Neural networks modelled by dynamical systems
Davide Murari
DNA Seminar - 20/06/2022


\(\texttt{davide.murari@ntnu.no}\)
Joint work with Elena Celledoni, Brynjulf Owren,
Carola-Bibiane Schönlieb and Ferdia Sherry
Outline
What is supervised learning
Consider two sets \(\mathcal{C}\) and \(\mathcal{D}\) and suppose to be interested in a specific (unknown) mapping \(F:\mathcal{C}\rightarrow \mathcal{D}\).
The data we have available can be of two types:
- Direct measurements of \(F\): \(\mathcal{T} = \{(x_i,y_i=F(x_i)\}_{i=1,...,N}\subset\mathcal{C}\times\mathcal{D}\)
- Indirect measurements that characterize \(F\): \(\mathcal{I} = \{(x_i,z_i=G(F(x_i))\}_{i=1,...,N}\subset\mathcal{C}\times G(\mathcal{D})\)
GOAL: Approximate \(F\) on all \(\mathcal{C}\).
What are neural networks

What are neural networks
They are compositions of parametric functions
\( \mathcal{NN}(x) = f_{\theta_k}\circ ... \circ f_{\theta_1}(x)\)
Examples
\(f_{\theta}(x) = x + B\Sigma(Ax+b),\quad \theta = (A,B,b)\)
ResNets
Feed Forward
Networks
\(f_{\theta}(x) = B\Sigma(Ax+b),\quad \theta = (A,B,b)\)
\(\Sigma(z) = [\sigma(z_1),...,\sigma(z_n)],\quad \sigma:\mathbb{R}\rightarrow\mathbb{R}\)
Neural networks modelled by dynamical systems
EXPLICIT
EULER
\( \Psi_{f_i}^{h_i}(x) = x + h_i f_i(x)\)
\( \dot{x}(t) = f(t,x(t),\theta(t)) \)
Time discretization : \(0 = t_1 < ... < t_k <t_{k+1}= T \), \(h_i = t_{i+1}-t_{i}\)
Where \(f_i(x) = f(t_i,x,\theta(t_i))\)
EXAMPLE
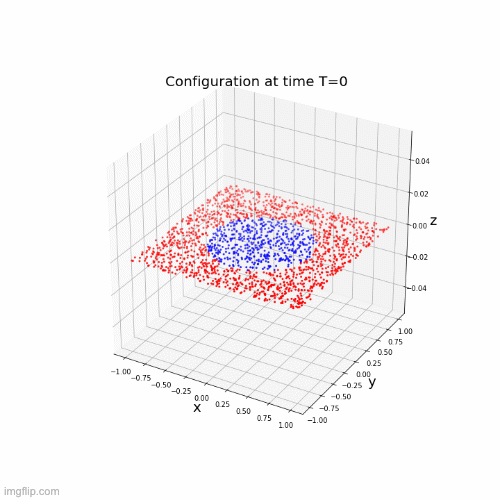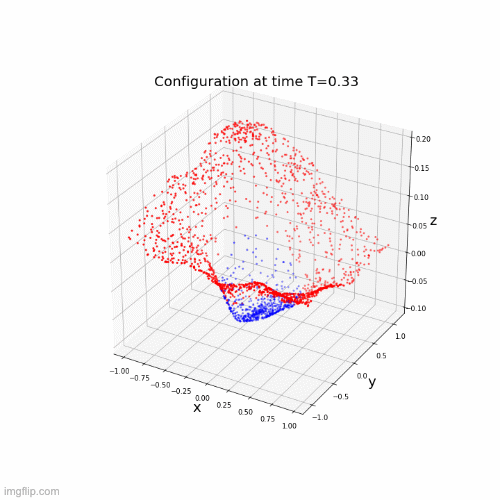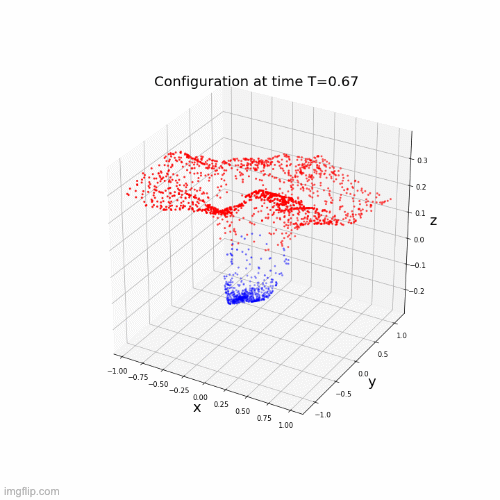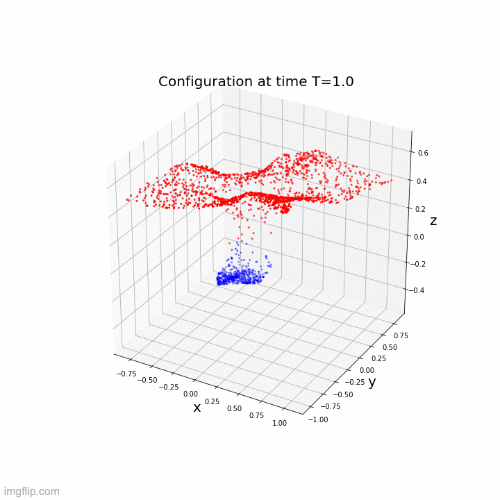
\(\dot{x}(t) = \Sigma(A(t)x(t) + b(t))\)
Imposing some structure
MASS PRESERVING NETWORKS
HAMILTONIAN NETWORKS
VOLUME PRESERVING, INVERTIBLE
Approximation result
Then \(F\) can be approximated arbitrarily well by composing flow maps of gradient and sphere preserving vector fields.
Approximation result
The classification problem
Given a "sufficiently large" set of \(N\) points in \(\mathcal{M}\subset\mathbb{R}^k\) that belong to \(C\) classes, we want to learn a function \(F\) assigning all the points of \(\mathcal{M}\) to the correct class.
Adversarial examples

What is a robust classifier?
An \(\varepsilon\)-robust classifier is a function that not only correctly classifies the points in \(\mathcal{M}\) but also those in
Suppose that
1.
2.
In other words, we should learn a
such that
Sensitivity measures for \(F\)
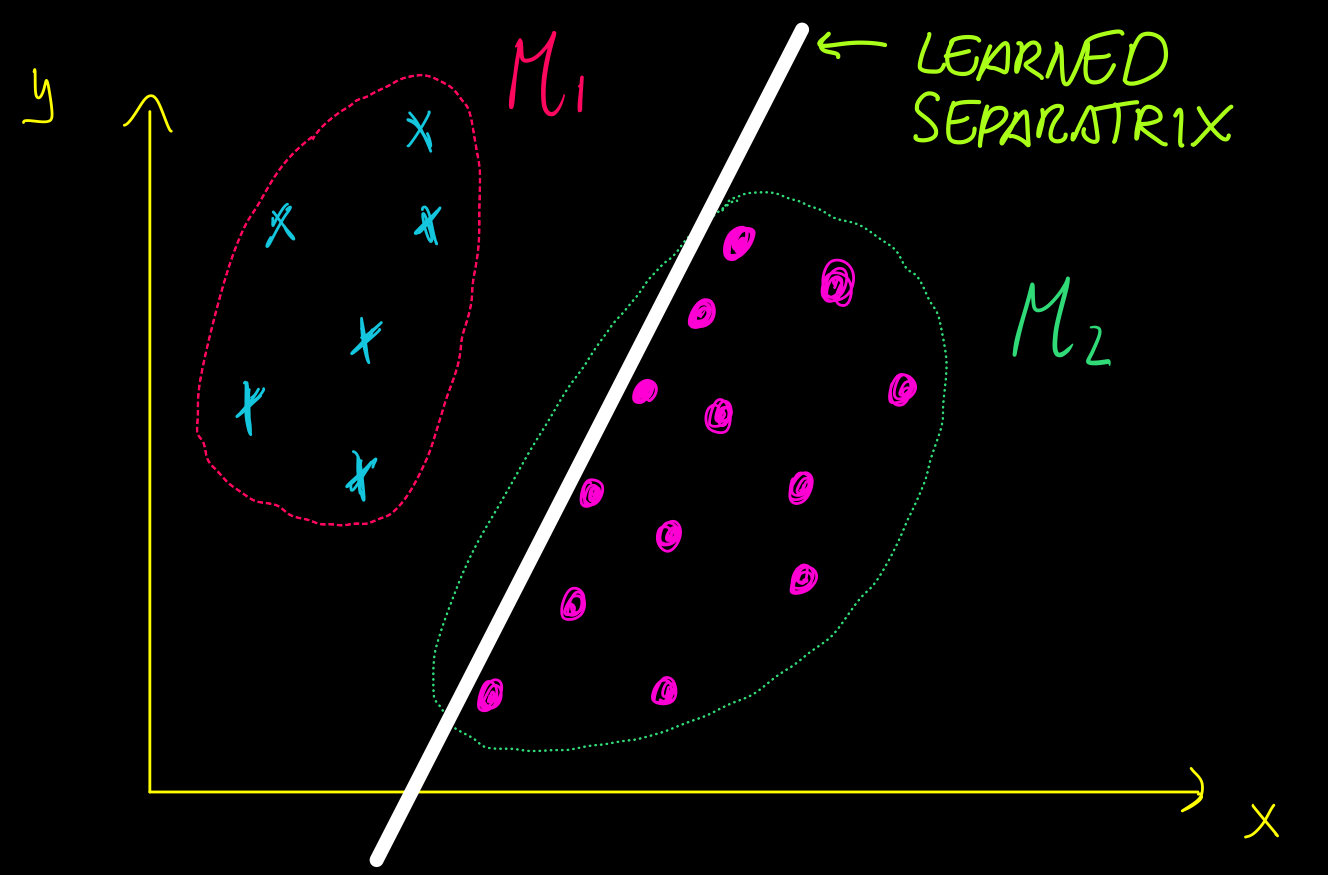
Idea:
"GOOD"
"BAD"
How to have guaranteed robustness
1️⃣
2️⃣
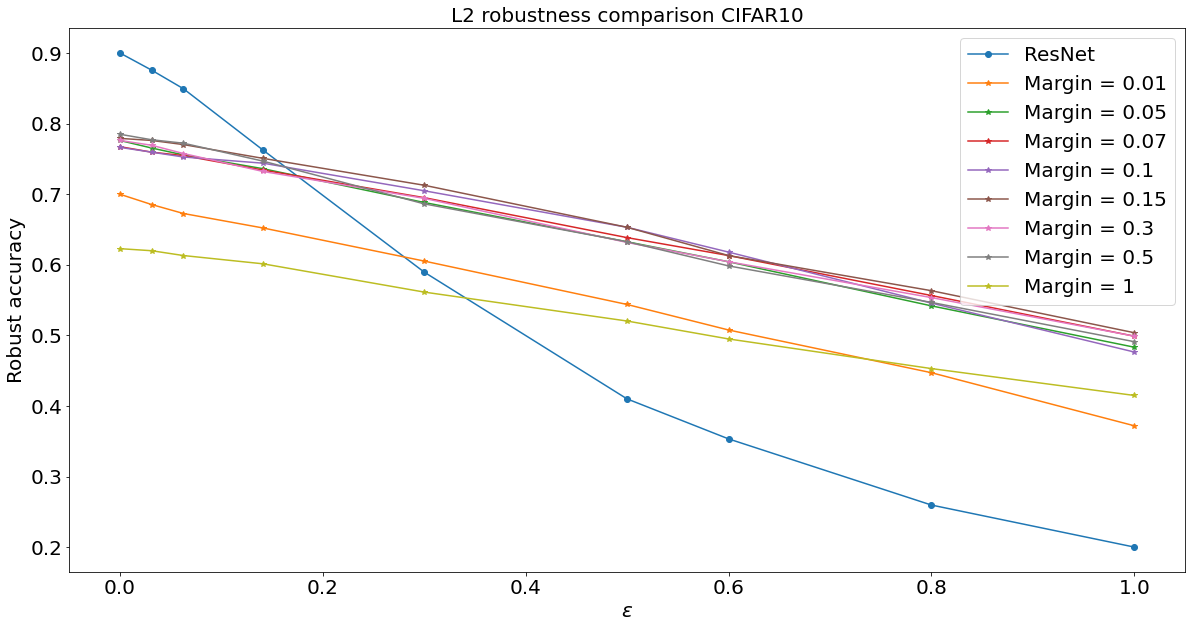
We constrain the Lipschitz constant of \(F\)
Lipschitz networks based on dynamical systems
Lipschitz networks based on dynamical systems
Adversarial robustness
Thank you for the attention