python資料分析
BY 企鵝
講師: YK
無論是為了學術研究或者只是賺錢,
我們都不時需要分析大量數據來獲得有用的資訊,
而Python恰好提供了一系列方便使用的
數學、統計、視覺化模組。
現在就讓我們一起認識它們。
關於 Python 資料分析
- Visual Studio Code(文字編輯器)
- Anaconda(虛擬環境)
- Google Colab(雲端筆記本,建議使用)
我要在哪裡寫程式?
用Colab的話可以跳過一些套件安裝步驟
還可以用很噁的方式把程式拆成一塊一塊的做測試
Colab
檔案>>新增筆記本>>開始寫
前情提要
為了沒加到暑訓的人
前情提要
小社課都不來的人(!!!)
或者只是不小心忘記Python語法的人
以下做個簡單的語法回顧~
變數
a = 3
b = 2.5
c = 'Never gonna give you up'
print(a) #3
print(a + b) #5.5
print(c) #Never gonna give you up
print(a + c) #TypeError: unsupported operand type(s) for +: 'int' and 'str'四則運算
呃,基本上跟C++一模一樣,只是不能用++和--
a = 3
b = 2.5
c = a - b
print(c) #0.5
a *= b #把a * b的值指派給a
print(a) #7.5其餘用法,聰明的各位可以自行類推
| + | 加 |
| - | 減 |
| * | 乘 |
| / | 除 |
| ** | 指數 |
| % | 取餘數 |
比較運算子
...還是跟C++一模一樣
| > | 大於 |
| < | 小於 |
| == | 相等 |
| >= | 大於等於 |
| <= | 小於等於 |
| != | 不等於 |
print(3 > 2) #True
a = 3
print(a >= 3) #True
a += 1
print(a!=4) #False100%國小等級
邏輯、if...elif...else
(這邊開始不太一樣了)
if 3 == 2 and 4 > 1: #False
print('A')
elif 3 == 2 or 4 <= 1: #False
print('B')
else:
print('Python so good') #Python so good有比較直覺...吧?
迴圈
#for loop
for i in range(0, 100): #當i在0到100之間
print(i)
#while loop
cnt = 0
while cnt < 100:
print(cnt)
cnt += 3for: 依指定次數執行
while: 依特定條件是否成立執行
List
seq = list([1, 4, 9, 16, 25, 36, 49])
for i in seq: #用for迴圈存取list內容
if i%2 == 1:
print(i)
#1 9 25 49之後我們會一直看到類似的東西
Method
等同C++的「函數」
格式類似:
(物件).函數名稱(參數)可能有回傳值可以指派給另一個變數
Numpy
numpy
- NumPy是一個提供高階陣列、矩陣之創建、運算,以及大量線性代數方法的擴充套件BlaBlaBla其實重點只有高階陣列而已
- 做為擴充套件,NumPy並沒有隨Python一同發布。因此我們需要在命令列輸入指令來安裝。
- Google Colab或Anaconda等環境則不需要輸入指令(已經幫你裝好了)。
pip install numpynumpy
並且在程式開頭進行引用:
import numpy as np #np是簡稱
創建Array
NumPy的array非常接近Python自帶的list,
以下範例創造了一維到三維的array,以及list對照組:
import numpy as np
a = np.array([0, 1, 2])
b = np.array([('a', 'b'), ('c', 'd'), ('e', 'f')])
c = np.array([[(1.8, 2.5), (0.7, 4)], [(-2.2, -8.1), (0, 7.3)]])
d = [3, 'a']
print("c:",c)
print("d:",d)創建Array
c: [[[ 1.8 2.5]
[ 0.7 4. ]]
[[-2.2 -8.1]
[ 0. 7.3]]]
d: [3, 'a']可以注意到,array中所有元素的類別必須相同,
像「4」這樣的整數會被轉換成浮點數「4.」。
輸出:
array初始化
import numpy as np
a = np.zeros((3,4)) #全部填0的3*4陣列
b = np.ones((5, 2)) #全部填1的5*2陣列
c = np.full((2, 2), 8) #全部填8的2*2陣列
print("a:",a)
print("b:",b)
print("c:",c)同時,NumPy還有更多初始化方法,以適應不同用途。
- 全部填入常數
array初始化
a: [[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
b: [[1. 1.]
[1. 1.]
[1. 1.]
[1. 1.]
[1. 1.]]
c: [[8 8]
[8 8]]輸出:
array初始化
import numpy as np
a = np.arange(1, 50, 12) #在1~50之間12為間隔創造一個數值陣列
b = np.linspace(25, 100, 7) #在25~100之間創造7個元素的數值陣列
print("a:",a)
print("b:",b)- 區間數值點
輸出:
a: [ 1 13 25 37 49]
b: [ 25. 37.5 50. 62.5 75. 87.5 100. ]array初始化
import numpy as np
for i in range(0, 3):
print(np.random.random((3,3))) #產生3*3的隨機矩陣,數值範圍0~1- 隨機填充
array初始化
[[0.28147825 0.96709883 0.38886481]
[0.69037383 0.56632421 0.11887002]
[0.56820809 0.22161438 0.04871162]]
[[0.19460509 0.01269472 0.58049943]
[0.64971552 0.30758513 0.04760169]
[0.18897162 0.98550729 0.73428153]]
[[0.34494893 0.07502964 0.38959092]
[0.27852453 0.31425516 0.88190124]
[0.48132711 0.60398328 0.75058455]]輸出:
這些特殊的初始化方法一般用於機器學習,
所以聽聽就好對生成測試資料十分有用。
array索引方法
import numpy as np
a = np.array([0, 1, 2])
b = np.array([('a', 'b'), ('c', 'd'), ('e', 'f')])
c = np.array([[(1.8, 2.5), (0.7, 4)], [(-2.2, -8.1), (0, 7.3)]])
print(a[1])
print(b[2, 1])
print(c[1, 0, 1])
#不出意外的話,輸出:
#1
#f
#-8.1讀寫array的方式與list非常類似:
array索引方法
import numpy as np
a1darr = np.array(['Alfa', 'Bravo', 'Charlie', 'Delta', 'Echo'])
a2darr = np.array([('Red', 'Green', 'Blue'), \
('Yellow', 'Cyan', 'Magenta')])
print(a1darr[1:4]) #第2~4個元素
print(a1darr[::2]) #所有元素,但以2為間隔取值
print(a2darr[:, 0:2]) #上下兩排的前兩個元素
#輸出:
#['Bravo' 'Charlie' 'Delta']
#['Alfa' 'Charlie' 'Echo']
#[['Red' 'Green']
#['Yellow' 'Cyan']]假如要讀取索引範圍內的數值:
array的運算與比較
import numpy as np
a = np.array([1, 2, 3])
b = np.array([1.414, 1.732, 2.236])
print(np.add(a, b))
print(np.subtract(a, b))
print(np.multiply(a, b))
print(np.divide(a, b))
#輸出:
#[2.414 3.732 5.236]
#[-0.414 0.268 0.764]
#[1.414 3.464 6.708]
#[0.70721358 1.15473441 1.34168157]我們可以對array進行四則運算:
array的運算與比較
import numpy as np
import math
some_ints = np.array([1, 4, 9])
some_numbers = np.array([0.1, 10, 1000])
some_floats = np.array([1/3 * math.pi, 1/2 * math.pi, 2/3 * math.pi])
print(np.sqrt(some_ints))
print(np.log10(some_numbers))
print(np.sin(some_floats))
#運算結果:
#[1. 2. 3.]
#[-1. 1. 3.]
#[0.8660254 1. 0.8660254]其它的運算也可以:
array的運算與比較
import numpy as np
a = np.array([(1, 2, 3), (4, 5, 6)])
b = np.array([(1, 3, 2), (4, 5, 7)])
print(a < 3)
print(a == b)
print(np.array_equal(a, b)) #檢查a, b是否完全相等
#答案顯而易見:
#[[ True True False]
# [False False False]]
#[[ True False False]
# [ True True False]]
#False最後,我們可以對array內容進行比較,
得到一個布林array作為回傳值,
代表原array中的各個元素是否符合條件:
array的運算與比較
import numpy as np
datas = np.array([1, 2.5, 3.8])
print(np.mean(datas)) #算術平均
print(np.std(datas)) #標準差
print(np.max(datas)) #最大值
#結果:
#2.433333333333333
#1.1440668201153674
#3.8總算來到NumPy最為實用的部份了
──聚合函數(Aggregate Functions)。
這些函數允許我們迅速計算出一系列數據的某個總體指標
(講人話,比如平均、標準差、最大值等)。
array的運算與比較
import numpy as np
datas_in_2d = np.array([[1, 3, 5], [2, 4, 6]])
print(datas_in_2d.min(axis=0))
print(datas_in_2d.min(axis=1))
print(datas_in_2d.mean(axis=0))
#還不是輕輕鬆鬆:
#[[1 3 5]
#[1 2]
#[1.5 3.5 5.5]喔不,如果遇到二維array呢?
array的運算與比較
| 1 | 3 | 5 |
| 2 | 4 | 6 |
axis = 1
axis = 0
Pandas
Pandas
講完了NumPy的各種功能,感覺好像不夠實用啊!
這是因為它更偏向為機器學習提供數學支援。
在統計資料方面,從NumPy衍生出來的Pandas可以做得更好。
pip install pandasimport pandas as pd同樣地,Pandas並非Python內建,所以…
安裝&引入!
Series & Dataframe
Pandas和NumPy最大的差別,
其實就只是增加了用標籤搜索數值的功能,
其餘部份可謂大同小異。
比如,本節標題的Series和Dataframe
分別對應一維和二維的array,
以下展示創建這兩種結構的方法。
Series & Dataframe
import pandas as pd
sr = pd.Series([44, 56, 58], \
index = ['Math', 'Physcis', 'Chemistry']) #這不是我(吧
print(sr, '\n')
print(sr.iloc[2]) #數值索引取值
print(sr['Physcis']) #標籤索引取值
#嗚嗚嗚:
#Math 44
#Physcis 56
#Chemistry 58
#dtype: int64
#58
#56Series :
import pandas as pd
df = pd.DataFrame({'Item name': ['CPU', 'RAM', 'GPU'],\
'Price(NTD)': [20000, 2900, 45000]}) #這更不是我
print(df, '\n')
print(df.loc[0: 1], '\n')
tag_df = pd.DataFrame({'Atomic number': [2, 10, 18, 36],\
'Atomic mass': [4.0026, 20.18, 39.95, 83.798]}, \
index = ['He', 'Ne', 'Ar', 'Kr'])
print('Here are some noble gas:', '\n', tag_df, '\n')
print('Info about Argon:', '\n', tag_df.loc['Ar'])Dataframe :
Series & Dataframe
Item name Price(NTD)
0 CPU 20000
1 RAM 2900
2 GPU 45000
Item name Price(NTD)
0 CPU 20000
1 RAM 2900
Here are some noble gas:
Atomic number Atomic mass
He 2 4.0026
Ne 10 20.1800
Ar 18 39.9500
Kr 36 83.7980
Info about Argon:
Atomic number 18.00
Atomic mass 39.95
Name: Ar, dtype: float64Dataframe啊真神奇 :
Series & Dataframe
可以注意到,
Dataframe的一行或一列
= Series
Height(m) Mass(kg)
Object1 168 55
Object2 181 71
Object3 175 888
Object4 188 68
Object5 132 34
Object6 476 1000
Object7 1453 7000
Object8 2024 18000
Object9 314 3140
Object10 2718 27180
Object11 192 74
Object12 175 67
Object13 173 64
Object14 173 63
Object15 162 51Series & Dataframe
當拿到一筆Dataframe資料,
我們或許會想提取一部分的樣本進行觀察。
當資料量很大的時候,head( )和tail( )就可以派上用場。
對於這樣一筆資料:
import pandas as pd
idx = []
for i in range(1, 16):
idx.append('Object'+ str(i))
a_BIG_AMOUNT_of_data = pd.DataFrame({'Height(m)':\
[168, 181, 175, 188, 132, 476, 1453, \
2024, 314, 2718, 192, 175, 173, 173, 162], \
'Mass(kg)':[55, 71, 888, 68, 34, 1000, 7000, \
18000, 3140, 27180, 74, 67, 64, 63, 51]}, index = idx)
print(a_BIG_AMOUNT_of_data.head()) #預設為5
print(a_BIG_AMOUNT_of_data.tail(3))可以用head( )擷取開頭、tail( )擷取結尾,並指定數量:
Series & Dataframe
Height(m) Mass(kg)
Object1 168 55
Object2 181 71
Object3 175 888
Object4 188 68
Object5 132 34
Height(m) Mass(kg)
Object13 173 64
Object14 173 63
Object15 162 51會輸出前5筆和最後3筆:
Series & Dataframe
stats = a_BIG_AMOUNT_of_data.describe()
print(stats, '\n')
print('Average Height:', stats.loc['mean', 'Height(m)'], '\n')
modified_stats = \
a_BIG_AMOUNT_of_data.describe(percentiles = [0.2 ,0.8])
#改看第20, 80百分位數
print(modified_stats.T) #轉置,可以當成將表格轉向沿用上面的數據(掰數據很累的),
假如要取得群體統計摘要,可以使用describe():
Series & Dataframe
輸出太多了,自己寫寫看吧
import pandas as pd
IDK_what_to_put_here = \
pd.DataFrame({'Status': ['Bad', 'No Good', 'Terrible']},\
index = ['APCS', 'Final Exams', 'Science Fair'])
print(IDK_what_to_put_here, '\n')
print('This df has', IDK_what_to_put_here.shape[0], 'rows') #橫列數
print('And', IDK_what_to_put_here.shape[1], 'columns') #直行數為了更好地處理數據,
我們會需要取得整個Dataframe的行數或列數,如下:
Series & Dataframe
Status
APCS Bad
Final Exams No Good
Science Fair Terrible
This df has 3 rows
And 1 columns輸出:
Series & Dataframe
import pandas as pd
goods = pd.DataFrame({'Unit Price(NTD)': [299, 149, 589],\
'Number': [3, 10, 1]})
goods['Total Price(NTD)'] = (goods['Unit Price(NTD)'] * goods['Number'])
#兩列相乘
print('Total price:', goods['Total Price(NTD)'].sum(), 'NTD')
#所有物品的總價
print('Original df:\n', goods, '\n')
m_goods = goods.copy()
m_goods.loc[1, 'Unit Price(NTD)'] = 349
#修改列索引為1,標籤為'Unit Price(NTD)'的欄位數值為349
print('The price is raised!\n', m_goods)最後最後!計算數值和修改Dataframe的方法:
Series & Dataframe
Total price: 2976 NTD
Original df:
Unit Price(NTD) Number Total Price(NTD)
0 299 3 897
1 149 10 1490
2 589 1 589
The price is raised!
Unit Price(NTD) Number Total Price(NTD)
0 299 3 897
1 349 10 1490
2 589 1 589效果十分顯著:
Series & Dataframe
├── pandas_csv_read.py
└── test.csvPandas的另外一個重要功能就是
在Dataframe和excel之間傳輸資料,
其中最經典的就是 .csv(逗號分隔值)。
這裡有兩個檔案:
IO工具
random numbers, square
2, 4
3, 9
4, 16
5, 25而 test.csv 的檔案內容如下(純文字):
IO工具
在 pandas_csv_read.py 中我們希望能讀取
test.csv的內容,只需要寫:
import pandas as pd
csv_df = pd.read_csv('test.csv') #是個Dataframe
print(csv_df)就可以獲得排版後的檔案內容了。
random numbers,square
2,4
3,9
4,16
5,25而 test.csv 的檔案內容如下(純文字):
IO工具
在 pandas_csv_read.py 中我們希望能讀取
test.csv的內容,只需要寫:
import pandas as pd
csv_df = pd.read_csv('test.csv') #是個Dataframe
print(csv_df)就可以獲得排版後的檔案內容了。
import pandas as pd
goods = pd.DataFrame({'Unit Price(NTD)': [299, 149, 589],\
'Number': [3, 10, 1]}) #它又出現了
goods.to_csv('output.csv')
print(pd.read_csv('output.csv'))
goods.to_csv('output.csv', index = False) #將最左一行的索引去除
print(pd.read_csv('output.csv'))反過來,如果要把Dataframe資料存進 .csv:
IO工具
Unnamed: 0 Unit Price(NTD) Number
0 0 299 3
1 1 149 10
2 2 589 1
Unit Price(NTD) Number
0 299 3
1 149 10
2 589 1得:
IO工具
將to_csv()換成to_excel()即可輸出成較新的格式.xls/.xlsx。
IO工具: in google colab
from google.colab import drive
drive.mount('/content/drive') #掛接雲端硬碟
csv_df = pd.read_csv('/content/drive/MyDrive/Py/test.csv') #是個Dataframe
print(csv_df)Matplotlib
pip install matplotlib如果我們只是一直玩弄操作矩陣和表格未免太過無聊,
畢竟它們不過是高級版的陣列而已。
所以接下來我們將進入最重要的部分──資料視覺化!
MATPLOTLIB
import matplotlib as plt然後import
當然要安裝的啦:
import matplotlib.pyplot as plt
import numpy as np
import math
x = np.arange(-10, 10, 0.1)
y = np.cos(x)
plt.plot(x, y) #指定x、y軸數值來源
plt.show() #顯示圖表我們已經學會了NumPy中的數值運算,
現在要如何畫出函數圖形?
Plot
Plot
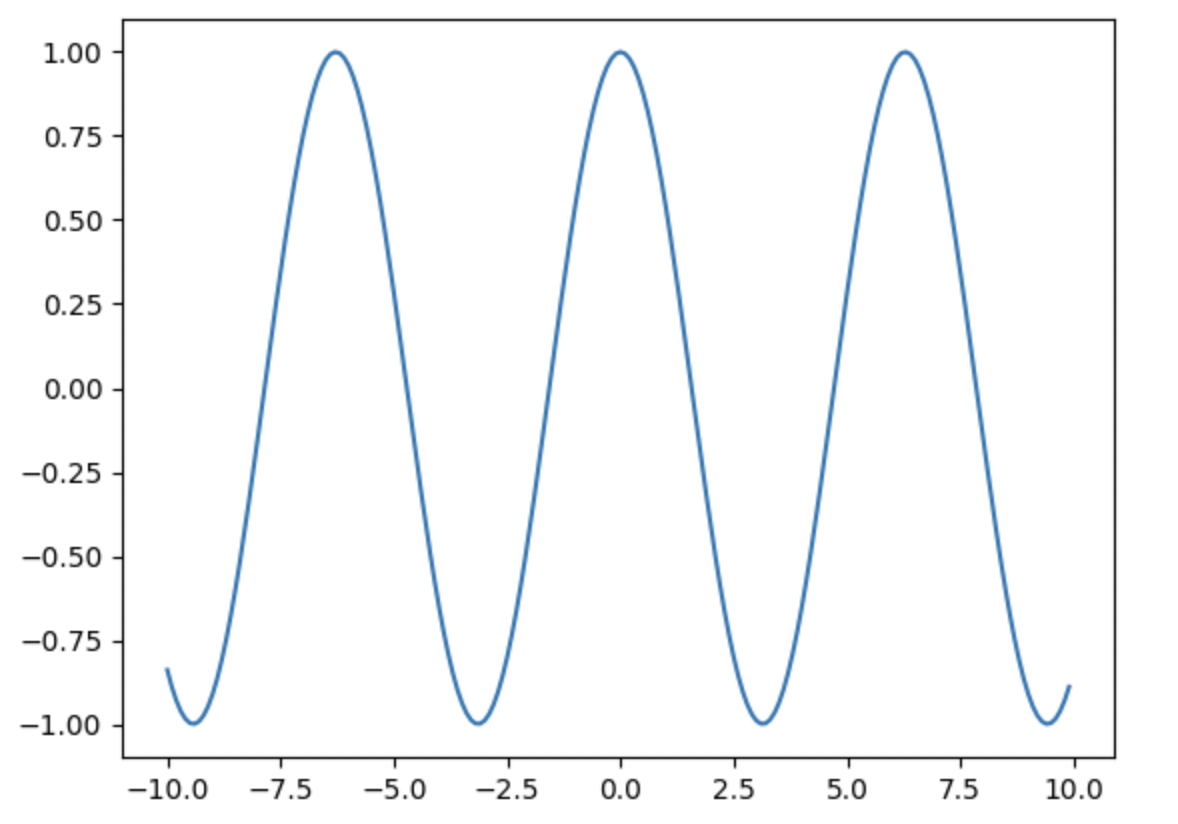
輸出:
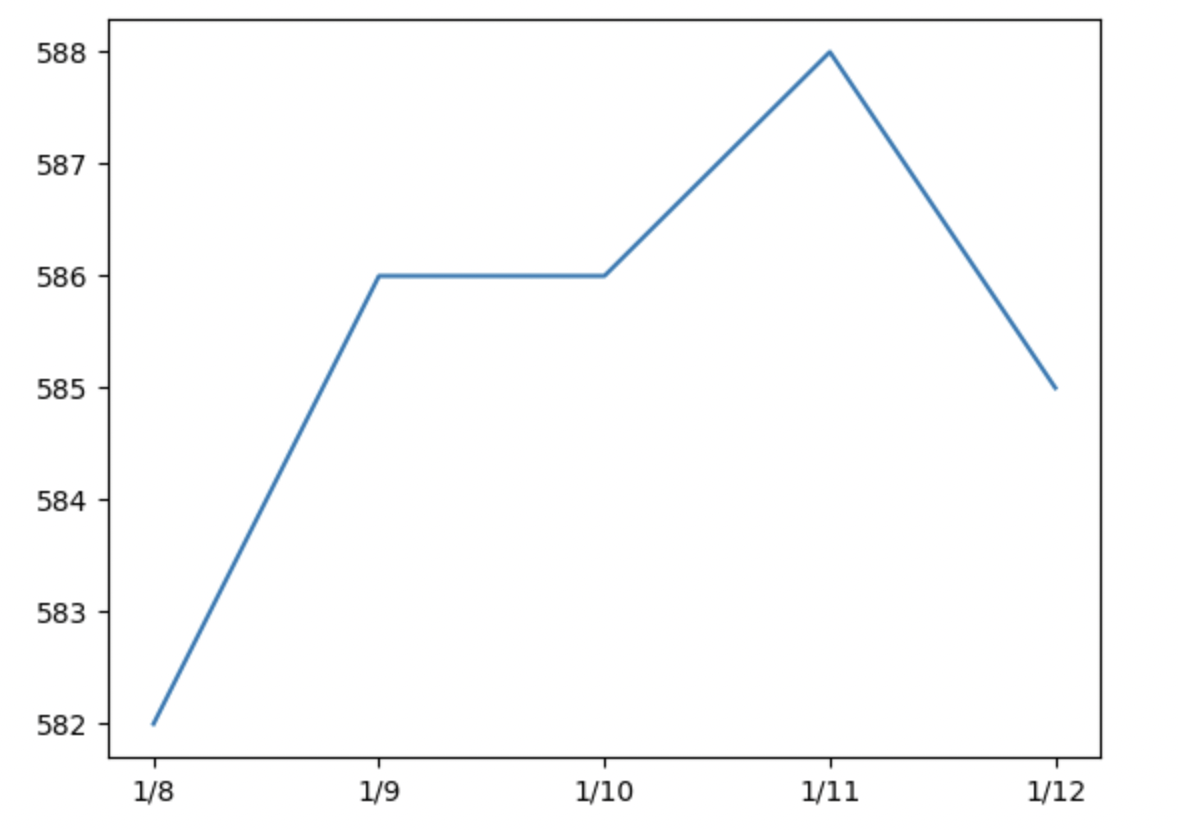
import matplotlib.pyplot as plt
import pandas as pd
random_stocks = pd.DataFrame(\
{'dates': ['1/8', '1/9', '1/10', '1/11',\
'1/12'],
'prices': [582, 586, 586, 588, 585]})
plt.plot(random_stocks['dates'], random_stocks['prices'])
plt.show()那如果資料來源是Dataframe?
Plot
疑似有點太陽春了,
因此我們要接著看看如何生成更複雜的圖表。
Plot
我們可以像流水線一樣,
逐漸往最簡單的圖表加入元素,讓它變得更加完整。
先創造一張圖:
圖表格式
import matplotlib.pyplot as plt
import pandas as pd
population_history = \
pd.DataFrame({'years':\
['1900', '1920', '1940', '1960', '1980', '2000', '2020'],\
'people': [16.71, 18.36, 22.40, 30.46, 44.20,
\61.44, 78.21]})
plt.plot(population_history['years'], population_history['people'])
plt.show()修改折線樣式:
圖表格式
plt.plot(population_history['years'], population_history['people'], \
color = 'b', marker = 'o', linestyle = '--')
#線條為藍色虛線,帶圓形節點為整張圖加個標題:
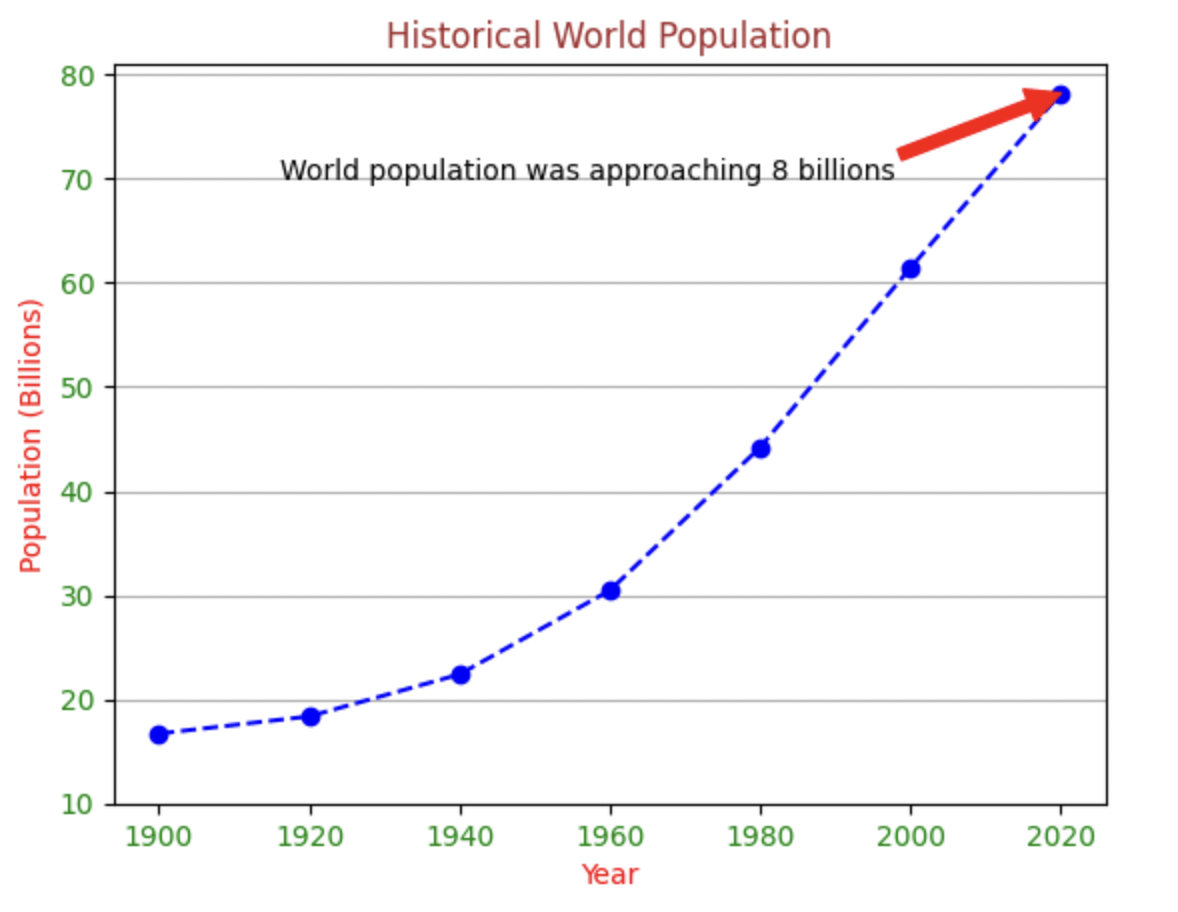
plt.title('Historical World Population', color = 'brown')然後調整座標軸格式(記得import numpy):
圖表格式
#x, y軸文字
plt.xlabel('Year', color = 'r')
plt.ylabel('Population (Billions)', color = 'r')
#x, y軸數值來源
plt.xticks(population_history['years'], color = 'g')
plt.yticks(np.arange(10, 81, 10.0), color = 'g')
plt.ylim(10, 81) #坐標軸數值極限添加標註、格線等小細節:
plt.annotate('World population was approaching 8 billions',\
xy = (6, 78.21), xytext = (0.8, 70),\
arrowprops = {'color': 'r'})
plt.grid(axis = 'y') #只有y方向放格線完整code:
圖表格式
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
population_history = \
pd.DataFrame({'years': ['1900', '1920', '1940', '1960', '1980', '2000',\
'2020'], 'people': [16.71, 18.36, 22.40, 30.46, 44.20,\
61.44, 78.21]})
plt.plot(population_history['years'], population_history['people'], \
color = 'b', marker = 'o', linestyle = '--')
plt.title('Historical World Population', color = 'brown')
plt.xlabel('Year', color = 'r')
plt.ylabel('Population (Billions)', color = 'r')
plt.xticks(population_history['years'], color = 'g')
plt.yticks(np.arange(10, 81, 10.0), color = 'g')
plt.ylim(10, 81)
plt.annotate('World population was approaching 8 billions', \
xy = (6, 78.21), xytext = (0.8, 70), \
arrowprops = {'color': 'r'})
plt.grid(axis = 'y')
plt.show()成品!!!
圖表格式
假如我們要呈現更多資料(畫更多的線),只需要…
多幾個plot就好啦!!!
圖表格式
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
#Here are 3 lovely countries!
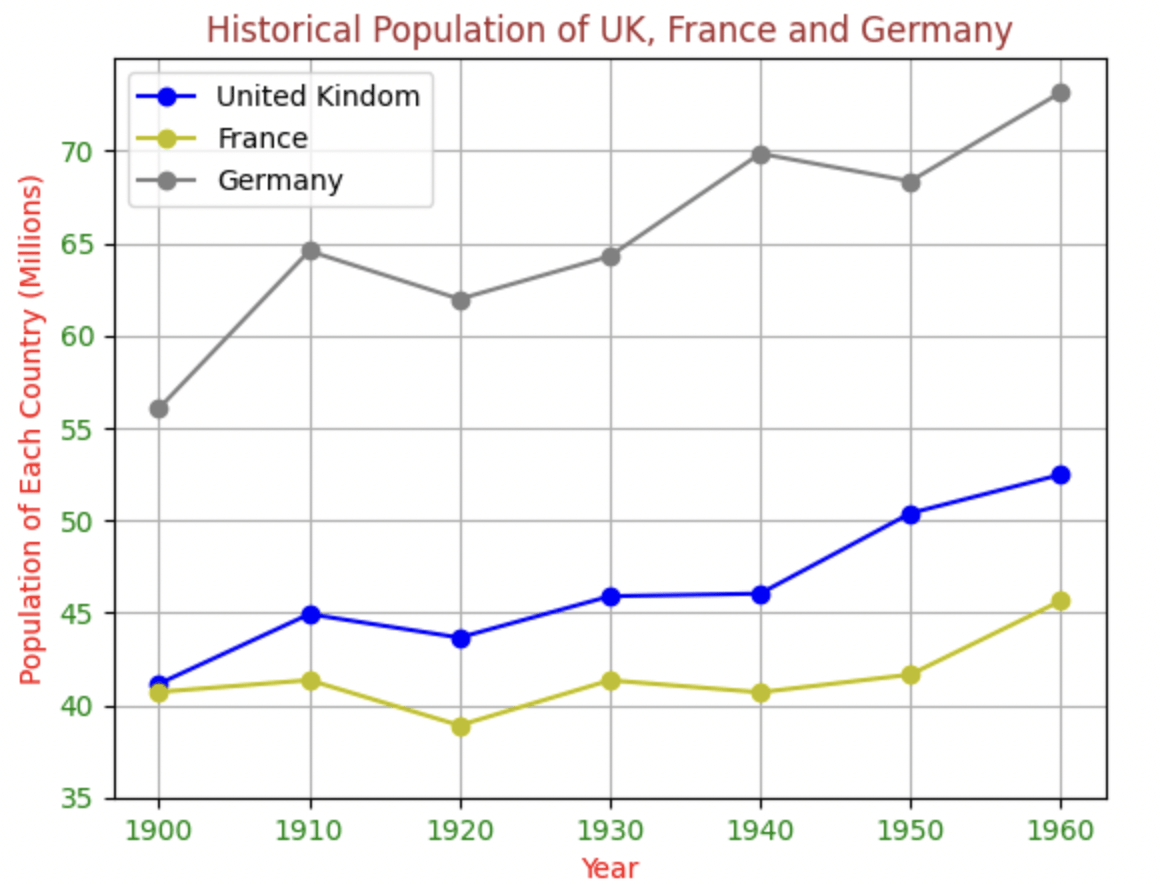
population_history_uk = pd.DataFrame({'years': ['1900', '1910', '1920', '1930', '1940', '1950', '1960'],\
'people': [41.15, 44.92, 43.65, 45.89, 46.03, 50.38, 52.47]})
population_history_fr = pd.DataFrame({'years': ['1900', '1910', '1920', '1930', '1940', '1950', '1960'],\
'people': [40.71, 41.35, 38.90, 41.34, 40.69, 41.65, 45.64]})
population_history_de = pd.DataFrame({'years': ['1900', '1910', '1920', '1930', '1940', '1950', '1960'],\
'people': [56.05, 64.57, 61.97, 64.29, 69.84, 68.35, 73.15]})
plt.plot(population_history_uk['years'], population_history_uk['people'],\
color = 'b', marker = 'o', label = 'United Kindom') #label是圖例中的文字
plt.plot(population_history_fr['years'], population_history_fr['people'],\
color = 'y', marker = 'o', label = 'France')
plt.plot(population_history_de['years'], population_history_de['people'],\
color = 'gray', marker = 'o', label = 'Germany')
plt.legend(loc = 'upper left') #圖例在左上角
plt.title('Historical Population of UK, France and Germany', color = 'brown')
plt.xlabel('Year', color = 'r')
plt.ylabel('Population of Each Country (Millions)', color = 'r')
plt.xticks(population_history_uk['years'], color = 'g')
plt.yticks(np.arange(35, 75, 5.0), color = 'g')
plt.ylim(35, 75)
plt.grid()
plt.show()我們成功把事情變得更複雜把圖表變得更精美了。
圖表格式
加量不加價
圖和子圖

不,不是這個
圖和子圖
- 圖(figure) = 畫布、圖表的背景
這兩個概念各自對應了figure()和subplot()函數。利用它們,我們可以繪製出更多種的圖表。
比如...
有兩個軸的折線圖(又是你!)
- 子圖(subplot) = 圖表內容
雙軸完整code(語法稍冗請見諒)
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
stock_prices = pd.DataFrame(\
{'dates': ['1/8', '1/9', '1/10', '1/11',\
'1/12'],
'tsmc': [582, 586, 586, 588, 585],\
'mtk': [920, 928, 924, 920, 926]})
fig = plt.figure() #圖
fig.suptitle('Stock Prices', color = 'brown', fontsize = 15)
ax1 = fig.add_subplot() #添加一個子圖
# 複製出第二個subplot
ax2 = ax1.twinx()
# x軸
ax1.set_xlabel('Date')
ax1.set_xticks(np.arange(len(stock_prices['dates']))) # x刻度間距
ax1.set_xticklabels(stock_prices['dates']) # x刻度數值
# 左y軸
ax1.set_ylabel('TSMC', color = 'r')
ax1.tick_params(axis = 'y', labelcolor = 'r') #刻度的屬性
ax2.spines['left'].set_color('red') #設定左y軸線的顏色(是ax2喔)
# 右y軸
ax2.set_ylabel('MTK', color = 'b')
ax2.tick_params(axis = 'y', labelcolor = 'b')
ax2.spines['right'].set_color('blue') # 右y軸線
# 畫線
line1 = ax1.plot(stock_prices.index, stock_prices['tsmc'], color = 'r', label = '台X電')
line2 = ax2.plot(stock_prices.index, stock_prices['mtk'], color = 'b', label = '聯X科')
# 格線
ax1.xaxis.grid(True)
ax1.yaxis.grid(True)
# 顯示
plt.show()雙軸
fig = plt.figure() #圖
fig.suptitle('Stock Prices', color = 'brown', fontsize = 15) # 圖表標題
ax1 = fig.add_subplot() #添加一個子圖
# 複製出第二個subplot
ax2 = ax1.twinx()創造出一張圖和兩個軸(對應兩個subplot)
雙軸
第3行:用arange()產生array來指示刻度分佈
# x軸
ax1.set_xlabel('Date')
ax1.set_xticks(np.arange(len(stock_prices['dates']))) # x刻度間距
ax1.set_xticklabels(stock_prices['dates']) # x刻度數值第2行:x軸的標題
第4行:每個刻度上的文字
雙軸
# 左y軸
ax1.set_ylabel('TSMC', color = 'r')
ax1.tick_params(axis = 'y', labelcolor = 'r') #刻度的屬性
ax2.spines['left'].set_color('red') #設定左y軸線的顏色(是ax2喔)
# 右y軸
ax2.set_ylabel('MTK', color = 'b')
ax2.tick_params(axis = 'y', labelcolor = 'b')
ax2.spines['right'].set_color('blue') # 右y軸線注意:軸(axis)、刻度(tick)、軸線(spine)的意義不同
雙軸
# 畫線
line1 = ax1.plot(stock_prices.index, stock_prices['tsmc'], color = 'r', label = '台X電')
line2 = ax2.plot(stock_prices.index, stock_prices['mtk'], color = 'b', label = '聯X科')
# 格線
ax1.xaxis.grid(True)
ax1.yaxis.grid(True)
# 顯示
plt.show()第2、3行:DataFrame有index屬性可供x軸參照
第5、6行:x、y軸的格線分開設置
雙軸
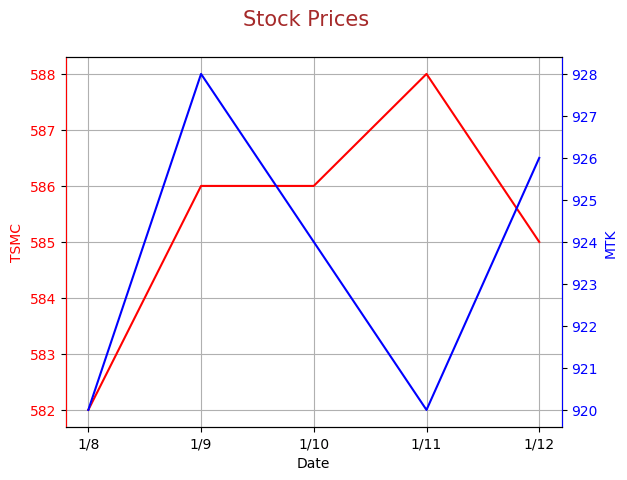
都是資料太少的錯
但至少我們知道雙軸怎麼用了
更多的圖
眾所周知,圖表除了折線圖之外,至少還有長條圖、散佈圖等等類型。
我們可以對此再多研究億點點東西...
更多的圖
好啦,其實只是把plot()函數換成:
- for長條圖:bar()
- for散佈圖:scatter()
而已
長條圖
長條圖
import matplotlib.pyplot as plt
import numpy as np
index = []
datas = []
for i in range(0, 10):
index.append(i)
datas.append(np.random.randint(0, 1000))
plt.bar(index, datas) #指定x、y軸數據,與plot類似
plt.show()最簡單的bar形式
長條圖
如果想讓低於某一標準線的長條呈現不同色:
長條圖
import matplotlib.pyplot as plt
import numpy as np
index = []
datas = []
for i in range(0, 100):
index.append(i)
datas.append(np.random.randint(-500, 500))
colors = [] # 顏色陣列
for a in datas:
colors.append('r' if a < 0 else 'b') # 小於0放紅色否則放藍色
plt.bar(index, datas, color = colors)
plt.show()有沒有發現,顏色參數可以是陣列格式的
長條圖
另外,
把bar()換成barh()就能產生水平的長條圖、
bar()兩次就能表示兩組數據...
歡迎自行嘗試
散佈圖
(二維常態分佈)
散佈圖
import matplotlib.pyplot as plt
import numpy as np
num = 5000
# 平均值(中心點)為0、標準差為1的標準常態分佈。輸出一個陣列。
x = np.random.normal(0, 1, num)
y = np.random.normal(0, 1, num)
plt.scatter(x, y,marker='v', alpha = 0.3) # 三角形點點,不透明度0.3
plt.show()散佈圖
還有一種情況我們會希望隨著數值,
改變散佈點的大小、顏色等屬性
散佈圖
import matplotlib.pyplot as plt
import numpy as np
num = 100
x = np.random.normal(0, 1, num)
y = np.random.normal(0, 1, num)
val = np.random.randint(0, 1000, num)
sizes = [i for i in val] # 隨數值改變點的大小
#s 是點的尺寸
plt.scatter(x, y, alpha = 0.3, s = sizes)
plt.show()存圖
在生成各種千奇百怪的圖表後
我們可能會需要把它們存成圖檔
而這就savefig()函數的功用
存圖
沿用上面那個看起來很酷其實毫無內容的散佈圖
加上plt.savefig(檔案位置)就能儲存圖表
import matplotlib.pyplot as plt
import numpy as np
num = 5000
# 平均值(中心點)為0、標準差為1的標準常態分佈。輸出一個陣列。
x = np.random.normal(0, 1, num)
y = np.random.normal(0, 1, num)
plt.scatter(x, y,marker='v', alpha = 0.3) # 三角形點點,不透明度0.3
plt.savefig('../../圖片/scatter.png') #Please自行修改存圖
將將將將~
成發
個人成發
主題
操作
把圖存成png/jpg格式(用colab程式碼.ipynb也可),連同資料來源網址/檔案(介紹用)一併放到這個資料夾>>小隊>>以你的綽號命名的資料夾。
工具
推薦網站: 台北市資料大平臺
選擇OpenData類型
工具
P.S. 在下載之前先點預覽,確認檔案編碼格式(有utf-8、big5等),在read_csv函數中指定
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('pi00106yac.csv', encoding='big5')
print(df) 年別 購買頻度別 原始值[統計數值] 年增率[%]
0 87年 每月至少購買1次 67.73 -
1 87年 每季(不含每月)至少購買1次 76.57 -
2 87年 每季購買不到1次 81.99 -
3 88年 每月至少購買1次 68.39 0.97
4 88年 每季(不含每月)至少購買1次 74.73 -2.4
.. ... ... ... ...
73 111年 每季(不含每月)至少購買1次 102.75 2.75
74 111年 每季購買不到1次 102.11 2.11
75 112年 每月至少購買1次 110.32 5.06
76 112年 每季(不含每月)至少購買1次 105.33 2.51
77 112年 每季購買不到1次 107.44 5.22
工具
當然,如果有人想嘗試其他的資料來源,比如台股股價等,遇到問題都歡迎提出。
或者也可以看看807🛐神提供的TDX(我還沒研究出API怎麼用)
結束啦!
下節課再見!