Real-time estimation of an heat pump I/O state with IoT data
Davide Poggiali


Euroscipy 2022, Basel CH
Summary
- Introduction
- The story behind the data
- Preprocessing steps
- Comparing the ML models results
- The "best" model
- Conclusions
1. Introduction
This talk presents a case study of the estimation of the state (I/O) of an heat pump given simple accelerometer data. I hope that this can be useful or inspiring for your future works.
The rising of the energy prices has given to this work an higher priority in my schedule, as the realtime I/O is directly proportional to the energy consumption of the heat pump.
2. The story behind the data

Every dataset has a story to tell, and I like to listen to it..

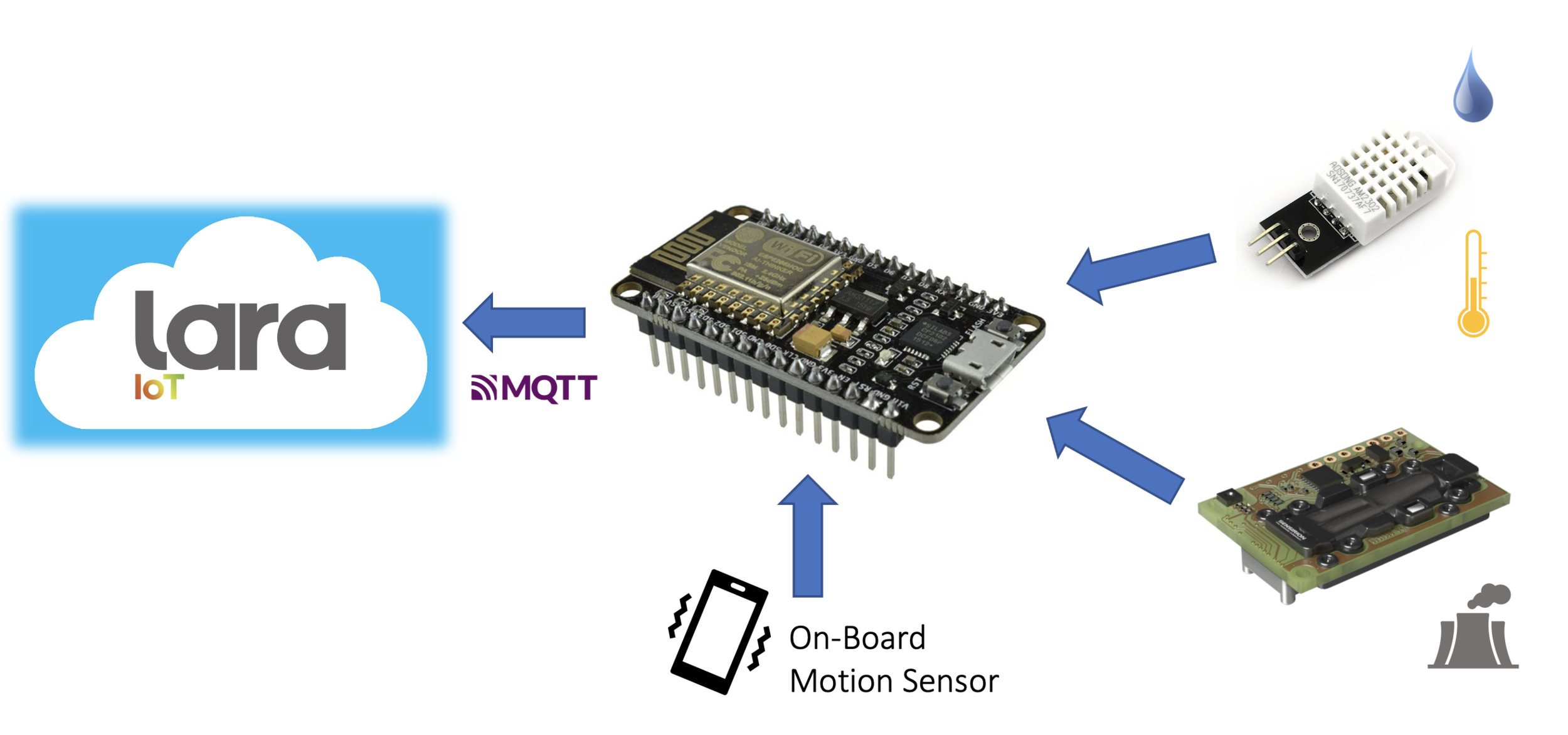
The data I am using comes from Arduino accelerometer posed in all the heat pumps of a private clinic in Milan, IT. The heat pumps serves for air conditioning, and medical equipment cooling too.
All the sensor installed in an environment is sent to Lara via an edge computer, and stored in a \( (time,value)\) format for future retrieval.
Accelerometer data comes in the three axes \((x,y,z)\).
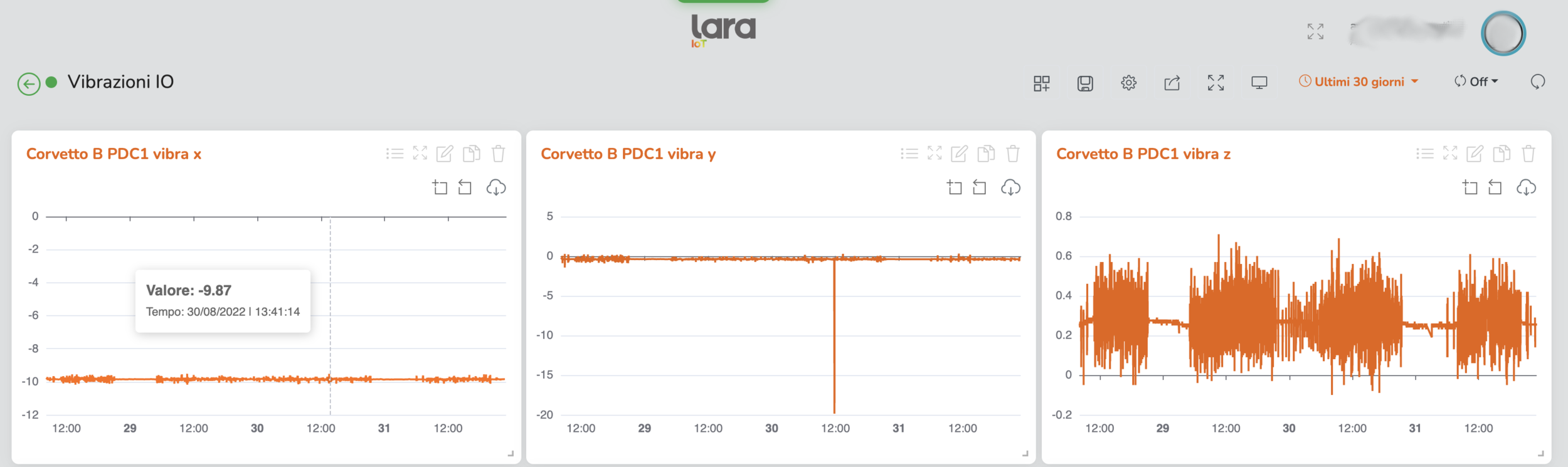
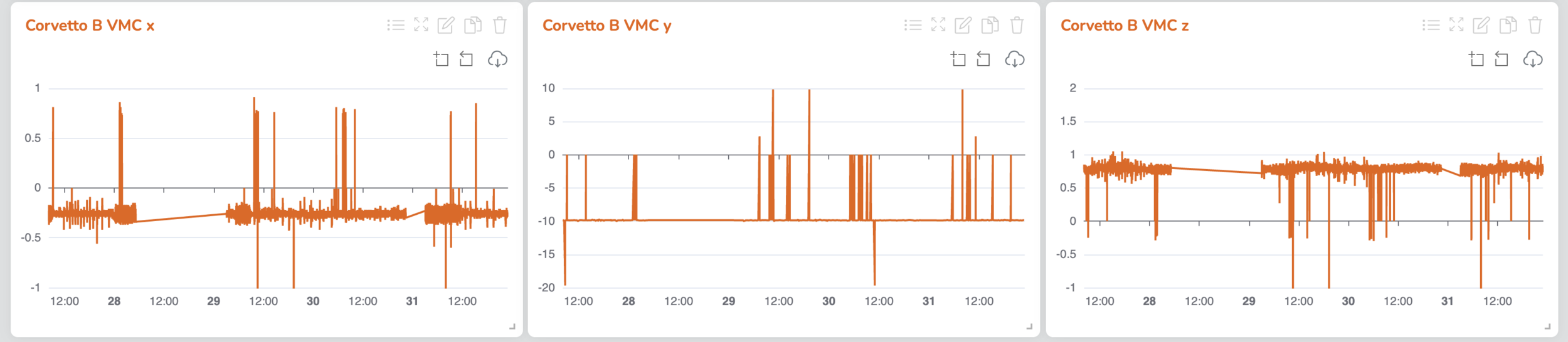
3. Preprocessing steps
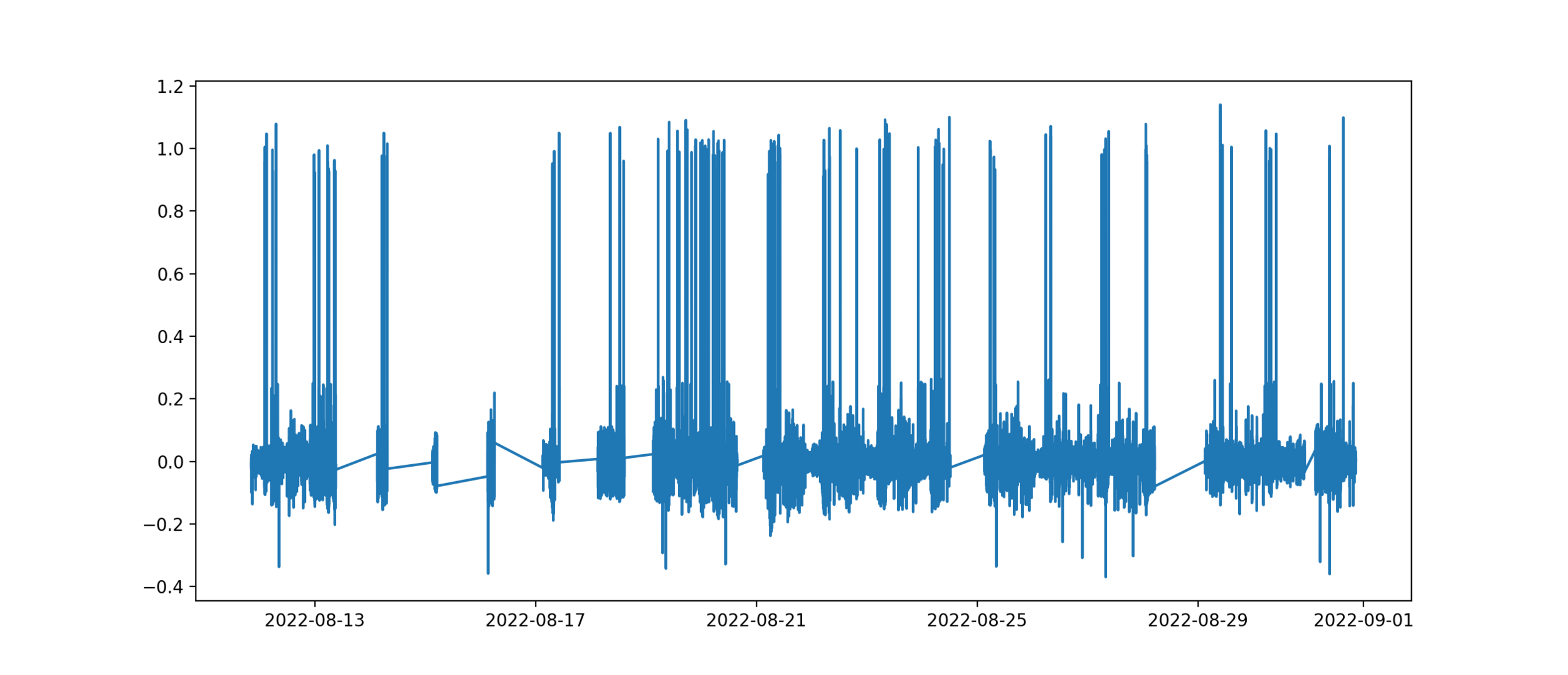
Let's take a look at some data, just the x-axis to begin.
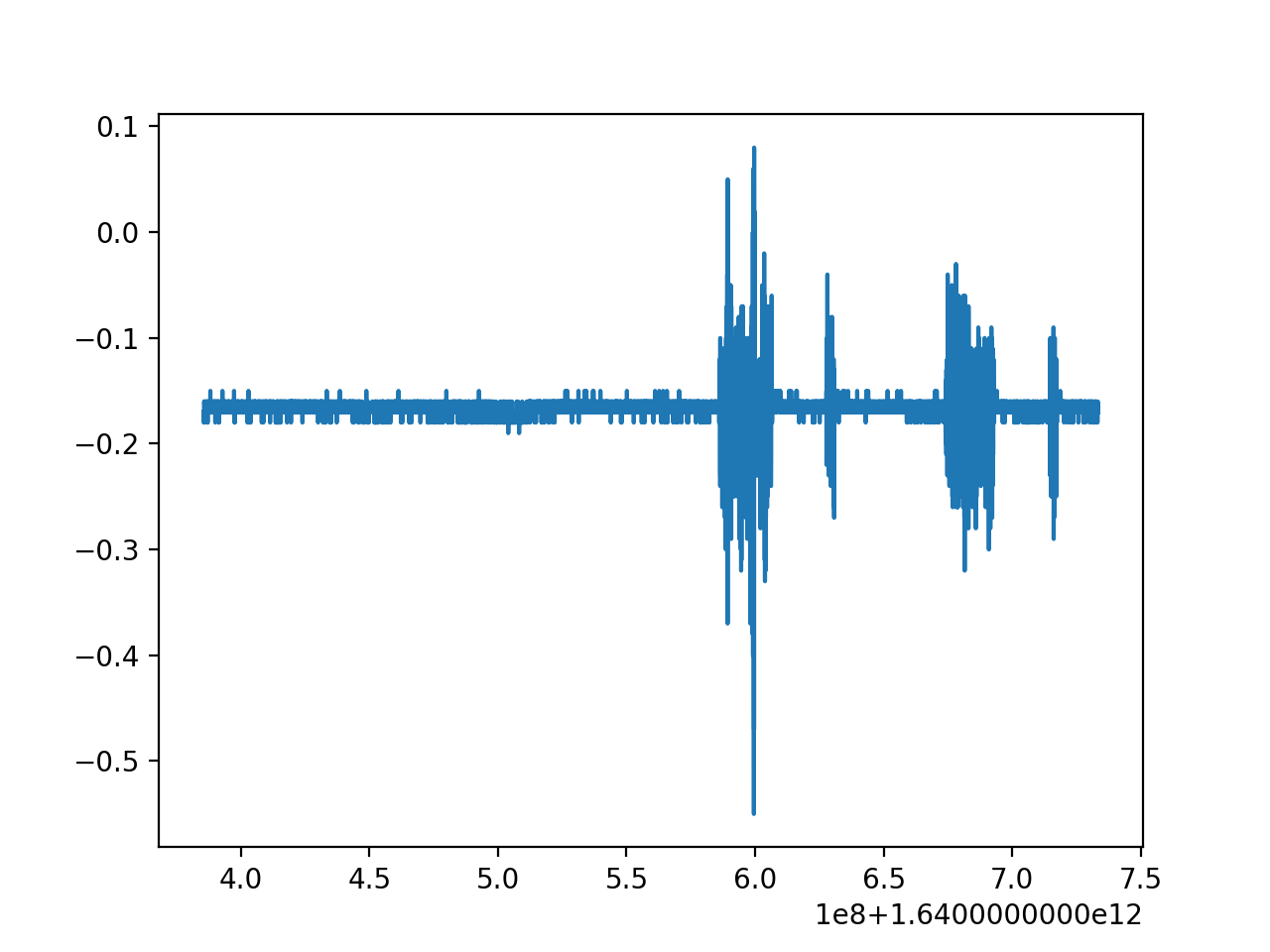
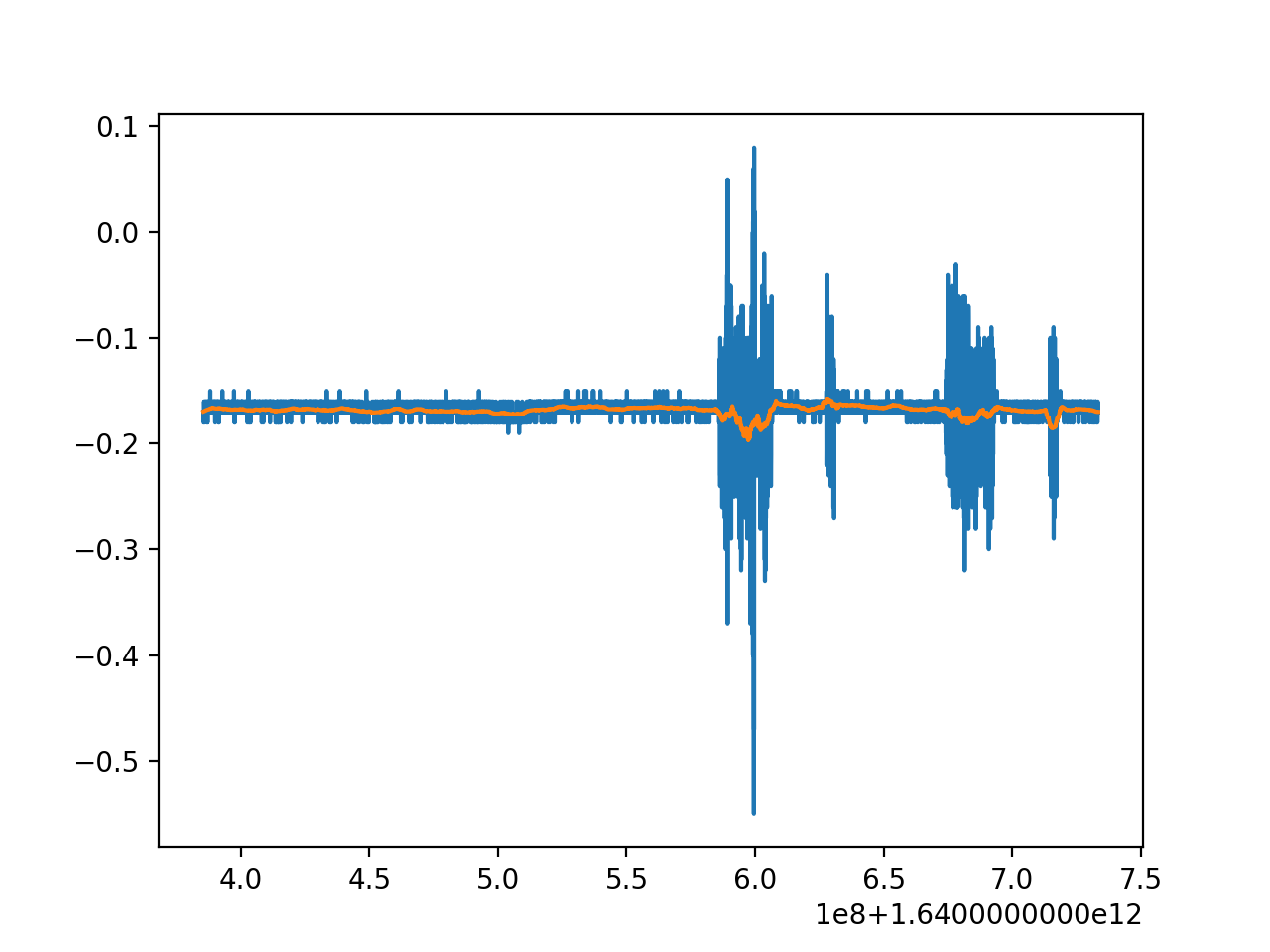
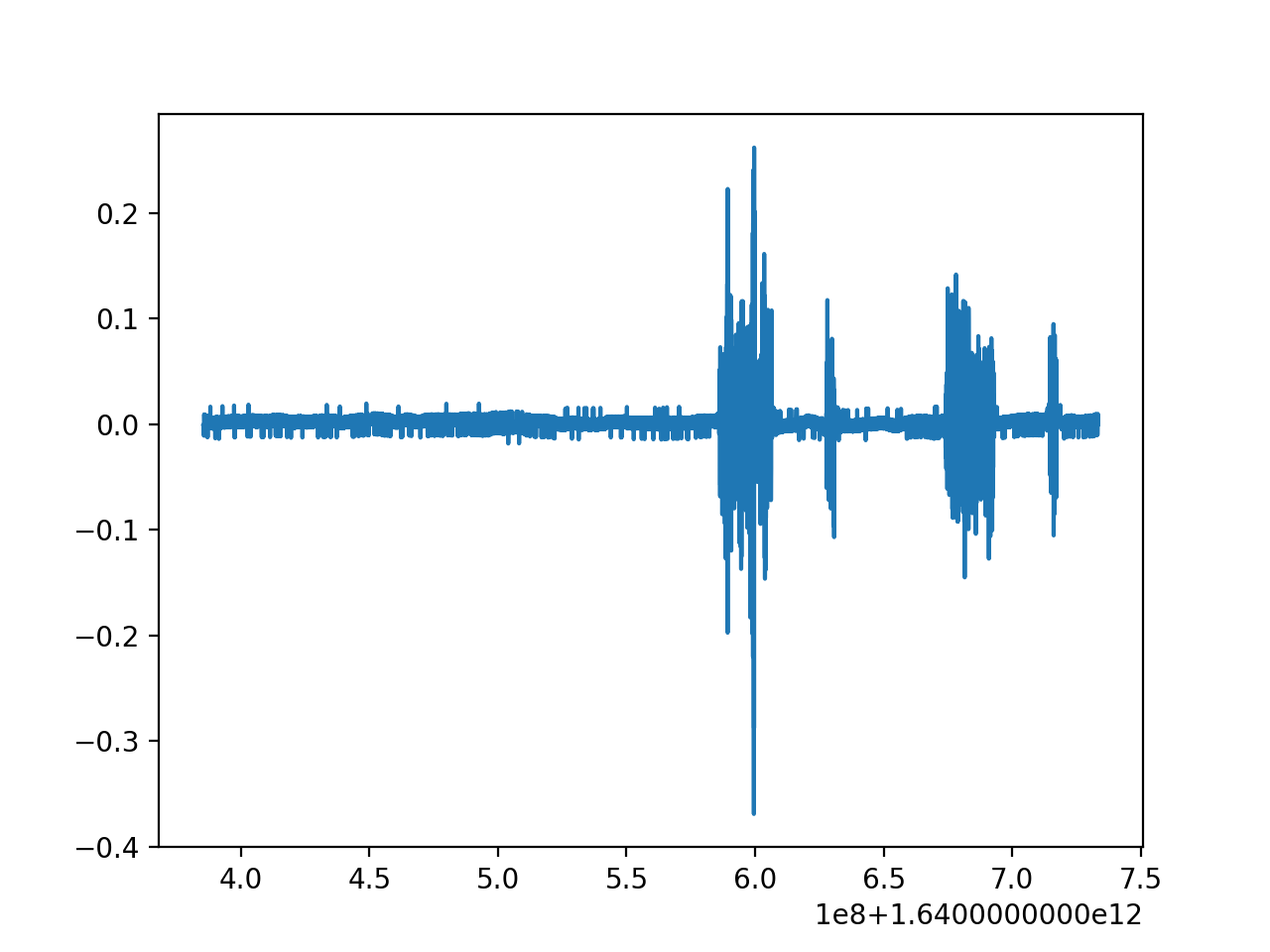
Now what could we do?
No labels (yet!)
Recall the data story ...
...we can use the accelerometer in the MRI scanner to the the times the HP was ON for sure!
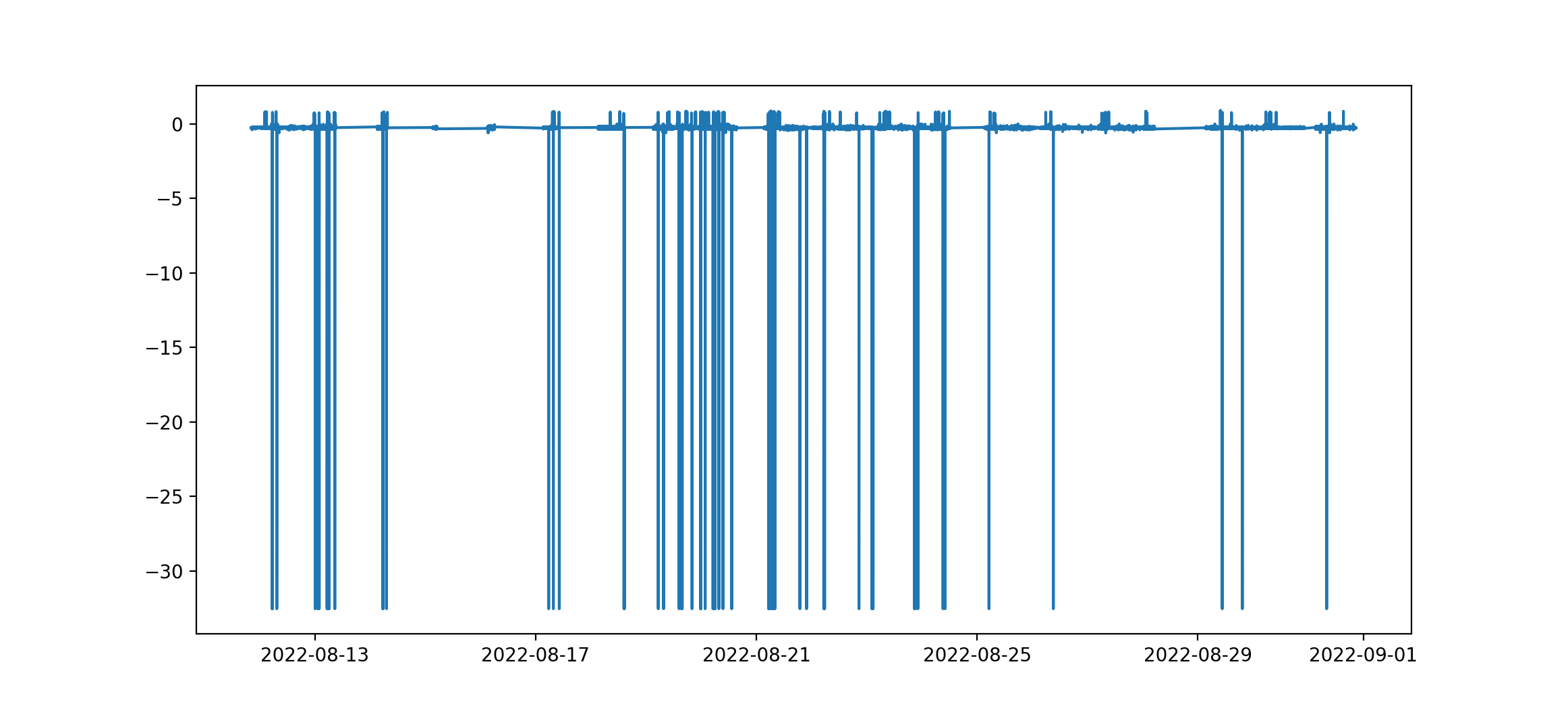
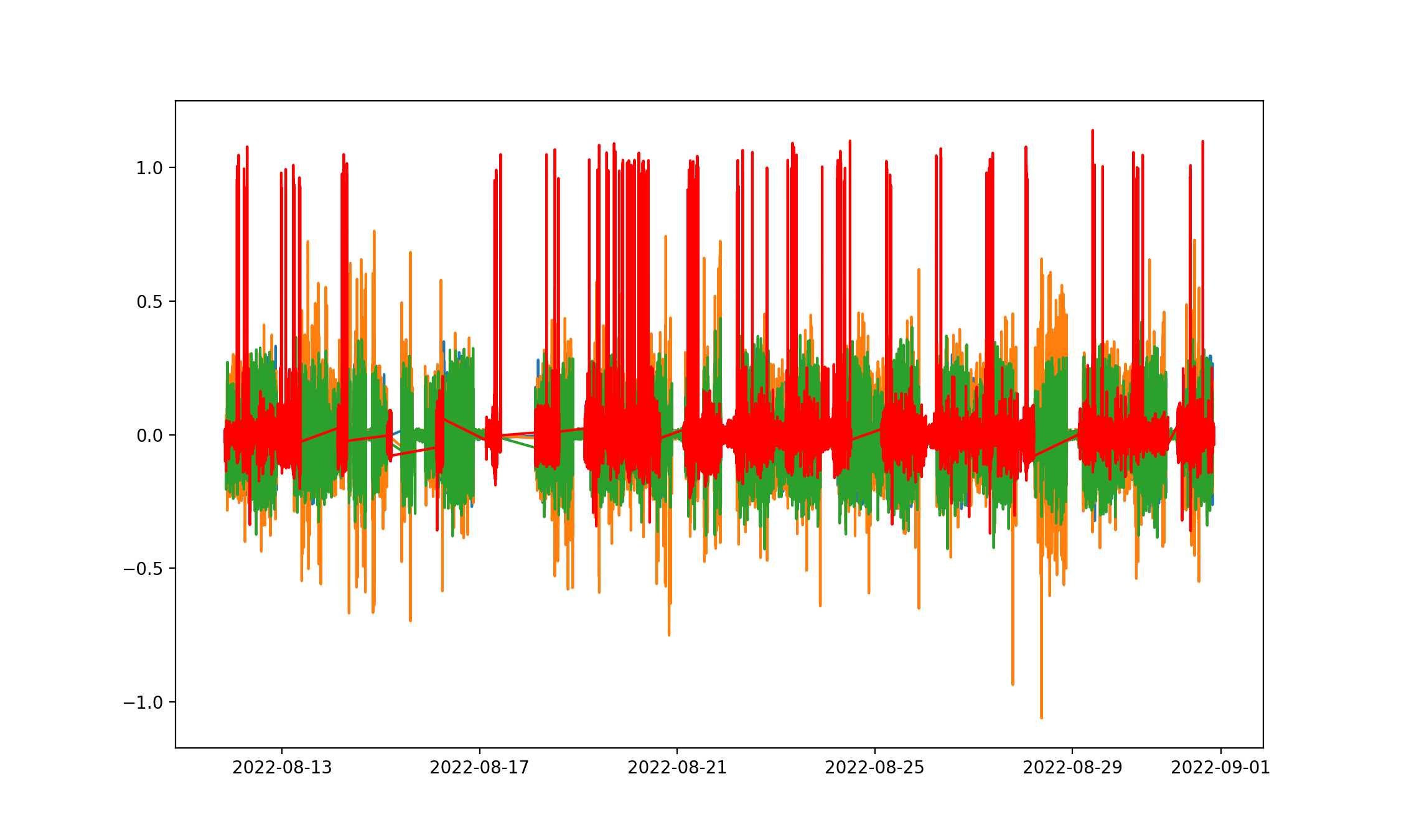
Just a quick look on MRI accelerometer data...
...better use an outlier detection and drop them out!
Now we can take look and patiently label some data by hand
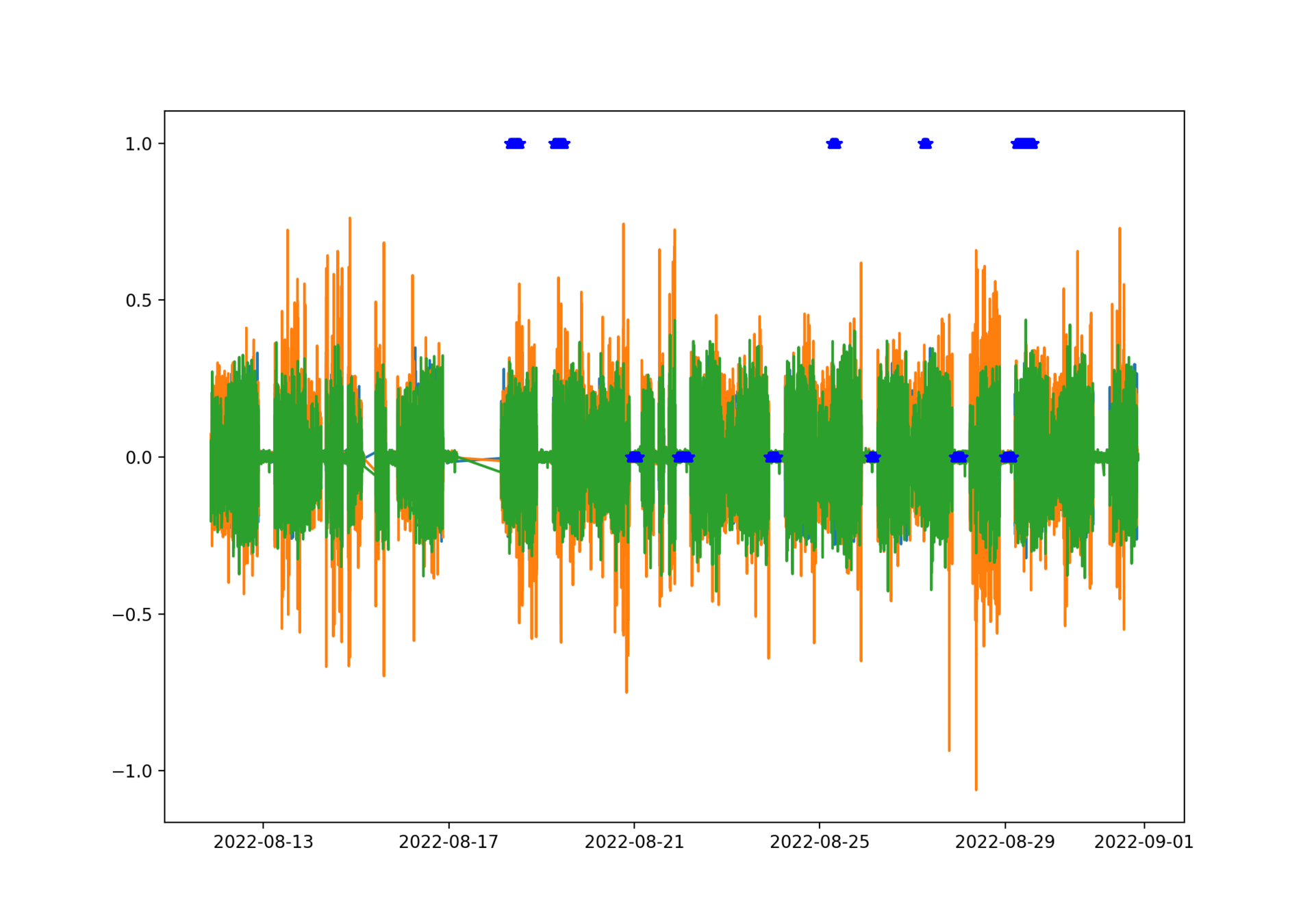
Now that about a 10% of the data has I/O labels, we can move on.
4. Comparing different ML models results
We choose some popular binary classification models provided by scikit-learn:
- Logistic Regression
- Support Vector Machines (SVC)
- Random Forest
- Naive Bayes
- K-Nearest Neighbour
and compare their performances after a Train-test random split in terms of accuracy, precision, recall, ROC-AUC, and evaluation times.
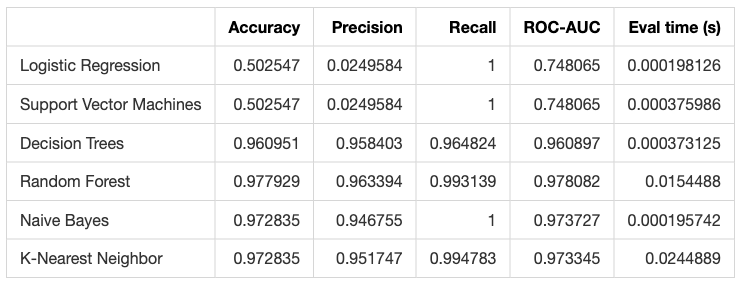
The results are shown in the following table.
5. The "best" model
We choose the Naive Bayes for its great speed and good performance results.
We now can apply it to the original, unlabeled dataset.
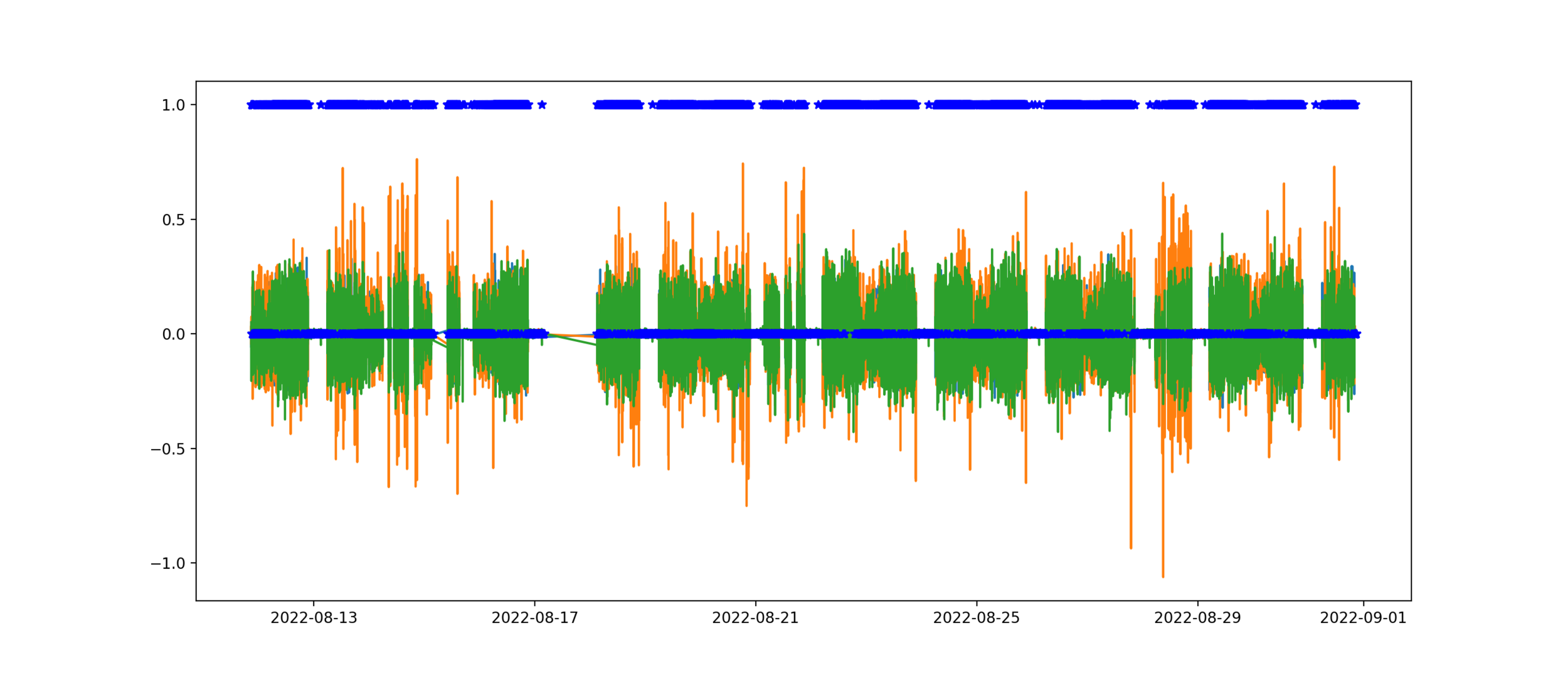
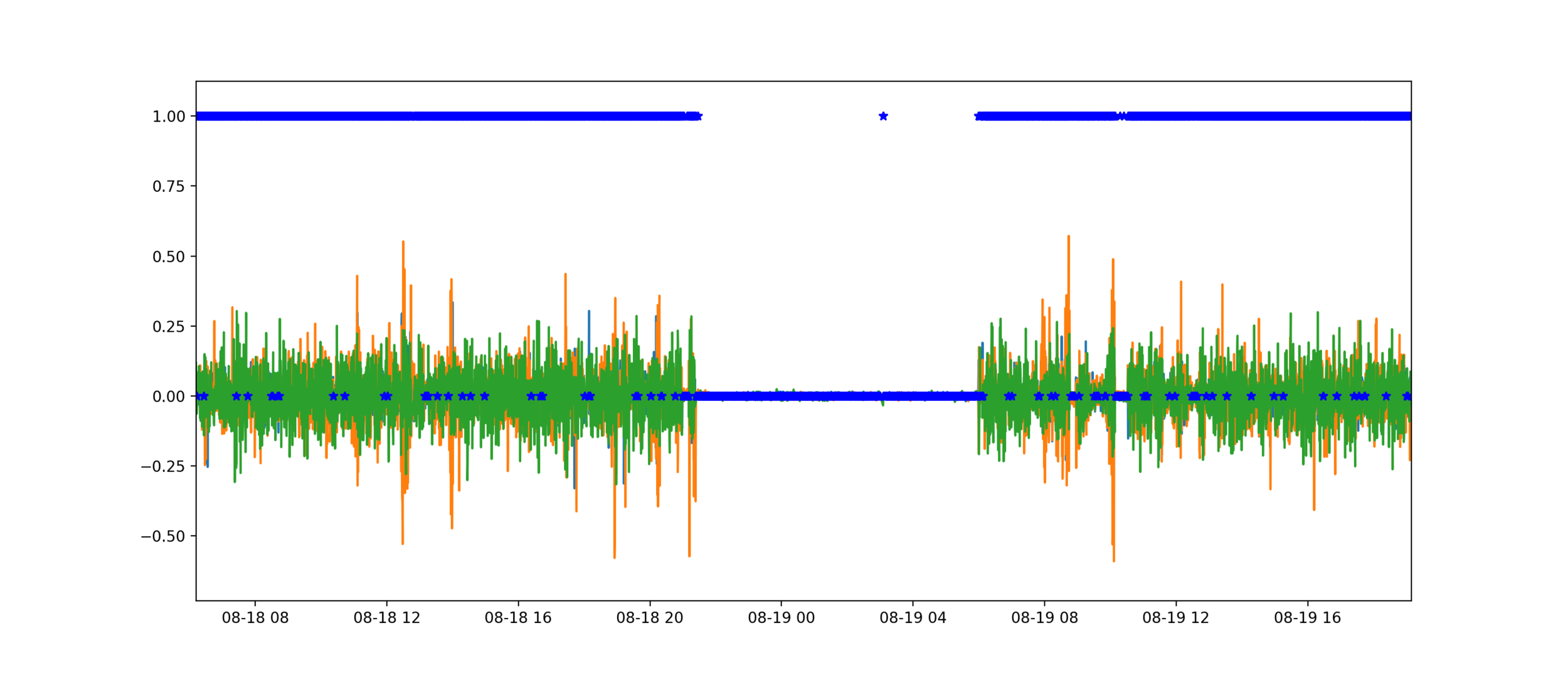
So, this models gives me a real-time I/O estimation
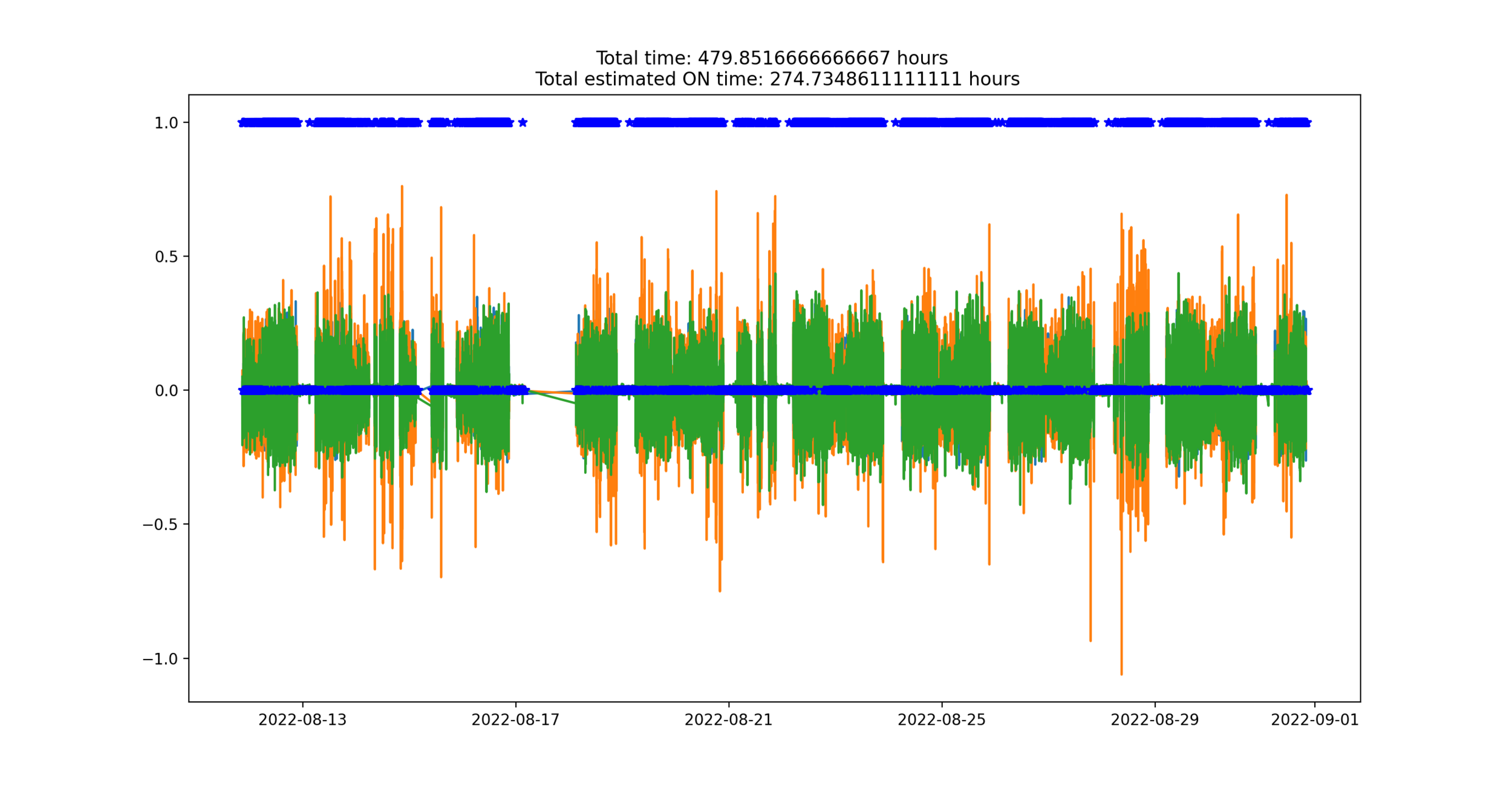
The estimation of the total ON time come for free, with a simple composite trapezoidal integration.
6. Conclusions:
Take-home messages:
- always sit down and hear the stories from your data
- labeled data does not exists in nature
- sometimes you have to be creative to label your data (or some subset).

Future works:
- Give a non-binary label to the Heat Pump activity
- Compare the estimated woking hours with some measures of the real electric consumption.
- Stopping with the GIFs (not gonna happen)

Acknowledgements:
I want to thank all my colleagues at FAR Networks for the continuous support, and for having developed some of the software that saved me a LOT of work.
I also want to thank Sant'Agostino, the private clinic network from which this dataset was recorded. In particular Andrea Codini for his availability.

And finally thanks to the organisers, and the audience, of course.