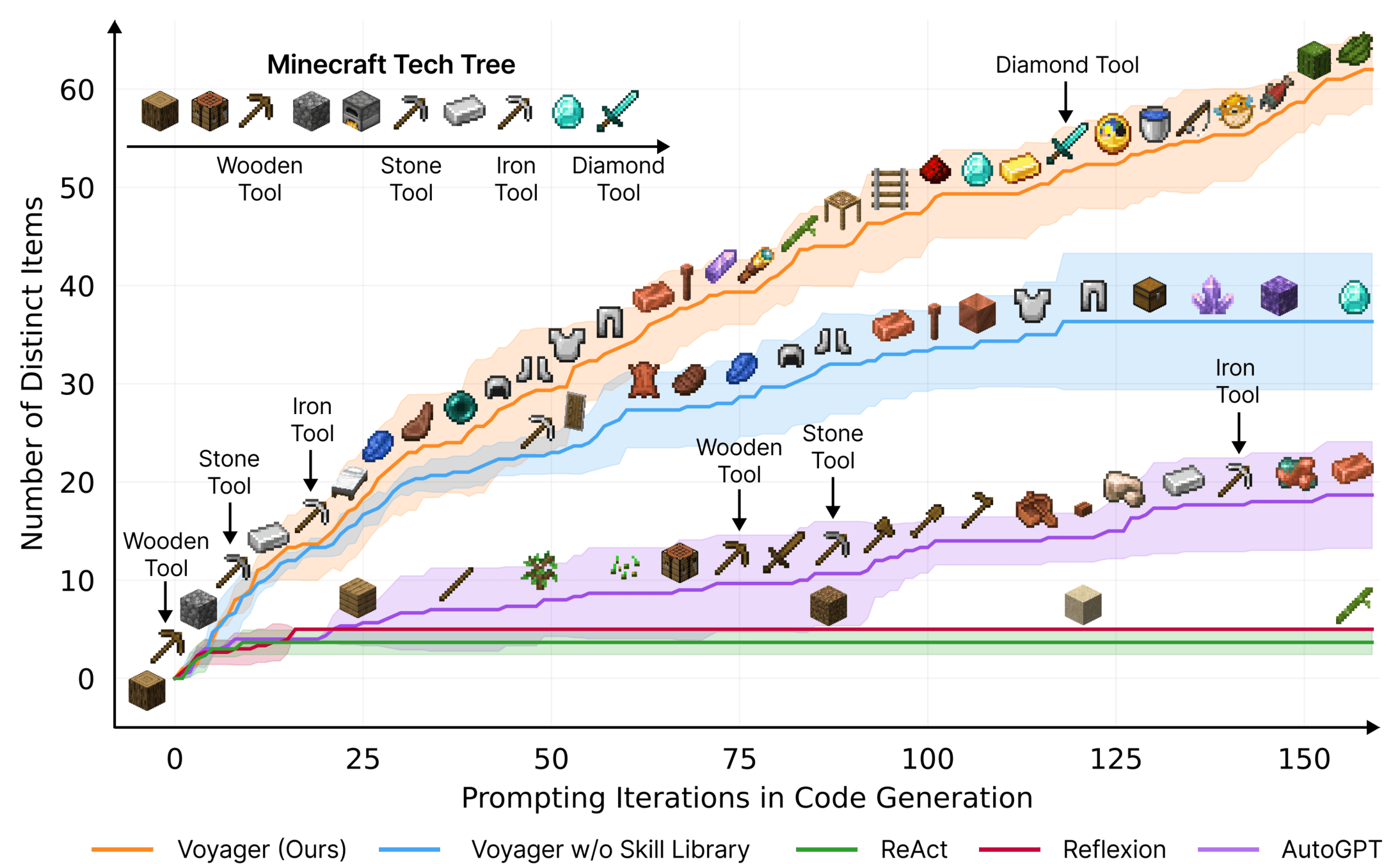
Voyager: An Open-Ended Embodied Agent with Large Language Models, Wang et al. , 2023
Challenges and Opportunities
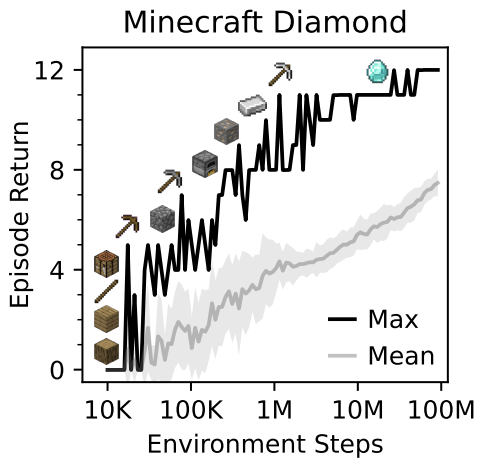
Is scaling all you need?

MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Why is LLM so useful for robotics?
- LLM parses unstructured tasks to structured programes
- LLM absorbs common sense knowledge
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Why is LLM so useful for robotics?
- LLM parses unstructured tasks to structured programes
- LLM absorbs common sense knowledge
How sufficient is this?
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
What did LLM absorb
- Wikipedia
- Book
- Website
- Blog
- Code
- ....
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Text is not the whole world!
- Humans do so many tasks with vision
- Human also do so many tasks with physical body
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Can we replicate success of LLM in robotics?
- LLM is good only because they are pre-trained on Internet scale of text data
- Is that the case for other domains?
- Vision? Action?
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Multi Modal LLM
Vision
Text
Action
Vision
Text
Action
Inputs
Outputs
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Vision? A case study
Vision
Text
Text
Inputs
Outputs
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Vision? A case study

The campus of the Massachusetts Institute of Technology in Cambridge will soon be home to a new college of computer science, which will get its own building
GPT-4V came almost a year after ChatGPT....
VLMs are pretrained on image-text pairs like these:
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Vision? A case study
- Paired image-text data is still widely available on the internet, though dirty and not at a scale similar to text data alone
- Distribution shift between pre-training and inference... Train on caption but test on QA & other fancy things
- This is unlike LLM!
Vision
Text
Text
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Vision? A case study
- How to solve this issue?
- Extensive instruction tuning (w/ human annotation) after pre-training
- Connect image encoder with pre-trained LLM so it has language knowledge already
Vision
Text
Text
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Vision? A case study
- How to solve this issue?
- Extensive instruction tuning (w/ human annotation) after pre-training
- Connect image encoder with pre-trained LLM so it has language knowledge already
Vision
Text
Text
works because output is text, so we also have generalization in output behavior
Pre-trained so we have some
generalization in input behavior
What about action?
Vision
Text
Vision
Text
Action
Inputs
Outputs
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
What about action?
- No internet scale data of joint angles, trajectories in states
- Even less paired action-text data
Vision
Text
Action
Pre-trained so we have some generalization in input behavior
Output behavior is unclear. Hard to get data to have a foundation model that generates actions
What about action?
- Let's try our best collecting enough data
- The promise: the input encoders already provides part of the generalization, so we need less action data for whole problem
- Valuable scientific explorations on this:
- Robot Transformer 1, RT2 from Google
- Large Behavior Model from TRI
- Some in academia
RT-1: Robotics Transformer for real-world control at scale, Brohan et al., 2022
RT2: RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control, Brohan et al., 2023
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion, Chi et al. 2023
What about action?
Teaching Robots New Behaviors, TRI 2023
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion, Chi et al. 2023
BTW don't miss the talk
Thursday (Dec 7th) 4 pm at 32-D463
Ben Burchfield & Siyuan Feng from TRI will be giving a talk, "Towards Large Behavior Models: Versatile and Dexterous Robots via Supervised Learning."
Is this enough?
- Each operator still needs an expensive robot
- Limited environment / task diversity
- This approach shows some generalization in individual tasks but not across tasks yet
- For a robot GPT we will need way more, maybe internet scale data containing actions!
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Alternative opportunities
- Let admit we have no action data on the internet, at least action data in lagrangian states
- But... We have other ways of extracting action data, with foundation models
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Generate simulation w/ LLM

GenSim: Generating Robotic Simulation Tasks via Large Language Models, Wang et al., 2023
Generate simulation w/ LLM
RoboGen: Towards Unleashing Infinite Data for Automated Robot Learning via Generative Simulation Wang et al., 2023

Generate simulation assets
One-2-3-45: Any Single Image to 3D Mesh in 45 Seconds without Per-Shape Optimization, Liu et al., 2023

Annotate reward for RL
Language to Rewards for Robotic Skill Synthesis, Yu et al., 2023
Eureka: Human-Level Reward Design via Coding Large Language Models, Ma et al., 2023
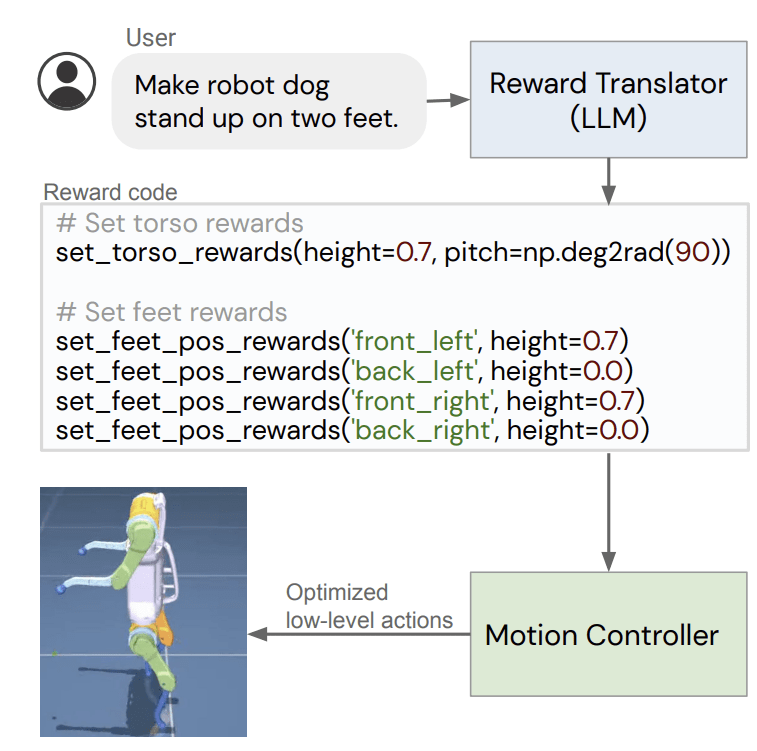

Annotate reward for RL
Vision-Language Models as Success Detectors, Du et al., 2023
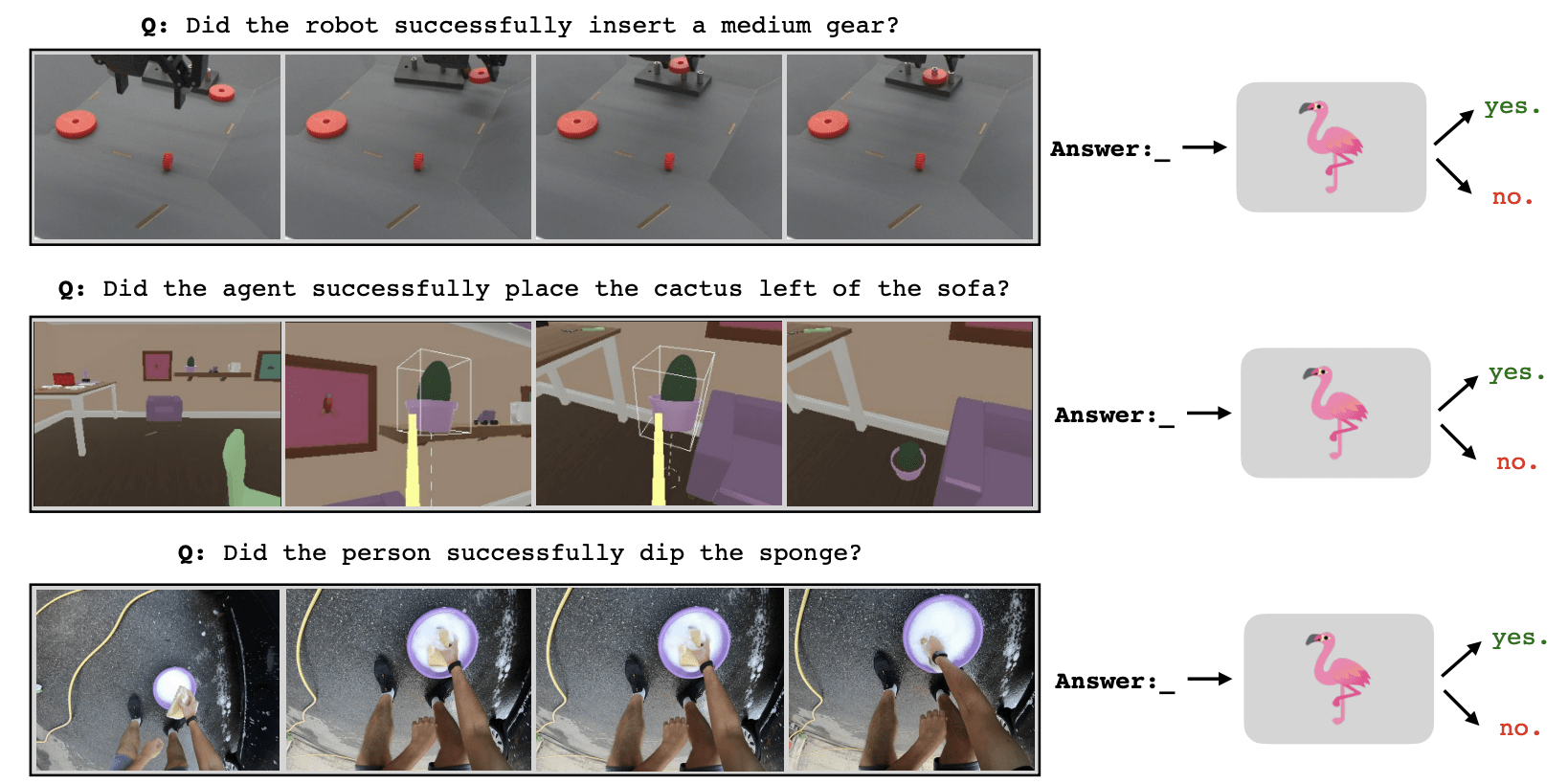
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models, Huang et al. 2023
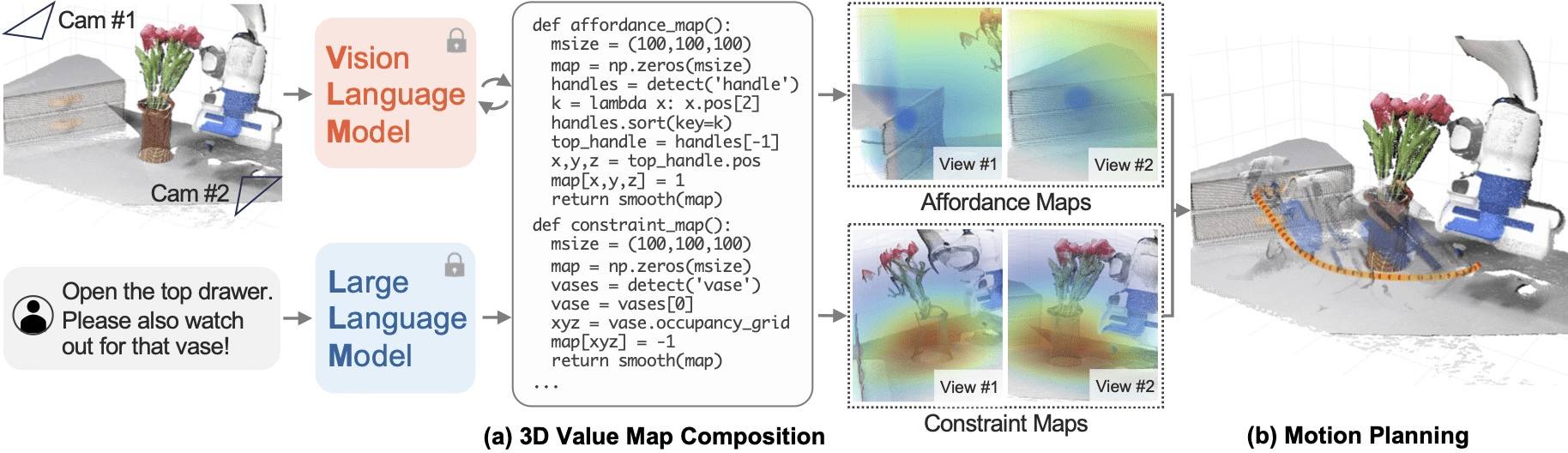
Annotate cost for Motion Planning
With all of these...
- Foundation Model -> simulations
- Foundation Model -> reward / cost
- Maybe we can generate internet scale action data with enough compute?
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Video Foundation Models
Boyuan Chen on scaling robotics:
Model scales, data collection doesn't.
Video give you action data.
Why video
- Video is how humans perceive the world (physics, 3D)
- Video is widely available on the internet
- Videos contains human actions and tutorial
- Video + LLM give you a world model
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Video is fundamental to vision, e.g. 3D
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
A lot of videos on internet

MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
A lot of actions/tutorials
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
Promise of video prediction
- Pre-train on entire youtube, first image + text -> video
- Finetune on some robot video
- Inference time,
- given observation image + text prompt ->
- video of robot / human hand doing the task ->
- back out actions
MIT 6.4210/6.4212 Guest Lecture By Boyuan Chen, Twitter, Website
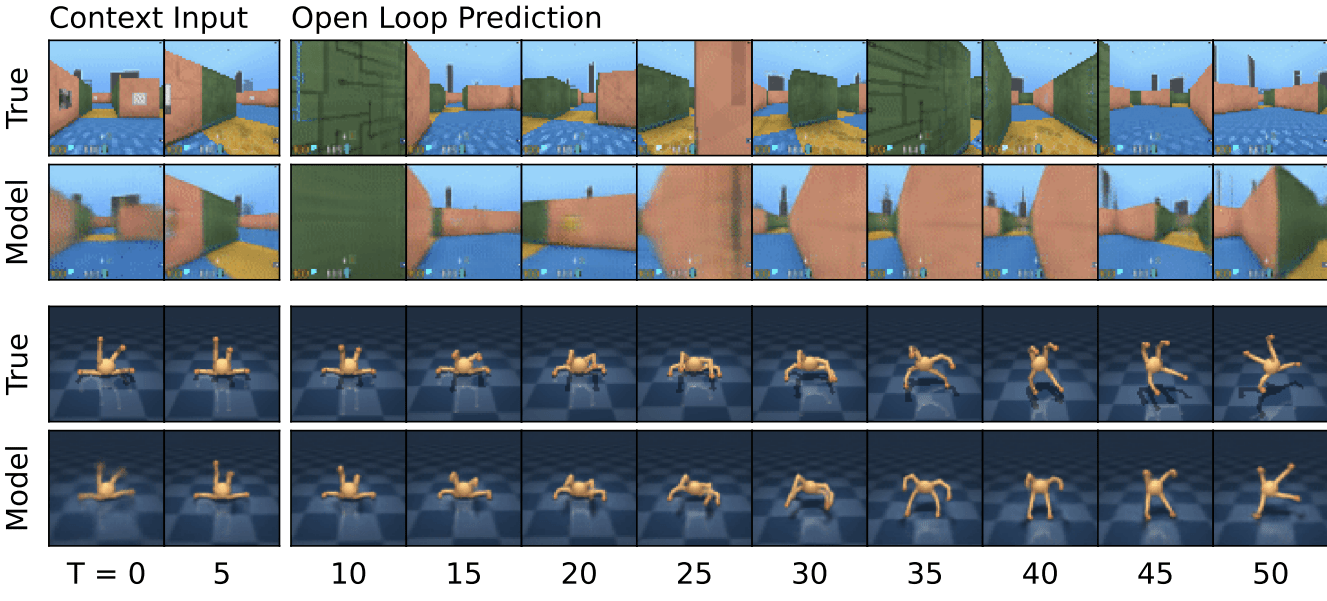
Universal dynamics model
UniSim: Learning Interactive Real-World Simulators, Du et al., 2023

Video Prediction for Robots
Learning Universal Policies via Text-Guided Video Generation, Du et al. 2023

Video Prediction for Robots
Learning Universal Policies via Text-Guided Video Generation, Du et al. 2023

Video + Language
Video Language Planning, Du et al. 2023
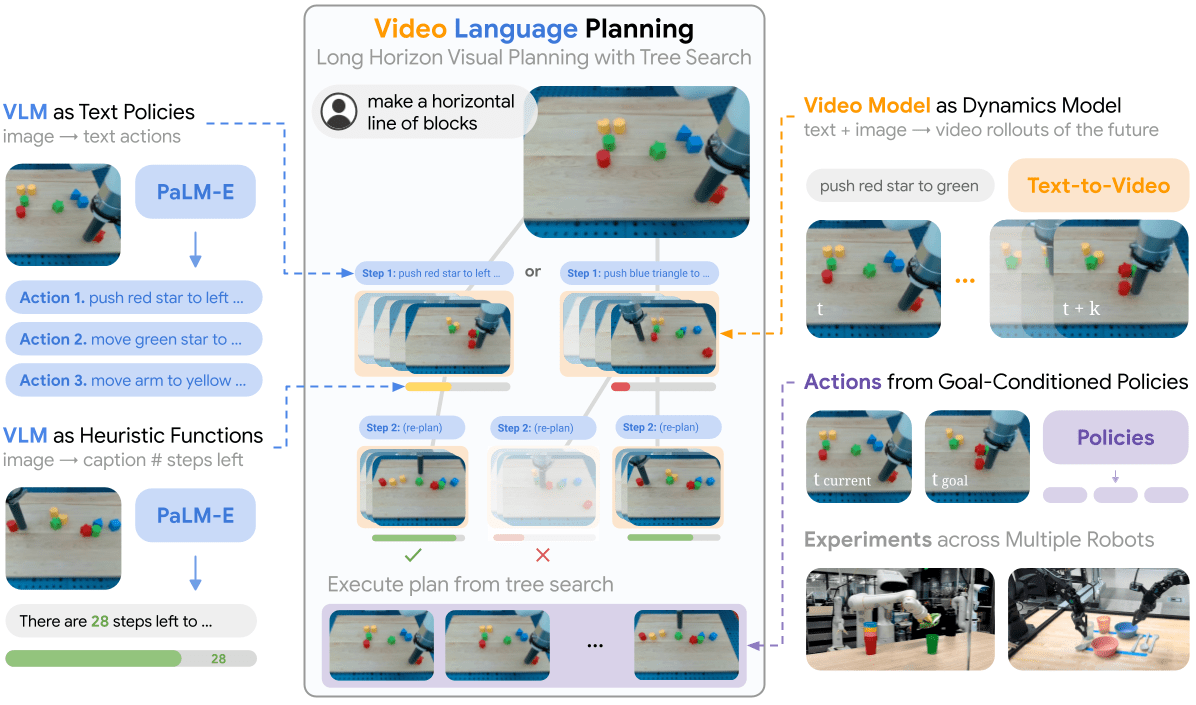
Video + Language
Video Language Planning, Du et al. 2023
Instruction: Make a Line
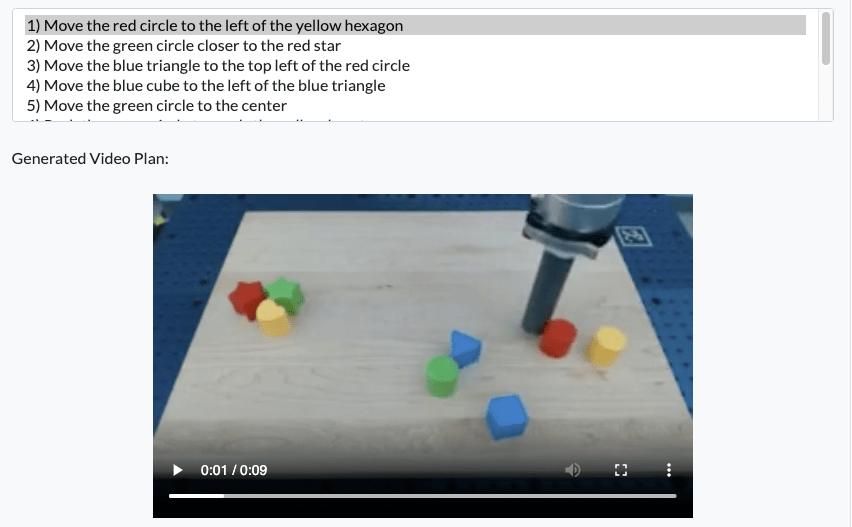
Video + RL
Mastering Diverse Domains through World Models, Hafner et al. 2023