Structure preserving neural networks coming from ODE models
Davide Murari
SciCADE 2021 - 28/07/2022


\(\texttt{davide.murari@ntnu.no}\)
Joint work with Elena Celledoni, Brynjulf Owren,
Carola-Bibiane Schönlieb and Ferdia Sherry

What are neural networks
They are compositions of parametric functions
\( \mathcal{N}(x) = f_{\theta_k}\circ ... \circ f_{\theta_1}(x)\)
Example
\(f_{\theta}(x) = x + B\Sigma(Ax+b),\quad \theta = (A,B,b)\)
\(\Sigma(z) = [\sigma(z_1),...,\sigma(z_n)],\quad \sigma:\mathbb{R}\rightarrow\mathbb{R}\)
Neural networks modelled by dynamical systems
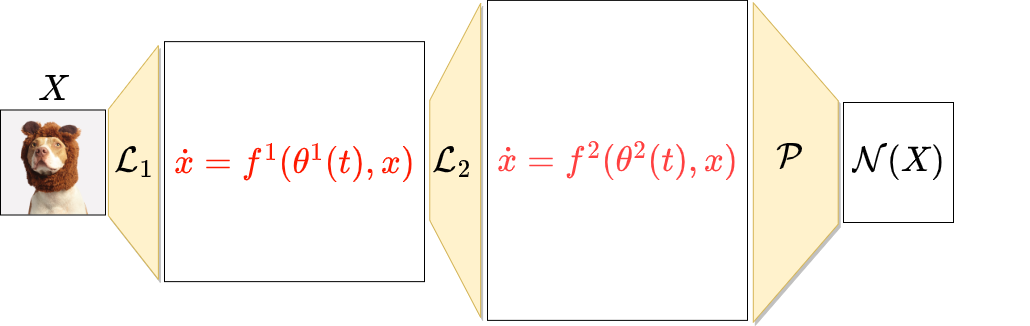
DYNAMICAL BLOCKS
Dynamical blocks
EXPLICIT
EULER
\( \Psi_{f_i}^{h_i}(x) = x + h_i f_i(x)\)
\( \dot{x}(t) = f(x(t),\theta(t)) \)
Time discretization : \(0 = t_1 < ... < t_k <t_{k+1}= T \), \(h_i = t_{i+1}-t_{i}\)
Where \(f_i(x) = f(x,\theta(t_i))\)
EXAMPLE
Imposing some structure
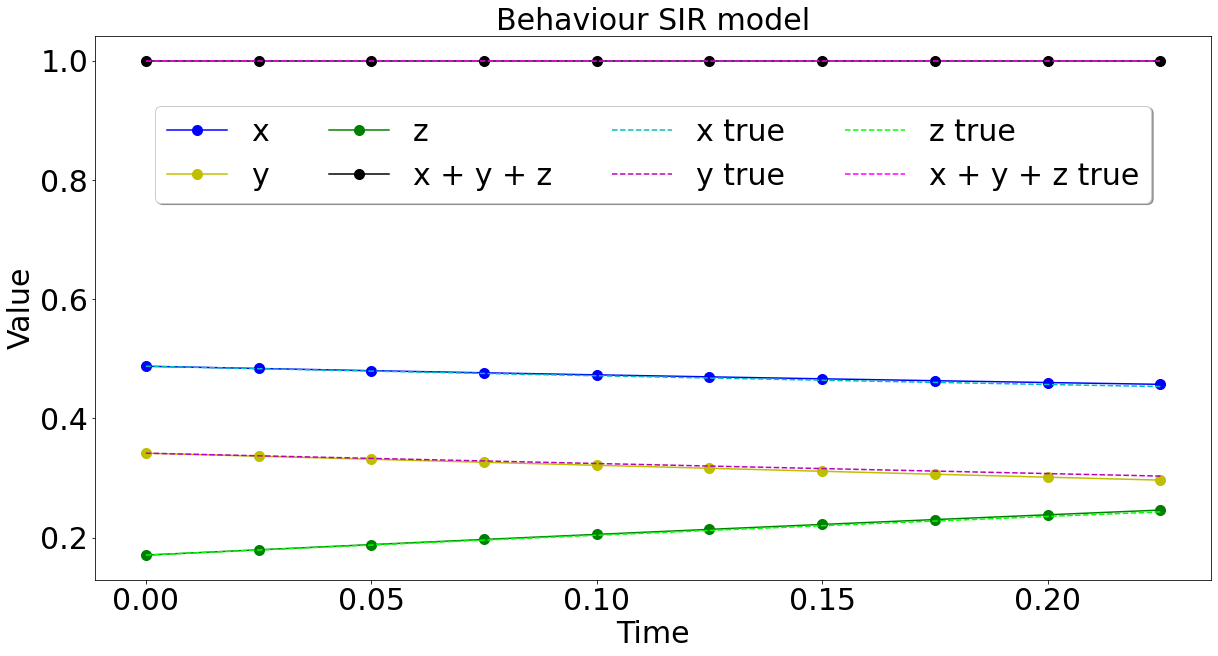
MASS PRESERVING DYNAMICAL BLOCKS
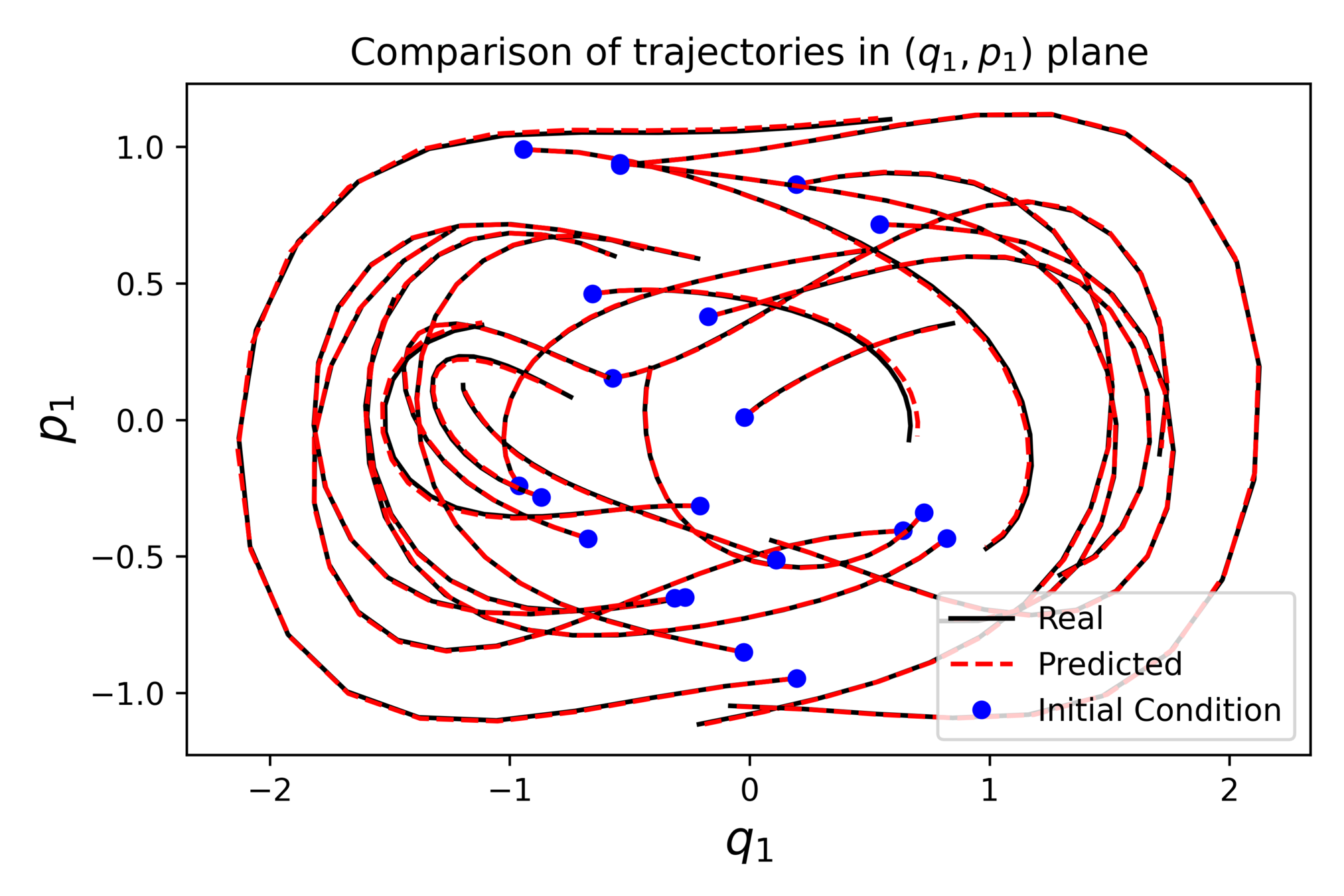
SYMPLECTIC DYNAMICAL BLOCKS
VOLUME PRESERVING DYNAMICAL BLOCKS
Then \(F\) can be approximated with flow maps of gradient and sphere preserving vector fields.
Can we still accurately approximate functions?
1-Lipschitz neural networks and the classification problem
Description of the problem
Given a "sufficiently large" set of \(N\) points in \(\mathcal{M}\subset\mathbb{R}^k\) that belong to \(C\) classes, we want to learn a function \(F\) assigning all the points of \(\mathcal{M}\) to the correct class.
Adversarial examples


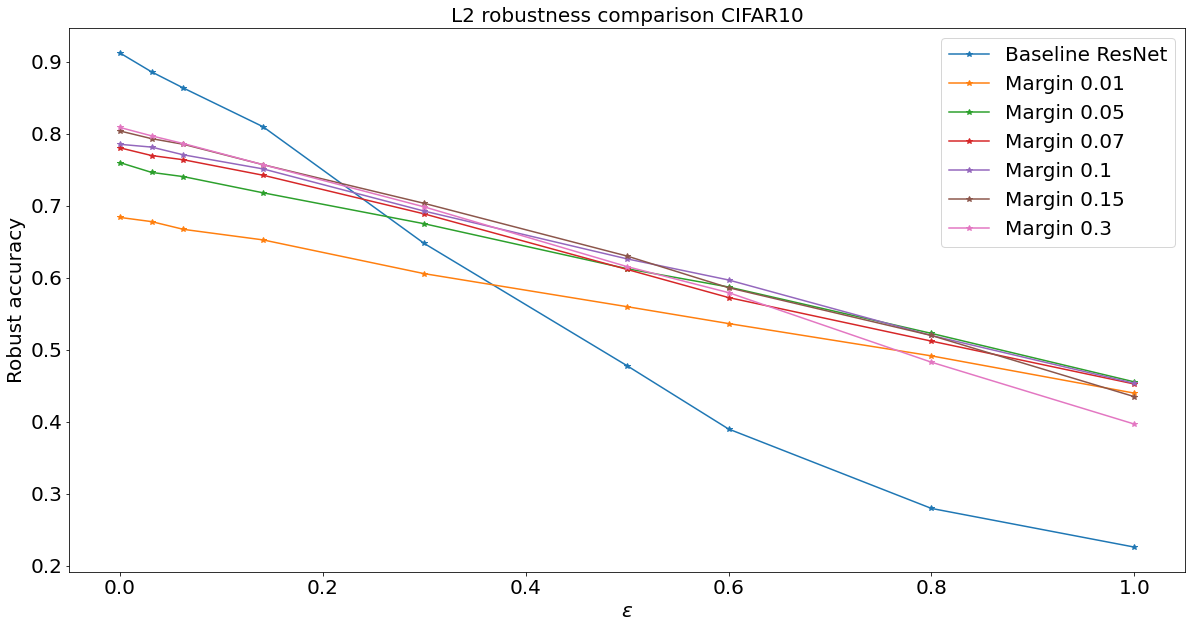
How to have guaranteed robustness
We constrain the Lipschitz constant of \(F\)
Lipschitz dynamical blocks
Lipschitz dynamical blocks
We impose : \(\gamma_i\leq 0\)
Adversarial robustness
Thank you for the attention
In progress:
Celledoni, E., Murari, D., Owren, B., Schönlieb, C. B., & Sherry, F.
Dynamical systems' based neural networks