ONLINE
MACHINE LEARNING
Darius Aliulis
A little about me
- Software Engineer / R&D Scientist @ DATA DOG / SATALIA
- Assistant lecturer @ Kaunas University of Technology
Business Big Data Analytics Master's study programme
- Formal background in Applied Mathematics (MSc), studied
@ Kaunas University of Technology (KTU)
@ Technical University of Denmark (DTU)
- Interested in:
- Solving Hard Problems
- Operational Machine Learning
- Streaming Analytics
- Functional & Reactive Programming
Batch vs Online Learning
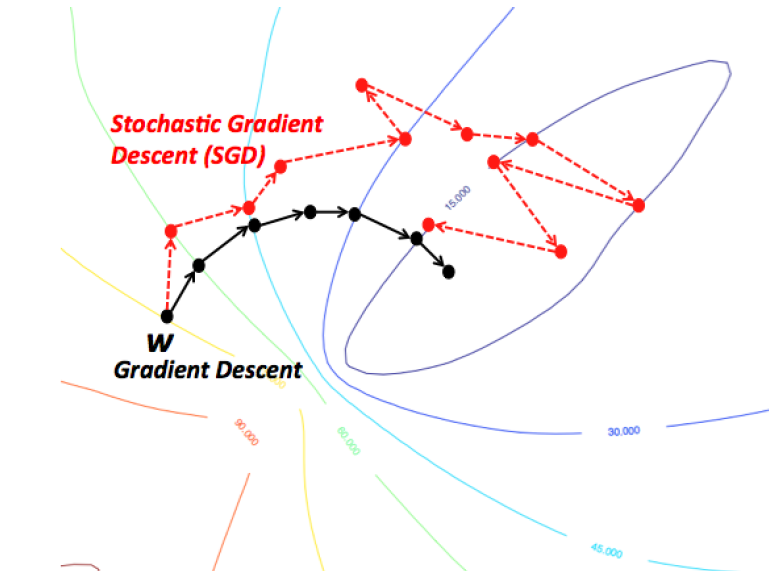
image source: https://wikidocs.net/3413
Intuition via Gradient Descent vs Stochastic Gradient Desccent
command line

it's not going away soon :)
Unix philosophy
As summarized by Peter H. Salus in A Quarter-Century of Unix (1994):[1]
- Write programs that do one thing and do it well.
- Write programs to work together.
- Write programs to handle text streams, because that is a universal interface.
command line tools used
- zsh
- cd, mv, rm, tar, tree, wc
- echo, cat, less, head, tail, cut, paste
- awk, sed
- parallel
- ...
click features
- is lazily composable without restrictions
- fully follows the Unix command line conventions
- supports loading values from environment variables out of the box
- supports for prompting of custom values
- is fully nestable and composable
- works the same in Python 2 and 3
- supports file handling out of the box
- comes with useful common helpers (getting terminal dimensions, ANSI colors, fetching direct keyboard input, screen clearing, finding config paths, launching apps and editors, etc.)
click alternatives
vowpal wabbit
Research project started by John Langford (initially Yahoo, now Microsoft)
Fast and scalable due to
- Out-of-core online learning: no need to load all data into memory
- Feature hashing trick
- Multi-threaded (parsing, learning)
- Distributed
- Highly optimized C++ code
- Command line interface
- Packages for Python, R, ...
vowpal wabbit
Multiple learning algorithms / models
- OLS regression
- Matrix factorization (sparse matrix SVD)
- Single layer neural net (with user specified hidden layer node count)
- Searn (Search and Learn)
- Latent Dirichlet Allocation (LDA)
- Stagewise polynomial approximation
- Recommend top-K out of N
- One-against-all (OAA) and cost-sensitive OAA reduction for multi-class
- Weighted all pairs
- Contextual-bandit
vowpal wabbit
Loss functions:
- squared
- logistic
- hinge
- quantile
- poisson
Optimization algorithms:
- stochastic gradient descent
- L-BFGS
- conjugate gradient
vw input format
[Label] (|[Namespace] Features)...Namespace=String[:Value]Features=(String[:Value])...here
tsv line
0 2 0 1 287e684f 0a519c5c 02cf9876vw line
-1 |n 1:2 2:0 3:1 4__287e684f 5__0a519c5c 6__02cf9876Example:
simplified format
CTR prediction example
LIVE
what could go wrong? :)
Regularization for Regressgion
source: scikit-learn docs
R(w) := \frac{1}{2} \sum_{i=1}^{n} w_i^2
L2 norm:
R(w) := \sum_{i=1}^{n} |w_i|
L1 norm:
leads to shrinked coefficients
leads to sparse coefficients
R(w) := \frac{\rho}{2} \sum_{i=1}^{n} w_i^2 + (1-\rho) \sum_{i=1}^{n} |w_i|
Elastic Net:

Thank you!
Let's talk now!