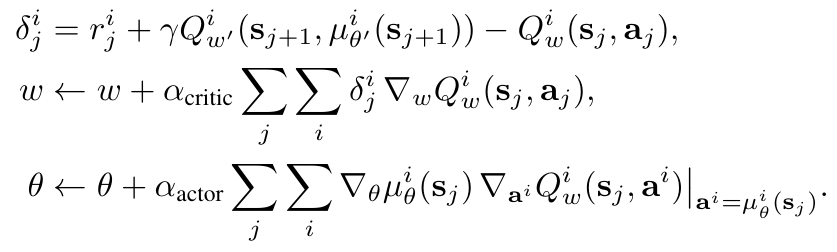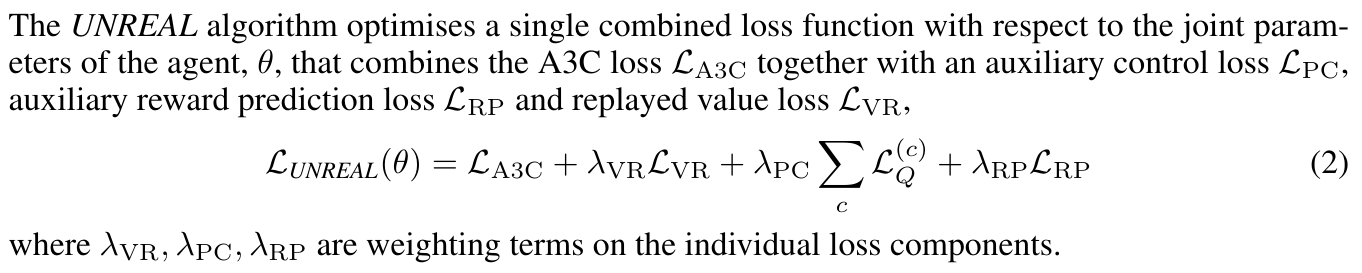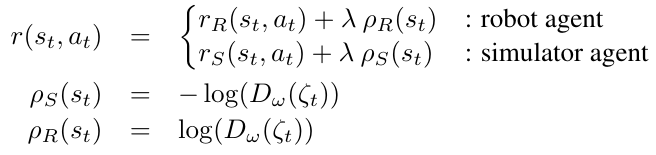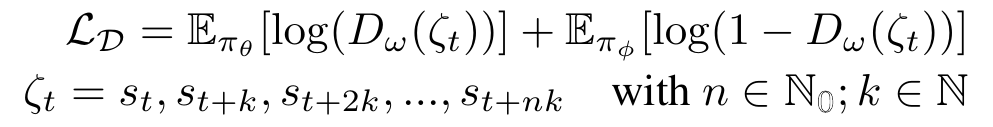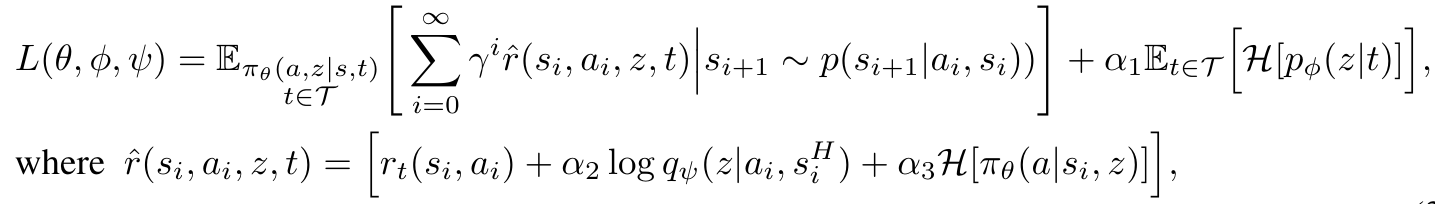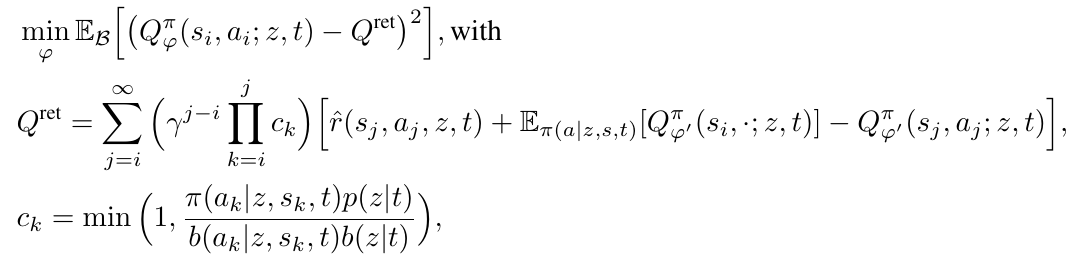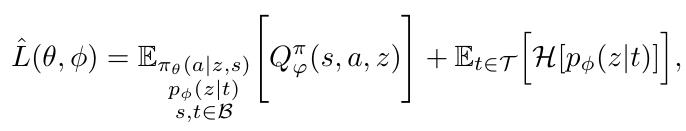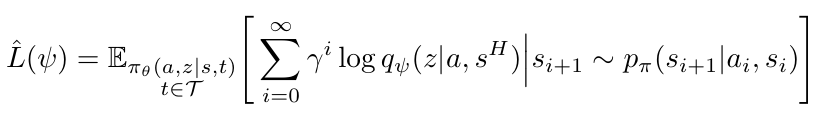Transfer & Multi-Task: Advanced RL @ YSDA, Spring 2020
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
Dmitry Nikulin | 30 April
Learn task A, then use that to learn task B faster.
based on http://arxiv.org/abs/1910.10897
Reach state \( g \):
\[ \begin{aligned} R_g(s, a, s') &= \mathbb{I} \left[ s' = g \right] \\ \gamma_g(s) &= 0.99 \cdot \mathbb{I} \left[ s \neq g \right] \end{aligned} \]
i.e. \( g \) becomes a pseudo-terminal state.
(this is pretty much the only case where \( \gamma \) is non-constant)
There is no standard benchmark in Multitask/Transfer.
Each paper rolls out their own evaluation.
Discrete actions: train a single agent to play multiple Atari games (select those where your results are most convincing).
Optionally: a Quake 3 fork.
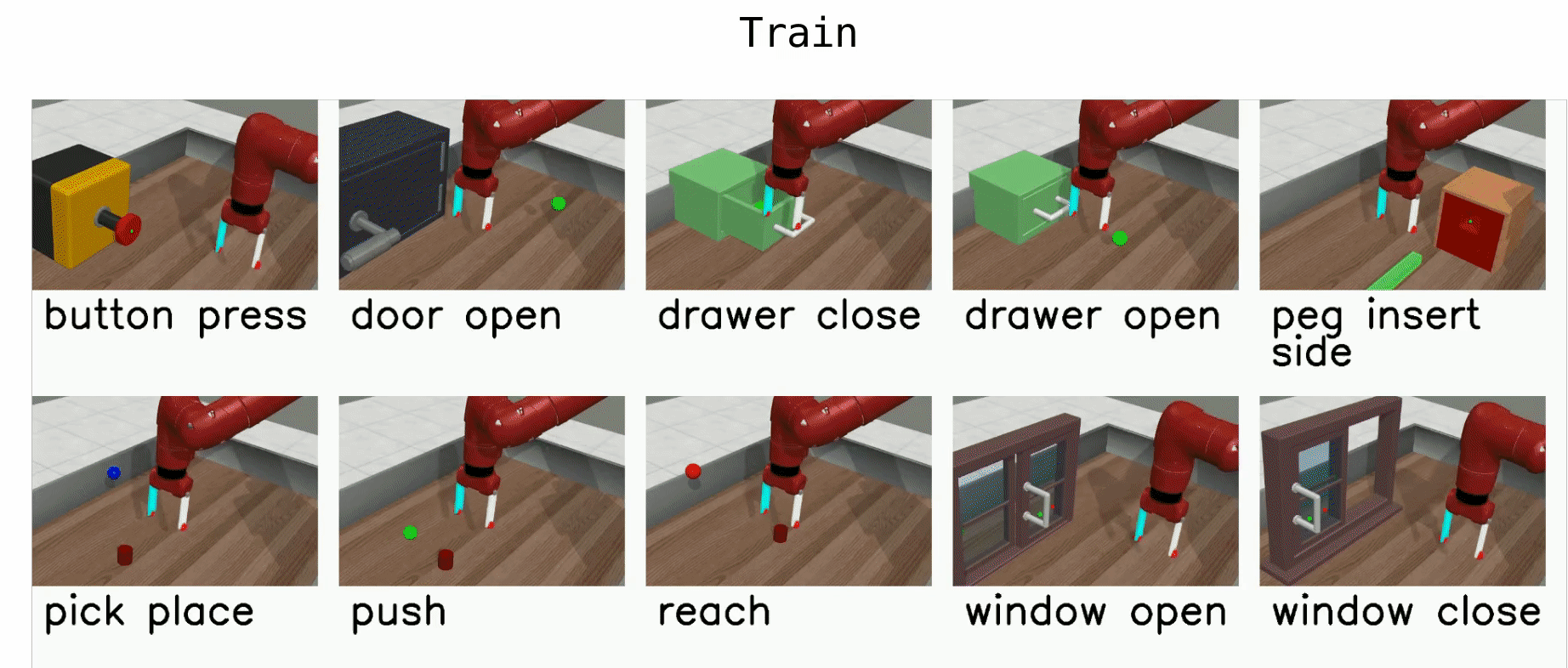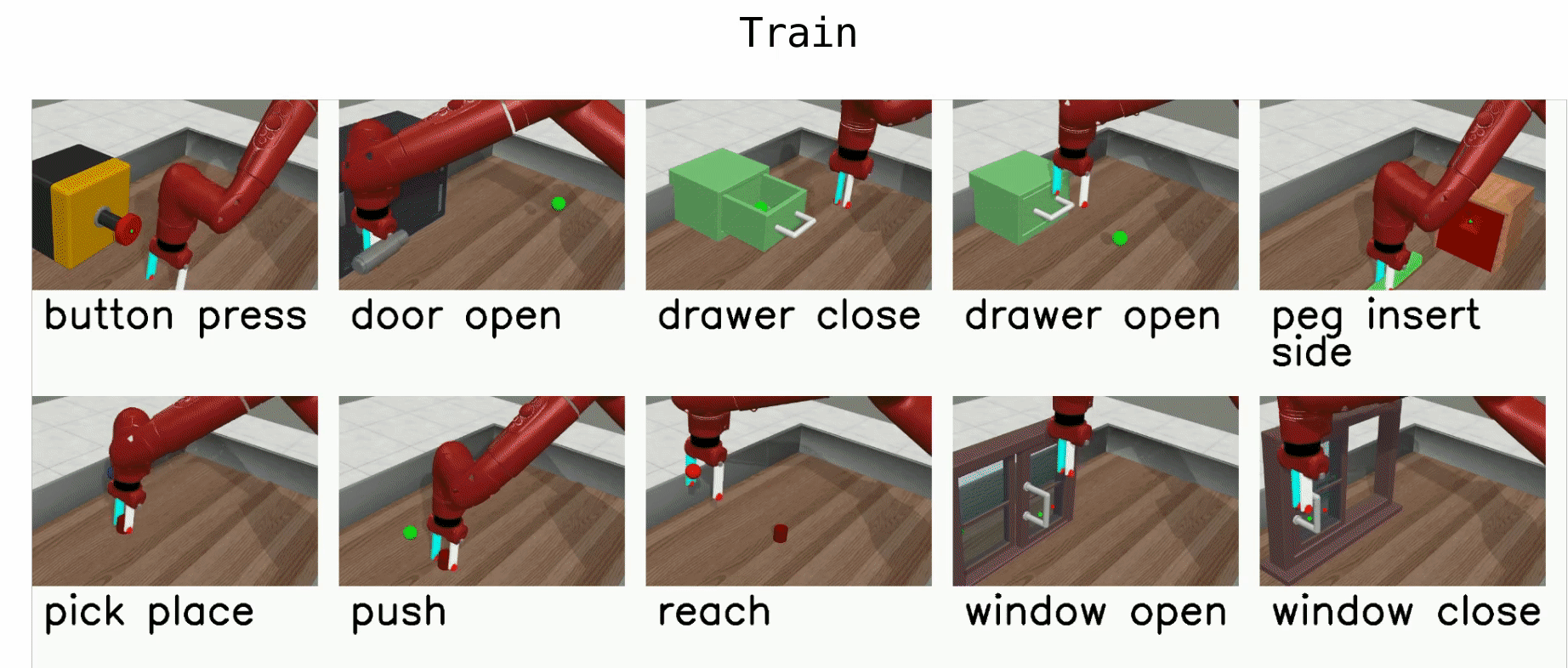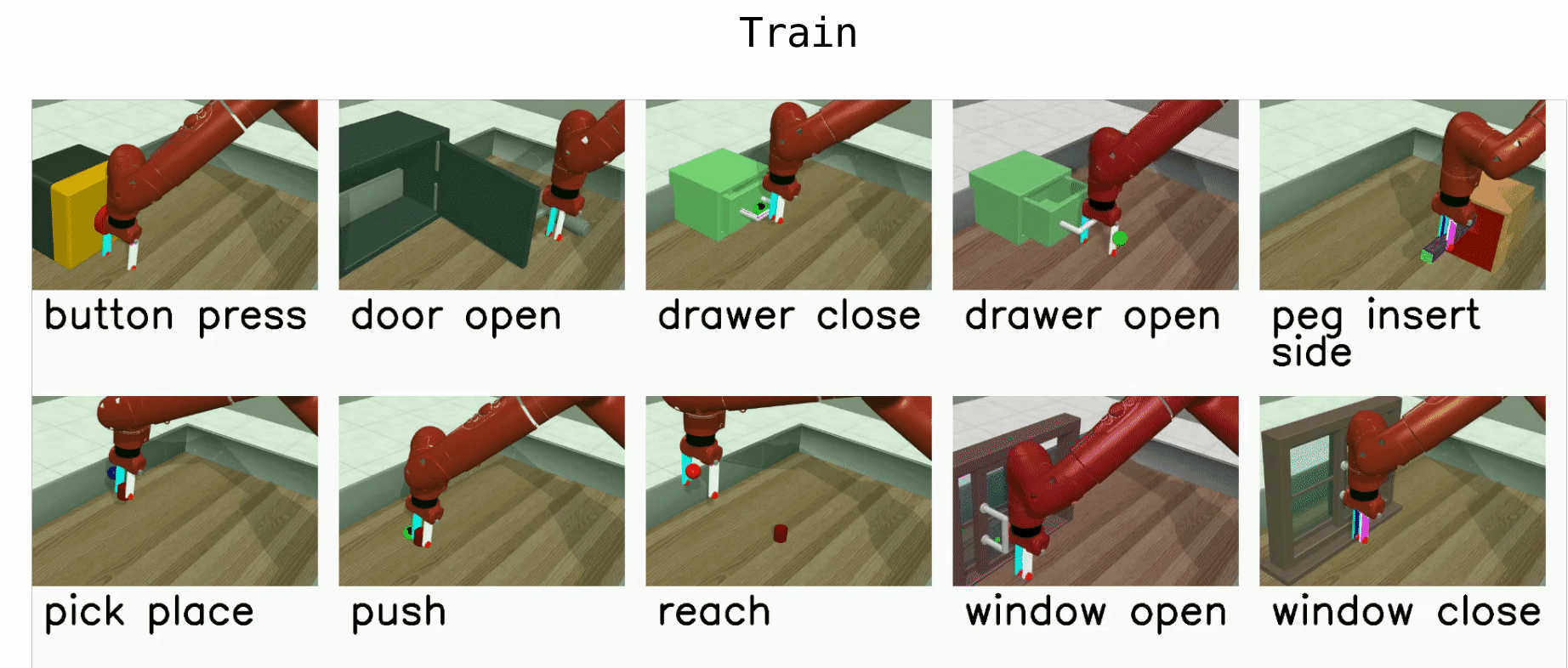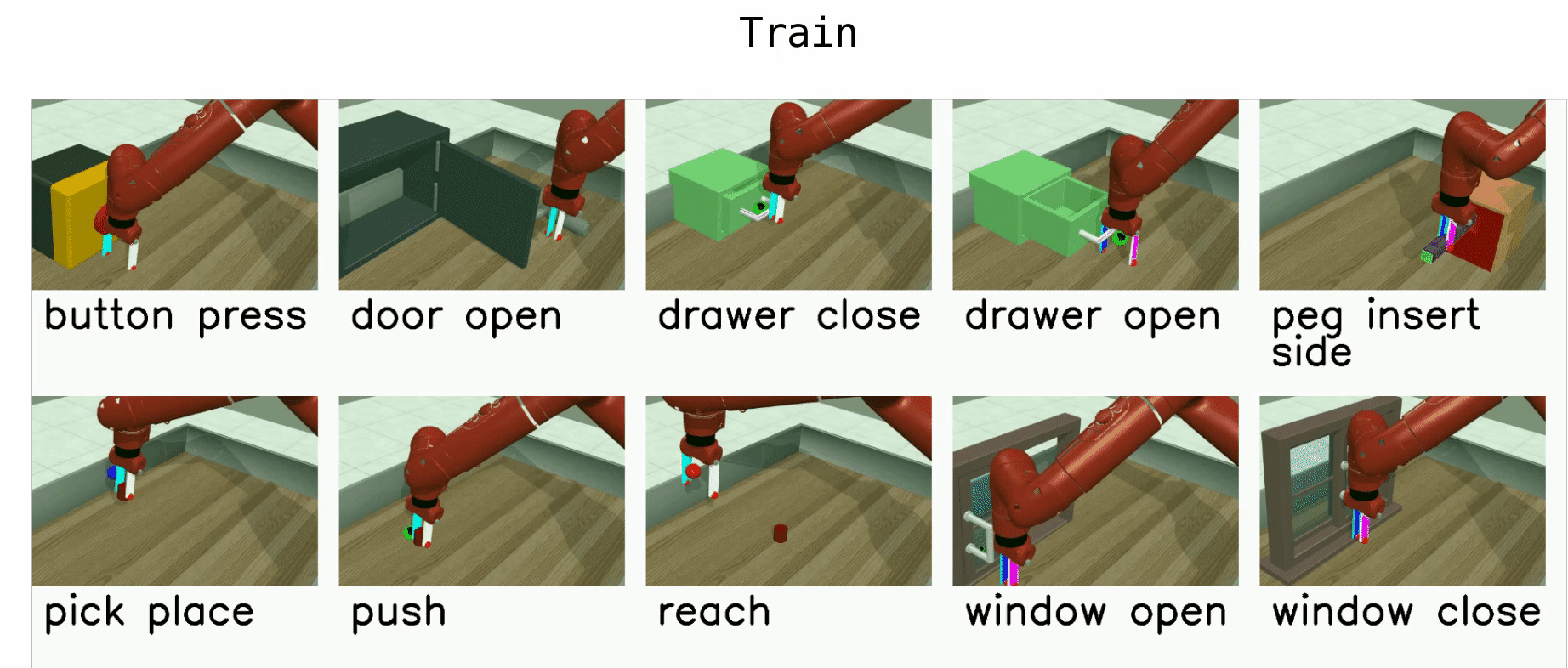
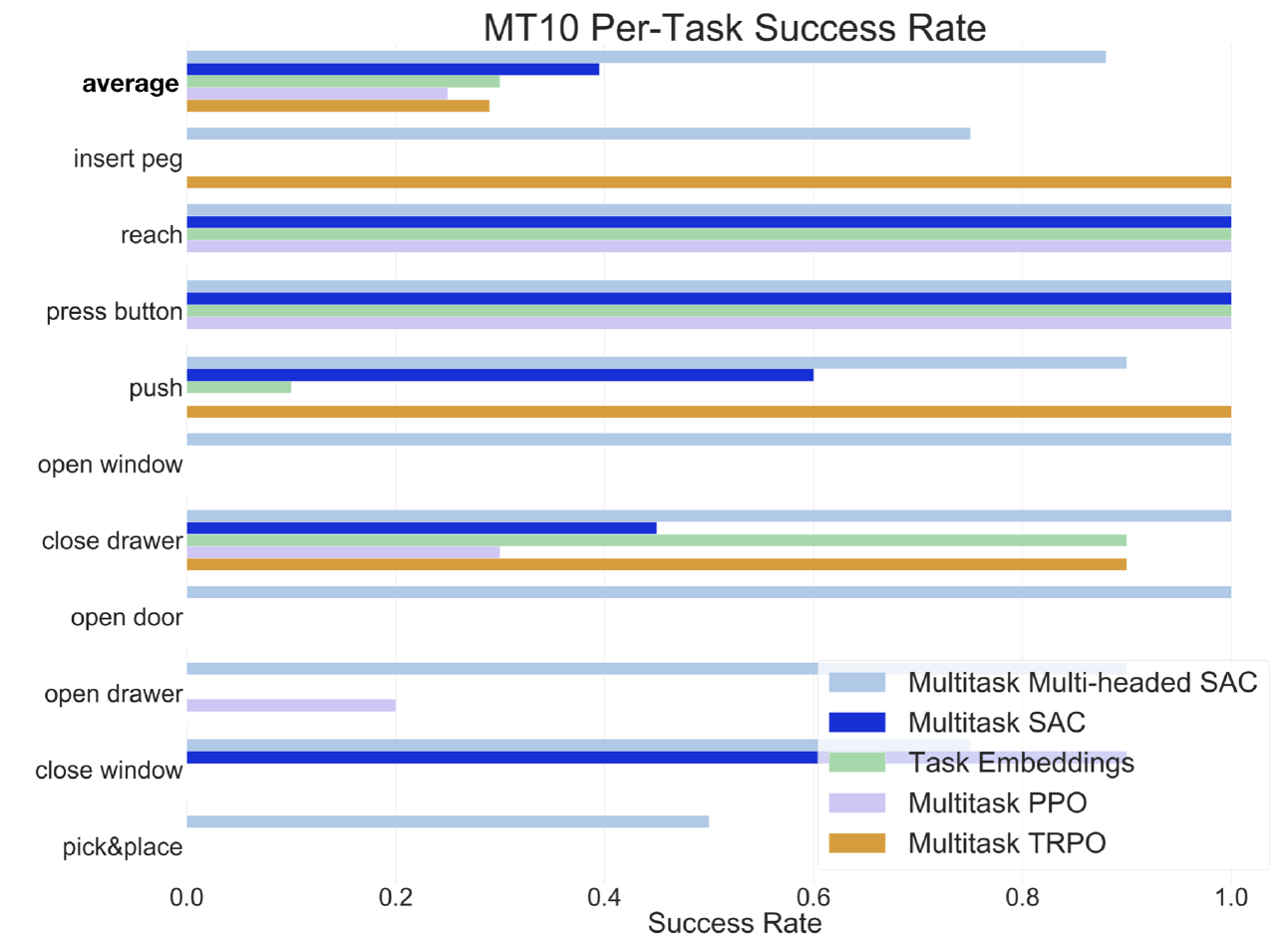
Yu et al. (Stanford & co), CoRL 2019, 263 GitHub stars
But:
Schaul et al. (DeepMind), ICML 2015, 319 citations
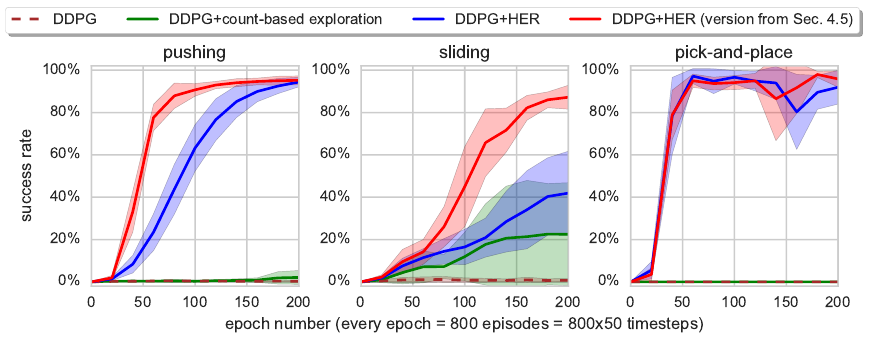
Andrychowicz et al. (OpenAI), NIPS 2017, 512 citations
Motivating example:
tl;dr: very large state space with very sparse rewards, but easy to solve once we figure it out.
🚲 Evaluation: custom robotic arm manipulation environment based on MuJoCo
Cabi et al. (DeepMind), CoRL 2017, 17 citations
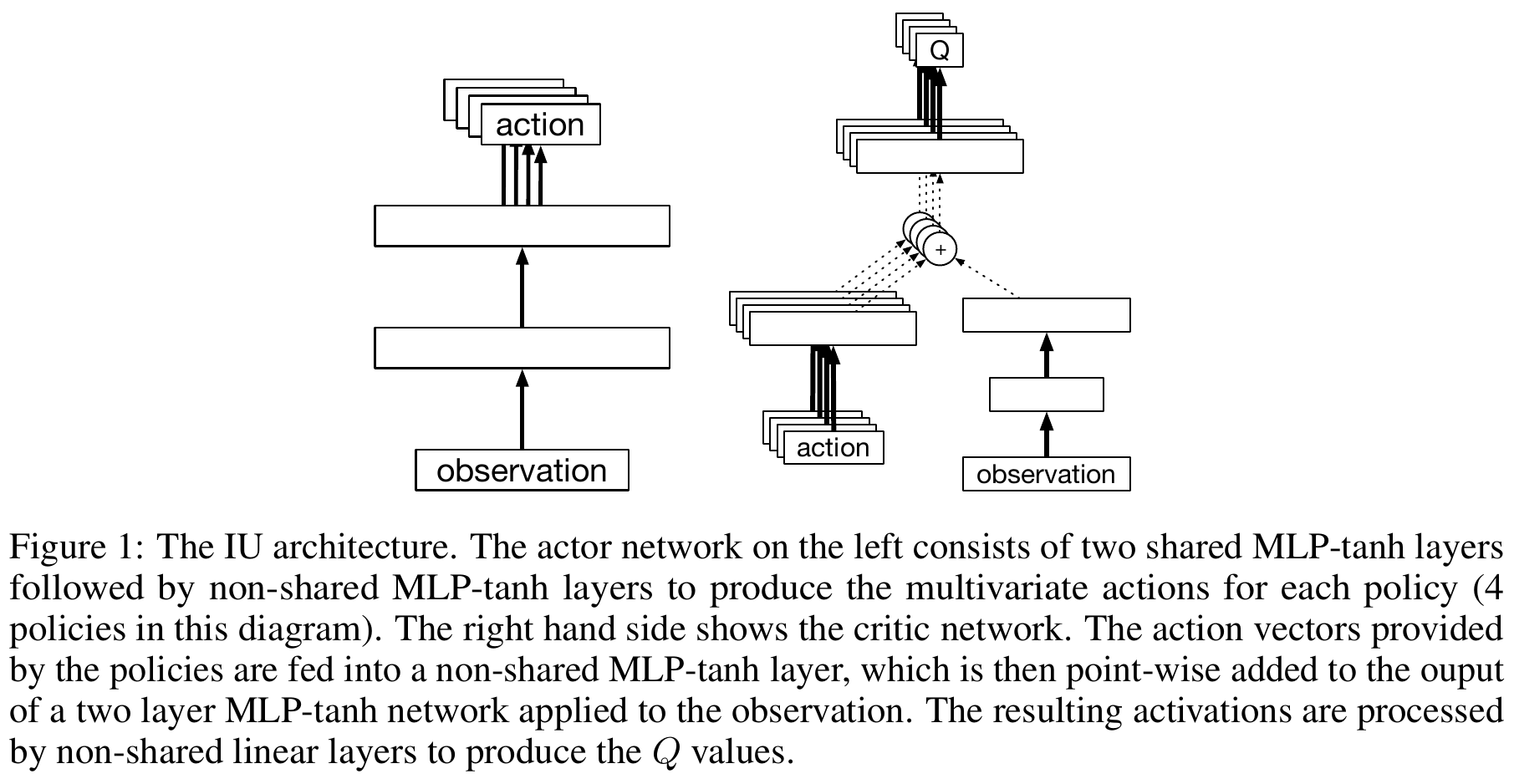
tl;dr: train a bunch of DDPG instances in parallel on one stream of experience while executing one of the policies being trained.
(intentional = behavioral policy, unintentional = other policies)
\( \theta \) — actor parameters
\( w \) — critic parameters (\( w' \) — target network)
\( i \) — index of a policy that solves \(i\)-th task
\( j \) — timestep
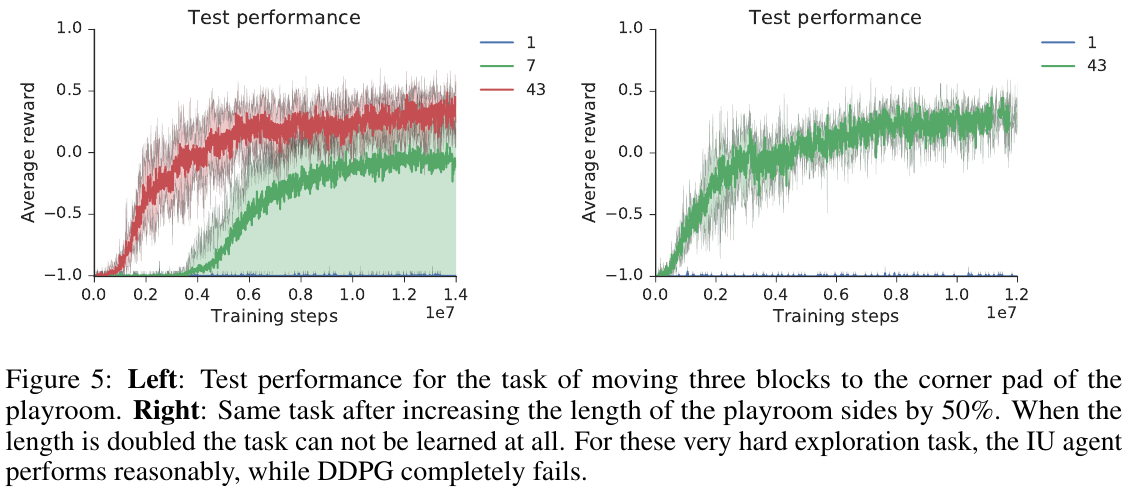
🚲 Evaluation:
Example tasks:
Results:
Jaderberg et al. (DeepMind), ICLR 2017, 508 citations
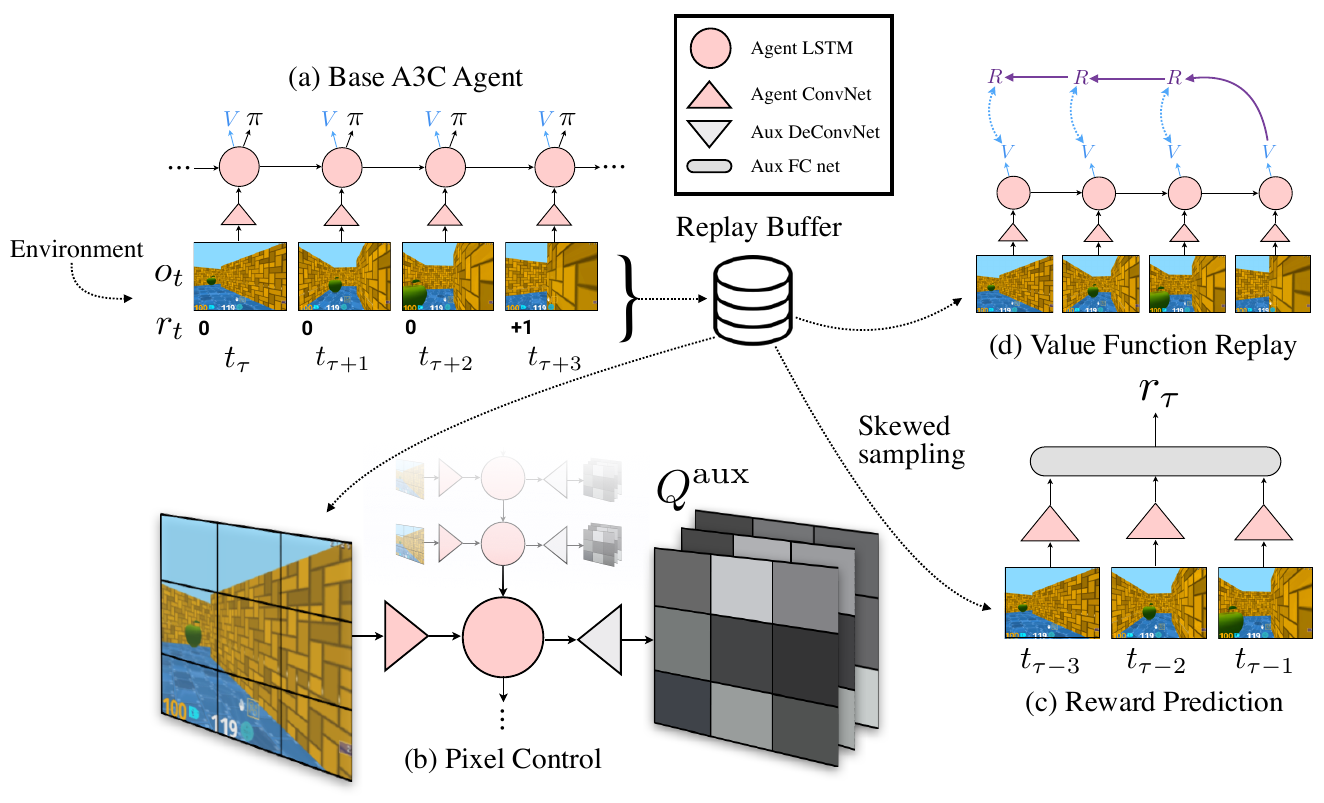
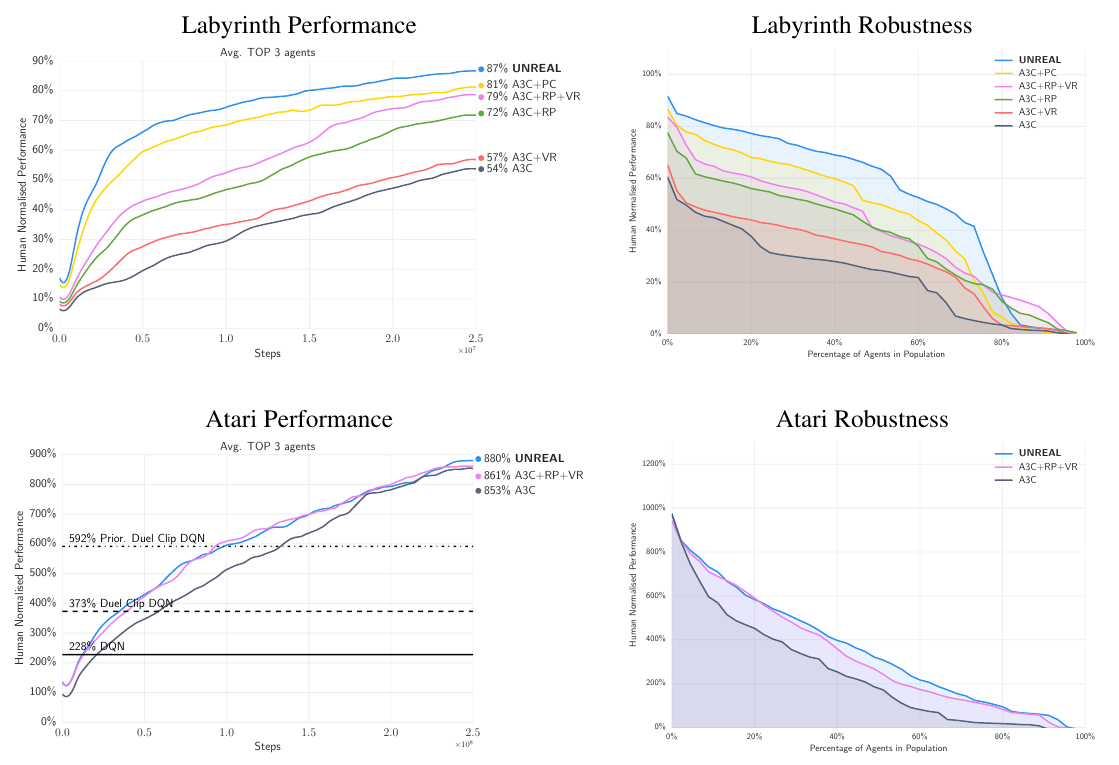
Train an A3C agent with a bunch of synthetic goals optimized via Q-learning:
Auxiliary control tasks:
Auxiliary reward prediction:
Auxiliary value function replay:
another illustration: https://github.com/miyosuda/unreal
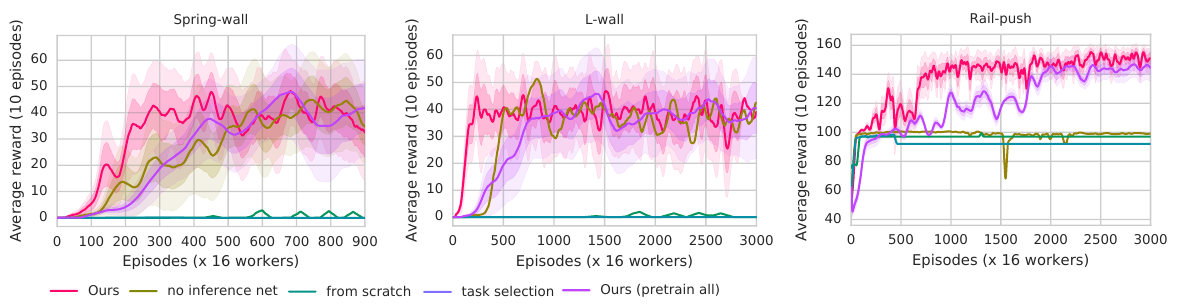
Wulfmeier et al. (BAIR), CoRL 2017, 27 citations
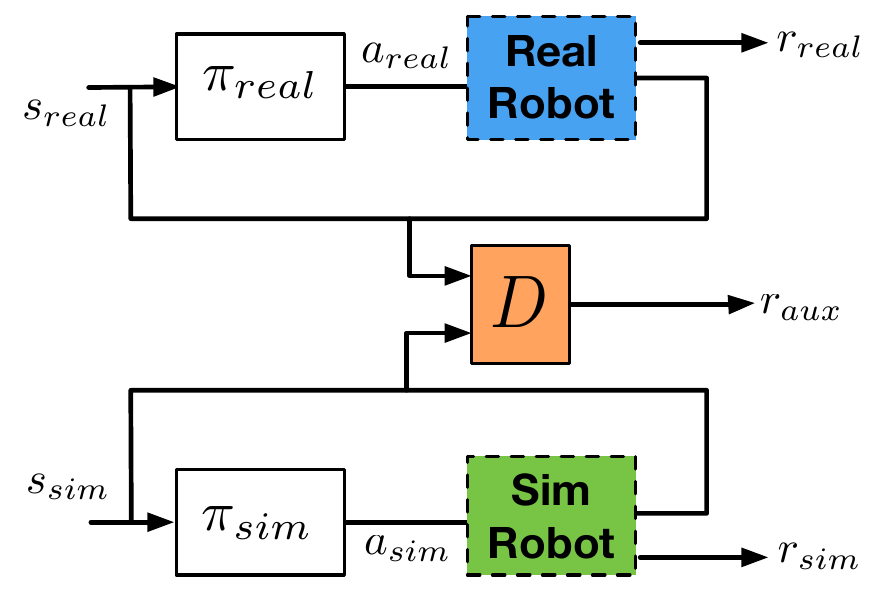
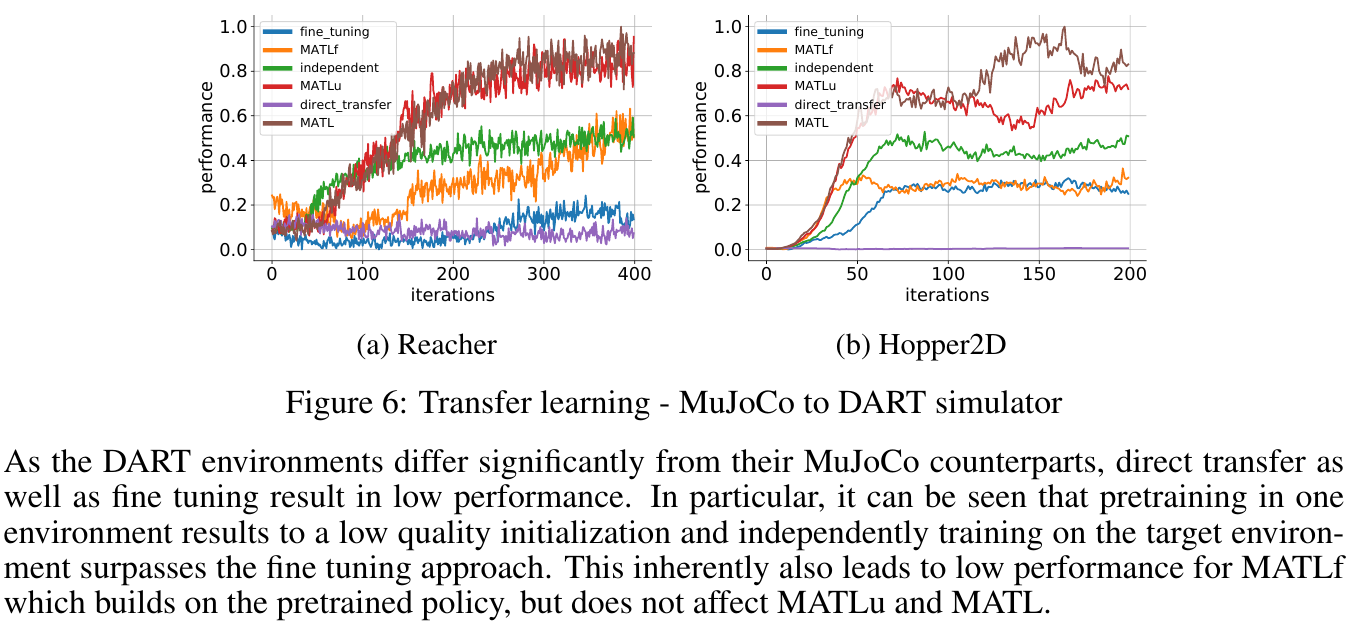
🚲 Evaluation: transfer between two different simulators.
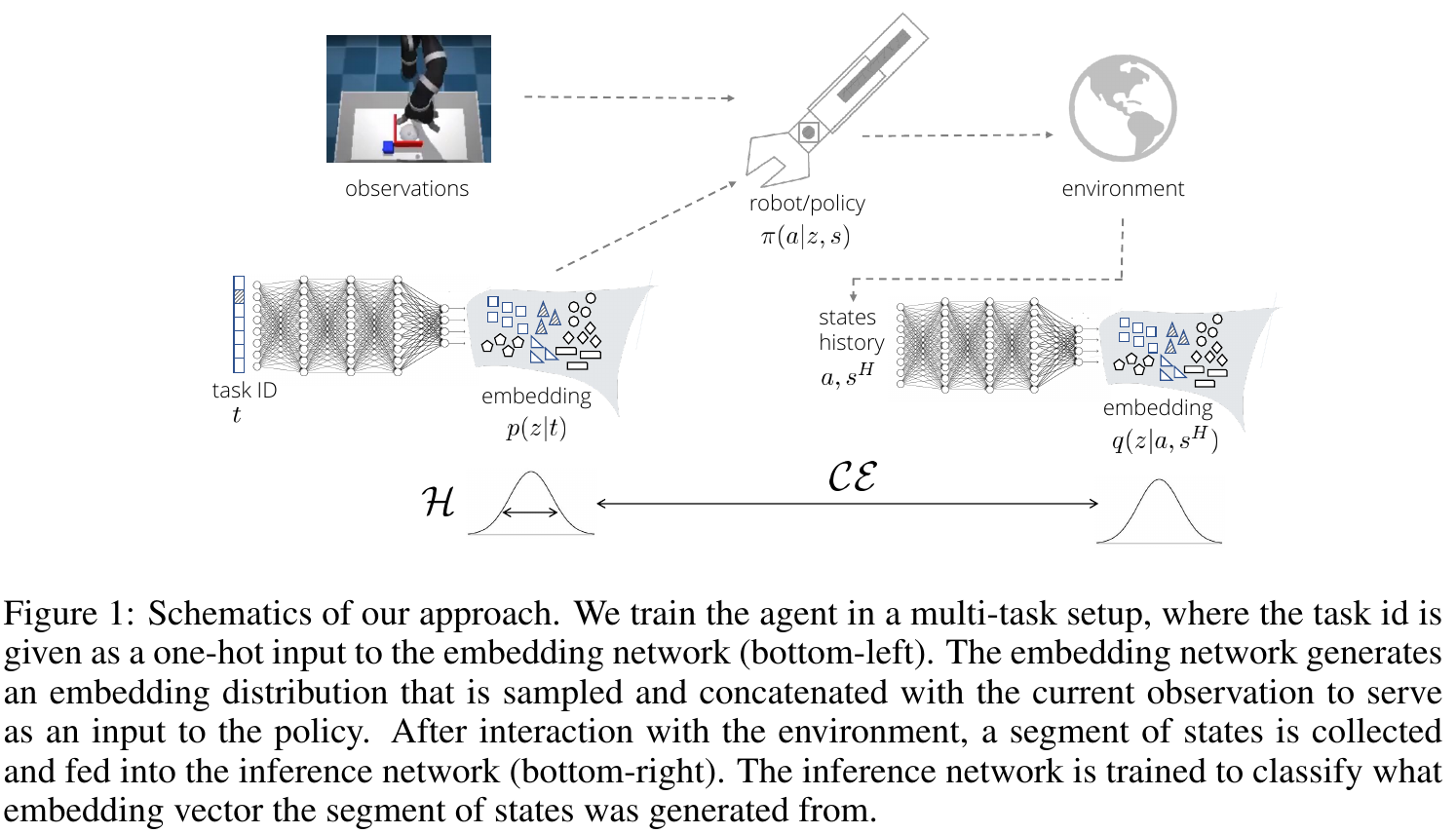
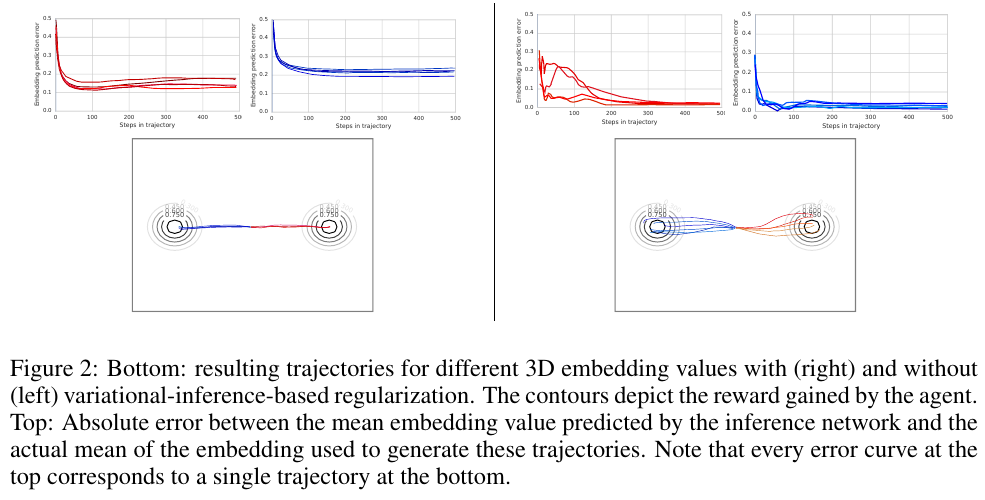
Hausman et al. (DeepMind), ICLR 2018, 76 citations
In training, the following is maximized:
env. reward
log-likelihood of true \( z \)
policy entropy
embedding entropy
(this is actually maximization of a lower bound on return of an entropy-regularized policy via variational inference)
For \( p_\phi \) and \( \pi_\theta \), this is done by learning a function \( Q_\varphi^\pi \) on the replay buffer with an off-policy correction:
and then maximizing:
For \( q_\psi \) (inference network), we maximize:
This is supervised learning, done offline, using the replay buffer.
The term for log-likelihood of true \( z \) in agent's reward helps generate more diverse trajectories:
🚲 Evaluation: transfer learning for robotic manipulation.
* text actually says "state-embedding network \( z = f_\vartheta(x) \)", but this seems to be a mistake
Rusu et al. (DeepMind), arXiv 2016, 592 citations
\( h_i^{(k)} = \operatorname{ReLU} \left( W_i^{(k)} h_{i-1}^{(k)} + \sum_{j = 1}^{k - 1} \operatorname{MLP}_i^{(k:j)} \left( h^{(j)}_{i - 1} \right) \right) \), where
\(i\) — layer index
\(j, k\) — column indices
\( \operatorname{MLP}_i^{(k:j)} \left( h^{(j)}_{i - 1} \right) = U_i^{(k:j)} \sigma \left( P_i^{(k:j)} \alpha_{i - 1}^{(j)} h^{(j)}_{i - 1} \right) \)
\( W_i^{(k)} \), \( U_i^{(k:j)} \) — linear layers
\( P_i^{(k:j)} \) — projection matrix
\( \alpha_{i - 1}^{(j)} \) — learnable scalar
\( \sigma \) — some nonlinearity
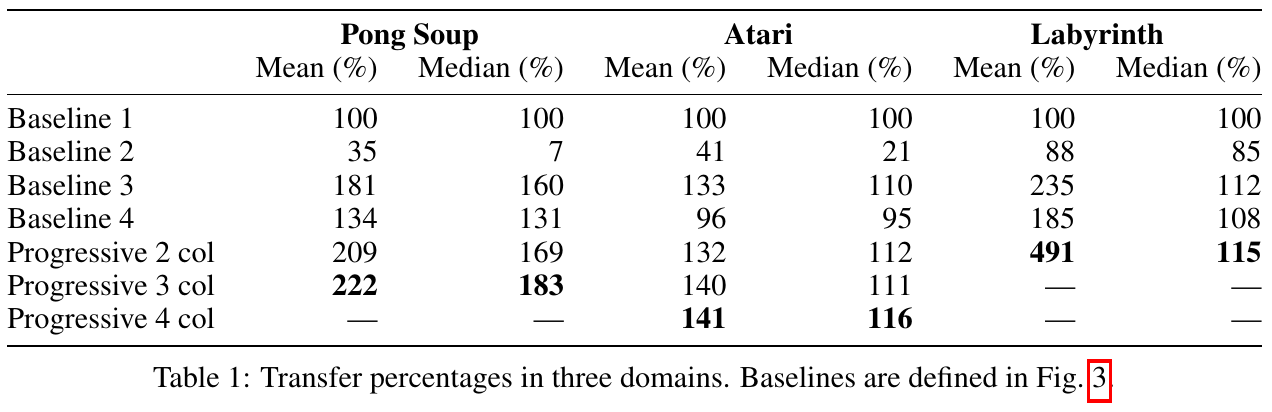
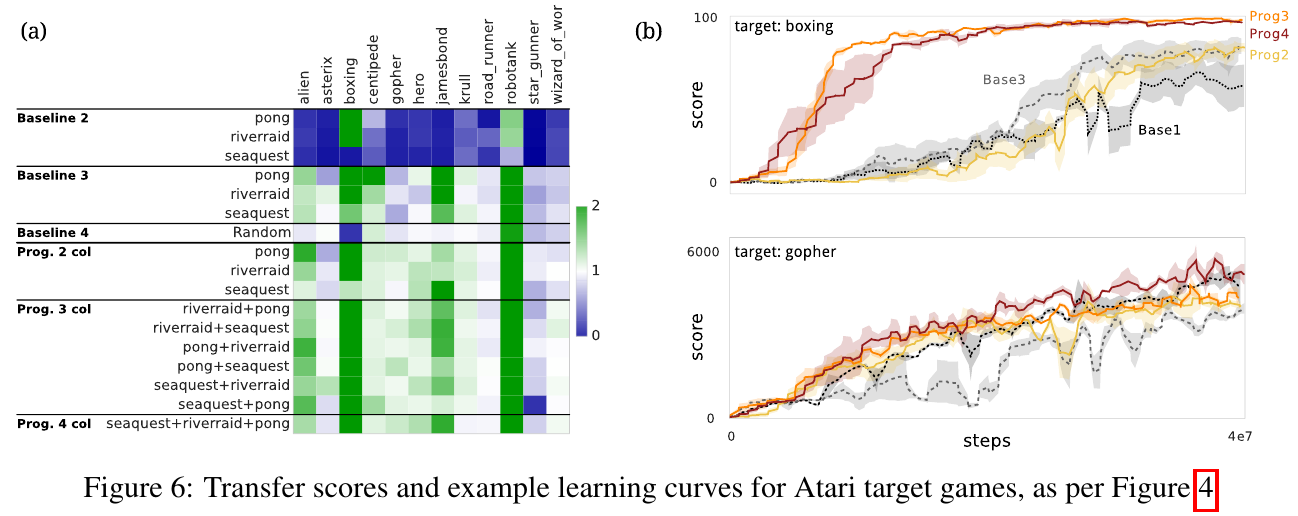
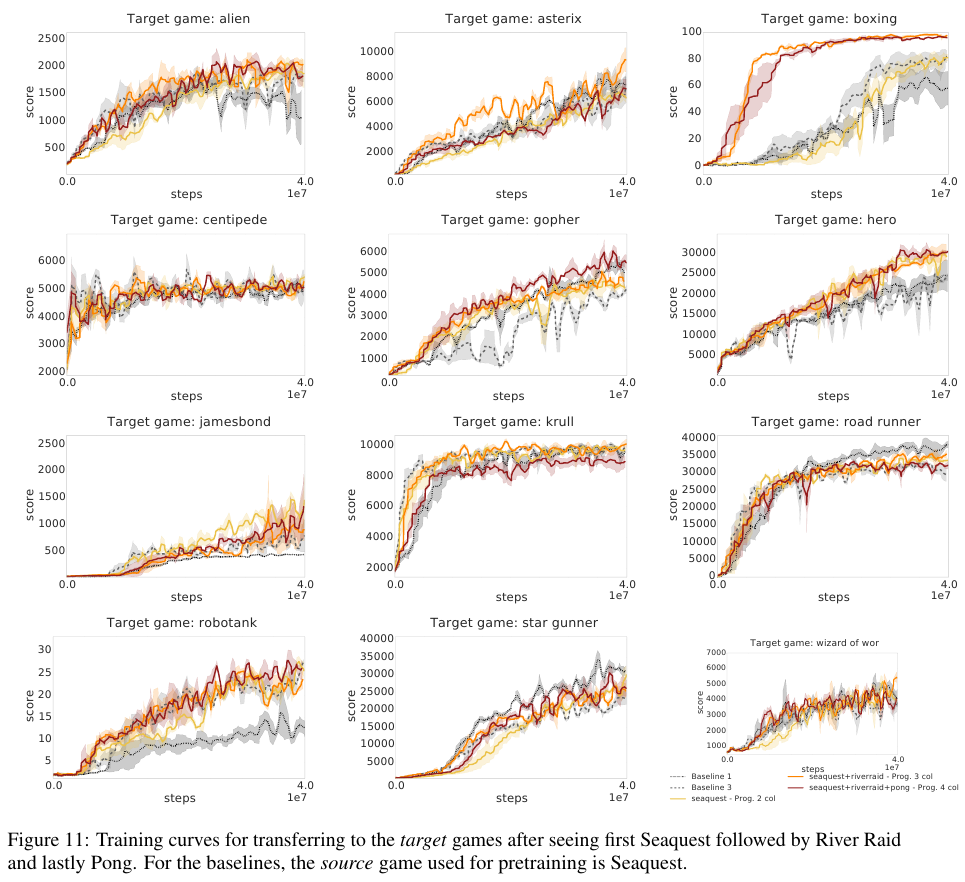
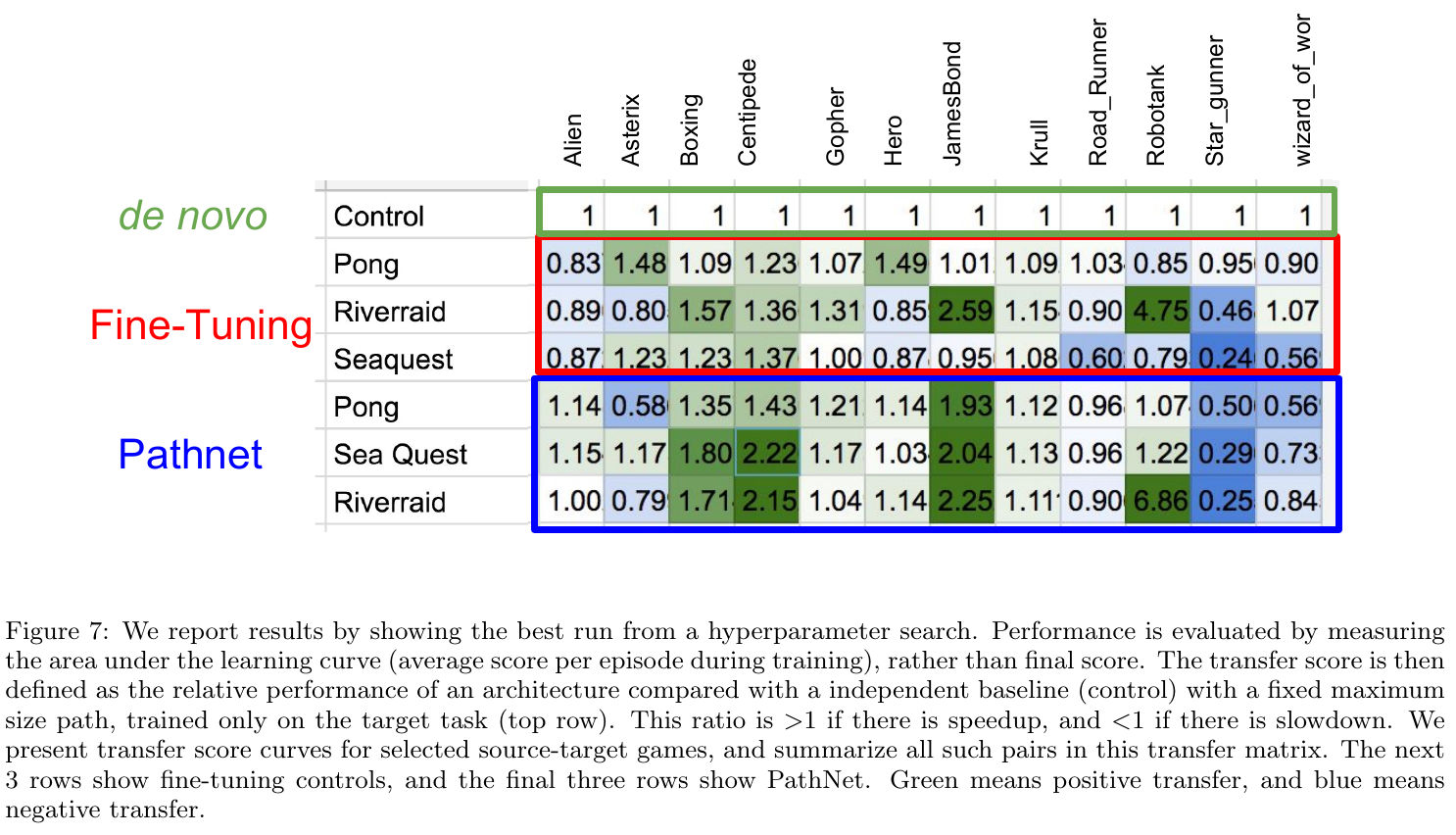
Evaluation baselines:
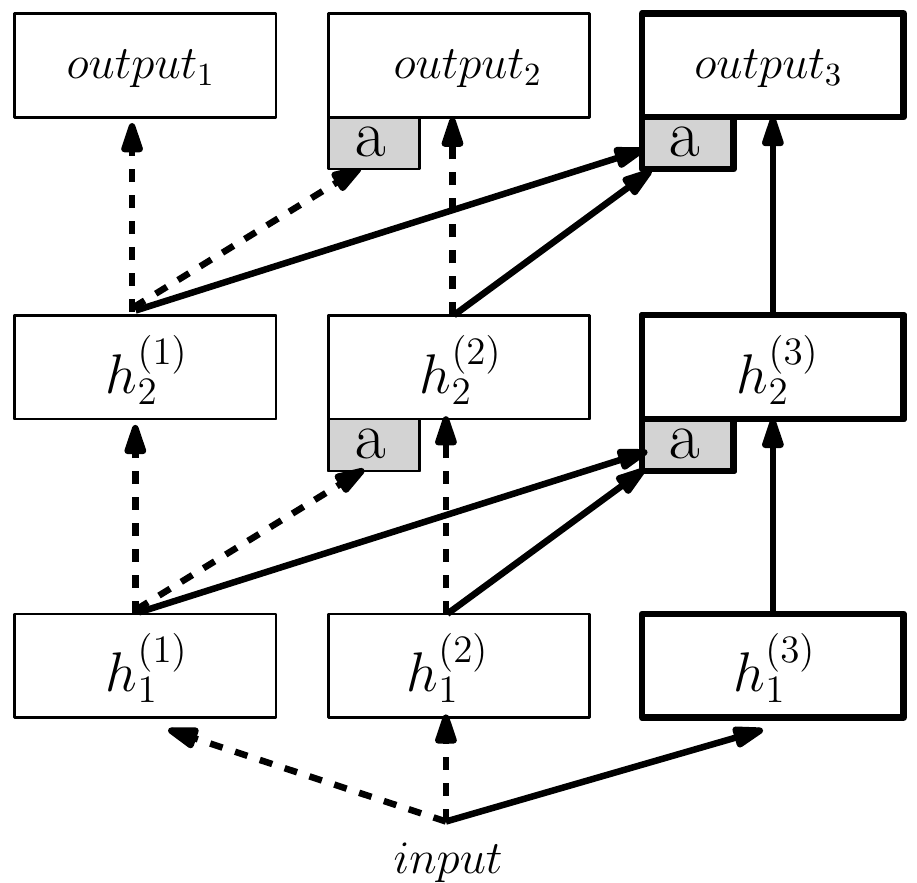
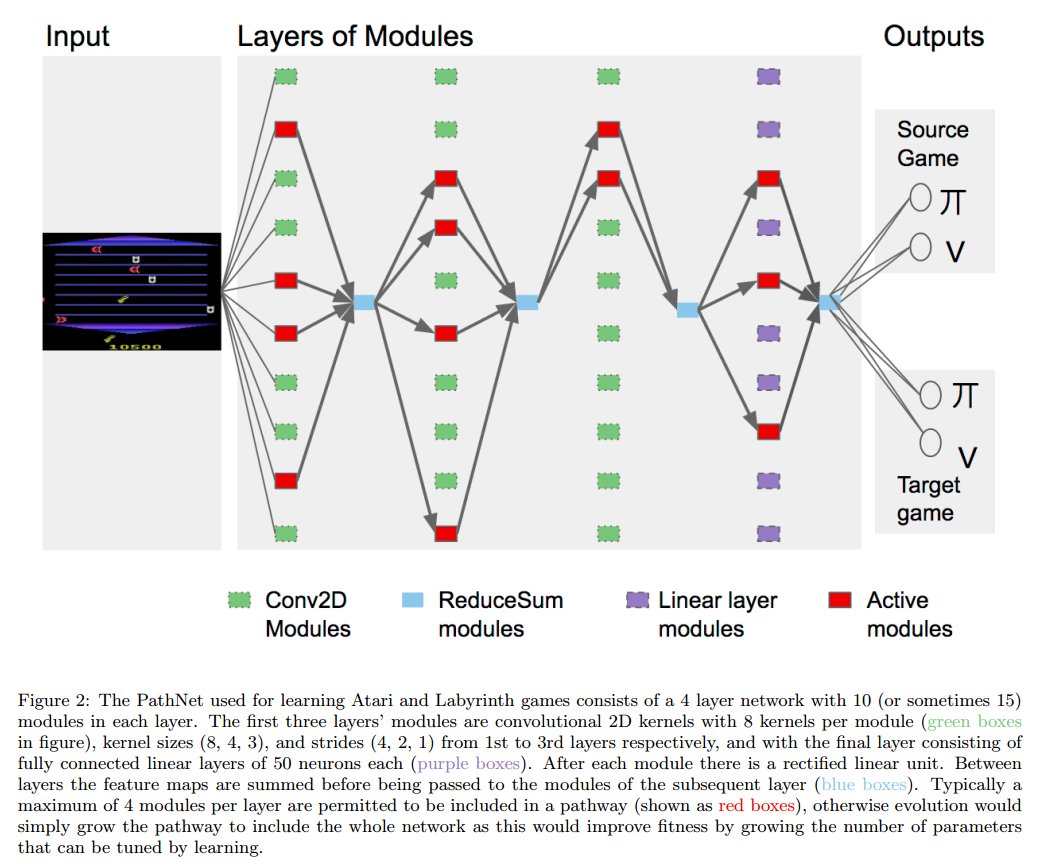
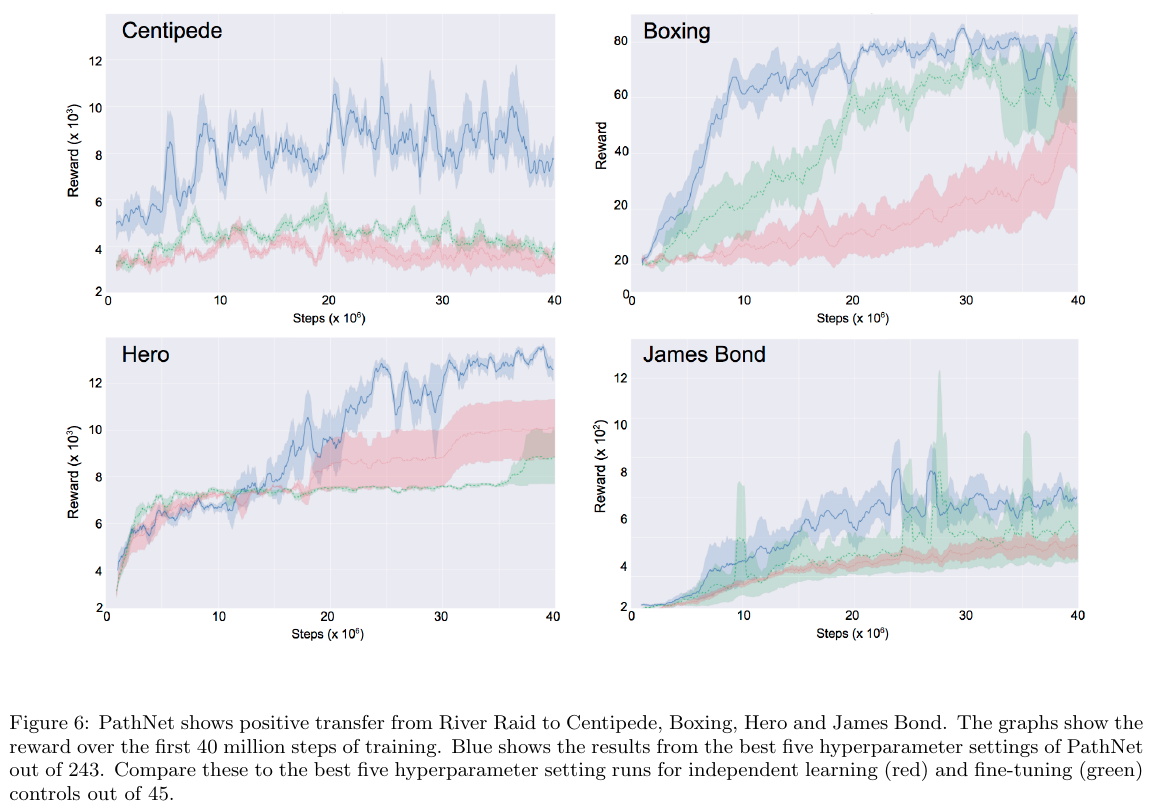
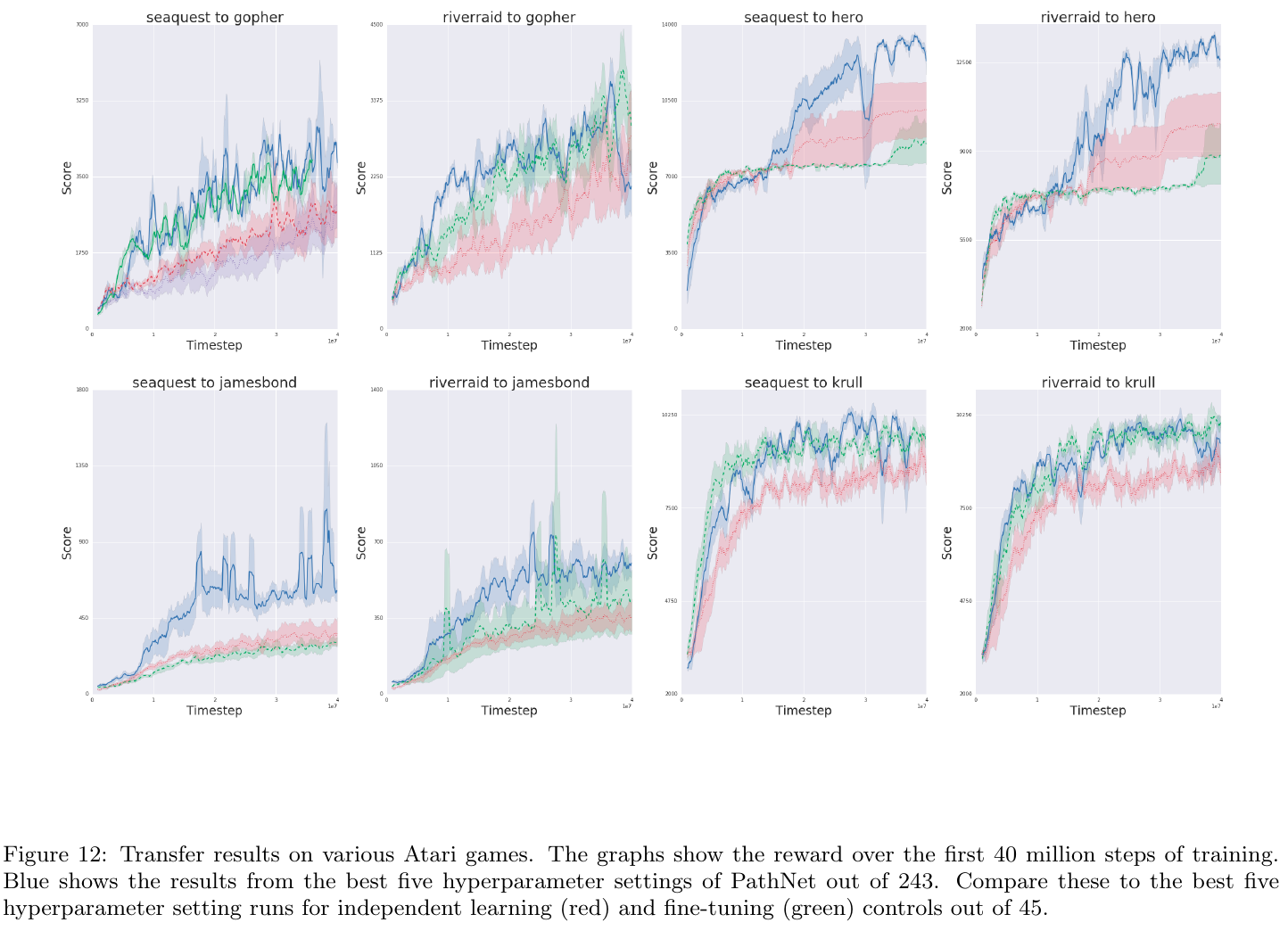
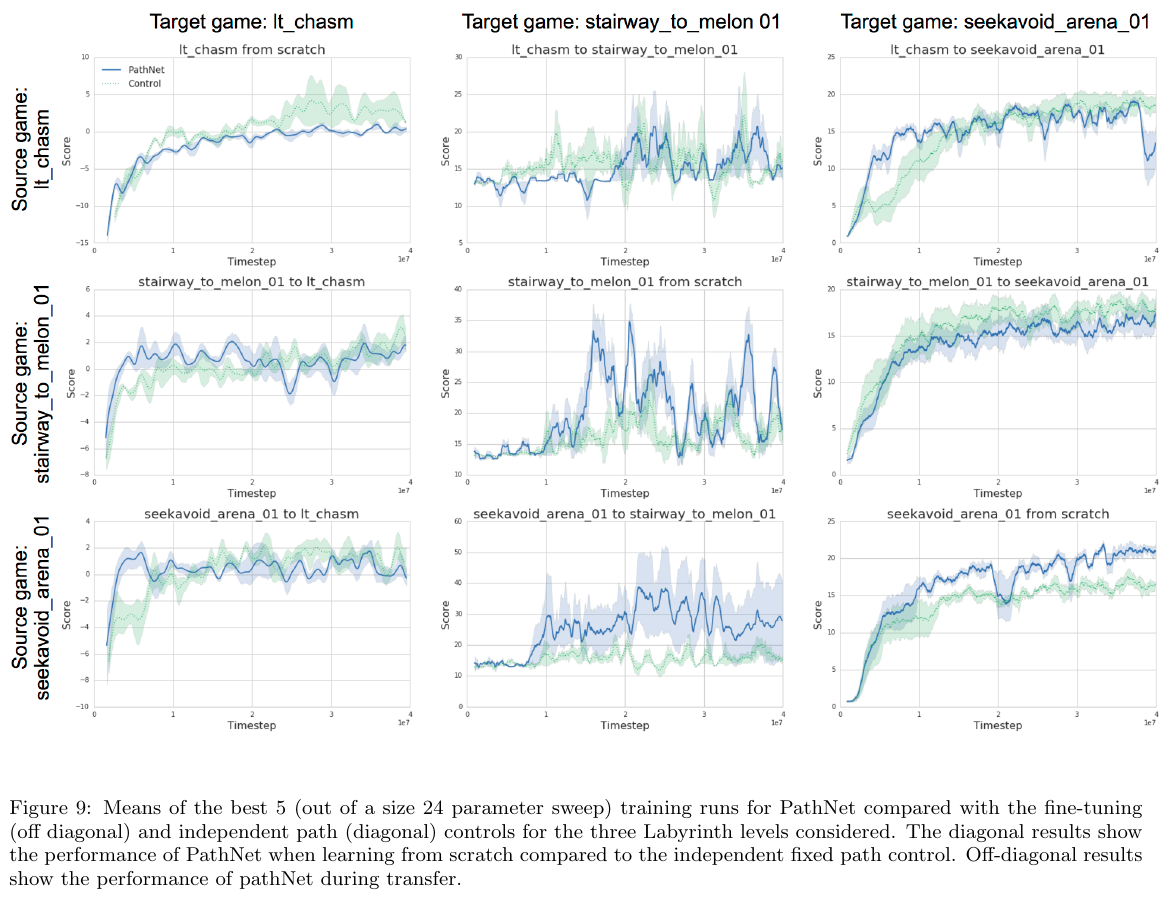
Fernando et al. (DeepMind), arXiv 2017, 263 citations
Architecture:
Training:
After training, winning pathway's weights are frozen before starting to train for another task. Other weights are reinitialized.