Mistakes I've Made
PyData Seattle 2015
Cam Davidson-Pilon

Who am I?
Cam Davidson-Pilon

- Lead on the Data Team at Shopify
- Open source contributer
- Author of Bayesian Methods for Hackers
(in print soon!)
Ottawa
Ottawa
Ottawa?
Case Study 1
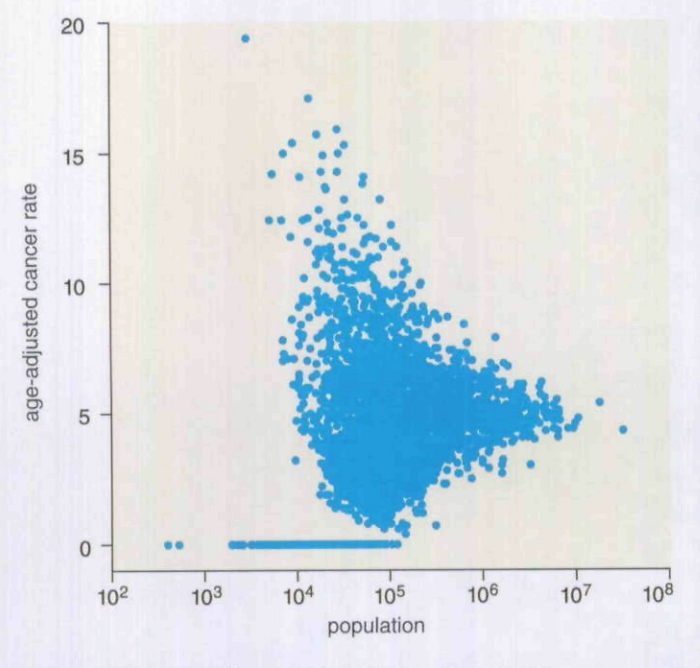
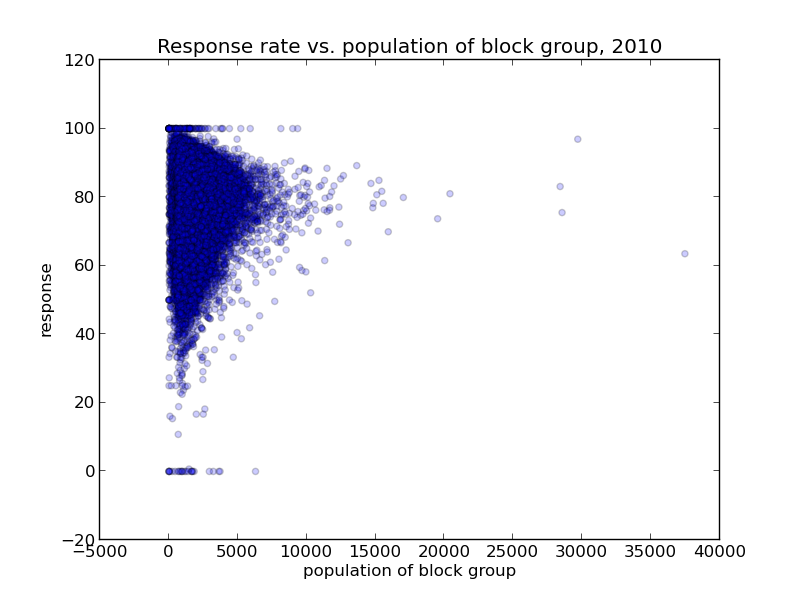
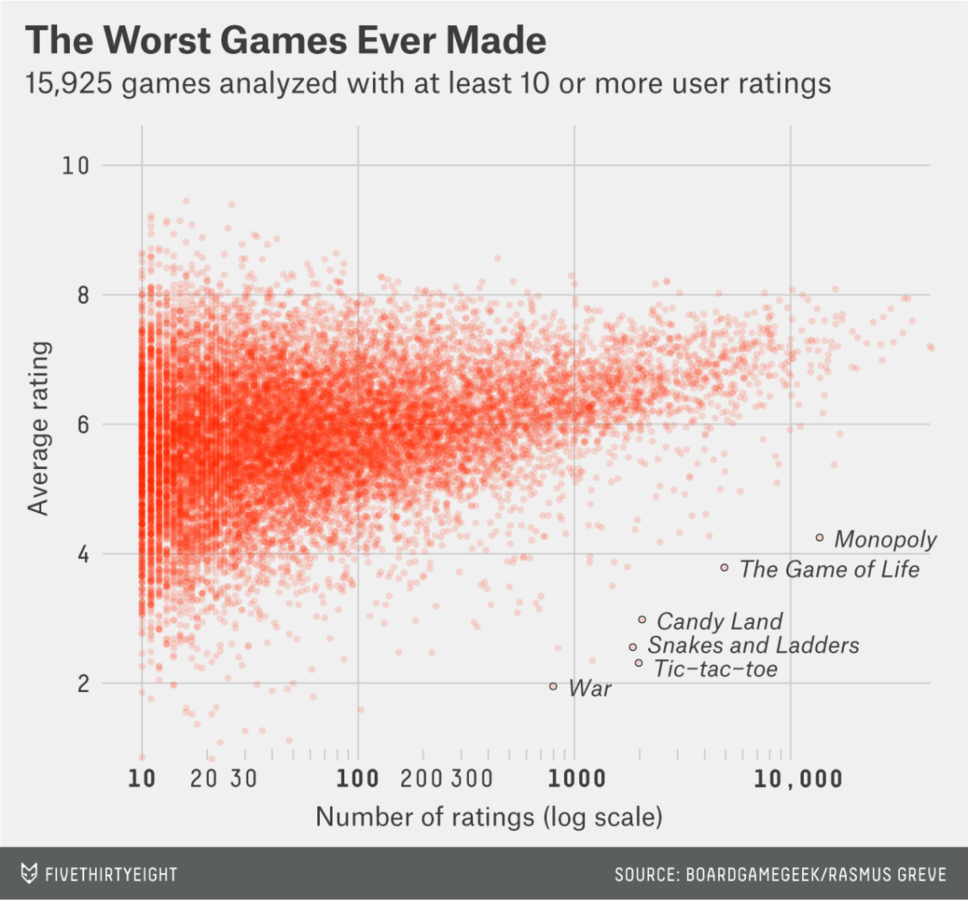
We needed to predict mail return rates based on census data.

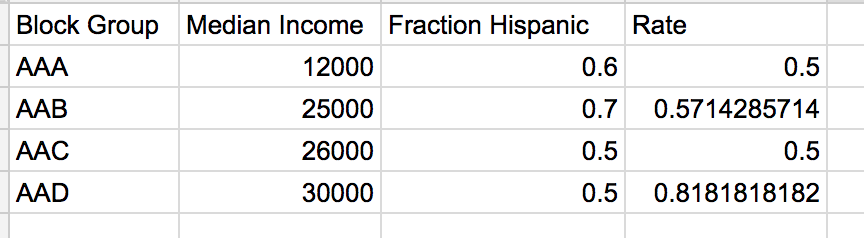
Sample Data (simplified):
Well I'm predicting the rate, so I build that:

Don't need margin of errors...
...then do "data science"

Outcome: failure
What went wrong? At the time, ¯\_(ツ)_/¯

(highly, highly recommended!)
"The std. deviation of the sample mean is equal to the std. deviation of the population over square-root n"
What I learned
- Sample sizes are so important when dealing with aggregate level data.
- It was only an issue because the sample sizes were different, too.
- Use the Margin of Error, don't ignore it - it's there for a reason.
- I got burned so bad here, I became a Bayesian soon after.
Case Study 2

A intra-day time series of S&P, Dow, Nasdaq and FTSE (UK index)
Suppose you are interested in doing some day trading. Your target: UK stocks.
Futures on the FTSE in particular.
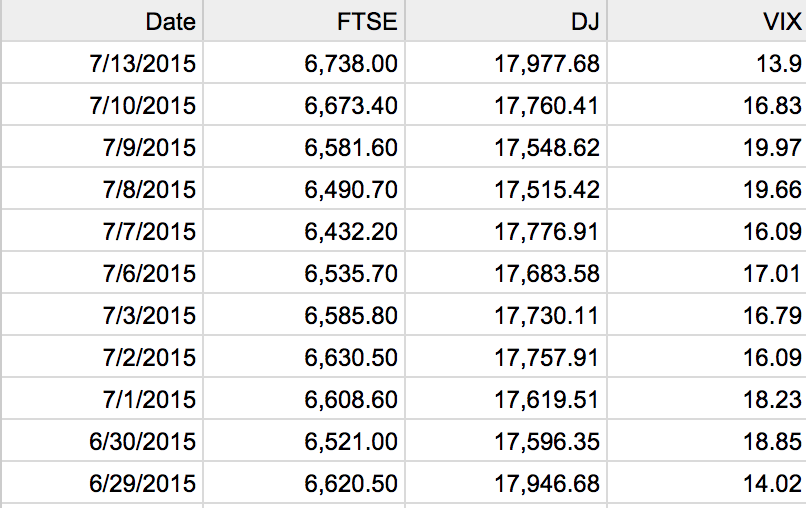
Post Backtesting Results

Push to Production - investing really money

What happened?
Data Leakage happened
What I learned
- Your backtesting / cross validation will always be equal or overly optimistic - plan for that.
- Understand where your data comes from, from start to finish.
Case Study 3

What I learned
- When developing statistical software that already exists in the wild, write tests against the output of that software.
- Be responsible for your software:
Case Study 4

It was my first A/B test at Shopify...
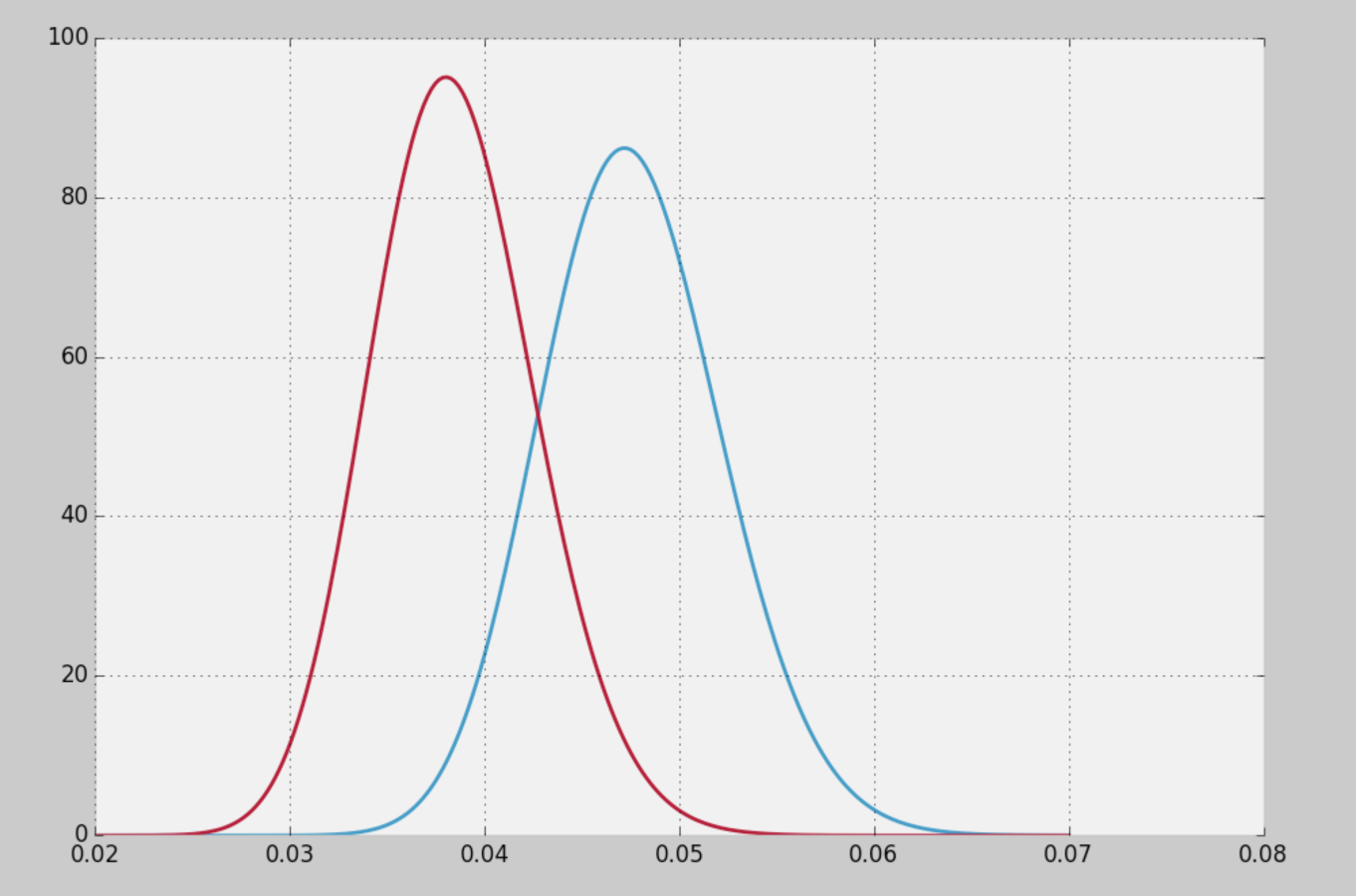
Control group: 4%
Experiment group: 5%
Bayesian A/B testing told me there was a significant statistical difference between the groups...
Upper management wanted to know the relative increase...
(5% - 4%) / 4% = 25%
No.
We forgot sample size again.



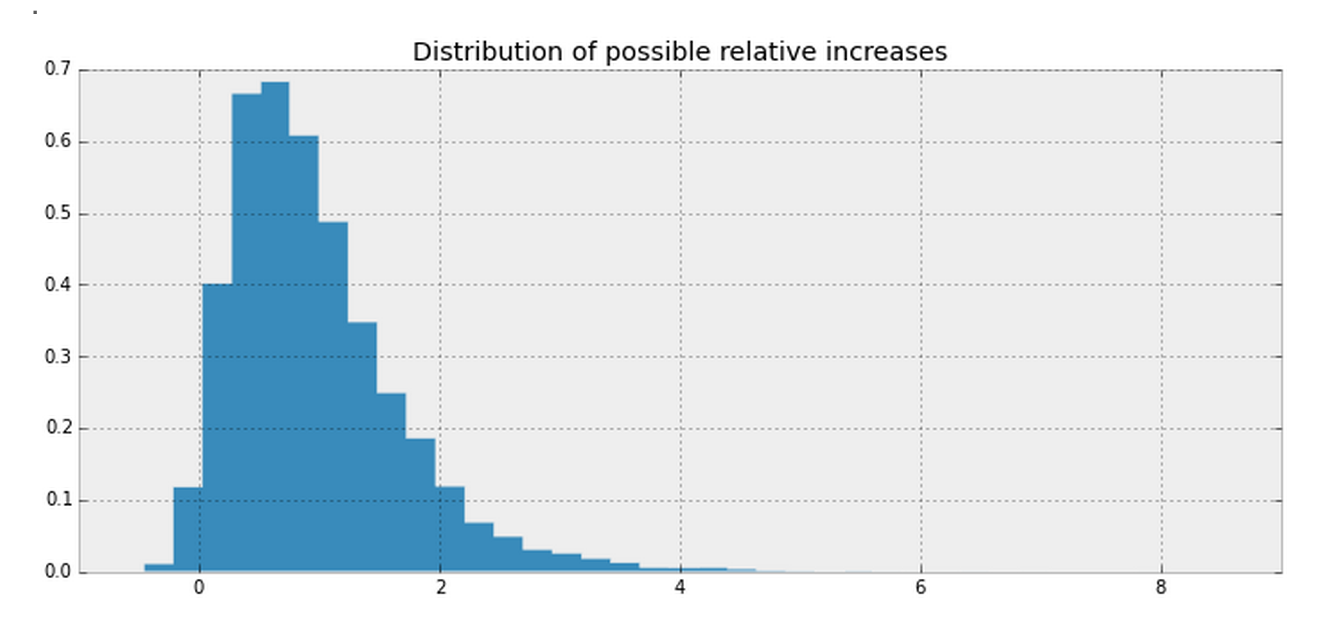
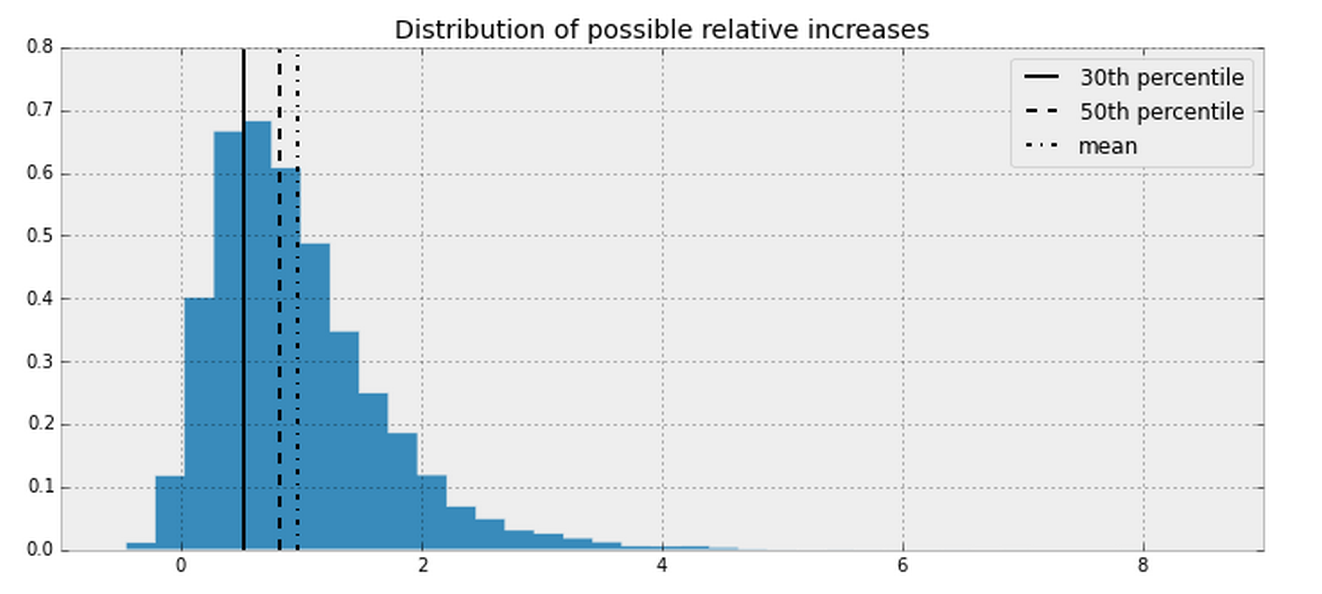
What I learned
- Don't naively compute stats on top of stats - this only compounds the uncertainty.
- Better to underestimate than overestimate
- Visualizing uncertainty is a the role of a statistician.
Machine Learning counter examples
Sparse-ing the solution naively
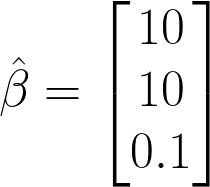
Coefficients after linear regression*:
*Assume data has been normalized too, i.e. mean 0 and standard deviation 1
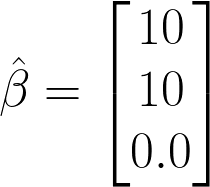
Decide to drop a variable:

Suppose this is the true model...
Okay, out regression got the coefficients right, but...
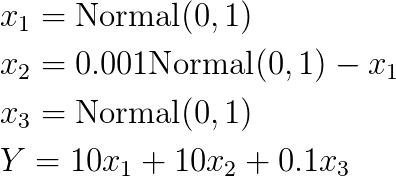
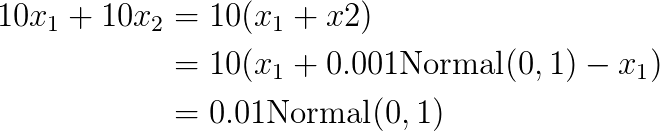
So actually, together, these variables have very little contribution to Y!
Solution:
Any form of regularization will solve this. For example, using ridge regression with with even the slightest penalizer gives:
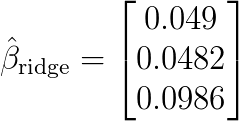
PCA before Regression
PCA is great at many things, but it can actually significantly hurt regression if used as a preprocessing step. How?
Suppose we wish to regress Y onto X and W. The true model of Y is Y = X - W. We don't know this yet.
Suppose further there is a positive correlation between X and W, say 0.5.
Apply PCA to [X W], we get a new matrix:
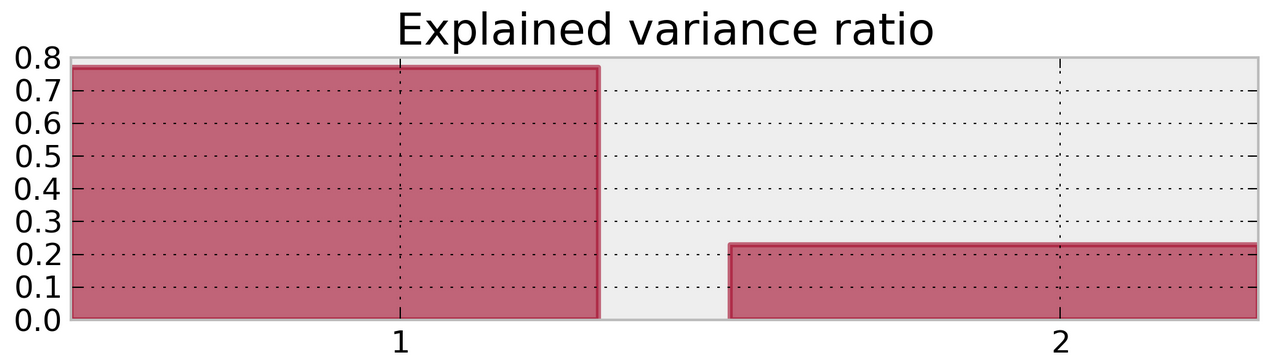
Textbook analysis tells you to drop the second dimension from this new PCA.
So now we are regressing Y onto:
i.e., find values to fit the model:
But there are no good values for these unknowns!
Quick IPython Demo
Solution:
Don't use naive PCA before regression, you are losing information - try something like supervised PCA, or just don't do it.
Thanks for listening :)
@cmrn_dp