Sharing & Re-using Data
Where, why, & how
Ryan Clement | Data Services Librarian | Reed College Library
Licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

What are we doing today?
-
The ethics of sharing & re-using data
-
Some major data repositories
-
Cleaning & preparing secondary data
-
How do you properly cite data?
Sharing data

image source: http://www.nature.com/news/specials/datasharing/images/datasharing.jpg
Data Sharing Horror Story
Data sharing considerations
- Legal Ownership (Copyright & Licenses)
- Data Quality
-
Personal Relationships
- Requestor’s Motives & Authority
- Advisors/PIs
- Collaborators/Co-owners
- Competitors
- Disciplinary/Lab Conventions
- Grant Requirements
- IRB Restrictions
- Contracts
- Campus Incubator/Accelerator
Anonymizing Data
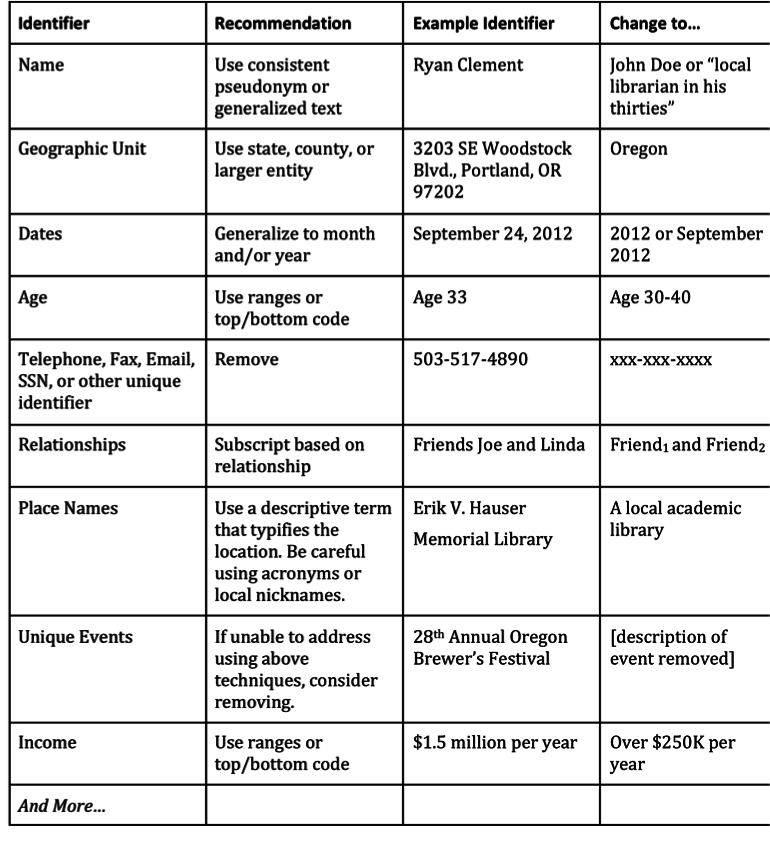
When anonymizing data
- Be careful with “search and replace” functions
- Mark the replacements in the text clearly: use [brackets] or XML tags <anon> … </anon>
- Keep a secure copy of the non-anonymized data for use within the research team and for restricted access preservation
- Create a log of all the replacements, aggregations, or removals made in each transcription. Store this log file separately from the de-identified data.
-
DSDR Qualitative Data Anonymizer
Before you start your data search
"Who would care about this?"
And who would care about keeping it?
What type of organization are they?
Educational institutions, government organization, private company, etc.
If not government, how valuable is the data?
And who would pay for it?
Are there privacy/confidentiality issues?
And at what level of observation do you need the data?
Part of the Institute for Social Research at University of Michigan
First attempt at openly sharing data amongst researchers (started with election studies data)
Curated, digitized, diverse historical data sets

IPUMS Project Goals
Collect and preserve data and documentation
Harmonize data
Disseminate the data absolutely free!
Use it for GOOD -- never for EVIL
Other data repositories
Codebooks

Column locations and widths for each variable (if necessary)
Definitions of different record types
Response codes for each variable
Codes used to indicate nonresponse and missing data
Exact questions and skip patterns used in a survey
Other indications of the content and characteristics of each variable
What's in a codebook?
What else is a codebook good for?

Now you want to play with data
Dirty, Unprepared Data

Missing data
Bad data
Unclear data
Data Citation
Image by Monica Duke (http://blogs.ukoln.ac.uk/sagecite/2011/05/16/data-citation-principles-harvard/)
The Data Citation
From International Studies Quarterly, King and Zeng, 2007, p. 209:
Gary King; Langche Zeng, 2006, "Replication Data Set for 'When Can History be Our Guide? The Pitfalls of Counterfactual Inference'" hdl:1902.1/DXRXCFAWPK UNF:3:DaYlT6QSX9r0D50ye+tXpA== Murray Research Archive [distributor]
The Data Citation
From International Studies Quarterly, King and Zeng, 2007, p. 209:
Gary King; Langche Zeng, 2006, "Replication Data Set for 'When Can History be Our Guide? The Pitfalls of Counterfactual Inference'" hdl:1902.1/DXRXCFAWPK UNF:3:DaYlT6QSX9r0D50ye+tXpA== Murray Research Archive [distributor]
Attribution
The Data Citation
From International Studies Quarterly, King and Zeng, 2007, p. 209:
Gary King; Langche Zeng, 2006, "Replication Data Set for 'When Can History be Our Guide? The Pitfalls of Counterfactual Inference'" hdl:1902.1/DXRXCFAWPK UNF:3:DaYlT6QSX9r0D50ye+tXpA== Murray Research Archive [distributor]
Verifiability
The Data Citation
From International Studies Quarterly, King and Zeng, 2007, p. 209:
Gary King; Langche Zeng, 2006, "Replication Data Set for 'When Can History be Our Guide? The Pitfalls of Counterfactual Inference'" hdl:1902.1/DXRXCFAWPK UNF:3:DaYlT6QSX9r0D50ye+tXpA== Murray Research Archive [distributor]
Findability
Data citations MUST have:
Author
Publication Date
Title
Publisher/Distributor or Location
Persistent Identifier (DOI, hdl, ark, URI)
It's also great to have:
Location (URL)
Version
Access Date
Feature or Subset Name
UNF (or other validation key)
Citation Management Software
Zotero
No dataset type
Use Document/Report/etc; just be consistent
Dataset coming
EndNote
Dataset type
Lots of useful fields (unit of observation, data type, separate producer/distributor)