INTRODUCCION A DEEP LEARNING
Deep Learning - Clase 1
Cristóbal Silva
¿Qué es Deep Learning?
Inteligencia Artificial
Machine Learning
Deep Learning
Agentes que aprenden a imitar "comportamiento inteligente"
Algoritmos que aprenden a partir de datos
Aprendizaje basado en Redes Neuronales con grandes cantidades de datos

1998 - LeNet 5
2012 - AlexNet
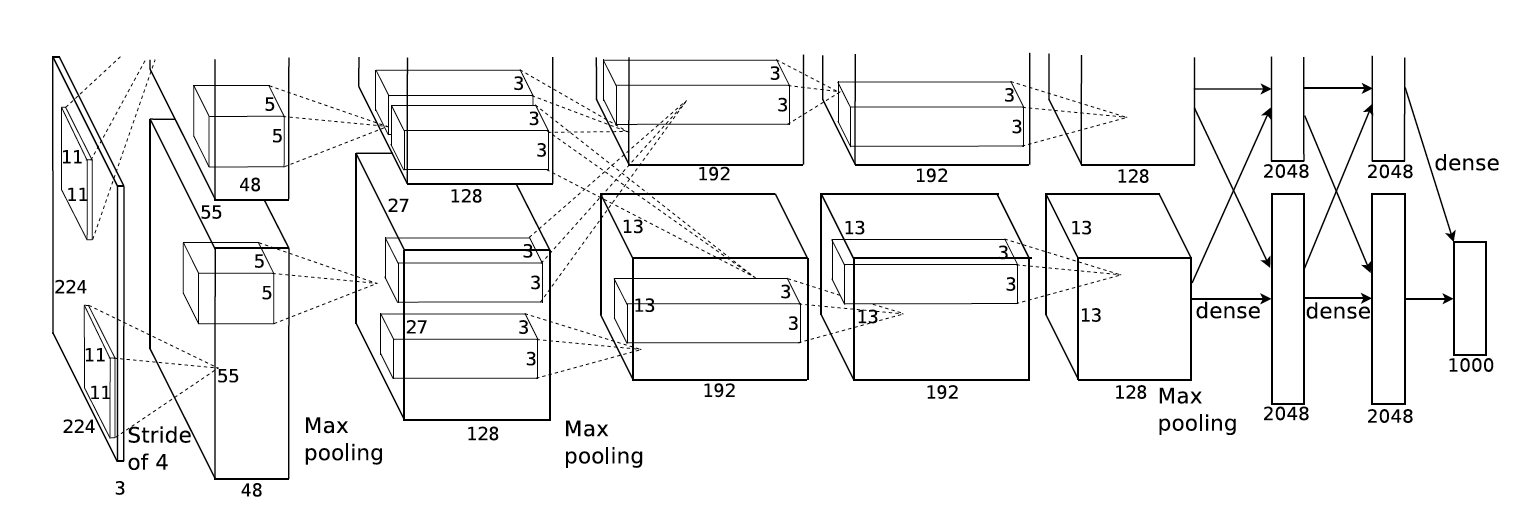

Contexto histórico
¿Qué han logrado desde entonces?

Detección de objetos en ambientes no controlados
Mask R-CNN (Facebook)
¿Qué han logrado desde entonces?
Modelos para generar voz
Mejor resultado antes de Deep Learning
WaveNet (Google Deepmind)
¿Qué han logrado desde entonces?
Transferencia de estilo
Deep Image Analogy (Microsoft)
¿Cómo lo logra?
No necesitamos diseñar features
Capa 1
Capa 2
Capa 3
bordes, esquinas
ojos, narices, bocas
partes de rostros
¿Cómo lo logra?
Tenemos más recursos que antes
Datos
Hardware






Frameworks






La mayoría respaldados por grandes compañías
Frameworks
Se basan en la idea del grafo computacional
a
b
u=a+b
v=3*b
f=u*v
Podemos calcular cualquier operación, e.g., el forward-pass de una red neuronal
¿cómo calculamos del backward-pass?
Frameworks
Se basan en la idea del grafo computacional
a
b
u=a+b
v=3*b
f=u*v
Se descompone cada derivada usando la regla de la cadena
Frameworks
Se basan en la idea del grafo computacional
a
b
u=a+b
v=3*b
f=u*v
Se descompone cada derivada usando la regla de la cadena
Frameworks
Se basan en la idea del grafo computacional
a
b
u=a+b
v=3*b
f=u*v
Se calcula como la magnitud del cambio desde un nodo hacia otro
Frameworks
Se basan en la idea del grafo computacional
a
b
u=a+b
v=3*b
f=u*v
Se calcula como la magnitud del cambio desde un nodo hacia otro
Frameworks
Se basan en la idea del grafo computacional
5
3
u=5+3
v=3*3
f=8*9
Frameworks
Se basan en la idea del grafo computacional
5
3
u=5+3
v=3*3
f=8*9
Propuesta: formular regresión logística en grafo
Frameworks
Regresor
Función de Costo
Frameworks
Se basan en la idea del grafo computacional
Varias formas de calcular una derivada
Diferenciación Numérica
Diferenciación Automática
Diferenciación Simbólica
Aproximación vía diferencias finitas
Se define la derivada de cada operación
Similar a la diferenciación simbólica, pero esta explota la estructura del grafo para evitar cálculos redundates
Hoy en día la mayoría de los frameworks usa diferenciación automática
Variantes o mejoras sobre el Descenso de Gradiente
Algoritmos de Optimización
Momentum
Adagrad
Adadelta
RMSProp
Adam
Agrega un término de "aceleración" al Descenso de Gradiente estocástico
Tasa de aprendizaje adaptiva, distinta para cada parámetro
Tasa de aprendizaje adaptiva, distinta para cada parámetro, extensión de Adagrad
Tasa de aprendizaje adaptiva, distinta para cada parámetro, más un término similar al de Momentum
Tasa de aprendizaje adaptiva, distinta para cada parámetro, extensión de Adagrad
Cada una tiene sus ventajas y sus propios hiper-parámetros
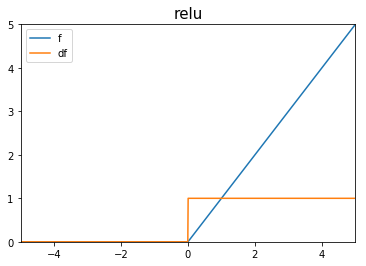
- Función no-lineal recomendada para capas ocultas [1].
- Derivada amigable con descenso de gradiente a pesar de no ser diferenciable en 0.
- "Construir cosas complejas a partir de cosas simples".
Rectified Linear Unit (ReLU)
Glorot et. al.; Deep Sparse Rectifier Neural Networks; Machine Learning Research; 2011
Funciones de Activación
Leaky ReLU
Funciones de Activación
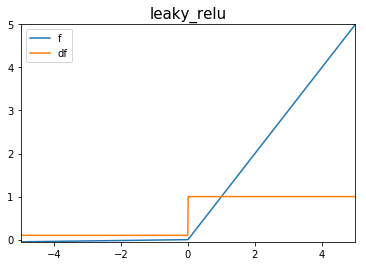
Sirven como alternativas
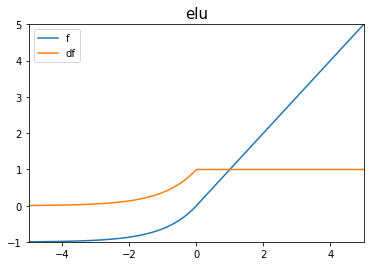
ELU (Exponential Linear Unit)
\((a = 1)\)
Funciones de Activación
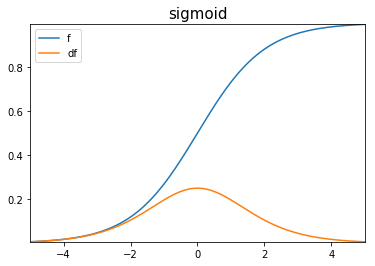
- No recomendada para capas intermedias.
- Ideal para clasificación binaria.
Sigmoidea
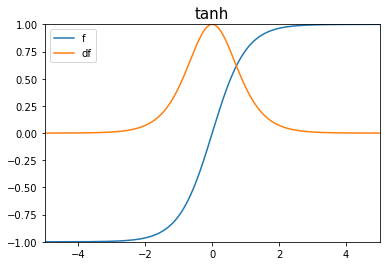
Tangente Hiperbólica
Funciones de Activación
- No recomendada para capas intermedias.
- Simétrica en 0, a diferencia de la función sigmoidea
- Antes de que se usaran ReLU, esta función era una buena alternativa para capas ocultas ya que su gradiente se comportaba mejor que la sigmoide en esos casos
Deep Learning Bayesiano
Podemos ver la red neuronal como un modelo probabilístico paramétrico
Optimizar usando Máxima Verosimilitud
Si definimos el costo como la log-verosimilitud negativa, entonces:
La capa de salida define la función de costo
Deep Learning Bayesiano
Podemos ver la red como un modelo paramétrico probabilístico
Optimizar usando Máxima Verosimilitud
Si definimos el costo como la log-verosimilitud negativa, entonces:
Deep Learning Bayesiano
Podemos separar la capa de salida de las capas intermedias (features)
Salida capas ocultas
\(\mathbf{x}\)
\(h(\mathbf{x};\theta)\)
\(y(\mathbf{h};W)\)
Deep Learning Bayesiano
Tipo
Continua
Binaria
Discreta
Capa
Lineal
Sigmoidea
Softmax
Distribución
Gaussiana
Bernoulli
Categórica
Se puede definir con...
Asumiendo una...
Salida...
Deep Learning Bayesiano
Capa de salida Lineal
Sirven para definir la media de una distribución Gaussiana
Maximizar verosimilitud es minimizar MSE
Deep Learning Bayesiano
Capa de salida Sigmoidea
Se define para problemas de clasificación binaria (Bernoulli)
Notemos que la sigmoidea es buena no solamente por estar entre 0 y 1, también posee gradientes fuertes cuando la predicción es errónea
Deep Learning Bayesiano
Capa de salida Softmax
Se define para problemas multi-clase
Modelos Generativos
Modelos generativos que tienen interpretación probabilística
- Autoencoders Variacionales
- Encuentra representación latente donde \(p(z)\) es una distribución generadora de muestras, usualmente \(\mathcal{N}(0,1)\)
-
Generative Adversarial Networks (GANs)
- Entrenan dos redes
- Un generador \(G(z)\) que intenta replicar la distribución de los datos reales
- Un discriminador \(D(x)\) que determina si la entrada proviene de los datos reales o fue creada por el generador
- Las redes compiten hasta llegar a un equilibrio
- Entrenan dos redes
Programación Probabilística
Frameworks de Deep Learning han permitido desarrollar librerías de programación probabilística
- Edward
- GPflow
- Pyro
- ProbTorch
- PyMC3
Inferencia Variacional
Markov-Chain Monte-Carlo
Procesos Gaussianos
Modelos Bayesianos Jerárquicos
Modelos Lineales Generalizados
Referencias
Arquitecturas
- He et. al.; Mask R-CNN; International Conference on Computer Vision (ICCV); March 2017
- Liao et. al.; Visual Atribute Transfer through Deep Image Analogy; ACM Transactions on Graphics; July 2017
- Oord A. et. al.; WaveNet: A Generative Model for Raw Audio; arXiv pre-print; 2016
Métodos de Optimización
- Qian et. al.; On the Momentum Term in Gradient-Descent Algorithmns; Neural Networks; January 1999
- Duchi et. al.; Adaptive Subgradient Methods for Online Learning and Stochastic Optimization; Journal of Machine Learning Research; July 2011
- Zeiler M.; ADADELTA: An Adaptive Learning Rate Method; arXiv pre-print; 2012
- Kingma et. al.; Adam: A Method for Stochastic Optimization; International Conference on Learning Representations; 2015
Referencias
Otras referencias
-
Deep Learning Book,
Goodfellow I., Bengio Y., Courville A.,
MIT Press, 2016 -
Deep Learning Specialization,
Deeplearning.ai, - Introduction to Deep Learning,
MIT 6.S191, 2017