
Grab the slides:
slides.com/cheukting_ho/legend-data-compare-models
Every Monday 5pm UK time

by Cheuk Ting Ho









Big Questions
How can we compare which machine learning model is better?
Why we choose this model over the other?
How do we define acurate?
If it's good on training data is it good on anything?
We need metrics, measurements to determin how good the performance of the model is
Common metrics:
https://scikit-learn.org/stable/modules/model_evaluation.html#common-cases-predefined-values
accuracy
precision and recall
F1 score
Accuracy
The percentage of correct labels
https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html#sklearn.metrics.accuracy_score
Although it provide a general measurement of how good a model is, it is not always a good measurement
Identify terrorists trying to board flights
Anyone can provide a model with greater than 99% accuracy
By predicting all passagers are not terrorists
Given the 800 million average passengers on US flights per year and the 19 (confirmed) terrorists who boarded US flights from 2000–2017, this model achieves an astounding accuracy of 99.9999999%!
https://towardsdatascience.com/beyond-accuracy-precision-and-recall-3da06bea9f6c
In this case, accuracy is not a good measurement because:
- The data is imbalance
- The stakes of making a mistake are high
- fIdentifying the positive cases (minority) is prefered

Precision-Recall
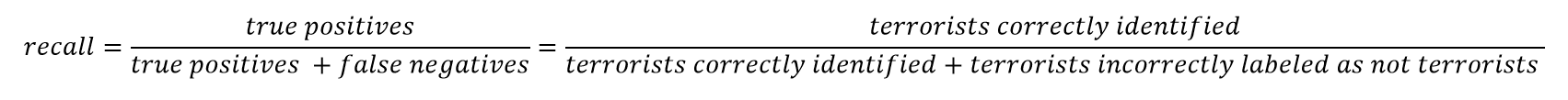
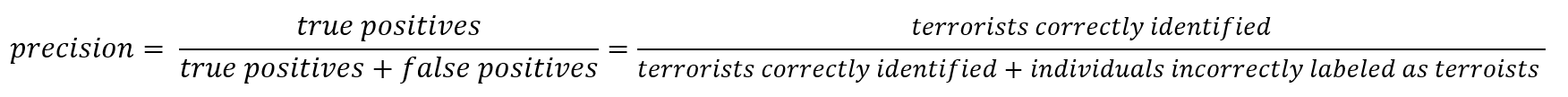
Recall can be thought as of a model’s ability to find all the data points of interest in a dataset.
While recall expresses the ability to find all relevant instances in a dataset, precision expresses the proportion of the data points our model says was relevant actually were relevant.
Precision-Recall

F1 score
F1 score is a combination of precision and recall
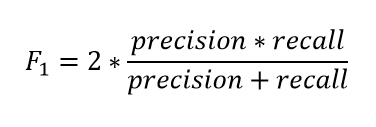
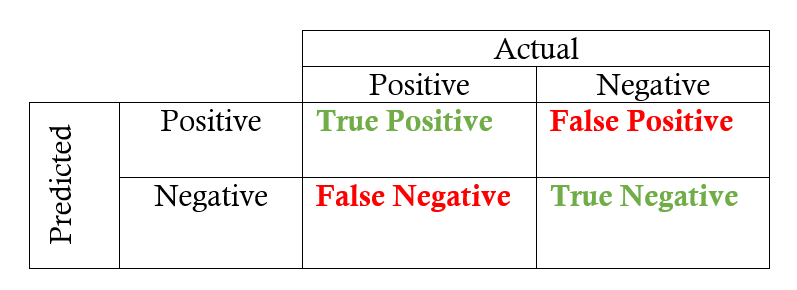
Confusion Matrix
Roc Curve
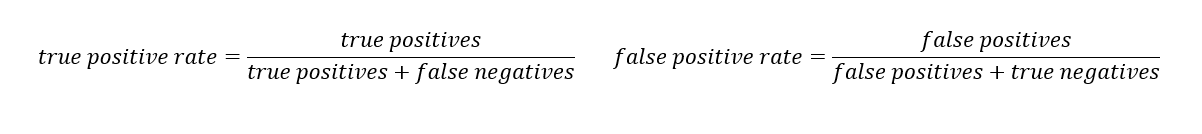
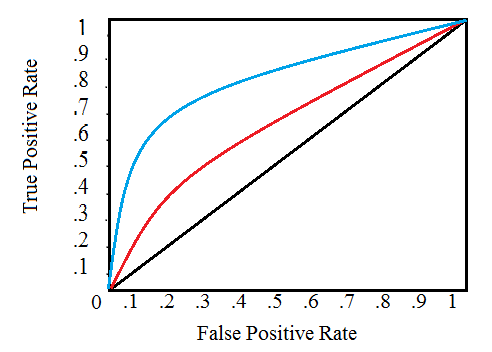
Over-fitting vs Under-fitting
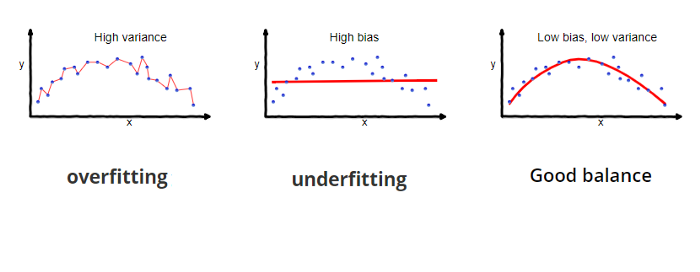
Low training score,
Low testing score
High training score,
Low testing score
High training score,
High testing score
Next week:
Boosting Algrithms
Every Monday 5pm UK time
Get the notebooks: https://github.com/Cheukting/legend_data