
Grab the slides: slides.com/cheukting_ho/legend-data-cat-data
Every Monday 5pm UK time

by Cheuk Ting Ho









Categorical Data
In statistics, a categorical variable is a variable that can take on one of a limited, and usually fixed, number of possible values, assigning each individual or other unit of observation to a particular group or nominal category on the basis of some qualitative property.
Categorical Data
They are everywhere in real life:
which party do people vote?
which recycling material?
which country people are in?
etc....
Categorical Data
But they are also difficult to deal with:
- Labels
- Not continuous
- Some times no meaningful order to labels
Linear regression
Logistic regression
- binary: 0 or 1
- special case of categorical data
- what about more than 0 or 1
Dummy Variables
In regression analysis, a dummy is a variable that is used to include categorical data into a regression model.
There are many ways of tunning a catagorical into numbers that you can use it in machine learning models
- One-Hot-Encoding
- Label-Encoding
- Other Encodings
One-Hot-Encoding
{'apple🍎', 'banana🍌', 'orange🍊'}
is_apple: {0 or 1}
is_banana: {0 or 1}
is_orange: {0 or 1}
Advantage: precise
Disadvantage: # of variables expanded, not suitable for variables with many classes
Label-Encoding
{'apple🍎', 'banana🍌', 'orange🍊'}
{1, 2, 3}
Advantage: # of variables remains the same
Disadvantage:
1) ordering of the classes is ambiguous
2) intensity of classes is ambiguous (e.g. Large, Medium, Small)
Other encodings?
- count labeling
- propotion labeling
Problem is, the data are viewed as a whole, each data entry is not a single entity and therefore a statistical conclusion is already drawn within the data.
Difficule to apply with the train-test split.
Maybe regression is not best with categorical data?
Other Machine Learning Algorithms
Decision Trees
Neural Network (with softmax activation)
Support Vector Machine (SVM)
Decision Trees
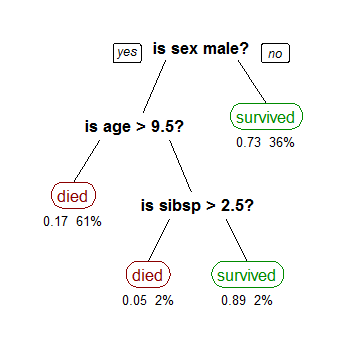
Decision Trees
Finding which feature(s) can help seperating one outcome from the others (making "decisions")
Sometimes a combination of decision trees can give a better picture of the "decision" and outcome statistically
- Random forests - comprised of a large number of decision trees.
- Tree boosting - build trees one at a time; each new tree helping to correct errors from the previously trained tree.
Next week:
Decision Trees
Every Monday 5pm UK time
Get the notebooks: https://github.com/Cheukting/legend_data