Machine Learning
Full Course

講師 - 呂家睿
- 建中資訊38屆學術長+副社
- 玩雀魂
- 頭像是應急食品
- 被電爛
- 有問題歡迎來問我啊

- Fastapi
- Qt(C++)
- 數學好難
- 一點點sandbox
- Machine Learning
- discord bot
- 打開電腦
學術力

講師 - 林瑋浩
成功電研38屆教學
- 擅長寫O(2ⁿ)演算法
- 不會數學
- 回訊息很快
- C++
- Python
littleWeb前端- Discord bot
Bongosort- Machine Learning
- Godot
學術力

LLM
What is LLM?



沒錯是這些好東西
Large Language Model大語言模型,簡稱LLM。是一種神經網路語言模型。特色是有很大量的參數,ex: DeepSeek-V4-Pro 1.6 T個。設計目的是處理自然語言,尤其是語言生成。
History
歷史課時間
未來
過去
2000
MIT創造了第一個chatbot
用的是模式匹配、替代法,模擬人類語言
1966
ELIZA
引入統計
從原本已制定規則的方法改成透過統計的方式建立語言模型
1980
N-gram
檢查前N個字
History
歷史課時間
未來
過去
2017
Google 發明了一個把文字轉換成高維度向量的方法,現在模型可以理解不同詞語之間存在的關係
2013
Word2Vec
RNN & LSTM
採用遞迴神經網路中和長短期記憶網路解決了模型現在能夠更好的判斷長句子
Transformer
Google 發表了一篇叫做 Attention is All You Need的論文,模型能夠同時考慮一段文字之間詞語的關係,LLM開始出現
Pipeline
大概先講一下LLM怎麼運作的
Output




Input
Tokenization
Embedding
Positional Encoding
Transformer Layers
Next Token Prediction
Tokenization
Tokenization
顧客:豆腐多少錢?
老闆:兩塊。
顧客:兩塊一塊?
老闆:一塊。
顧客:一塊兩塊?
老闆:兩塊
- 中文十級聽力測試
所以ChatGPT真的看得懂嗎?
它看不懂
Hello World
電腦只能看得懂數字
[15496, 2159]
人要是行,幹一行行一行,一行行行行行,行行行幹哪行都行,要是不行,幹一行不行一行,一行不行行行不行,行行不行幹哪行都不行。想要行行行,首先一行行,成為行業內的內行,行行成內行,行行行,你說我說的行不行?
- 中文十級聽力測試2
再來一個
Character
最直覺的方法應該是給把每一個字母都當作一個Token,這被稱作Character Tokenization
Hello
['h', 'e', 'l', 'l', 'o']
優點:
- 字典很小
- 不會有 Out of Vocabulary問題
- 可以處理任何新單字
缺點:
- 句子很長
Token很多
Attention會爆炸
不適合LLM

Word
好吧所以我們改成使用一個單字為單位,這被稱作Word Tokenization,這是早期 NLP 、也是 Word2Vec 時代常見做法。
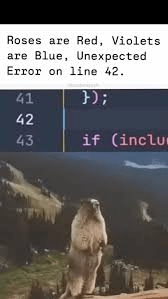
['Roses', 'are', 'Red', ',', 'Violets', 'are', 'Blue', ',', 'Unexpected', 'Error', 'on', 'line', '42', '.']
優點:
- token數量減少
- 可以處理更多內容
缺點:
- 字典大小嚴重膨脹
- 出現新單字、打字錯誤容易出問題
依舊爆炸
Sub-word
為了讓效果能夠更好,我們取一個中間值,把一個字切 成幾個小部分
["It", " wasn", "'t", " working", ",", " so", " I", " read", " it", " line", " by", " line", " and", " wrote", " comments", " to", " find", " the", " problem", ".", " And", " now", " it", " works", "."]
優點:
- 不需要巨大字典
- 不怕新單字
- Token 數量也不會太多
現在的模型都用這個
缺點:
- 不穩定

Tokenization
剛剛講的是核心的部分,通常前後還會加上一些雜七雜八的處理
現在Tokenization有點像一個壓縮器,在保留文意的情況下,盡可能減少token數
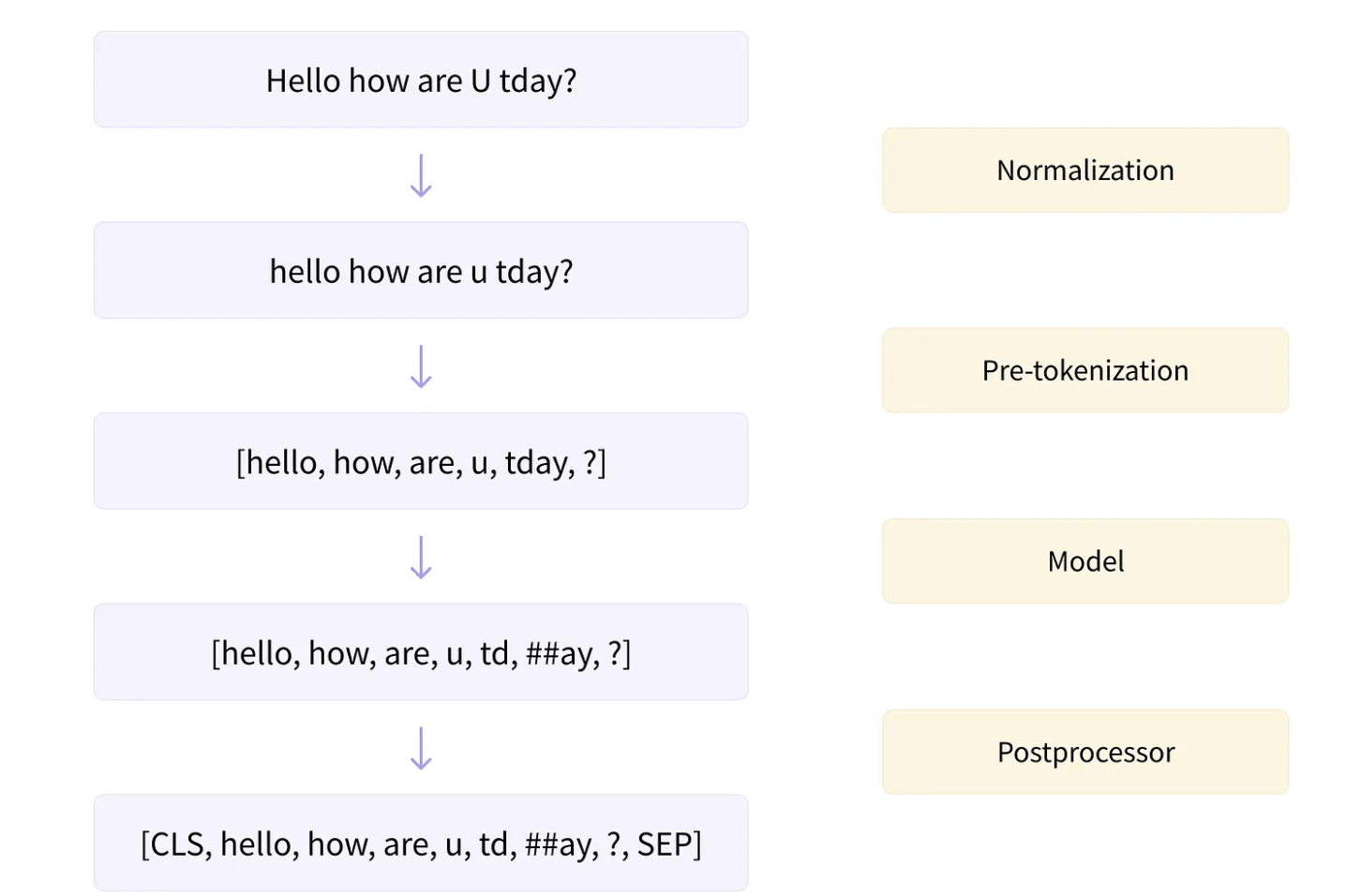
Vocabulary Lookup
最後一步是把文字轉換成數字(ID),基本上查表,十分簡單,有手就行

你問我字典怎麼來的?這個還真有一些學問
Tokenizer Algorithms
怎麼把文字做成一個字典有很多種方法,但基本上離不開兩個關鍵:
- 找到常出現的字序
- 建立正向(Vocab to ID) 跟反向(ID to Vocab)的字典
BPE
(Byte Pair Encoding)
1. 把文本拆成Byte
2. 統計頻率
3. 將高頻組合合併
Word Piece
跟BPE很像

Unigram
1. 從很多可能的subword開始
2. 刪掉一些不重要的subword
3. 看怎麼樣損失最小
Embedding
Embedding
很好現在我們有一堆token了! 但他們之間沒有任何關聯性,我們用Embedding讓模型了解到他的「語意」
token(ID)
高維度向量
Embedding
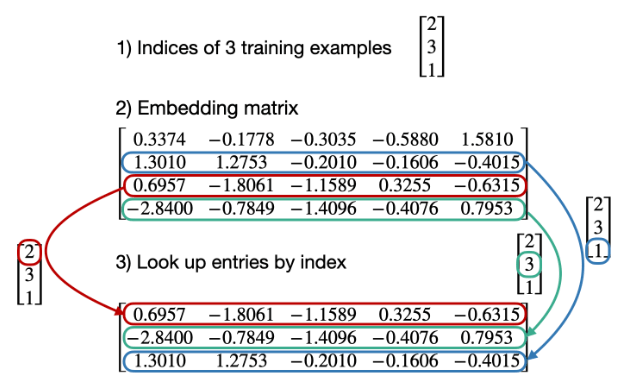
更具體的說,Embedding也有點像是可以查表又可以學習的矩陣。他不是手動設計的,而是deep learning學出來的。
飯粒: GPT - 4
vocabulary
embedding vector
embedding matrix
示意圖
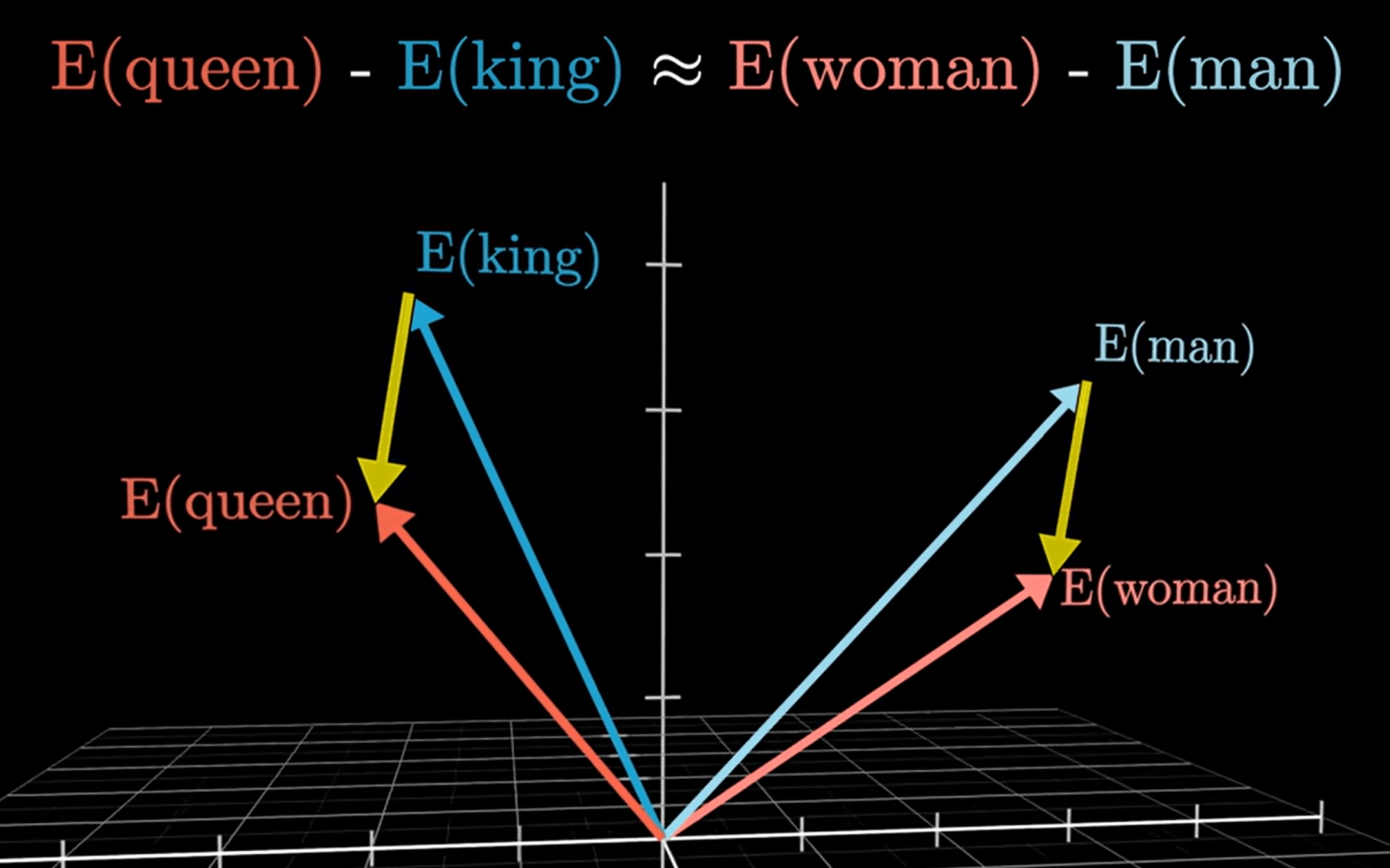
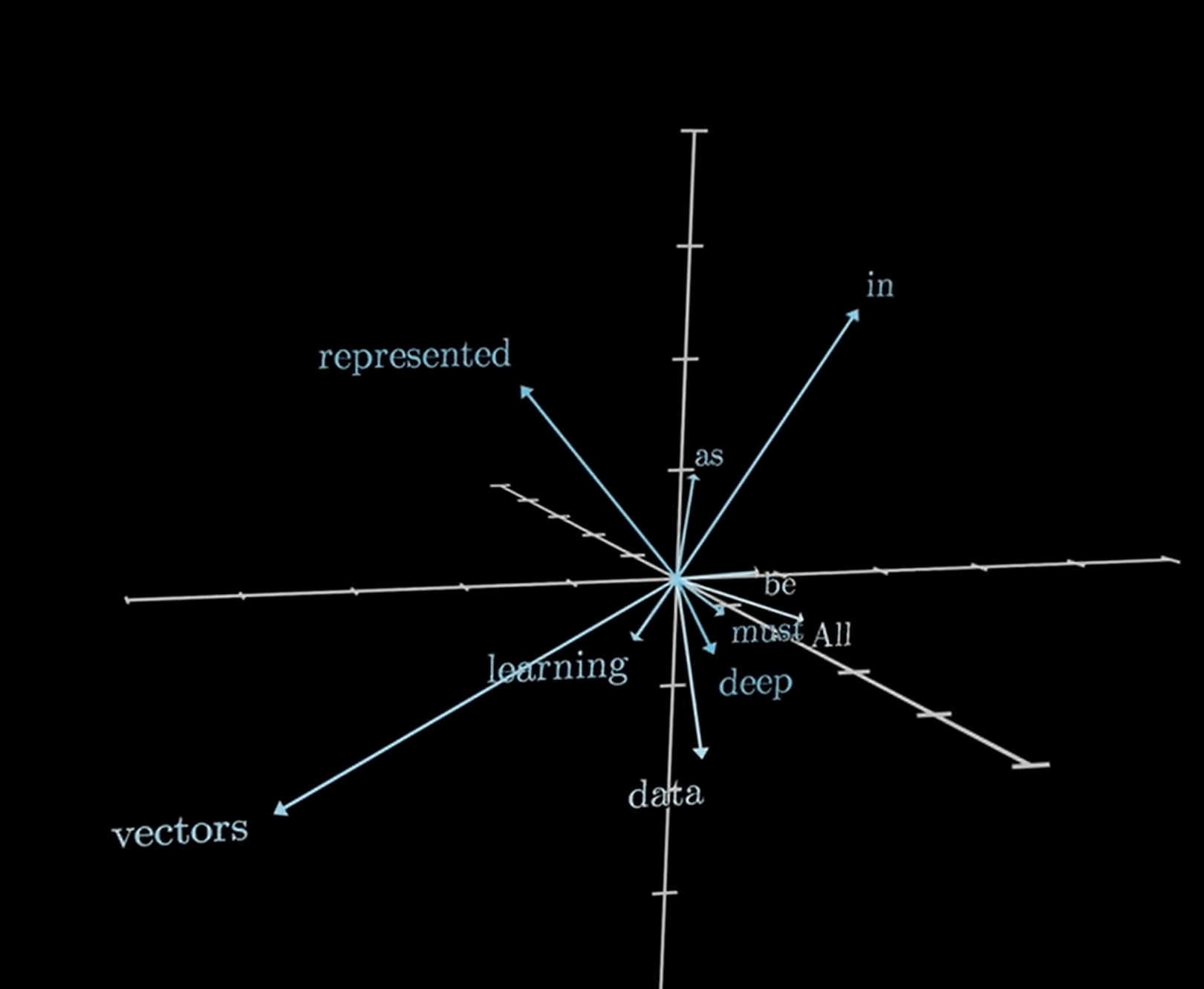
示意圖
怎麼知道兩個詞與之間的關係強弱呢?
可以用cosine similarity
TF-IDF
這是古早古早的embedding方法,分成兩個部分Term-Frequency (TF)跟Inverse Document Frequency (IDF):
字詞出現的次數
字詞在不同文件中的稀有度
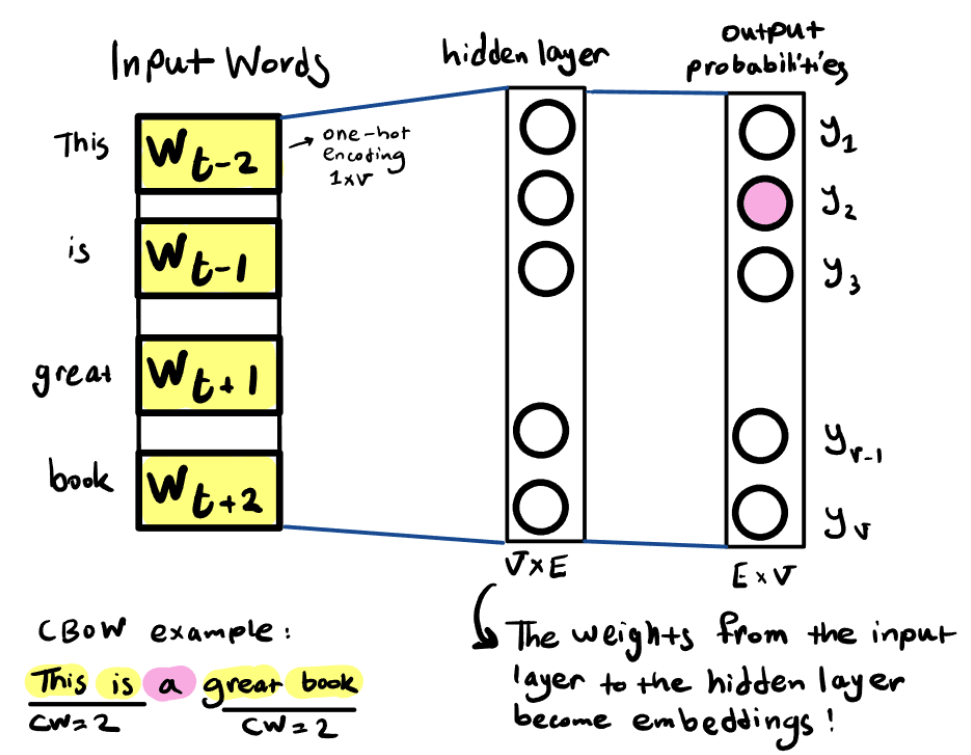
word2vec
上禮拜應該聽過了,就是一個google提出來利用CBOW(預測一連串的字)訓練出一個隱藏層。這個隱藏層就是可以把token轉換成關係向量的embedding向量
Dynamic Embedding
上面的word2vec是一種static embedding。所謂static embedding就是一個字基本上只有一個意思。如果模型覺得bank是銀行的意思,那麼他看到river bank就會覺得是河川銀行。
Dynamic Embedding則會根據Attention(觀察周遭環境)動態的調整象徵這個token屬性的向量
Positional Encoding
Positional Encoding
我們前置步驟感覺都做完了,但還差最後一件事,那就是排位置。對你沒聽錯,transformer不知道字的位置,所以我們要告訴他
之前我們用RNN的時候因為它是一步一步看下去,所以沒有字詞順序的問題。但transformer是一次看一堆字,我們需要把字的順序也納入考量才不會失真
Sinusoidal
其實這步挺簡單,套個公式就結束了,公式看起來挺可怕就是了
pos是位置,d是embedding向量的維度,i是向量中的第幾個元素
圖片
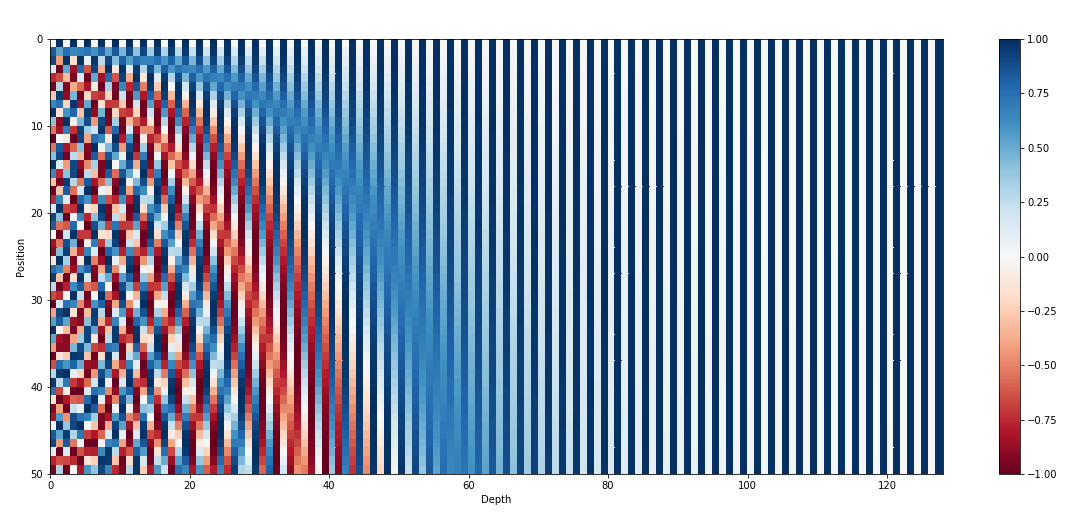
我盡力解釋
RoPE
好所以說前面的方法雖然暫時解決了問題,但是還是有一個致命傷。比方說第1個token跟第5個token距離是4,第101個第105個token距離也是4,但是用剛剛方法沒辦法發現他們兩者距離是一樣的。於是有人想到了我們可以改用旋轉的方法來表達相對位置。
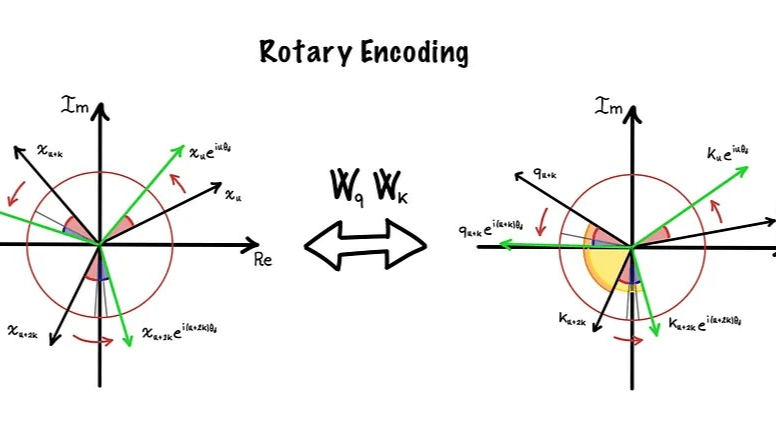
旋轉矩陣,高二會教這個
Attention
Attention
ok終於進入真正的重點了,前面我們已經看到了很多LLM跟以前的模型不同之處,但是Attention才是他真正質變的地方
Attention

it是什麼?
作為一個正常人你應該知道it指的是code,但是模型他怎麼知道?
RNN的做法是遞回下去,把前面看到的東西記住,跟下面的判斷。
但是transformer不是,他看一整塊,他怎麼知道要看這塊地哪個token?
Attention的功能就是告訴每個token你需要關注哪幾個其他的token
it
code = 0.8
God= 0.15
I= 0.05
最可能是code
Q, K, V
Q(Query): 作為當前token考慮
K(Key): 作為其他token考慮
V(Value): 考慮內容
token embedding完得到的矩陣
不同權重
Multi-head Attention
我們可以把attention拆成好幾個部分,每個部分平行運算,這樣既可以比較快,也可以確保不同部分會判斷不同東西
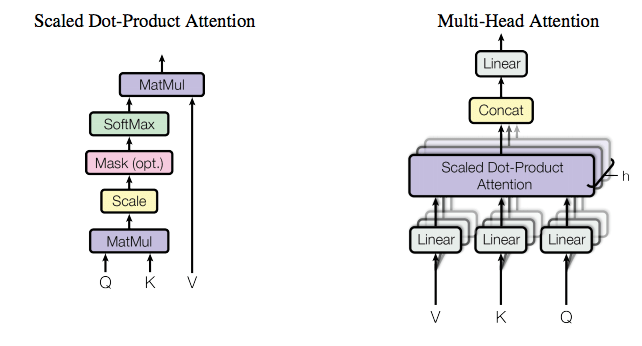
Transformer
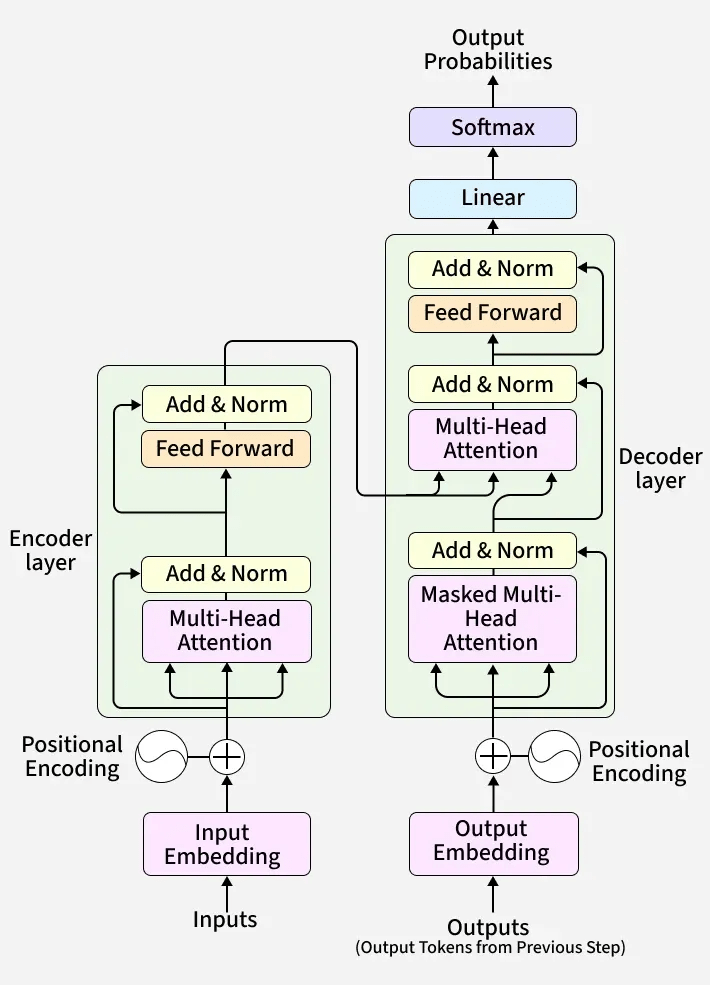
我偷台大的簡報,非常好簡報
Transformer是一個把法文翻譯成英文的模型,分成兩個部分encoder跟decoder
Improvement
1. Decoder-only
現代的模型發現把encoder部分刪掉,把理解的部分加入decoder效果依舊不減還可以節省資源。
現在分成prefill 跟 decode,兩個步驟都只需要decoder
2. GQA(Grouped Query Attention)
MHA: 獨立、耗費資源
MQA: 單一、精準度下降
GQA: 折衷
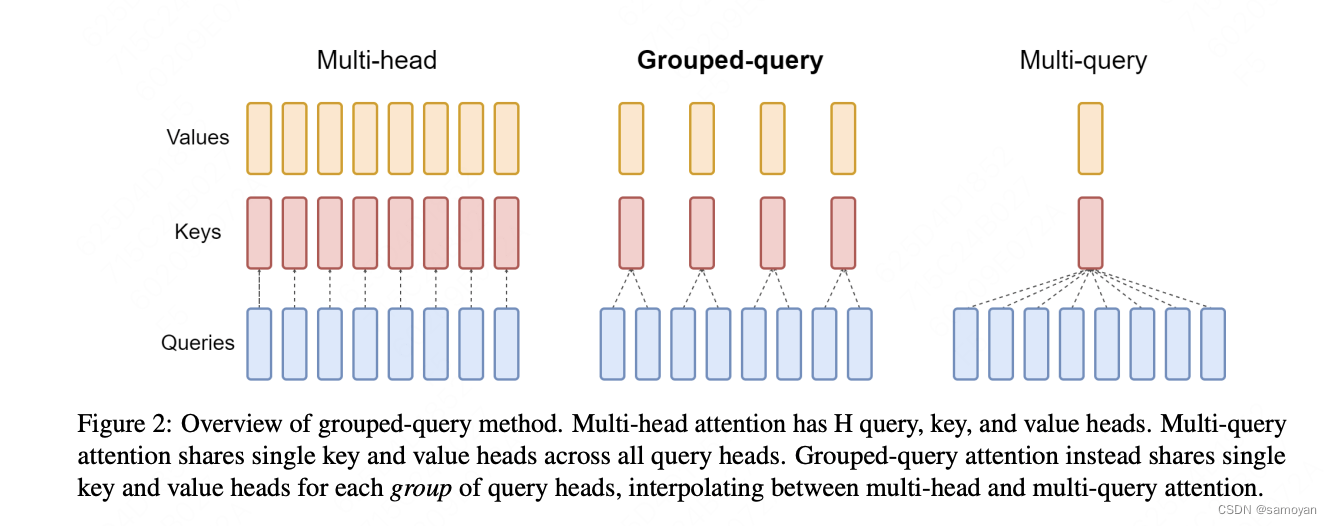
Improvement
3. Pre-norm
4. RMS norm
從ReLU換成了SwiGLU
5. Activation Function
R = root
M = mean
S = square
方均根層歸一化
下課!!!!!
