Toward a Science of Causal Interpretability in Deep Learning for Software Engineering
Final Defense
April 14, 2025
David N. Palacio
Department of Computer Science

Motivating Example:
Code Generation

def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
Input: Prompt
Output: Completed Code
Neural Code Model
A typical setup for conditioned generation
To what extent is the current prevalence of code generation driven by Hype?
How trustworthy is the generated snippet?
Accuracy: ~0.8

Why that code generation/prediction?
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
Input: Prompt
Output: Completed Code
Neural Code Model
Accuracy-based metrics are insufficient
Accuracy: ~0.8
Not Interpretable
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
Input: Prompt
Output: Completed Code
Neural Code Model
Interpretability is understanding how and why models make predictions so that decision-makers (e.g., programmers, doctors, judges) can assess the extent to which they can trust models' output
(Doshi-Velez & Kim, 2017) (Weller,2019) (Lipton,2017) (Pearl,2019)
def (, ) :
First Explanation: Unreliable Prediction
Explanations can be provided by observing the semantics and syntax of the prompt
Accuracy: ~0.8
Not Interpretable
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
def countChars(string, character):Prompt
Tokens
Features
Output: Completed Code
def (, ) :
countChars string character
First Explanation: Unreliable Prediction
Second Explanation: Trustworthy Prediction
Accuracy: ~0.8
Not Interpretable
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
Code Completed
def countChars(string, character):Prompt
Tokens
Features
Explanations can be provided by observing the semantics and syntax of the prompt
Typical Post-Hoc Interpretability Pipeline
complex model
autoregressive
extract interpretability features
prompts/inputs
outputs
inner parts (e.g, layers, neurons)
Interpreter or Explainer
Simpler Models or Explanations
Explaining why a Neural Code Model makes the predictions it does has emerged as one of the most challenging questions in DL4SE
(Palacio. et al., 2023) (Lipton,2017) (Pearl,2016)
We propose using scientific explanations based on causality to reduce the conceptual interpretability gap
Factors or Treatments
Outcomes
Causal Effect or Explanation
Some Examples of Scientific Explanations
Factors or Treatments
Outcomes
Causal Effect or Explanation
Type of Prompts, Hyperparameters,
or SE Interventions
Correlations,
ATEs,
or Counterfactual Pr.
Accuracy,
Logits,
or Predictions
How do we interpret Neural Code Models with Scientific Explanations?
Syntax (De)Composition
Pearl's Ladder of Causation
Syntax (De)Composition
Pearl's Ladder of Causation
Syntax (De)Composition
Pearl's Ladder of Causation
Pearl introduced a mathematical model of causality, enabling AI sys. to distinguish between:
Association
(correlation)
Intervention
(causation)
Counterfactual
Reasoning
Rung/Level 1
Rung/Level 2
Rung/Level 3
Association
(correlation)
Intervention
(causation)
Counterfactual
Reasoning
Rung/Level 1
Rung/Level 2
Rung/Level 3
“People who eat ice cream are more likely to swim.”
“If we make people eat ice cream, will they swim more?”
“If people had not eaten ice cream, would they have
gone swimming?”
Some Examples
Pearl introduces different levels of interpretability and argues that generating counterfactual explanations is the way to achieve the highest level of interpretability.
Rung/Level 1
Rung/Level 2
Rung/Level 3
Associational
Interpretability
Interventional
Interpretability
Counterfactual
Interpretability
Causal Interpretability occurs at different levels
Rung/Level 1
Rung/Level 2
Rung/Level 3
Associational
Interpretability
Interventional
Interpretability
Counterfactual
Interpretability
How is the code prediction Y related to (testing) code data with bugs T ?
To what extent does a (test) buggy sequence impact error learning or code prediction?
Would the model generate accurate code predictions if bugs had been removed from training code data?
How can we formulate causal questions?
What is Causality?
The Causal Effect is a measure of the influence of a variable T on another variable Y .
Treatment:
Bugs in Code
Potential Outcome:
Code Prediction
?
"T causes Y if Y listens to T":
If we change T, we also have to observe a change in Y (Pearl, 2019)
We want to understand how code predictions react under different input data (or hyperparameter tuning)
We encode causal relationships between variables in a Structural Causal Model.
(Structural) Causal Graph
(DAG)
Both representations (graph and equations) refer to the same object: a data-generating process
(Structural) Causal Graph
(DAG)
Functional Relationships
:= is a walrus operator or arrow (directional or asymmetric relations)
Causal Interpretability is a mathematical framework by which NCMs are interpreted or explained from a causal assumption encoded in a Structural Causal Graph
complex model
autoregressive
extract interpretability features
feasible snippets
output logits
causal interpretability
causal explanations
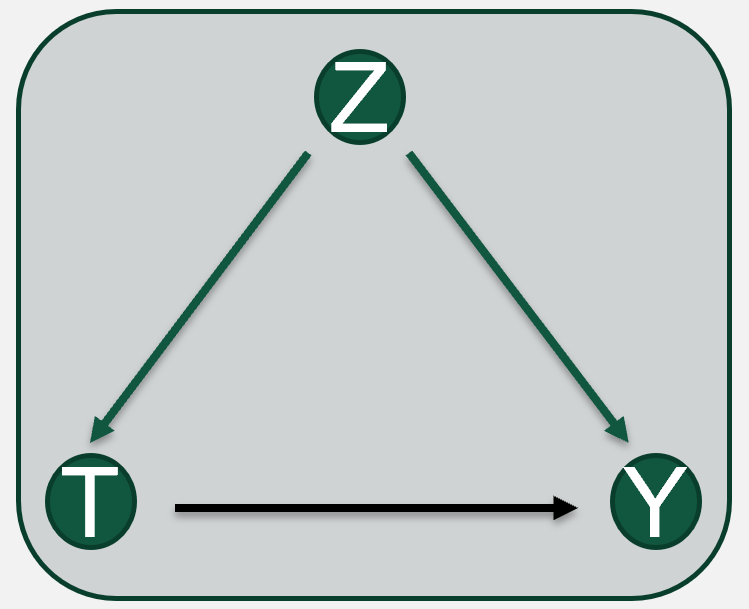
Structural Causal Graph/Model
This Dissertation: Causal Interpretability
To what extent is the current prevalence of code generation driven by Hype?
The Main Contributions of This Dissertation
Syntax (De)Composition
Pearl's Ladder of Causation
[Technique] Probabilistic Functions/Interactions
[Method] Code-Based Explanations
[Method] Neurosymbolic Rules
[Metric] Proposensity Score for Smells
Syntax (De)Composition
Rung 1: Association (correlation)
Rung 2: Intevention (causation)
Rung 3: Counterfactual Reasoning
[Method] Code Rationales
[Method] TraceXplainer
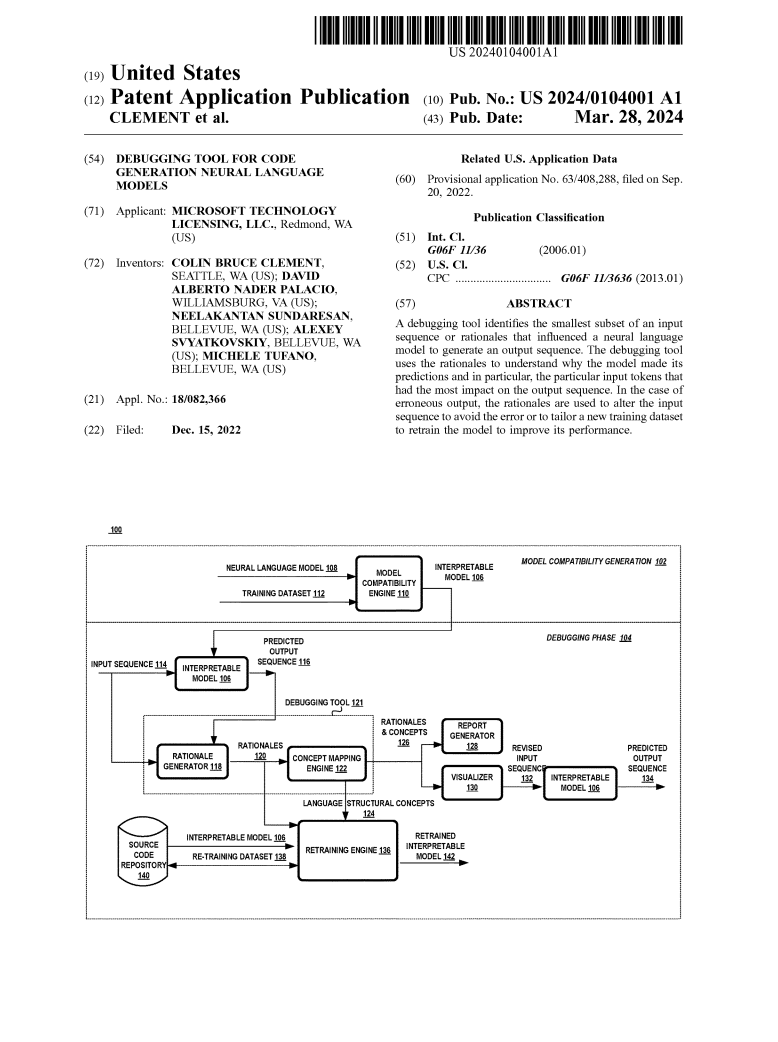
[Patent] Debugging Rationales
[Methodology] doCode
[Empirical Eval.] Interpretability Scenarios
[Benchmarking] Causal SE
[Prospective Analysis] Autopoietic Arch.
Pearl's Ladder of Causation
This presentation concentrates on three components
First Component: Syntax (De)Composition
Part I: Confounding Bias
Counfounding Bias Example:
Disparities in Gender Classification






Aggregated metrics obfuscate key information about where the system tends to success or fail

Neural Classifier
Accuracy of 90%
(Burnell. et al., 2023)
Segregated metrics enhance the explanation of prediction performance
Neural Classifier
Darker Skin Woman
Lighter Skin Man
Error:
34.7%
Error:
0.8%
Simpson's Paradox: Confounders affect the correlation
Darker Skin Woman
Lighter Skin Man
Error:
34.7%
Error:
0.8%
Accuracy of 90%
Aggregated Metrics
Segregated Metrics
What about software data?
Disparities in Code Generation

def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
unconditioned
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
conditioned
prompt
completed
generated
codegen-mono-2b
sampling
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
unconditioned
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
conditioned
prompt
completed
generated
codegen-mono-2b
sampling
Aggregated Accuracy ~0.84

Feasibility Area
High Dimensional [Accuracy] Manifold
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
unconditioned
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
conditioned
prompt
completed
generated
codegen-mono-2b
sampling
Aggregated Accuracy ~0.84
Feasibility Area
Statistical Functions
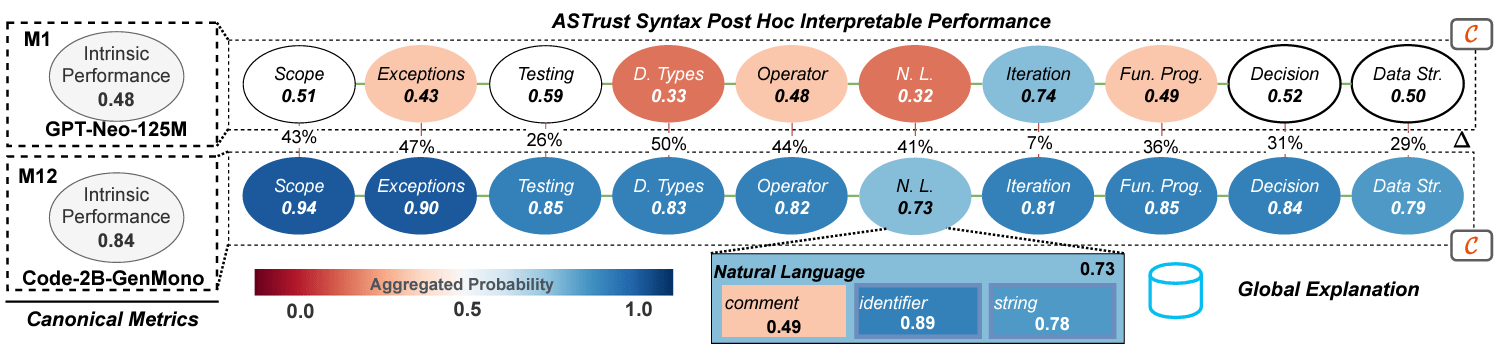
Segregated Accuracy by Code Features
natural language ~0.72
- comments (0.49)
- string (0.78)
- identifier (0.89)
types ~0.83
- float (0.78)
- integer (0.87)
decision ~0.84
- if_statement (0.78)
- elif (0.79)
High Dimensional [Accuracy] Manifold
natural language ~0.72
- comments (0.49)
- string (0.78)
- identifier (0.89)
types ~0.83
- float (0.78)
- integer (0.87)
decision ~0.84
- if_statement (0.78)
- elif (0.79)
Darker Skin Woman
Lighter Skin Man
Error:
34.7%
Error:
0.8%
Confounding Variables allow us to decompose the performance into meaningful clusters
Gender Classification
Code Generation
Confounding Bias is purely a Causal Inference Concept (not a statistical one)
First Component: Syntax (De)Composition
Part II: Examples of Manifold Partition for Code
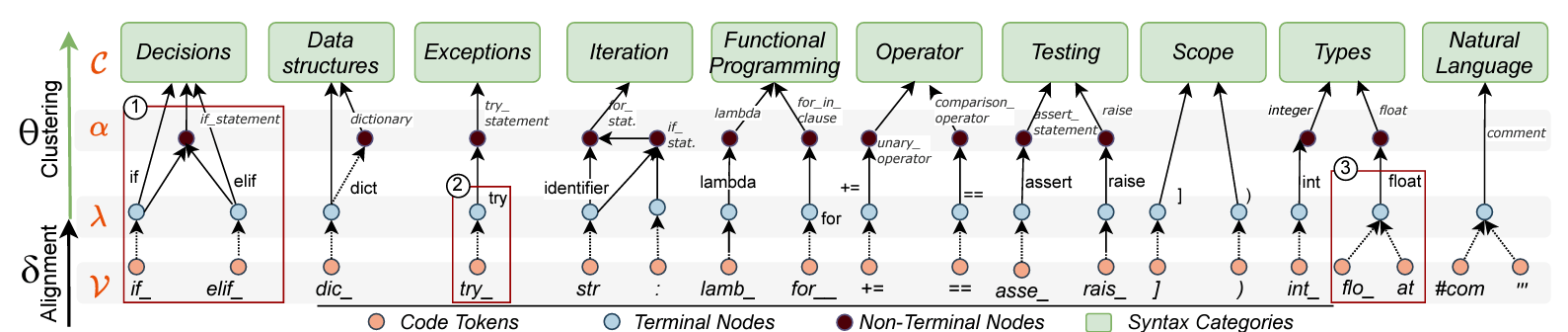
Statistical Function: AST decomposition
natural language ~0.72
- comments (0.49)
- string (0.78)
- identifier (0.89)
types ~0.83
- float (0.78)
- integer (0.87)
decision ~0.84
- if_statement (0.78)
- elif (0.79)
Aggregated measures offer a partial understanding of neural models' inference process, while partitions make the measures more interpretable (for practitioners).
High Dimensional [Accuracy] Manifold
How do we know how to partition or which partitions are correct?
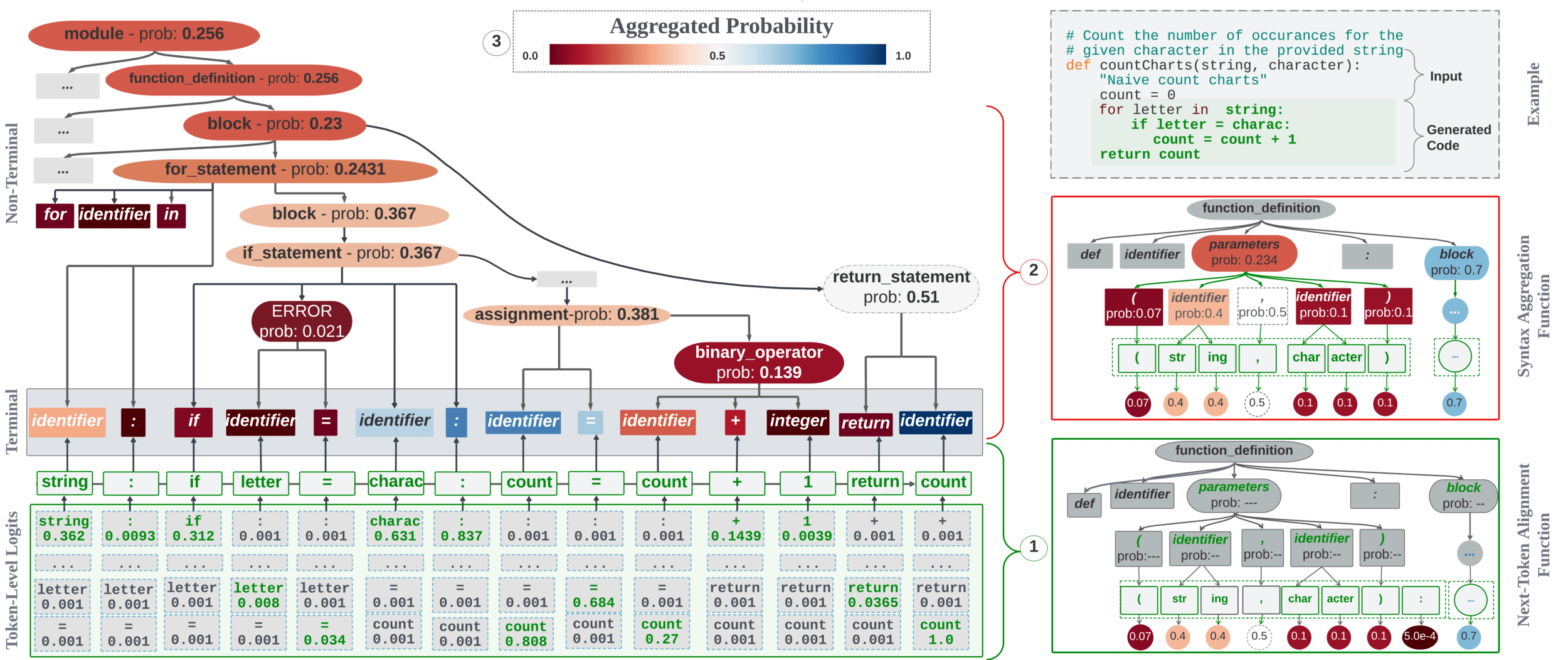
AST decomposition: ASTscore
Syntax (De)Composition: A manifold partition of the intrinsic metric space (e.g., accuracy space)
High Dimensional [Accuracy] Manifold
AST decomposition: ASTscore
Syntax (De)Composition: A manifold partition of the intrinsic metric space (e.g., accuracy space)
High Dimensional [Accuracy] Manifold
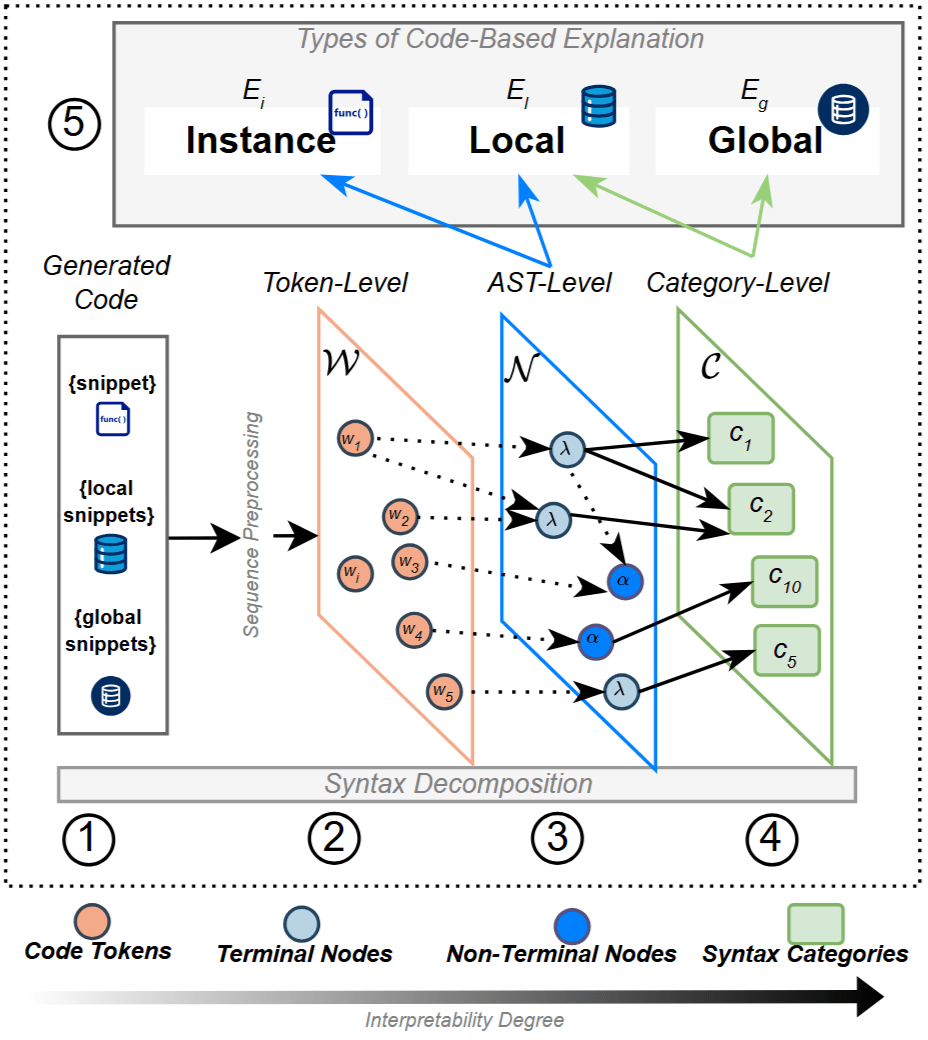
Syntax (De)composition is based on two mathematical interactions: alignment and clustering
Aggregated ASTscore
Segregated ASTscore
Example of Results: Aggregated vs. Segregated Score
High Dimensional [Accuracy] Manifold
AST decomposition: ASTscore
We can partition with different functions (e.g., Natural Language, Keywords, Focal Methods) and manifolds (e.g., accuracy, SHAP values, Shapley values, rationales)
High Dimensional [Accuracy] Manifold
NL decomposition: NLscore
Keywords decomposition: KEYscore
High Dimensional [SHAP] Manifold
High Dimensional [Rationales] Manifold

This work goes beyond correlational analysis by proposing interpretability methods to control for confounders
Second Component: doCode
Part I: The math of doCode
The Causal Interpretability Hypothesis
doCode is a causal interpretability method/methodology that aims to make Deep Learning for Software Engineering (DL4SE) systems (e.g., pretrained or LLMs) and their decision-making process understandable for researchers and practitioners
doCode operates at the intervention level
complex model
autoregressive
extract interpretability features
feasible snippets
output logits
causal interpretability
causal explanations
The doCode pipeline is based on Pearl's Causal Theory
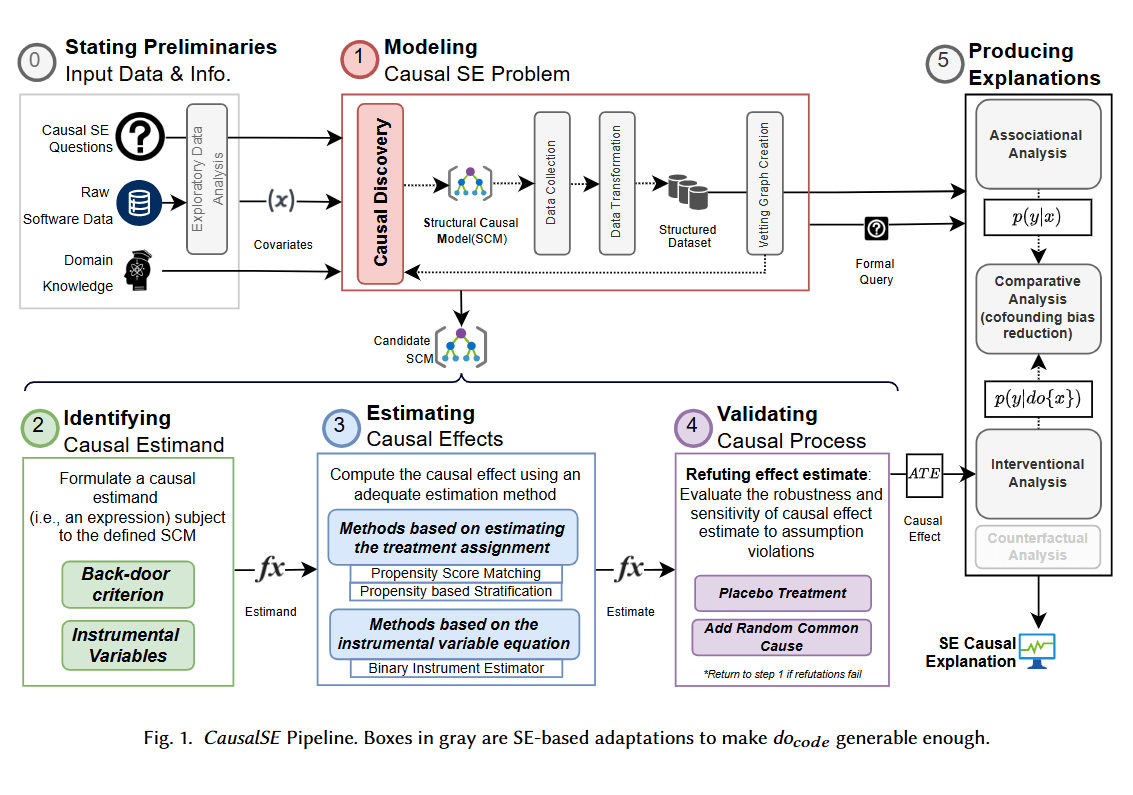
1. Modeling
2. Identification
4. Validation
3. Estimation
causal explanations
domain knowledge
input software data
exploratory analysis
Encode causal assumptions in a graph
Formulate a causal estimand
Structural Causal Graph
Math Expression
Compute a Causal Effect using an estimation method
Evaluate the robustness of estimated causal effect
Causal Estimation
Step 1: Modeling Causal Problem
Endogenous nodes can be employed to model relationships among interpretability variables
Structural Causal Model for Interpretability (SCMi)
treatments
potential outcomes
confounders
Graph Criteria
SE-based (interpretability) interventions
Representation of code predictions
Variables that affects both proposed SE-based interventions and code predictions
BuggyCode
Cross-Entropy Loss
Sequence Size
causal effect
What is a treatment variable?
Treatments are the variables that represent the intervention in the environment.
treatments
potential outcomes
confounders
causal effect
data inteventions
BuggyCode
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
feasible correct snippet
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count - 1
return count
feasible buggy snippet (line 5)
Caveat. Treatments can be binary, discrete, or linear variables. We can intervene on data, model parameters, or any other possible SE property.
treatments
potential outcomes
confounders
causal effect
data inteventions
model inteventions
What is a potential outcome?
Potential Outcomes are the variables that represent the object of the causal effect—the part of the graph that is being affected.
treatments
potential outcomes
confounders
causal effect
potential outcome (or cross-entropy loss) under a Treatment T
0.02
0.0002
What are confounders?
Confounders are the variables that represent a common cause between the treatment and the outcome.
treatments
potential outcomes
confounders
causal effect
SE Metrics as Covariates
McCabe's Complexity
# Varibles
Lines of Code
# Lambda Expressions
# Max nested blocks
# Modifiers
# Returns
# Try-Catch
# Unique Words
Sequence Lenght/Size
Step 2: Identifying Causal Estimand
Level 1: Association
Conditional Probability
treatments
potential outcomes
confounders
causal effect
Level 1: Association
Conditional Probability
treatments
potential outcomes
confounders
causal effect
graph surgery/mutilation
Level 1: Association
Conditional Probability
causal effect
FixedCode
treatments
potential outcomes
confounders
causal effect
Variable Z is controled
graph surgery/mutilation
Level 2: Intervention
Interventional Probability
Adjustment Formula or Estimand
Interventional Distribution (Level 2)
Observational Distribution (Level 1)
back-door criterion
(algebraic + statistical properties)
Caveat. Not all covariates are confounders
Sequence Size as Confounder
Sequence Size as Mediator
Sequence Size as Instrument
Back-door
Front-door
Instrumental Variables
The back-door, mediation, and front-door criteria are special cases of a more general framework called do-calculus (Pearl, 2009)
Step 3: Estimating Causal Effects
We can use the adjustment formula to compute or estimate causal effects from observational data (Pearl, et al., 2016)
Interventional Distribution for one data sample
Interventional Distribution for one data sample
We can compute for a set of samples (i.e., code snippets) obtaining an ATE (average treatment effect)
Interventional Distribution for one data sample
We can compute for a set of samples (i.e., code snippets) obtaining an ATE (average treatment effect)
For binary treatment (i.e., BuggyCode), we can derive an expected value expression.
Treatment (T=1) means FixedCode
NO Treatment (T=0) means BuggyCode
Expected value terms can be estimated from data using propensity score matching, linear regression, or machine learning methods
Treatment (T=1) means FixedCode
NO Treatment (T=0) means BuggyCode
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count - 1
return count
feasible buggy snippet (line 5)
feasible correct snippet

Correct Snippets Dataset
Buggy Snippets Dataset
Step 4: Validating Causal Process
Testing for the causal graph quality, fitting the data, would be the main issue
How can we falsify graph-encoded assumptions?
Refuting Effect Estimates
Add Unobserved Common Cause
treatments
potential outcomes
confounders
Unobserved Cause
How can we falsify graph-encoded assumptions?
Refuting Effect Estimates
Add Unobserved Common Cause
treatments
potential outcomes
confounders
Unobserved Cause
should be the same quantity
After the doCode pipeline, we obtain our validated causal effect quantity!
1. Modeling
2. Identification
4. Validation
3. Estimation
causal explanations
domain knowledge
input software data
exploratory analysis
Encode causal assumptions in a graph
Formulate a causal estimand
Structural Causal Graph
Math Expression
Compute a Causal Effect using an estimation method
Evaluate the robustness of estimated causal effect
Causal Estimation
We show that doCode combines rigorous statistical instruments and causal inference theory to give rise to contextualized SE explanations (of NCMs) using Structural Causal Models (SCMs)
Third Component
Part II: Interpretability Scenarios in Software Engineering
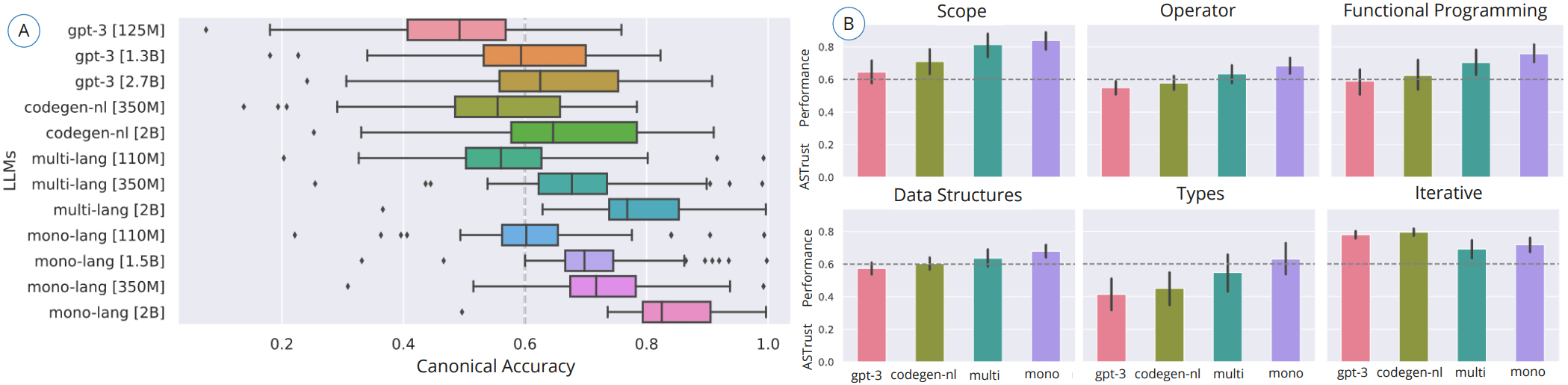
The study proposes (7+1) scenarios to demonstrate the efficacy and applicability of causal interpretability for code generation
Data-based interventions
Model-based interventions
Syntax Decomposition as Treatments
[special] Prompt Engineering as Treatments
[case A] Buggy Code Impact
[case B] Inline Comments Impact
[case C|D] Code Clones Impact
[case E] # of Layers Impact
[case F] # of Units Impact
[case G] On encoder-only models
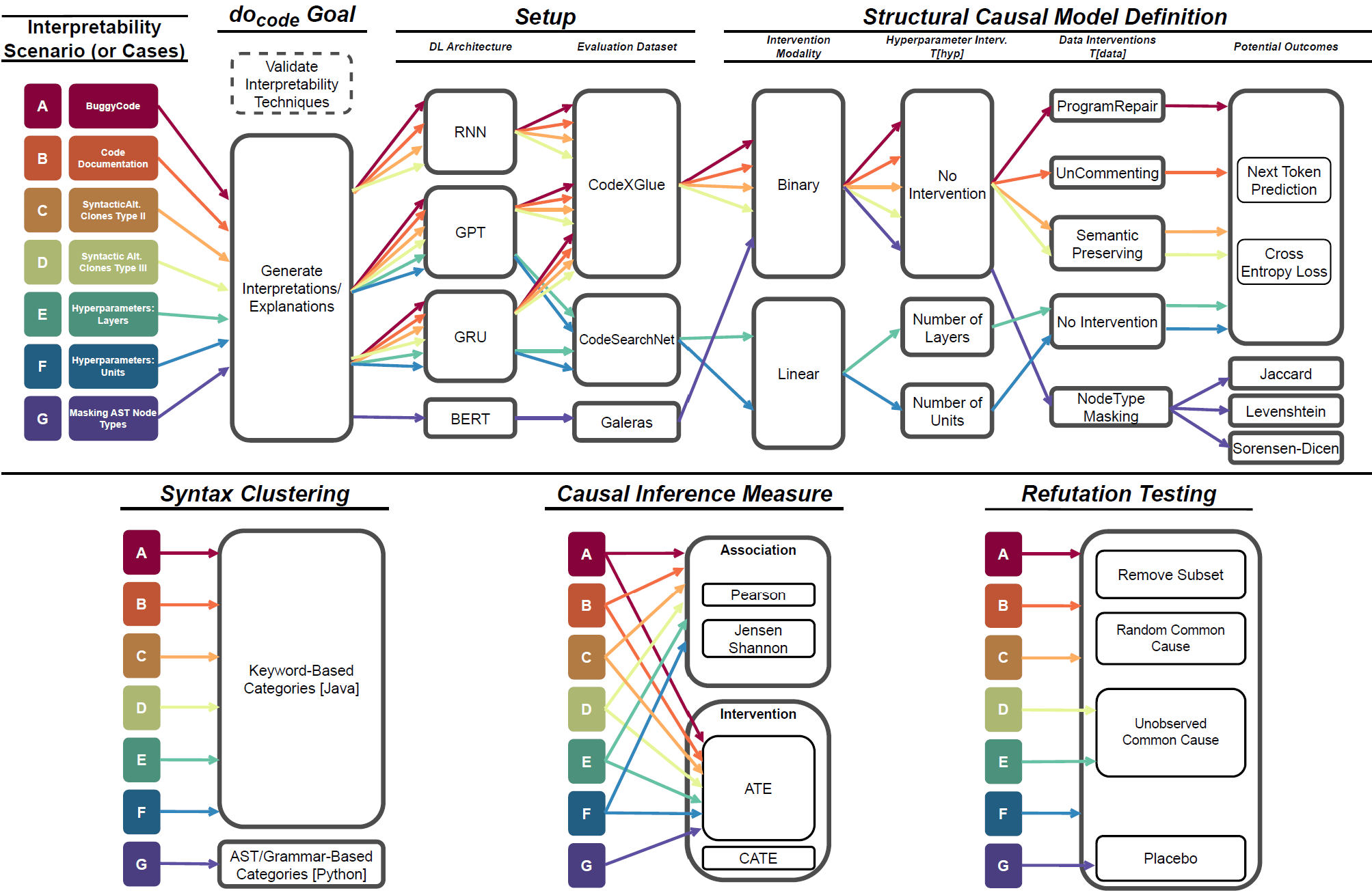
Seven permutations were proposed across causal dimensions,
but doCode allows for extending it
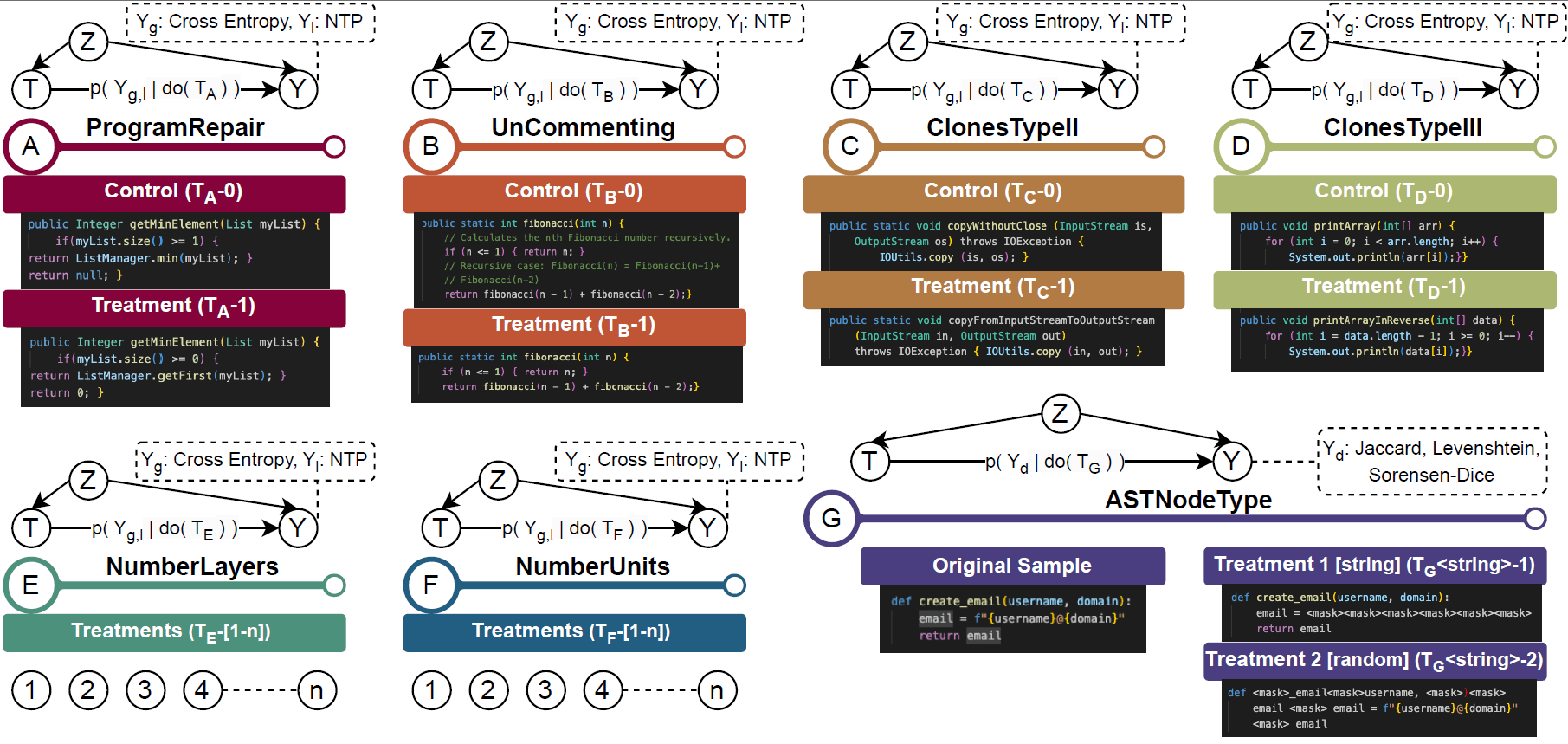
Tailored Directed Acyclic Graphs (DAGs) or Causal Graphs for each SE scenario
For this talk, I am focusing on:
- [case A] Data Intervention for BuggyCode
[case A]:
To what extent does a buggy sequence impact error learning or code prediction?
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
feasible correct snippet
codegen-mono-2b
count
=
count
+
count
=
+
-
=
+
0.6
0.4
0.01
0.01
0.4
0.6
0.01
0.01
0.5
0.4
0.01
0.01
0.05
0.04
0.01
0.8
def
...
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
feasible correct snippet
codegen-mono-2b
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count - 1
return count
feasible buggy snippet (line 5)
count
=
count
+
count
=
+
-
=
+
count
=
count
-
count
=
+
-
=
+
-
0.6
0.4
0.01
0.01
0.6
0.4
0.01
0.01
0.4
0.6
0.01
0.01
0.4
0.6
0.01
0.01
0.5
0.4
0.01
0.01
0.5
0.4
0.01
0.01
0.05
0.04
0.01
0.8
0.05
0.04
0.01
0.8
def
def
...
...
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
feasible correct snippet
codegen-mono-2b
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count - 1
return count
feasible buggy snippet (line 5)
=
count
+
-
0.4
0.6
0.01
0.01
0.5
0.4
0.01
0.01
0.05
0.04
0.01
0.8
0.05
0.04
0.01
0.8
correct snippet
buggy snippet
count
=
+
-
=
+
-
Treatment:
Bugs in Code
Potential Outcome:
Code Prediction
average causal effect ?
context
def
...
Assume a given correlation between T and Y
Treatment:
Bugs in Code
Potential Outcome:
Code Prediction
Corr = -0.8
Test data with buggy code is negatively affecting code predictions of syntax operators {'+','-'} by 80%
Causal Explanation for the generated code
What if the relationship between the treatment and the outcome is spurious*?
*Other factors affecting the relationship (confounding bias)
The relationship between T and Y can be confounded by a third variable Z
Treatment:
Bugs in Code
Potential Outcome:
Code Prediction
Confounder:
Sequence Size
causal effect = ?
Causal Inference helps us to control for confounding bias using graphical methods
After sequence size control, test data with buggy code is negatively affecting code predictions of syntax operators {'+','-'} by 40%
Causal Explanation for the generated code:
Treatment:
Bugs in Code
Potential Outcome:
Code Prediction
Confounder:
Sequence Size
causal effect = -0.4
Experiment Setup for BuggyCode
autoregressive
extract interpretability features
feasible snippets
output logits
causal explanations
Structural Causal Model (SCM)
To what extent does a (test) buggy sequence impact error learning or code prediction?
RNNs
GRUs
GPT2
Neural Code Models
Testbed: BuggyTB (Tufano, et al., 2019)
Training : CodeSearch Net
Level 1: Association Results
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
To what extent does a (test) buggy sequence impact error learning or code prediction?
Research Question
Level 1: Association
RNNs
GRUs
GPT2
0.730
0.230
0.670
Neural Code Model
Level 2: Intervention Results
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
To what extent does a (test) buggy sequence impact error learning or code prediction?
Research Question
Level 1: Association
RNNs
GRUs
GPT2
0.730
0.230
0.670
Neural Code Model
Level 2: Intervention
-3.0e-4
-2.3e-5
-2.0e-4
Null Causal Effects after controlling for confounders
[case A] Takeaway:
Causal Explanation:
The presence or absence of buggy code (in the test set) does not appear to causally influence (or explain) the prediction performance of NCMs even under high correlation.

A summary of the most relevant implications and findings for SE practitioners
No strong evidence that buggy code, comments, or syntax changes in the context window influence/cause NCMs' performance
Information Content in the prompt affects (positively and negatively) code predictions
BERT-like NCMs do not entirely capture the node's information of Abstract Syntax Trees (ASTs)
[special] Prompt Engineering
[cases A, B, C, and D]
[case E and F]
[case G]
No strong evidence that minimal increments in the #layers or #units influence/cause NCMs' performance
Consolidation
Part I: Who benefits from Causal Interpretability?
doCode can provide a more transparent, robust, and explainable approach to DL4SE, allowing for a better understanding of the decision-making process of the model and facilitating more effective detection of confounding bias
Software Researchers
- Introducing rigorous and formal methods to understand, explain, and evaluate NCMs (Palacio, et al., 2023).
- Promoting the use of Causal Inference as a complementary framework for Empirical SE studies, e.g., "the why-type questions" (Palacio, et al., 2025).
Practitioners from Industry
- Providing recourse to practitioners who are negatively affected by predictions, e.g., NCMs generating buggy code without affecting accuracy (Palacio, et al., 2023; Rodriguez-Cardenas, et al. 2023).
- Vetting models to determine if they are suitable for deployment, e.g., different interpretability scenarios (Palacio, et al., 2023).
- Assessing if and when to trust model predictions by detecting confounding bias (Velasco, et al., 2023; Khati, et al., 2025).
Causal Interpretability must be conducted as
a separate stage in the ML pipeline
Consolidation
Part II: Challenges and Limitations
Some challenges practitioners might face when adapting doCode to their interpretability analyses
Proposing new syntax decomposition functions
Collecting data for formulating SE-based interventions
Integrating doCode in DL4SE life-cycle
Causal Discovery: Creating Structural Causal Graph
Criticism From Philosophy of Science to Pearl's do-calculous
Interventions are not always cleanly separable from other factors
(Cartwright 1989,1999,2007)
Interventions must be understood mechanistically
(Bunge 1959,2003,2011)
Causal Graphs are oversimplifications that ignore real-world complexities
(Cartwright 1989,1999,2007)
Causal Graphs lack deterministic physical mechanisms
(Bunge 1959,2003,2011)
Consolidation
Part III: Future Remarks
The intersection between Causal Inference and Software Engineering is beyond interpretability aspects. It is a whole new science that must be employed to enhance software data analyses (to reduce confounding bias) and causal discovery (to elaborate explanations)
Causal Software Engineering

Consolidation
Part IV: Contributions and Derivative Work
1. Code Generation and Representation
2. Guidelines and Trustworthiness for DL4SE
3. Interpretability and Evaluation of AI Code Models
2019 | 2020
2025
2021 | 2022
2023 | 2024
1. Code Generation and Representation
2019 | 2020
2025
[technique] CNNs for Code Traceability (ICSME'19)
[technique] COMET Bayesian Representation (ICSE'20)
2021 | 2022
2023 | 2024
[Method] NeuroSymbolic Rules (ICPC'25)
1. Code Generation and Representation
2019 | 2020
2025
[technique] CNNs for Code Traceability (ICSME'19)
[technique] COMET Bayesian Representation (ICSE'20)
[Survey] Use of DL in SE (TOSEM'21)
[Survey] ML Practices in SE Research (TOSEM'24)
2021 | 2022
2023 | 2024
[Method] NeuroSymbolic Rules (ICPC'25)
[Survey] Trust and Trustworthiness in LLMs for Code (TOSEM'25)
2. Guidelines and Trustworthiness for DL4SE
1. Code Generation and Representation
3. Interpretability and Evaluation of AI Code Models
2019 | 2020
2025
[technique] CNNs for Code Traceability (ICSME'19)
[technique] COMET Bayesian Representation (ICSE'20)
[Survey] Use of DL in SE (TOSEM'21)
[Survey] ML Practices in SE Research (TOSEM'24)
[Patent] Debugging Tool Rationales (Microsoft'22)
[Method/Methodology] Theory of Causality for DL4SE Interpretability (TSE'23, ICSE'25)
[Empirical SE] Syntactic Capabilities Learned by LLMs (ICSE'23)
[Benchmarking] Strategy to collect Causal SE Info. (ICSME'23)
[Empirical SE] Eval and Explaning LLMs for Code (ArXiv'24)
2021 | 2022
2023 | 2024
[Framework] Causal SE (TOSEM'25)
[Method] Code Rationales (ArXiv'22, TOSEM'25)
[Method] TraceXplaner Info. Sciencie (ArXiv'20, ArXiv'25)
[Method] NeuroSymbolic Rules (ICPC'25)
[Survey] Trust and Trustworthiness in LLMs for Code (TOSEM'25)
[Metric] Propensity Code Smells (ICSE'25)
2. Guidelines and Trustworthiness for DL4SE
1. Code Generation and Representation
3. Interpretability and Evaluation of AI Code Models
2019 | 2020
2025
[technique] CNNs for Code Traceability (ICSME'19)
[technique] COMET Bayesian Representation (ICSE'20)
[Survey] Use of DL in SE (TOSEM'21)
[Survey] ML Practices in SE Research (TOSEM'24)
[Patent] Debugging Tool Rationales (Microsoft'22)
[Method/Methodology] Theory of Causality for DL4SE Interpretability (TSE'23, ICSE'25)
[Empirical SE] Syntactic Capabilities Learned by LLMs (ICSE'23)
[Benchmarking] Strategy to collect Causal SE Info. (ICSME'23)
[Empirical SE] Eval and Explaning LLMs for Code (ArXiv'24)
2021 | 2022
2023 | 2024
[Framework] Causal SE (TOSEM'25)
[Method] Code Rationales (ArXiv'22, TOSEM'25)
[Method] TraceXplaner Info. Sciencie (ArXiv'20, ArXiv'25)
[Method] NeuroSymbolic Rules (ICPC'25)
[Survey] Trust and Trustworthiness in LLMs for Code (TOSEM'25)
[Metric] Propensity Code Smells (ICSE'25)
2. Guidelines and Trustworthiness for DL4SE
Acknowledgments
[Agradecimientos]

Mom & Friends
Gracias!
[Thank you]
Appendix
Traditional Interpretability
-
Inherently interpretable models:
- Decision Trees
- Rule-based models
- Linear Regression
- Attention Networks
- Disentangled Representations
-
Post Hoc Explanations:
- SHAP
- Local Interpretable Model-Agnostic Explanations (LIME)
- Saliency Maps
- Example-based Explanations
- Feature Visualization
Causal Interpretability
Approaches that follow Pearl's Ladder
- Average Causal Effect of the neuron on the output (Chattopadhyay et, al., 2019)
- Causal Graphs from Partial Dependence Plots (Zhao & Hastie, 2019)
- DNN as an SCM (Narendra et al., 2018)
[case C] Syntax Decomposition on Encoder-Only experiment setup.
autoregressive
extract interpretability features
code completion logits
feasible completions
causal explanations
method 3
Structural Causal Model (SCM)
How good are MLMs at predicting AST nodes?
CodeBERT
Neural Code Models
Testbed: GALERAS

[case C] Structural Causal Graph proposed (graph hypothesis)
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
GALERAS
Token Prediction
Static Tools
Research Question
How good are MLMs at predicting AST nodes?
Structural Causal Model
Control
AST Node Types
[case C] Results
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
Research Question
How good are MLMs at predicting AST nodes?
Structural Causal Model

Local Jaccard
[case C] Syntax Decomposition Encoder-Only
Takeaway or Causal Explanation:
CodeBERT tent to complete missing AST-masked tokens with acceptable probability (>0.5). However, the reported performance suffers from high variability (+- 0.21) making the prediction process less confident compared to completing randomly masking tokens.

Source File
Requirement File
Test File
Test File
Do we use Inference or Prediction to compute θ?
Model understanding is critical in high-stakes domains such as code generation since AI systems can impact the lives of millions of individuals (e.g, health care, criminal justice)
interpretable pretrained model
Facilitating debugging and detecting bias
Providing recourse to practitioners who are negatively affected by predictions
Assessing if and when to trust model predictions when making decisions
Vetting models to determine if they are suitable for deployment in real scenarios
What is Interpretability?
"It is a research field that makes ML systems and their decision-making process understandable to humans" (Doshi-Velez & Kim, 2017)
1. Appendix Preliminaries
Generative Software Engineering
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
observational data
Statistical Learning Process by Induction: empirical risk minimization or minimizing training error
target function
human-generated data are collected
first approximation
learning process is iterative
second approximation
observational data (ie., large general training set)
code generation has been mainly addressed using self-supervised approaches
Extracted Labels
extract, make
Neural Code Model
Pretrained Model
Self-Supervised Pretraining
Pretext Task
observational data (ie., large general training set)
code generation has been mainly addressed using self-supervised approaches
Extracted Labels
extract, make
Neural Code Model
Pretrained Model
Self-Supervised Pretraining
target specific dataset
Labels
Pretrained Model
Final Model
Finetuning on target dataset
Transfer Learning
Pretext Task
Downstream Task
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
observational data
Autoregressive
def
count
Chars
count =
?
Code generation uses self-prediction (a self-supervised strategy):
autoregressive or masking (i.e., hiding parts of inputs)
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
observational data
Code generation uses self-prediction (a self-supervised strategy):
autoregressive or masking (i.e., hiding parts of inputs)
Autoregressive
Masking
def count[mask](string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
[masked]
def
count
Chars
count =
?
def
count
[mask]
(string
count
Neural Architectures
Autoregressive
Masking
NCMs: GPT, RNNs
NCMs: BART, BERT
Some examples of generative software engineering
Automatic Bug Fixing
(Tufano, et al, TOSEM'19)
Learning Code Changes (Tufano, et al, ICSE'19)
Assert Statements Generation (Watson, et al, ICSE'20)
Clone Detection (White, et al, ASE'16)
Learning to Identify Security Requirements (Palacio, et al, ICSME'19)
What is an explanation?
An explanation describes the model behavior and should be faithful and understandable.
Explanation
Complex Model
Practitioners

faithful (or aligned)
understandable
Model Parameters (e.g, coefficients, weights, attention layers)
Examples of predictions (e.g., generated code, snippet, bug fix)
Most important features or data points
Counterfactual Explanations / Causal Explanations
An explanation can have different scopes: local and global
Explanation
Global
Local
Explain overall behavior
Help to detect biases at a high level
Help vet if the model is suitable for deployment
Explain specific domain samples
Help to detect biases in the local neighborhood
Help vet if individual samples are being generated for the right reasons
Instance
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count

sample
One data-point
David Hume [1775]: We are limited to observations. The only thing we experience is that some events are conjoined.
Aristotle [322 a.C]: Why-type questions is the essence of scientific explanations.
[1747 James Lind - Early 20th century Neyman and Fisher]
The idea of Interventions:
Babies and Experimentation
Conditioning Learning
Association
The holy grail of the scientific method: Randomized Controlled Trials (RCT)



Judea Pearl [21st Century]: A causal link exists in two variables if a change in A can also be detected in B.
Experiments are not always available. To draw a causal conclusion, data itself is insufficient; we also need a Causal Model.
Bunge & Cartwright [Later 20th Century]
-
Both reject Humean causation (which sees causality as just a regular sequence of events);
-
Both emphasize mechanisms over statistical correlations in determining causal relationships.
2. Appendix Associational Interpretability
When correlations are useful
The taxonomy of traditional interpretability methods
Interpretablity
Intrinsic:
Self-explaining AI
Bottom-Up:
Mechanistic
Top-Down:
Concept-Based
Post-Hoc
- [Association] Method 1: TraceXplainer
- [Association] Method 2: Code Rationales
Rung 1
Association
(correlation)

Method 2: Code Rationales
Rationalizing Language Models contributes to understanding code predictions by searching a set of concepts that best interpret the relationships between input and output tokens.
complex model
autoregressive
extract interpretability features
compatible model
prompts
Code Rationales
Set of Rationales (or important F)
method 2
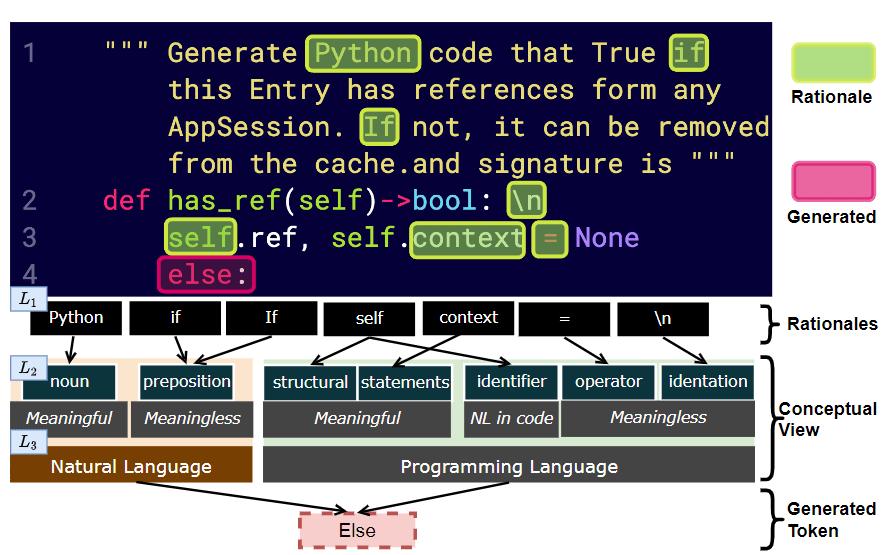
Rationalization is finding a group of tokens that best predict the next token using syntax (de)composition

How can we evaluate (autoregressive) code generation?
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
unconditioned
def countChars(string, character):
count = 0
for letter in string:
if letter = character:
count = count + 1
return count
conditioned
prompt
completed
pretrained model
generated snippet
unconditioned sampling
pretrained model
Code Feaseability
Aggregated Metrics
Accuracy
Perplexity
CodeBLEU
Semantic Distance
sampling
Rationales Dependency Map
structural
statements
Semantic
else
self
context
\n
Natural Language in Code
identifier
Non-Semantic
operator
=
Programming Language
Natural Language
Python
noun
Semantic
Non-Semantic
preposition
If
if
"""Generate Python code that True if this Entry has references from any AppSession.
If not, it can be removed from the cache.and signature is"""
def has_refs(self) -> bool: [\n]
self.ref, self.context = None
else:Prompt 1
module
statements
function
string
identifier
parameters
identifier
type
identifier
block
statements
assignments
pattern_list
identifier
Concept View
Syntax Code Concepts
Generated Token
FindLongestConsecutiveSequence {
public int findRecursive(int[] array) {
validateInput(array);
return findRecursiveInner(array, 1, 0, 0);
}
FindLongestConsecutiveSequence();
int findIterative(int[] numbers);
int findRecursive(int[] array);
public float sequence;
}Focal Method
Class
Constructor
Method Signatures
Fields
Rationales
AST-Based
Context Window
Dependency Map of Rationales
types
exceptions
asserts
conditionals
oop
else
if
default
Semantic
[ if ]
Concept View
Rationales
Generated Token
float
char
int
class
private
instanceof
try
catch
assert
Natural Language in Code
identifier
string
var_1
'sql comment'
Non-Semantic
indentation
\t
punctuation
,
Programming Language
Natural Language
run
test
verb
Semantic
Non-Semantic
determiner
the
a
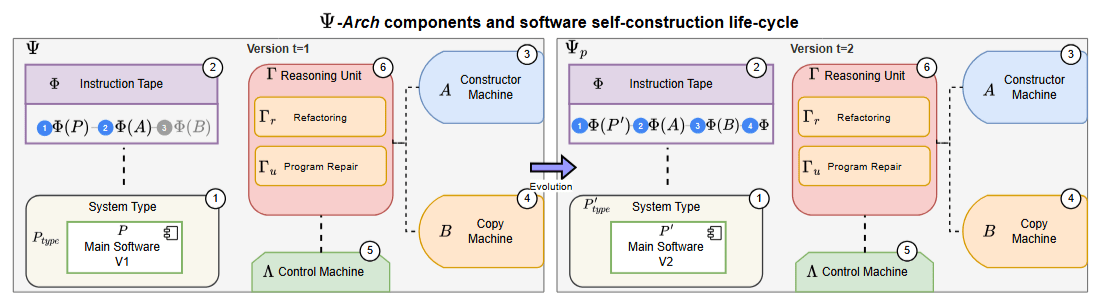
Instead of developing counterfactual interpretability, we envision an autopoietic architecture to enable self-construction of software
Maturana & Varela (1973) + Von Neumann Self-Replication (1966)
Contributions Roadmap
Learning to Identify Security Requirements (ICSME'19)
Improving the Effectiveness of Traceability Link Recovery using Bayesian Networks (ICSE'20)
Systematic Review on the use of Deep Learning in SE Research (TOSEM'21)
No Intepretable
Neural Code Models
Observation: Code vs NL modality
Software Artifacts and their relationships can be represented with stocastic variables
Observation: Code vs NL modality
Learning to Identify Security Requirements (ICSME'19)
Improving the Effectiveness of Traceability Link Recovery using Bayesian Networks (ICSE'20)
Systematic Review on the use of Deep Learning in SE Research (TOSEM'21)
Toward a Theory of Causation for Interpreting Neural Code Models (TSE'23; ICSE25)
No Intepretable
Neural Code Models
Observation: Code vs NL modality
Software Artifacts and their relationships can be represented with stocastic variables
Contributions Roadmap
Learning to Identify Security Requirements (ICSME'19)
Improving the Effectiveness of Traceability Link Recovery using Bayesian Networks (ICSE'20)
Systematic Review on the use of Deep Learning in SE Research (TOSEM'21)
Debugging Tool for Code Generation Naural Language Models (Patent'22)
Toward a Theory of Causation for Interpreting Neural Code Models (TSE'23; ; ICSE25)
No Intepretable
Neural Code Models
Observation: Code vs NL modality
Software Artifacts and their relationships can be represented with stocastic variables
Feature Importance Technique: Code Rationales
Evaluating and Explaining Large Language Models for Code Using Syntactic Structures (Preprint'24)
A formalism for Syntax Decomposition
Which Syntactic Capabilities Are Statistically Learned by Masked Language Models for Code? (ICSE'23)
Benchmarking Causal Study to Interpret Large Language Models for Source Code (ICSME'23)
CodeBert Negative Results (not learning syntax)
Prompt Engineering Evaluation
Conjecture:
Software Information exhibits causal properties
Contributions Roadmap
Learning to Identify Security Requirements (ICSME'19)
Improving the Effectiveness of Traceability Link Recovery using Bayesian Networks (ICSE'20)
Systematic Review on the use of Deep Learning in SE Research (TOSEM'21)
Debugging Tool for Code Generation Naural Language Models (Patent'22)
Toward a Theory of Causation for Interpreting Neural Code Models (TSE'23)
No Intepretable
Neural Code Models
Observation: Code vs NL modality
Software Artifacts and their relationships can be represented with stocastic variables
Feature Importance Technique: Code Rationales
Evaluating and Explaining Large Language Models for Code Using Syntactic Structures (Preprint'24)
A formalism for Syntax Decomposition
Which Syntactic Capabilities Are Statistically Learned by Masked Language Models for Code? (ICSE'23)
Benchmarking Causal Study to Interpret Large Language Models for Source Code (ICSME'23)
CodeBert Negative Results (not learning syntax)
Prompt Engineering Evaluation
Software Agents
Contributions Roadmap
Causal Software Eng.
Fourth Component
Prospective Analysis: Autopoietic Arch.
What about counterfactual interpretability?
The Fundamental Problem of Causal Inference (Holland, 1986)
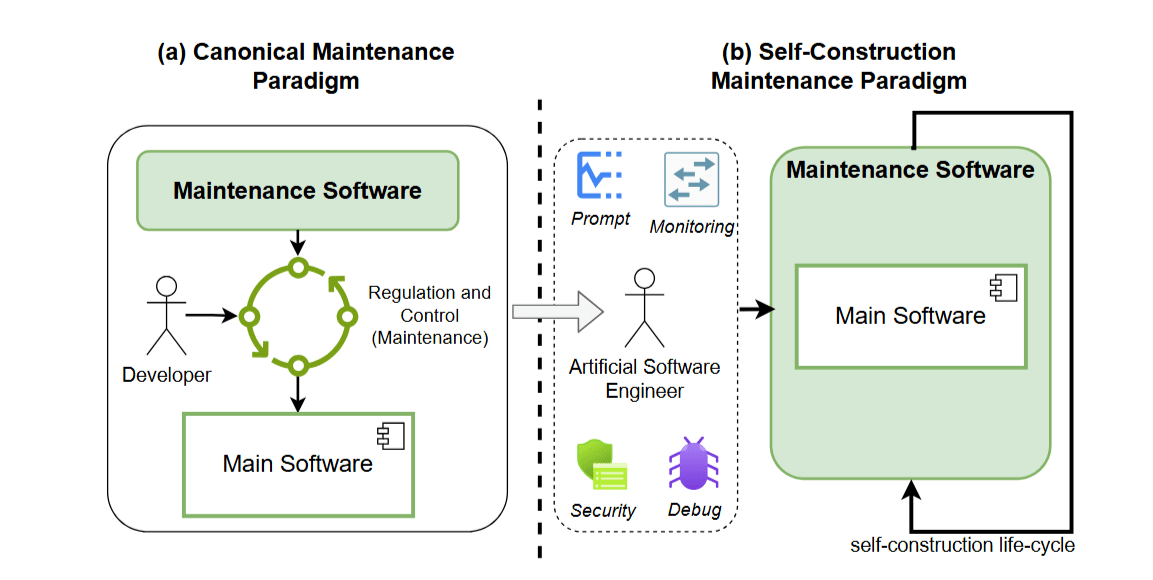
Maintenance Paradigm Shift: a) Software Maintenance (SM) is independent from the main software, and b) SM wraps the main software
Maturana & Varela (1973) + Von Neumann Self-Replication (1966)
Instead of developing counterfactual interpretability, we envision an autopoietic architecture to enable self-construction of software
Artificially Engineering
Software Systems
Code Generator
Causal Reasoning
Unit
self-replication
Evolved Agent
Replication Unit
Perception Unit
Controller
Requirement Generator
Causal Reasoning
Unit
Replication Unit
Perception Unit
Controller
SE Agents or Autopoietic Arch
software information: req
causal queries

Prediction
Inference
Use the model to predict the outcomes for new data points
Use the model to learn about the data generation process
Prediction
Statistical Inference Methods:
- Probabilistic Inference or Bayesian Inference
- Causal Inference
Inference
Learning Process:
- Machine Learning
- Deep Learning
The causal effect can be represented as a conditional probability (Level 1: Association)
treatments
potential outcomes
confounders
causal effect
Observational Distribution
BuggyCode Example
The observational distribution does not represent an intervention. We now want to set the variable T to FixedCode using the do-operator (Level 2: Intevention)
causal effect
Interventional Distribution
Adjustment Formula
potential outcomes
confounders
treatments
FixedCode
Assumptions encoded in causal graphs are supported by observations of a data-generating process. Testing for the quality of the causal graph fitting the data would be the main issue.
Refuting Effect Estimate
Vetting graph creation
treatments
potential outcomes
confounders
How can we falsify graph-encoded assumptions?
Refuting Effect Estimates
Add Unobserved Common Cause
treatments
potential outcomes
confounders
Unobserved Cause
should be the same quantity
Add Random Common Cause
Placebo Treatments
From Philosophy of Science Perspective
| Aspect | Pearl (2000, 2009, 2018) | Cartwright (1989, 1999, 2007) | Bunge (1959, 2003, 2011) |
|---|---|---|---|
| Causal Representation | Uses DAGs and do-calculus to model causality. | Emphasizes capacities and context-dependent causality. | Focuses on real-world systems and deterministic causality. |
| Intervention-Based Causality | Formalized through do(X) operator. | Interventions are not always cleanly separable from other factors. | Interventions must be understood mechanistically. |
| Criticism of Do-Calculus | Claims causality can be inferred from graphs. | Argues DAGs are oversimplifications that ignore real-world complexities. | DAGs lack deterministic physical mechanisms. |
| Application to AI | Used in machine learning, fairness, healthcare AI. | Suggests AI must be context-sensitive and adaptable. | AI should incorporate multi-layered causal structures. |
Some general recommendations were carried out before proposing the statistical control
(Becker et al., 2016)
doCode does not control for undocumented confounders
doCode uses conceptually meaningful control variables
doCode conducts exploratory and comparative analysis to test the relationship between independent and control variables
[special] Prompt Intervention experiment setup.
autoregressive
extract interpretability features
code completion
distance metrics
causal explanations
method 3
Structural Causal Model (SCM)
To what extent does the type of prompt engineering influence the code completion performance?
ChatGPT
Neural Code Models
Testbed: GALERAS
[special] Structural Causal Graph proposed (graph hypothesis)
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
GALERAS
Distance Metric
Static Tools
Research Question
To what extent does the type of prompt engineering influence the code completion performance?
# Complete the following python method: ```{code}``` # Write a Python method that starts with ```{code}``` , I need to complete this function. Remove comments, summary and descriptions.# Remember you have a Python function named {signature}, the function starts with the following code {code}. The description for the function is: {docstring} remove comments; remove summary; remove description; Return only the code
Structural Causal Model
Control
More Context
Multiple Interactions
[special] Accuracy Results
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
Research Question
Structural Causal Model
Control
More Context
Multiple Interactions
Levenshtein
CodeBLEU
Not much variability
To what extent does the type of prompt engineering influence the code completion performance?
[special] Causal Effects Results
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
Research Question
Structural Causal Model
Control
More Context
Multiple Interactions
Levenshtein
CodeBLEU
Treatment 1 Effect
Treatment 2 Effect
To what extent does the type of prompt engineering influence the code completion performance?
[special] Takeaway:
Causal Explanation:
Elemental context descriptions in the prompt have a negative causal effect on the output with an ATE of -5%. Conversely, prompts with docstrings and signatures have a positive impact on the performance (ATE of 3%)

Example of Results 1: Partitioning of manifold space into syntax-based concepts
Scope Concepts are related to termination keywords of the language: '{', '}', 'return'
Acceptable Prediction
A mathematical language is required to formulate causal queries for code generation
To what extent does a (test) buggy sequence impact error learning or code prediction?
If we remove bugs from training code data T, will the model generate accurate code predictions Y?
Structural Causal Graph proposed (graph hypothesis)
treatments
potential outcomes
confounders
causal effect
Structural Causal Model
BuggyTB
Model Outputs
Static Tools
To what extent does a (test) buggy sequence impact error learning or code prediction?
Research Question
treatment effect of a snippet i
outcome for snippet i when they recived treatment [T=Fixed]
outcome for the same snippet i when they did not recived treatment [T=Buggy]