Python爬蟲分享
By 泰瑋
目錄
-
基礎爬蟲
- 資工系的各種職業
- 動機
- Python安裝
- get、post介紹
- 抓圖片
- 剖析網頁(bs4)
- 進度條
- 命令列
- 最後組裝
- 參考資料
Text
學物理幹嘛?

電學、電子電路學
倒是有一點關聯

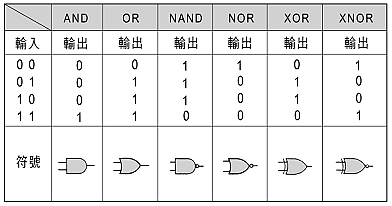
邏輯設計
接電路

電機類、偏硬體的工作

古人用0101來寫程式
於是發明了組合語言

系統越來越完備
程式語言就會越來越簡單

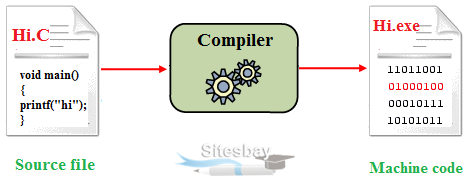
所以要學編譯器
compiler
編譯器的始祖
就是正規語言的作者

想當駭客?
組語、作業系統、編譯器要學好

我想像中的同學

這是我的室友

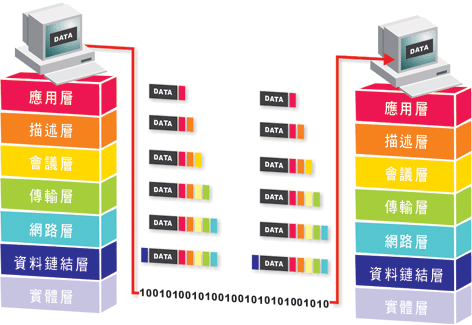
網路
未來工作:網管

中興大學的網管:
網路跟作業系統關係很緊密

資料庫
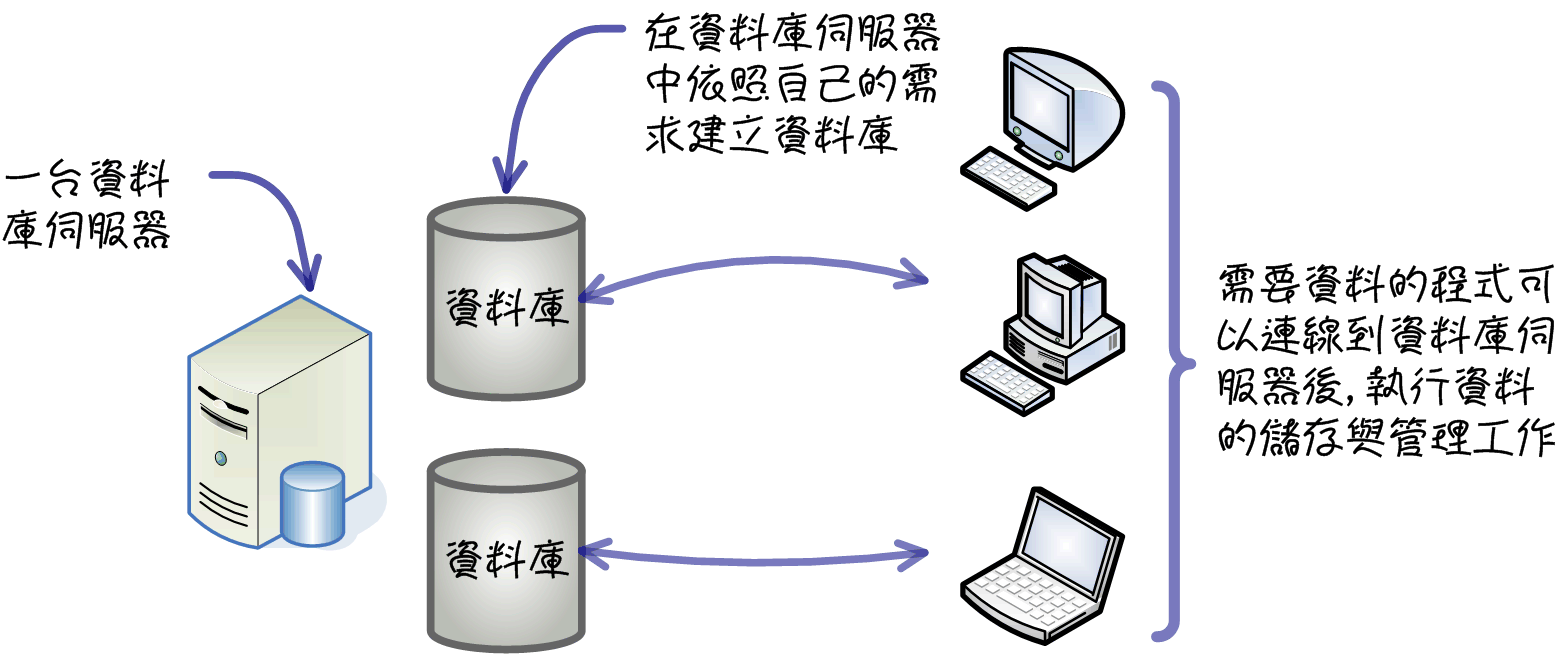
就跟excel沒兩樣
race condition 競爭危害

money = 1000
money = 1000 + 800 = 1800
money = 1000
money = 1000 - 500 = 500
race condition 競爭危害

race condition 競爭危害
資料庫工程師
應用程式開發

資料探勘(Data Mining)

機器學習

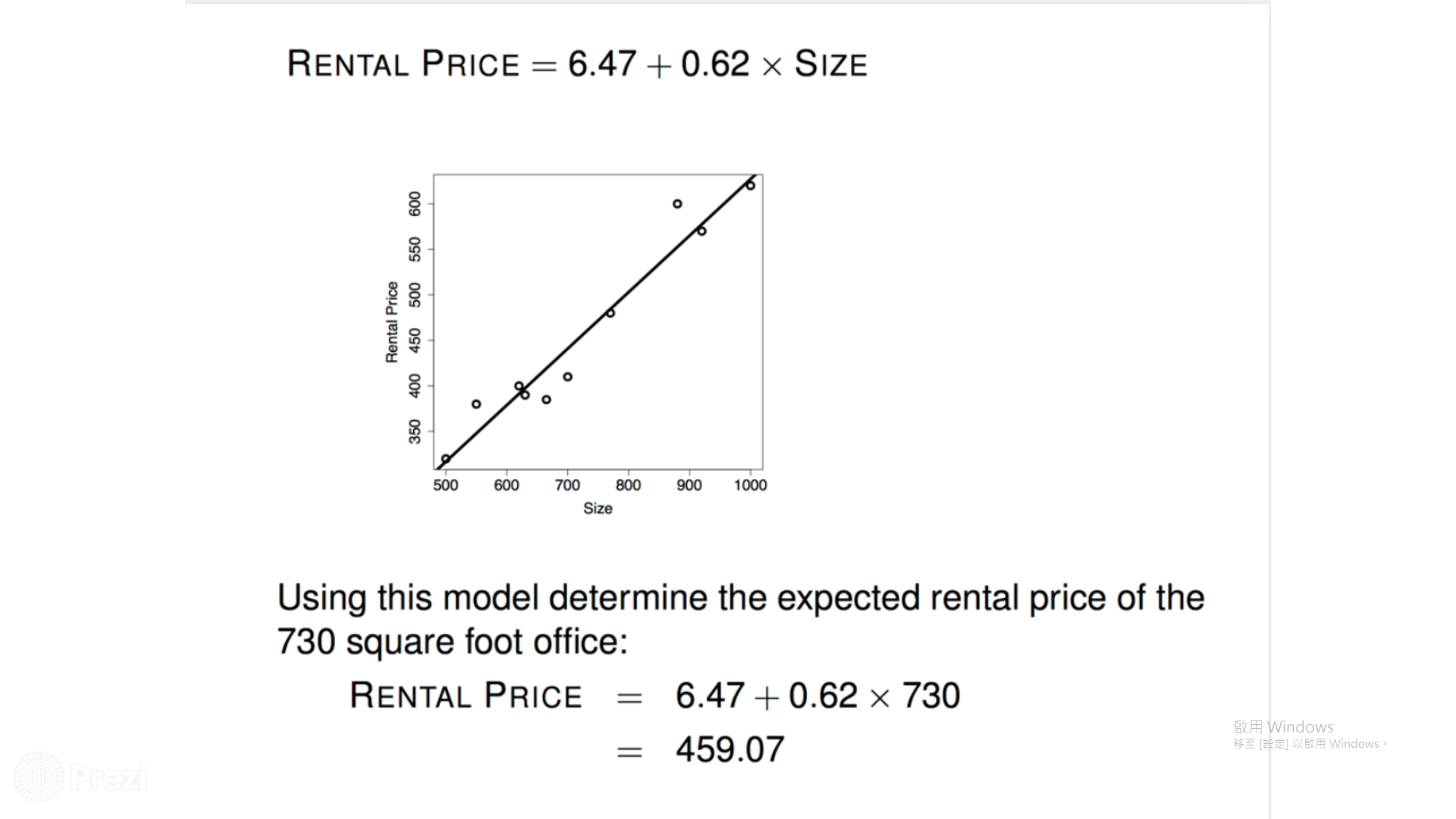
目標:用一條線性方程式預測房價
學習初始狀態:?x+?=y
訓練過程中,會跟你說正確答案是什麼,而且你的答案與正解差多少
預測房價

讓機器從中學習
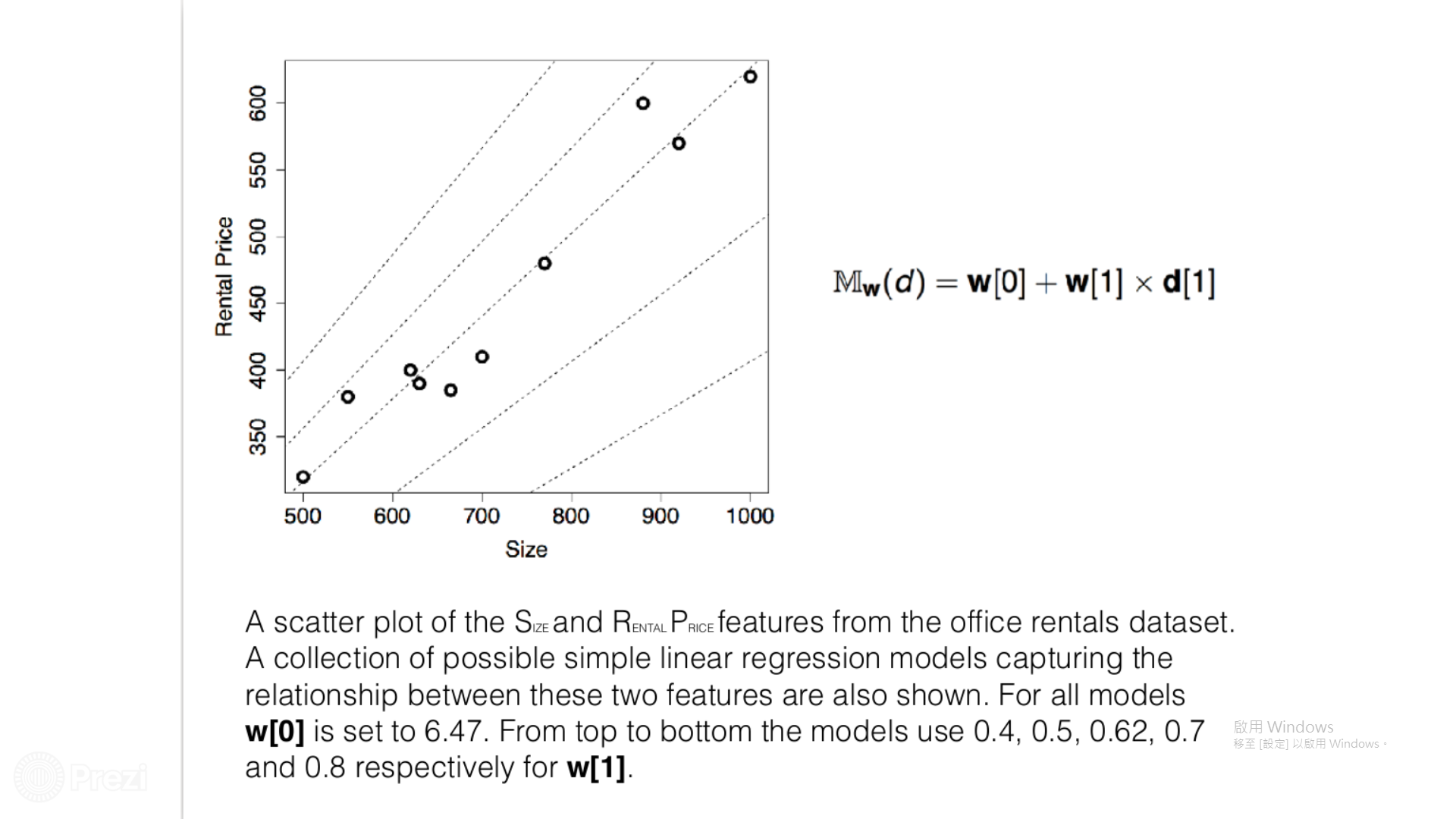
找到最好的線
找最佳解
你需要會
- 微積分
- 線性代數
- 演算法
- 資料結構
回來講資料探勘
機器學習:找出一個誤差盡可能小的解
資料探勘:找出一組進可能有趣的解

今天的主角:爬蟲

講者介紹

基礎爬蟲
動機
為什麼需要爬蟲?
學長姐的專題


安裝:
- 動態語言 (可以不用宣告形態)
- 常用於科學運算、資料分析
Python:最熱門大數據相關語言
觀察歷年趨勢,大數據相關語言成長幅度明顯,其中包含Julia、Python、R和Scala等,皆提供許多能快速分析大量資料的工具。
市場對Python和Java相關工作需求量大
目前,市場對Python和Java的工作需求仍最大,Python的工作需求約為R語言的15倍。IEEE分析,R語言是視覺化和探索性分析的熱門工具,受到學術研究的歡迎,然而Python整合至數據生產工具中更為容易,且用途也較廣,因此對使用者而言,使用Python在開發環境中更有優勢。
有誰在用Python ?
- DropBox
- NASA
- 還有我 XD
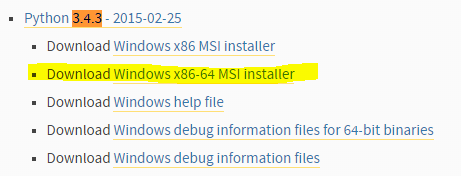
選第二個選項 : entire feature wil be XXX
要去勾喔 勾完X就會不見!!!
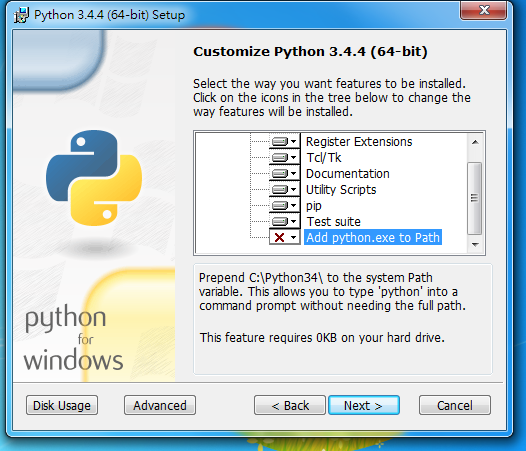
其他的都無腦安裝
這樣可以幹嘛?
把Python加到環境變數裡面
就可以在cmd裡面打python把它的interpreter給叫出來
Interpreter的環境
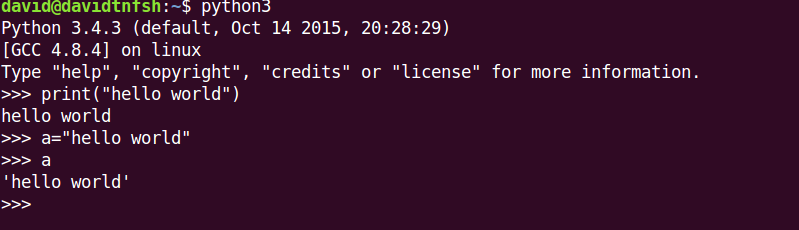
可以讓你key指令進去
遇到不懂的就打打看
如果怎麼用都失敗的話
or 用821的電腦
c:\python34\;C:\python34\Scripts;
# 注意喔 如果你裝的python版本不是3.4的話
# C曹的資料夾就是pythonXX
# 請自己變通 把下面這一行加到環境變數
e.q. 安裝requests這個套件
pip install requests
如果電腦裏面裝了python2跟3,這樣就是指定python3
pip3 install requestspip:python的套件管理工具
類似ubuntu的apt-get
行前須知:
pip install -r requirements.txt
facebook-sdk
requests
simplejson
pyprind
bs4在你放程式碼的資料夾底下新增requirements.txt 內容如下:
然後執行該指令(把需要的套件一次安裝完)
python demo.py
如果電腦裏面裝了python2跟3,這樣就是指定python3
python3 demo.py
執行
什麼時候要加3請自行變通喔XD
基礎功教學

# 就跟寫數學考卷一樣
x = 1
print(x)
y = 2*x + 3
print(y)
程式基礎
# 假設你很夯
toolMan = ['我是1號工具人', '我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
# 你想選擇哪個工具人?
toolMan[0] #=> 我是1號工具人
toolMan[1] #=> 我是2號好棒棒
陣列 就是資料的容器
# 假設你很夯
toolMan = ['1號工具人', '2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
# 不同情境需要不同工具人
scenario = '孤單寂寞覺得冷'
if scenario == '電腦壞掉':
print('需要' + toolMan[0])
elif scenario == '孤單寂寞覺得冷':
print(toolMan[1] + ' + ' + toolMan[2] + '兩個都想要')
else:
print(toolMan[4] + '陪我讀書')
條件判斷
# 假設你很夯
toolMan = ['我是1號工具人', '我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
# 召喚所有工具人
for i in toolMan:
print(i)
一個一個取好浪費時間...
for i in [1,2,3,4,5,6,7,8,9]:
tmp = ''
for j in [1,2,3,4,5,6,7,8,9]:
tmp += str(i*j) + ', '
print(tmp)99乘法表
import time
LoveYou = True
while LoveYou:
print('honey你好帥')
print('睡一下')
time.sleep(2)while
import time
LoveYou = True
count = 1
while LoveYou:
print('honey你好帥')
print('睡一下')
time.sleep(0.5)
count = count + 1
if count == 7:
print('我對你沒感覺了' )
breakwhile + if
count = count + 1奇怪的式子

count = 1
count = count + 1
# count = 1 + 1 = 2
count = 2
count = count + 1
# count = 2 + 1 = 3在程式的世界叫作指派
電腦都先看 = 的右邊
然後才執行到左邊
import time
LoveYou = True
count = 1
while LoveYou:
print('honey你好帥')
print('睡一下')
time.sleep(0.5)
count = count + 1
if count == 7:
print('我對你沒感覺了' )
breakwhile + if
for V.S. while
通常明確知道要跑幾次的任務 => for
不知道要跑幾次,直到符合條件才停止 => while
function -> 就是自定義的指令
# -*- coding: utf-8 -*-
import time
def girlfriend(c):
LoveYou = True
count = c
while LoveYou:
print('honey你好帥')
print('睡一下')
time.sleep(1)
count = count + 1
if count == 7:
print('我對你沒感覺了' )
break
girlfriend(5)練習1:召喚工具人
# 假設你很夯
toolMan = ['我是1號工具人', '我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
# 弄成這樣
我是1號工具人
我是2號好棒棒
3號小鮮肉
4號司機
5號書僮
6號外送員工具人也是要有自尊的

練習2:用過的工具人就不能再被用
# 假設你很夯
toolMan = ['我是1號工具人', '我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
# 弄成這樣
['我是1號工具人', '我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
['我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
['3號小鮮肉', '4號司機', '5號書僮', '6號外送員']
['4號司機', '5號書僮', '6號外送員']
['5號書僮', '6號外送員']
['6號外送員']
toolMan[1:] # ['我是2號好棒棒', '3號小鮮肉', '4號司機', '5號書僮', '6號外送員']練習3:印出一顆星星樹 + 使用function
獎金XXX元
*
**
***
****
*****
******
*******
********
FB 爬蟲

fb官方提供的graph api
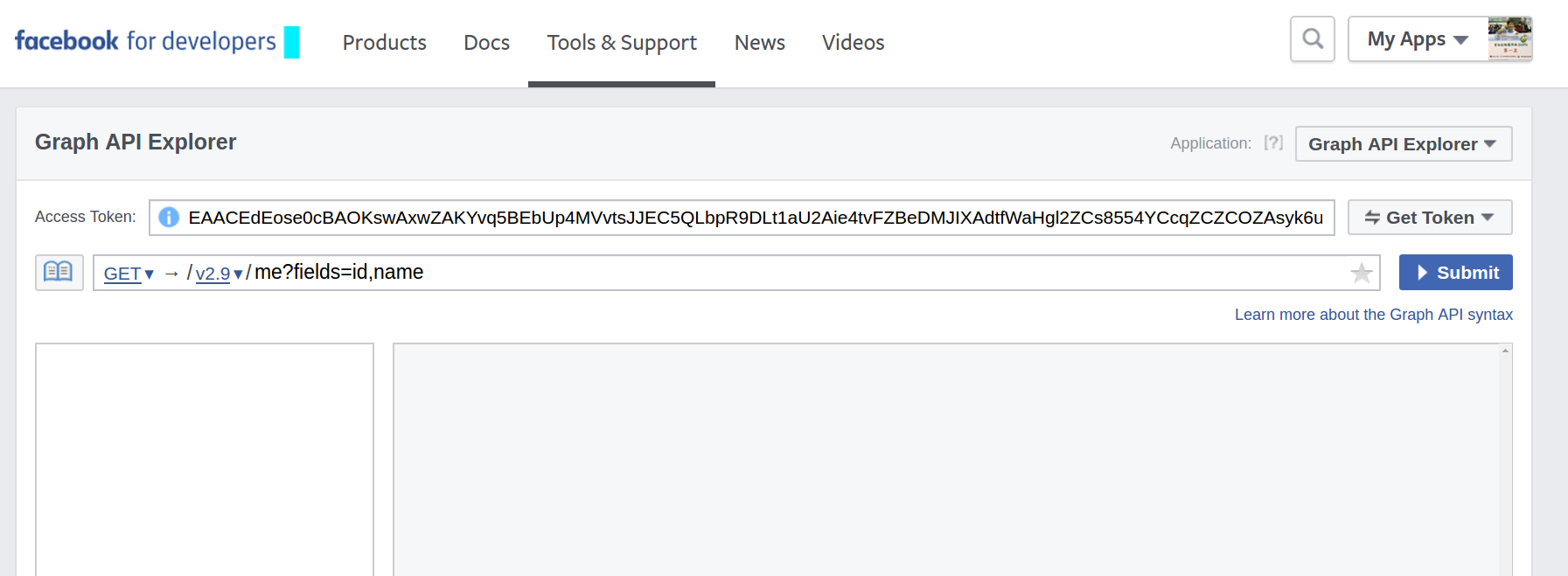
我們改用facebook-sdk(第3方套件)
pip install facebook-sdkText
Text
先去facebook graph api拿到access token
import facebook
# 透過access_token建立一個facebook api的物件
graph=facebook.GraphAPI(access_token='sdjfkwejkrjkjfksldjflkjfk', version='2.6')
# get_object() 取得粉專或自己的名稱
info = graph.get_object(粉專或自己的id)
# get_connections() 可以取得貼文、按讚、留言等資料
# 拿到粉專的貼文
posts = graph.get_connections(粉專或自己的id, 'posts')
# posts裏面也會有每篇文章的id
# 可以拿到按讚和回應
graph.get_connections(文章id, 'reactions')
graph.get_connections(文章id, 'comments')# 透過access_token建立一個facebook api的物件
graph=facebook.GraphAPI(access_token='sdjfkwejkrjkjfksldjflkjfk', version='2.6')
# get_object() 取得粉專或自己的名稱
info = graph.get_object(粉專或自己的id)
# get_connections() 可以取得貼文、按讚、留言等資料
# 拿到粉專的貼文
posts = graph.get_connections(粉專或自己的id, 'posts')
# posts裏面也會有每篇文章的id
# 可以拿到按讚和回應
graph.get_connections(文章id, 'reactions')
graph.get_connections(文章id, 'comments')with open('filename', 'r or w') as f:
f.write('要寫入的內容')
# 一旦離開縮排範圍,f這個檔案物件就會自動關檔
# f.close()就不用寫with 開關檔
json 讀寫檔
# 讀取json檔案
f = open('xxx.json', 'r')
xxx = json.load(f)
# 匯出json檔
f = open('xxx.json', 'w')
data = [123, 2354, 45, 2435, 324]
json.dump(data, f)#coding=UTF-8
import facebook, json
token='EAACEdEose0cBAJ4k8OC3WQblAb0LjdGNby5JxY4LHgZCm0SJLunElknjfZB5n9Ae2SzayvOKlskUZBPbwi045nEVR8wg50SmpaW4TuzEk7ZBlthwasZBmYfJALRqLBQpXlUO3RFJwwtajRfhnaOkNqxAyMGA78KRNYbYi5CZCELN7E3usLaeOZCaWl7lv2vJEcZD'
#token為access token
graph=facebook.GraphAPI(access_token=token, version='2.6')
#i為要所需的FB頁面之id
def crawl(i):
info = graph.get_object(i)
print(info)
posts = graph.get_connections(i, 'posts')
for p in posts['data']:
p['reactions'] = graph.get_connections(p['id'], 'reactions')
p['comments'] = graph.get_connections(p['id'], 'comments')
with open('facebook.json', 'w') as f:
json.dump(posts, f)
crawl('1623149734611090') # 選課小幫手的粉專facebook 爬蟲
:Get 跟 Post
必備技能1
import requests需要用到requests這個函式庫
Get

GET程式demo
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Morbi nec metus justo. Aliquam erat volutpat.
import requests
re = requests.get("http://www.gomaji.com/Changhua")
# 裏面可以放任意的網址
print(re.text)
# 這樣就可以看到該網頁的html>>> re.text
'<!DOCTYPE html>\n<html lang="en">\n<head>\n <meta charset="UTF-8">
\n <title>Chinese Search</title>\n <meta name="viewport" content="width=792,
user-scalable=no">\n <meta http-equiv="x-ua-compatible" content="ie=edge">\n <!-- Icon -->\n <link href="pics/favicon.png" rel="icon" type="image/x-icon" />\n
<!-- MathJax -->\n <!-- CSS Stle -->\n <link rel="stylesheet" href="lib/shower/themes/ribbon/styles/screen.css">\n <link rel="stylesheet" href="lib/highlight/styles/tomorrow.css" type="text/css"/>\n <link rel="stylesheet" href="static/custom.css" type="text/css"/>\n</head>\n<body class="list">\n <!-- Header in overview -->\n <header class="caption">\n <h1>Chinese Search Sharing</h1>\n <p style="line-height: 32px; padding-top:15px;"><a href="http://liang2.tw">Liang Bo Wang (亮亮)</a>,
2015-09-14</p>\n </header>\n <!-- Cover slide -->\n <section id="cover" class="slide cover w"><div>\n <h3 id="talk-subheader">MLDM Monday, 2015-09-14</h3>\n <h2 id="talk-header" class="place">中文搜尋經驗分享</h2>\n <p id="talk-author">\n By <a href="http://liang2.tw" target="_blank">Liang<sup>2</sup></a> under CC 4.0 BY license\n </p>\n <p id="usage-instr">\n
<kbd>Esc</kbd> to overview <br />\n <kbd>←</kbd> <kbd>→</kbd> to navigate\n </p>\n <img src="pics/cover.jpg" alt="">\n </div>\n <style>\n #talk-header {\n color: #EEE;\n text-shadow: 0px 0px 5px black;\n text-align: center;\n font-size: 110px;\n line-height: 1.2em;\n opacity: 1;\n position: relative;\n top: 60px;\n width: 120%;\n }\n #talk-subheader {\n color: #E9FFDA;\n text-shadow: 0px 0px 2px black;\n text-align: center;\n font-size: 36px;\n opacity: 1;\n position: relative;\n top: -20px;\n }\n #talk-author {\n positPost
把要提交的訊息放在封包裏面,除非偷看封包不然沒辦法知道你傳了什麼資訊
範例: 學校的課程查詢
Post程式demo
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Morbi nec metus justo. Aliquam erat volutpat.
import requests
re = requests.post("https://onepiece.nchu.edu.tw/cofsys/plsql/crseqry_home",
data={'v_career':'U','v_dept':'U56','v_level':'2'})
# 裏面可以放任意的網址
# data這個參數裏面放的是我們提交表單的參數
print(re.text)
# 這樣就可以看到該網頁的html駭到學校的資料惹

怎麼知道要data要打那些?

先按開F12
- 然後提交選項之後按到Network的地方
- 選擇第一個:crseqry_home
- 拉到最下面看到的Form Data
- 把Form Data的資料轉換成
dict的型態提交出去即可
{
'v_career' : 'U'
...
}
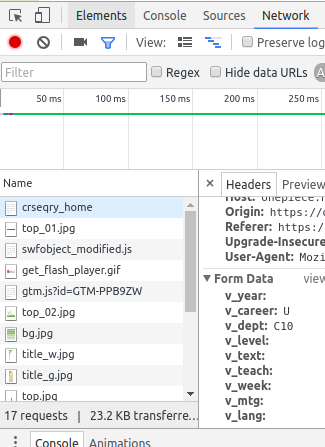
如果你還問:
Network裏面那麼多選項
我怎麼知道要點第一個阿?
通常是點docs或xhr
or 靠經驗XD

必備技能2
下載圖片
省時間

範例網站:
圖片的函式
import shutil需要用到shutil這個函式庫
img = requests.get(url, stream=True)
stream=True,用串流的方式下載
with open('xxx.jpg', 'wb') as f:
shutil.copyfileobj(img.raw, f)with是python開關檔案的語法
因為要存圖片所以要用2進制的方式
img是request的物件,raw會用2進制顯示結果
import requests, shutil
def savePict(url, restaurant):
img = requests.get(url,stream=True)
with open(restaurant+'.jpg', 'wb') as f:
shutil.copyfileobj(img.raw, f)
savePict("http://i2.disp.cc/imgur7/146Qf.jpg", "test")Try it~
必備技能3
剖析網頁
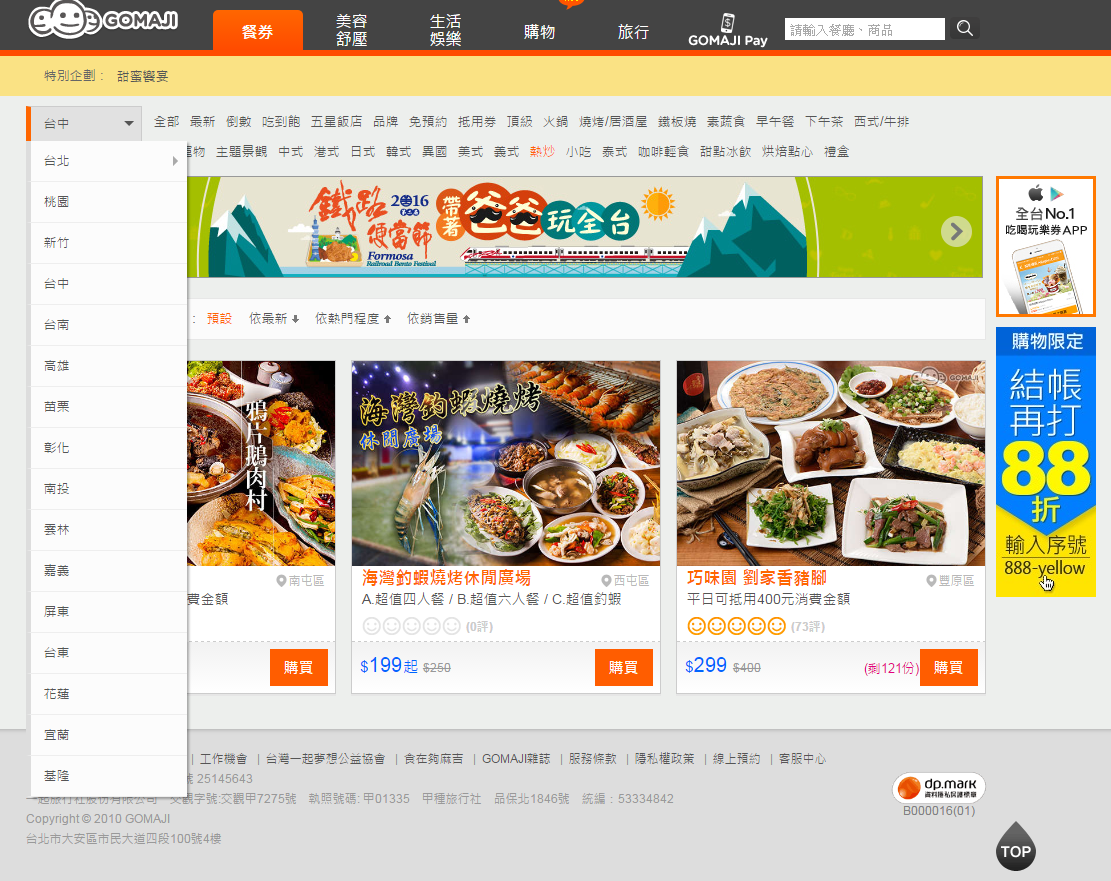
範例:把餐廳跟餐點爬下來
範例網站:gomaji
# select用法
# 指定css選取器的語法
# select 回傳list 也就是array
soup.select('ul or h1 or img or a ...各式各樣的css選取器的語法'):
把要抓的網頁內容丟進beautifulSoup建構式裡面
res.text就是顯示網頁的內容
res = requests.get(url)
soup = BeautifulSoup(res.text)什麼是css選取器

Chrome插件 infolite
titleList = soup.select('.proname_3')
# 長這樣
[<h3 class="proname_3">A.瞬間幸福經典天使蛋糕一個 /
B.瞬間幸福巧克力天使蛋糕一個 /
C.瞬間幸福草莓天使蛋糕一個</h3>,
<h3 class="proname_3">平假日皆可抵用1000元消費金額</h3>,
<h3 class="proname_3">黑羽土雞精煉萃取大容量原味滴雞精禮盒一盒(150ml x 10包)</h3>,
<h3 class="proname_3">鳳凰花開限定版</h3>,
<h3 class="proname_3">小樽燒伴手禮</h3>,
<h3 class="proname_3">平假日皆可抵用600元消費金額</h3>]
# 只取文字
titleList[0].text挑出餐點的標題
取得DOM物件的屬性
a = soup.select('a')
first = a[0]
# 拿到Tag的屬性
first['href']
first['class']
# 拿到tag裏面的文字
first.textimport requests
from bs4 import BeautifulSoup
def parsePage(url):
res = requests.get(url)
soup = BeautifulSoup(res.text)
for i in soup.select('.proname_3'):
print(i.text + '\n')
parsePage('http://www.gomaji.com/index.php?city=Taichung&tag_id=28')
簡單版的教材
把爬蟲的結果存成json
def dump(fileName):
with open(fileName, 'w', encoding='UTF-8') as f:
json.dump(json_arr, f)import json需要用到json這個函式庫
import requests, json
from bs4 import BeautifulSoup
json_arr = []
def dump(fileName):
with open(fileName, 'w', encoding='UTF-8') as f:
json.dump(json_arr, f)
def parsePage(url):
res = requests.get(url)
soup = BeautifulSoup(res.text)
for i in soup.select('ul.deal16 li.box-shadow2px'):
product = i.select('h3.proname_3')[0].text
restaurant = i.select('h2.ref_name_2')[0].text
imghref = i.select('img')[0]['src']
tmp={}
tmp['product'] = product
tmp['restaurant'] = restaurant
json_arr.append(tmp)
dump('demo.json')
parsePage('http://www.gomaji.com/index.php?city=Taichung&tag_id=28')Try it~
補充一下python變數的生存範圍
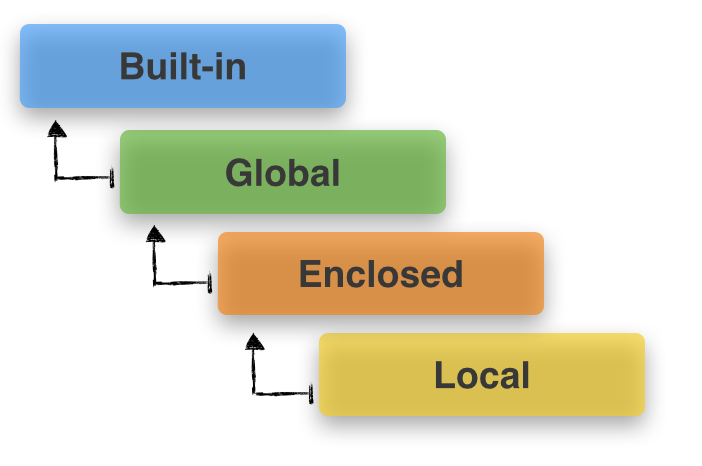
來個範例比較清楚
a_var = 'global value'
def outer():
a_var = 'enclosed value'
def inner():
a_var = 'local value'
print(a_var)
inner()
outer()python會從區域環境開始尋找變數
如果沒有的話才漸漸往上找
不過 如果你有指派的話他就會自己幫你創一個區域環境的變數喔
如果想要指定使用全域的變數的話要加global
要休息嗎?

這邊才是要教高中生的
爬漫畫+正妹
#!/usr/bin/python3
# -*- coding: utf-8 -*-
import requests
from bs4 import BeautifulSoup
import shutil
def savePict(url, name):
img = requests.get(url,stream=True)
with open(name, 'wb') as f:
shutil.copyfileobj(img.raw, f)
res =requests.get('http://www.timliao.com/bbs/viewthread.php?tid=76515')
soup = BeautifulSoup(res.text)
for index, i in enumerate(soup.select('img')):
try:
savePict(i['src'], str(index)+'.jpg')
except Exception as e:
print(e)可以爬提母正妹網
爬看看漫畫版看看
後端跟前端的差別
你會需要先安裝
模擬瀏覽器的動作
pip install selenium#!/usr/bin/python3
# -*- coding: utf8 -*-
from selenium import webdriver
from bs4 import BeautifulSoup
import shutil, requests
def savePict(url, name):
img = requests.get(url,stream=True)
with open(name, 'wb') as f:
shutil.copyfileobj(img.raw, f)
url = "http://v.comicbus.com/online/comic-103.html?ch=871-2"
driver = webdriver.Chrome(executable_path="./chromedriver")
# driver = webdriver.PhantomJS(executable_path='./phantomjs')
driver.get(url)
soup = BeautifulSoup(driver.page_source)
savePict(soup.select('#TheImg')[0]['src'], 'test.jpg')
driver.close()
可以爬無線動漫的漫畫下來
把蛇姬洗澡的那話抓下來
航海王網址

選修技能1
進度條
需要pyprind
Subtitle
import pyprind 出現進度調的特效
for i in pyprind.prog_bar(一個陣列):
xxxx
# demo
for i in pyprind.prog_bar(soup.select('h3')):
print(i)
效果

Try it~
#coding=UTF-8
import facebook, json, pyprind
token='EAACEdEose0cBAJ4k8OC3WQblAb0LjdGNby5JxY4LHgZCm0SJLunElknjfZB5n9Ae2SzayvOKlskUZBPbwi045nEVR8wg50SmpaW4TuzEk7ZBlthwasZBmYfJALRqLBQpXlUO3RFJwwtajRfhnaOkNqxAyMGA78KRNYbYi5CZCELN7E3usLaeOZCaWl7lv2vJEcZD'
#token為access token
graph=facebook.GraphAPI(access_token=token, version='2.6')
#i為要所需的FB頁面之id
def crawl(i):
info = graph.get_object(i)
print(info)
posts = graph.get_connections(i, 'posts')
for p in pyprind.prog_bar(posts['data']):
p['reactions'] = graph.get_connections(p['id'], 'reactions')
p['comments'] = graph.get_connections(p['id'], 'comments')
json.dump(posts, open('facebook.json', 'w'))
crawl('1623149734611090') # 選課小幫手選修技能2
命令列
記得import sys
import sys先來看看sys.argv是啥

他會把命令列的參數已list的型態印出來
print(sys.argv)放上main函式
if __name__ == "__main__":
parsePage(sys.argv[1])
dump(sys.argv[2])Try it ~
import requests, json, pyprind, sys, shutil
from bs4 import BeautifulSoup
json_arr = []
def savePict(url, restaurant):
img = requests.get(url,stream=True)
with open(restaurant+'.jpg', 'wb') as f:
shutil.copyfileobj(img.raw, f)
def dump(fileName):
with open(fileName, 'w', encoding='UTF-8') as f:
json.dump(json_arr, f)
def parsePage(url):
res = requests.get(url)
soup = BeautifulSoup(res.text)
for i in pyprind.prog_bar(soup.select('ul.deal16 li.box-shadow2px')):
product = i.select('h3.proname_3')[0].text
restaurant = i.select('h2.ref_name_2')[0].text
imghref = i.select('img')[0]['src']
tmp={}
tmp['product'] = product
tmp['restaurant'] = restaurant
json_arr.append(tmp)
savePict(imghref, restaurant)
if __name__ == "__main__":
print(sys.argv)
parsePage(sys.argv[1])
dump(sys.argv[2])優化一下語法
# 會到一個generator
# 一般的for loop
# 會等要迭代的東西都準備好才開始迭代
# generator 是lazy computation
# 每次要for loop才計算下一個
# 避免cpu被卡在那邊太久
map(lambda x:x**2, range(1,10))
# 用map做所花的時間
>>> @timing
... def m():
... return map(lambda x:x**2, range(1,1000000))
...
>>> m()
It cost 1.1920928955078125e-05 seconds to do m
# for loop做
>>> @timing
... def f():
... result = []
... for i in range(1,1000000):
... result.append(i**2)
return result
...
>>> f()
It cost 0.38407206535339355 seconds to do f
map 內建函式(用c寫的,速度快)
import requests, json, pyprind, sys, shutil
from bs4 import BeautifulSoup
def savePict(url, restaurant):
img = requests.get(url,stream=True)
with open(restaurant+'.jpg', 'wb') as f:
shutil.copyfileobj(img.raw, f)
def parsePage(url):
res = requests.get(url)
soup = BeautifulSoup(res.text)
json.dump(list(map(lambda i:dict(product=i.select('h3.proname_3')[0].text, restaurant=i.select('h2.ref_name_2')[0].text, pic=savePict(i.select('img')[0]['src'], i.select('h2.ref_name_2')[0].text)), pyprind.prog_bar(soup.select('ul.deal16 li.box-shadow2px')))), open('demo.json', 'w'))
if __name__ == "__main__":
parsePage(sys.argv[1])把他縮在同一行
參考資料
- Gomaji的完整版爬蟲
- 小幫手爬蟲
- ptt爬蟲(其他大大做的) <- 主任跟耀中的組別
- 台鐵票價資訊 -> 高老師的組別
- 大數學堂 (我是看這個網站學的)
- css selector
下回

沒看過流氓隊友ㄇ
