Storytelling with Code
and living happily ever after
Goals of this talk:
- Provide practical tips for writing more readable code - regardless of your preferred programming language
- Show how writing readable code usually means you're writing more testable and maintainable code too!
- Encourage questions and participation
- Live happily ever after


Delaine Wendling
Software Engineer




Who's reading your code anyway?
Who's reading your code anyway?



Readable code is:
If I can easily, and quickly, reason about the code and explain it to non-technical people or other developers - I would say the code is highly readable.
A little caveat before we dive in:
The Road to Readable Code
and living happily ever after
What story does this tell?
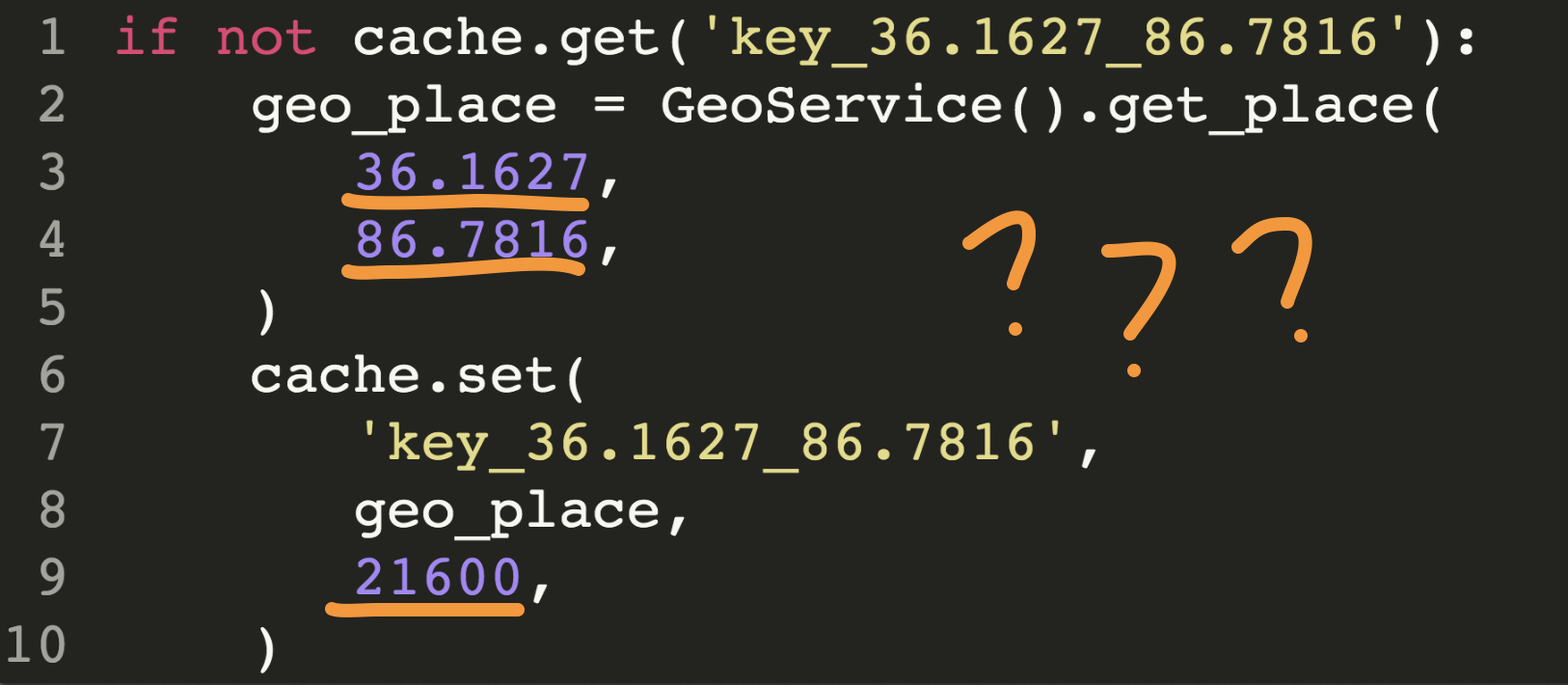
if not cache.get('key_36.1627_86.7816'):
geo_place = GeoService().get_place(
36.1627,
86.7816,
)
cache.set(
'key_36.1627_86.7816',
geo_place,
21600,
)Is this a better story?
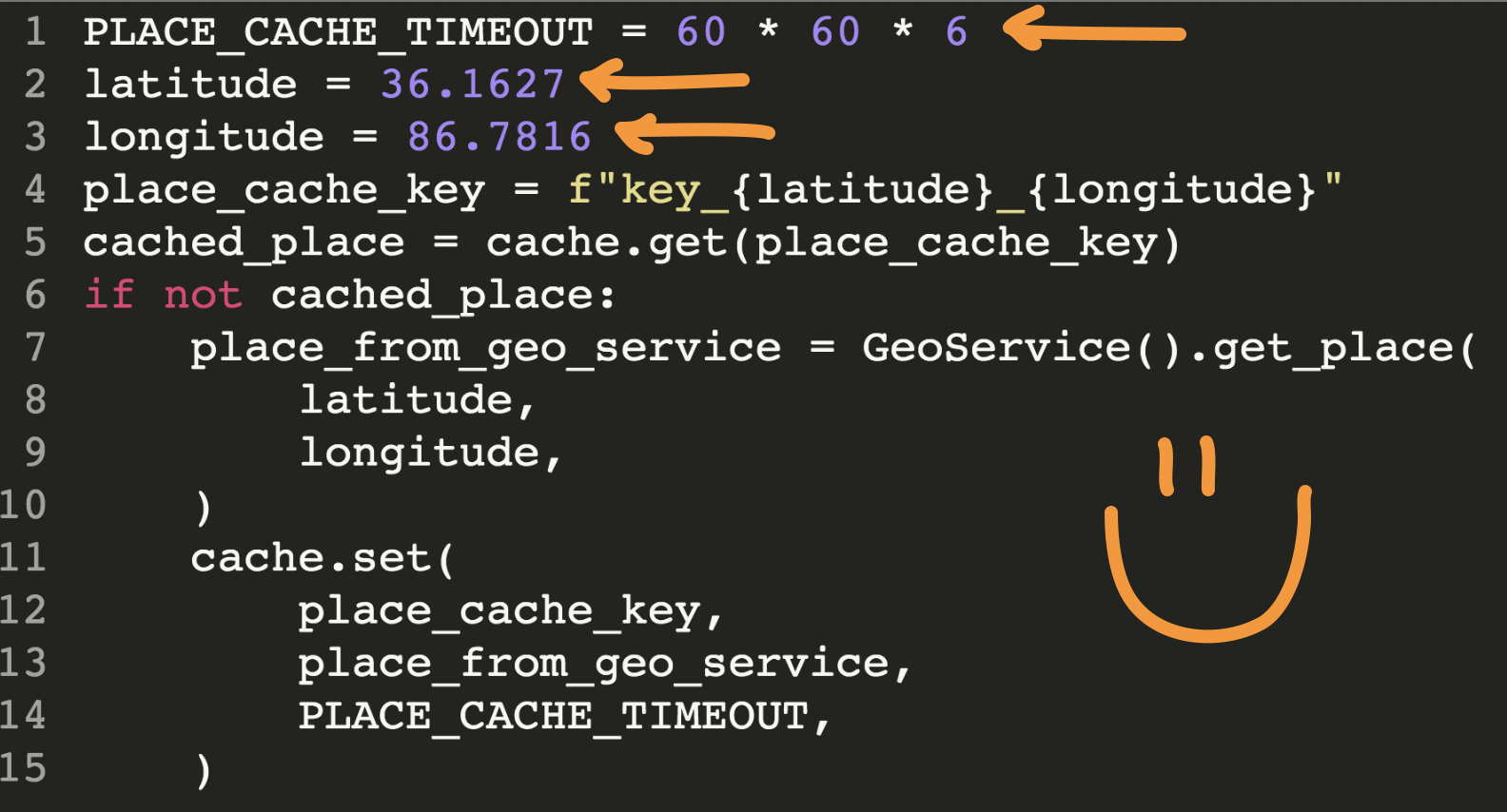
latitude = 36.1627
longitude = 86.7816
place_cache_key = f"key_{latitude}_{longitude}"
cached_place = cache.get(place_cache_key)
place_cache_timeout = 60 * 60 * 6
if not cached_place:
place_from_geo_service = GeoService().get_place(
latitude,
longitude,
)
cache.set(
place_cache_key,
place_from_geo_service,
place_cache_timeout,
)Telling a Better Story Tip 1:
Create context using variables with meaningful names
(long names are ok but not TOO long)
place_cache_keyplace_cache_key_with_latitude_and_longitudeThink not
l_1 = 36.1627
l_2= 86.7816
key = f"key_{l_1}_{l_2}"
x = cache.get(place_cache_key)
t = 60 * 60 * 6
if not cached_place:
z = GeoService().get_place(
l_1,
l_2,
)
cache.set(
x,
z,
t,
)Telling a Better Story Tip 2:
Avoid naked numbers
Telling a Better Story Tip 2:
Avoid naked numbers
You can even write a number as a mathematical expression to provide context (i.e. CACHE_TIMOUT = 60 * 60 * 6 rather than CACHE_TIMOUT = 21600)
password_length = len(password)
if password_length < 8:
raise ValidationError("""Must create a
password that is 8 characters or more""")MIN_PASSWORD_LENGTH = 8
password_length = len(password)
if password_length < MIN_PASSWORD_LENGTH:
raise ValidationError(f"""Must create a
password that is {MIN_PASSWORD_LENGTH}
characters or more""")Naked Number Alert!
Much better :)
def validate_password(password):
password_length = len(password)
if password_length < 8:
raise ValidationError("""Must create a
password that is 8 characters or more""")Testing with a naked number
def test_validate_password(self):
password = ''.join(
random.choices(string.ascii_lowercase,
k=7,
))
with self.assertRaises(ValidationError) as e:
validate_password(password)
self.assertEqual(e.exception.errors[0],
"""Must create a password that is
8 characters or more""")def validate_password(password):
password_length = len(password)
if password_length < MIN_PASSWORD_LENGTH:
raise ValidationError(f"""Must create a
password that is {MIN_PASSWORD_LENGTH}
characters or more""")Testing with a constant (variable)
def test_validate_password(self):
password = ''.join(
random.choices(string.ascii_lowercase,
k=MIN_PASSWORD_LENGTH - 1,
))
with self.assertRaises(ValidationError) as e:
validate_password_length(password)
self.assertEqual(e.exception.errors[0],
f"""Must create a password that is
{MIN_PASSWORD_LENGTH} characters or more""")Telling a Better Story Tip 3:
Break up larger chunks of code into smaller methods/functions (that do one thing)
but not too small or too many
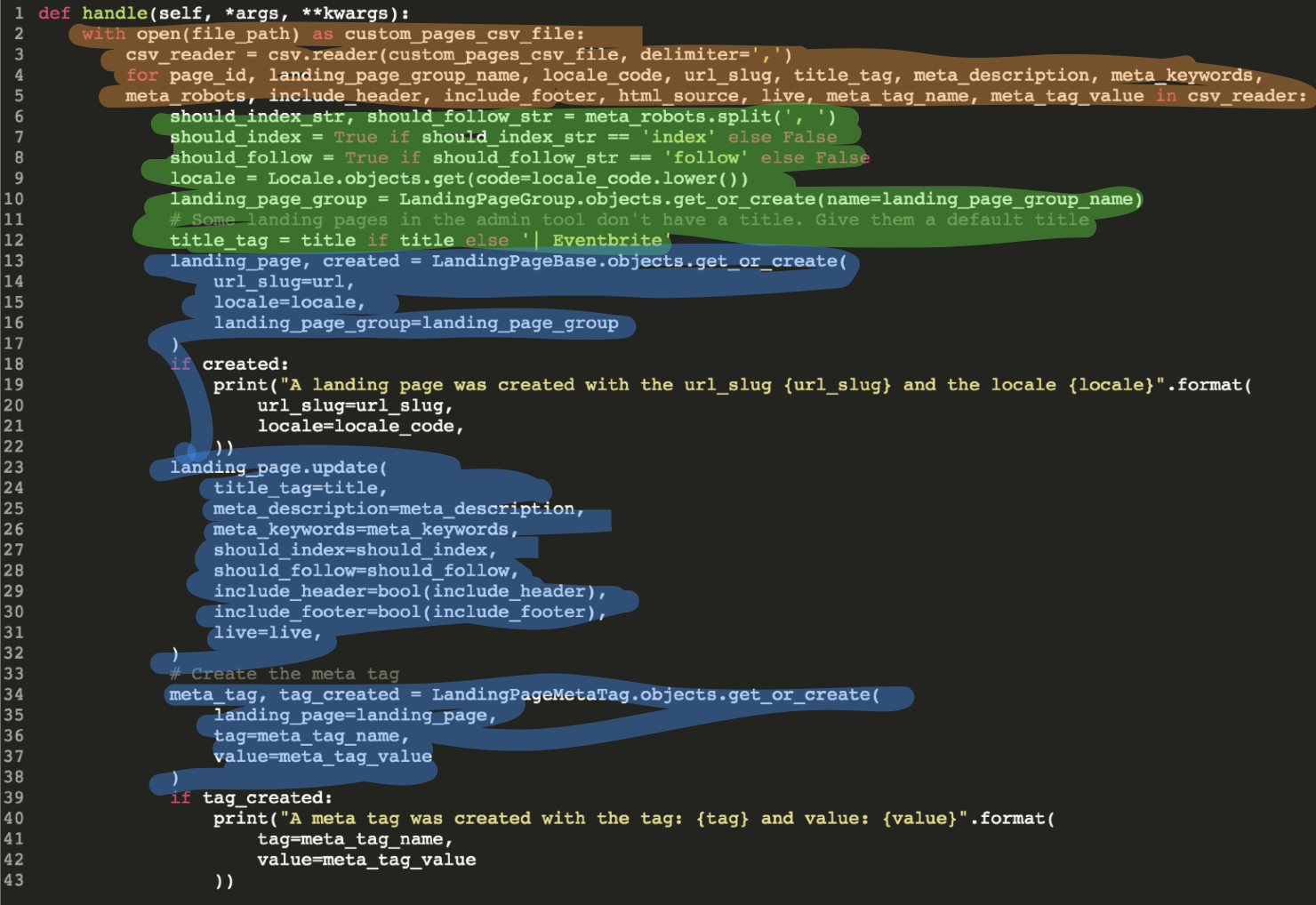
Parsing the CSV
Cleaning the data
Hitting the database
def handle(self, file_path, *args, **kwargs):
pages_data = parse_pages_csv(file_path)
cleaned_pages = clean_pages_data(pages_data)
create_or_update_pages(cleaned_pages)
Few rules of thumb:
- If you are tempted to put the word "and" in the name of a function or method, it's probably doing more than one thing and you should make more than one function or method.
- Re-evaluate if you have a call stack of methods that have almost the exact same name
fetchEvent()
fetchEventFromApi()
getEvent()
prepareEvent()This is a real example
Telling a Better Story Tip 4:
Think of your tests as another source of documentation for your code
import re
def increment_string(strng):
# The following regex only finds numbers at the end of a string
# (numbers in the middle of the string will not be found)
ending_num_group = re.search(r'\d+$', strng)
if ending_num_group:
ending_num = ending_num_group.group()
new_ending_num = int(ending_num) + 1
num_length = len(ending_num)
last_index_before_num = len(strng)-num_length
# zfill returns a copy of the string with
# '0' characters padded to the left
new_string = strng[:last_index_before_num] +
str(new_ending_num).zfill(num_length)
else:
new_string = strng + '1'
return new_string@parameterized.expand([
('no number at the end', 'slug', 'slug1'),
('20 at end', 'adfe20', 'adfe21'),
('100 at end', 'slug100', 'slug101'),
('number at beginning', '100-club', '100-club1'),
('number at beginning and end', '100-club-2', '100-club-3'),
('number in the middle', 'jointhe100club', 'jointhe100club1'),
(
'number in the middle and end with zeroes',
'jointhe100club002',
'jointhe100club003',
),
])
def test_increment_string(self, _test_name, string_input, expected):
result = increment_string(string_input)
self.assertEqual(result, expected)Telling a Better Story Tip 5:
Verbosity (not complexity) > Cleverness
Write simple functions with specific names. Remove anything “clever”.
If you’re trying to achieve something in the least amount of code lines possible, it most likely won’t be easily readable.
increment_string=f=lambda s:s and s[-1].isdigit()and(f(s[:-1])+"0",
s[:-1]+str(int(s[-1])+1))[s[-1]<"9"]or s+"1"
Your job is to write a function which increments a string, to create a new string.
- If the string already ends with a number, the number should be incremented by 1.
- If the string does not end with a number, the number 1 should be appended to the new string.
increment_string=f=lambda s:s and s[-1].isdigit()and(f(s[:-1])+"0",
s[:-1]+str(int(s[-1])+1))[s[-1]<"9"]or s+"1"
Your job is to write a function which increments a string, to create a new string.
- If the string already ends with a number, the number should be incremented by 1.
- If the string does not end with a number. the number 1 should be appended to the new string.
import re
def increment_string(strng):
# The following regex only finds numbers at the end of a string
# (numbers in the middle of the string will not be found)
ending_num_group = re.search(r'\d+$', strng)
if ending_num_group:
ending_num = ending_num_group.group()
new_ending_num = int(ending_num) + 1
num_length = len(ending_num)
last_index_before_num = len(strng)-num_length
# zfill returns a copy of the string with
# '0' characters padded to the left
new_string = strng[:last_index_before_num] +
str(new_ending_num).zfill(num_length)
else:
new_string = strng + '1'
return new_stringTelling a Better Story Tip 6:
Comments and Docstrings
when needed
Cleverness is just another spectrum, it’s not always good and it’s not always bad, there’s a tradeoff.
If I have something clever that has advantages, other than simply being clever, I would consider possibly documenting it rather than just throwing it out
def get_full_place_name(self, place_type, current_place):
"""
Formats the place name according to the following rules:
* Cities
- '{city}, {region}' for cities in the United States and Australia
- '{city}, {country}' for cities in other countries
* Regions - '{region}, {country}'
* Countries - '{country}'
e.g.
* Nashville, TN and Mendoza, Argentina
* California, United States
* Iceland
:param place_type: Indicates what kind of place it is
(i.e. city, region)
:type place_type: string
:param current_place: A dictionary of information about the
current place
(e.g. {
'city': 'Nashville',
'region': 'Tennessee',
'country': 'United States',
})
:type current_place: dict
:returns place_name: Returns the correctly formatted place name
according to the rules listed above.
:rtype: string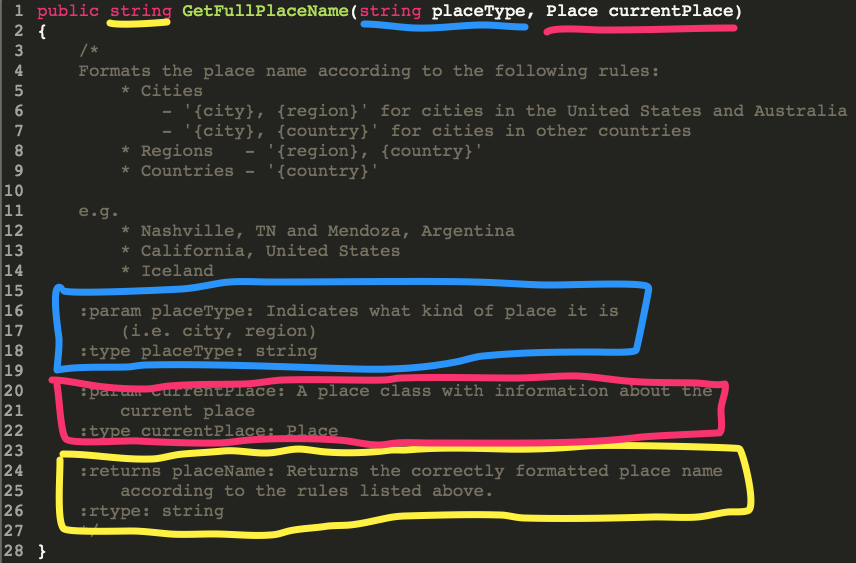
Telling a Better Story Tip 7:
Follow the style guide and norms of the language you're using and your place of work
Telling a Better Story Tip 8:
Avoid deep nesting
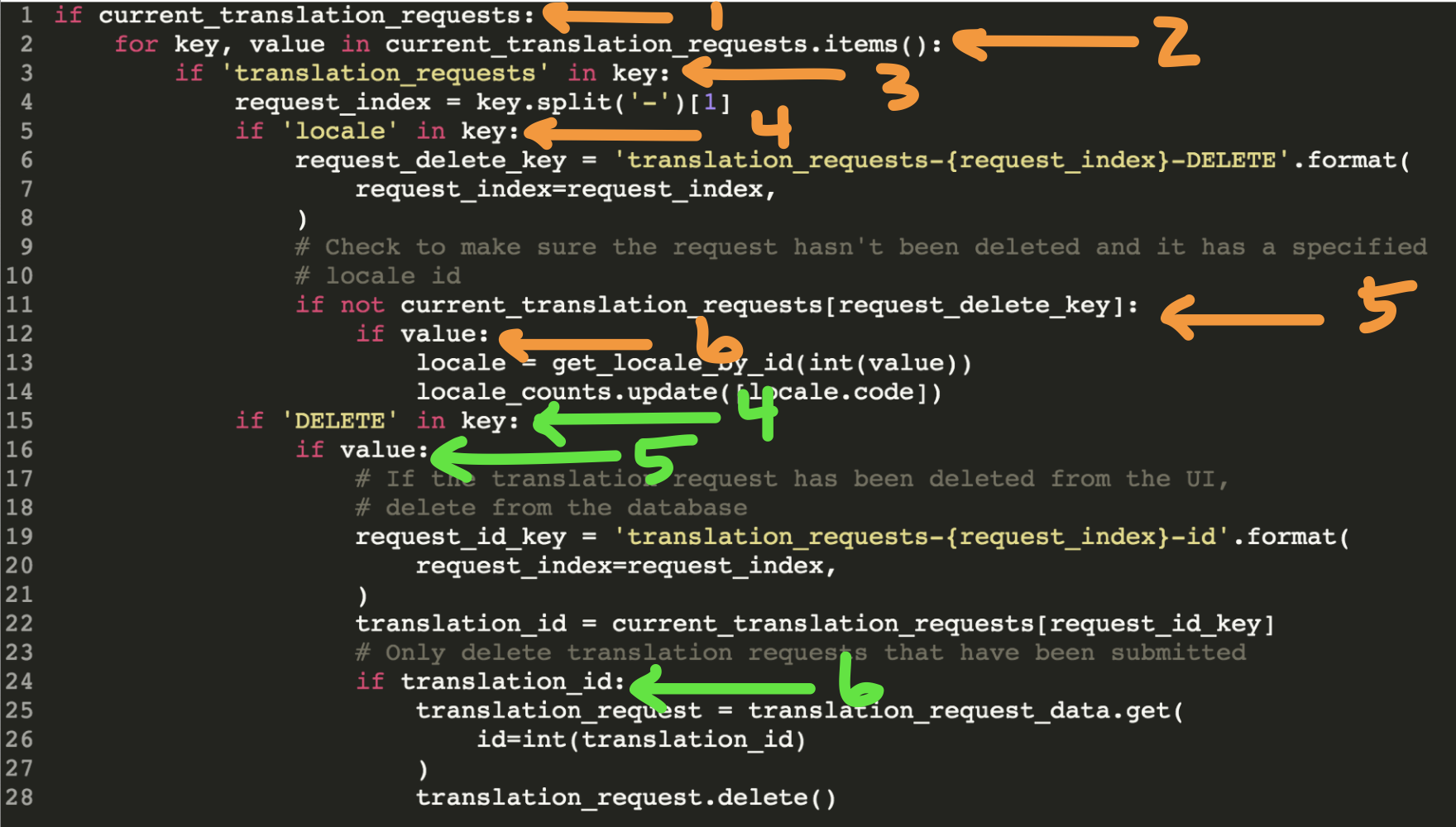
- Use boolean operators to flatten out the structure
- Create methods/functions
- Use built-in methods
if 'DELETE' in key and value:if 'DELETE' in key:
if value:VERSUS
Telling a Better Story Tip 9:
INDENTATION!
<table>
<tr>
<td> Lorem ipsum dolor sit amet
</td>
<td>
Consectetur adipisicing
</td>
</tr>
<tr>
<td>
Lorem ipsum dolor sit amet
</td>
<td>
Consectetur adipisicing
</td>
</tr>
</table>def get_context_data(self, **kwargs):
place_id = kwargs.get('place_id')
enrollments = kwargs.get('enrollments', {})
content = self.get_content(place_id,
should_enable_city_browse_carousel)
buckets = content.get('buckets')
location_slug = kwargs.get('location_slug')
context = { 'place_id': place_id,
enrollments: enrollments, content: content,
buckets: buckets,
location_slug: location_slug,}
return contextTelling a Better Story Tip 10:
Association > Inheritance
I would argue against using mixins/multiple inheritance. They make supporting code like a magical nightmare web where you have no idea where functionality is coming from. I prefer explicit composition where possible. This makes a clearly defined trail you can follow to find functionality.
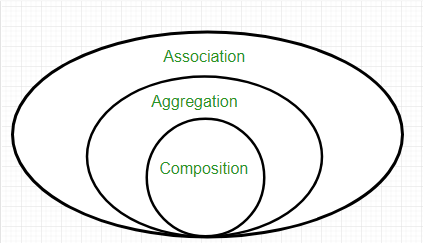
Association is a relationship between two separate classes which is established through their Objects
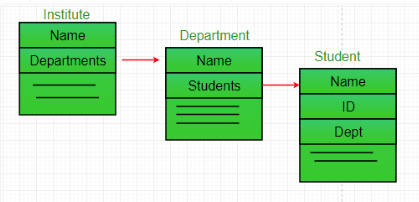
Aggregation represents a Has-A relationship.
Code reuse is high with this architecture.
Objects are independent of one another.
Composition represents a Part-Of relationship.
Objects are dependent on one another.

Questions?
Resources:
Small Functions Considered Harmful: https://medium.com/@copyconstruct/small-functions-considered-harmful-91035d316c29
Association, aggregation and composition. https://www.geeksforgeeks.org/association-composition-aggregation-java/
Advice and quotes from my lovely co-workers