Abacus FWAM Presentation
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
Lehman Garrison (SCC, formerly CCA)
FWAM, High-Performance Computing Case Study
Oct. 28, 2022
https://github.com/lemmingapex/N-bodyGravitySimulation
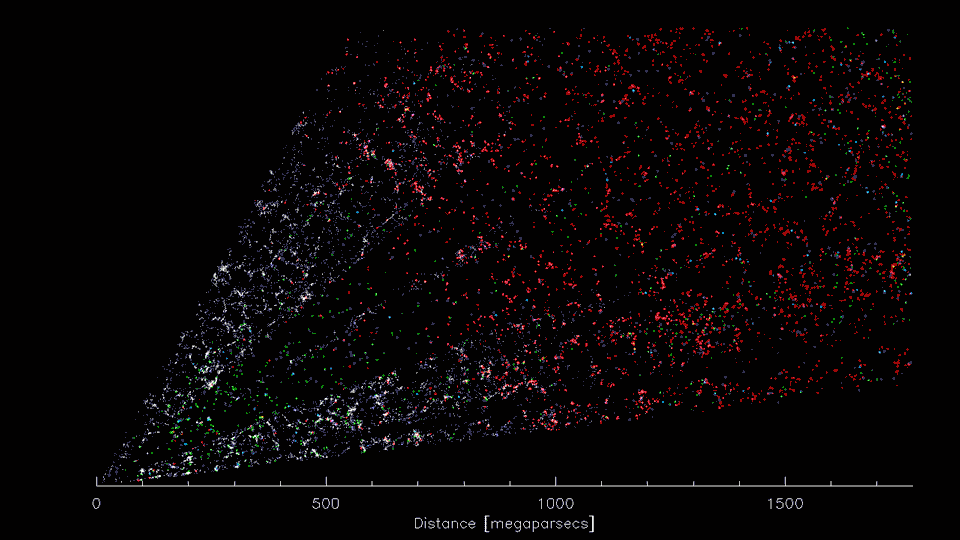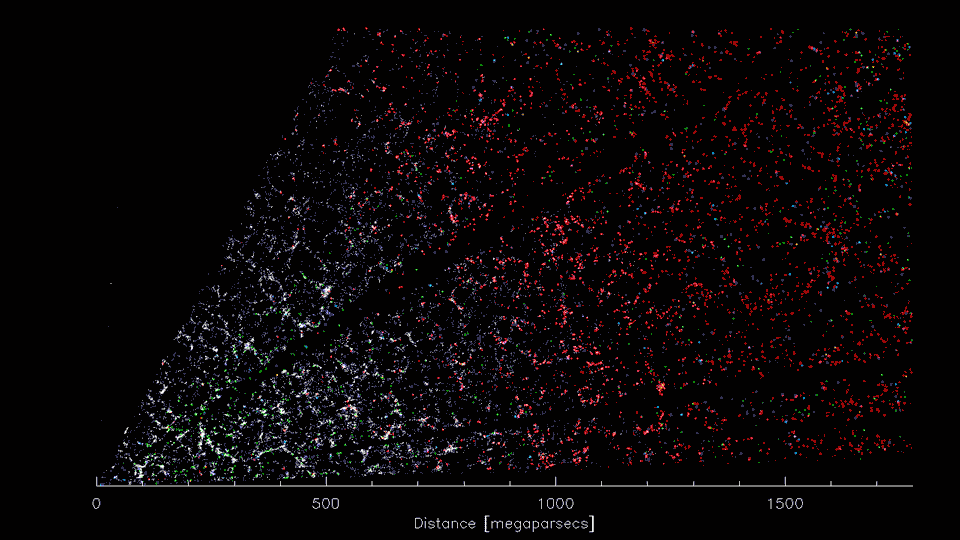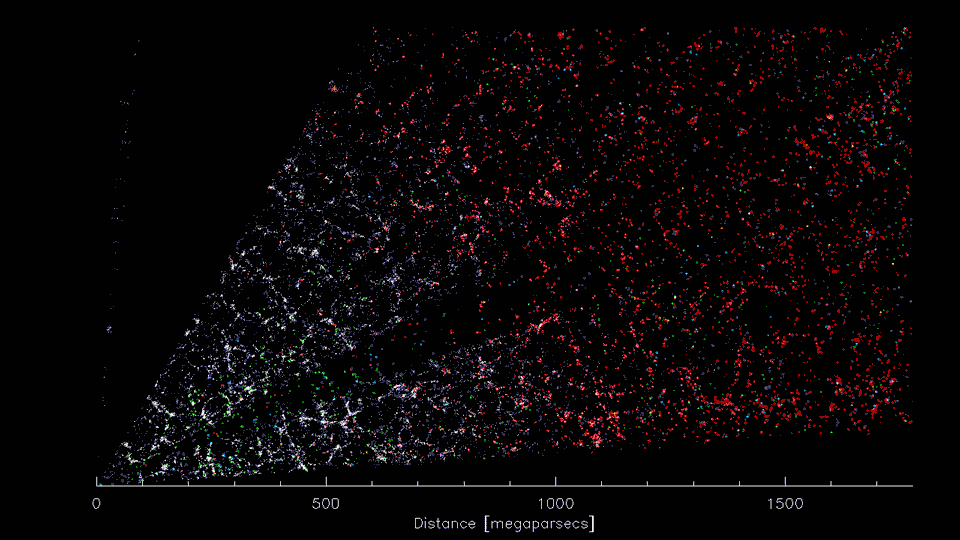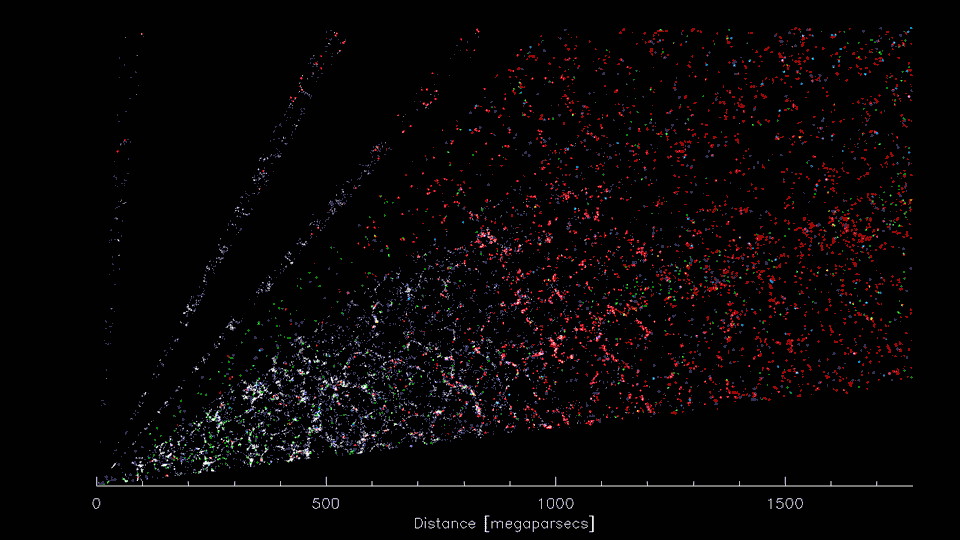
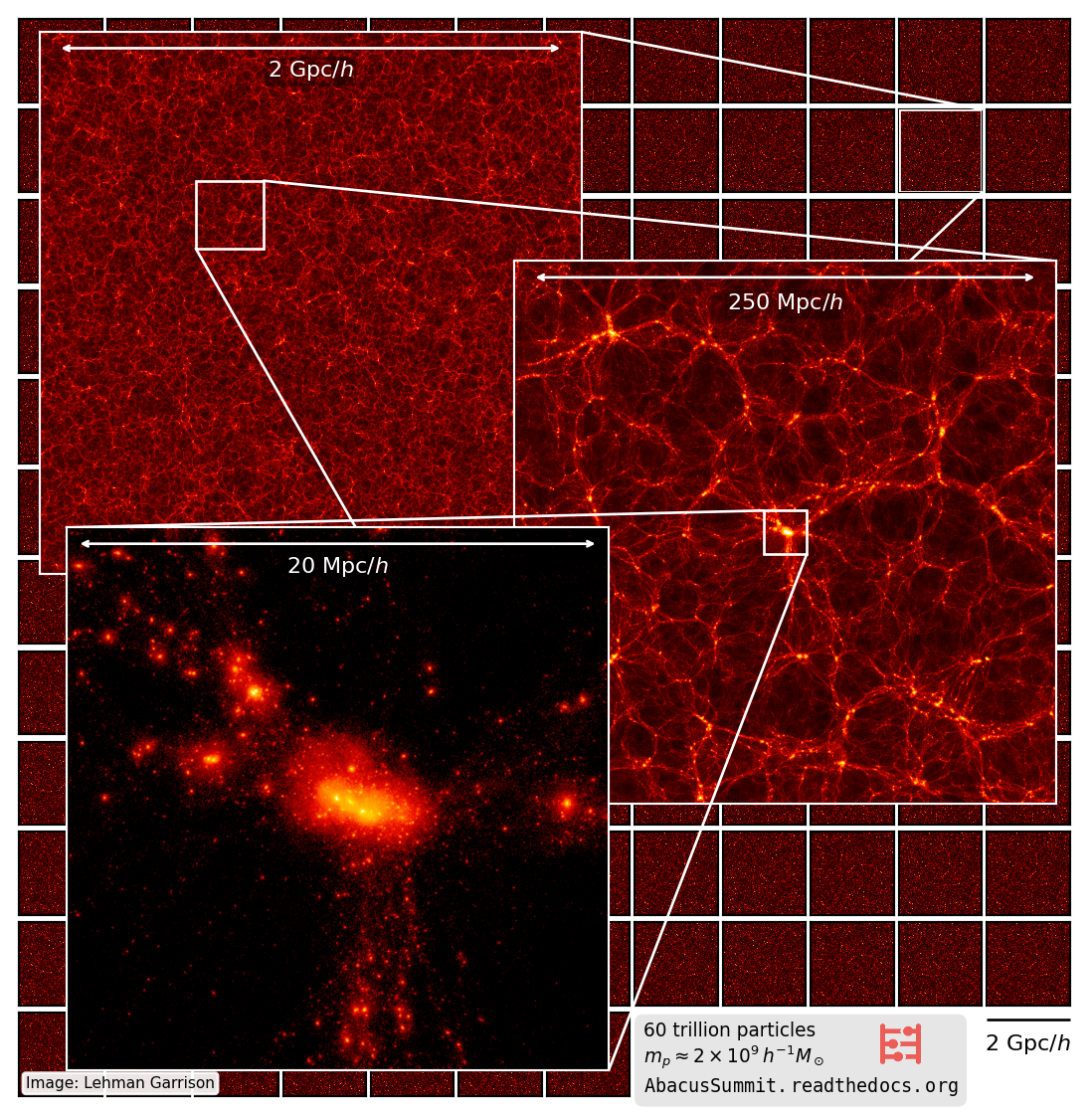
First 8 weeks of DESI Survey data (2021; Credit: D. Schlegel/Berkeley Lab)
Telescope surveys see that galaxies cluster together, forming a "cosmic web"
Credit: Benedikt Diemer & Phil Mansfield
Abacus cluster in the Harvard Astro Dept. basement
Lesson #0: Don't cook your hard drives
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
\(X\)-axis
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Far-field
force
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Far-field
force
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Near-field
force (GPU)
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Near-field
force (GPU)
Far-field
force
Kick/Drift/
Multipoles
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Near-field
force (GPU)
Far-field
force
Kick/Drift/
Multipoles
Write
Slab 7
Slab 6
Slab 5
Slab 4
Slab 3
Slab 2
Slab 1
Read
Near-field
force (GPU)
Far-field
force
Kick/Drift/
Multipoles
Write
void slab_pipeline(){
while(!Finish.doneall()){
if(LaunchRead.precondition()) LaunchRead.action();
if(NearForce.precondition()) NearForce.action();
if(FarForce.precondition()) FarForce.action();
if(Kick.precondition()) Kick.action();
if(Drift.precondition()) Drift.action();
if(Finish.precondition()) Finish.action();
}
}
class NearForce : Stage {
int precondition(int slab){
for(int i = -RADIUS; i <= RADIUS; i++){
if(!Read.done(slab+i)) return 0;
}
return 1;
}
void action(int slab){
SubmitToGPU(slab);
}
};
Abacus used to use static scheduling, but started choking on load balancing in big sims
Socket 1
Socket 2
CPU 1
CPU 1
CPU 2
CPU 3
CPU 3
CPU 4
void KickSlab(int slab){
#pragma omp parallel for schedule(???)
for(int j = 0; j < nrow; j++){
KickRow(slab,j);
}
}
CPU 2
CPU 4
#define NUMA_FOR(N)
_next_iter[0] = 0; // node 0
_last_iter[0] = N/2;
_next_iter[1] = N/2; // node 1
_last_iter[1] = N;
#pragma parallel
for(int j; ; ){
#pragma atomic capture
j = _next_iter[NUMA_NODE]++;
if(j >= _next_iter[NUMA_NODE+1])
break;
#pragma omp parallel for
for(int j = 0; j < nrows; j++){
KickRow(slab,j);
}
NUMA_FOR(nrow)
KickRow(slab,j);
}
Given the following code:
Rewrite as:
Lesson #1: don't let your threads access memory on the wrong NUMA node
Lesson #1b: Don't write a custom OpenMP scheduler
Lesson #1a: don't let your threads access memory on the wrong NUMA node
void multipoles(const double *pos, const int N, double *multipole){
for(int i = 0; i < N; i++){
double mx = 1.;
for(int a = 0; a <= ORDER; a++){
double mxy = mx;
for(int b = 0; b <= ORDER - a; b++){
double mxyz = mxy;
for(int c = 0; c <= ORDER - a - b; c++){
multipole[a,b,c] += mxyz;
mxyz *= pos[2,i];
}
mxy *= pos[1,i];
}
mx *= pos[0,i];
}
}
}
}
Performance: \(7\times10^6\) particles/sec (1 core)
print('double mx = 1.;')
for a in range(ORDER + 1):
print('double mxy = mx;')
for b in range(ORDER - a + 1):
print('double mxyz = mxy;')
for c in range(ORDER - a - b + 1):
print(f'multipoles[{a},{b},{c}] += mxyz;')
print('mxyz *= pos[2,i];')
print('mxy *= pos[1,i];')
print('mx *= pos[0,i];')
\(19\times10^6\) particles/sec
print('__m512d mx = _mm512_set1_pd(1.);')
for a in range(ORDER + 1):
print('__m512d mxy = mx;')
for b in range(ORDER - a + 1):
print('__m512d mxyz = mxy;')
for c in range(ORDER - a - b + 1):
print(f'multipoles[{a},{b},{c}] = '\
f'_mm512_add_pd(multipoles[{a},{b},{c}],mxyz);')
print('mxyz = _mm512_mul_pd(mxyz,pos[2,i]);')
print('mxy = _mm512_mul_pd(mxy,pos[1,i]);')
print('mx = _mm512_mul_pd(mx,pos[0,i]);')
\(54\times10^6\) particles/sec
Lesson #2: don't trust the compiler to optimize complicated, performance-critical loops!
Other tricks: interleaving vectors, FMA, remainder iterations
Typical cache line size 64 bytes
Keep threads away from each other by at least this much
Lesson #3: don't share cache lines, especially in tight loops
Lesson #4: don't send data to the GPU unless you have a lot of floating-point work to do on it
Checksumming
Compression/file formats
Representation of particle positions
SSD TRIM
GPU intermediate accumulators