CUDA Basics
- Meta
- CPU vs. GPU
- Coding
- Optimization
Structure
1. Meta

What's the most heavy object known to humans?

C
ompute
U
D
A
nified
evice
rchitecture
General Purpose GPU-Computing
Use Cases
2. CPU vs. GPU
Single Instruction
Multiple Data



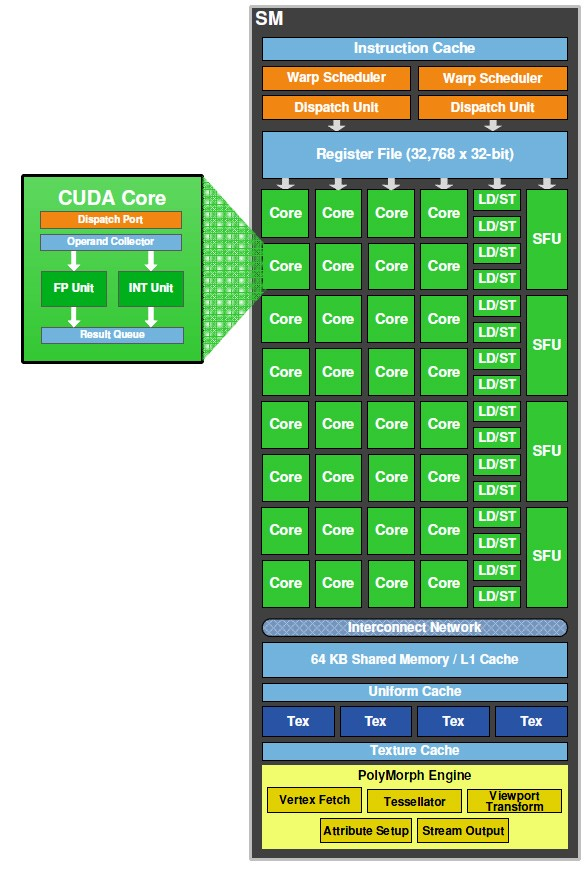
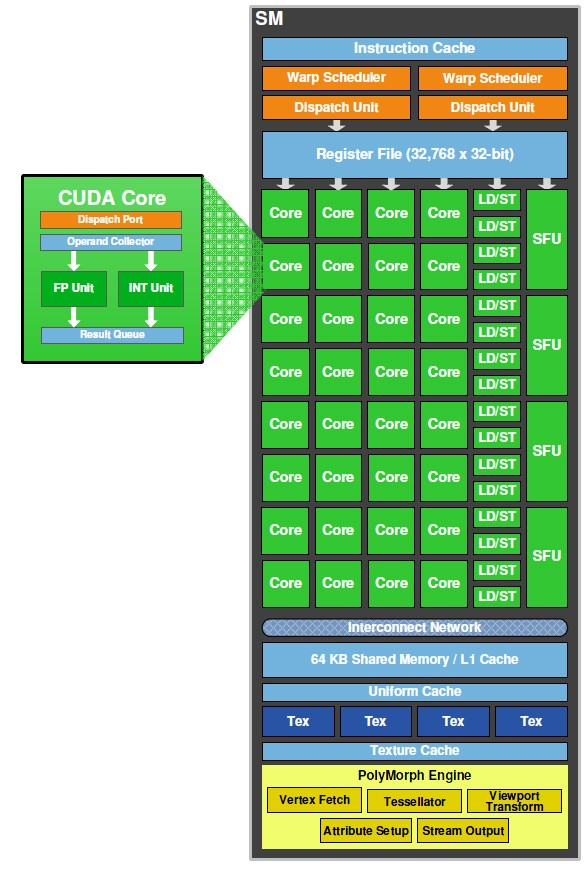
CUDA Cores?
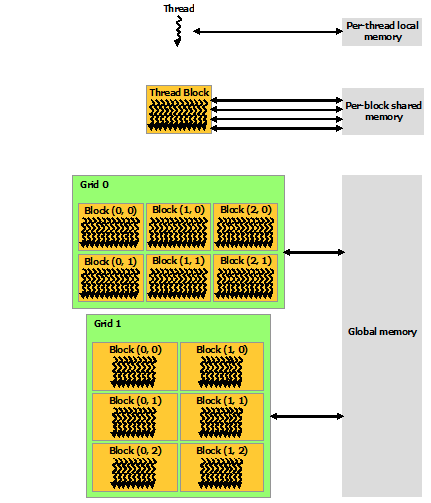
3. Coding
C
C++
Fortran
Perl
Python
Ruby
Java
.NET
Matlab
R
Mathematica
IDE?
File Extension
.cu
Compiling
nvcc -o helloWorld helloWorld.cu- sequential code
- kernel code
Compiling
nvcc -o helloWorld helloWorld.cu- sequential code
- kernel code
Parallel Thread eXecution
gcc
102
__host__
__global__
important
functions
Memory
cudaMalloc (void** devPtr,
size_t size)
cudaFree (void* devPtr)
cudaMemcpy (void* dst,
const void* src,
size_t count,
cudaMemcpyKind kind)5
basic
steps
GPU
RAM
1. global memory allocation
GPU
RAM
2. fill global memory
GPU
RAM
3. call kernel
GPU
RAM
4. read global memory
GPU
RAM
5. free global memory
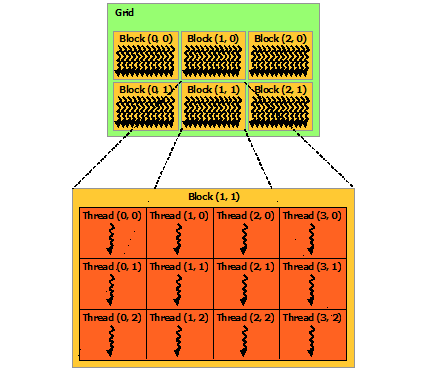
my_kernel<<<grid,block>>>
Kernel Call
dim3 gsize(3, 2, 1);
dim3 bsize(4, 3, 1);
my_kernel<<<gsize, bsize>>>
e.g.
gridDim.{x|y|z}
blockDim.{x|y|z}
blockId.{x|y|z}
threadId.{x|y|z}
Dimensions & IDs
#include "buddyKVGSum.cuh"
__device__ int gcd(int a, int b) {
if (a == 0) {
return b;
} else {
while (b != 0) {
if (a > b) {
a -= b;
} else {
b -= a;
}
}
return a;
}
}
__device__ int lcm(const int a, const int b, const int gcd) {
return (a / gcd) * b;
}
__device__ int f(const int a, const int b, const int min_lcm) {
return lcm(a, b, gcd(a, b)) >= min_lcm ? 1 : 0;
}
__global__ void buddyKVGSum(const Matrix a,
const Matrix b,
Matrix c,
const int n,
const int min_lcm) {
extern __shared__ int shared_copy[];
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
if (tx == 0) {
if (ty == 0) {
for (int i = 0; i < n; i++) {
shared_copy(0, i) = a(by, i);
}
} else if (ty == 1) {
for (int i = 0; i < n; i++) {
shared_copy(1, i) = b(bx, i);
}
}
}
__syncthreads();
if (f(shared_copy(0, tx), shared_copy(1, ty), min_lcm)) {
atomicAdd(&shared_copy[2*n], 1);
}
__syncthreads();
if (tx == 0 && ty == 0) {
c(bx, by) = shared_copy[2*n];
}
}
void print(const Matrix a, const int n) {
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
printf("%d ", a(i, j));
}
printf("\n");
}
}
void sum(const Matrix a,
const Matrix b,
Matrix c,
const int n,
const int min_lcm,
const int input_size,
const int verbose) {
Matrix ad, bd, cd;
int *nd, *min_lcmd;
gpuErrchk(cudaMalloc((void **)&ad, input_size));
gpuErrchk(cudaMalloc((void **)&bd, input_size));
gpuErrchk(cudaMalloc((void **)&cd, input_size));
gpuErrchk(cudaMalloc((void **)&nd, sizeof(int)));
gpuErrchk(cudaMalloc((void **)&min_lcmd, sizeof(int)));
gpuErrchk(cudaMemcpy(ad, a, input_size, cudaMemcpyHostToDevice));
gpuErrchk(cudaMemcpy(bd, b, input_size, cudaMemcpyHostToDevice));
gpuErrchk(cudaMemcpy((void *)nd, (void *)&n, sizeof(int), cudaMemcpyHostToDevice));
gpuErrchk(cudaMemcpy((void *)min_lcmd, (void *)&min_lcm, sizeof(int), cudaMemcpyHostToDevice));
if (0 != (2 & verbose)) {
print(a, n);
printf("\n");
print(b, n);
printf("\n");
}
dim3 gsize(n, n);
dim3 bsize(n, n);
clock_t time = clock();
buddyKVGSum<<<gsize, bsize, (2*n+1)*sizeof(int)>>>(ad, bd, cd, n, min_lcm);
gpuErrchk(cudaDeviceSynchronize());
time = clock() - time;
gpuErrchk(cudaMemcpy(c, cd, input_size, cudaMemcpyDeviceToHost));
if (0 != (1 & verbose)) {
print(c, n);
printf("\n");
}
printf("Execution time: %f\n", (float) time / CLOCKS_PER_SEC);
gpuErrchk(cudaFree(ad));
gpuErrchk(cudaFree(bd));
gpuErrchk(cudaFree(cd));
cudaDeviceReset();
}
int main(int argc, char **argv) {
if (argc < 5) {
printf("Program must be called with at least 4 parameters.");
return 42;
}
const int n = atoi(argv[1]);
const int m = atoi(argv[2]);
const int min_lcm = atoi(argv[3]);
const int seed = atoi(argv[4]);
const int verbose = argc > 5 ? atoi(argv[5]) : 0;
const int matrix_size = n * n;
const int input_size = matrix_size * sizeof(int);
Matrix a = (Matrix) malloc(input_size),
b = (Matrix) malloc(input_size),
c = (Matrix) malloc(input_size);
srand(seed);
int i, j;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
a(i, j) = rand() % (m - 1) + 1;
}
}
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
b(i, j) = rand() % (m - 1) + 1;
}
}
sum(a, b, c, n, min_lcm, input_size, verbose);
free(a);
free(b);
free(c);
return EXIT_SUCCESS;
}
4. Optimization
Optimizations
- many threads per SM
- same flow for all threads
- register & shared memory
- prefetching
- memory coalescing
- tiling
Memory Coalescing
read this data
with
threads!
4
| ... | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | a | b | c | d | e | f | ... |
memory look like this:
thread 1
thread 2
thread 3
thread 4
0
4
8
c
1
5
9
d
2
6
a
e
3
8
b
f
T1
T2
T3
T4
thread 1
thread 2
thread 3
thread 4
0
4
8
c
1
5
9
d
2
6
a
e
3
8
b
f
thread 1
thread 2
thread 3
thread 4
0
1
2
3
4
5
6
7
8
9
a
b
c
d
e
f
Tiling
Memory
task
s
Summary
- CPU: sequential
- cores execute threads
- GPU: parallel
, same operation
, much data
in blocks
in a grid
- CUDA is C-like
care for your memory!
optimize its usage!
think multidimensional!