遊戲AI&強化學習
Game AI & Reinforcement Learning

課程大綱
Course Outline
規劃
建構遊戲
Connect Four in Python
初始化
ROW_COUNT = 6 #列
COLUMN_COUNT = 7 #行
pt_player1 = 0 #玩家一分數
pt_player2 = 0 #玩家二分數函式 - 建立棋盤
import numpy
def create_board():
board = numpy.zeros((ROW_COUNT,COLUMN_COUNT))
return board函式 - 下棋
def drop_piece(board, row, col, piece):
board[row][col] = piece
函式 - 是否為合法操作
def is_valid_location(board, col):
return board[ROW_COUNT-1][col] == 0函式 - 找到該行最後位置
def get_next_open_row(board, col):
for r in range(ROW_COUNT):
if board[r][col] == 0:
return r函式 - 列印棋盤
def print_board(board):
print(numpy.flip(board, 0))函式 - 檢查有沒有贏
def winning_move(board, piece):
# Check horizontal locations for win
for c in range(COLUMN_COUNT-3):
for r in range(ROW_COUNT):
if board[r][c] == piece and board[r][c+1] == piece and board[r][c+2] == piece and board[r][c+3] == piece:
return True
# Check vertical locations for win
for c in range(COLUMN_COUNT):
for r in range(ROW_COUNT-3):
if board[r][c] == piece and board[r+1][c] == piece and board[r+2][c] == piece and board[r+3][c] == piece:
return True
# Check positively sloped diaganols
for c in range(COLUMN_COUNT-3):
for r in range(ROW_COUNT-3):
if board[r][c] == piece and board[r+1][c+1] == piece and board[r+2][c+2] == piece and board[r+3][c+3] == piece:
return True
# Check negatively sloped diaganols
for c in range(COLUMN_COUNT-3):
for r in range(3, ROW_COUNT):
if board[r][c] == piece and board[r-1][c+1] == piece and board[r-2][c+2] == piece and board[r-3][c+3] == piece:
return True函式 - 下棋策略
def player1(board):
return which_col
def player2(board):
return which_col主程式
執行n次看勝率
total_times = 100
unvalid_player1 = 0
unvalid_player2 = 0
totaltimecost_player1 = 0
totaltimecost_player2 = 0
for times in range(total_times):
board = create_board()
turn = 0
n = random.randint(0, 1)
while turn < 42:
if (turn+n)%2 == 0:
nowsystime = time.process_time()
while True:
col = player1(board)
if is_valid_location(board,col):
row = get_next_open_row(board,col)
drop_piece(board,row,col,1)
break
unvalid_player1 += 1
totaltimecost_player1 += time.process_time() - nowsystime
if winning_move(board, 1):
pt_player1 += 1
break
else:
nowsystime = time.process_time()
while True:
col = player2(board)
if is_valid_location(board,col):
row = get_next_open_row(board,col)
drop_piece(board,row,col,2)
break
unvalid_player2 += 1
totaltimecost_player2 += time.process_time() - nowsystime
if winning_move(board, 2):
pt_player2 += 1
break
#print_board(board)
turn += 1
print(f'[{total_times} games]\n-----game result-----\nplayer1 : {pt_player1/total_times}\nplayer2 : {pt_player2/total_times}\ndraw : {(total_times - pt_player1 - pt_player2)/total_times}\n------time cost------\nplayer1 : {totaltimecost_player1}\nplayer2 : {totaltimecost_player2}\n----unvalid moves----\nplayer1 : {unvalid_player1/total_times}per game\nplayer2 : {unvalid_player2/total_times}per game')隨機操作
Random Operation
隨機
import random
def player1(board):
return random.randint(0, 6)
def player2(board):
return random.randint(0, 6)勝率
player1 : 0.5521
player2 : 0.4451
預想後一步
One-Step Lookahead
檢查下一步會不會贏
def one_step_look_ahead(board):
for col in range(7): //自己下一步會贏
if not is_valid_location(board,col):
continue
row = get_next_open_row(board, col)
board[row][col] = 2
if winning_move(board, 2):
board[row][col] = 0
return col
board[row][col] = 0
for col in range(7): //對手下一步會贏
if not is_valid_location(board,col):
continue
row = get_next_open_row(board, col)
board[row][col] = 1
if winning_move(board, 1):
board[row][col] = 0
return col
board[row][col] = 0
return random.randint(0, 6)加入自己的策略
Text
預想後n步
N-Step Lookahead
極小化極大演算法
Minimax
一方要在可選的選項中選擇將其優勢最大化的選擇,另一方則選擇令對手優勢最小化的方法
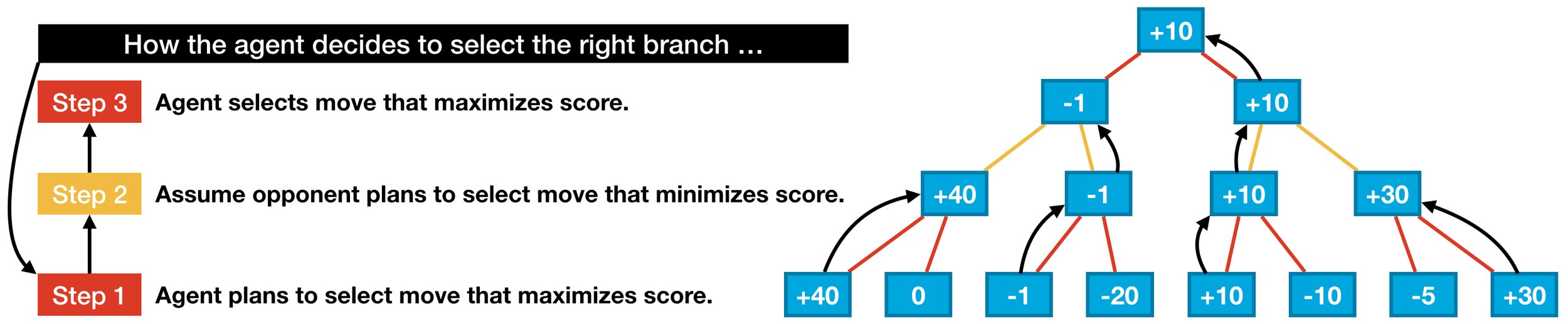
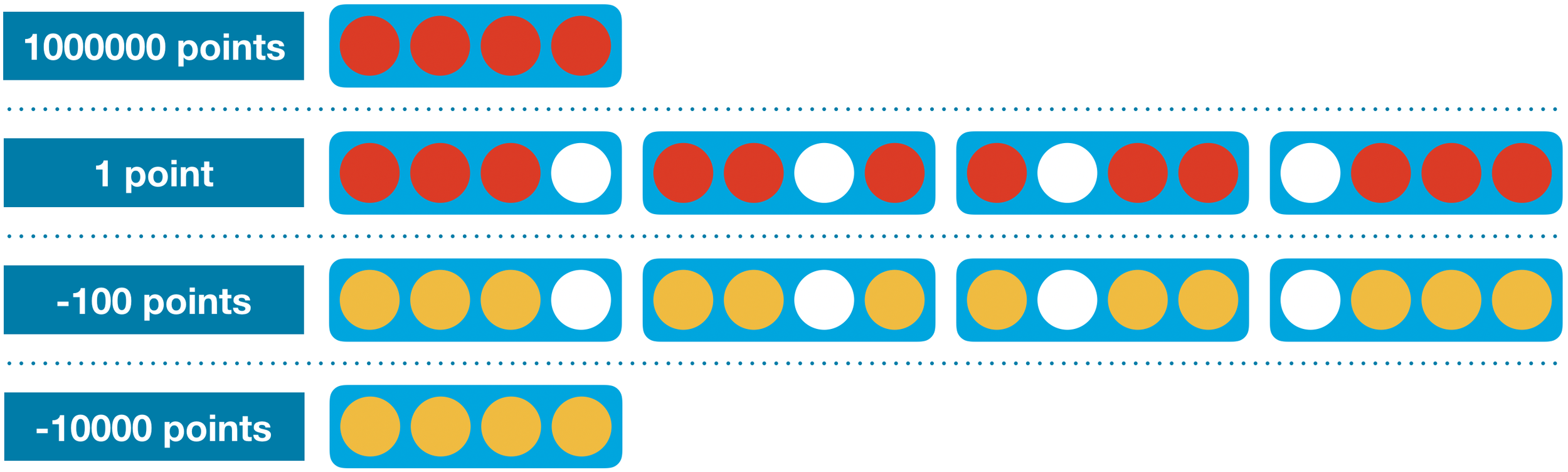
計分方式
強化學習
Reinforcement Learning