Machine Learning Process
by: preston parry
Today's Tour
- Data
- Pull data
- Filter data
- Feature engineering
- Train/test split
- Train
- Model types
- Interpreting results
- Test!
- Error Metrics
- Overfitting
Pulling Data
- ML algorithms need tabular data
- SQL Queries
- Process data in SQL, filter it in Python
- Iterating on filters is important
- Recency
- Sample data for training speed
- X: features (data we think will be useful for making our prediction)
- y: our output values (the value we are trying to predict)
Nerd-snipe
- Equation, if you're into that kind of thing (and you definitely don't have to be)
- Trying to solve for W * X = y
- W is Weights (for each feature)
- Thanks Raghav!
Filtering Data
- Crazy important
- Make sure you're predicting the thing you think you are
- Algos learn patterns most effectively when you've removed noise
Feature Engineering
- Quite possibly the most fun part!
- Finding the best data to feed into the model
- Dates
- Historical aggregates
- Other examples
Feature Engineering: Empathy
- The best features come from understanding the behavior in your dataset
- For most standard ML business problems, empathy leads to better accuracy than advanced ML knowledge
Train/Test Split
- Is the model any good?
- You need to know how well your model will generalize to new data
- Random, or time-based
- Sometimes you'll see people using two test sets
- Second is often called a holdout dataset
- You can ignore this for now until you start doing more advanced modeling
Train the model
- Feed data to auto_ml
- Grab a coffee, check your Slack, while auto_ml does all the heavy lifting for you!
But I wanna know more!! What happens in there?
Model Types
- Super basic: linear model

Model Types
- Tree-based model
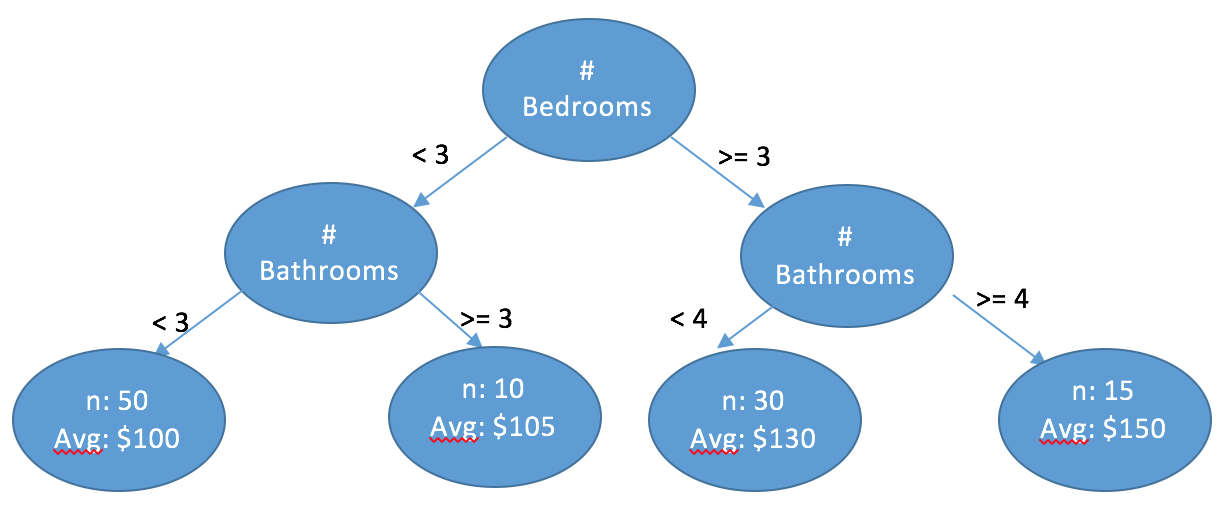
The usual suspects
- Random Forests
- Gradient Boosted Trees
Interpret the model results
- Linear model: coefficients
- Tree-based model: feature importances
- auto_ml: feature_responses
Score the model
- Error metrics!
- All just different ways of saying "how far off are my predictions from the actual values?"
- Get a prediction for every row in your test dataset
- Compare the prediction to the actual value for that row (the error for that row)
- Aggregate these individual errors together in some way
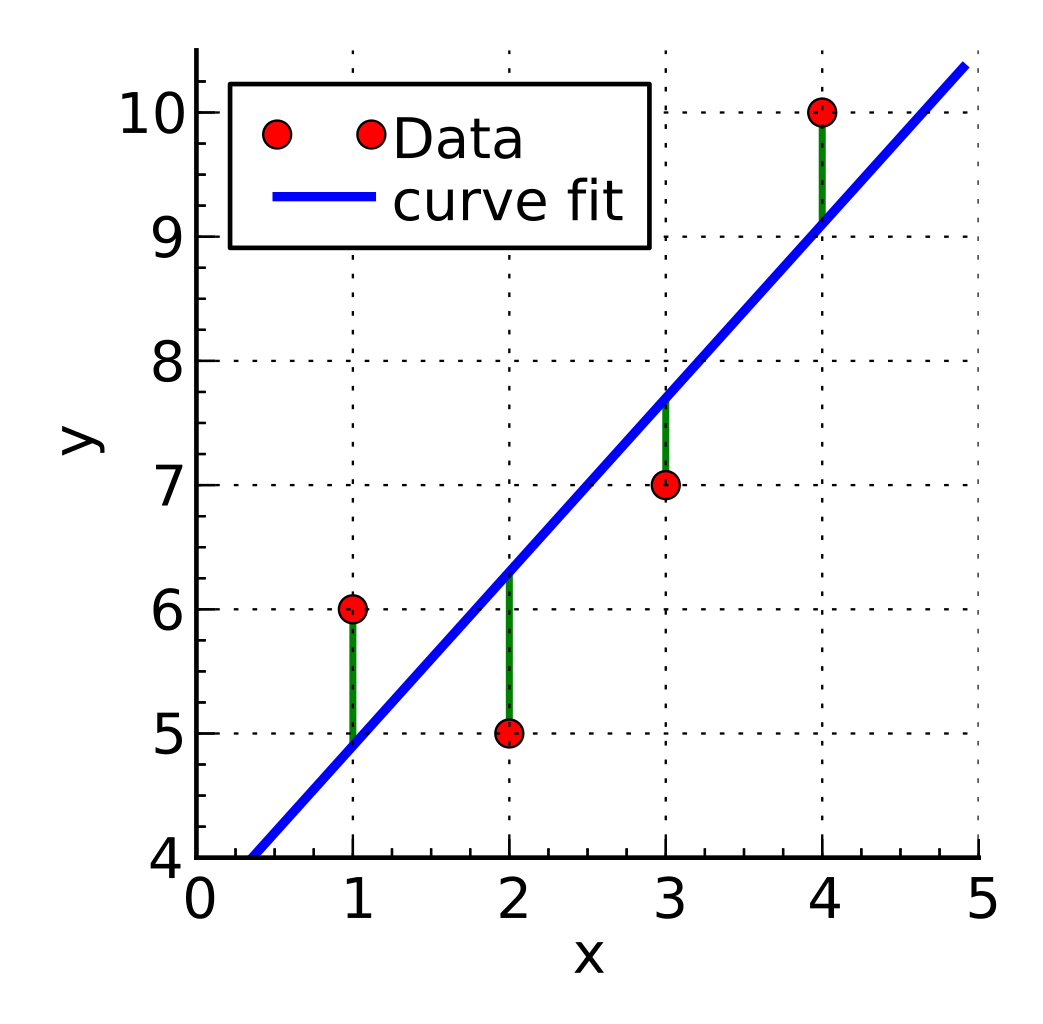
Regression
- Median Absolute Error
- Mean Absolute Error
- Mean Squared Error
- Root Mean Squared Error (RMSE)
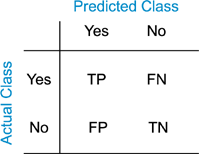
Classification
- Accuracy
- Precision/Recall
- Probability Estimates
Overfitting
- There are better ways to store a dataset than in a random forest
- source: https://commons.wikimedia.org/wiki/File:Overfitting.svg

Overfitting: Why it's a problem
- Generalization
- Misleading analytics
Overfitting: Symptoms
- Test score is too good
- Train score is much better than test score
- Training score is much better than production score
- One feature is too useful
Overfitting: Causes
- Telling the model the future
- Too small a dataset
- Too complex a model
- Data leakage (time series averages- beware!)
Overfitting: Solutions
- Inverse of cause :)
- Simplify model
- Feature selection
- Regularization
Underfitting
- Not scoring very well, even on the training data
- Add in more features
- More data filtering to remove noise
- This is a really powerful step, especially if your data collection itself is messy and relies on human actions
- More complex models
Next Steps
- Set up your dev environment
- Write a SQL query to get some data
- Toss it into auto_ml and see what happens!