Daniel Himmelstein, PhD
Data-Driven Drug Repurposing Virtual Workshop Series
Deep dive into the challenges and potential applications of knowledge graphs
2024-02-12
Metapath-based approaches for therapeutic crosspurposing and the challenge of degree/study bias

slides.com/dhimmel/dddr-workshop
slides released under CC BY 4.0
most hetio project websites are offline
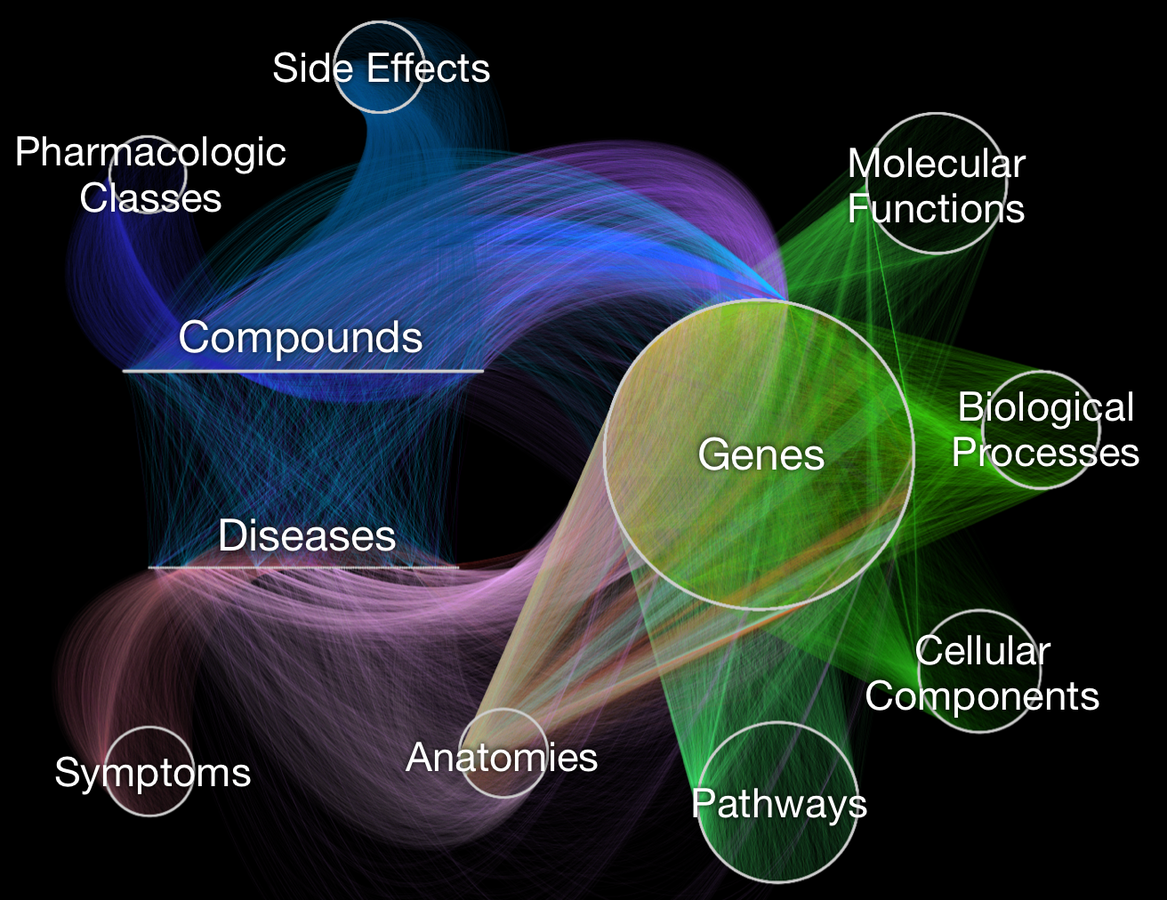
- knowledge graph for drug repurposing
- integrates 29 public resources
knowledge from millions of studies
- ~50 thousand nodes
11 types (metanodes)
- ~2.25 million relationships
24 types (metaedges)
Hetionet v1.0
Systematic integration of biomedical knowledge prioritizes drugs for repurposing
Daniel S Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, Sergio E Baranzini
eLife (2017) https://doi.org/cdfk
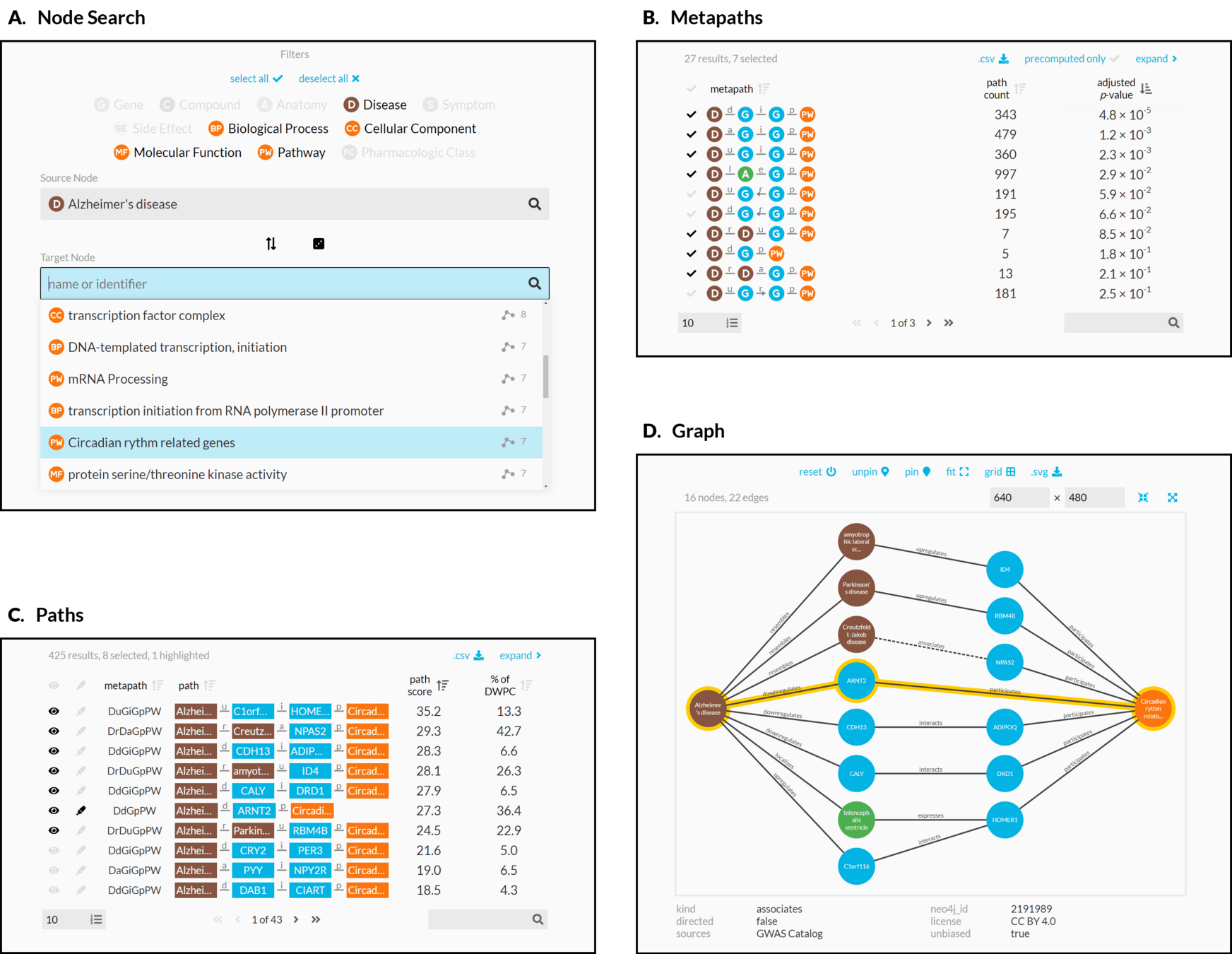
Hetionet metagraph (schema)


metapaths
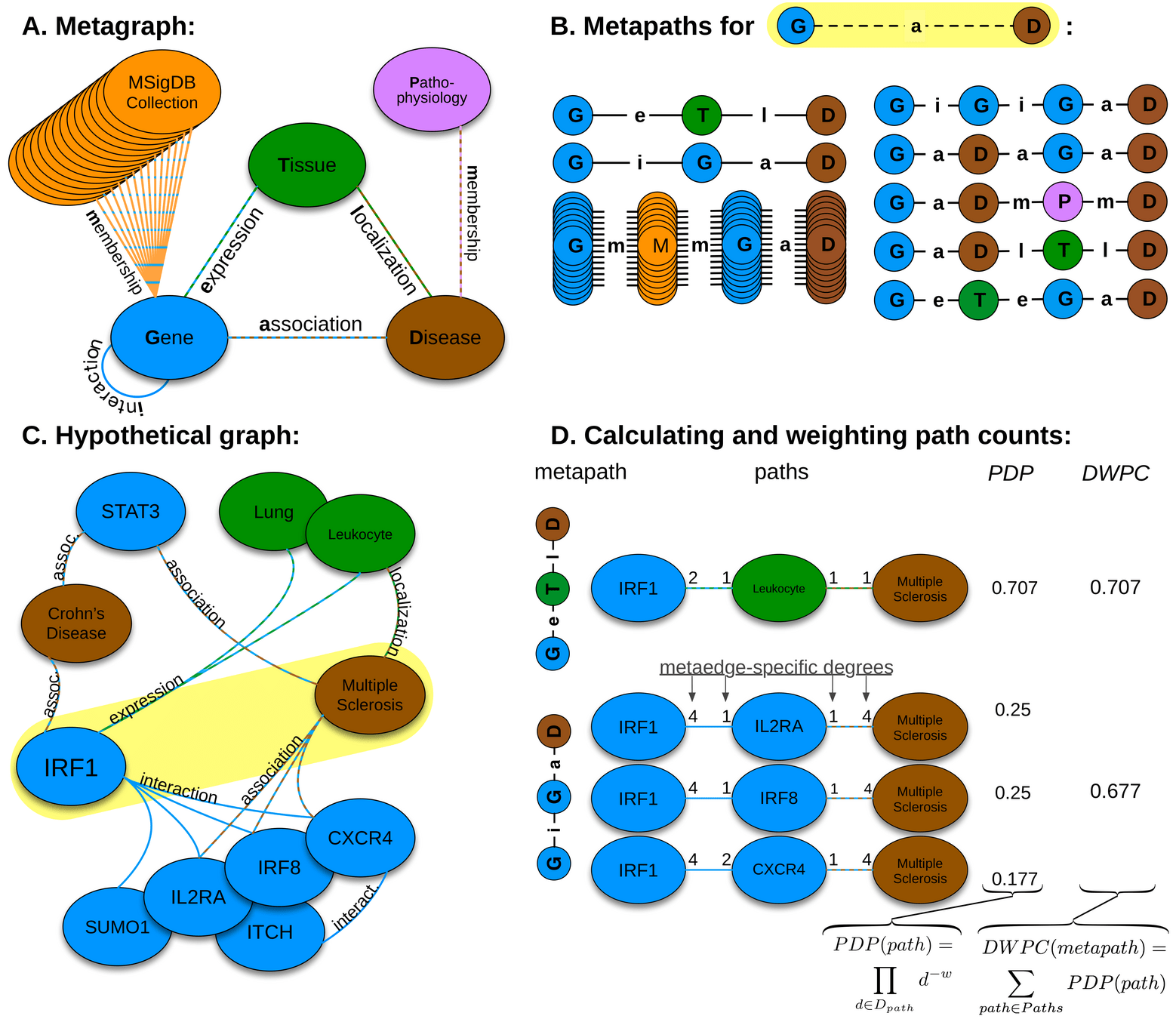
degree-weighted path count
DOI: 10.1371/journal.pcbi.1004259
observations =
compound–disease pairs
features = types of paths
Project Rephetio
Systematic integration of biomedical knowledge prioritizes drugs for repurposing
Daniel S Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, Sergio E Baranzini
eLife (2017) https://doi.org/cdfk
therapeutic crosspurposing for 209,168 compound–disease pairs
https://het.io/repurpose/
1,538 connected
138 connected
explainability of metapath-based approaches
predictions can be decomposed into their component metapath and path contibutions
Comparison to EveryCure
- Project Rephetio performed therapeutic crosspurposing
- Hetionet designed for
- approved drugs
- common, complex diseases
- Rare diseases are difficult to link in networks, but the time is right:
- genetics
- phenotypes / symptoms
- expression
- literature study
- NCATS knowlege graphs

degree/study bias
the Achilles' heel of network-based approaches
Hetnet connectivity search provides rapid insights into how biomedical entities are related
Daniel Himmelstein, Michael Zietz, Vincent Rubinetti, Kyle Kloster, Benjamin Heil, Faisal Alquaddoomi, Dongbo Hu, David Nicholson, Yun Hao, Blair Sullivan, Michael Nagle, Casey Greene
GigaScience (2023) https://doi.org/gsd85n
The probability of edge existence due to node degree: a baseline for network-based predictions
Michael Zietz, Daniel Himmelstein, Kyle Kloster, Christopher Williams, Michael Nagle, Casey Greene
GigaScience (2024) https://doi.org/gtcbks
A Proteome-Scale Map of the Human Interactome Network
Thomas Rolland, Murat Taşan, Benoit Charloteaux, Samuel J Pevzner, Quan Zhong, Nidhi Sahni, Song Yi, Irma Lemmens, Celia Fontanillo, Roberto Mosca, … Marc Vidal
Cell (2014-11) https://doi.org/f3mn6x
Figure 4A: Adjacency matrices showing Lit-BM-13 (blue) and HI-II-14 (purple) interactions, with proteins in bins of ∼350 and ordered by number of publications along both axes. The color intensity of each square reflects the total number of interactions for the corresponding bins
study bias
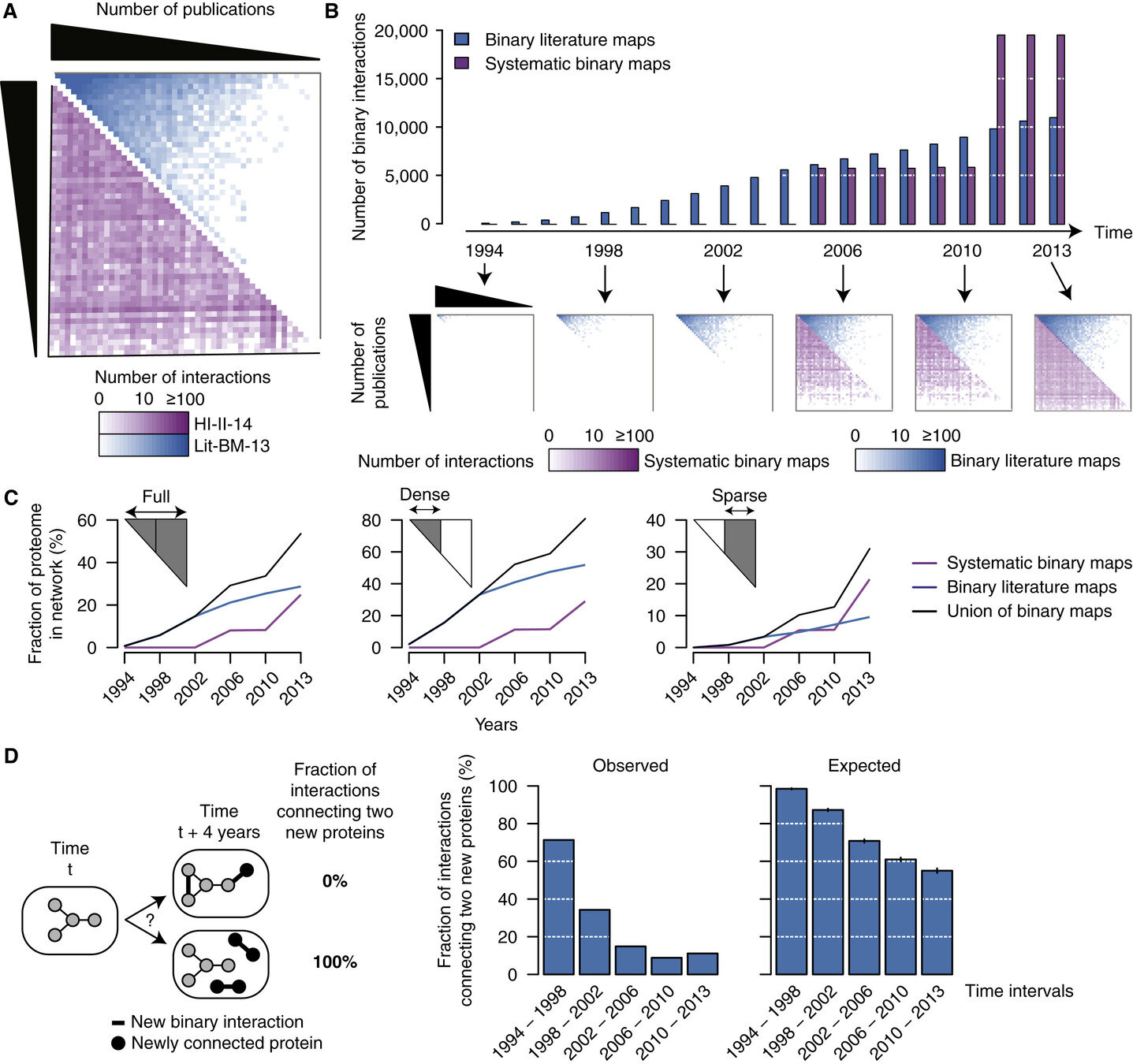
Genome-wide systematic PPI method
Literature derived PPI method
- systematic omics-scale data is ideal
- degree bias in networks often arises from study bias rather than the ground truth
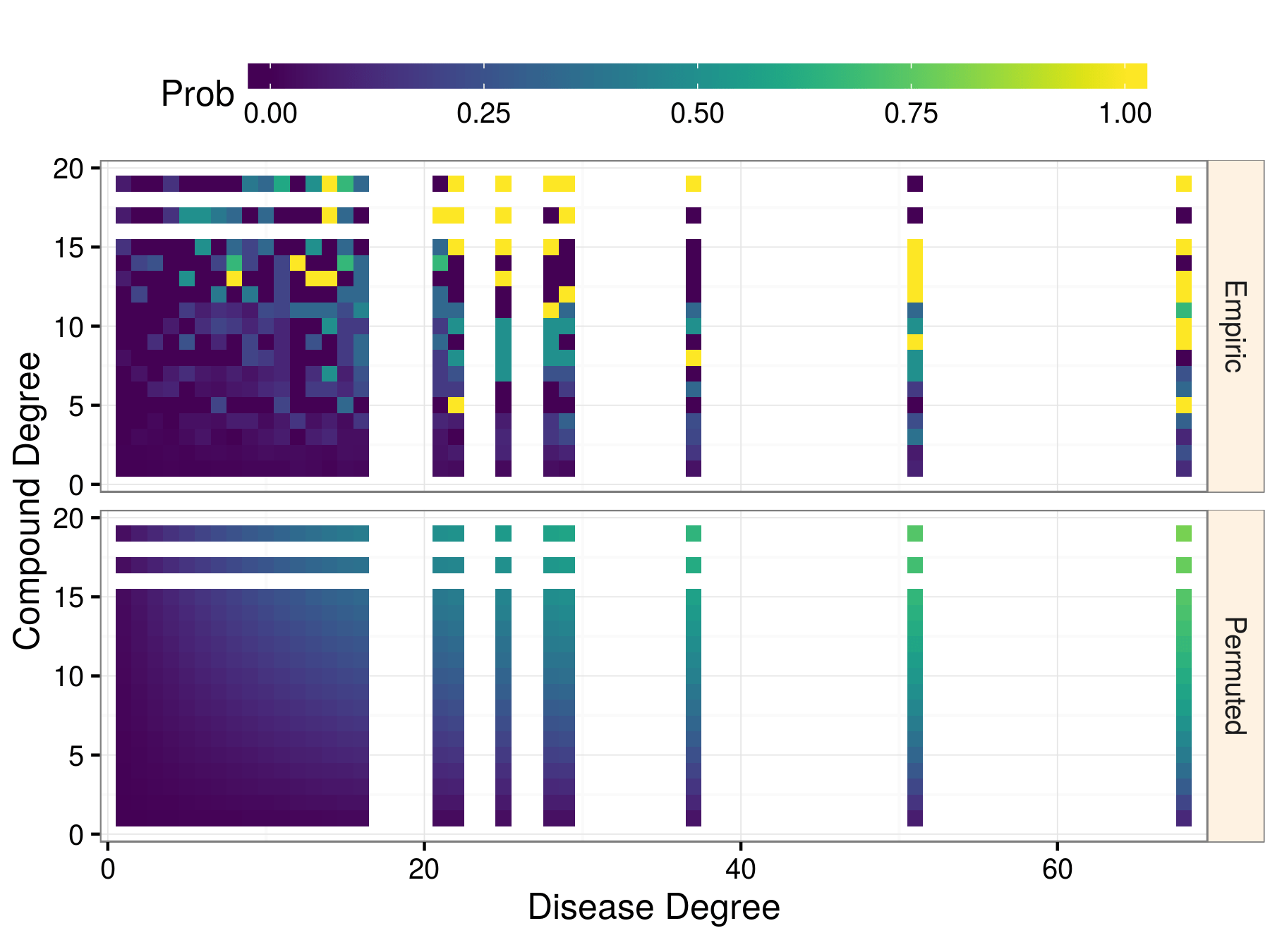
compound × disease, both with 1 treatment: prior = 0.12%
methotrexate × hypertension = 80% prior probability of treatment
The prior predicted in-sample treatments with AUROC = 97.9% but under-performed on validations:
- 54.1% on DrugCentral
- 62.5% on clinical trials

The edge prior was not able to predict the separate PPI network better than by random guessing (AUROC of roughly 0.5). Only slightly better was its performance in predicting the separate TF-TG network, at an AUROC of 0.59. We find superior performance in predicting the coauthorship relationships (AUROC 0.75), which was expected as the network being predicted shared roughly the same degree distribution as the network on which the edge prior was computed
For all biomedical networks we've seen, degree is highly predictive of whether an edge exists, but it rarely generalizes to independent validation.
The probability of edge existence due to node degree: a baseline for network-based predictions
Michael Zietz, Daniel Himmelstein, Kyle Kloster, Christopher Williams, Michael Nagle, Casey Greene
GigaScience (2024) https://doi.org/gtcbks
empirical approximation of the edge prior
- create many randomized (permuted) networks and count the proportion with an edge.
- degree-preserving permutations using XSwap
- IndeCut by Koslicki & co evaluates several methods
- bonus: metrics can be computed on permuted networks to form a degree baseline
analytical approximation of the edge prior — Pᵢ,ⱼ
probability that an edge exists solely based on degree
- m = total number of edges in the network
- uᵢ = source node degree
- vⱼ = target node degree

Michael Zietz / zietzm.com
Finishing PhD at Columbia
1,206 compound–disease metapaths (length ≤ 4)
-
Upper tier:
traditional pharmacology -
Upper-middle tier:
traditionally biomedicine, but newer in drug efficacy -
Lower-middle tier:
genome-wide / high-throughput data sources -
Lower tier:
cellular components
Browse at het.io/repurpose/metapaths.html

DWPC Δ AUROC: performance of a metapath on the real network minus performance on permuted networks
Conclusions
- knowledge graphs / hetnets can succeed at therapeutic crosspurposing
- but so can predictions based only a compound's and disease's degree
- evaluate the performance of the "edge prior"
- make predictions on permuted (degree-preserving) networks as a baseline
- study and degree biases are not favorable to rare diseases, but high predictions for a rare disease that are still low predictions overall might be picking up on important non-degree signals