Explaining machineJS To My Parents Part 3:
Training, Tuning, Selecting, and Validating your machine learning algorithms
Today's Tour
- Overfitting
-
Cross-Validation
- Defines "right" for us
-
Tuning
- Finding the right version of a given algorithm
-
Selecting
- Finding the right algorithm
-
Ensembling
- Using machine learning to assemble together all your machine learning results!
- machineJS does all this for you!
Overfitting
- Machine learning is really good at learning all the trends in a data set...
- ... sometimes too good
- If you're not careful, it will just memorize the data you gave it
- "There are far more efficient ways to store data than inside a random forest"
- -mlwave.com
- "There are far more efficient ways to store data than inside a random forest"
Overfitting Example
- Let's say we're trying to figure out which dots belong to the blue group, and which belong to the red group:

- As humans, we can see pretty clearly that the black line is a better differentiator
- But the computer, if we're not careful, is going to get excited and learn the training data really well, drawing the hyperspecific green line
- Clearly, the green line will not generalize to other data well!
image credit: mlwave.com
Overfitting- Problem
- Let's say we're trying to figure out which dots belong to the blue group, and which belong to the red group:
- Again, the point of machine learning is to make predictions on new data, so what we want is a general solution, not one that's hyperspecific to only this training data
- And clearly even though we'll predict a couple points in the training data incorrectly, the black line will make much more sense for new data than the green line
image credit: mlwave.com
Cross-Validation
- The solution to over-fitting!
- Train the algorithm on one dataset, but then test it on a different dataset!
- This prevents you from asking the machine "how well did you memorize the data I already gave you?"
- hint: machines are really good at memorizing!
- Instead, you're now asking how well it learned patterns that are broadly useful
- "Ok, so let's see how well you can apply what you've learned when we ask you about some new data points"
Cross-Validation
- Typically you'll split your incoming dataset into 80% to train the algorithm on, and 20% to test it on
- This lets us define how accurate a model is, by seeing how good the predictions are that the algorithm makes on the test data
Cross-Validation
- machineJS relies heavily on cross-validation to figure out define what's "right"
Tuning
- There are all kinds of shapes and sizes a particular machine learning algorithm can take on
image credit: mathworks.com
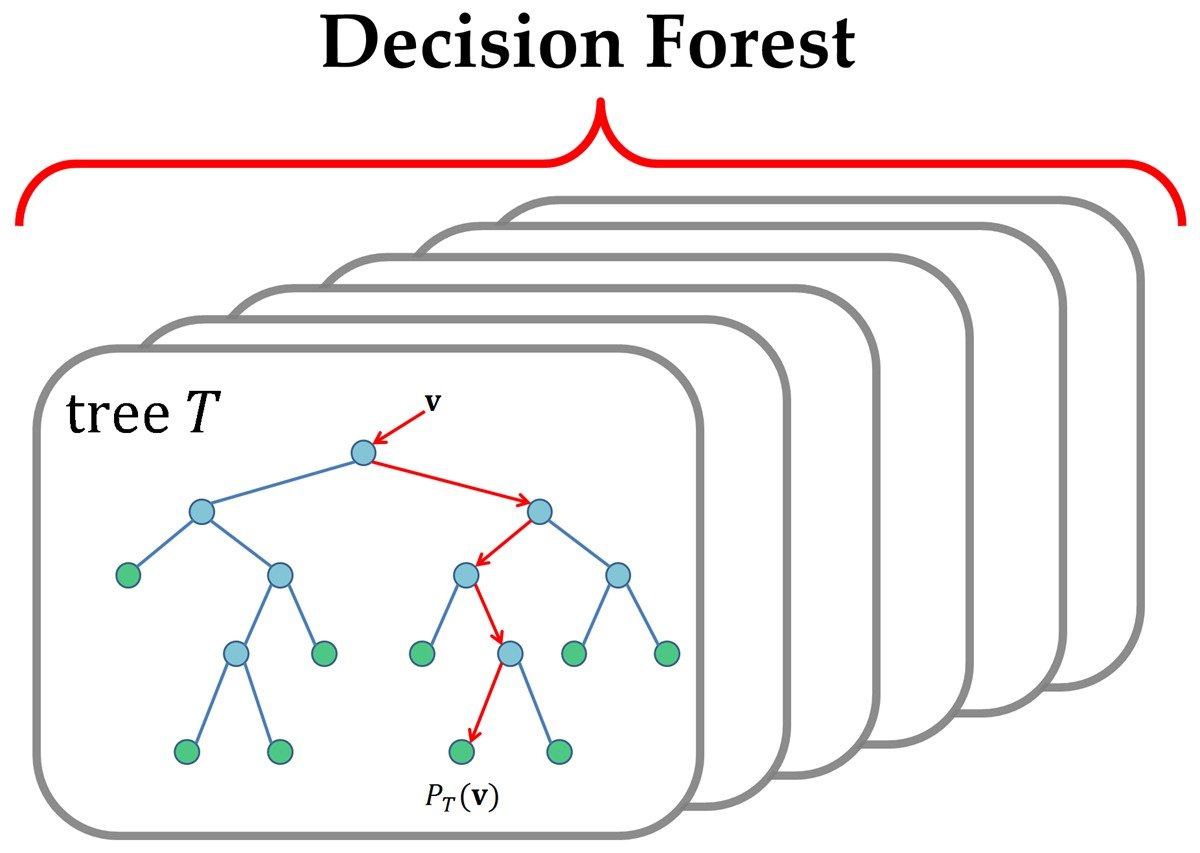
How Deep?
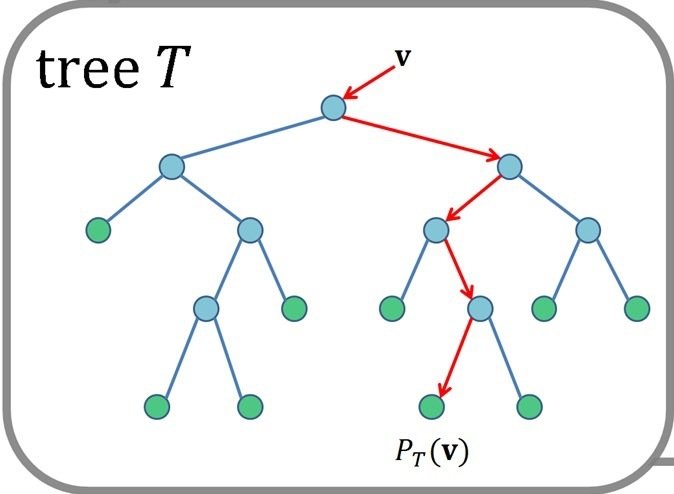
How Many Ways to Split?
Right now these are all splitting two different ways
How Many Trees?
Tuning
- In order to pick the best possible "shape" for a given machine learning algorithm, we basically just try a bunch of different options
- This is a tedious process- just try a bunch of new parameters, and see how that impacts the observed accuracy at the end (using cross-validation!)
Tuning
- machineJS does all this for you!
Selecting the Best Algorithm
- There are (depending on what you're trying to do) a half dozen or a dozen algorithms that might be really useful for your problem
- Which algorithm do you pick? And then, once you've selected which algorithm to use, which set of parameters do you choose to tune that algorithm with?
Selecting the Best Algorithm
- This, again, is a tedious process
- Just try a bunch of things and see which one works best
Selecting the Best Algorithm
- machineJS does all this for you as well!
Ensembling
- Ok, so in the previous stage, we trained up dozens or hundreds of machine learning algorithms to find the best ones
- We've probably trained up quite a few that are useful- now we need to figure out how to put together all these predictions!
Ensembling
- One basic thing we could do is to average together the 5 best algorithms
- Another thing we could do is to pick the two algorithms that are least alike, and average together their results
- Or, we could pick the highest value of all the predicted results.
- Or the lowest
- Or the average ignoring the extremes
- Or the most extreme value
- Or the...
Ensembling
- This is getting tough.
- But luckily, we have figured out some great machine learning algorithms that can take in a huge number of data points and make sense of them all
- Sooo, let's feed the results of our earlier predictions into another round of machine learning to get our final results!
Ensembling
- The logistics of doing this are a bit more complicated, but the understanding is pretty easy:
- We trained up a bunch of machine learning algorithms to find the best one
- Instead of just taking the best one, we think we can use the results of several to be more effective!
- The way we pick which results to use is... you guessed it, machine learning!
Ensembling
- As you might have guessed, machineJS does this for you too :)
machineJS
- Automates the entire process
- Uses cross-validation to:
- Find the right "shape" for each algorithm
- Find the right algorithm
- Ensemble together the results from various algorithms
- Uses cross-validation to:
- Freeing you, the machine learning engineer, up to focus on the interesting parts (feature engineering, figuring out how to put this into practice and make it useful for the business, creative ensembling, etc.)
Thanks!
you can find machineJS at
https://github.com/ClimbsRocks/machineJS