PFHub REFACTor
Daniel Wheeler


11/02/2021
Current Difficulties
- Difficult for me to maintain and update
- Difficult to implement BM8 and BM9 due to data aggregation
- Frontend needs updating (JS / HTML dependency versions)
- Apps need maintenance (Staticman, data app)
- Difficult for collaborators to develop
- Data views impossible to amend
- Wiki is unreliable
Solutions
- Use Jupyter Notebooks pervasively
- Better upload procedure
- Fork example repository
- Use GitHub Actions / CI to update data views
- Stop using in-browser updates
- Remove apps / no more additional apps
Radical idea: no custom Website
USE Jupyter Notebooks
- Move comparison pages to Jupyter notebooks (in progress, implementing BM8)
- Auto-generated individual landing pages via notebooks
- Check notebooks on the CI
- instead of JS/HTML frontend views
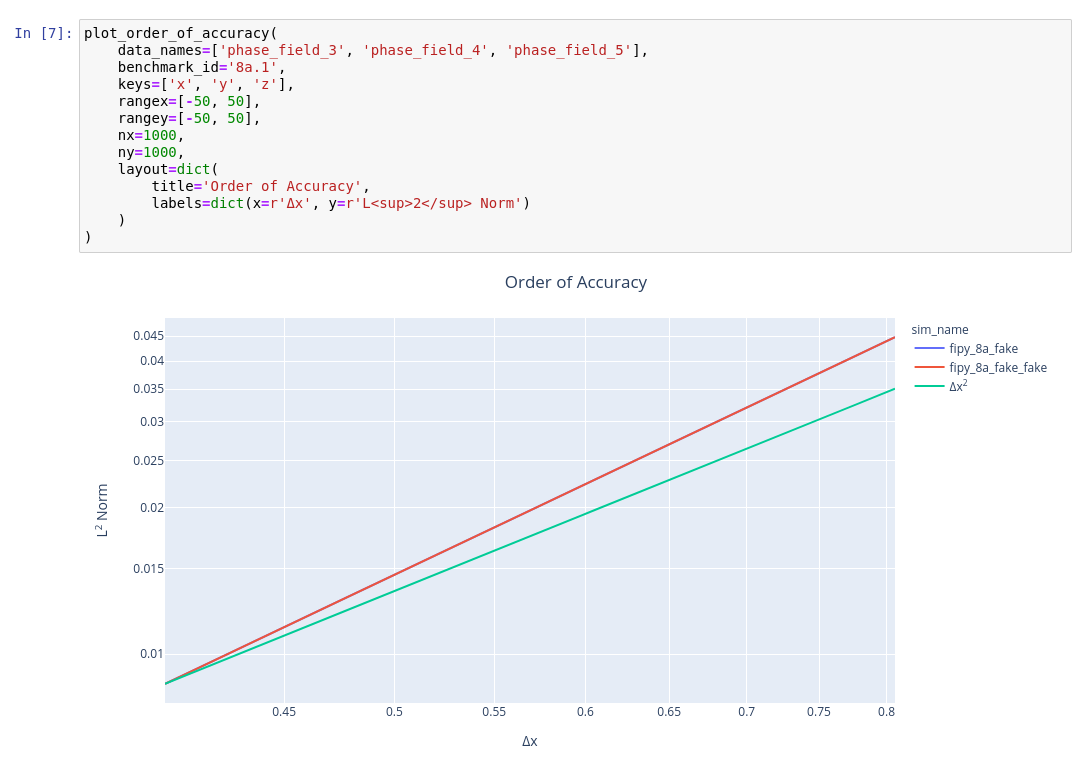
Jupyter Example
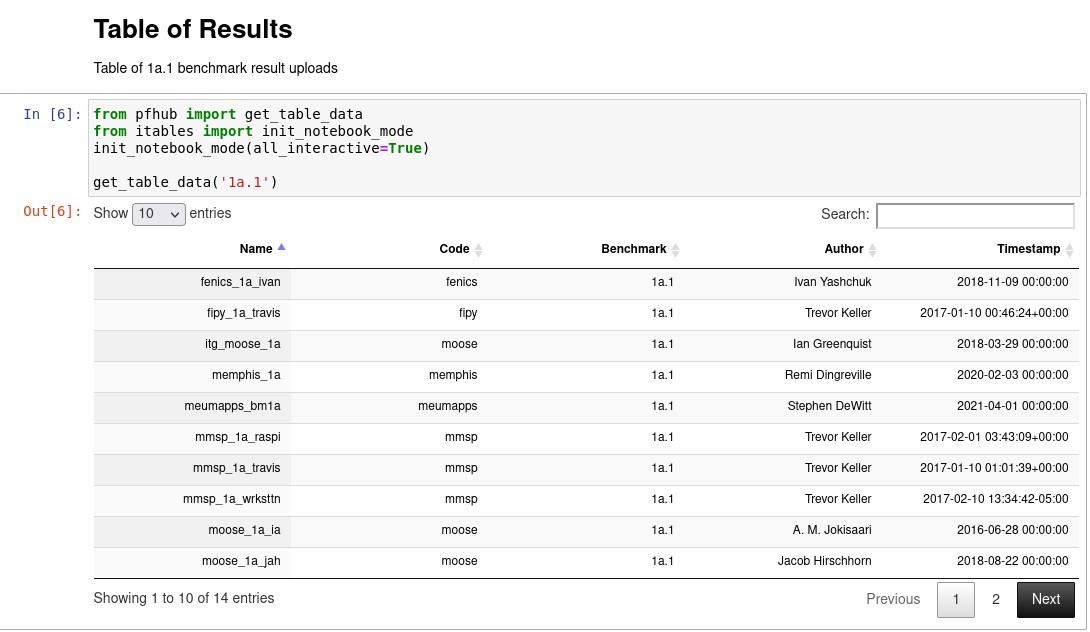
Jupyter Example
PFHUb PYTHON MODule
- Python package that deals with all data transformations and aggregations (implemented)
- All data exported as Pandas dataframes
- Easy for others to augment, develop, change
- Everything in Python
- Plotly has improved Python support
- Everything working outside of website setting
UPLOAD Procedure
- Fork example repository
-
Edit pfhub.yaml in repository
- Store data in forked repository
- Git LFS for large data
- PFHub extracts metadata from forks
- GitHub Actions rebuilds website and notebooks after fork
-
github Actions / Git LFS
- Use GitHub Actions / CI
- Stop using Staticman, Data app, Box app
- Use Git LFS
- Very low barrier solution both for maintenance and for users
No custom website
- Notebooks for everything
- Nbviewer for display
- Binder / Jupyter Hub instance for all notebooks
- GitHub wiki for content
- GitHub Actions + CI for all automation
- Git LFS for larger data
- No more apps to maintain
- ...maybe keep small Jekyll front page?