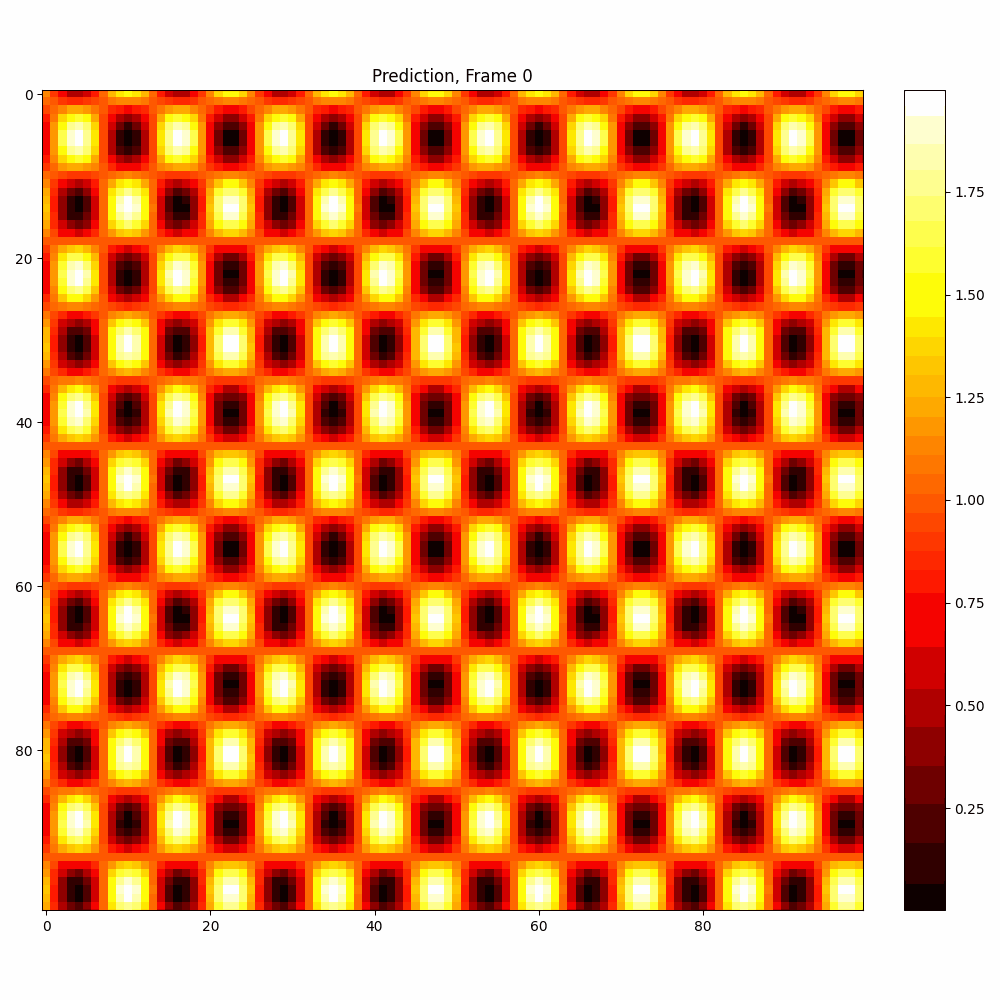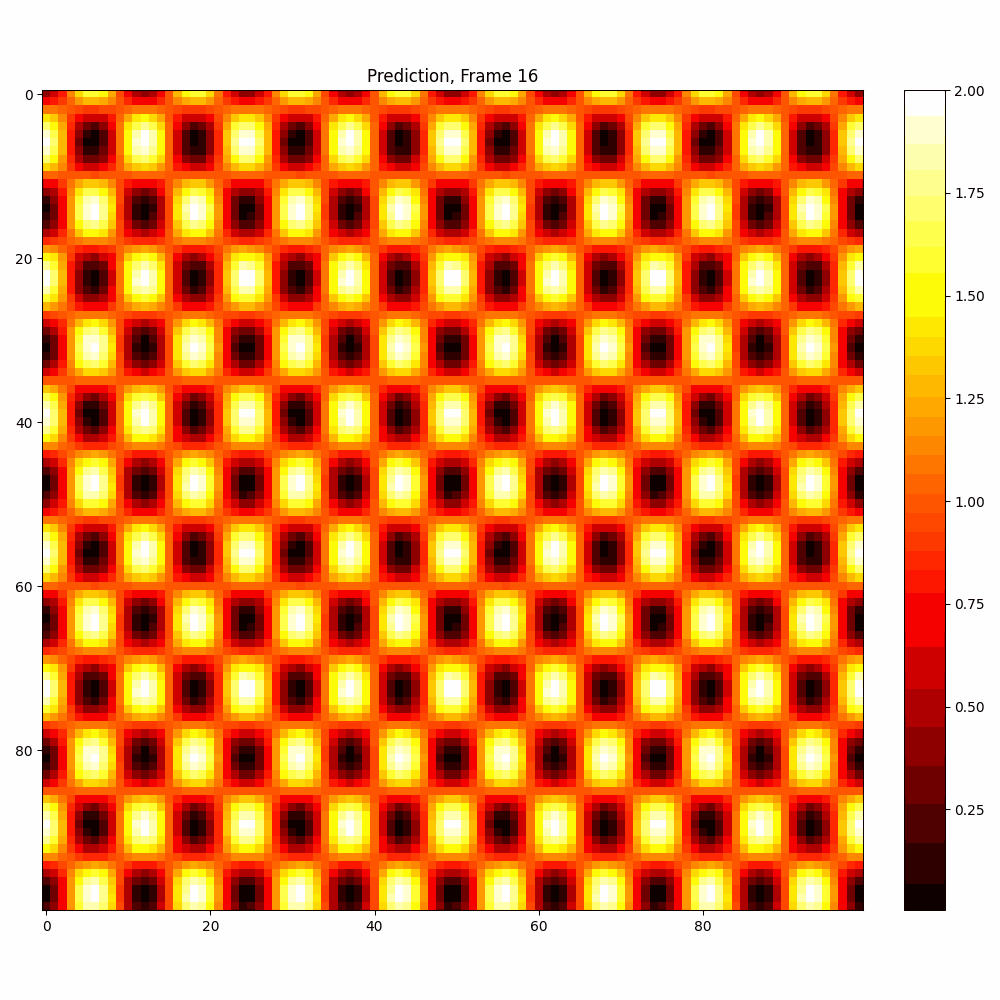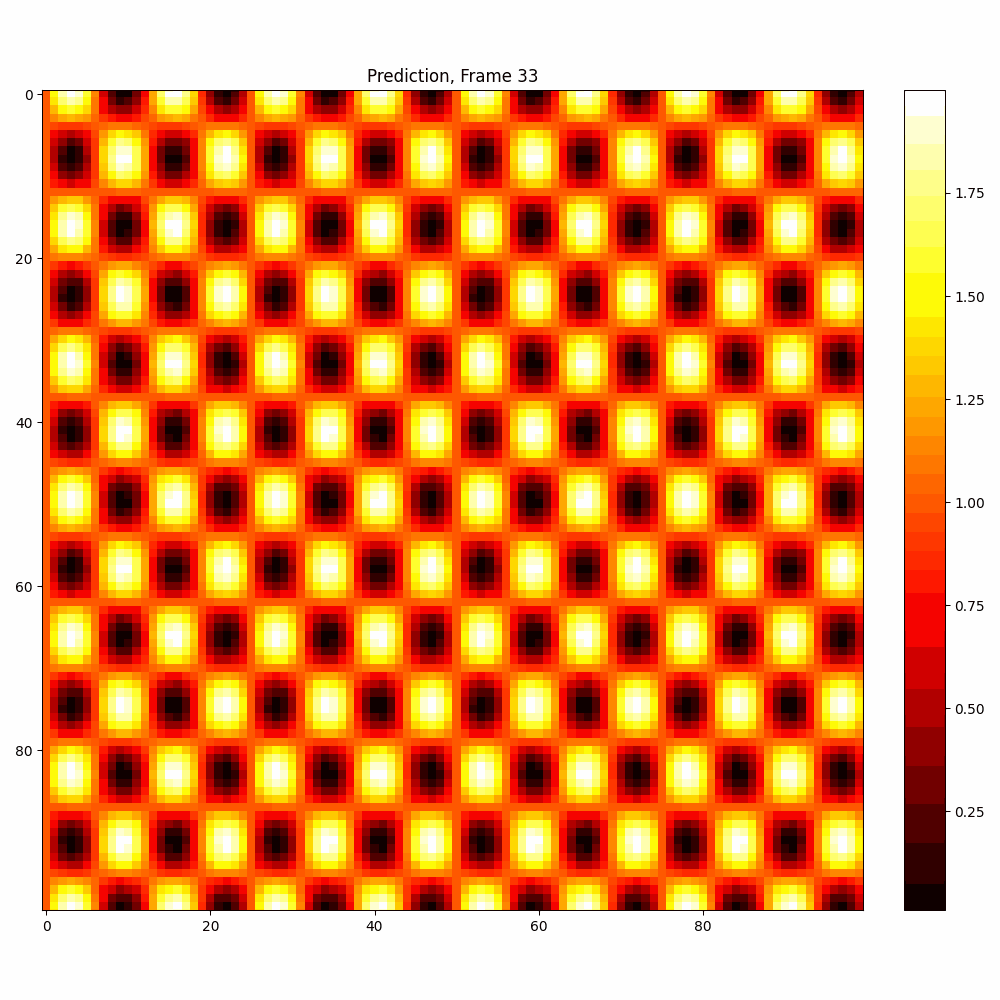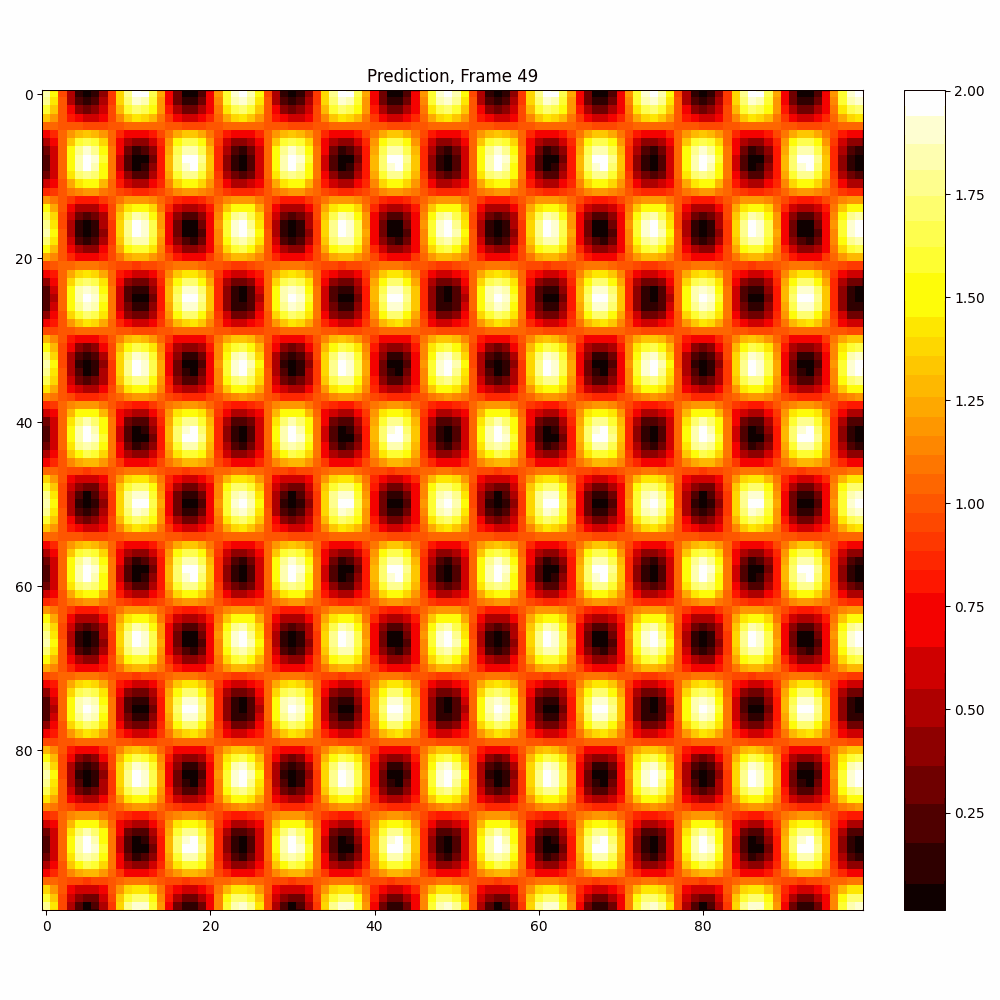
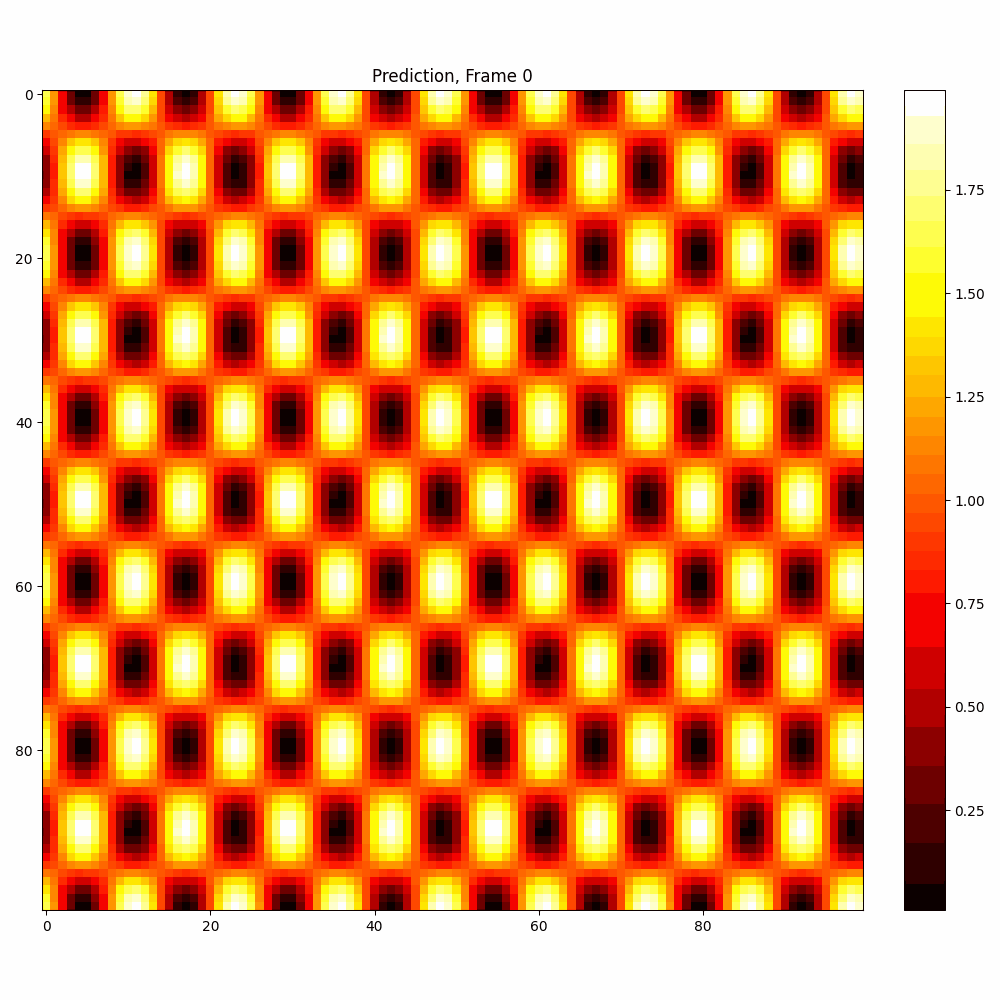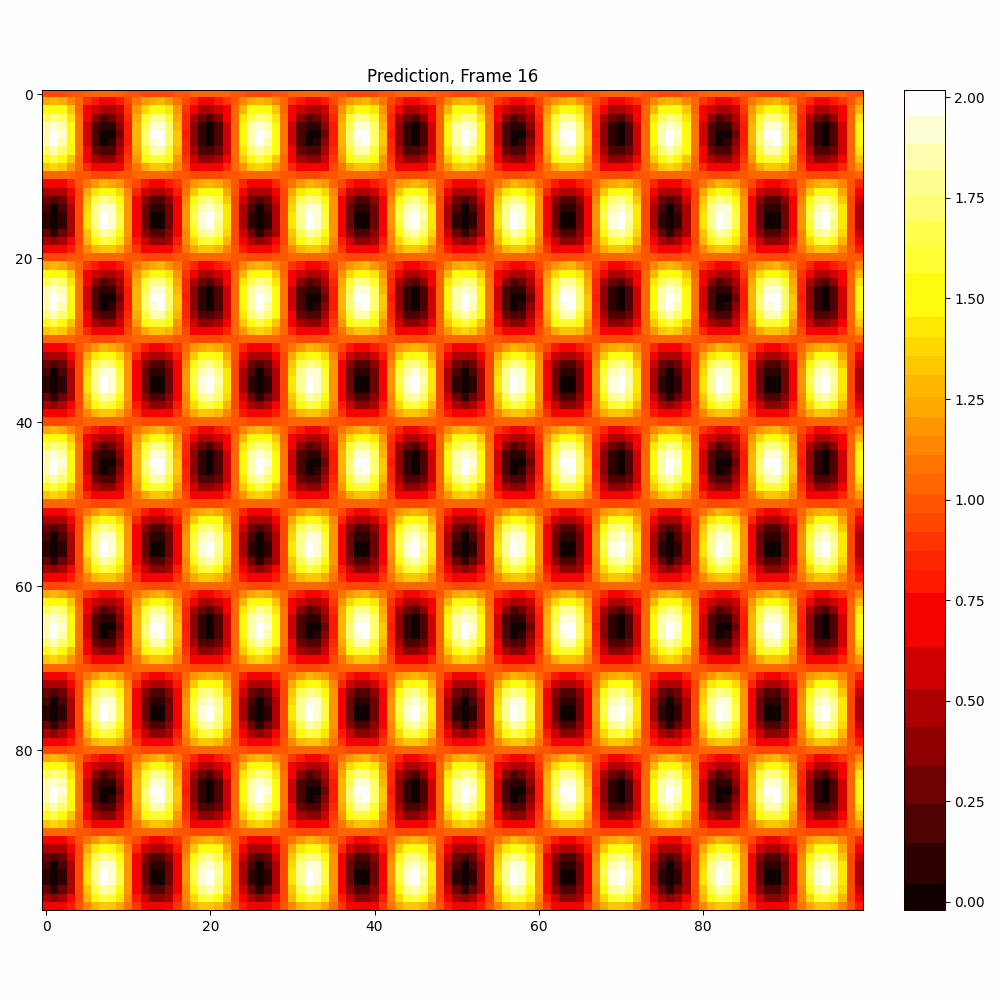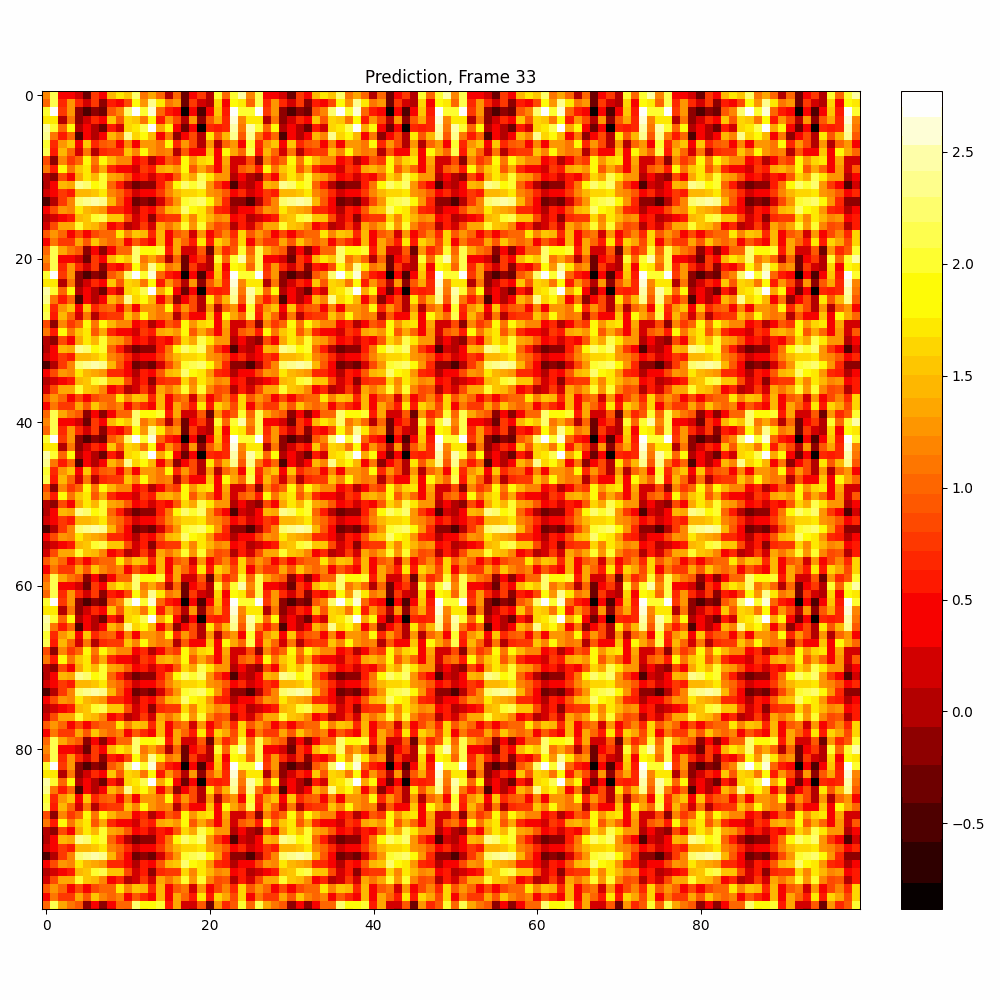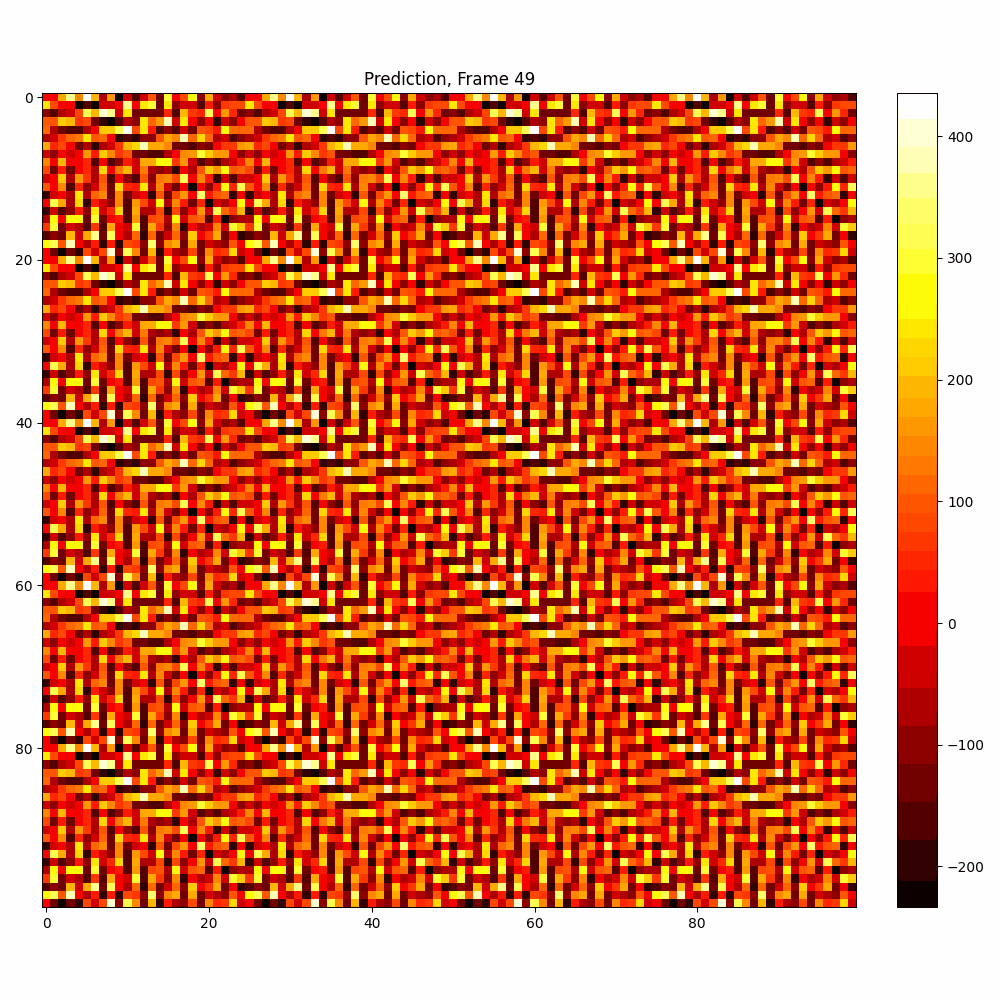
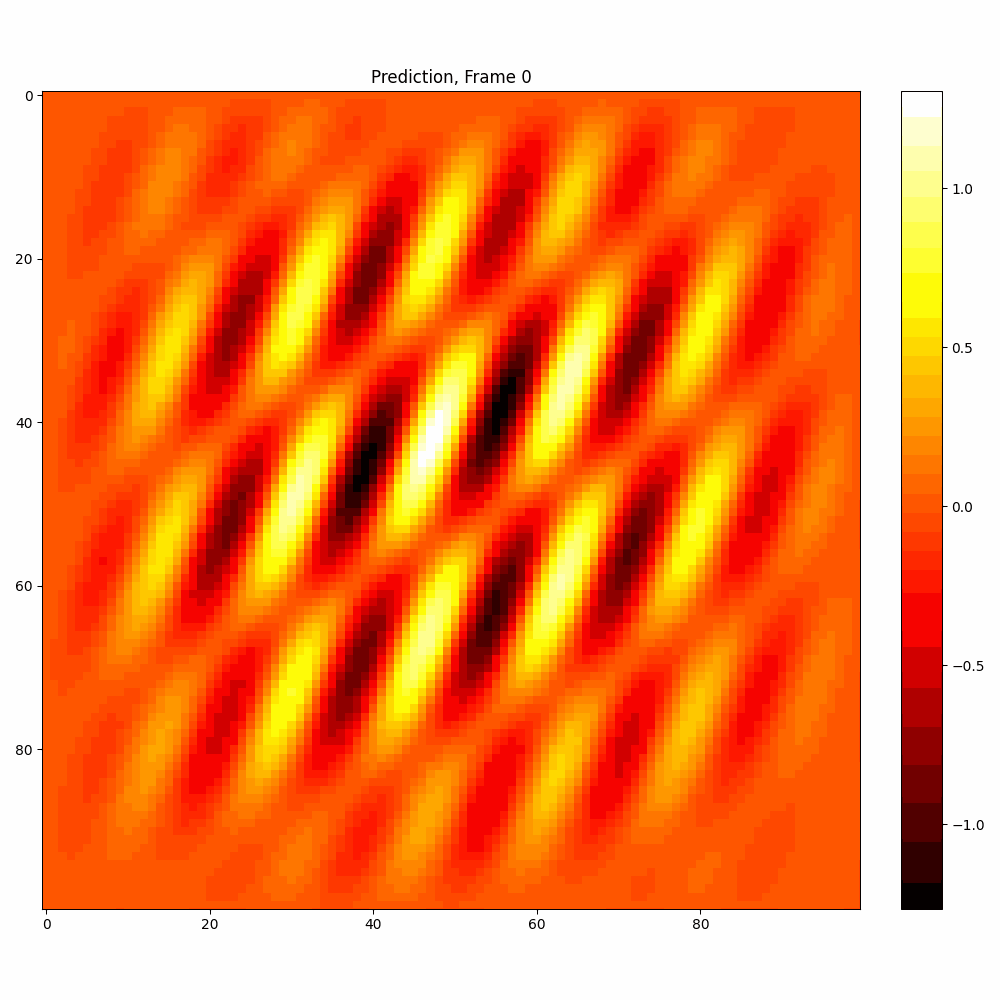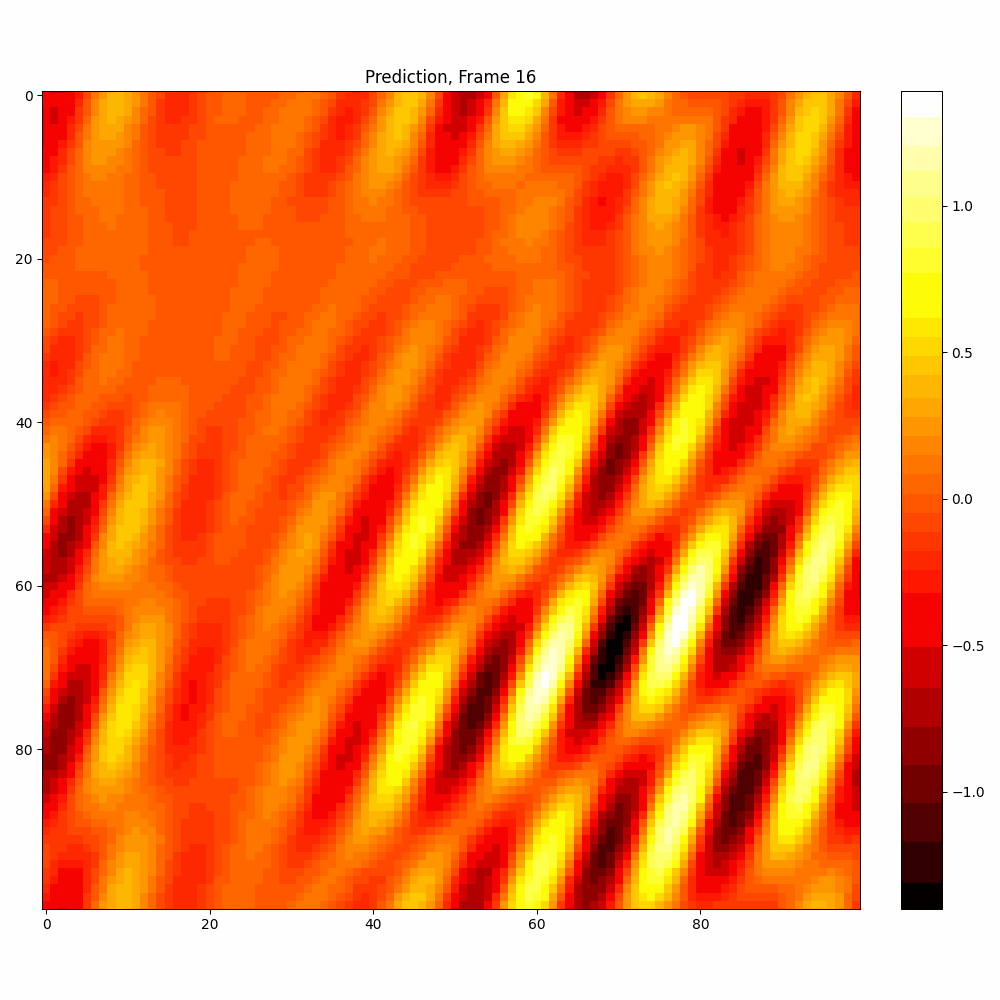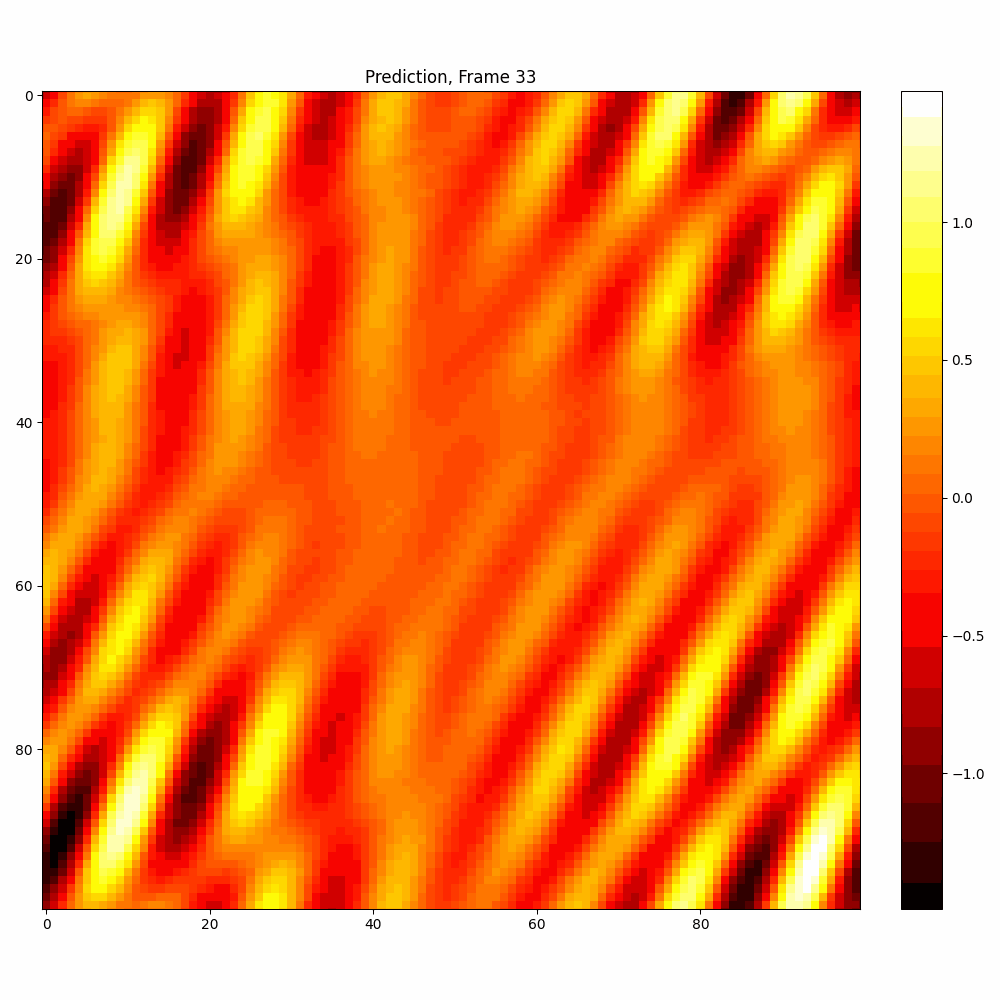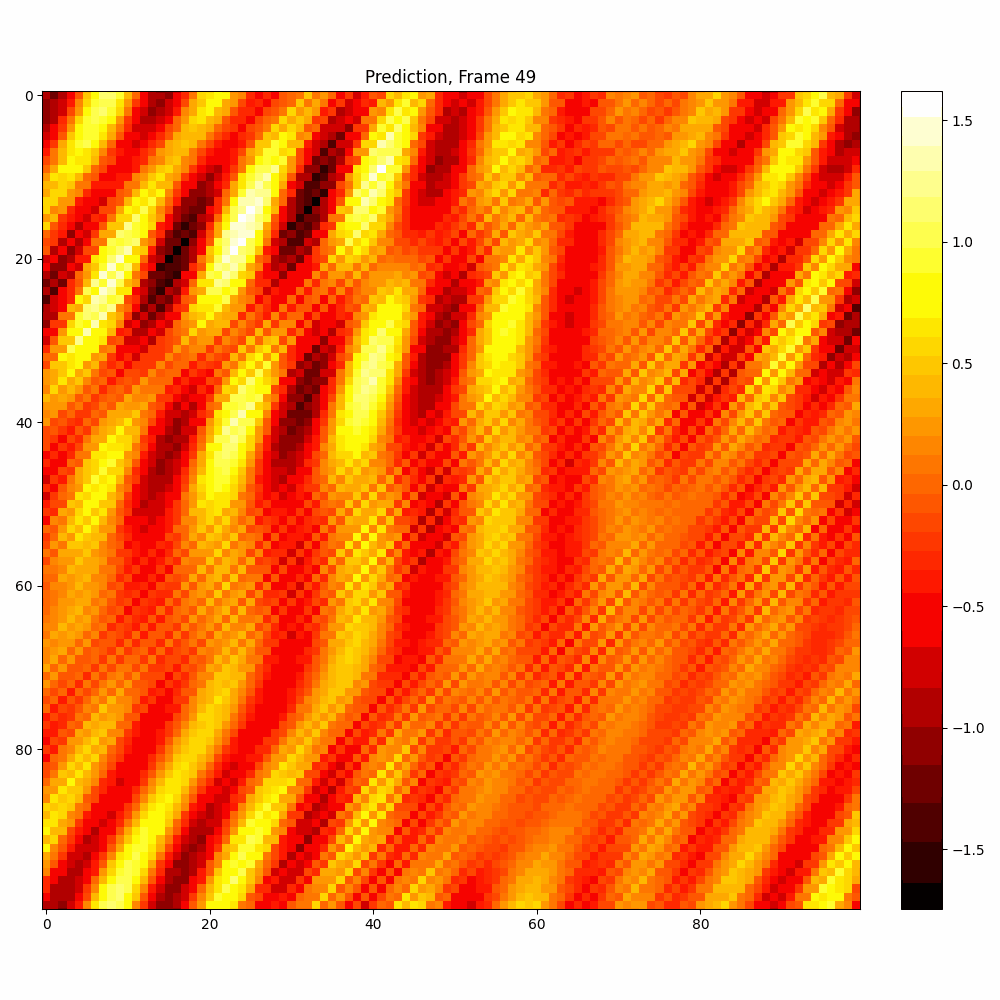
Current results predictions from Pixel data
Neptune runs are here :
Architecture
Linear case:
\begin{split}
U_0 &= U\\
U_{i+1} &= U_i + \frac{\delta T}{L}v*\mathrm{ReLU}(K*U_i),\,\,i=0,...,L-1
\end{split}
Non linear case:
\begin{split}
U_0 &= U\\
U_{i+1} &= U_i + \frac{\delta T}{L}K*U_i,\,\,i=0,...,L-1
\end{split}
K\in\mathbb{R}^{1\times 1\times 5\times 5}
K\in\mathbb{R}^{2\times 1\times 5\times 5},\,\,v\in\mathbb{R}^{1\times 2\times 1\times 1}\\
\text{initialization of v: }v=[1,-1]
Checkerboard DATASET
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | Yes |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 639 |
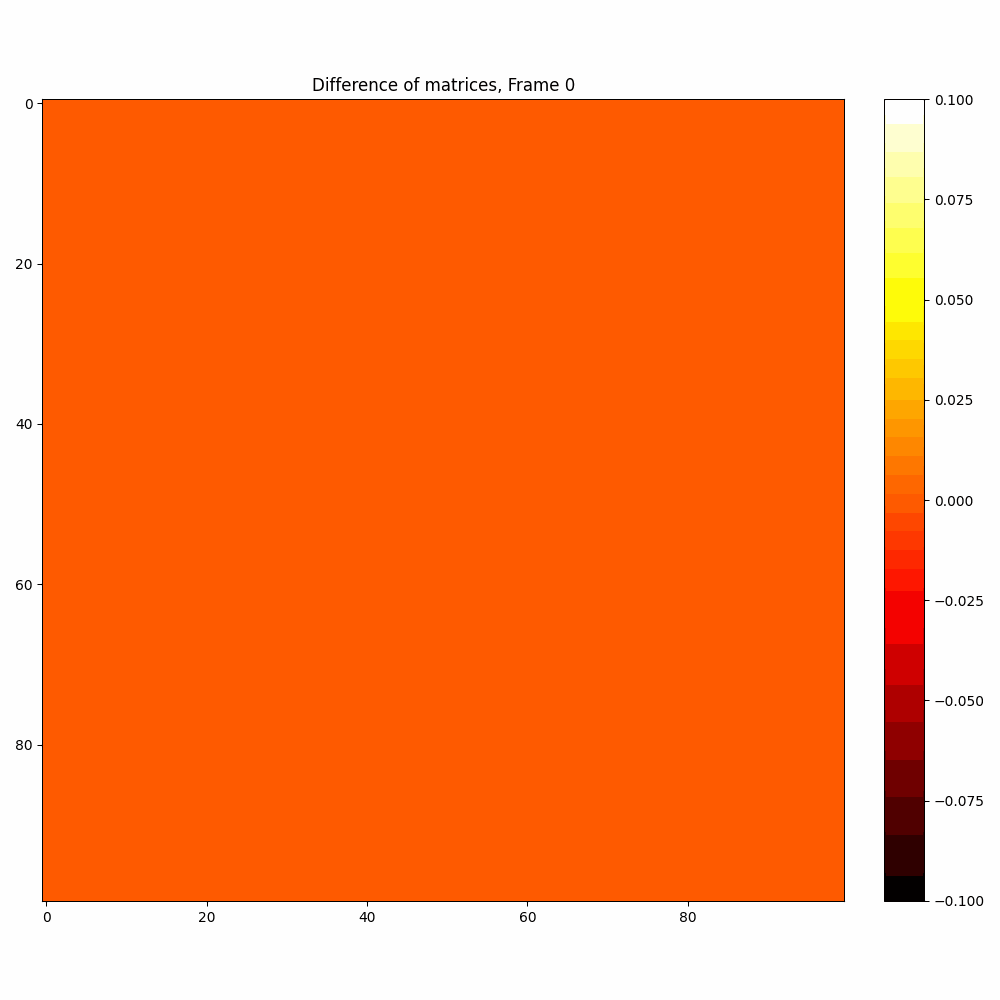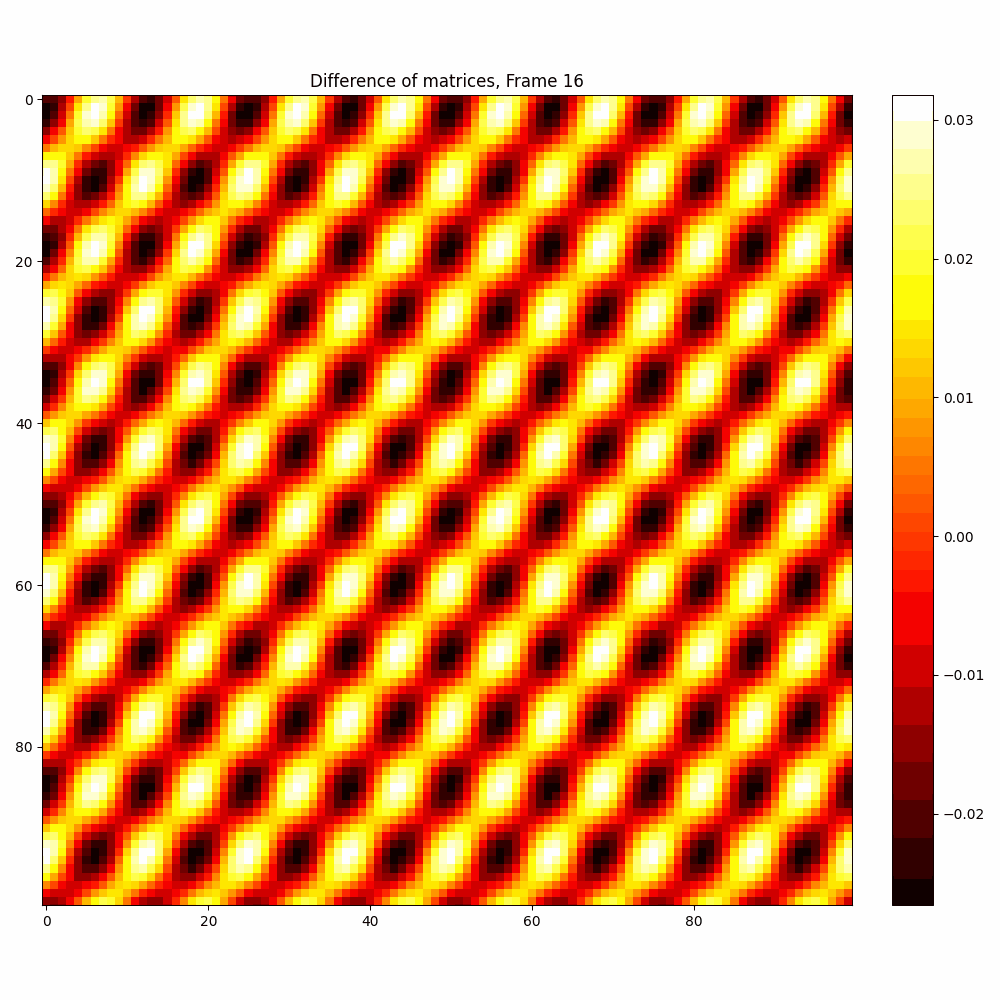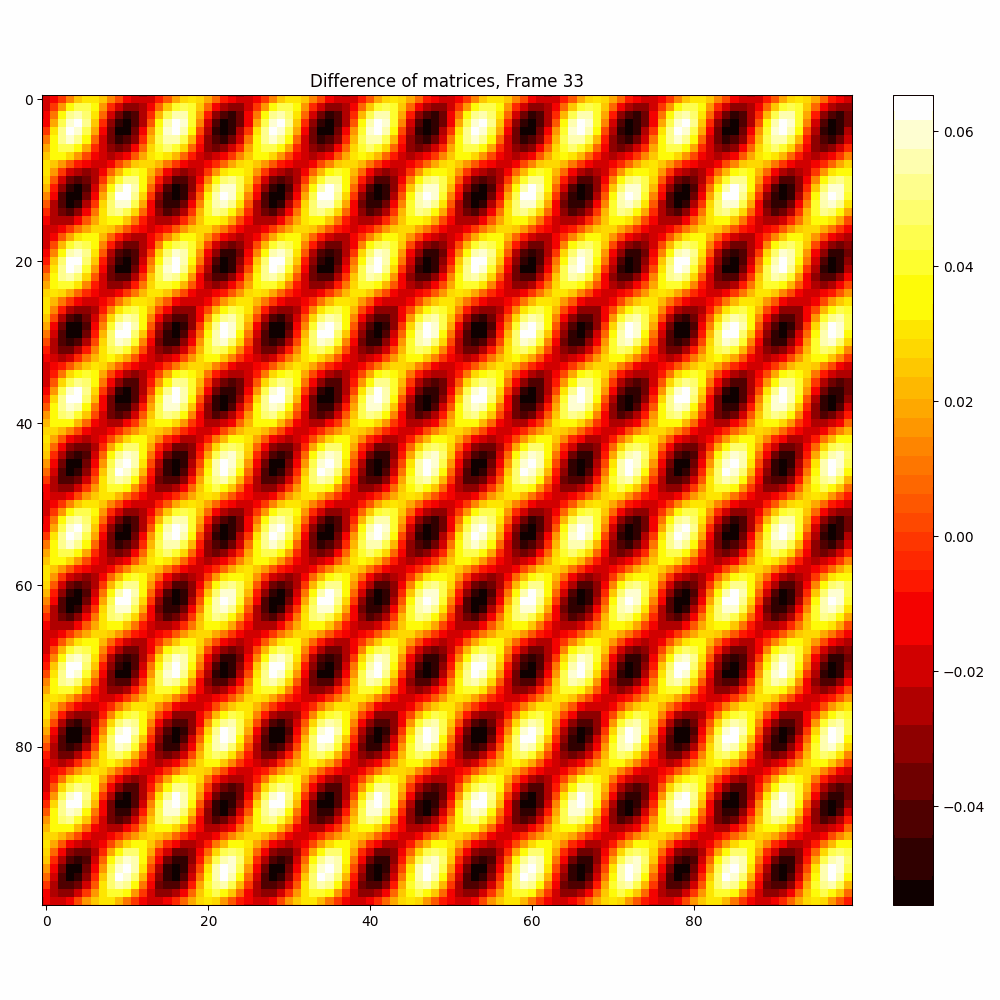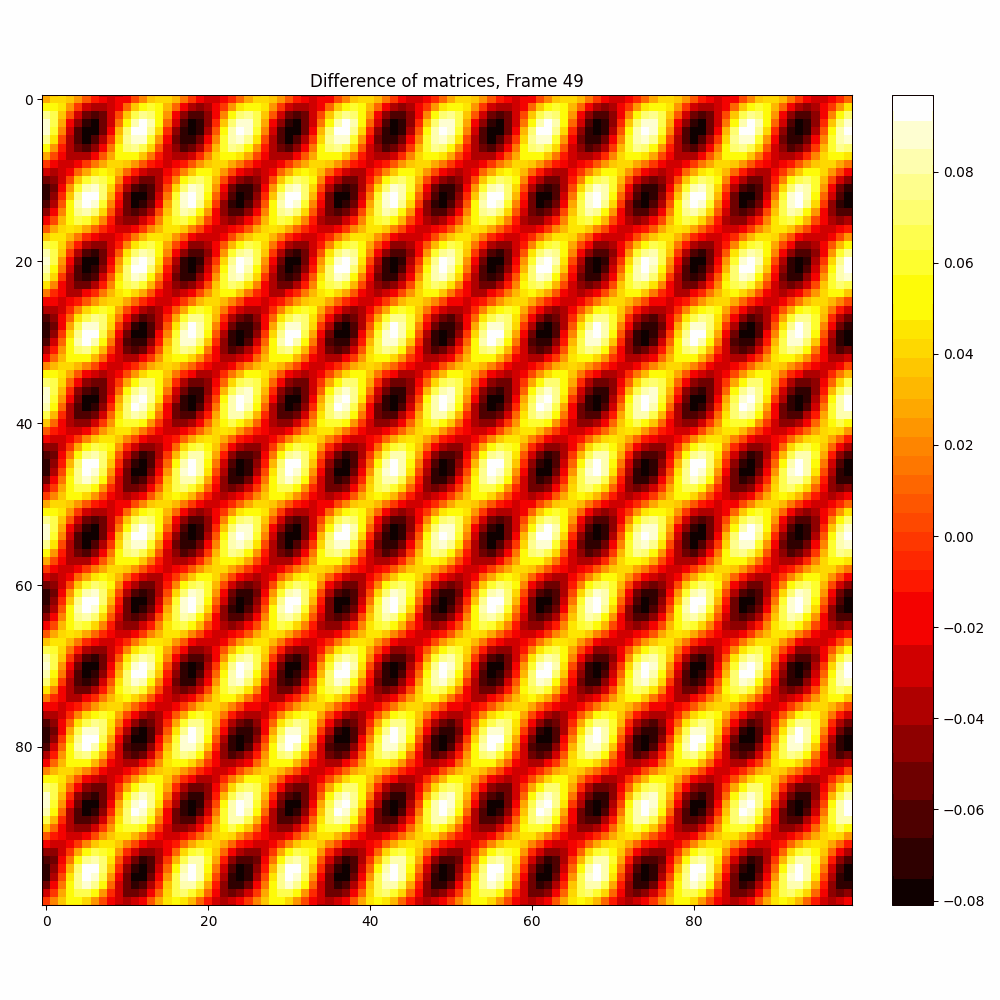
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | No (but all trainable weights) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 640 |
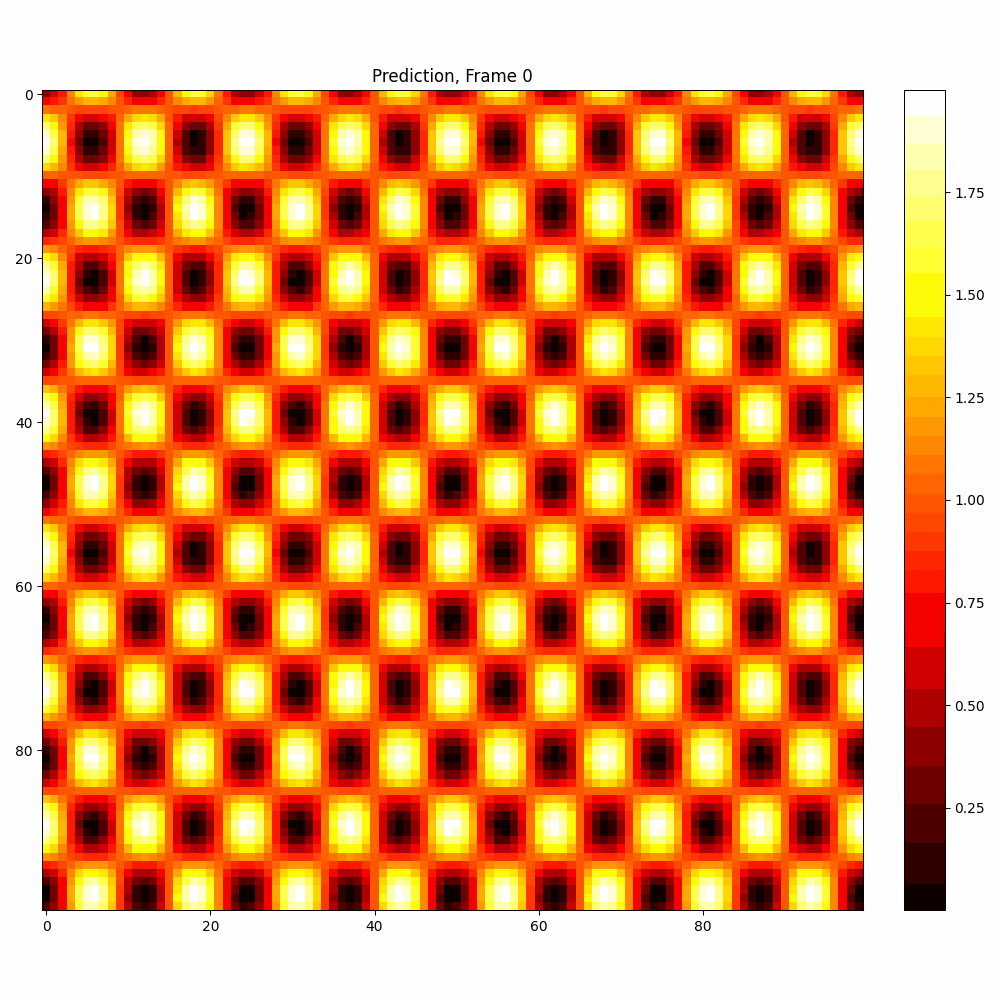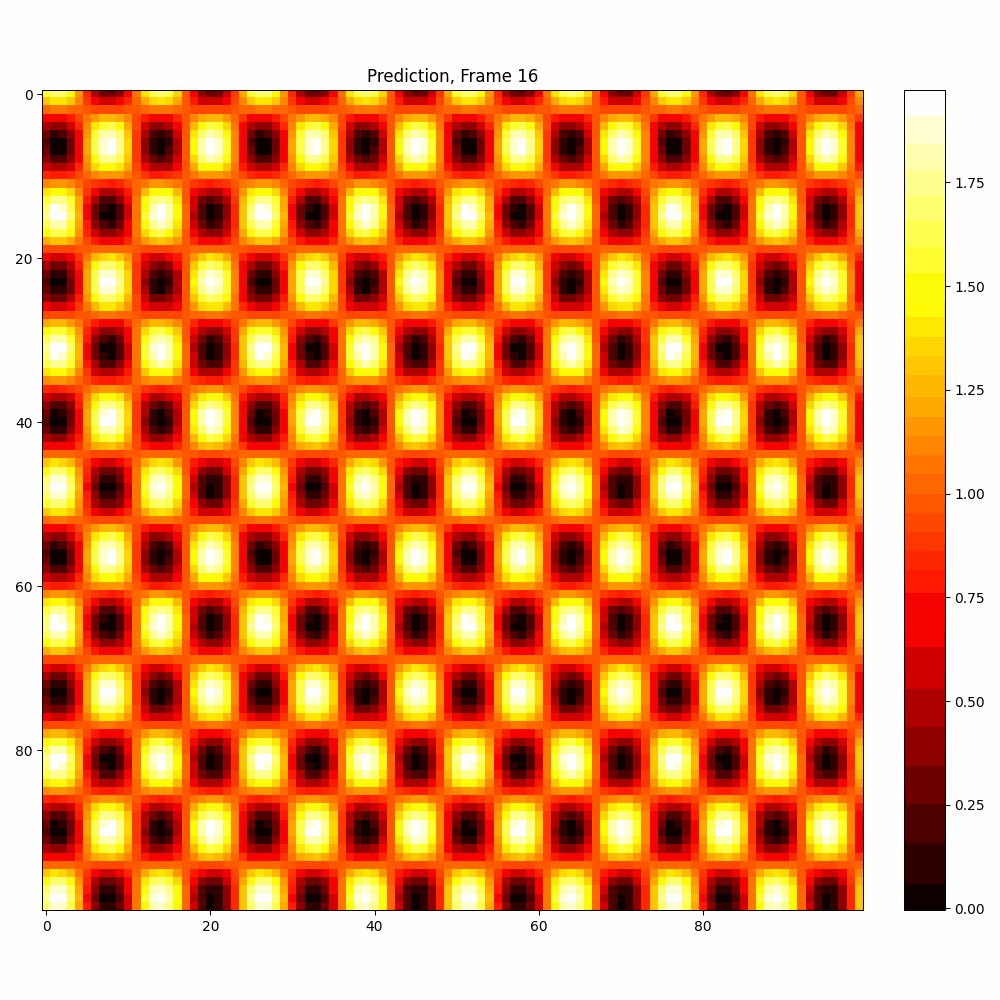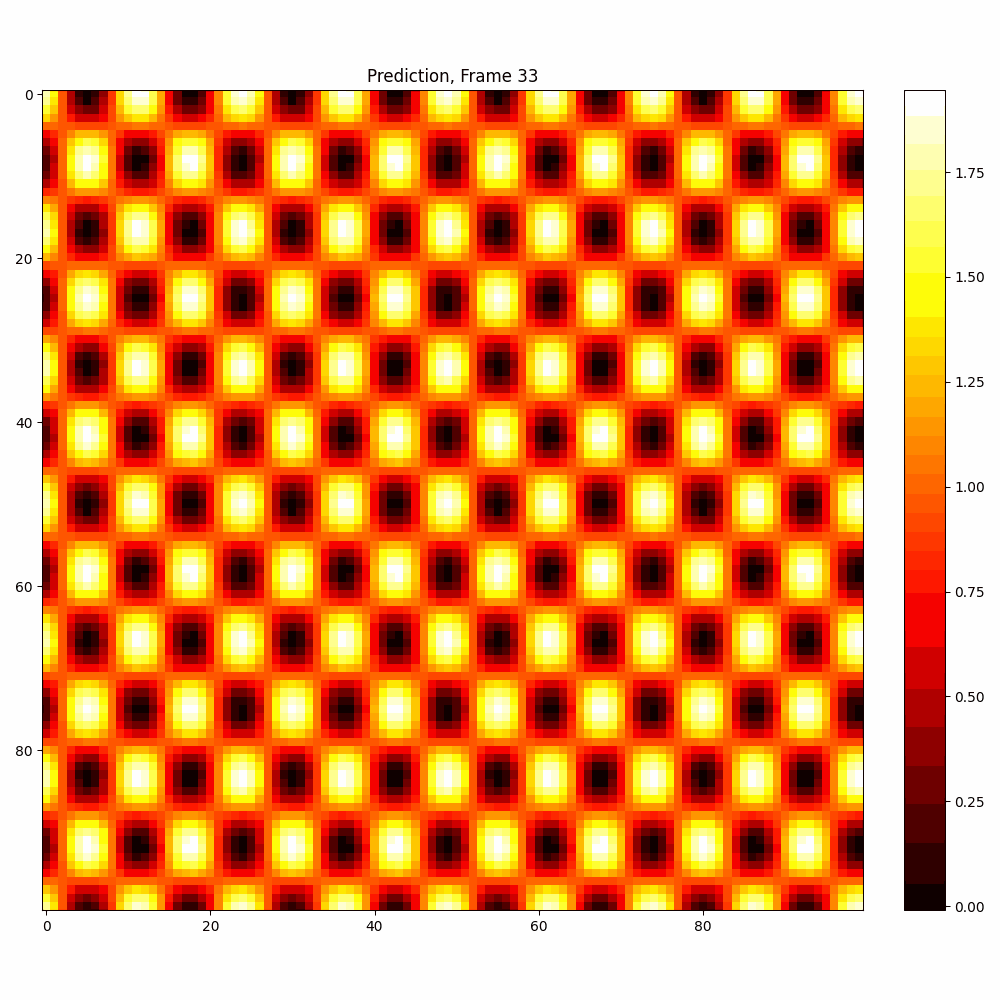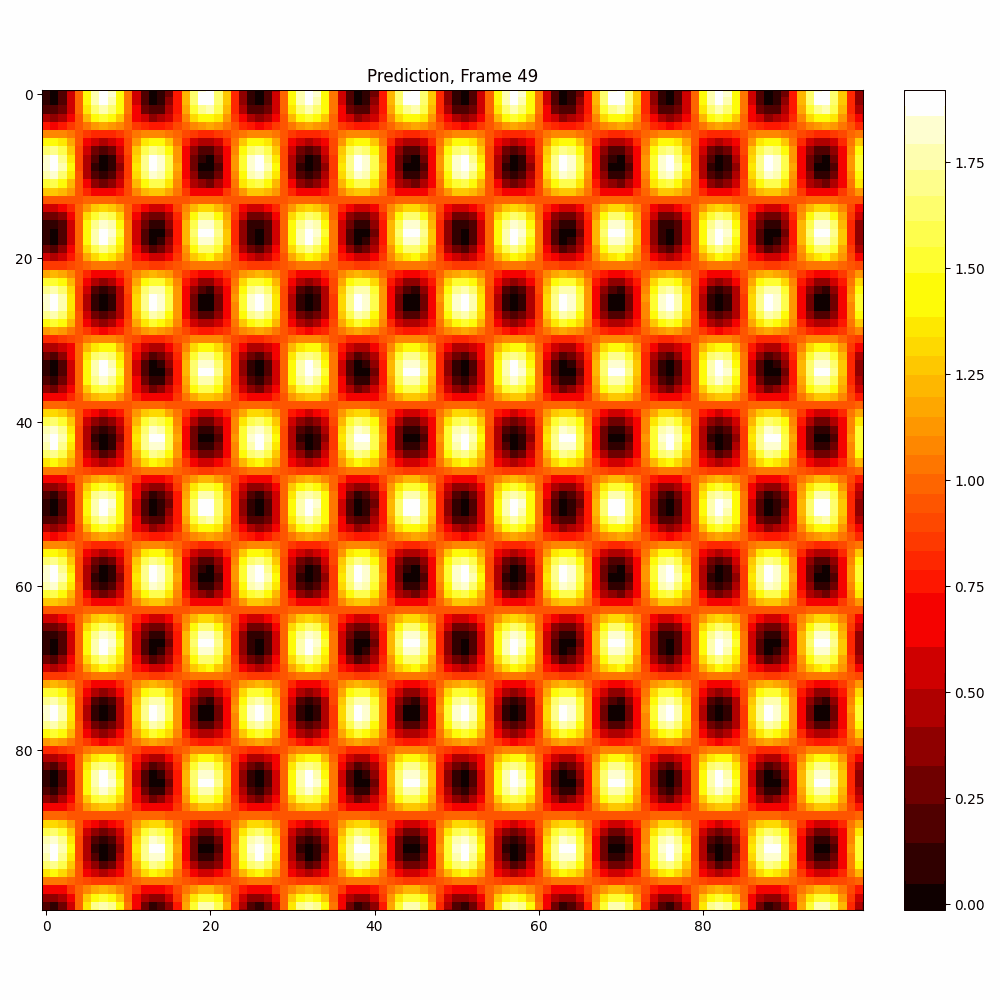
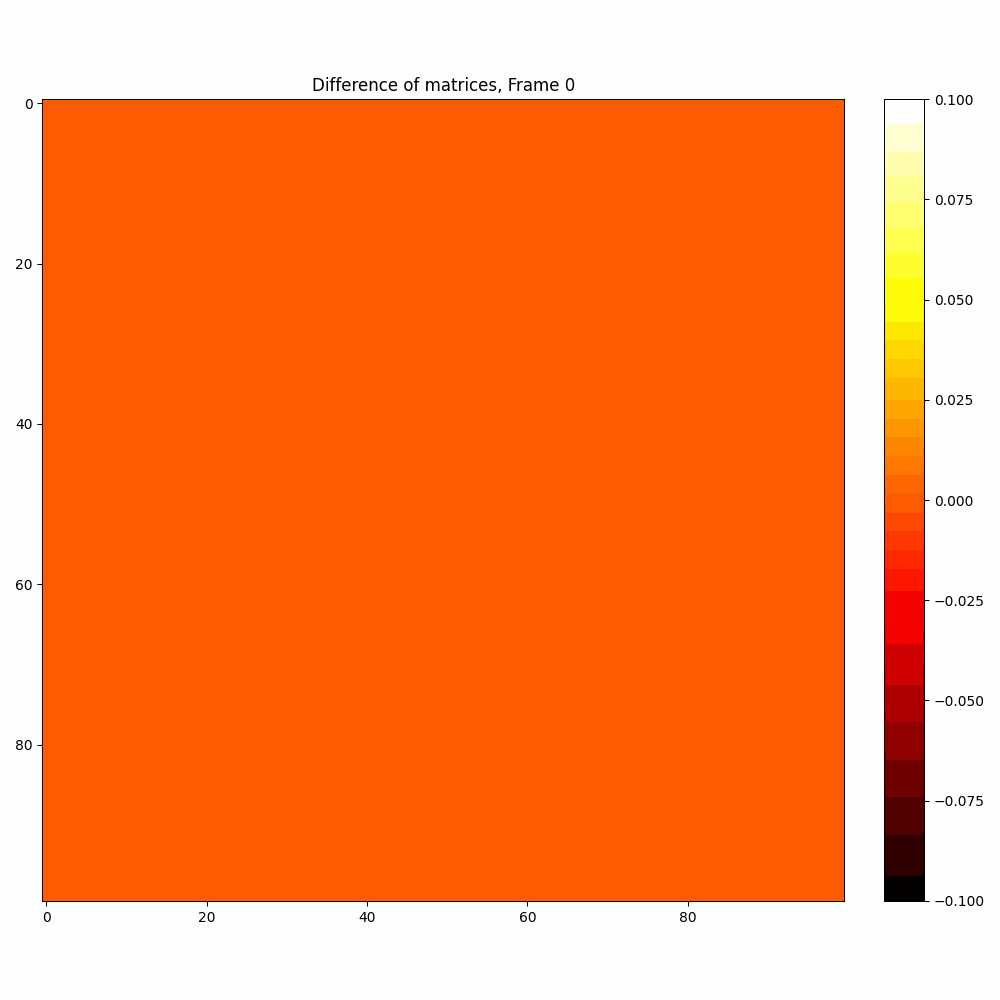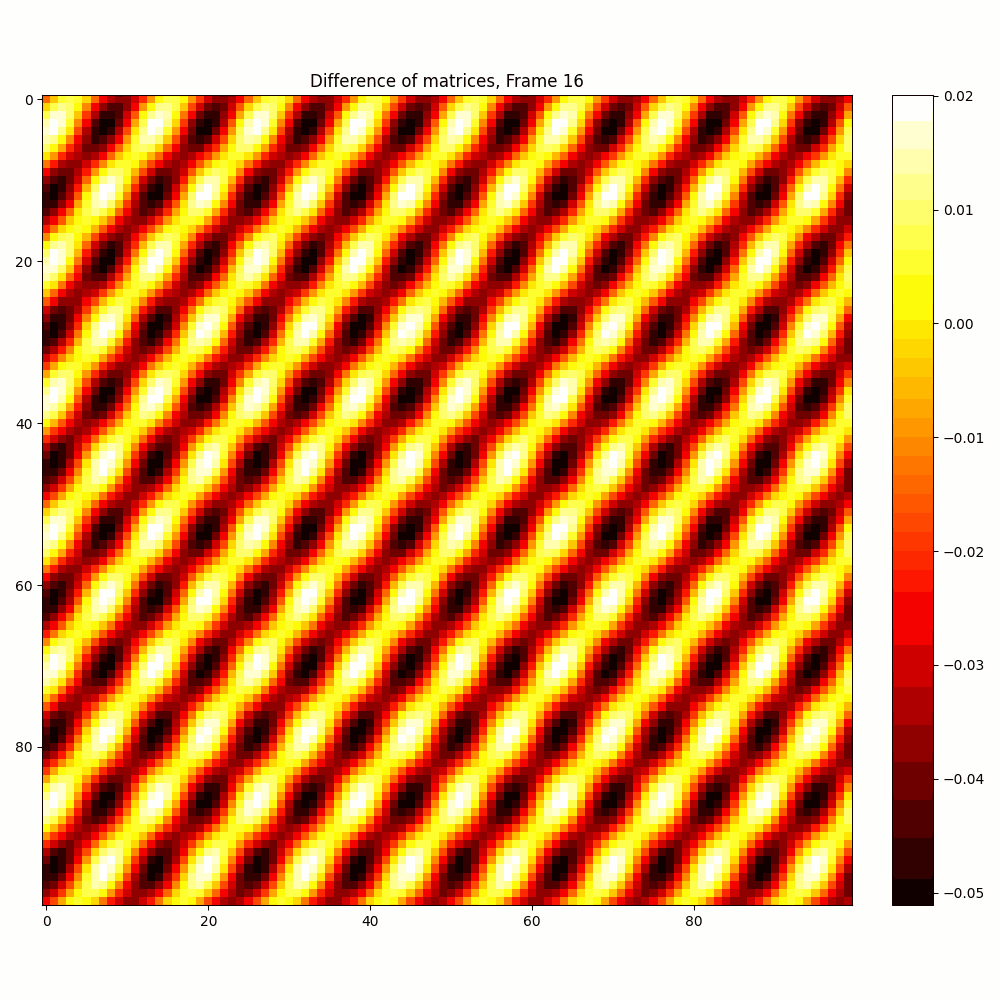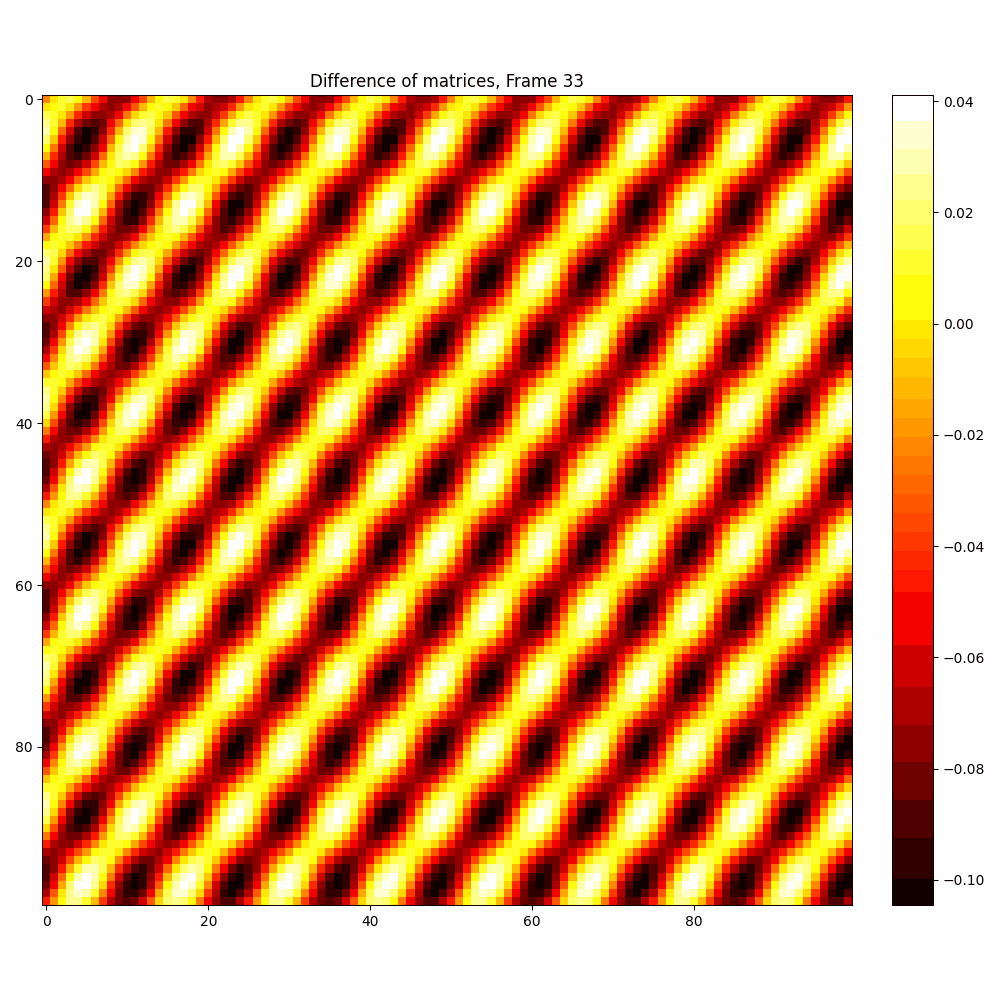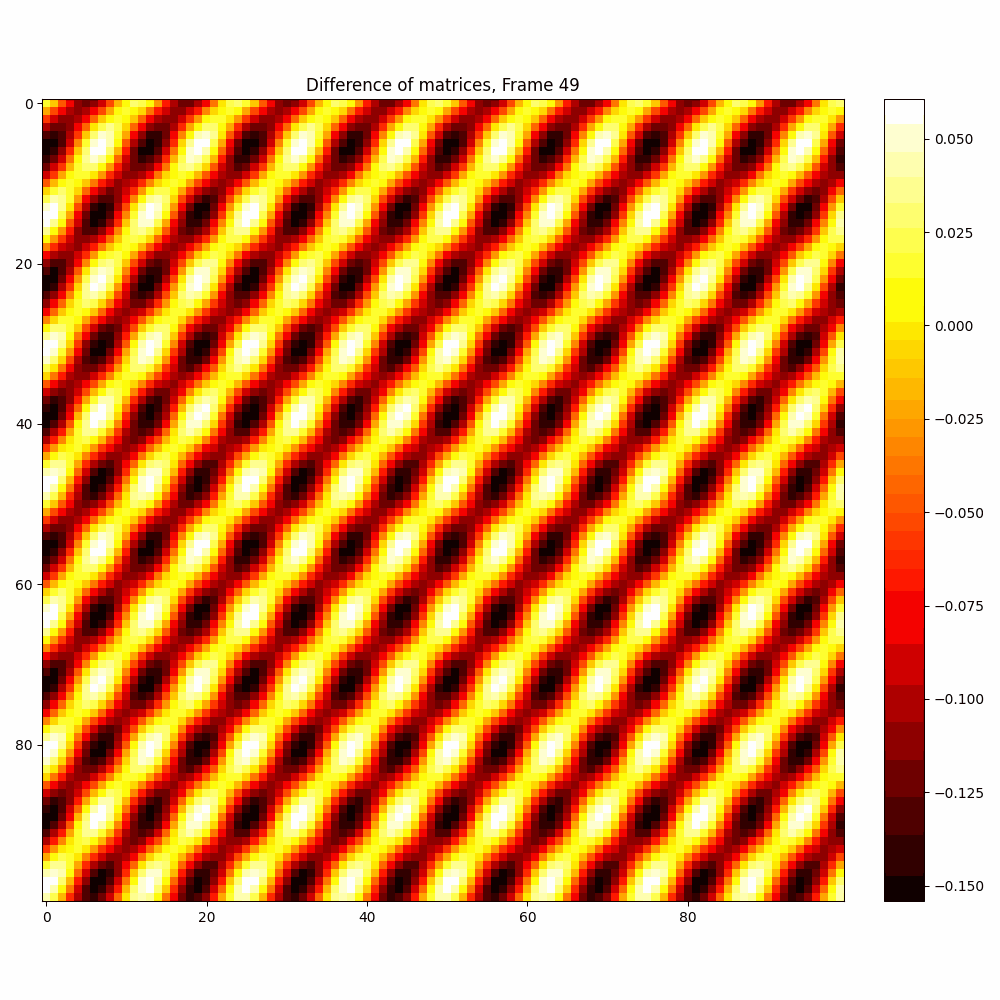
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | No (last layer not trainable) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 641 |
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | No |
| Linear | No (all trainable parameters) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 655 |
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | No |
| Linear | No (last layer fixed) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 658 |
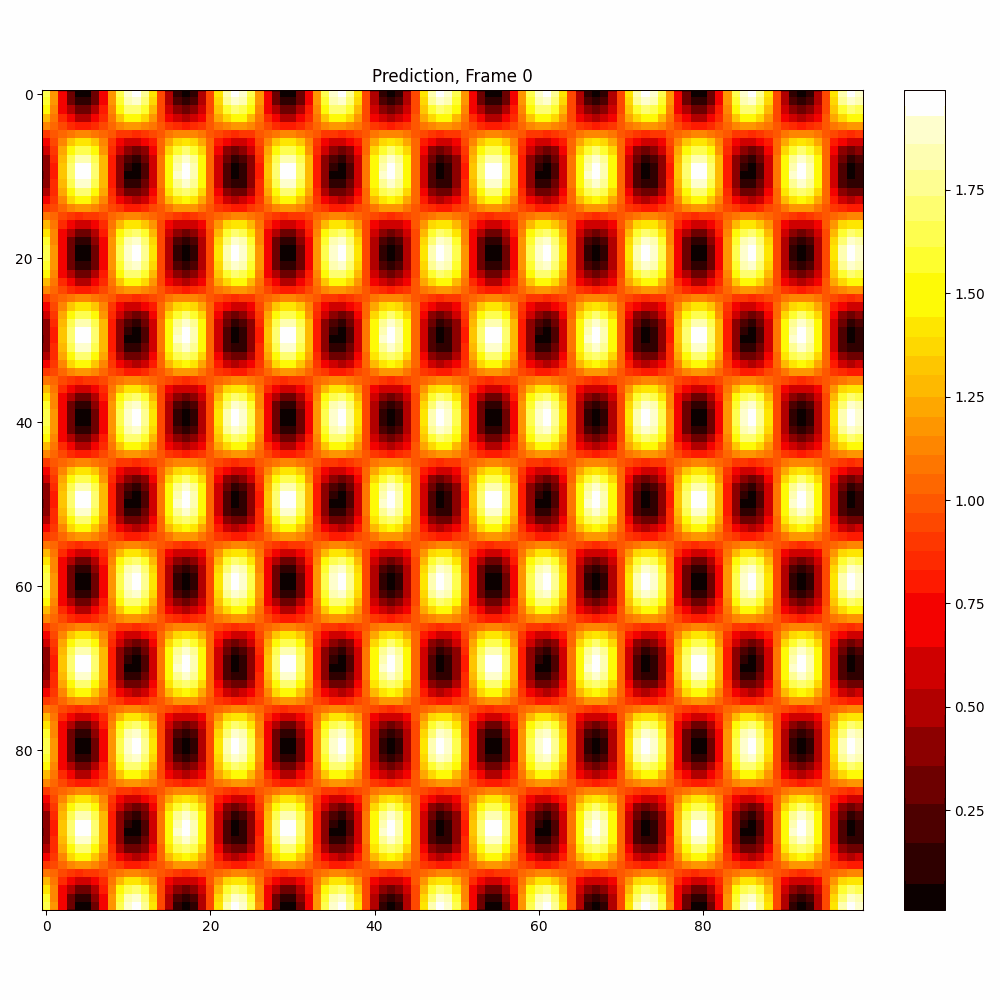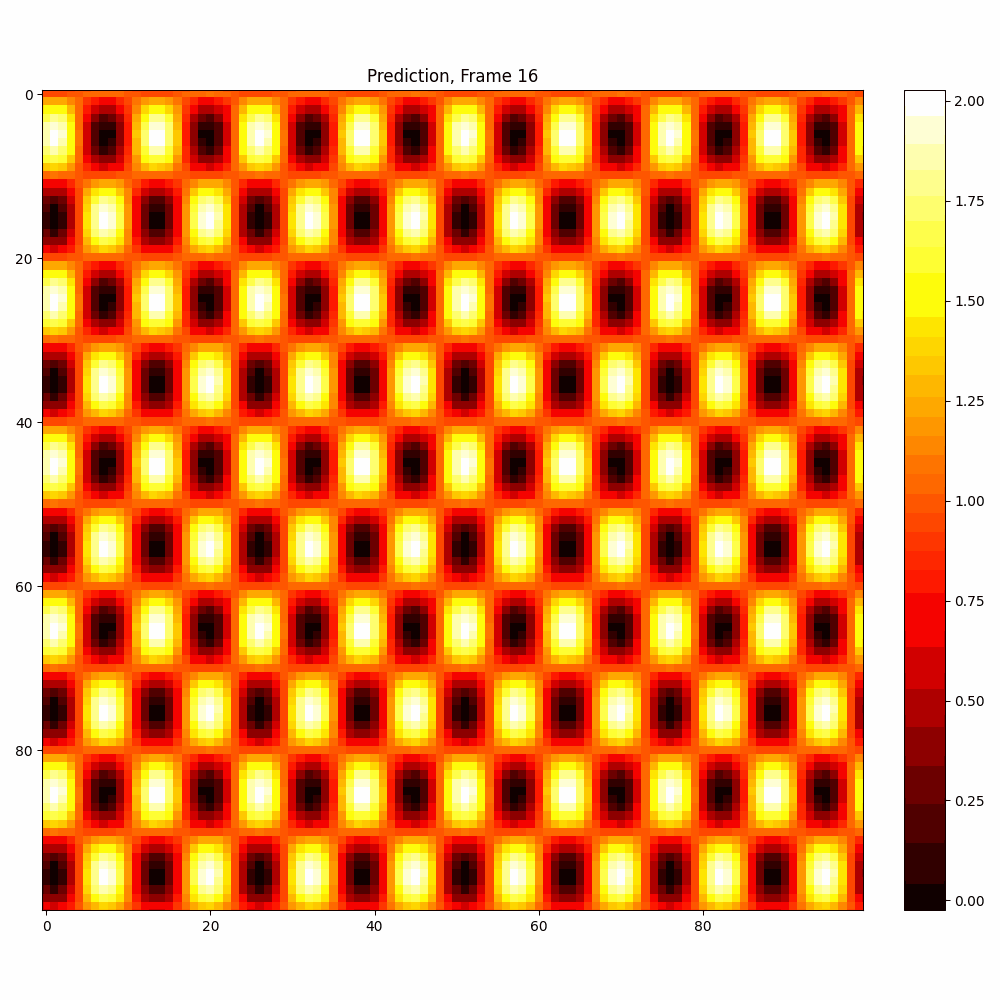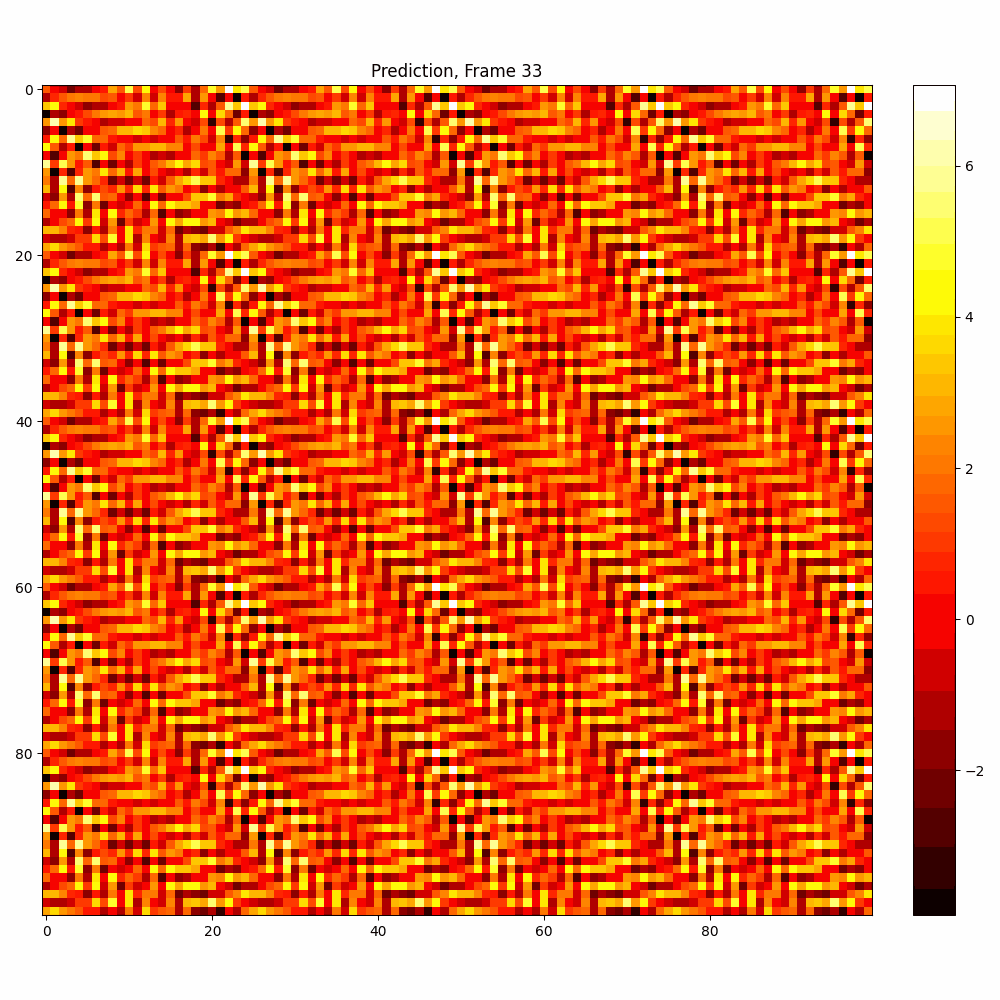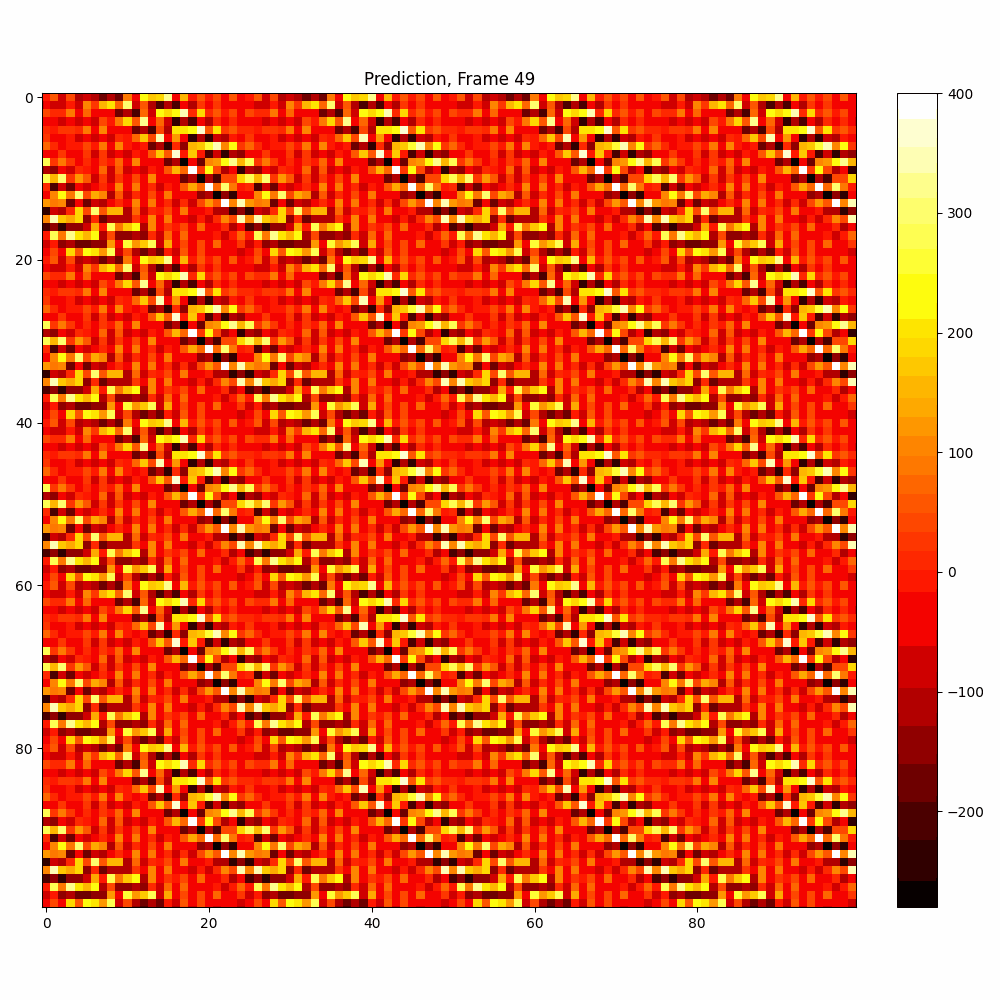
More complicated dataset (non random)
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | No |
| Linear | No (all trainable) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 663 |
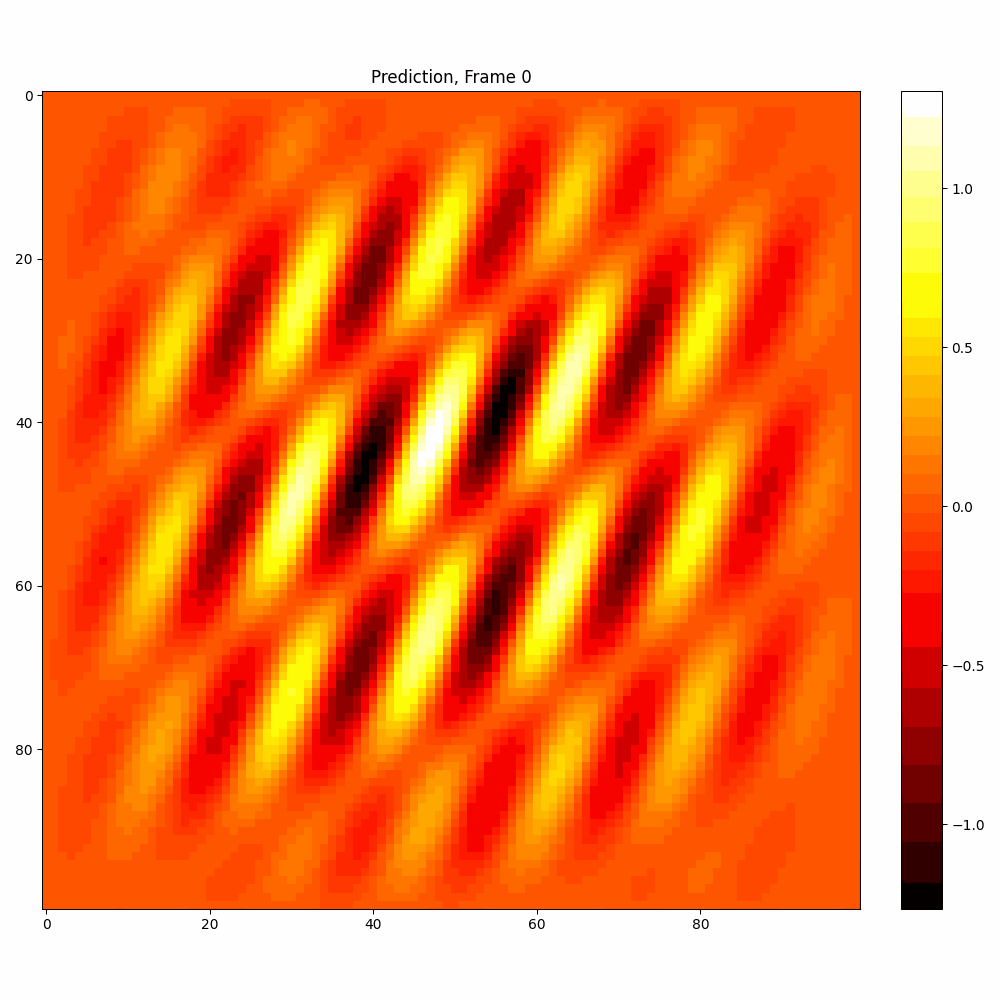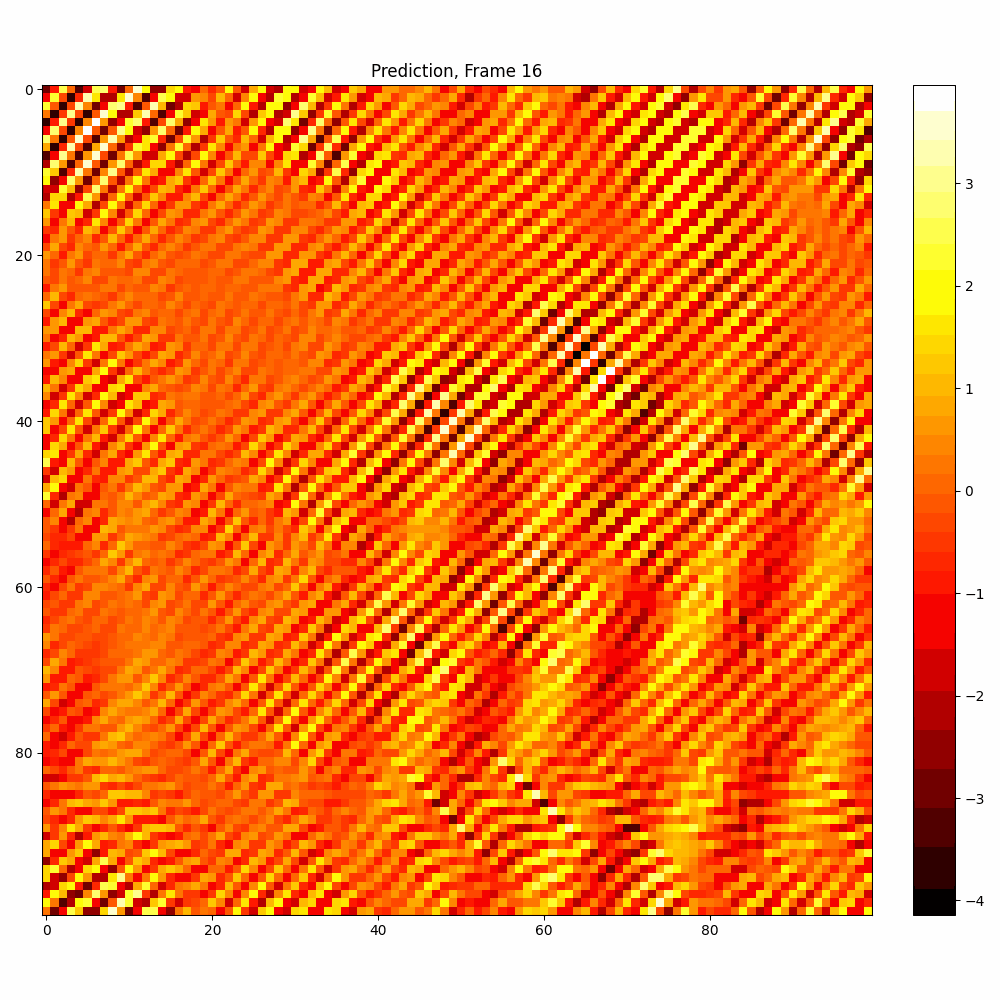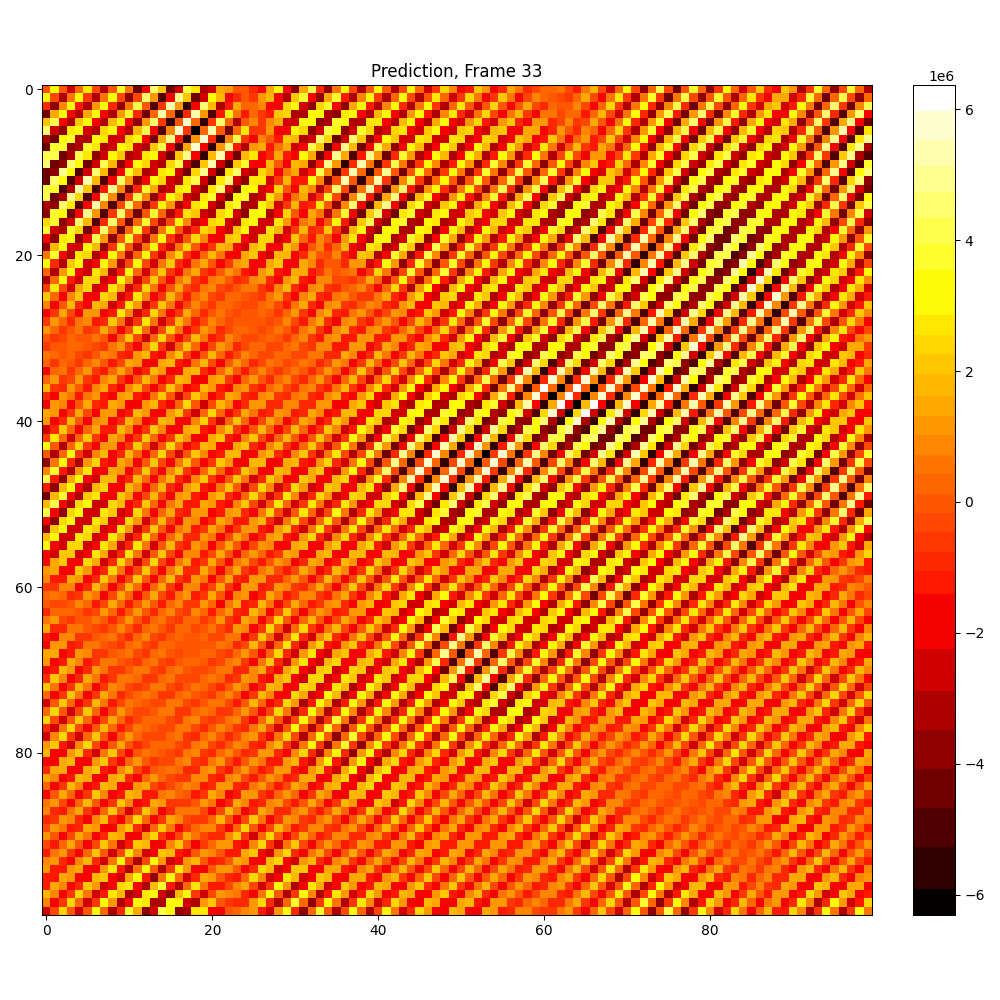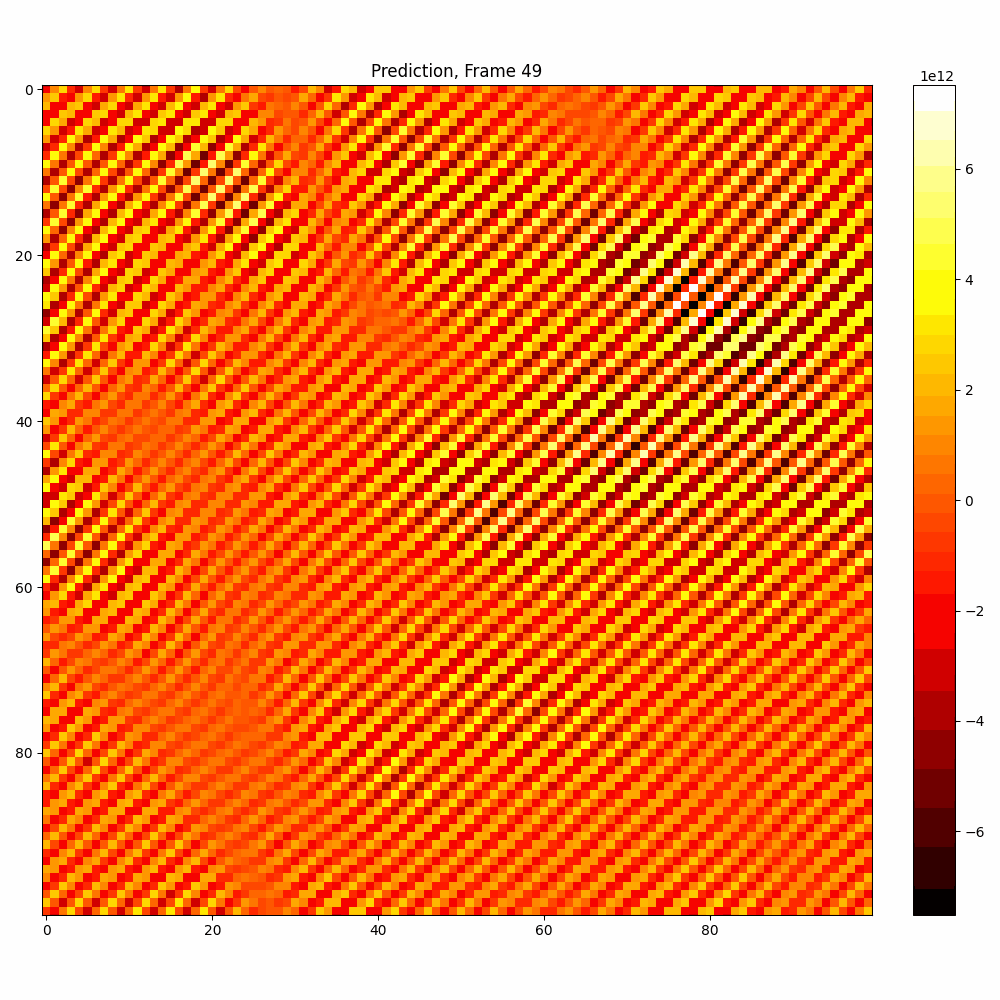
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | No (all trainable) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 666 |
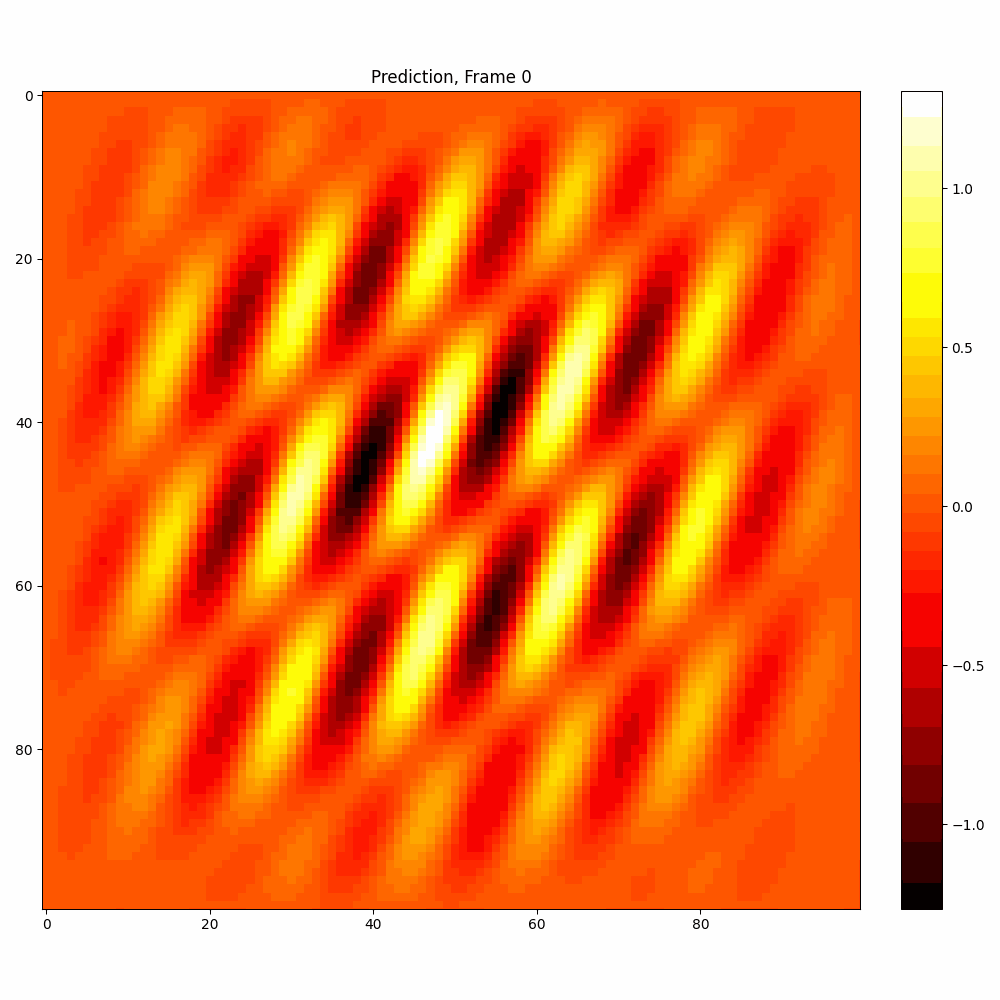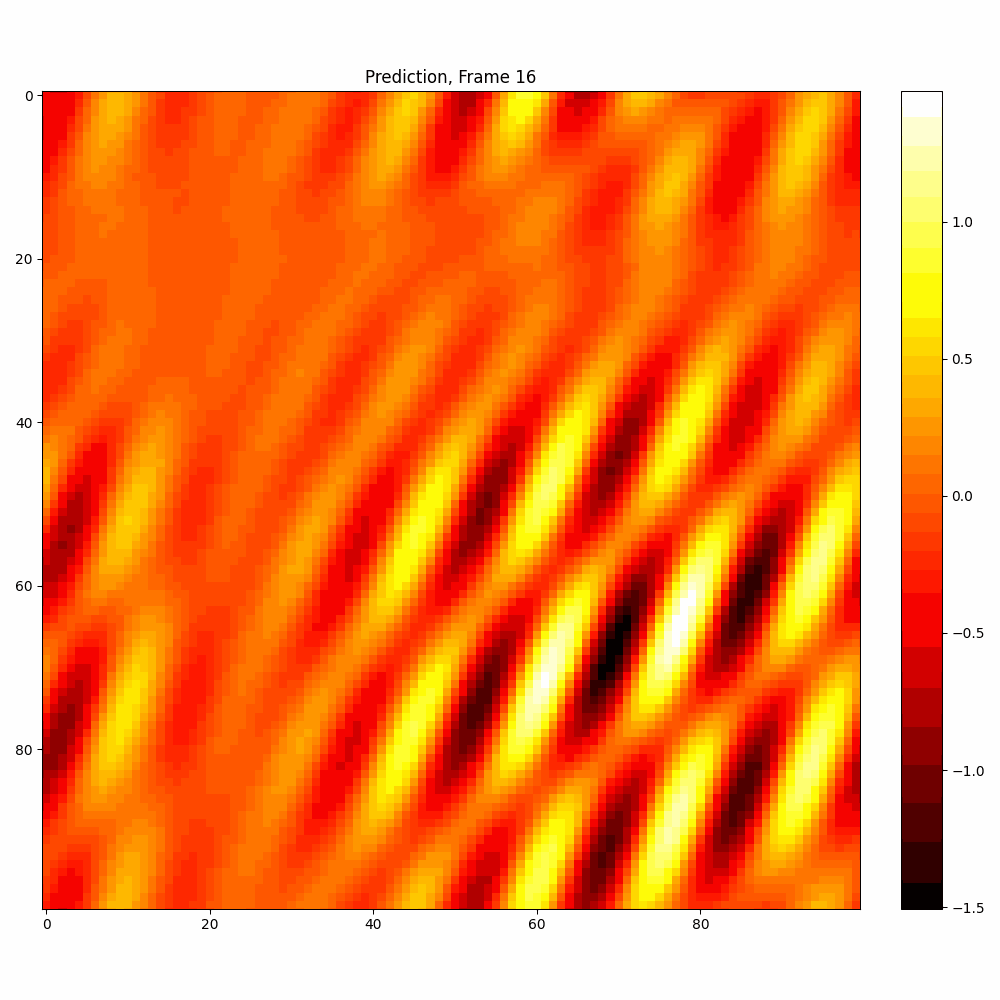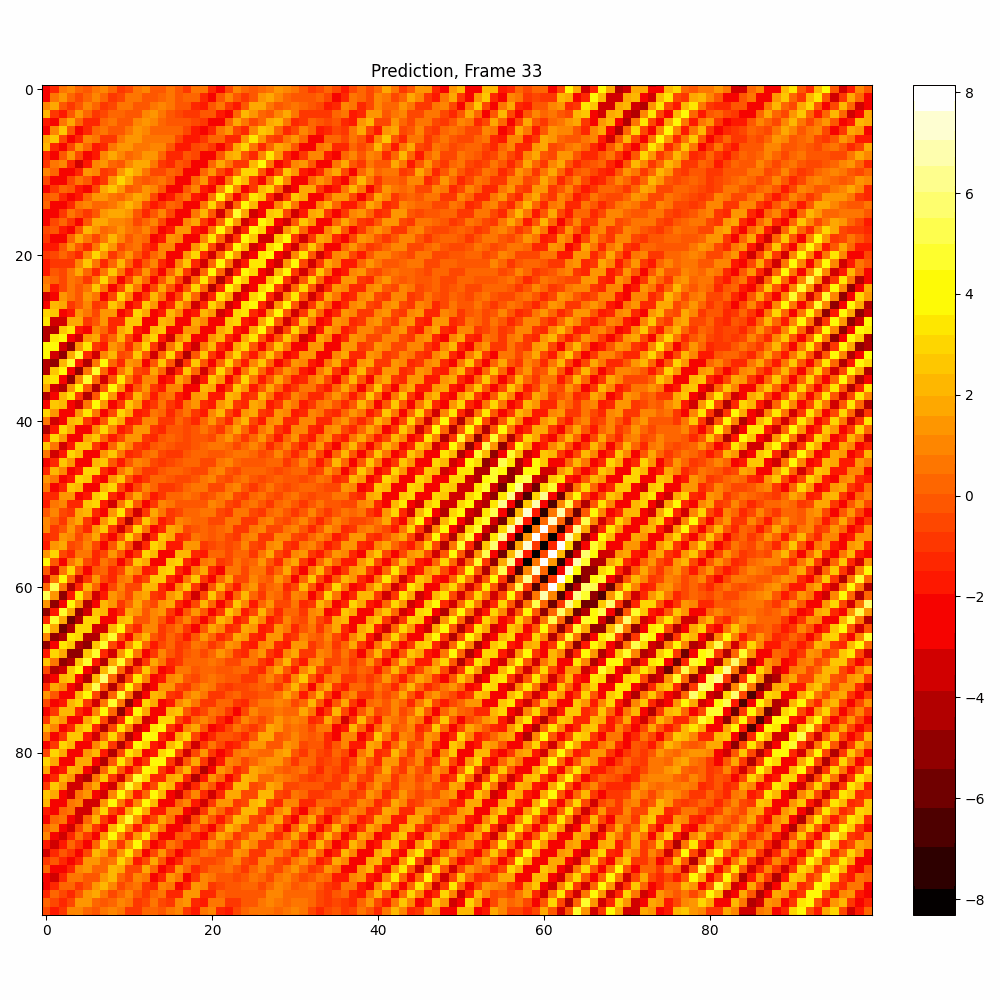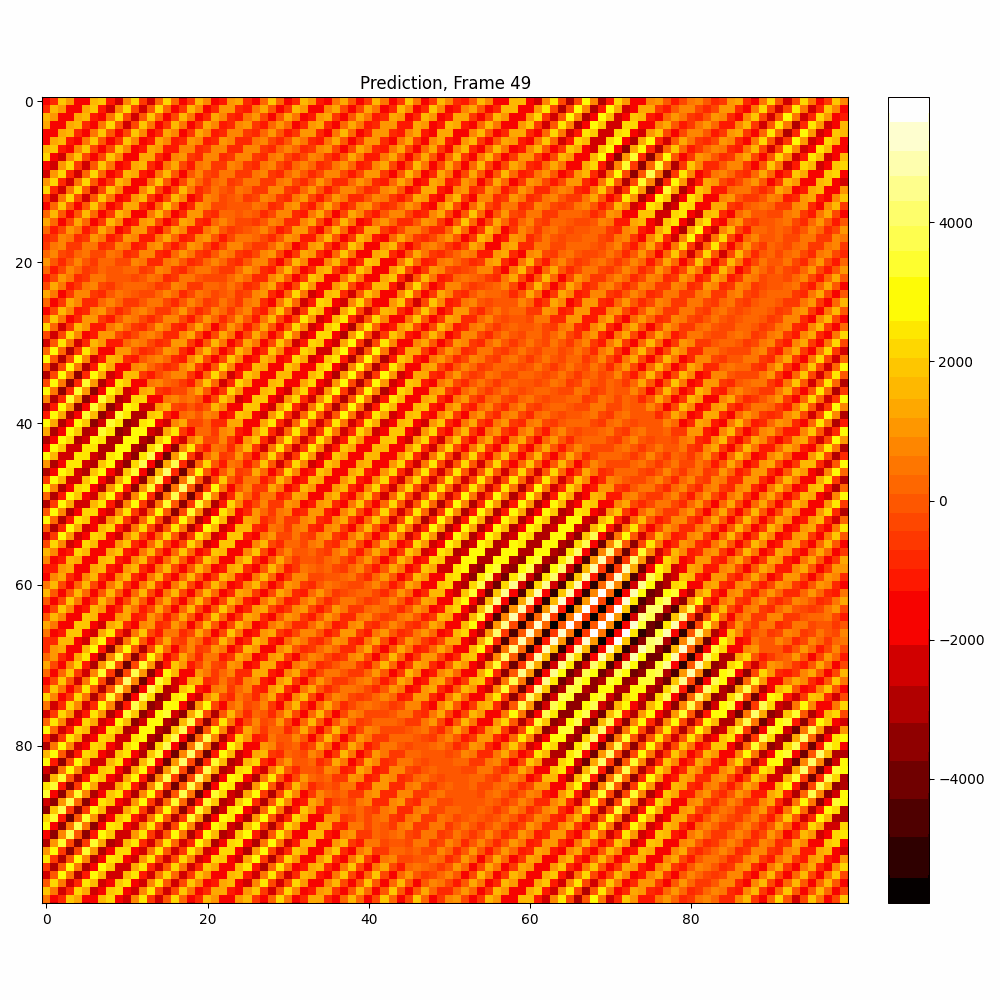
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | No (all trainable) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 677 |
| Zero sum CNN filters | Yes |
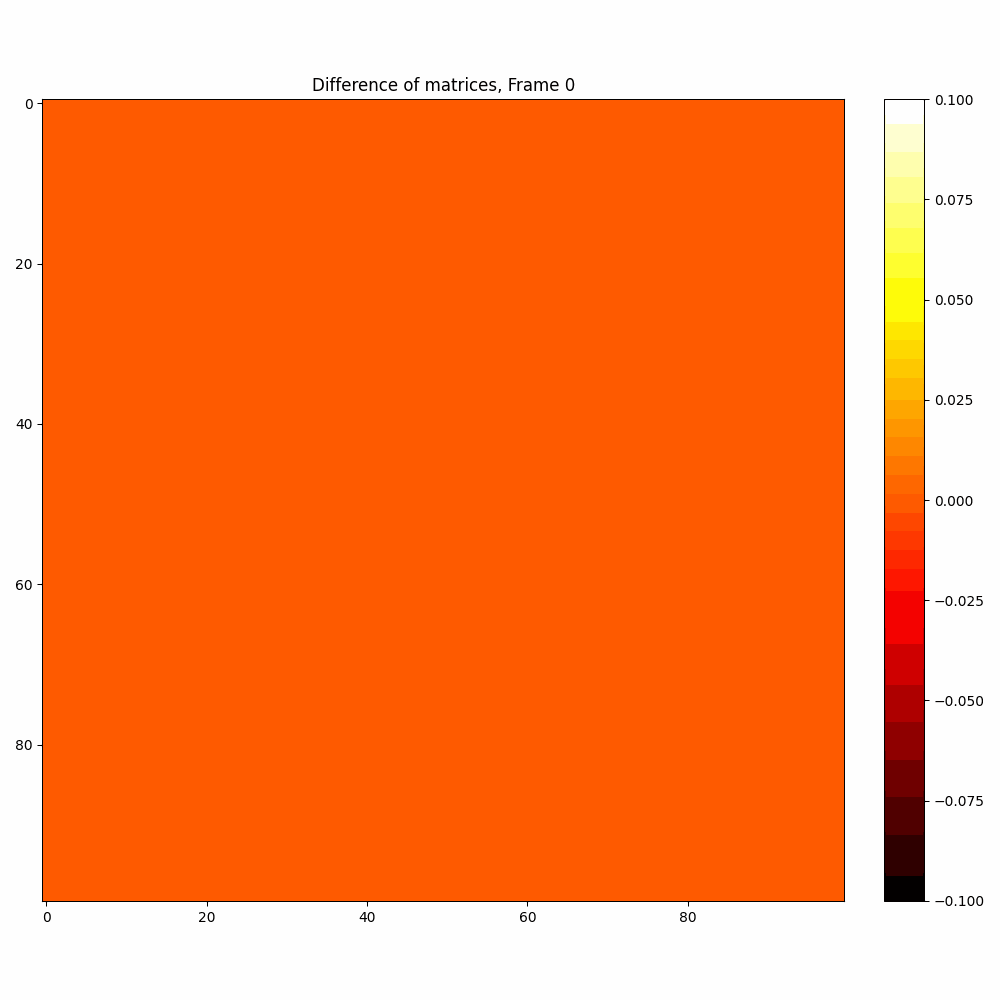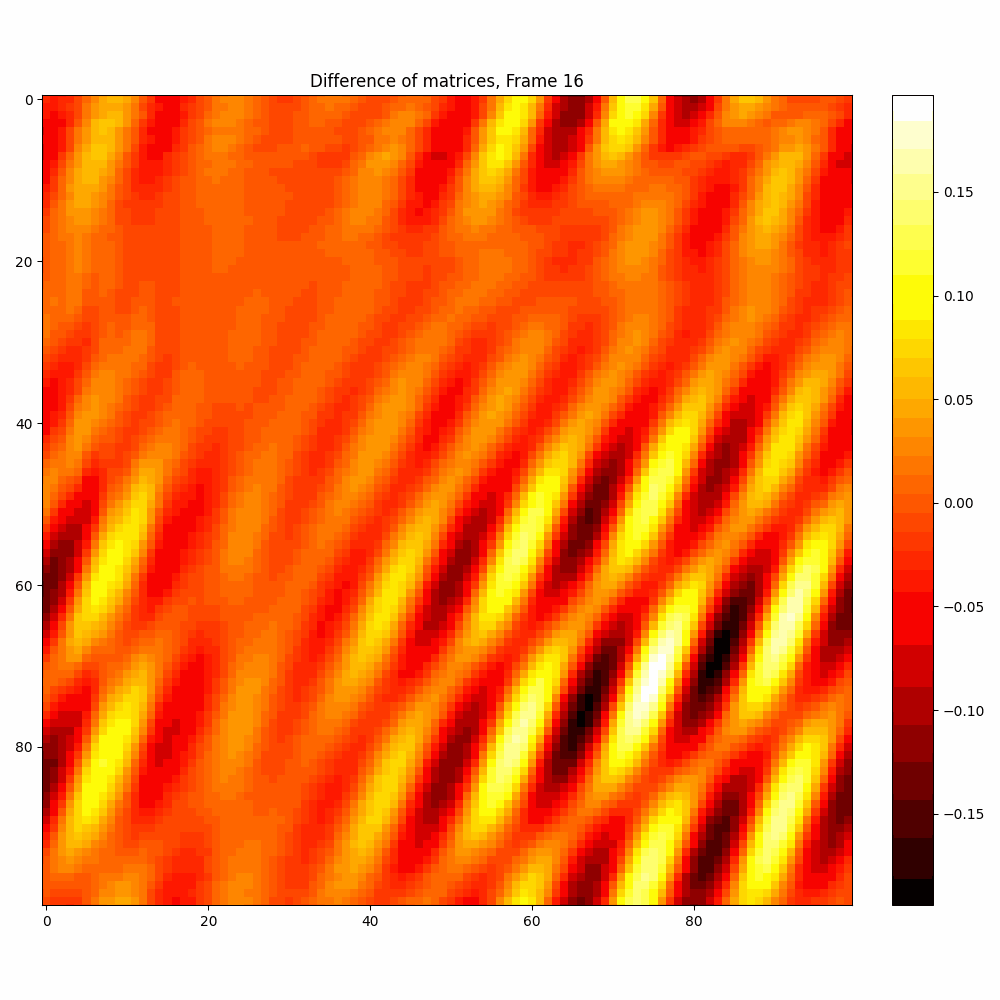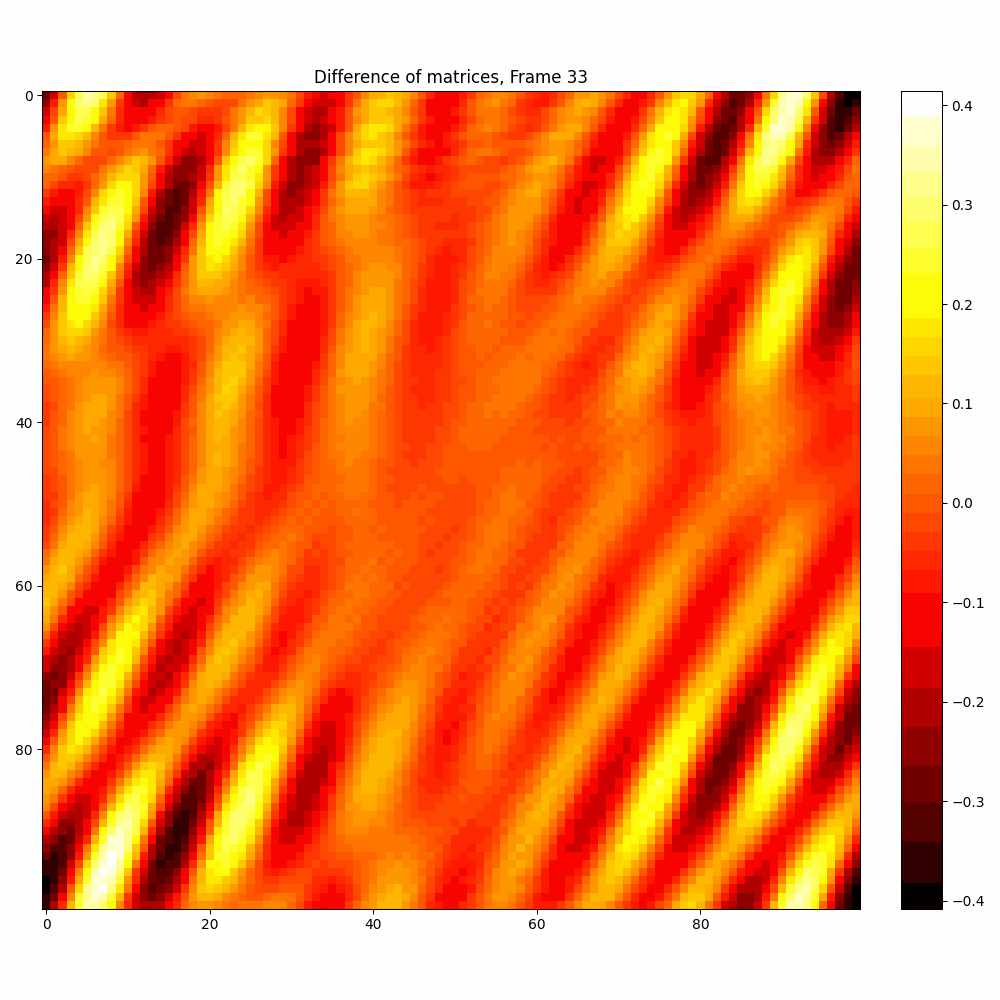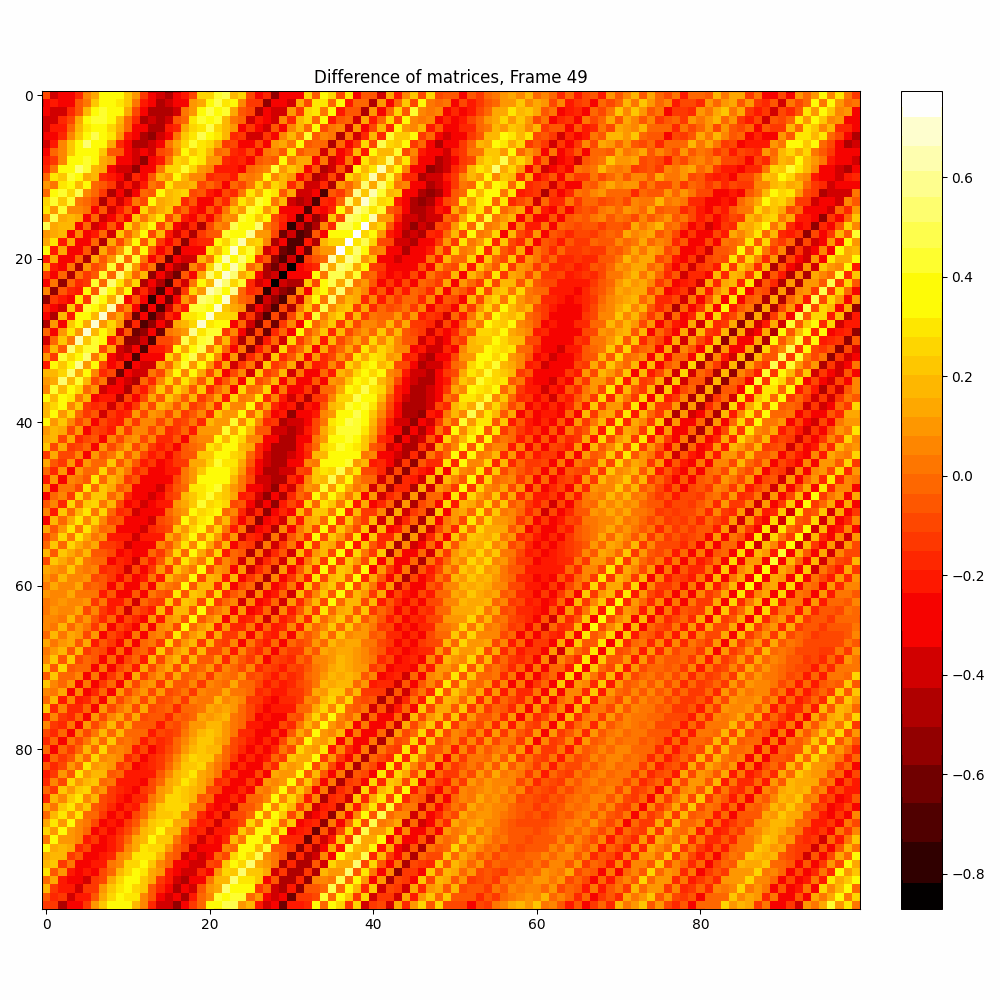
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | No (all trainable) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 678 |
| Zero sum CNN filters | No |
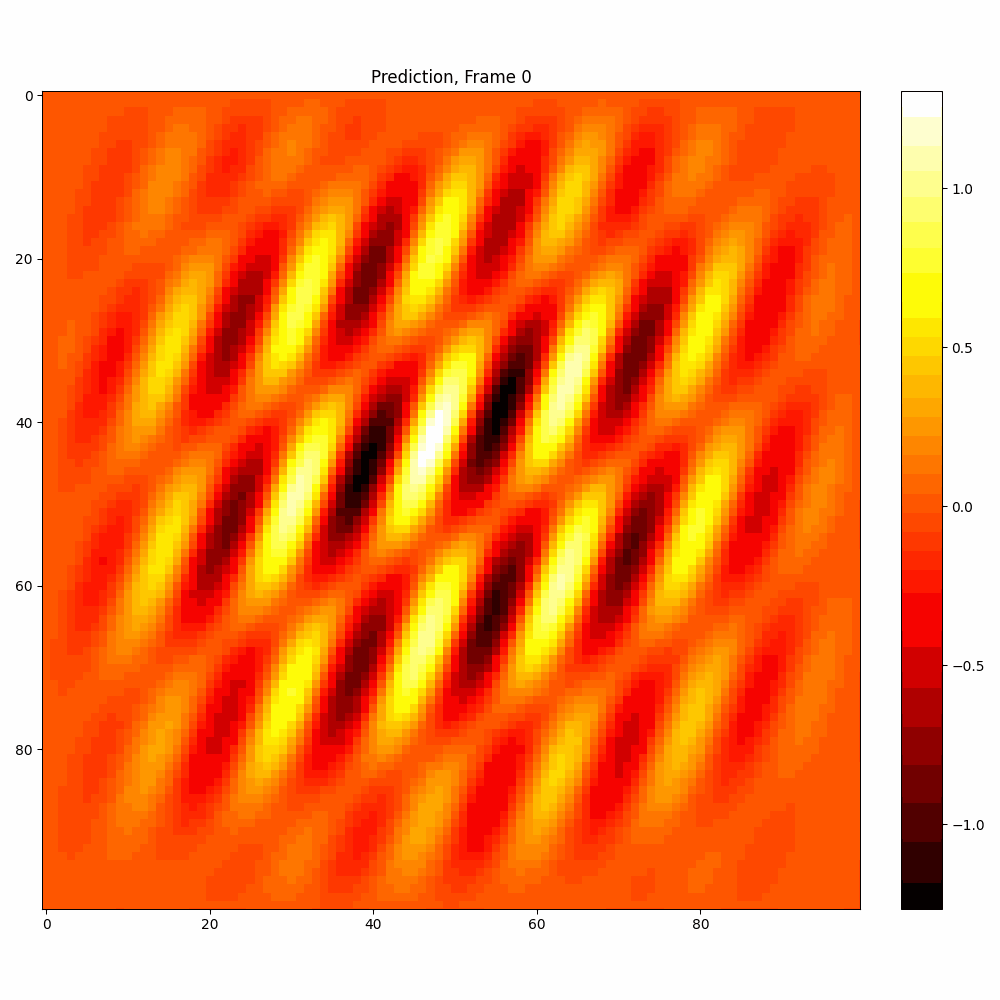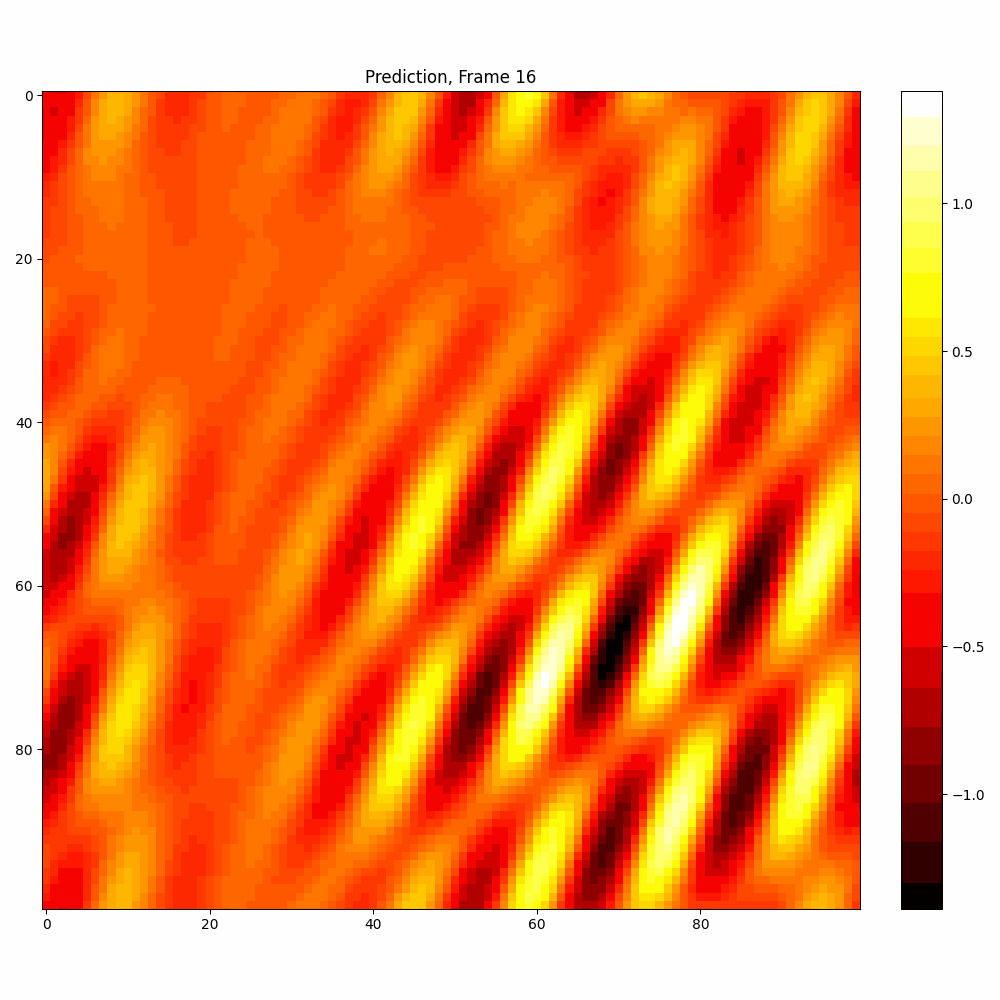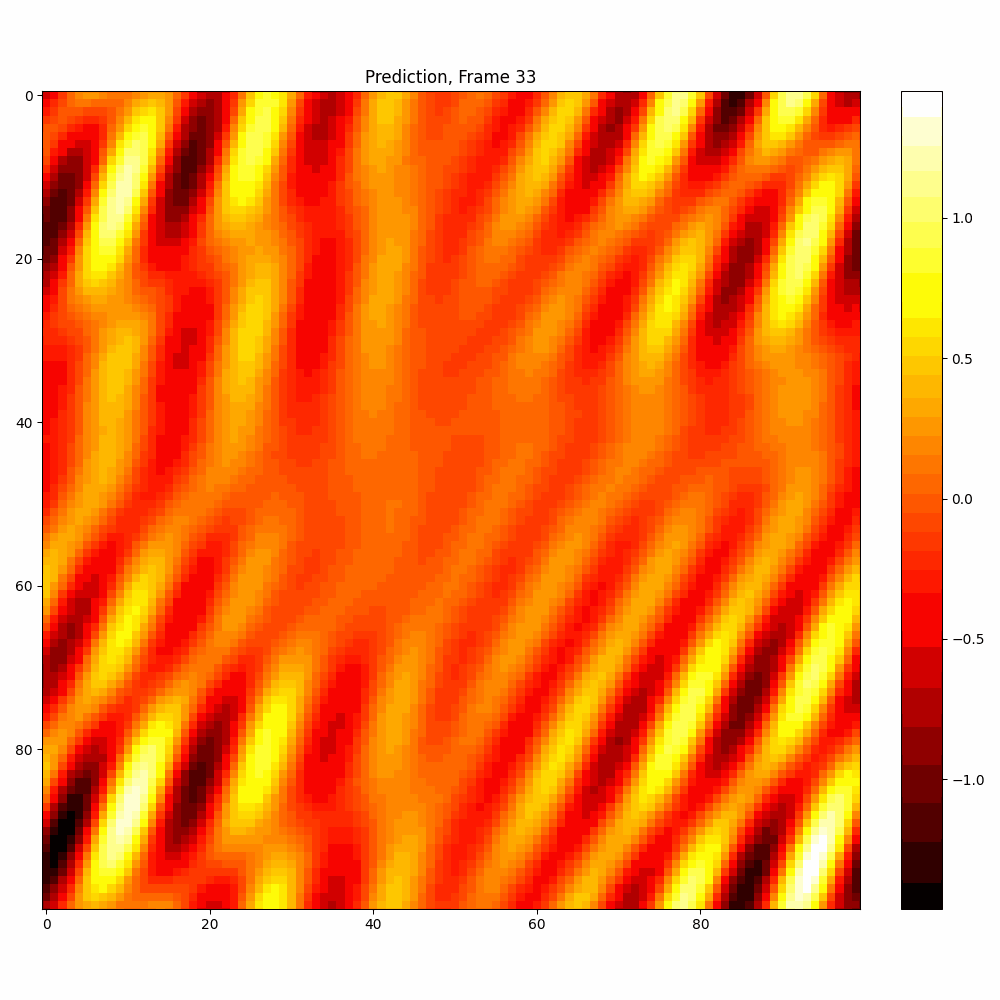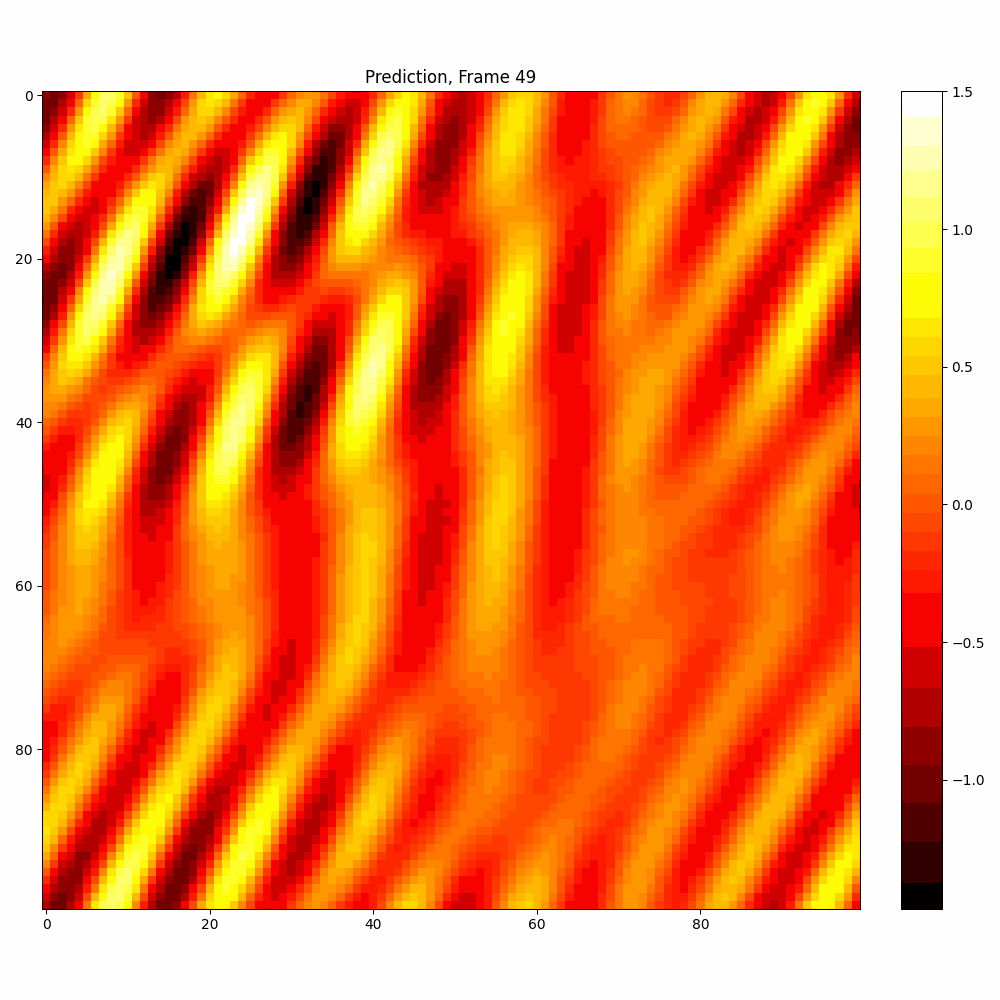
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | No (fixed weights final) |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 679 |
| Zero sum CNN filters | No |
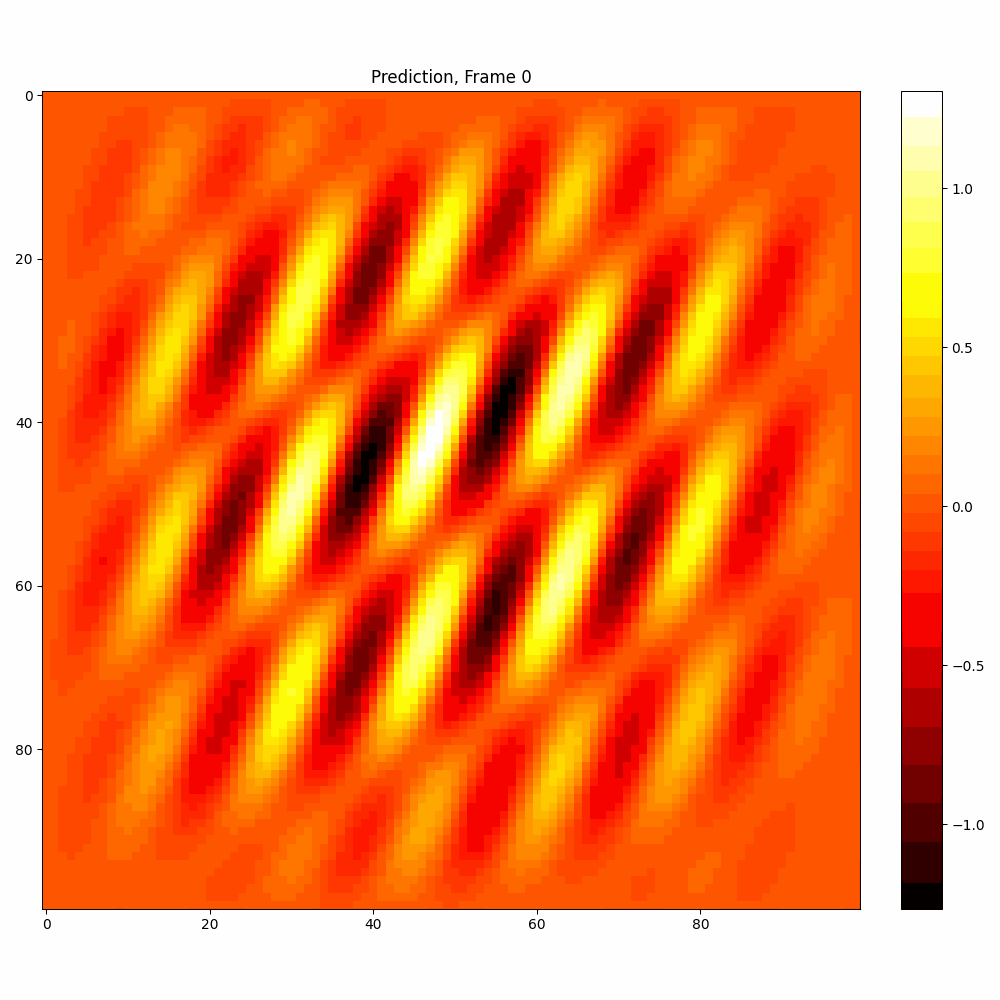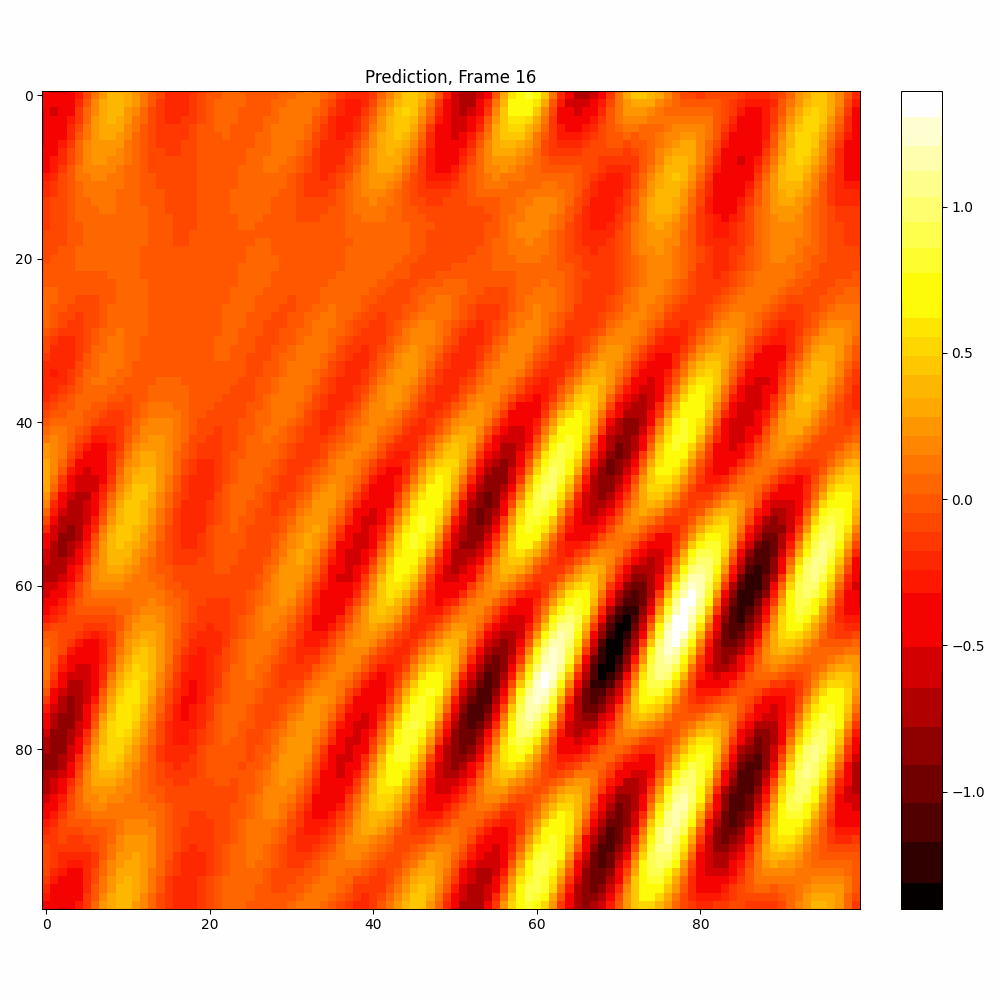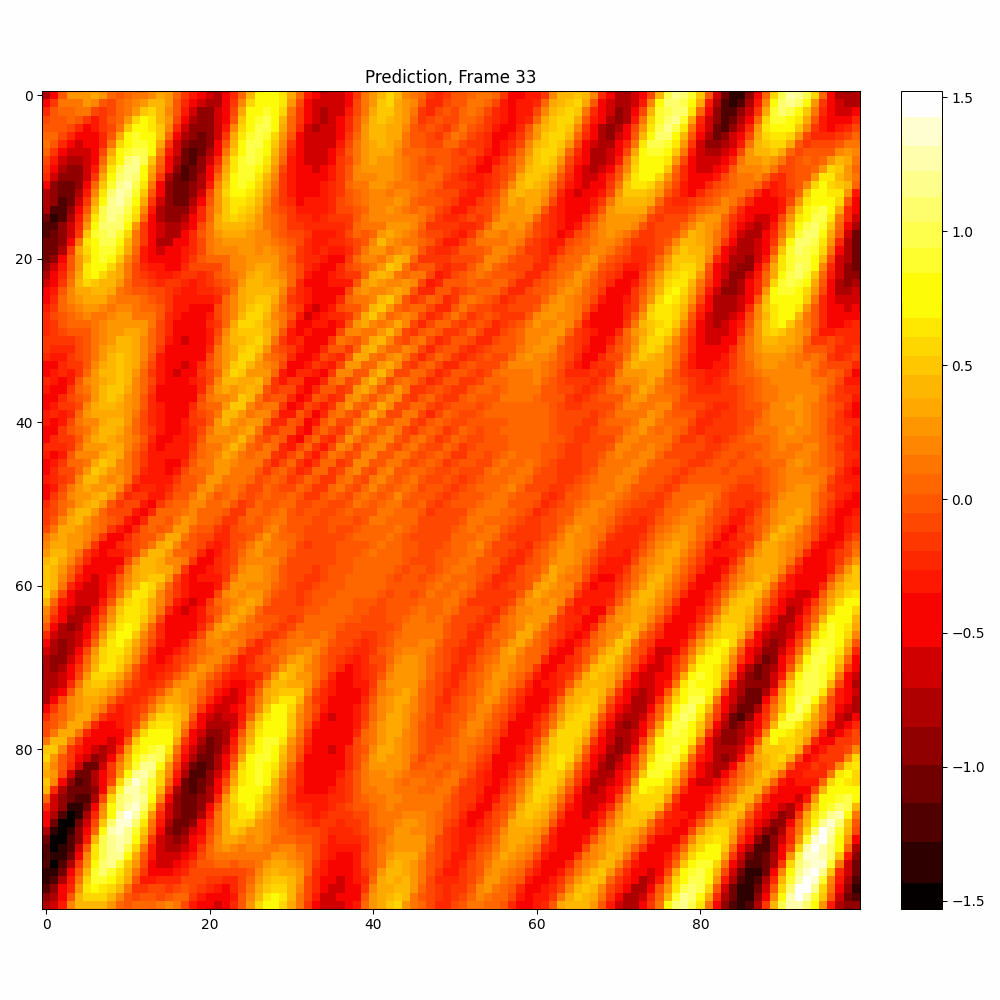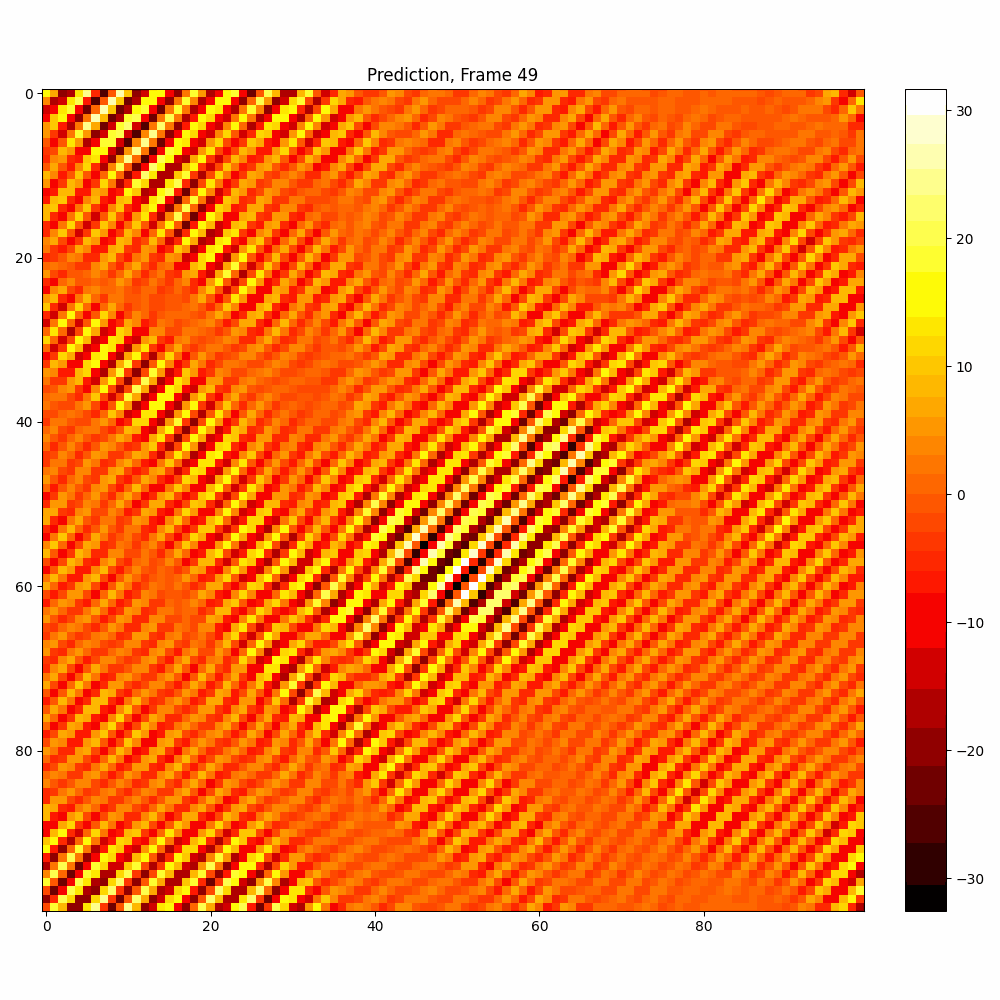
| Hyperparameter | Values |
|---|---|
| Cyclic Scheduler | Yes |
| Added Noise | Yes |
| Linear | Yes |
| Kernel size | 5 |
| Number of layers (time steps) | 3 |
| Number neptune run | 680 |
| Zero sum CNN filters | No |
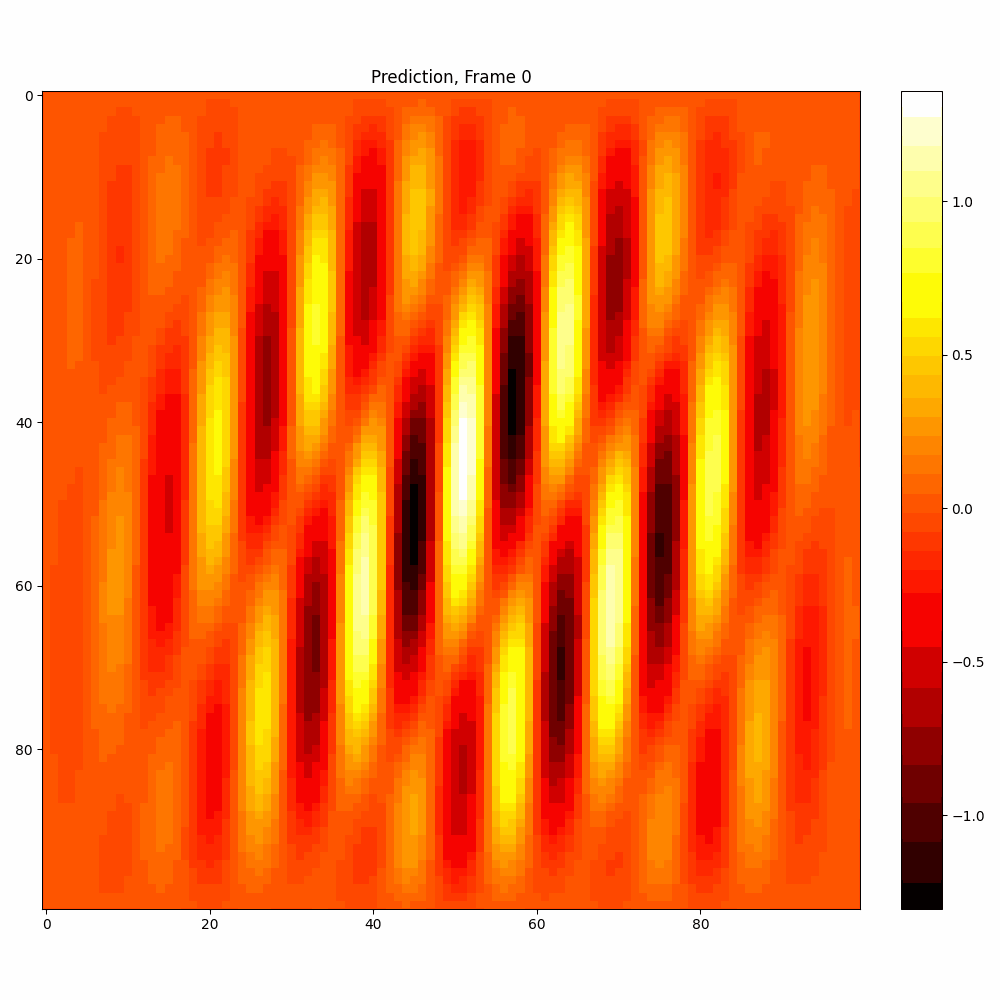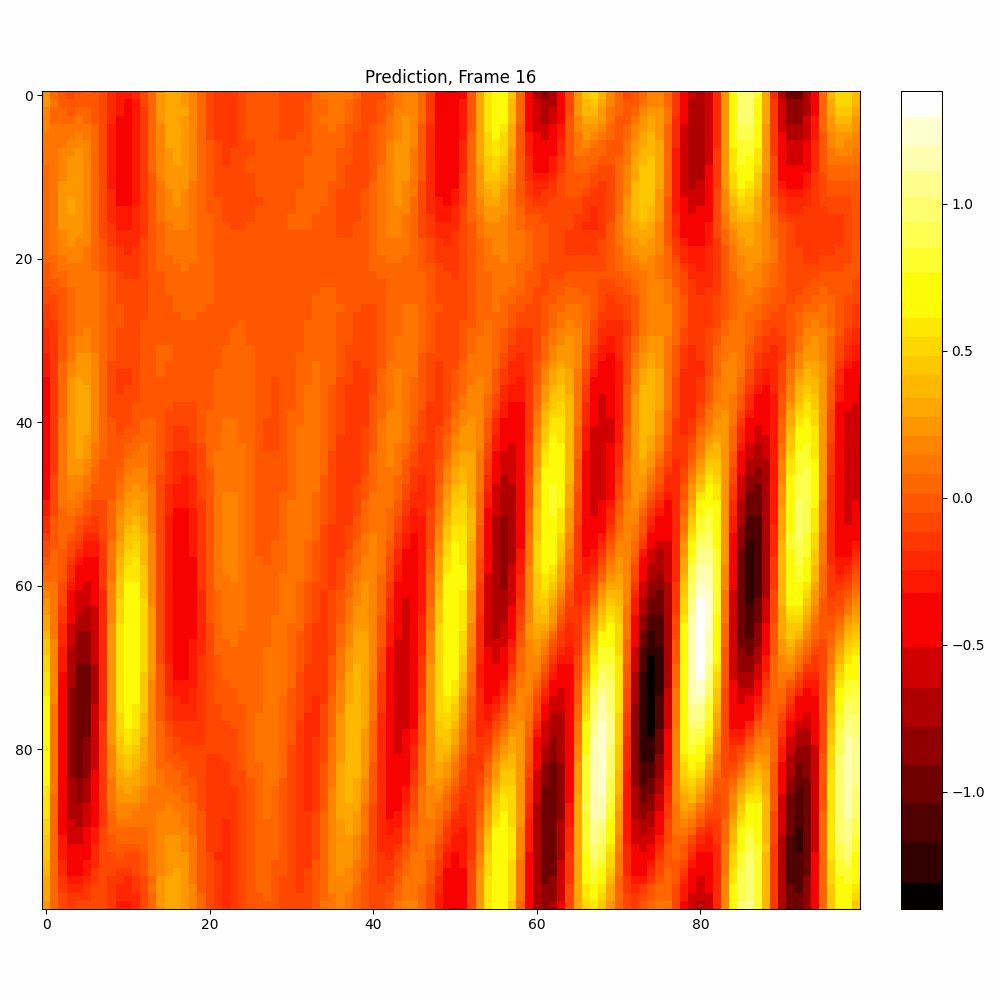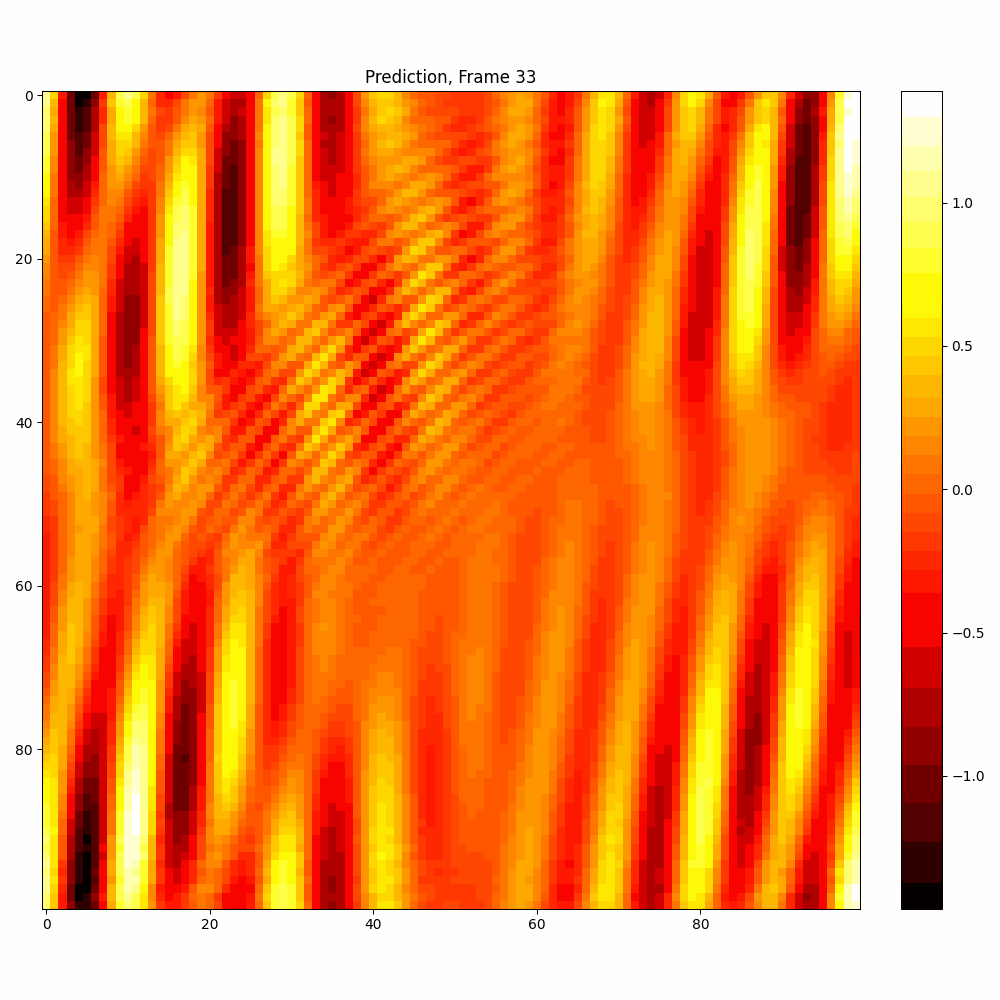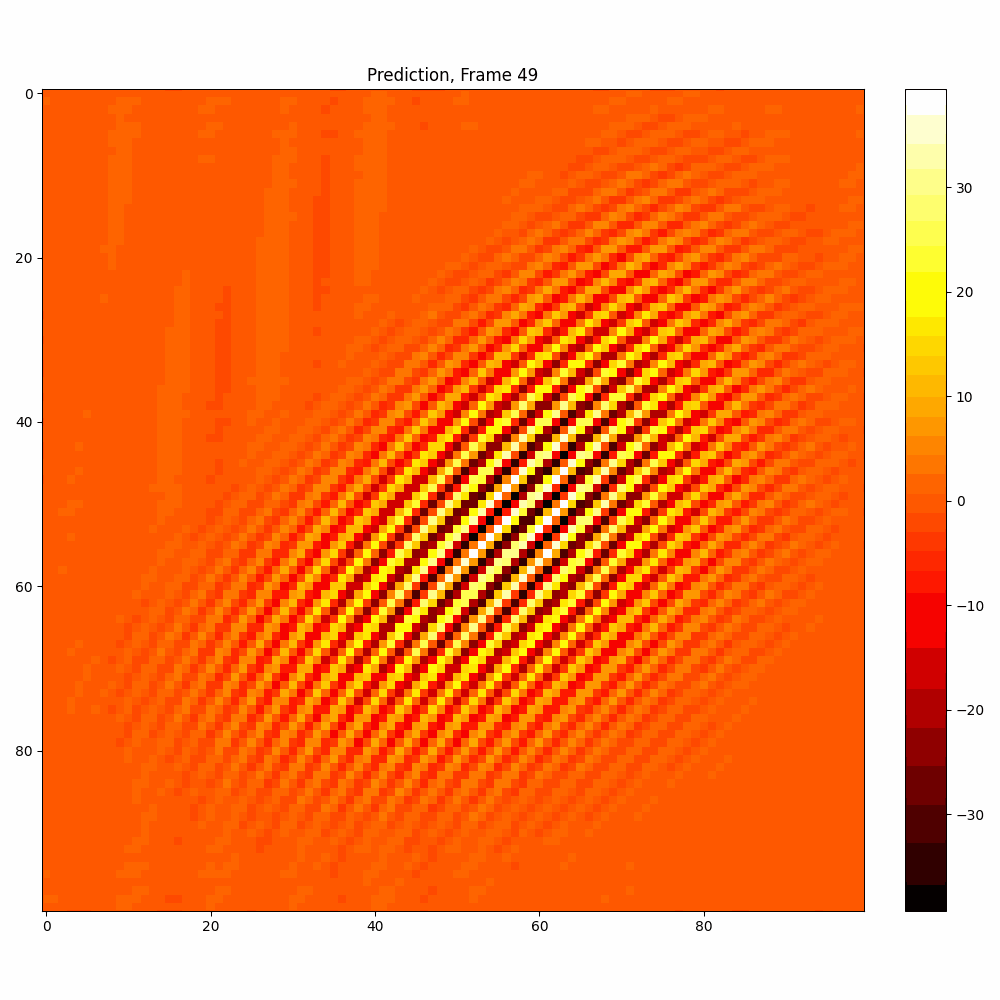
Calculations with added noise
We can start from the simplest case
w,x\in\mathbb{R}^n,\,\,\varepsilon_i\sim\mathcal{N}(0,\sigma^2),\,\text{i.i.d.}
\mathcal{N}(x)=w^Tx,\,\,\mathcal{L}(x)=\mathbb{E}((w^Tx-\ell(x))^2)
L(x+\varepsilon) = \mathbb{E}((w^Tx+w^T\varepsilon-\ell(x))^2) \\
= \mathbb{E}((w^Tx-\ell(x))^2)+\mathbb{E}((w^T\varepsilon)^2) + 2\mathbb{E}((w^Tx-\ell(x))w^T\varepsilon)\\
= L(x) + \sum_{i=1}^N w_i^2 \mathbb{E}(\varepsilon_i^2) = L(x) + \sigma^2\|w\|_2^2.
Thus, injecting noise in the inputs is equivalent to adding weight decay regularisation.