Greene Lab Journal Club
9:00 AM on September 9, 2016


| Measure | Value |
|---|---|
| Exomes | 60,706 |
| HQ Variants | 7,404,909 |
| mean exome base pairs per variant | 8 |
| loss-of-function intolerant genes | 3,230 |
- Browser: http://exac.broadinstitute.org
- Paper Repo: https://github.com/macarthur-lab/exac_2015
ExAC Stats
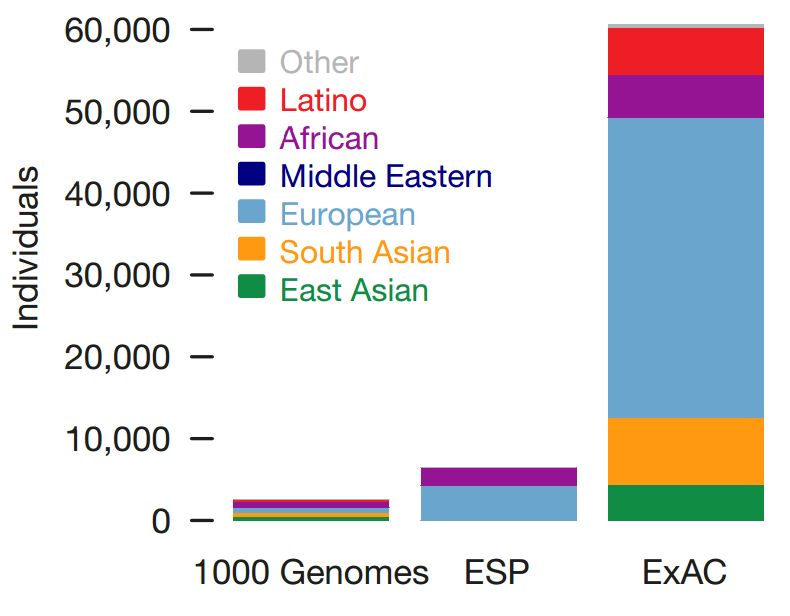
The size and diversity of public reference exome data sets.
ExAC exceeds previous data sets in size for all studied populations.
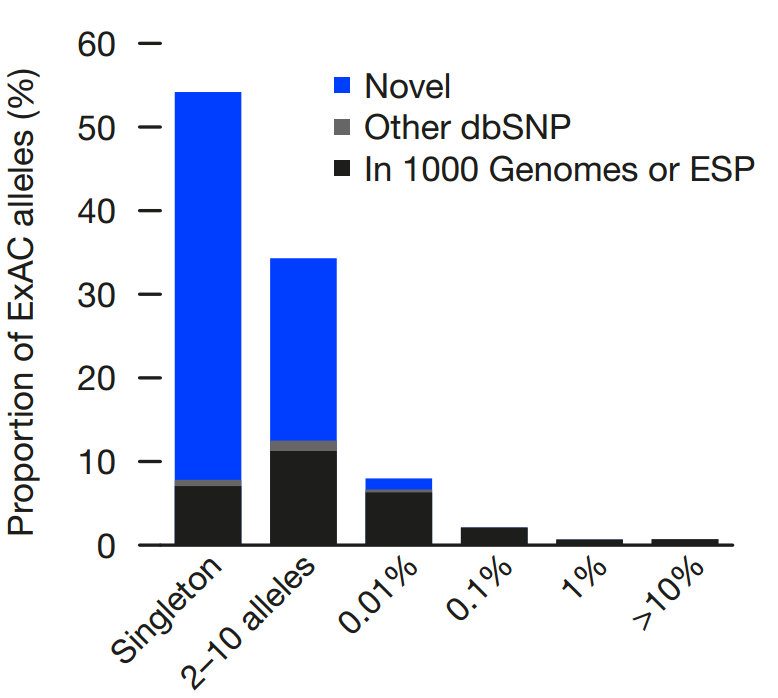
The allele frequency spectrum of ExAC highlights that the majority of genetic variants are rare and novel (absent from prior databases of genetic variation, such as dbSNP)
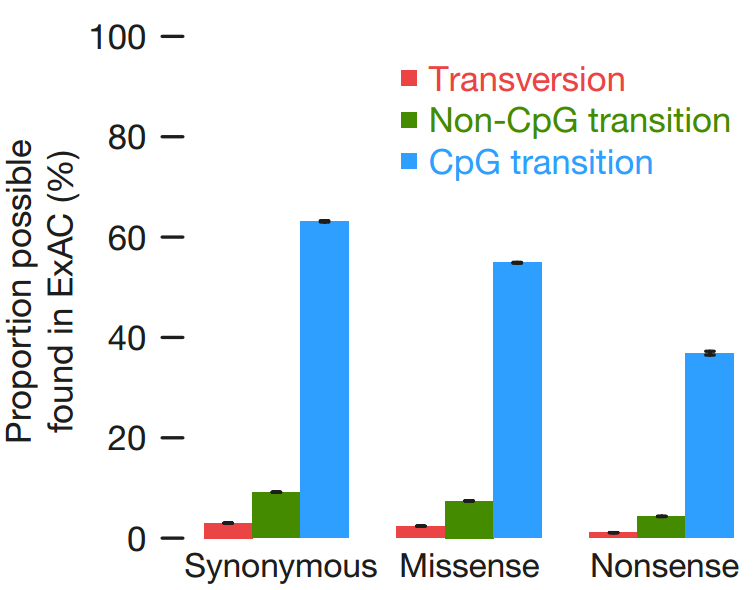
The proportion of possible variation observed by mutational context and functional class.
Over half of all possible CpG transitions are observed.
synonymous in grey, missense in orange, and proteintruncating in maroon
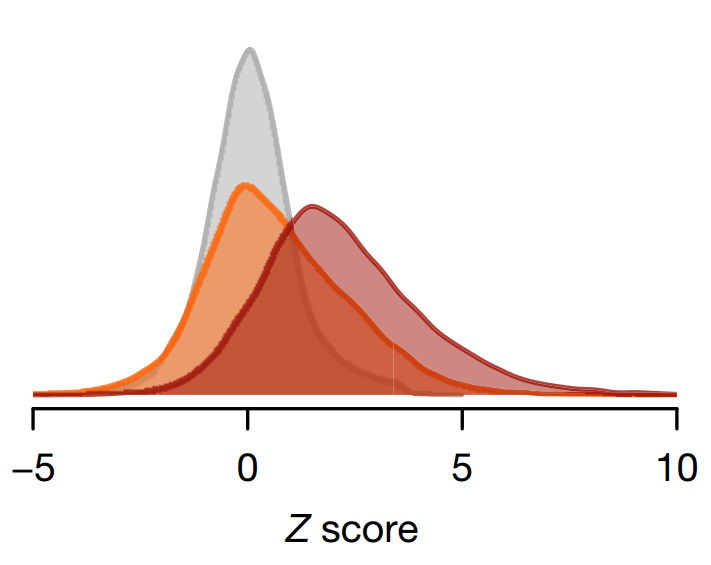
Histograms of constraint Z scores for 18,225 genes
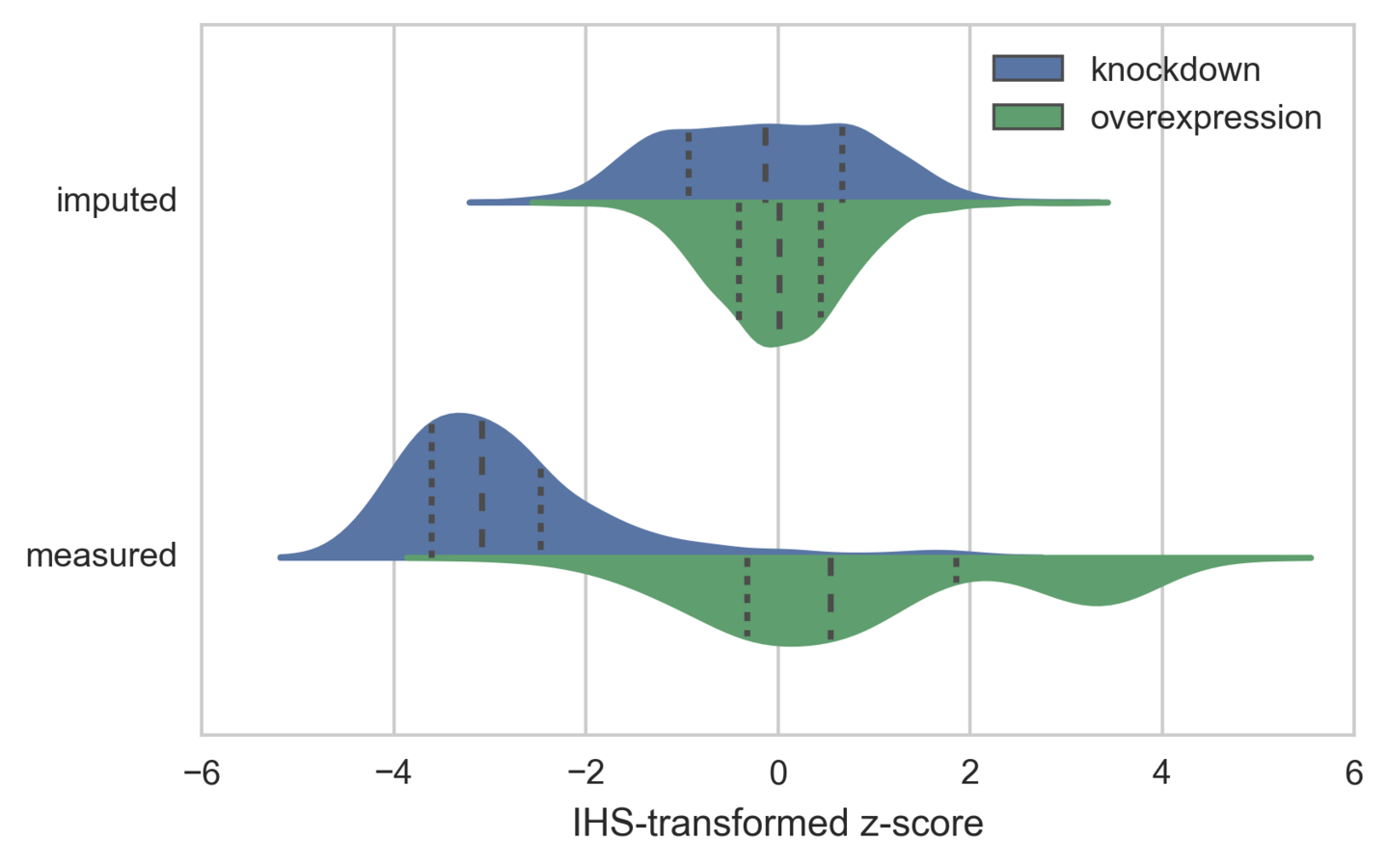
LINCS L1000: distribution of dysregulation z-scores by imputation status and perturbation type
Daniel Himmelstein (2016) Assessing the imputation quality of gene expression in LINCS L1000. Thinklab. DOI: 10.15363/thinklab.d185

However, the computational approach adopted by the LINCS program is currently based on linear regression (LR), limiting its accuracy since it does not capture complex nonlinear relationship between expressions of genes.
WARNING: all rights reserved, use at your own risk.
Funded by the NIH (P50GM76516) & NSF (DBI-0846218).
For the microarray platform, we used the GEO data for training, validation and testing. Specifically, we randomly partitioned the GEO data into 80% for training (88,807 samples denoted as GEO-tr), 10% for validation (11,101 samples denoted as GEO-va) and 10% for testing (11,101 samples denoted as GEO-te). The validation data GEO-va were used to do model selection and parameter tuning for all the methods.
D-GEX is a multi-task multi-layer feedforward neural network. It consists of one input layer, one or multiple hidden layers and one output layer.
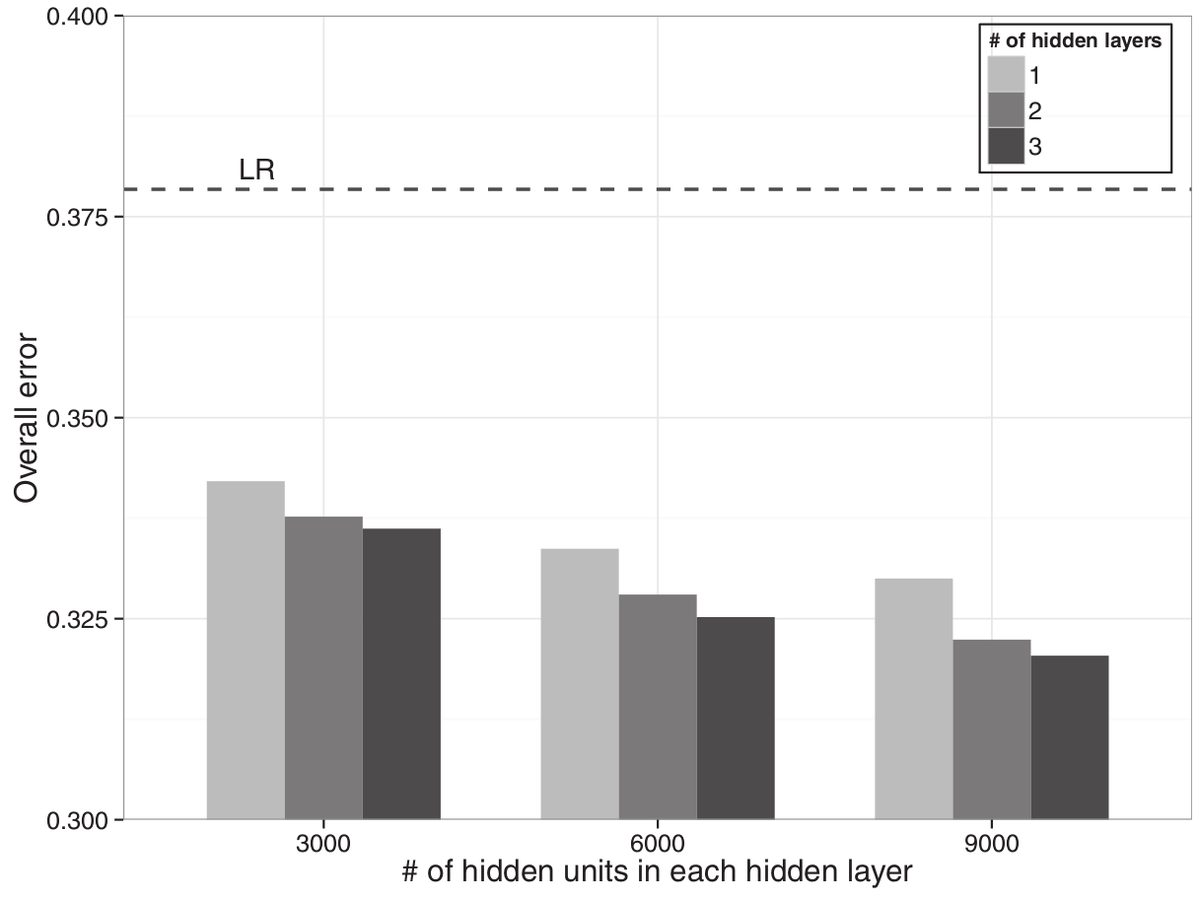
The overall errors of D-GEX-10% with different architectures on GEO-te. The performance of LR is also included for comparison
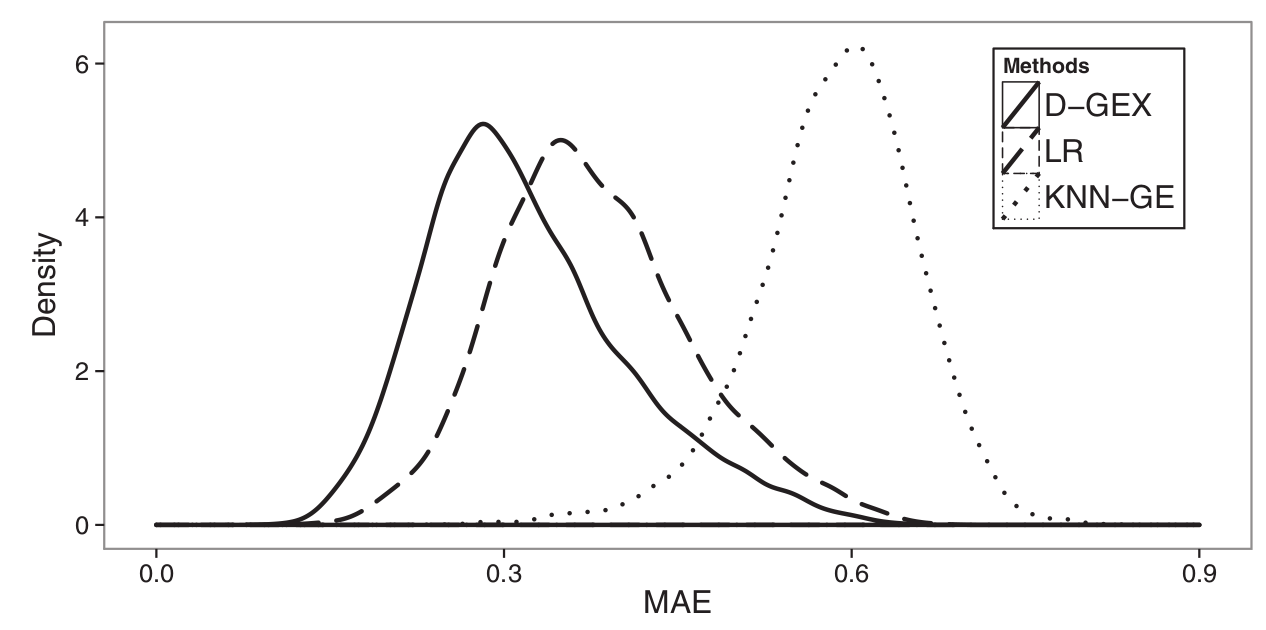
The density plots of the predictive errors of all the target genes by LR, KNN-GE and GEX-10%-9000 3 on GEO-te
2D histogram needed here
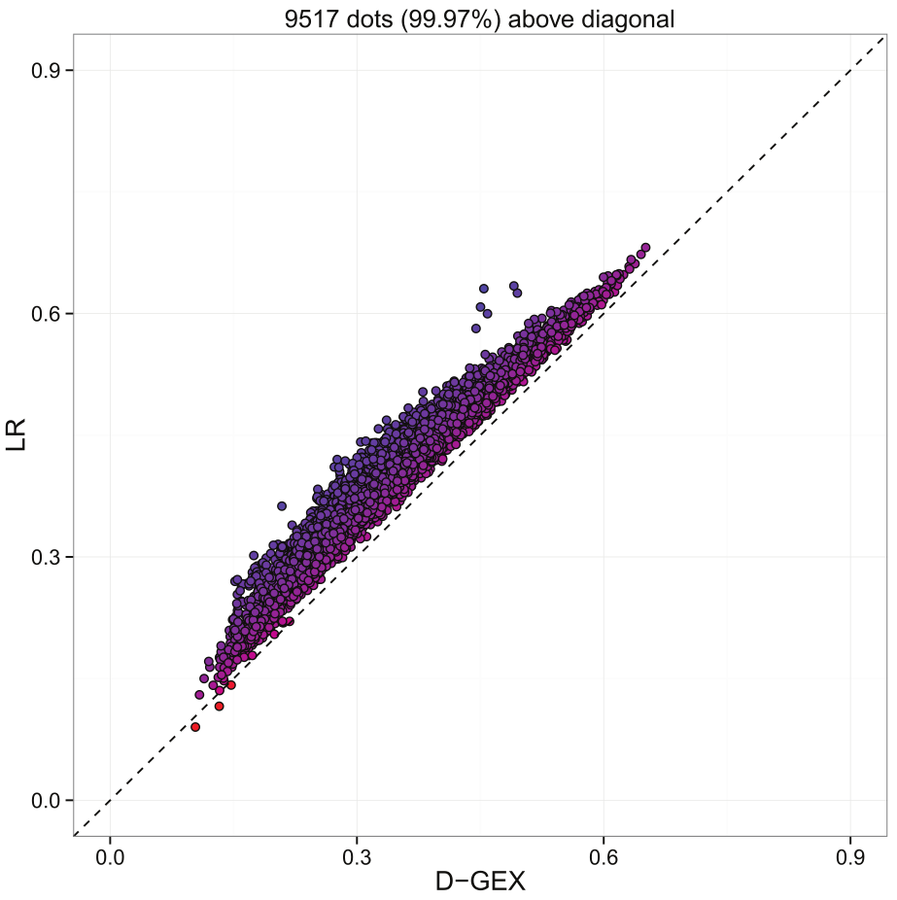
The predictive errors (MAE) of each target gene by GEX-10%-9000 × 3 compared with LR on GEO-te. Each dot represents one out of the 9520 target genes.
See also discussion for the greenelab/deep-review

Everyone agrees that reproducibility and replicability are fundamental characteristics of scientific studies. These topics are attracting increasing attention, scrutiny, and debate both in the popular press and the scientific literature. But there are no formal statistical definitions for these concepts, which leads to confusion since the same words are used for different concepts by different people in different fields. We provide formal and informal definitions of scientific studies, reproducibility, and replicability that can be used to clarify discussions around these concepts in the scientific and popular press.
Publication: Making a public claim on the basis of a scientific study.
Reproducible: Given a population, hypothesis, experimental design, experimenter, data, analysis plan, and code you get the same parameter estimates in a new analysis
Replicable study: Given a population, hypothesis, experimental design, and analysis plan you get consistent estimates when you recollect data and redo the analysis
P-hacking: Given a population, hypothesis, experimental design, experimenter, data, analysis plan, and analyst, the code changes to match a desired statement.
Informal Definitions

Motivated by the Project Rephetio Epilepsy Predictions
WARNING: all rights reserved, use at your own risk.
Funded by CONICET.
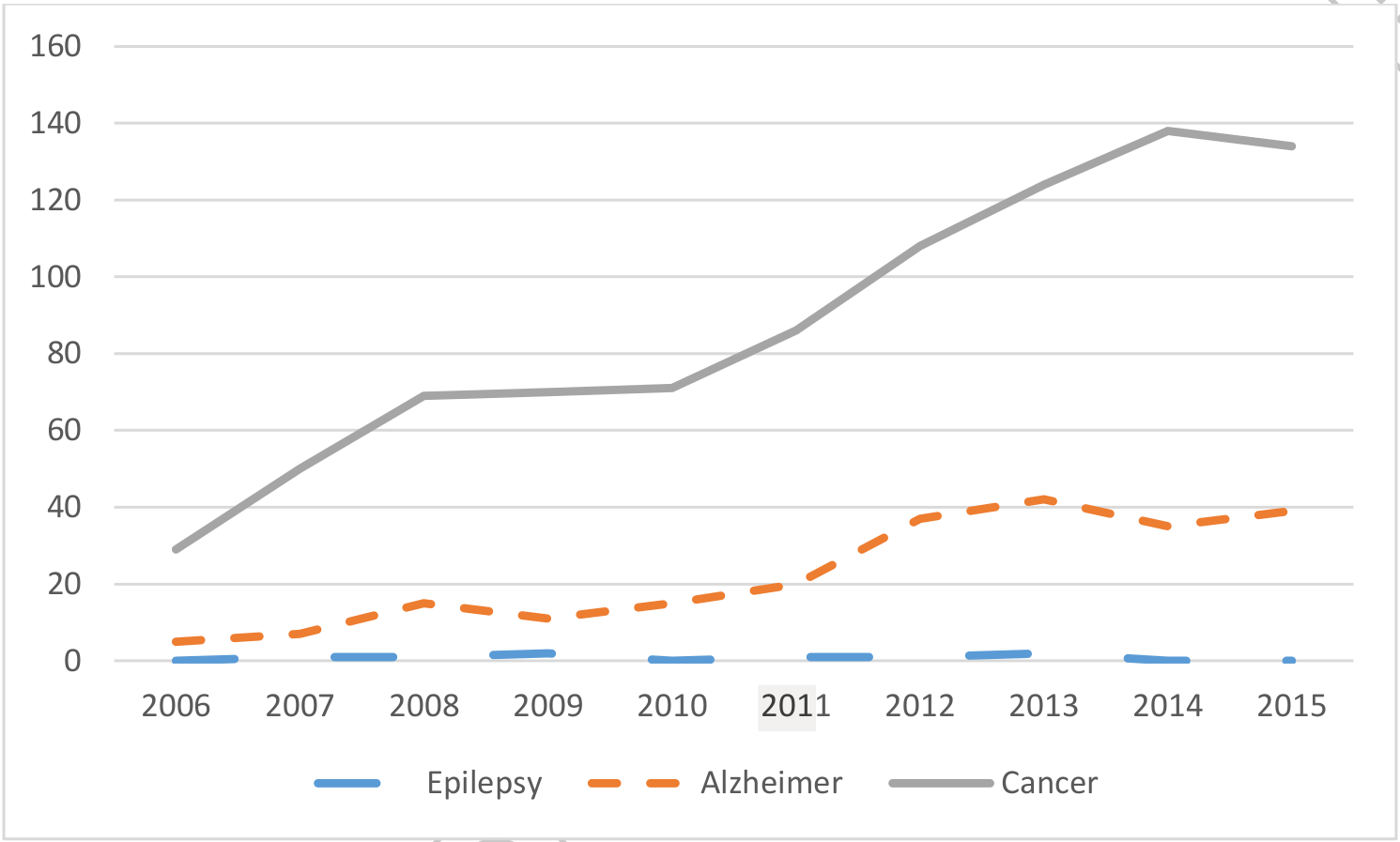
While tailored multi-target agents to address other complex central nervous system conditions (including neurodegenerative diseases and mood disorders) have been abundantly explored, this strategy has been (at most) meagerly applied in the search of novel solutions for epilepsy (Figure 2)