Aqueduct - Data Processing At Scale
Table of Contents
- Introduction
- Guiding Principles
- Pipeline Components

ABOUT ME
Cosmin Catalin Sanda
Data Scientist and Engineer at AudienceProject
Blogging at https://cosminsanda.com
Github at https://github.com/cosmincatalin
AudienceProject
AudienceProject helps brands, agencies and publishers plan, optimize and validate digital campaigns and to activate our customers online audiences in order to deliver reach
in high-value segments.
Timelord - The Old Pipeline
Problems with the old pipeline:
- Slow updates to customers (every two hours)
- Difficult to manage the codebase
- Hard to scale the pipeline to process more data
Aqueduct - The New Pipeline
The new pipeline in turn needed to be:
- Fast to deliver reports (real-time)
- Easy to manage and upgrade
- Easy to scale up and down
- Easy to consume
Eventual Consistency
- Customers get approximate results while the campaign is active
- The longer the campaign the less noticeable the impact of eventual consistency
- After the campaign ends results are always precise
- Failures are acceptable
- Requires resilience
- Creates the conditions for fault tolerance
Idempotence
- Customers' reports never change with time
- Reproducibility and ease of auditing
- Lineage dependencies need to be "pinned"
- Allows backtesting
Incremental Updates
- Allows "out of order" events to be gracefully handled
- Optimized resource usage through minimal processing
- Supports resilience
Processing Elements
Business impact
- Easy to onboard new developers
- Use of functional microservices
- Clearly defined data inputs and data outputs
- Communication only by means of data and not direct API
Scalability
- Scale up and down with no operational impact
- Requires monitoring of services and processing elements
- Scaling horizontally or vertically based on metrics
Simplicity
- Easy to onboard developers
- Small sub-projects with clearly defined purposes
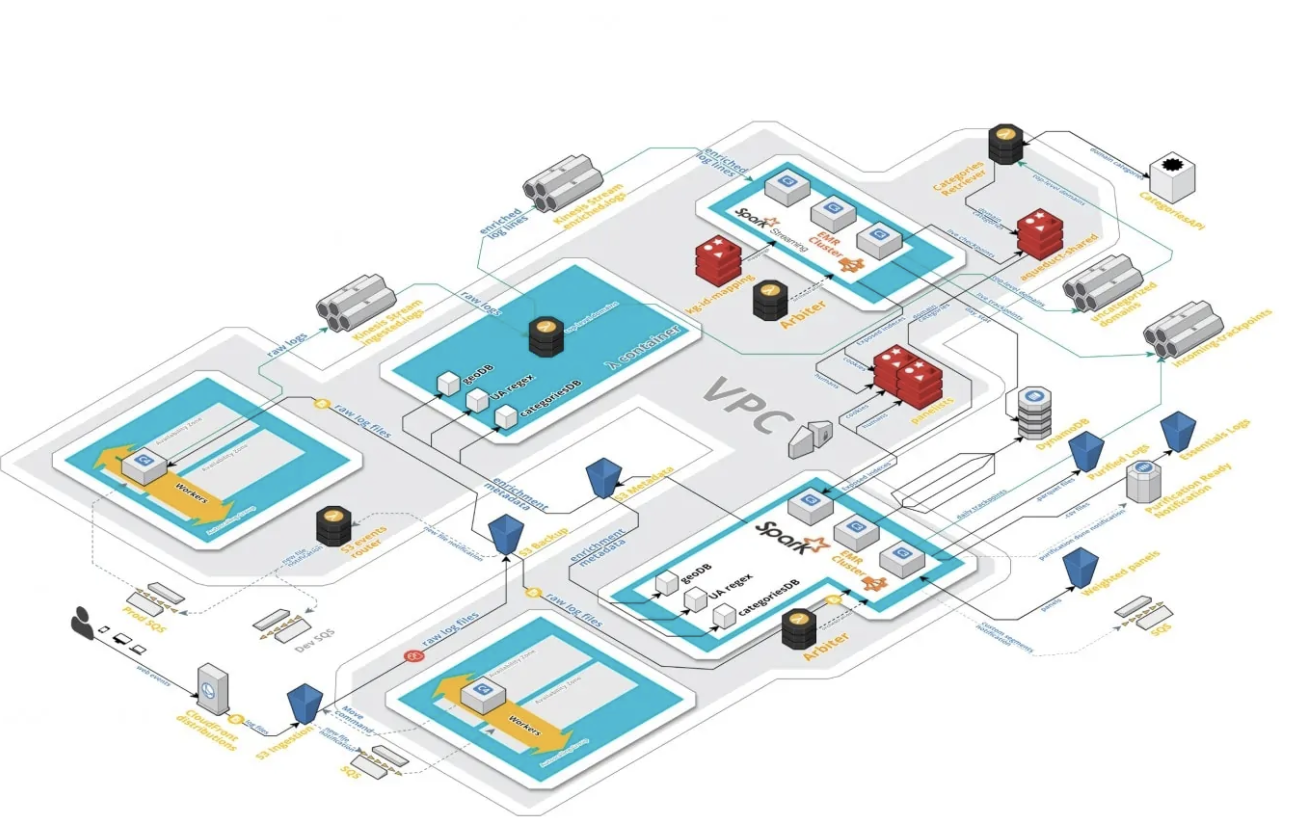
Data Ingestion
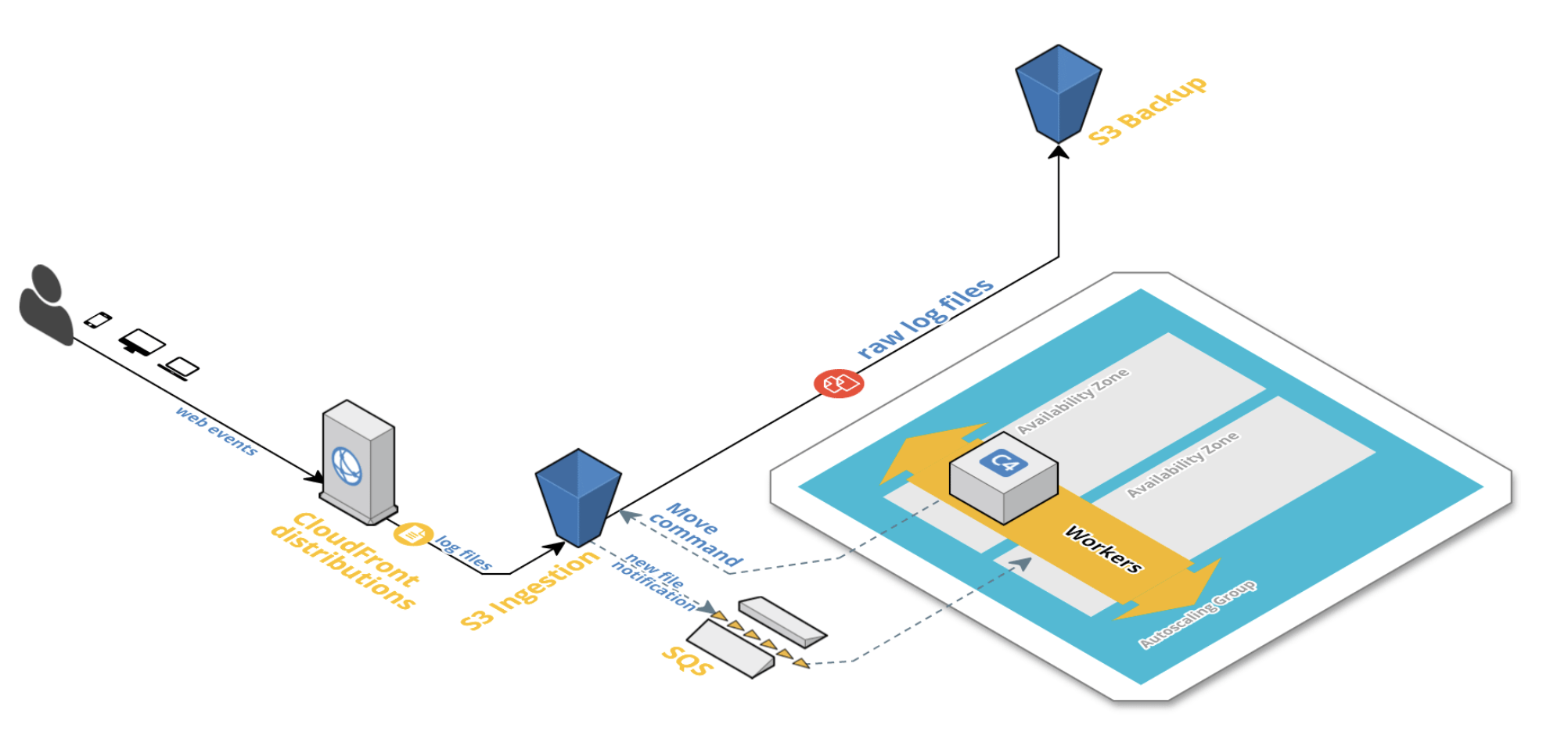
- Events are captured and processed in an average of less than 10 minutes
- Backup is the first concern
- Resilience is built in via retry mechanisms
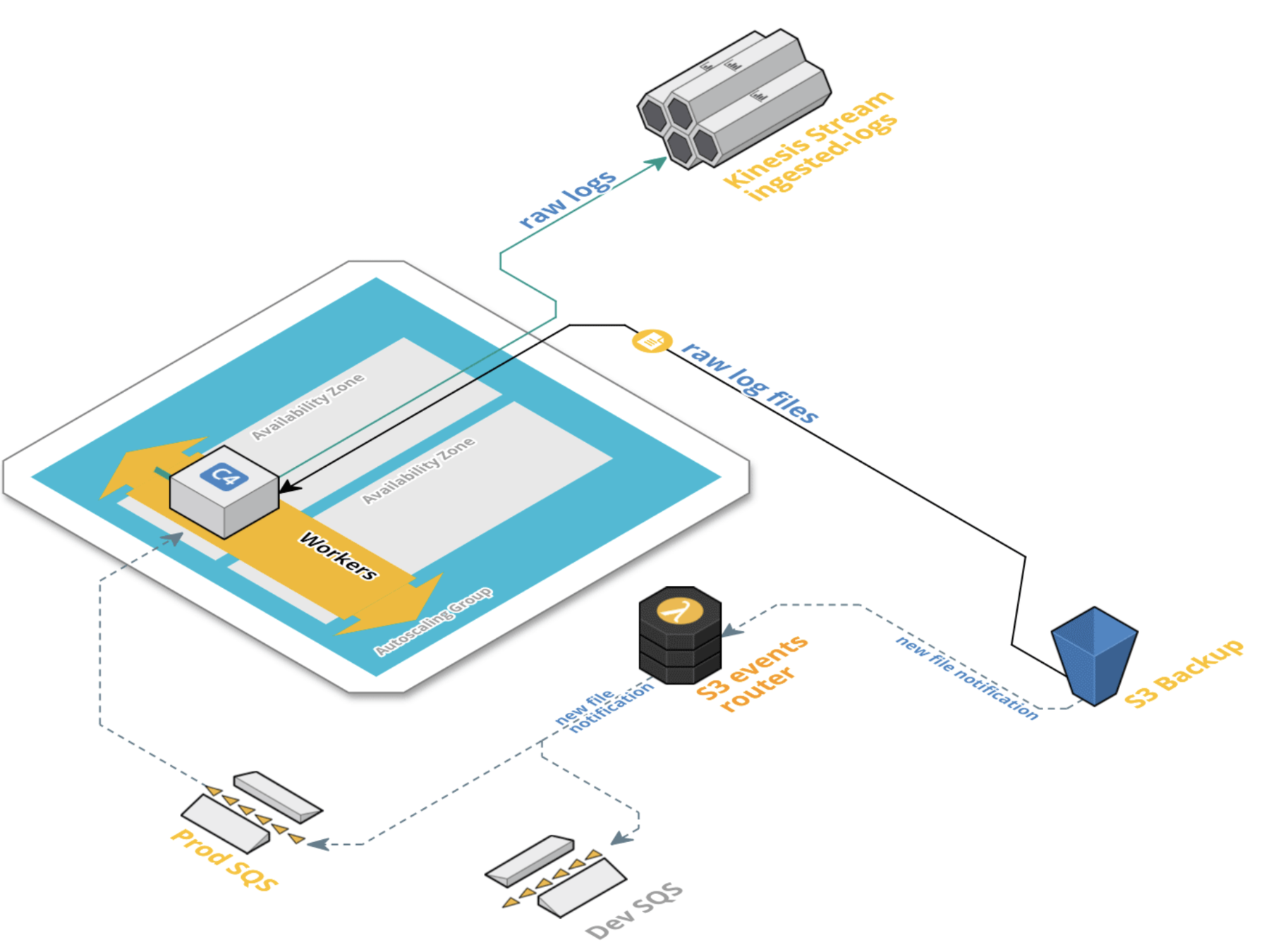
Streaming Data
- Use a message bus to deliver data
- Allows easy creation of a development pipeline
- Data is optimally packed to leverage allocated throughput
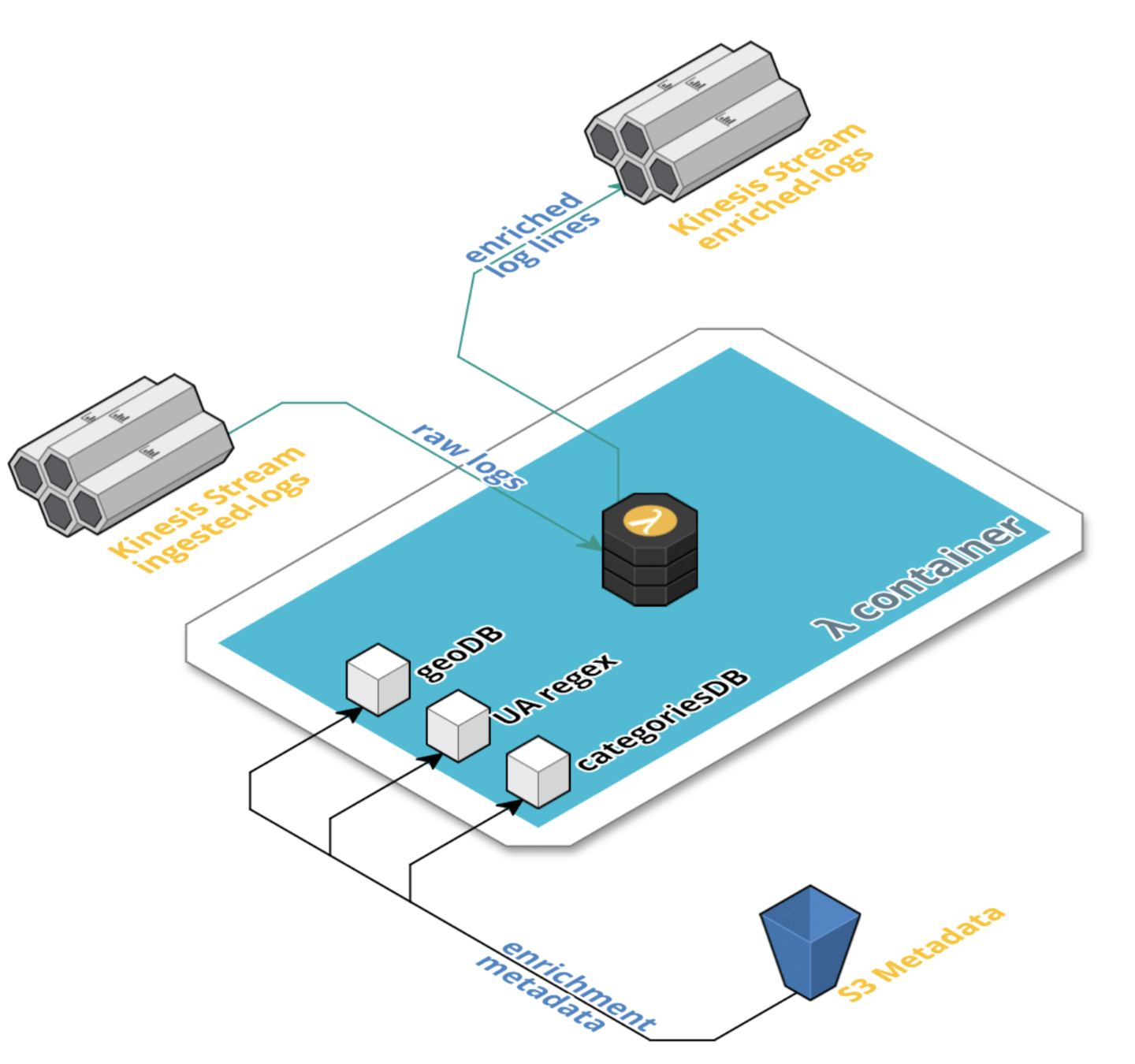
Enriching Data
- Data is enriched via a serverless function
- Metadata pinned for the day it is used
- Scales automatically with the data
Data Processing
- Stream processing in micro batches every 5 minutes
- Low cost by using Spot instances
- Built in resilience
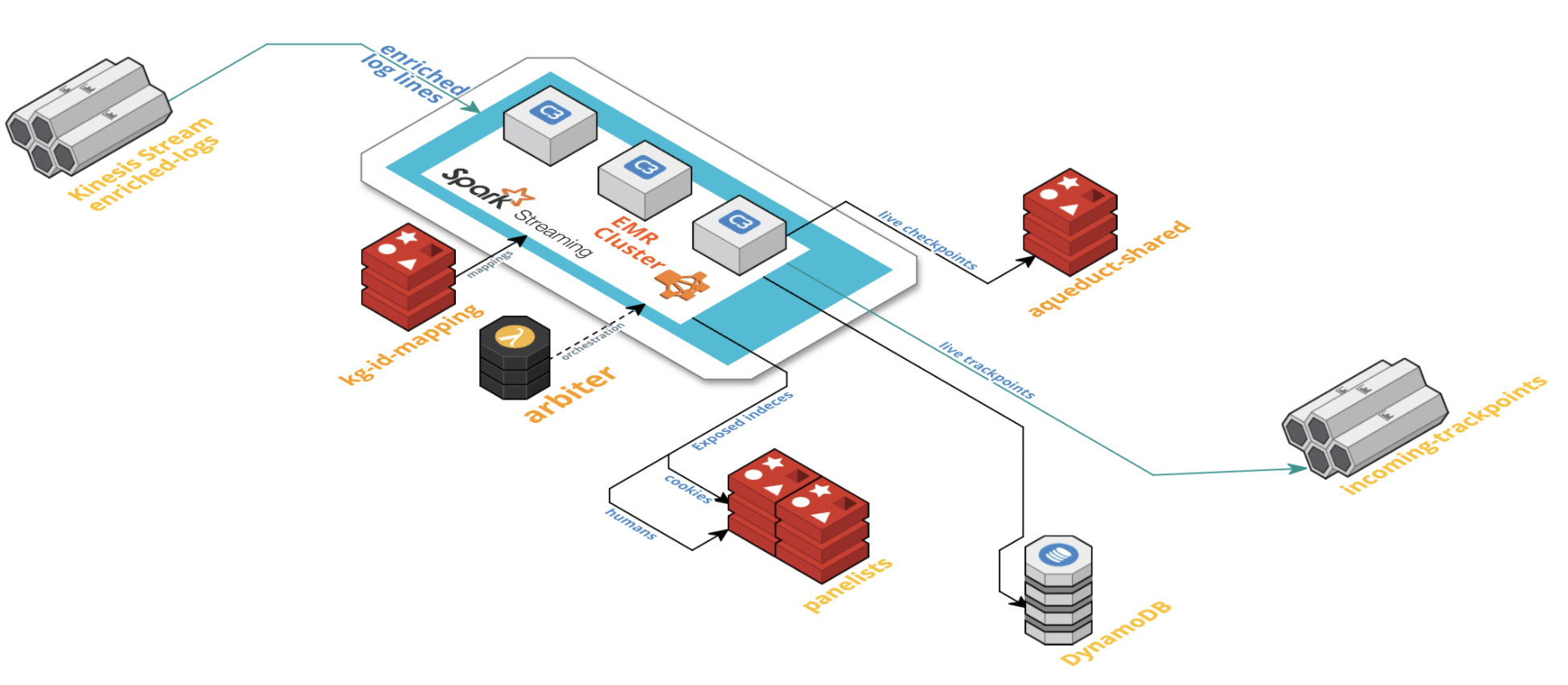
Correction Job
- Reprocesses everything the real-time pipeline does and more
- Pins the versions for the metadata databases
- Locks down aggregation results in place
- Ensures fault tolerance
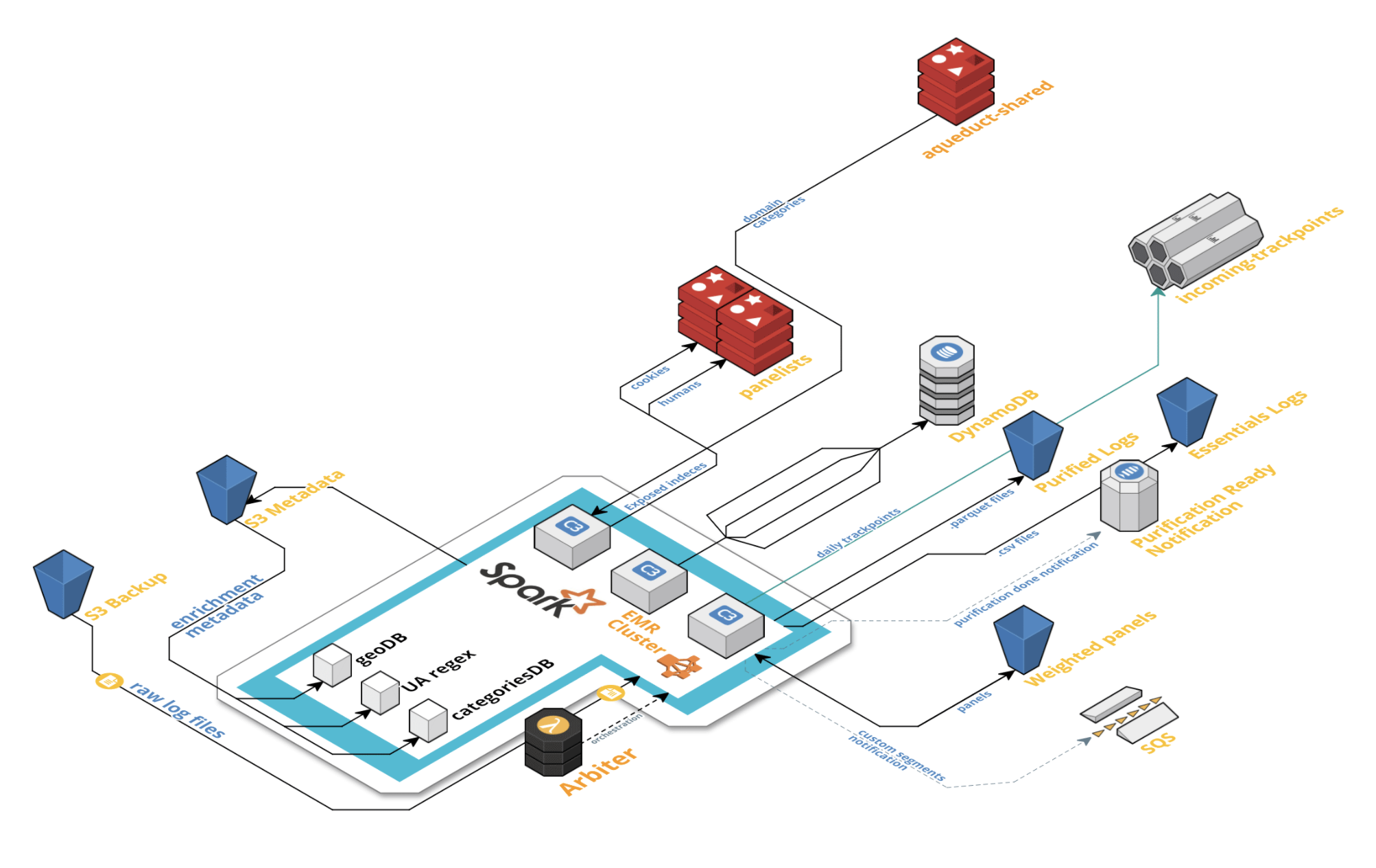
Other concepts
- Architecture is largely based on the Lambda architecture
- Established in 2017, still running today, mostly unchanged