
Slides online at: slides.com
/dhimmel
/rocky
Friday December 9, 2016
10:05–10:15 am (OP 18)
cognition
+
carcinoma
presentation abstract
(as seen on GitHub and the Rocky Program)
Precision oncology requires that we functionally categorize cancers into treatment-relevant subtypes. The predominant approach—characterizing tumors based solely on actionable mutations—struggles to detect complex changes in gene or pathway function. Alternatively, genome-wide expression profiles provide a comprehensive reflection of aberrant cellular states resulting from mutation events. Therefore, we embarked on Project Cognoma to translate between gene expression and mutation in cancer.
Cognoma is an open-source/citizen-science philanthropy being developed as a collaboration between the Greene Lab at Penn and the DataPhilly and Code for Philly meetups. This arrangement leverages the collective fullstack expertise of our diverse contributor base. Hitherto, hundreds of individuals have attended Cognoma meetups, and more than fifty have gotten involved on GitHub. Our priorities are everyone learns something new and putting machine learning in the hands of cancer biologists.
Our product is cognoma.org, a webapp that makes it easy to build mutation status classifiers from gene expression on 7,306 TCGA samples representing 33 cancer types. The publicly available dataset contains RNA-seq gene expression for 20,530 genes, non-silent mutation calls for 21,940 genes, and sample attributes such as the patient's disease, age, sex, and survival. Cognoma enables a cancer biologist to assign each sample a mutation status based on one or more selected genes. Next, a disciplined classifier is trained using gene expression and sample attributes as features. As output, the user receives the importance of each feature—offering insight into the molecular effects of their chosen mutation—as well as a mutation scores for samples—which potentially identify hidden responders to targeted pharmacotherapies.
Authors: Daniel Himmelstein, Gregory Way, Andrew Madonna, Alan Elkner, Benjamin Dolly, Yichuan Liu, Claire McLeod, Derek Goss, Haitao Cai, Chris Fuller, Robert Paul Miller, Nabeel Sarwar, Branka Jokanovic, Mans Singh, Stephen Shank, Joel Eden, Karin Wolok, Casey Greene
putting machine learning in the hands of cancer biologists
Cognoma Motto 1


machine learning
Predicting cancer mutations from gene expression

Using public domain TCGA data
(from Xena Browser)
7,306 samples
20,468 genes with expression
RNA-Seq
21,960 genes with mutation.
Sequencing
covariates

elastic net logistic regression
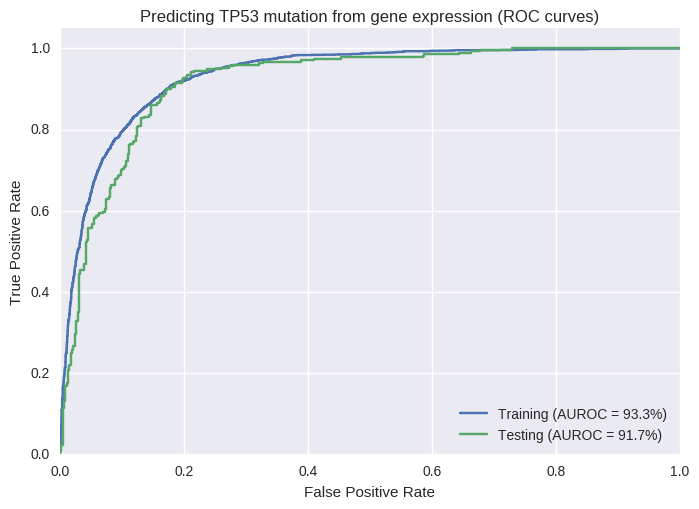
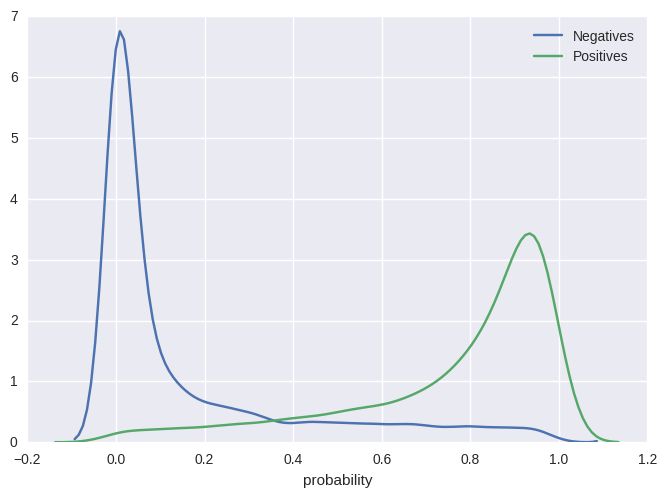
TP53
- tumor protein p53
- tumor suppressor protein
- 35% of samples mutated
| Sample | Organ | Mutation | Prediction |
|---|
| 0 |
| 0 |
| 0 |
| 0 |
| 0 |
| 0 |
| 0 |
| 99.2% |
| 99.2% |
| 99.1% |
| 98.8% |
| 98.4% |
| 98.4% |
| 98.2% |
| Esophagus |
| Esophagus |
| Ovary |
| Breast |
| Lung |
| Esophagus |
| Rectum |
| TCGA-L5-A8NR-01 |
| TCGA-L5-A4OH-01 |
| TCGA-09-2051-01 |
| TCGA-B6-A0I6-01 |
| TCGA-55-6981-01 |
| TCGA-L5-A4OO-01 |
| TCGA-EI-6513-01 |
Could gene expression identify hidden responders?
- 70+ targeted cancer therapies approved by the FDA
everyone learns something new
Cognoma Motto 2

Pull requests model for contribution

Contribution per user by GitHub repository
Full Stack Data Science
Four teams:
- Cancer data
- Machine learning
- Backend
- Frontend


Thanks!
Organization Members: Andrew Madonna, Benjamin Dolly, Gregory Way, Casey Greene, Karin Wolok, Jesse Prestwood-Taylor, Claire McLeod, Stephen Shank, Josh Levy, Yichuan Liu, Derek Goss, Tanner Wells & many more at https://git.io/v65k6.