statistical forays of a modern biodata scientist
my left hemisphere imagining motion by Anisha Keshavan
September 4, 2015
Online at slides.com/dhimmel/statistical-forays
Original content released under CC0, attribution via hyperlink
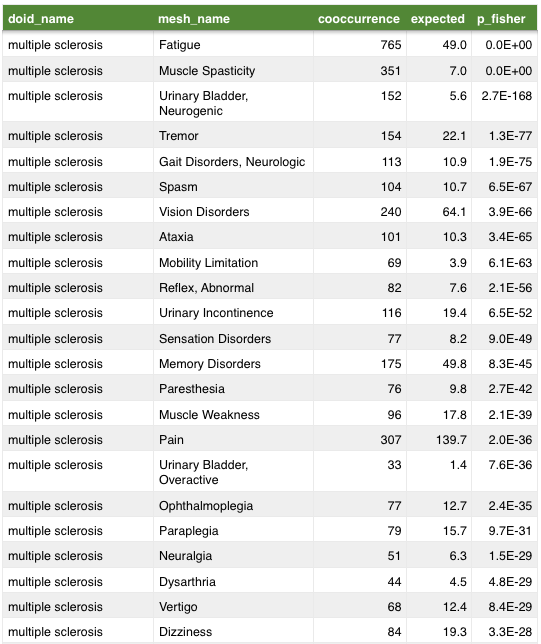
MEDLINE Topic Cooccurrence
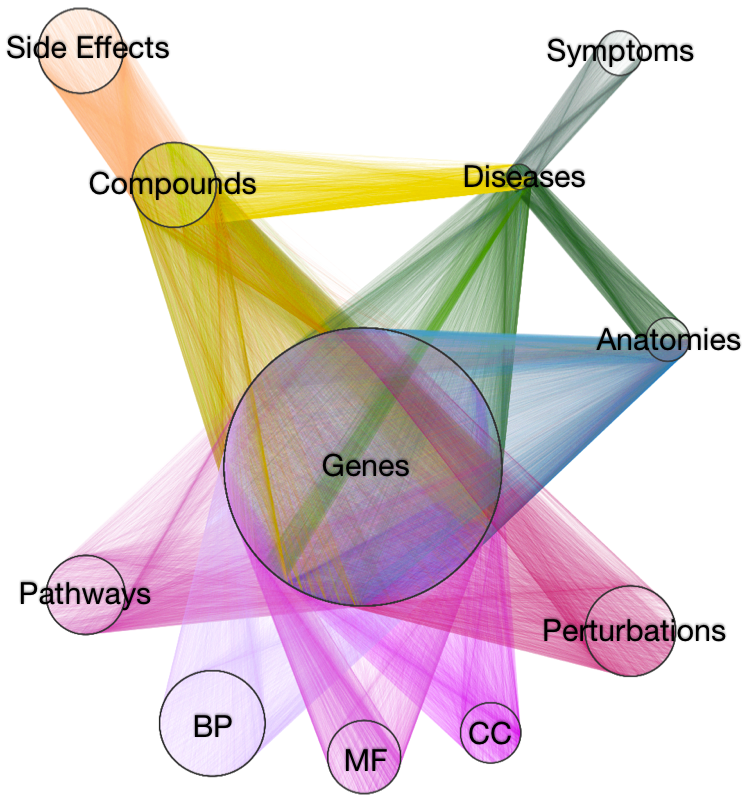
MEDLINE topics
http://thinklab.com/d/67
- curators read abstracts and annotate topics
- 21 million articles
-
5,594 journals
- cooccurence of two topics indicates a relation
Contingency Table
Independence of variables test:
- Fisher's exact test
- chi-squared goodness-of-fit
- Barnard's test

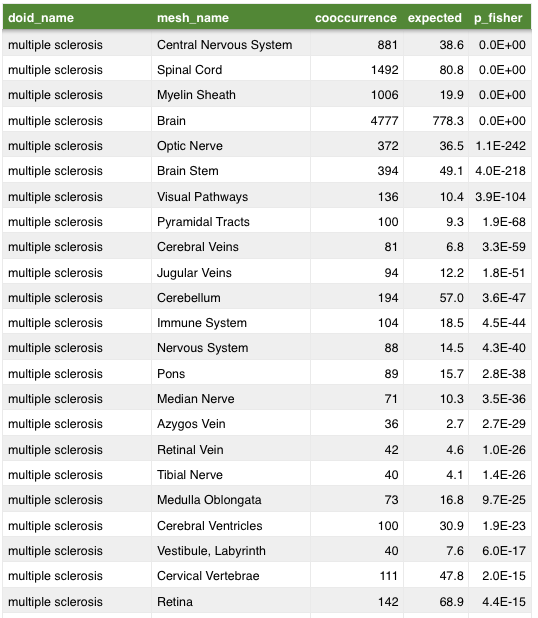
anatomy
symptom
Mining MEDLINE for disease context
meta-analysis
Combining measures of significance:
- p-values — Fisher's method
- z-scores — Stouffer's method
Combining measures of effect size:
- weighted average
- fixed effects model
- random effects model
LINCS L1000
← genes →
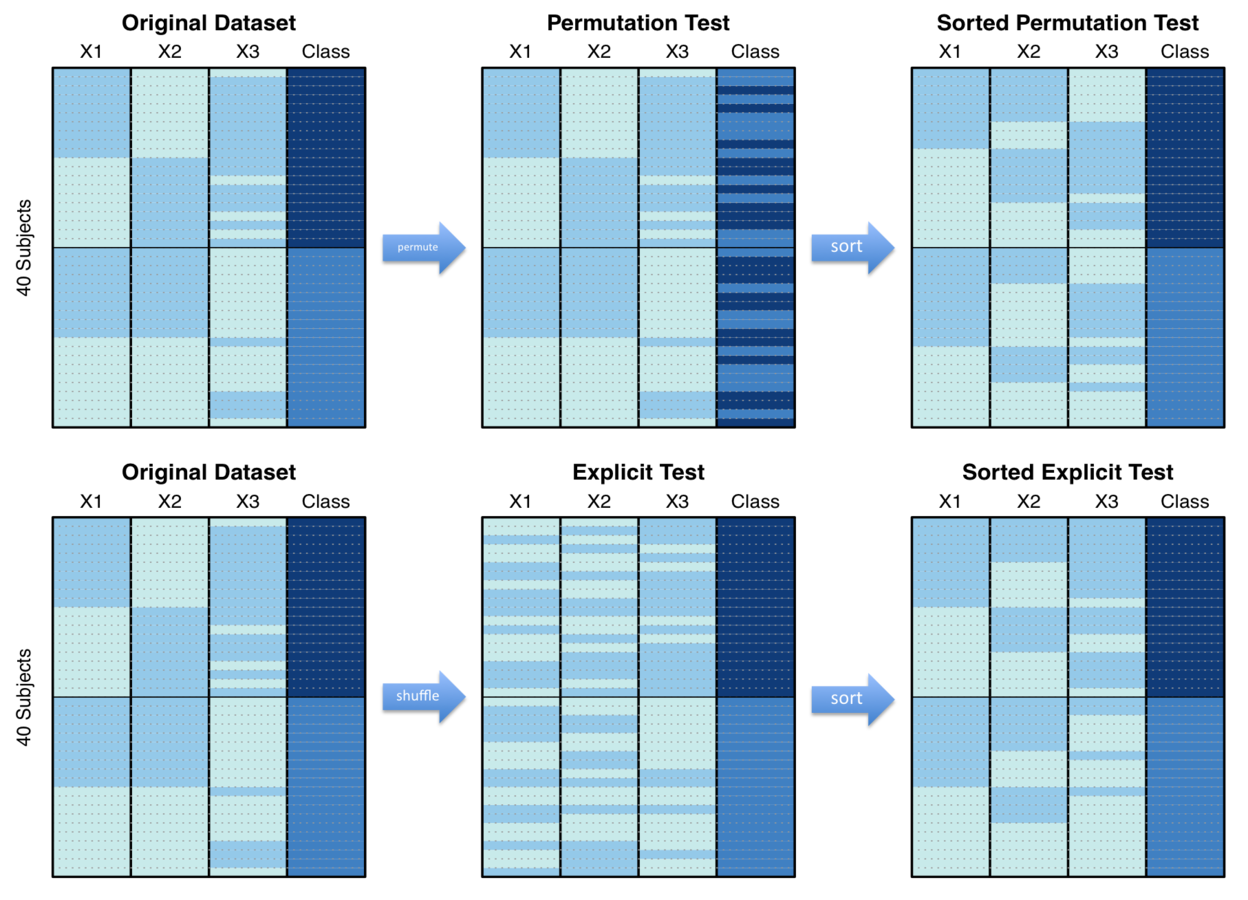
permutation testing
Network edge swaps
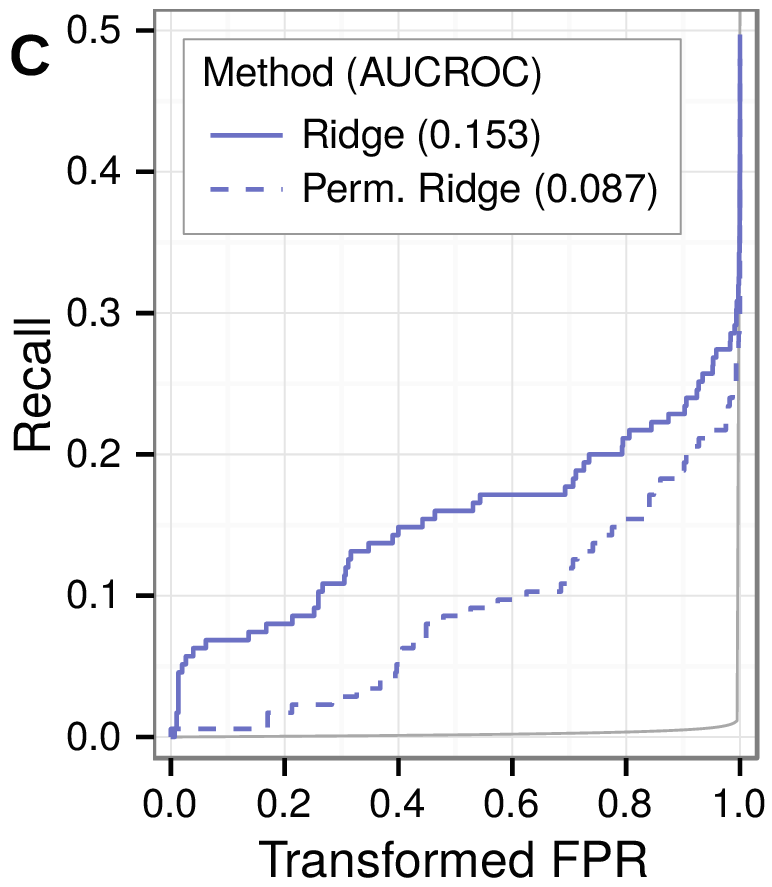
machine learning
Say no to models that overfit
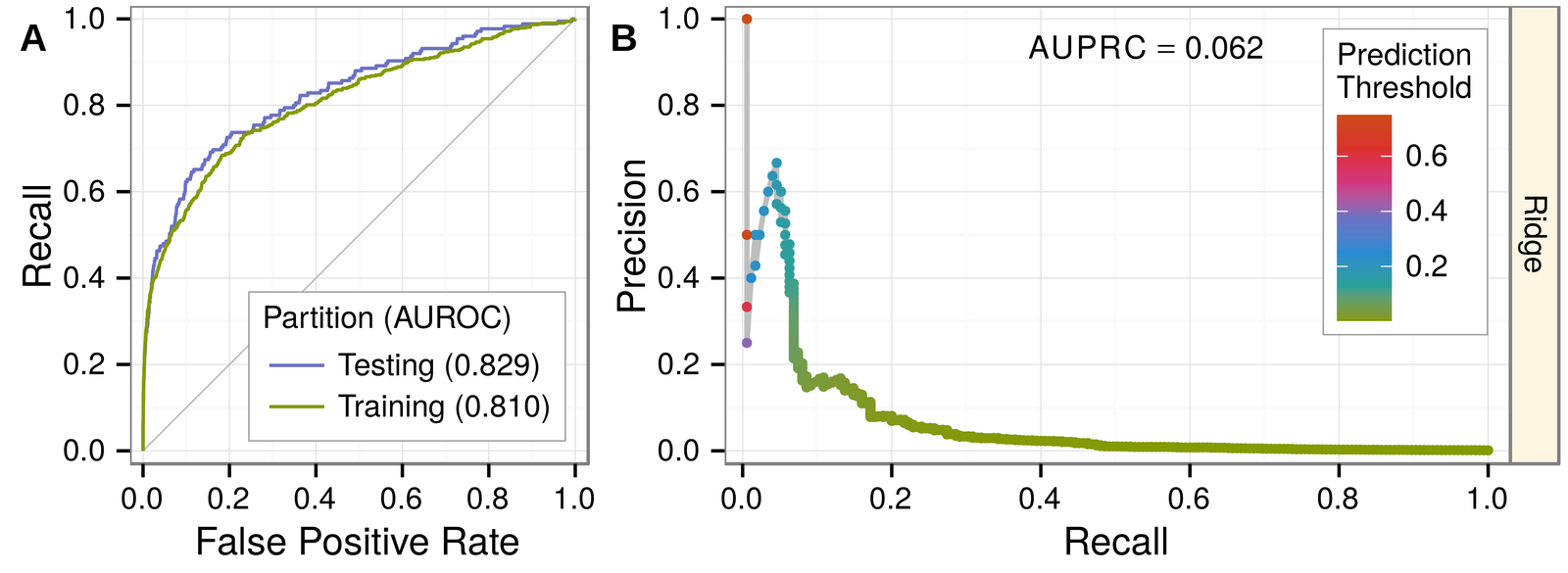
Look for:
testing performance ≈ training performance
But still:
evaluate performance based on testing
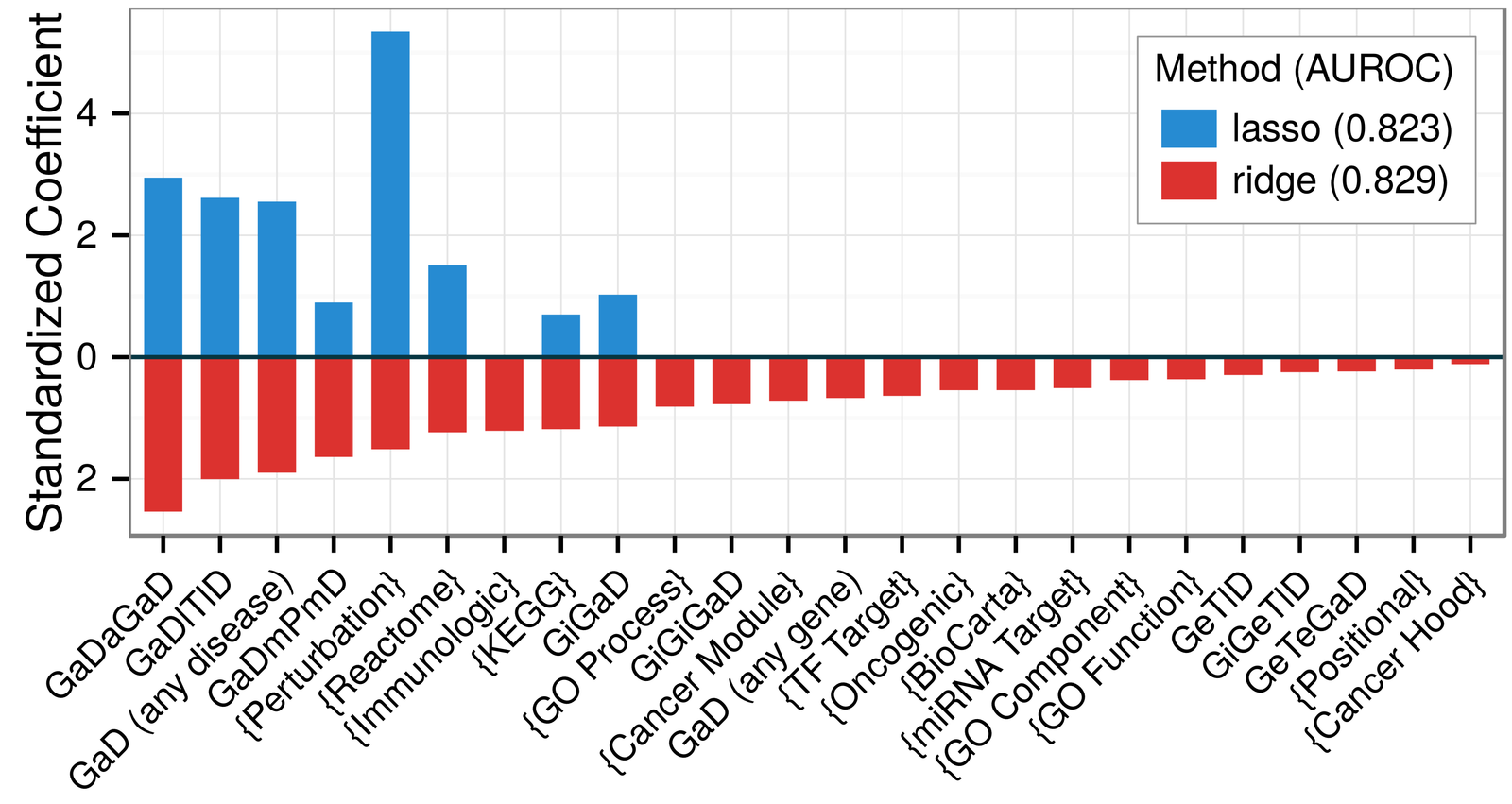
Regularized regression:
- prevents overfitting
- glmnet package in R
- ridge -- coefficient shrinkage
- lasso -- coefficient shrinkage & variable selection
There are two cultures in the use of statistical modeling to reach conclusions from data. One assumes that the data are generated by a given stochastic data model. The other uses algorithmic models and treats the data mechanism as unknown. The statistical community has been committed to the almost exclusive use of data models. This commitment has led to irrelevant theory, questionable conclusions, and has kept statisticians from working on a large range of interesting current problems. Algorithmic modeling, both in theory and practice, has developed rapidly in fields outside statistics. It can be used both on large complex data sets and as a more accurate and informative alternative to data modeling on smaller data sets. If our goal as a field is to use data to solve problems, then we need to move away from exclusive dependence on data models and adopt a more diverse set of tools.
Leo Breiman (2001) Statistical Modeling: The Two Cultures. Statistical Science

Sandler Neurosciences Center

Sergio

Lab retreat in Tahoe
Northstar California Resort
February 2015
Egle Cekanaviciute