Web Scraping: Con la paciencia hasta el cielo y el scrapeo hasta el suelo
Mauricio Matias C.


Taller con Python

https://github.com/cr0wg4n/web-scraping-workshop
Contenido
- Web 1.0, Web 2.0 y Web 3.0
- Anatomía de la Web
- Métodos de recolección de información con Python
- ¿Qué es el SEO?
- Debate: Limites éticos y responsabilidad del manejo de la información

Web 1.0
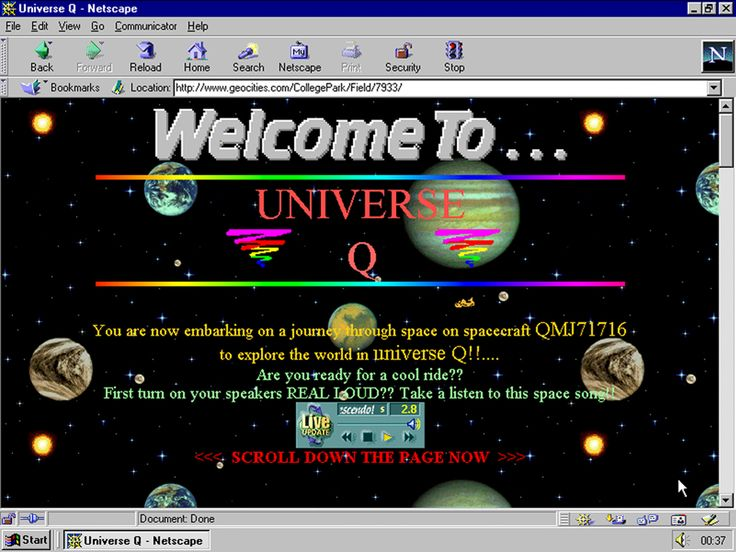
- Páginas estáticas
- Lectura y obtención de información
- Prácticamente unidireccional
- Correo electrónico como medio de comunicación
1990
Web 2.0
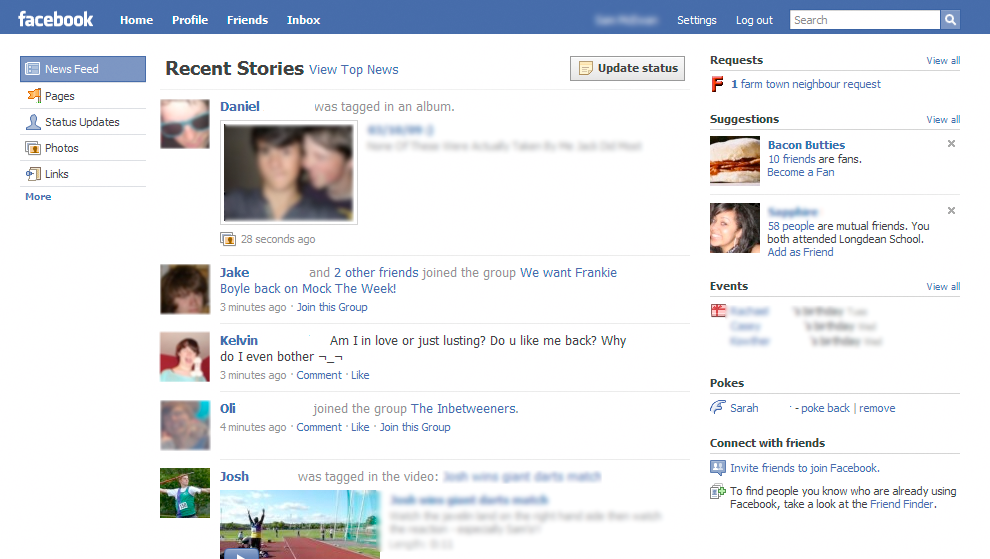

- Páginas dinámicas e interactivas
- Creación de contenido: Foros, wikis, periódicos, blogs..
- Redes sociales y medios sociales
- Aplicaciones web
- Espacios colaborativos
- HTML5, Adobe Flash, Ajax, XML, JSON, Atom, RSS...
1999
Web 3.0?



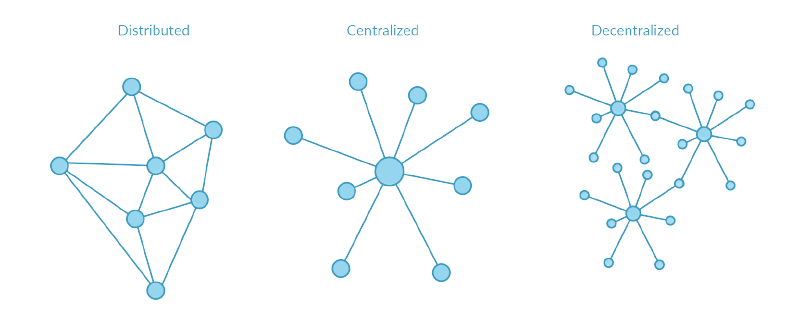

IA
Web 3.0
Web 2.0
Web 1.0

"La fuente de la verdad"
Anatomía de la Web
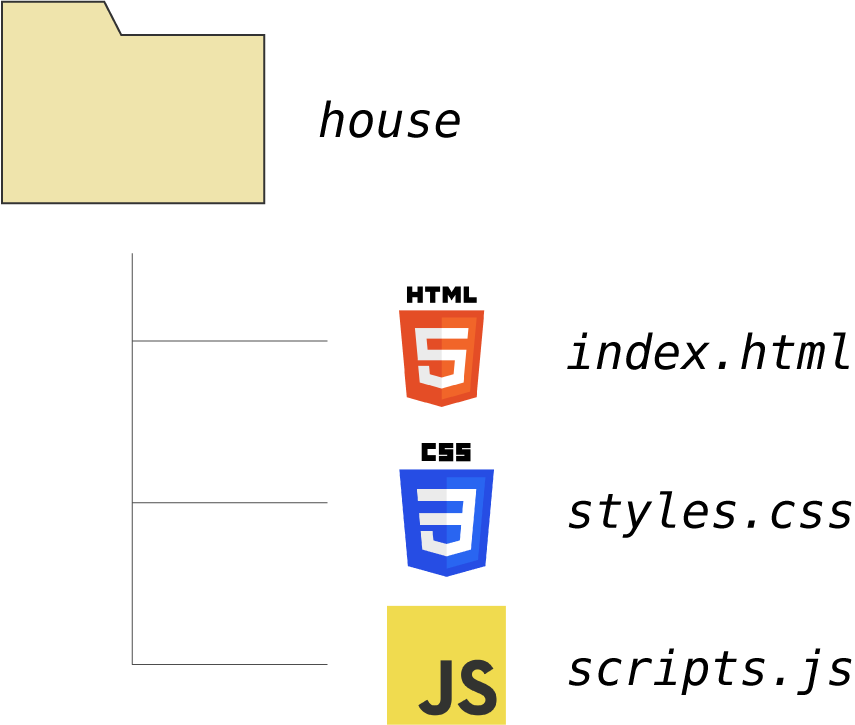
Index.html
Index.css
Index.js
Webpage


Estructura
Estilo / Colores / Figuras ...
Lógica de negocio y dinamicidad
Anatomía de la Web
¿Qué pasa cuando veo un momito?
⚠️ Necesitas establecer comunicación (HTTP/HTTPS)
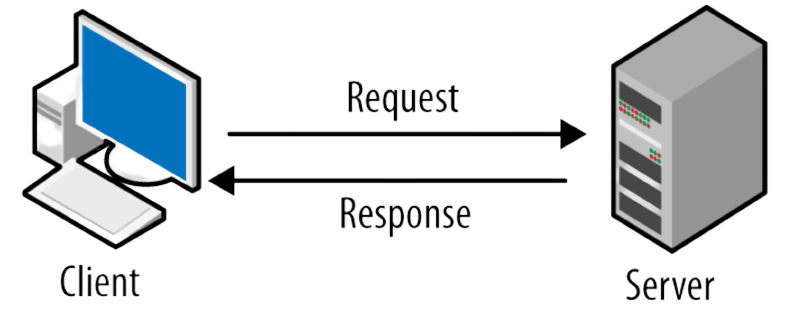
Syn
Syn/Ack
Ack
www.facebook.com
157.240.197.35
Tu maquinita
Anatomía de la Web
¿Qué pasa cuando veo un momito?

GET https://scontent.fcbb1-1.fna.fbcdn.net/v/perritu.png
200 (Ok) perritu.png
GET /
python -m http.server 8000 --directory simple-website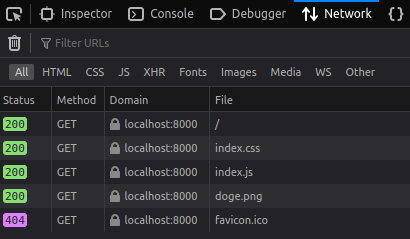
GET index.css
GET index.js
200 (Ok)
200 (Ok)
200 (Ok)
GET favicon.ico
404 (Not found)
🧪 Laboratorio
python -m http.server 8000 --directory complex-websitepython -m http.server 8000 --directory production-like-websiteAnaliza ambos sitios con el inspector web en "Network/Redes"
F12 ó CTRL+SHIFT+I
🧪 Laboratorio en Casa
🧪 Laboratorio
curl "google.com"
curl "https://google.com"Analicemos los resultados
## Verbose (da un resultado mas detallado)
curl -v "https://google.com"
## Sigue redirecciones
curl -L "https://google.com"Un poco de HTML
<img
class="eyebrow-banner-icon d-block width-auto mr-3"
width="44"
height="44"
loading="lazy"
decoding="async"
alt=""
aria-hidden="true"
src="https://github.githubassets.com/ima....copilot-x.svg"
>Atributo/Propiedades
Valor de atributo
Elemento HTML
Un poco de HTML
<p id="main-text" class="h1 text-muted">
Este es un texto aleatorio
</p>
<div class="container center">
<div class="card">
<div class="card__title center">
Lorem ipsum dolor sit amet
</div>
<div class="card__image center">
<img src="doge.png" alt="doge coin">
</div>
<div class="card__content text-justify">
Lorem ipsum dolor sit amet consectetur adipisicing elit.
Provident odio commodi ipsam harum qui omnis eos nis.
</div>
</div>
</div>Atributo
Valor de atributo
Contenido
Toncs.. ¿Qué es Web Scraping?
Una técnica automática para la recolección continua de información a través de la Web
- Páginas web en general
- Blogs
- Periódicos
- RRSS (facebook, instagram, twitter, etc.)
- E-comerce
- Motores de busqueda
- ...
¿Qué es posible recolectar? 🤷♂️
¿Para qué? 😏
- Alimentar bases de datos
- Monitorizar
- Extraer contenido
- Analizar el estado de un sitio:
- Detección de URLs
- Manejo del SEO
- Detección de cambios
- Analítica empresarial
¿Qué necesito saber? 🤔
- Como funciona HTTP y la Web
- Como funciona las cookies
- Como funcionan los navegadores
- HTML y JavaScript
- Lenguaje de programación (Python)
- beautifulsoup4, Puppeteer, Selenium, Playwright
- Regex
Algunas Herramientas Extra 🛠️
- Dev Station Extension (extensión de navegador)
- Wappalyzer (extensión de navegador)
- curl, insomnia, postman, jq
- Regex tester https://regex101.com/
- XML parser https://jsonformatter.org/xml-parser
Live Code
Nuestro Objetivo...?
- Recolectar noticias diariamente
- Las noticias serán extraídas de Los Tiempos
🧪 Laboratorio
La paciencia hasta el cielo..
- Utiliza distintos User-Agents
- Reduce tu velocidad intencionalmente
- Usa un pool de proxies
- Limpia tus cookies
- Controla los errores en tu código (usa try-catch)
- Ten un segundo plan
Puede fallar muchas veces así que:
Con Limites Éticos
- Respeta los términos de servicio
- Respeta los derechos de autor, propiedad intelectual, privacidad y datos personales
- Limita la carga, quieres scrapear no hacer DDoS
- https://gdpr-info.eu
- https://gdpr-info.eu/art-14-gdpr/
- https://www.octoparse.com/blog/gdpr-compliance-in-web-scraping
Y el scrapeo hasta el suelo....
