How We Matched You to Your CodeLabs Team
Julie Cover, SRND
Watch the slides live on your device!
1. The Problem, and Others Like It
2. My Solution + Algorithm Design
3. Lessons from Another Itteration
The Problem, and
Others Like It
Phase 1: Priorities and Recommendations

Phase 2: Placement
for id, project in all_project_data.items():
if project["proj_size_remaining"] == project["num_first_choice"]:
all_project_data,
student_placements = place_students_of_choice(all_project_data, student_placements,
id, 1,
project["proj_size_remaining"])
for id, project in all_project_data.items():
if project["proj_size_remaining"] >= project["num_first_choice"]:
all_project_data,
student_placements = place_students_of_choice(all_project_data, student_placements,
id, 1,
project["proj_size_remaining"])
_all_project_data = deepcopy(all_project_data)
for id, project in _all_project_data.items():
if project["proj_size_remaining"] >= project["num_first_choice"]:
all_project_data,
student_placements = place_students_of_choice_balanced(all_project_data,
student_placements,
id, [2, 15],
project["proj_size_remaining"])
_all_project_data = deepcopy(all_project_data)
for id, project in _all_project_data.items():
all_project_data,
student_placements = place_students_of_choice_balanced(all_project_data, student_placements,
id, [1, 2],
project["proj_size_remaining"])
for i in range(3, 16, 4):
_all_project_data = deepcopy(all_project_data)
for id, project in _all_project_data.items():
if project["proj_size_remaining"] >= project["num_first_choice"]:
all_project_data,
student_placements = place_students_of_choice_balanced(all_project_data,
student_placements, id,
[i, i + 1, i + 2, i + 3],
project["proj_size_remaining"])Stable Roommates Problem
- Does not require preferences on all members
- Only one group
Stable Marriage Problem
AKA Gale–Shapley algorithm
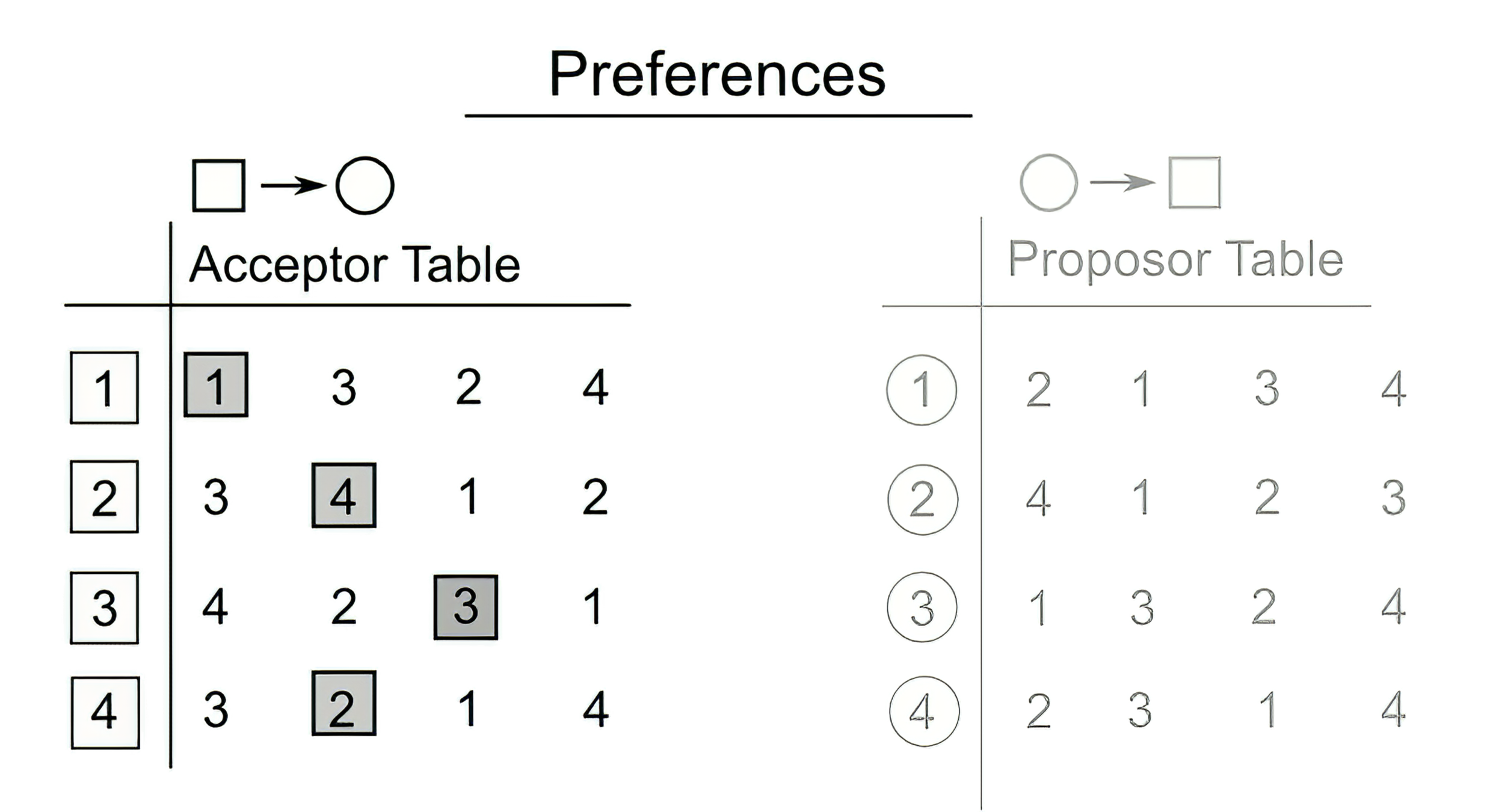

Stable Roommates Problem
- Does not require preferences on all members
- Only one group
Stable Marriage Problem
AKA Gale–Shapley algorithm
My Solution
(with a side of algorithmic design tips)
0. Data Collection
1. Elastic and Suggestions
2. APIs n' Stuff
3. Placement Algorithm
4. Manual Verification
Phase 0: Data
const mentorSchema = {
mentor_id: "",
name: "",
company: "",
bio: "",
backgroundRural: true,
preferStudentUnderRep: 2, (0-2)
okExtended: true,
timezone: -7,
preferToolExistingKnowledge: true,
proj_id: "",
proj_description: "",
proj_tags: [""],
studentsSelected: 2,
};const studentSchema = {
id: "",
name: "",
rural: false,
underrepresented: false,
requireExtended: true,
timezone: -3,
interestCompanies: [""],
interestTags: [""],
beginner: true,
};
Phase 1: Matching w/ Elastic

Phase 1: Matching w/ Elastic
Elastic is great, but also the worst
- Docs are from another era



Phase 1: Matching w/ Elastic
Elastic is great, but also the worst
- Docs are from another era
- Python tooling is hit or miss



=

Phase 1: Matching w/ Elastic
Elastic is great, but also the worst
- Docs are from another era
- Python tooling is hit or miss
- Elasticsearch-DSL
=



Phase 1: Matching w/ Elastic
Elastic is great, but also the worst
- Docs are from another era
- Python tooling is hit or miss
- Elasticsearch-DSL
- Q() Syntax
=
# Lines 56-74
company_q = None
for company in student["interestCompanies"]:
if company_q is None:
company_q = Q(
"function_score",
query=Q("fuzzy", company=company),
weight=company_score,
boost_mode="replace",
)
else:
company_q = company_q | Q(
"function_score",
query=Q("fuzzy", company=company),
weight=company_score,
boost_mode="replace",
)# 111-113
combined_query = Q(
"function_score",
query=combined_query,
functions=SF(
"gauss",
numStudentsSelected={"origin": 0,
"scale": 3,
"offset": 3,
"decay": 0.50
}
)
)Phase 1: Matching w/ Elastic
Elastic is great, but also the worst
=
combined_query = Q(
"function_score",
query=combined_query,
functions=[
SF(
"script_score",
script={
"source": """
int student_tz = params.student_tz;
int mentor_tz = 0;
// Null check. Even though timezone is required, somehow some null rows snuck in and bamboozled me
if (doc['timezone'].size() == 0) {
mentor_tz = 0;
} else {
mentor_tz = (int)doc['timezone'].value;
}
int diff = (int)Math.abs(student_tz - mentor_tz);
boolean mentor_ok_tz_diff = false;
if (doc['okTimezoneDifference'].size() == 0) {
mentor_ok_tz_diff = false;
} else {
mentor_ok_tz_diff = doc['okTimezoneDifference'].value;
}
if (mentor_ok_tz_diff == true) {
if (student_tz > 0) {
// Mentor is OK with the time difference and student has a large time difference
return 1;
} else {
// Mentor is ok with time difference and student has a normal time
return 0.75;
}
} else {
if (diff <= 2) {
// Mentor is not ok with time difference and student has normal time
return 1;
} else if (diff == 3) {
return 0.75;
} else {
// Mentor is not ok with time difference and student has weird time
return 0;
}
}
""",
"params": {"student_tz": student["timezone"]},
},
)
],
boost_mode="multiply",
score_mode="sum",
)
2. Code in strings
3. Lack of Readability
1. Painless Scripts
1. Painless Scripts
4. Debugging is a disaster
5. Breaks the explain function
- Docs are from another era
- Python tooling is hit or miss
- Elasticsearch-DSL
- Q() Syntax
Elastic - What's Your Point?
- Elastic is incredibly powerful
- Solves many unique problems
- Queries themselves are almost language-agnostic
- Complexity is inevitable
- Bad docs and language APIs aren't
- ... probably just buy the book
Phase 2: APIs n' Stuff
It's super easy!

Great for APIs!
Phase 2: APIs n' Stuff
It's super easy!
@app.route("/matches/<student_data>", methods=["GET"])
def matches(student_data):
try:
data = decode(student_data, current_app.jwt_key, algorithms=["HS256"])
except exceptions.DecodeError:
raise Unauthorized("Something is wrong with your JWT Encoding.")
ela_resp = evaluate_score(data, current_app.elasticsearch, 25)
resp = [
{"score": hit._score, "project": hit._source.to_dict()}
for hit in ela_resp.hits.hits
]
return json.dumps(resp)# This is needed to allow the other libraries to import database,
# as python doesn't check in the parent directory otherwise.
currentdir = os.path.dirname(os.path.abspath(
inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
sys.path.insert(0, parentdir)# Store any Object on the App object!!
app.elasticsearch = Elasticsearch(elastic_host)
app.jwt_key = os.getenv("JWT_KEY")
-----------------
from flask import current_app
print(current_app.jwt_key)Phase 2: APIs n' Stuff
It's super easy!

// Sample GET request input
const requestData = {
"id": str(uuid.uuid4()),
"name": "John Peter",
"rural": True,
"underrepresented": False,
"timezone": -4,
"interestCompanies": ['Microsoft', "Google"],
"interestTags": ["Backend", "Data", "python", "php"],
"requireExtended": False,
"track": "Advanced"
}eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjE5NWY2ZDI5LTYyMjYtNDUyNC05ODJmLTc5M2ZhMThlN2ViOSIsIm5hbWUiOiJKb2huIFBldGVyIiwicnVyYWwiOnRydWUsInVuZGVycmVwcmVzZW50ZWQiOmZhbHNlLCJ0aW1lem9uZSI6LTQsImludGVyZXN0Q29tcGFuaWVzIjpbIk1pY3Jvc29mdCIsIkdvb2dsZSJdLCJpbnRlcmVzdFRhZ3MiOlsiQmFja2VuZCIsIkRhdGEiLCJweXRob24iLCJwaHAiXSwicmVxdWlyZUV4dGVuZGVkIjpmYWxzZSwidHJhY2siOiJBZHZhbmNlZCJ9.kZ_LsGQrno3kL5Gm_M9WD1ttFsHz4BO32aAZvAYt5n0Phase 3: Placement Algorithm
1. Start with projects that have the right number of first place votes already. Assign students to those by adding their information to the saved project dictionary. Remove those student's votes from all projects to avoid duplicates, and remove the projects
2. Then, assign first choice votes to students on projects with less first choice votes than the projects need. Also those students votes from other projects. Decrement `proj_size_remaining`.
3. Then, assign second, third, and more choice votes as needed until `proj_size_remaining` = 0, them remove the project. Do this in order, all second place votes, third place votes, and so on so that students get their lowest possible choice. If multiple students are tied, be sure to assign based on which student has the fewest votes left in other projects. Also remember to remove the student from all other projects when their vote is saved.
4. Once all projects with less first choice votes than needed are dealt with, we are left with only projects that started with more than enough first choice votes. These should have exactly the correct number of first choice votes left due to how students have been removed. Assign these students, and complain loudly if something is wrong.
- Multiple Steps - as many as needed
- Verbose, clear, and actionable descriptions
- Build in checks and metrics
- Planning
- Revising / Breaking
- goto 1
- Implementation
- Patching
- Tuning
- Being Done
Phase 3: Placement Algorithm
Or: Jake's Guide to Algorithm Design
"For every n minutes of planning, you save 10n minutes implementing"
- Sun Tzu
Phase 4: Manual Cleanup - Sometimes
Not always possible!
Try to work with others
Speed Round
Thanks for Watching!
Find slides at: