Inteligencia Artificial
Piezas y Partes
Daniel Kottow, abril 2023
Elementos para un sano juicio
- ¿De dónde viene la Inteligencia Artificial?
- ¿Qué sabe hacer y cómo lo aprende?
- ¿Cómo y en qué ha progresado "ahora" ?
- ¿Qué tan cerca está de "nivel humano" ?




- Cada célula nerviosa es una unidad independiente
- La sinapsis transfiere impulsos entre células


1906
Santiago Ramón y Cajal
Camillo Golgi
Redes Neuronales
- El cerebro humano tiene ~100 000 000 000 neuronas
- Sus neuronas tienen hasta 15 000 conexiones

1943



Warren S. McCulloch & Walter Pitts
1959

No todo es cerebro ni binario
J.Y. Lettvin, H.R. Maturana, W.S. McCulloch and W.H. Pitts
D. H. Hubel and T. N. Wiesel

1957
Frank Rosenblatt
Fotoceldas x Potenciómetros
Entradas
Pesos
Salida

Elementos para un sano juicio
- ¿De dónde viene la Inteligencia Artificial?
- No viene de la computación tradicional!
- Viene de una abstracción matemática - ingenieril de las neuronas biológicas bastante grosera.
Perceptrones multicapa
Yann LeCun
Meta AI


Geoffrey Hinton
Google AI
1986
1989
1989

3Blue1Brown
Luego de treinta años AI Winter...
David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams
LeCun, Yann. et al.
Hornik, Kurt et al.
El Tamaño importA
1998
2012

Alex Krizhevsky
ex-Google
Ilya Sutskever
Open AI

| Entradas | Capas | Pesos | Salidas |
|---|---|---|---|
| 28 x 28 | 5 | 430K | 10 |
| 224 x 224 x 3 | 8 | 61M | 1000 |

Elementos para un sano juicio
2. ¿Qué sabe hacer y cómo lo aprende?
- Gran aumento de poder computacional en los últimos 10 años (GPUs).
-
Transformar miles de entradas - números, imágenes - usando muchas "neuronas" iguales.
-
Entradas similares entregan salidas iguales (clasificación).
- Aprende cualquier transformación a partir de ejemplos.
3. ¿Cómo y en qué ha progresado "ahora" ?

Nature science report
2015

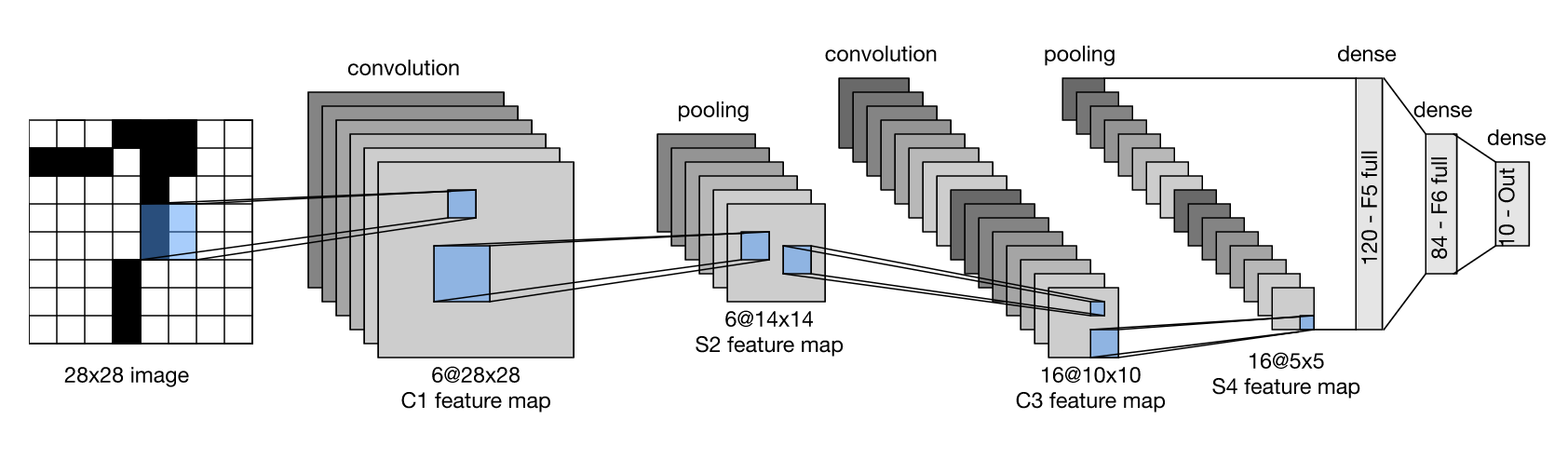
Yann LeCun - Meta AI
1989 -1998
Redes neuronales multicapa
Imagen 28 x 28
10 Categorías

Alex Krizhevsky
2012
Imagen 224 x 224 x 3
1000 Categorías
Ilya Sutskever - Open AI
Geoffrey Hinton - Google


Fase Entrenamiento
Fase Producción
Machine Learning
¡Entrenar requiere muchos y buenos ejemplos!
Validar
Entrenar
?=

¡La corrección de los pesos es delicada!
Entrenamiento AlexNet: 90 x 1.000.000 Imagenes ~ 6 días
¿Cómo encontrar pesos óptimos durante el entrenamiento?
-
Comenzar con pesos aleatorios.
- Procesar ejemplo y calcular error.
- Cambiar pesos en dirección que mejor corrija el error cometido.
- Iterar hasta convergencia ajustando "learning rate".


1986
Sutton & Barto
2013
Google DeepMind
AlphaGo
AlphaFold
2018
2015

Demis Hassabis
Towards Data Science
- Siempre "en loop".
- Acciones y premios están desfasados.

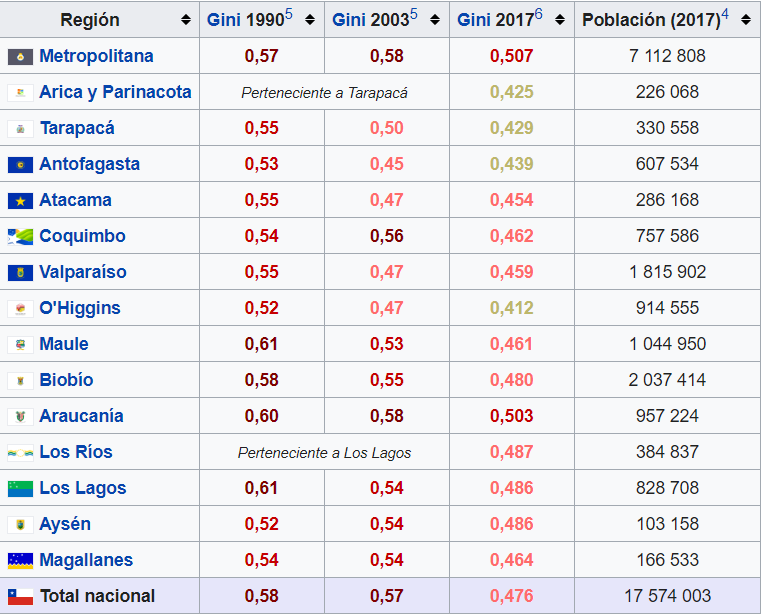
| Biología | Machine Learning |
|---|---|
| Aprendizaje continuo | Entrenamiento / Producción |
| Química / Neurotransmisores | Optimización / Diseño |
| Plasticidad neuronal | Arquitecturas fijas |


1.000 Mill EUR
2013 - 2023
Aprendizaje
Elementos para un sano juicio
- Aprende en base a ejemplos o premios ajustando iterativamente el modelo.
- Aprende solo durante fase de entrenamiento.
- No se progama, se construye y parametriza. Aquí está el arte!
- No sabemos codificar programas equivalentes! (caja negra)
2. ¿Qué sabe hacer y cómo lo aprende?

CS antes de US mejora resultados.
1897

Ivan Pavlov
Neurons wire together if they fire together


1949
Neuronas Espejo

1990s

Donald Hebb
Aprender es asociar
Vectores

Neuronas calculan similitud entre entradas y pesos (memoria)
"Neurons wire together if they fire together"
1949
Donald Hebb
Neurosicólogo
8 conexiones / 8 dimensiones

Digitalizar es Vectorizar

- Imágenes
- Sonidos
- Planillas
- Letras
- ¿Palabras?
2013

Tomáš Mikolov
ex Google

- Wikipedia 2014 + Gigaword 5
- 6B tokens
- 400K vocab

0. frog
1. frogs
2. toad

¡Palabra (concepto) "king" en 50 dimensiones!
"king - man + woman = queen"



1. Seleccionar textos
2. Generar ejemplos deslizando una ventana
Ventanas de 5 - 20 palabras
Jay Allamar
3. Entrenar (SL)

- Representación de palabras con vectores númericos de muchas dimensiones.
- Medida de similitud coseno entre vectores permite establecer errores y aprendizaje.
- Aprendizaje ocurre "leyendo" textos. No requiere preparación de ejemplos!
- Similitud entre palabras aprendidas refleja su próximidad / relación en los textos.
Elementos para un sano juicio
3. ¿Cómo y en qué ha progresado "ahora" ?
Large Language Models
¿Cómo se llama la capital de Chile?
La capital de Chile es Santiago.
What is the name of Chile´s capital?

Modelo de lenguaje para traducir y responder
2014
Google AI
Él vio a ella con un telescopio.
Contextos tienen largo variable.
Secuencias y Contexto





Jay Allamar
Secuencia y contexto largo fijo
Atención y Contexto
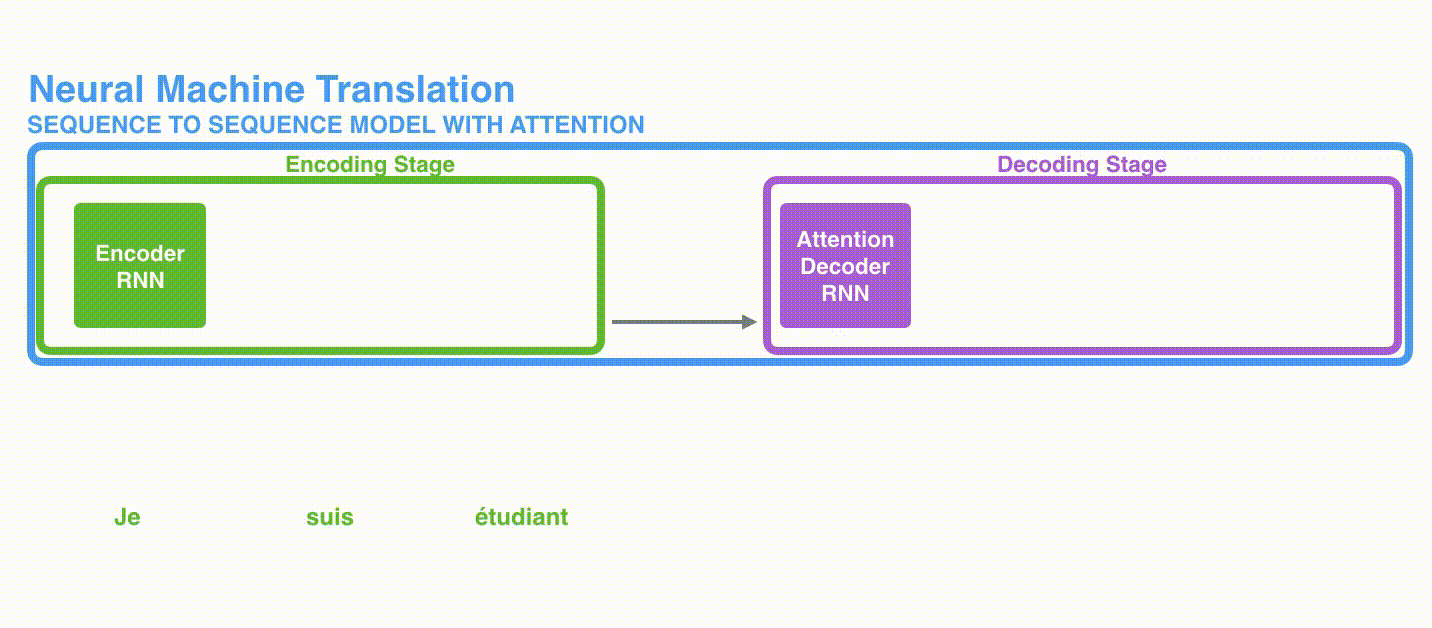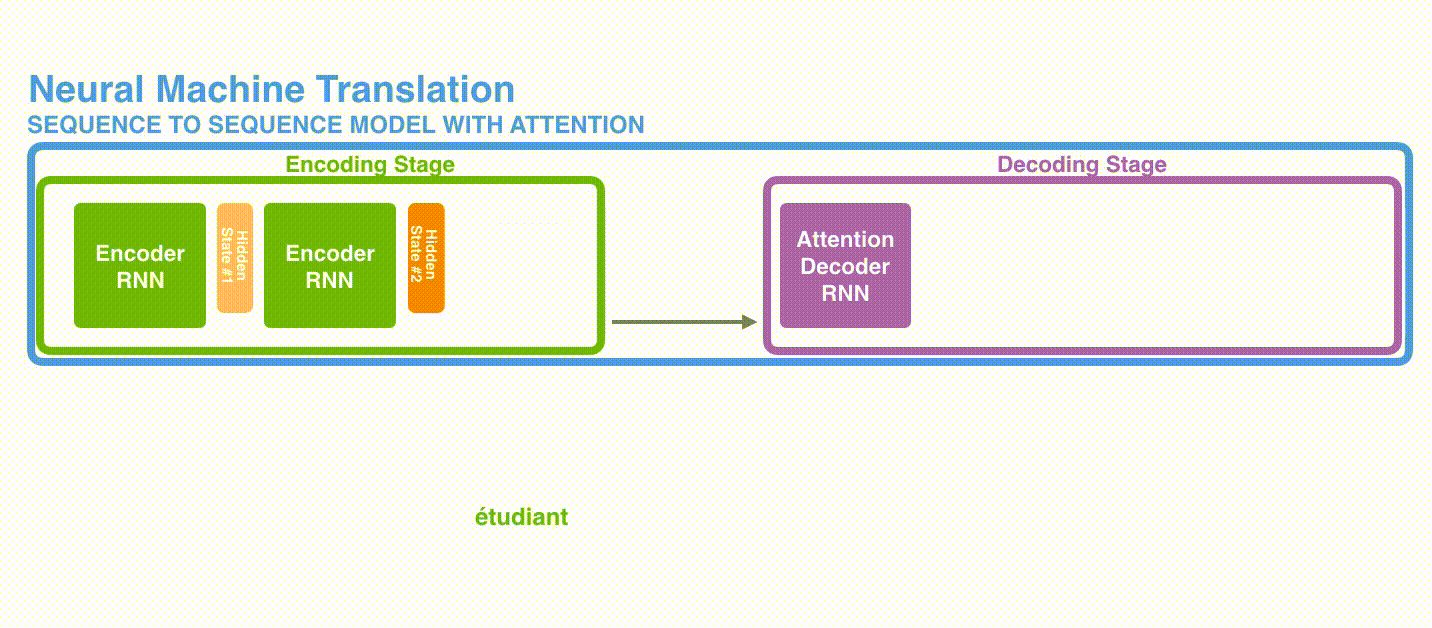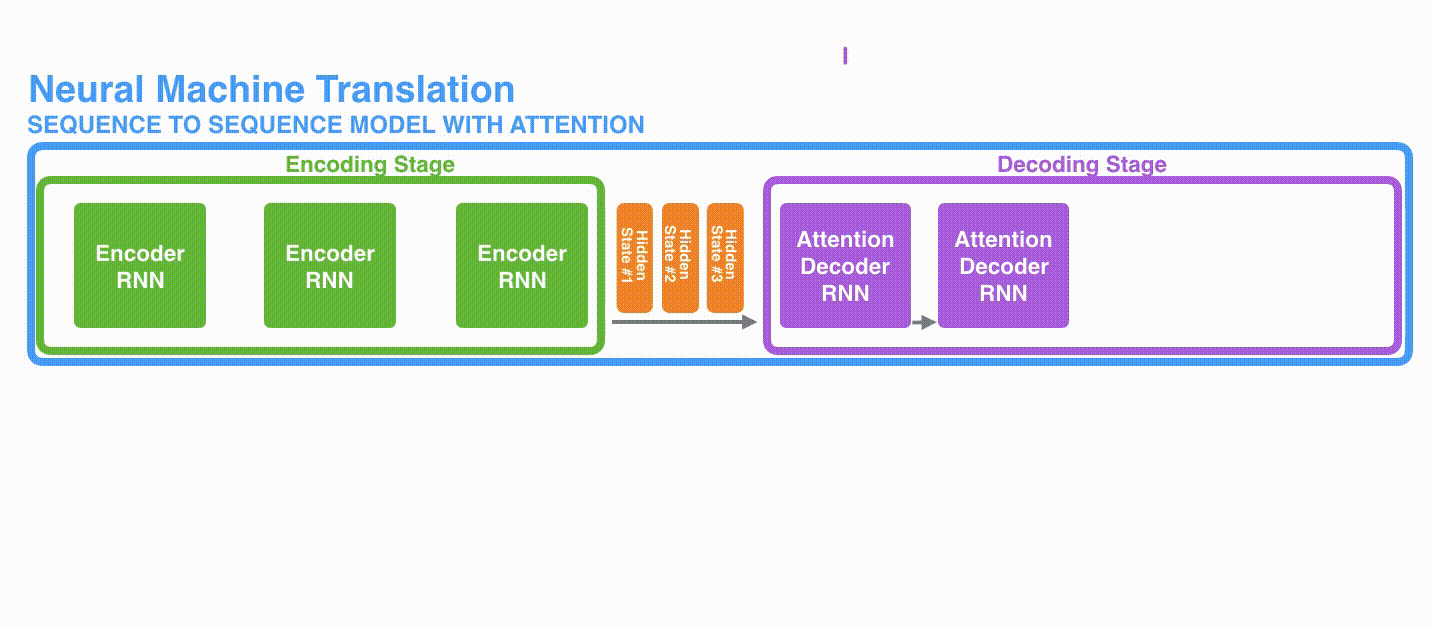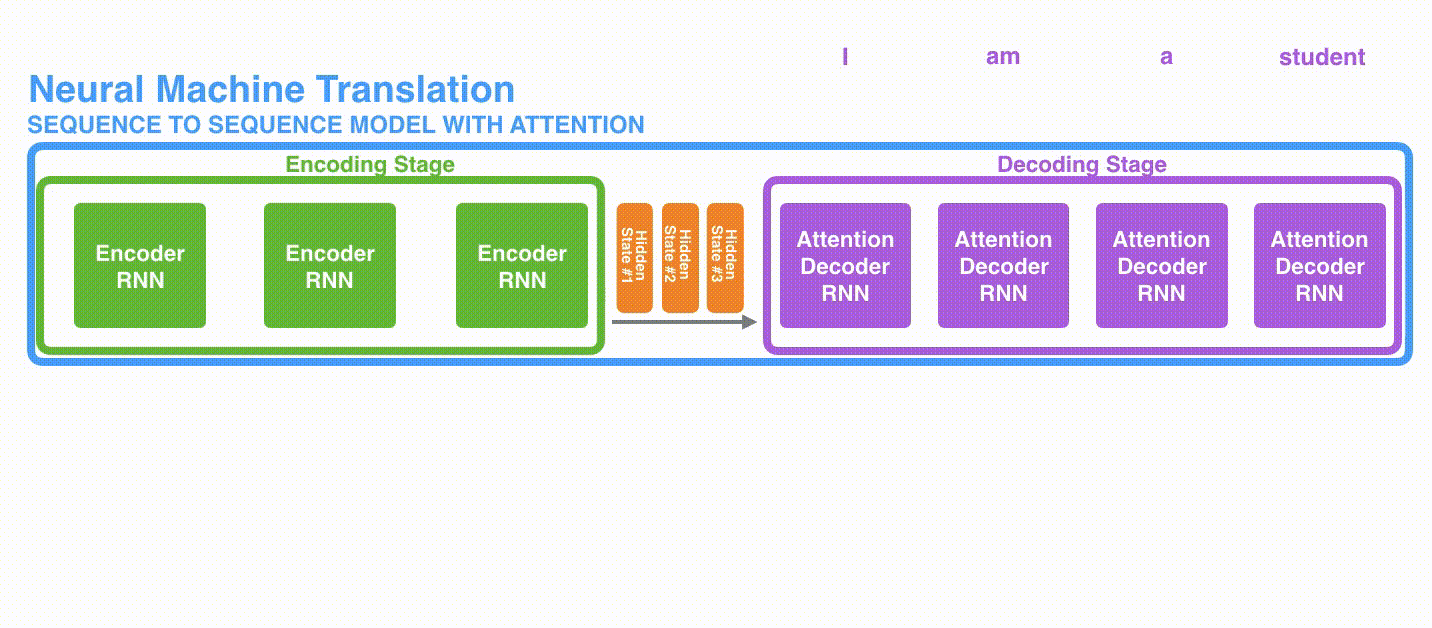
Secuencia y contexto completo

Atención pondera contextos dinámicamente
2015
D. Bahdanau et al
Transformer
2017

Ashish Vaswani
ex-Google
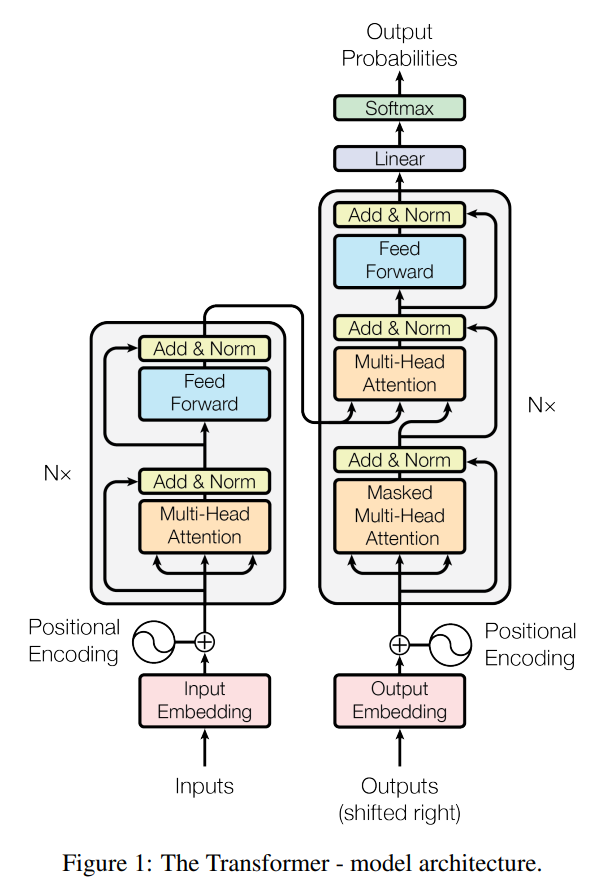
Secuencia transformer (N = 3).
Arcos ilustran capas de atención.
A. Vaswani et al


Google AI Blog
Atención capta contexto apropiado para discernir "it"
El Tamaño importA - parte 2
| Publicado | Entrenamiento | Parámetros | Prompt | |
|---|---|---|---|---|
|
GPT-1 |
Q2 2018 |
Common Crawl BookCorpus |
117.000.000 |
1024 |
| GPT-2 | Q1 2019 | + WebText | 1.500.000.000 | 2048 |
| GPT-3 | Q2 2020 | + Wikipedia + libros |
175.000.000.000 | 4096 |
| GPT-4 | Q1 2023 | Desconocido | 1.000.000.000.000 | 32000 |
- El cerebro humano tiene ~100 000 000 000 neuronas
- Sus neuronas tienen hasta 15 000 conexiones


Entrenamiento ChatGPT
- Entrenar a predecir próxima(s) palabra(s) "leyendo" textos de entrenamiento (GPT 3.5).
- Refinamiento supervisado con respuestas ejemplares.
- Refinamiento RLHF con humanos expresando sus preferencias entre respuestas alternativas.

A portrait photo of a kangaroo wearing an orange hoodie and blue sunglasses standing on the grass in front of the Sydney Opera House holding a sign on the chest that says Welcome Friends!
Propiedades Emergentes
Sebastien Bubeck

Google AI Blog
Elementos para un sano juicio
-
Atención y contexto modelan una memoria de trabajo (no persistente). ¡Aqui está lo "creepy"!
- Fenómenos emergentes
con mismo modelo, solo más "grande".
Muchas gracias :)
3. ¿Cómo y en qué ha progresado "ahora" ?
4. ¿Qué tan cerca está de "nivel humano" ?
-
En "poder computacional" parece estar cerca.
-
Manejo de lenguaje natural a nivel humano.
- Razonamiento y discernimiento de sus capacidades limitados.