Structured neural networks and some applications to dynamical systems
Davide Murari
davide.murari@ntnu.no

In collaboration with : Elena Celledoni, Andrea Leone, Brynjulf Owren, Carola-Bibiane Schönlieb, and Ferdia Sherry
FoCM, 12 June 2023
\( \mathcal{N}(x) = f_{\theta_M}\circ ... \circ f_{\theta_1}(x)\)
Neural networks motivated by dynamical systems
\( \mathcal{N}(x) = f_{\theta_M}\circ ... \circ f_{\theta_1}(x)\)
Neural networks motivated by dynamical systems
\( \dot{x}(t) = f(x(t),\theta(t)) \)
\( \delta t_i = t_{i}-t_{i-1}\)

\( \mathcal{N}(x) = f_{\theta_M}\circ ... \circ f_{\theta_1}(x)\)
Neural networks motivated by dynamical systems
\( \dot{x}(t) = f(x(t),\theta(t)) \)
Where \(f_i(x) = f(x,\theta(t_i))\)
\( \delta t_i = t_{i}-t_{i-1}\)
Neural networks motivated by dynamical systems

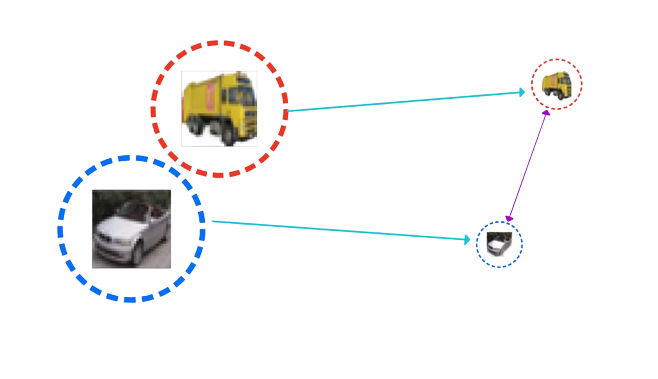
Accuracy is not everything


\(X\) , Label : Plane
\(X+\delta\), \(\|\delta\|_2=0.3\) , Label : Cat
Informed network design
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\) Volume preservation
Family \(\mathcal{F}\) of vector fields that satisfy \(\mathcal{P}\)
\(f_{\theta}(x,v) = \begin{bmatrix} \Sigma(Av+a) \\ \Sigma(Bx+b) \end{bmatrix} \)
\(\mathcal{F}=\{f_{\theta}:\,\,\theta\in\Theta\}\)
Informed network design
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\) Volume preservation
Integrator \(\Psi^{\delta t}\) that preserves \(\mathcal{P}\)
Informed network design
Family \(\mathcal{F}\) of vector fields that satisfy \(\mathcal{P}\)
\(f_{\theta}(x,v) = \begin{bmatrix} \Sigma(Av+a) \\ \Sigma(Bx+b) \end{bmatrix} \)
\(\mathcal{F}=\{f_{\theta}:\,\,\theta\in\Theta\}\)
GENERAL IDEA
EXAMPLE
Property \(\mathcal{P}\)
\(\mathcal{P}=\) Volume preservation
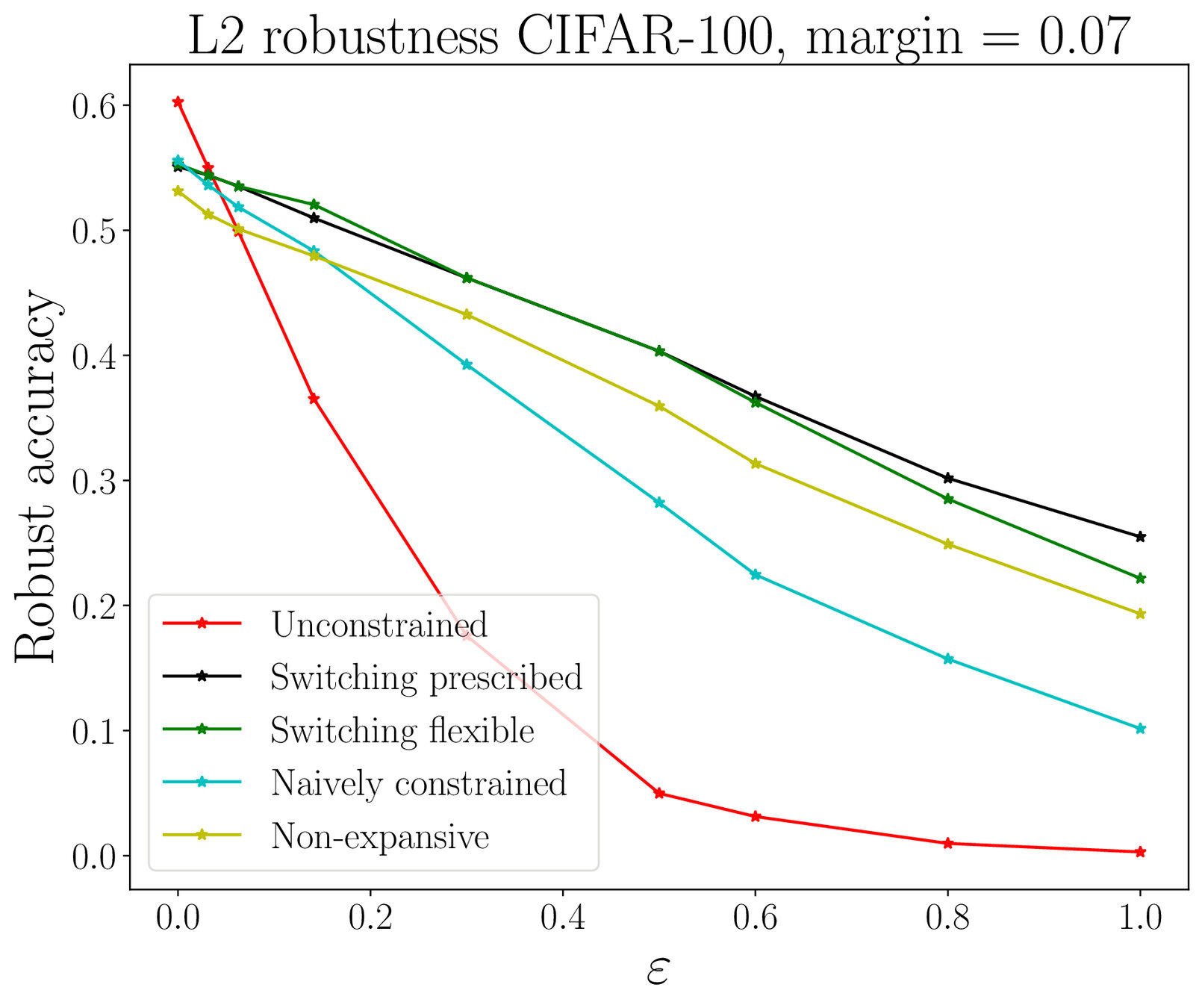
Non-expansive neural
networks
\(\mathcal{N}_{\theta}\)
\(\mathcal{N}_{\theta}\)
Margin
\(B_{\delta}(X)\)
\(B_{\gamma}(Y)\)
\(B_{\gamma'}(\mathcal{N}_{\theta}(Y))\)
\(B_{\delta'}(\mathcal{N}_{\theta}(X))\)
\(X\)
\(Y\)
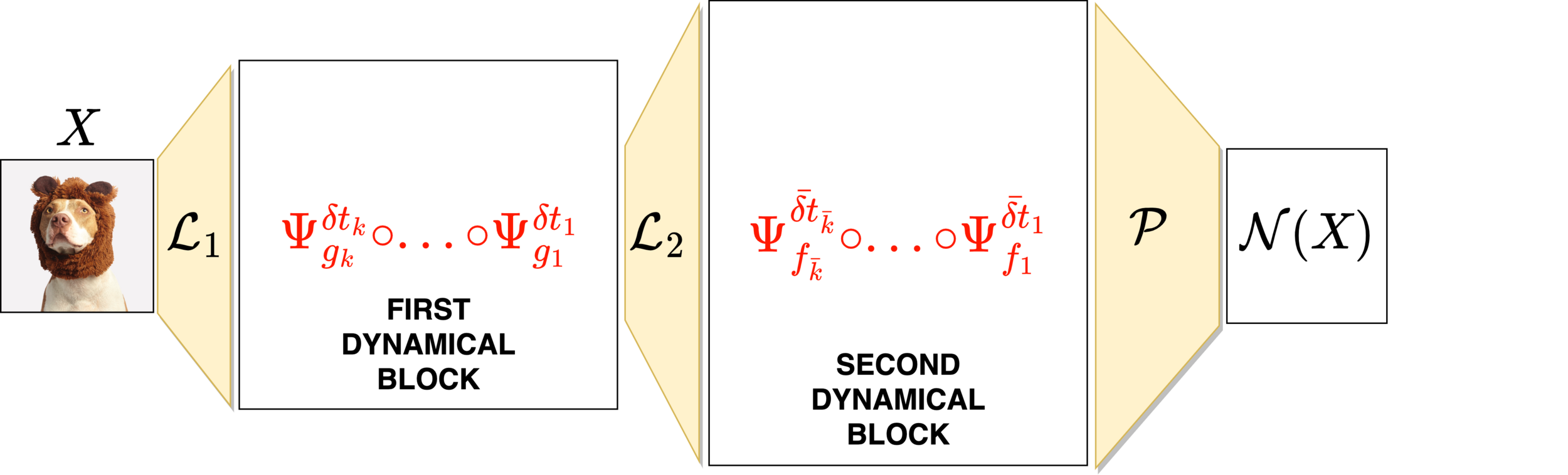
Building blocks of the network
We impose :
Non-expansivity constraint
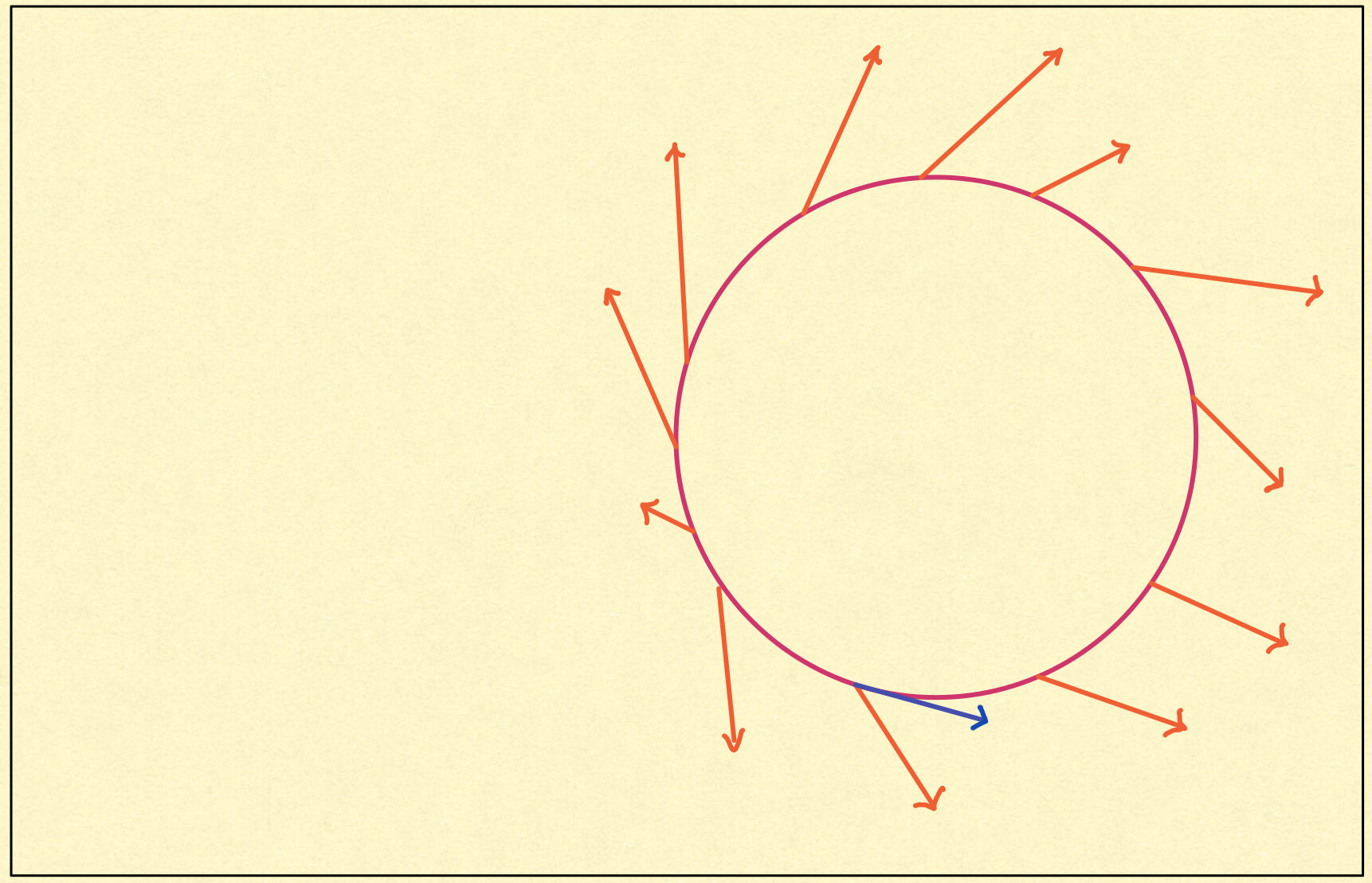
Adversarial robustness
Approximating constrained mechanical systems
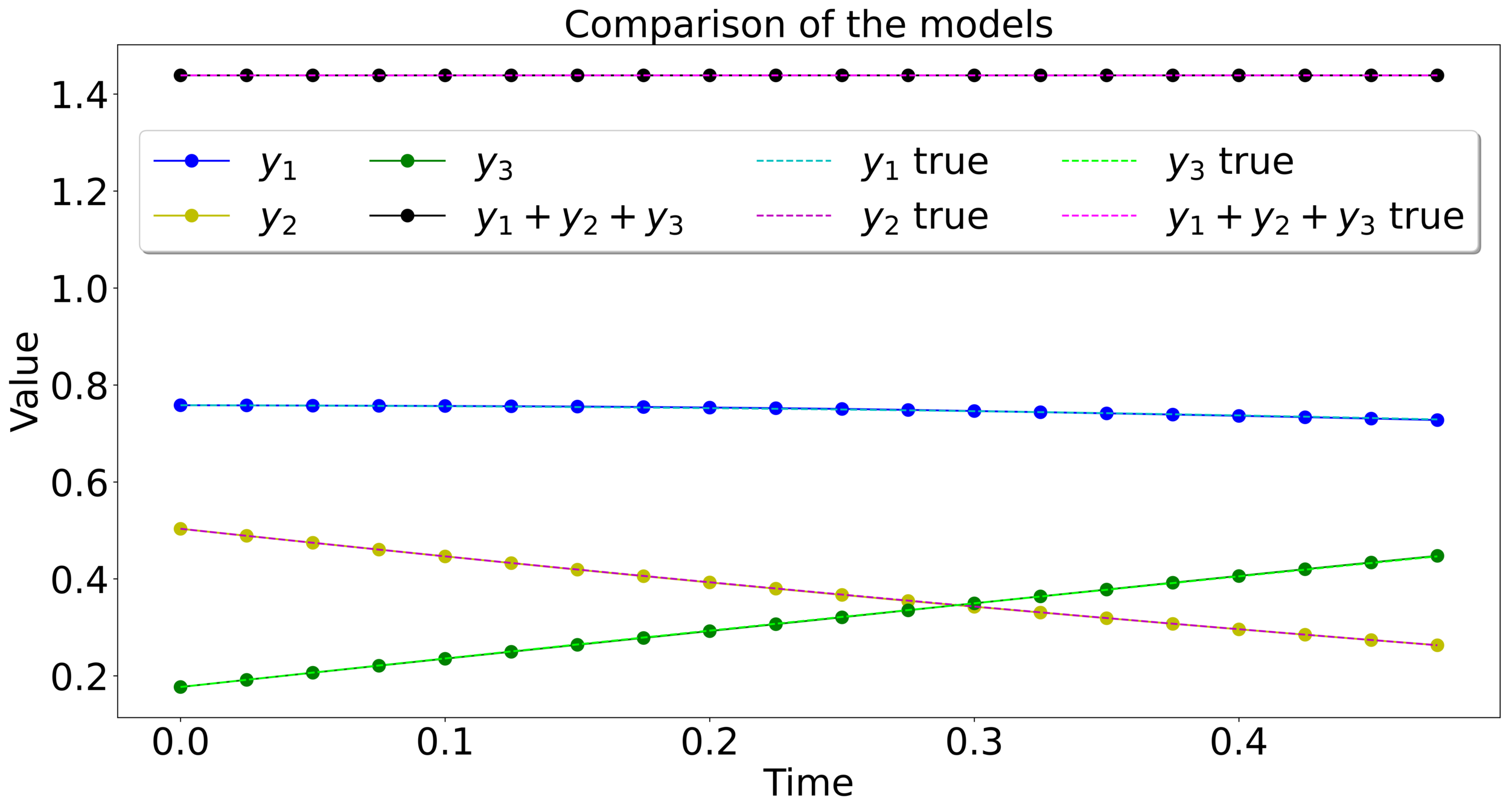
Data : \(\{(y_i^0,...,y_i^M)\}_{i=1,...,N}\)
\(y_i^{j} = \Phi^{j\delta t}_{Y}(y_i^0) + \varepsilon_i^j\in\mathbb{R}^n\)
\(Y\in\mathfrak{X}(\mathcal{M})\) and
\(\delta t>0\) unknown
Goal : Approximate the map \(\Phi^{\delta t}_Y\)
\(\mathcal{M}\subset\mathbb{R}^n\)
\(y_1^0\)
\(y_1^1\)
\(y_1^2\)
\(y_1^3\)
\(y_2^0\)
\(y_2^1\)
\(y_2^2\)
\(y_2^3\)
\(y_3^0\)
\(y_3^1\)
\(y_3^2\)
\(y_3^3\)

A possible approach
\(\mathcal{N}_{\theta}:=\Psi^h_{Y_{\theta}}\circ ... \circ \Psi^h_{Y_{\theta}}\)
\(\theta = \arg\min_{\rho} \sum_{i=1}^N\sum_{j=1}^M\left\|y_i^j -\mathcal{N}_{\rho}^j(y_i^0)\right\|^2\)
\(P(q) : \mathbb{R}^n\rightarrow T_q\mathcal{M},\, q\in\mathcal{M}\)
\(X_{\theta}\in\mathfrak{X}(\mathbb{R}^n)\)
\(Y_{\theta}(q) = P(q)X_{\theta}(q)\in T_q \mathcal{M}\)
\(\Psi_{Y_{\theta}}^h : \mathcal{M}\rightarrow\mathcal{M}\)
\(X_{\theta}(q)\)
\(q\)
\(Y_{\theta}(q)\)
Hamiltonian case
⚠️ On \(\mathbb{R}^{2n}\setminus\mathcal{M}\) the vector field extends non-uniquely.
Hamiltonian case
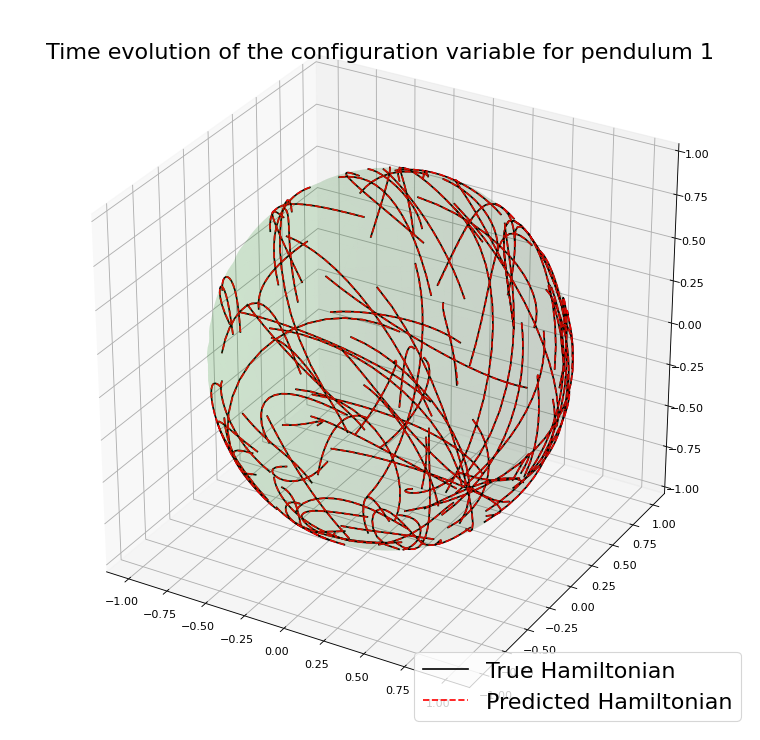
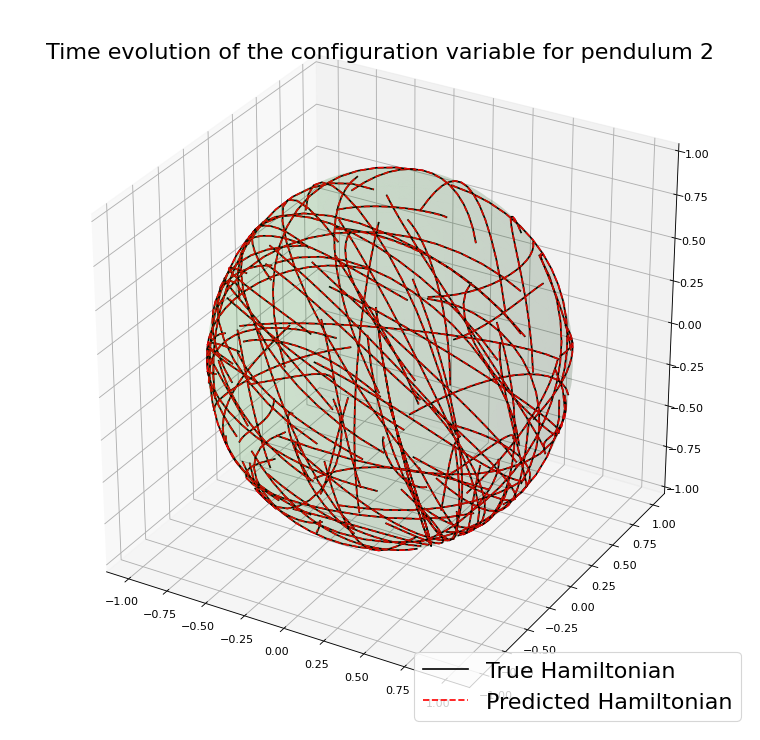
Double spherical pendulum
\(\Psi^h\) is Commutator Free Lie Group method of order 4
Conclusion
- Dynamical systems and numerical analysis provide a natural framework to analyse and design (structured) neural networks.
- Imposing a specific structure can be valuable for qualitatively accurate approximations or a "better behaved" model.
- Interesting questions: How is the expressivity of the model restricted when we impose some structure? How to efficiently deal with implicit geometric integrators to design, for example, symplectic or energy-preserving neural networks?
Thank you for the attention
- Celledoni, E., Leone, A., Murari, D., Owren, B., JCAM (2022). Learning Hamiltonians of constrained mechanical systems.
- Celledoni, E., Murari, D., Owren B., Schönlieb C.B., Sherry F, preprint (2022). Dynamical systems' based neural networks
Choice of dynamical systems
MASS-PRESERVING NEURAL NETWORKS
+ Any Runge-Kutta method
Choice of dynamical systems
MASS-PRESERVING NEURAL NETWORKS
SYMPLECTIC NEURAL NETWORKS
+ Any Runge-Kutta method
+ Any Symplectic method