MISTIQUE: A System to Store and Query Model Intermediates for Model Diagnosis
When we start building a model
Input data
Transform1
Transform2
Transform3
......
TransformN
Result
Model
?
When we start building a model
Input data
Transform1
Transform2
Transform3
......
TransformN
Result
Model
An Iteration
When we try to make a model work
Iteration
Iteration
Iteration
Iteration
......
Iteration
Result
✔️
When we try to make a model work
Iteration
Iteration
Iteration
Iteration
......
Iteration
Result
Time
Time
Time
Time
Time
✔️
Enormous Time

TRAINING!
MODEL'S TRAINING
DATA SCIENTIST
We need model management for diagnosis (to save time)
Current use pattern for model diagnosis
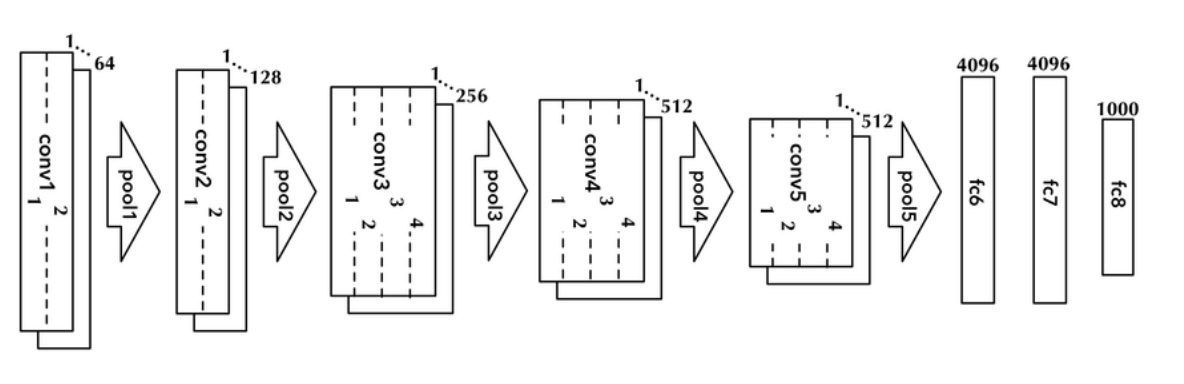
VGG 16 for Image classification
Current use pattern for model diagnosis
Current use pattern for model diagnosis


Current use pattern for model diagnosis
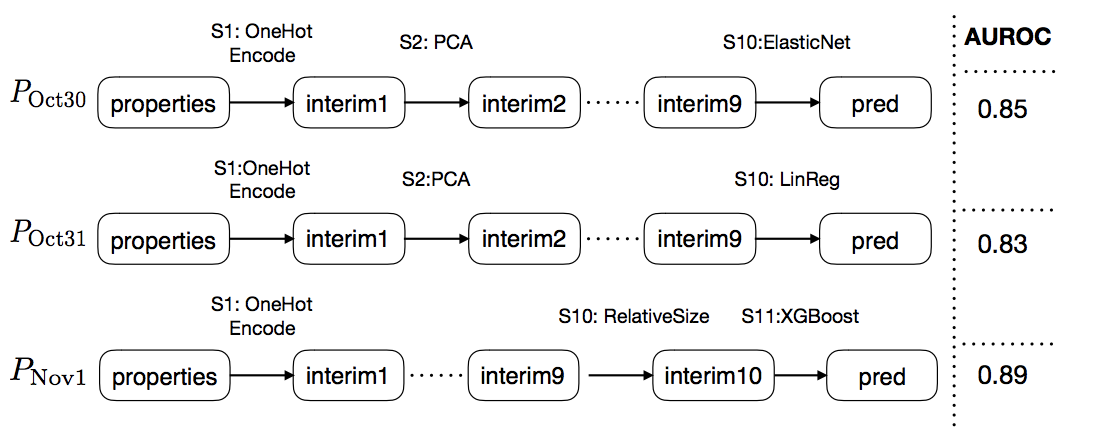
House price prediction
Current use pattern for model diagnosis
VisML: Visualizing ML Model
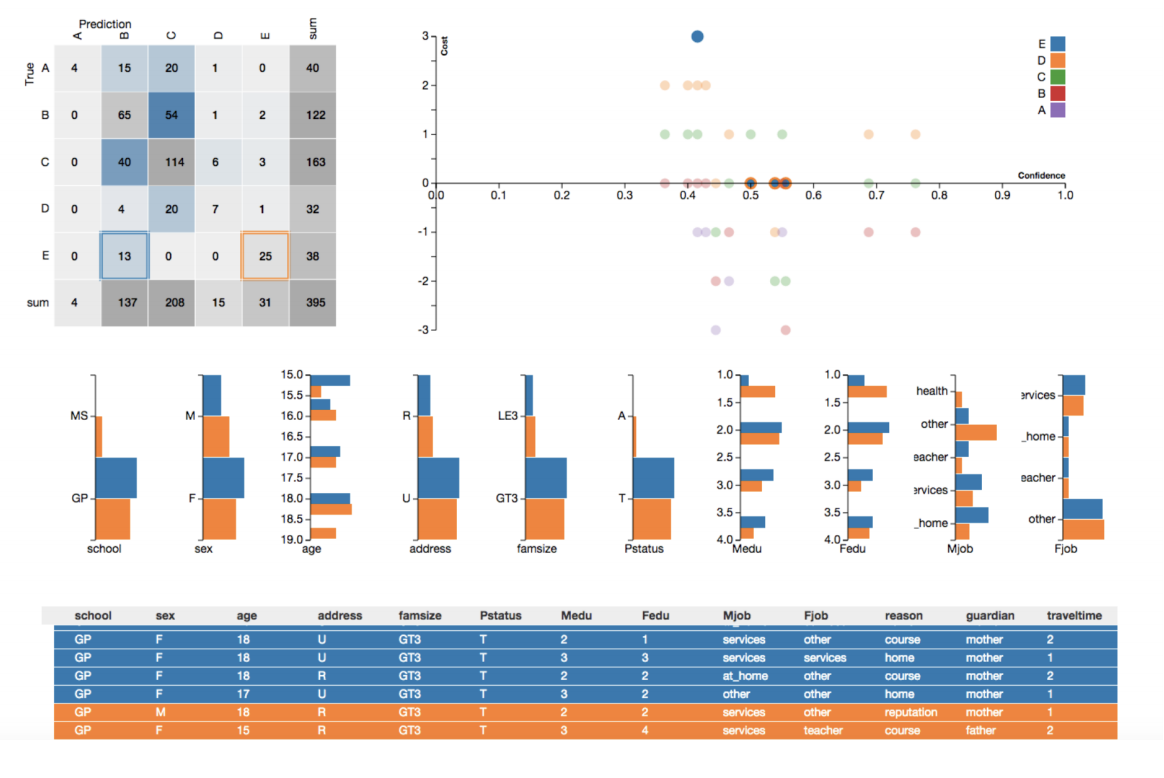
Key: Model Intermediates
- the learned model parameters
- log files
- gradient information
- intermediate datasets produced by different stages of the model
Solution 1: Store everything?
But: storing intermediates for ten variants of the popular VGG16 network on a dataset with 50K examples requires 350GB of compressed storage.
These intermediates could also be generated anew each time, however, this would require running the model >200 times on the full dataset.
Solution 2: Mistique
Examples for DNN and traditional ML
Solution 2: Mistique - System Architecture
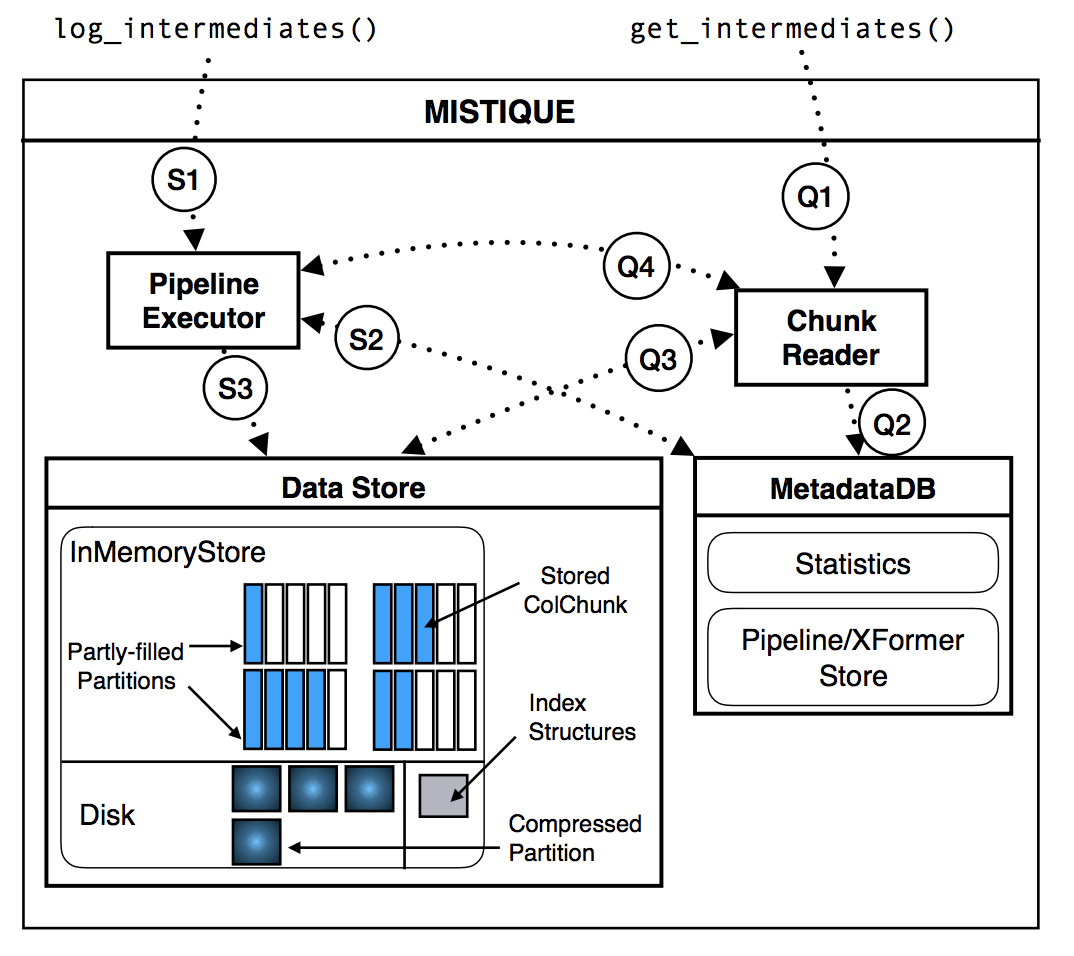
- PipelineExecutor
- DataStore
- ChunkReader
Solution 2: Mistique - DataStore
- Column based
- Mem buffered
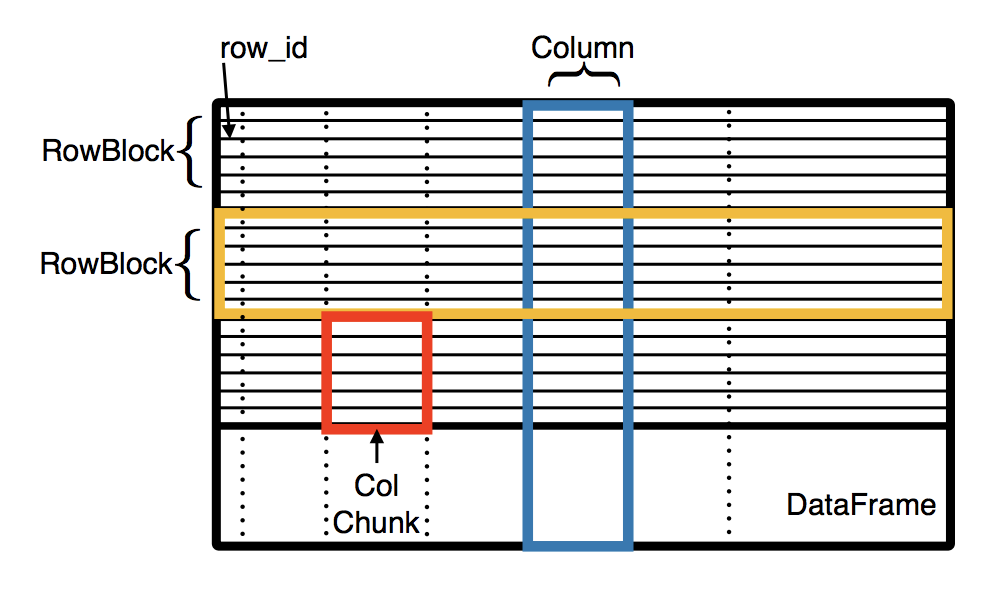
Solution 2: Mistique - Optimizations
- Quantization and Summarization
- Exact and Approximate De-duplication
- Adaptive Materialization
Quantization and Summarization (NN)
Observation: only relative values matters
Quantization and Summarization (NN)
Observation: only relative values matters
- Lower precision float representation (LP_QT): 2X, 4X reduction
- k-bit quantization (KBIT_QT): \(o_{bit} \rightarrow b_{bit} \Rightarrow \frac{o}{b}\), \(2^b\) bins
- Threshold-based quantization(THRESHOLD_QT): just for extreme case (Netdissect)
- Pooling quantization (POOL_QT): \(S \times S \rightarrow \sigma\times\sigma \Rightarrow \frac{S^2}{\sigma^2}\)
Exact and Approximate De-duplication
Observation:
- Intermediates in traditional ML pipelines often have many identical columns
- TRAD and DNN intermediates often have similar columns
Exact and Approximate De-duplication
- Identical columns: Hash the ColumnChunk
- Similar columns: Jaccard similarity over threshold \(\tau\)
- (DNN): Only Hash and put ColumnChunks from same intermediate into same partition
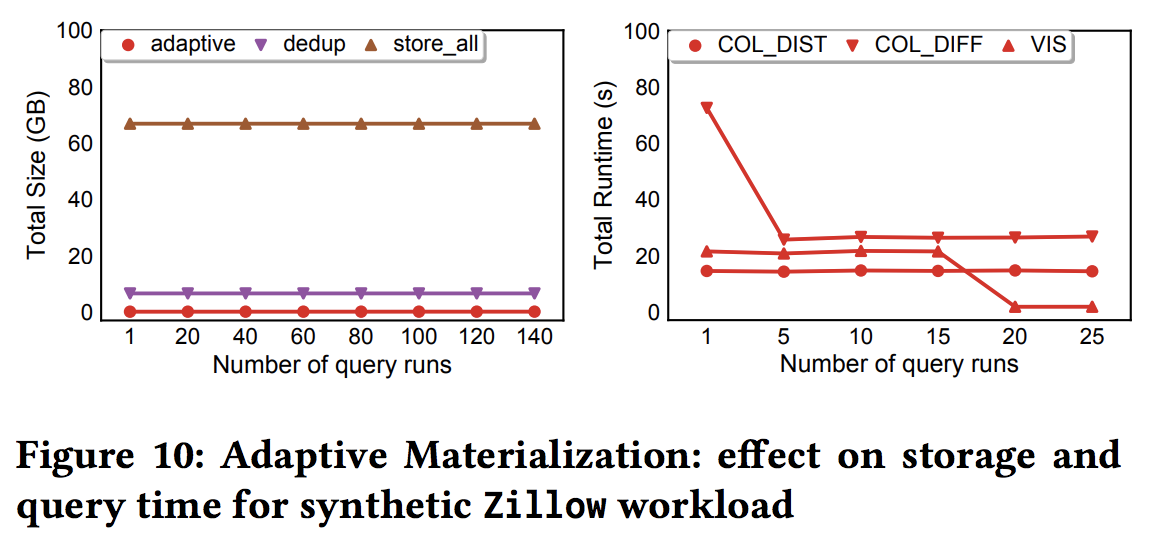
Adaptive Materialization
Observation:
- Not all intermediates are visited with same frequency
Adaptive Materialization
Observation: non-uniform frequency
Solution:
- Trade-off the increase in storage cost (materialization) against recalculating, by comparing the cost \(\gamma\) using a cost function.
Storage process in a nutshell
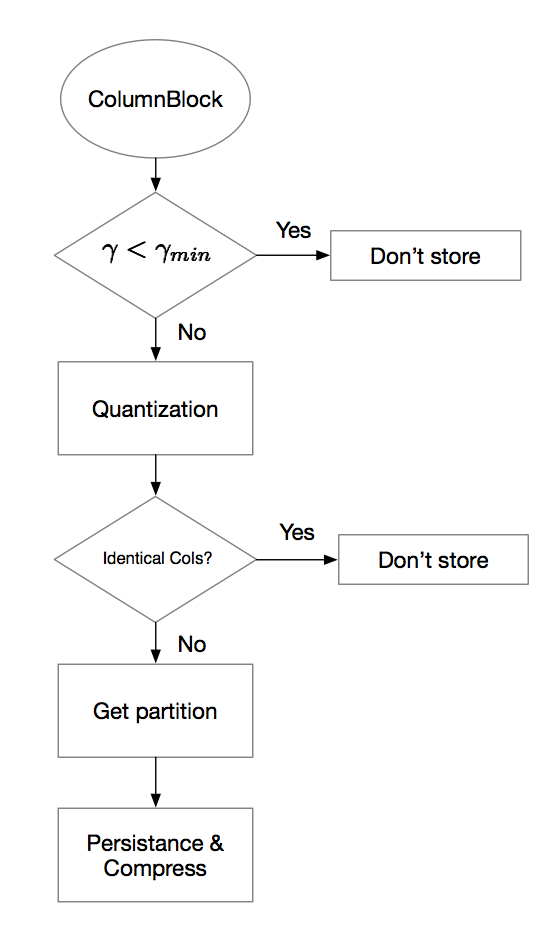
Query cost model
\(t_{diag} = t_{fetch} + t_{compute}\)
Time to run a diagnosis
Time to fetch the data, recalculating or from materialization
Time to run the computation
Query cost model
\(t_{diag} = t_{fetch} +\) \(t_{compute}\)
Time to run a diagnosis
Time to fetch the data, recalculating or from materialization
Time to run the computation
SAME
Query cost model
\(t_{i,fetch}\)
\(t_{i,read}\)
\(t_{i,re-run}\)
VS
Query cost model
\(t_{i,fetch}\)
\(t_{i,read}\)
\(t_{i,re-run}\)
VS
\(\sum_{s=0}^i \{t_{read\_xformer}(s) + t_{read\_xformer\_input}(s)+t_{exec\_xformer}(s)\}\)
Query cost model
\(t_{i,fetch}\)
\(t_{i,read}\)
\(t_{i,re-run}\)
VS
\(t_{i,read} = \frac{n_{ex} \cdot sizeof(ex)}{\rho_d}\)
Storage cost model
\(\gamma = \frac{(t_{i,\text{re-run}}-t_{i,read}) \cdot n_{query}(i)}{S(i)}\)
Whether to store the model intermediate?
The unit of \(\gamma\) is sec/GB, indicates the willingness to use storage in exchange of time.
e.g. 0.5 sec/GB means Bob want to use additional 1 GB to save 0.5 second execution time
Experiments
We want to verify:
- Time speedup
- Storage gain
- Quantization effect on accuracy for DNNs
- Overhead of MISTIQUE vs baseline
- Adaptive materialization effect on storage and query time
Datasets setting
TRAD: Kaggle Zestimate competition (House price prediciton)
DNN: CIFAR10 image recognition
Do we get time speed up?
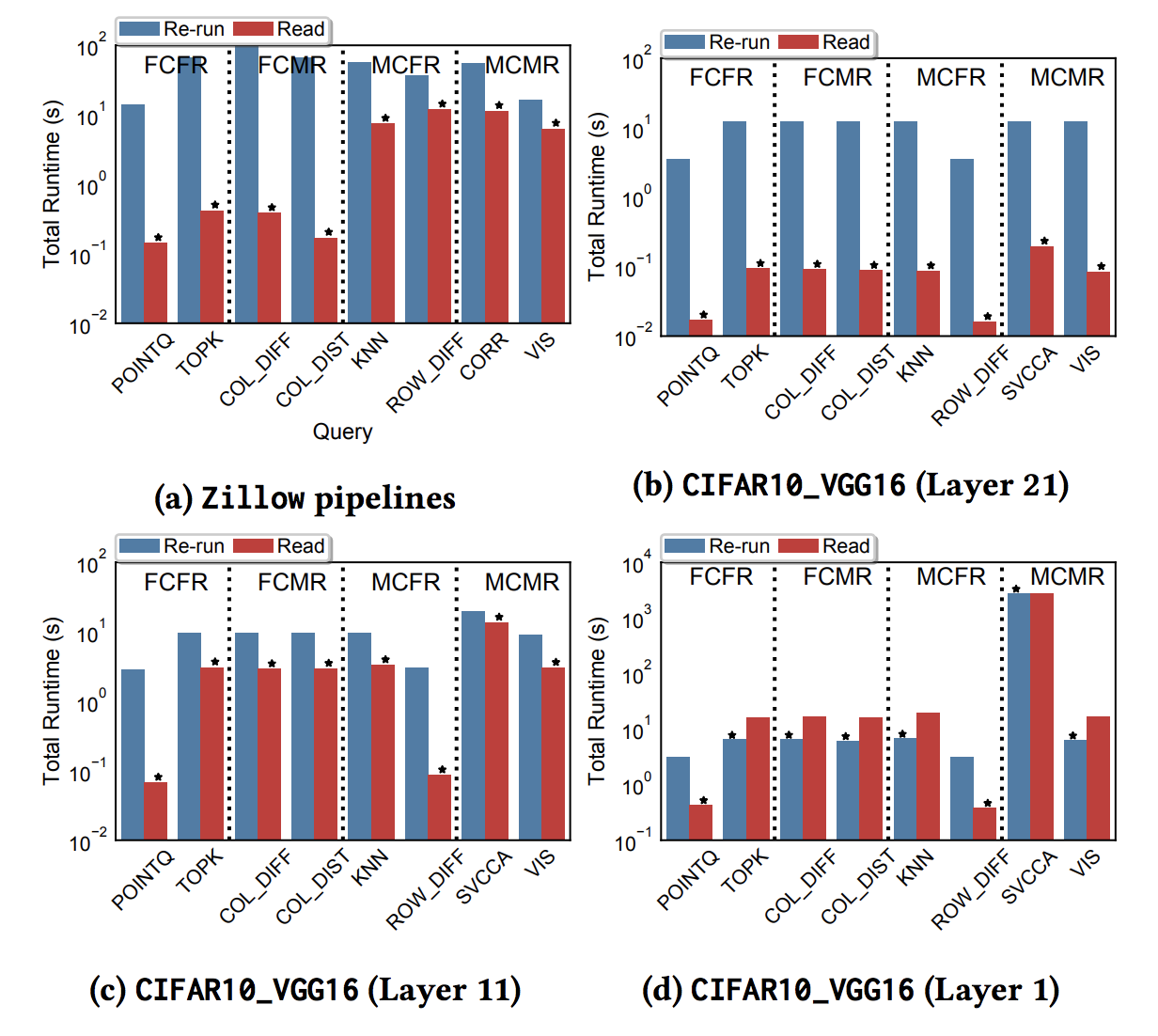
TRAD: 2.5X-390X
CIFAR10: 2X-210X
Storage gain pattern
Input 168MB, Store All: 67GB
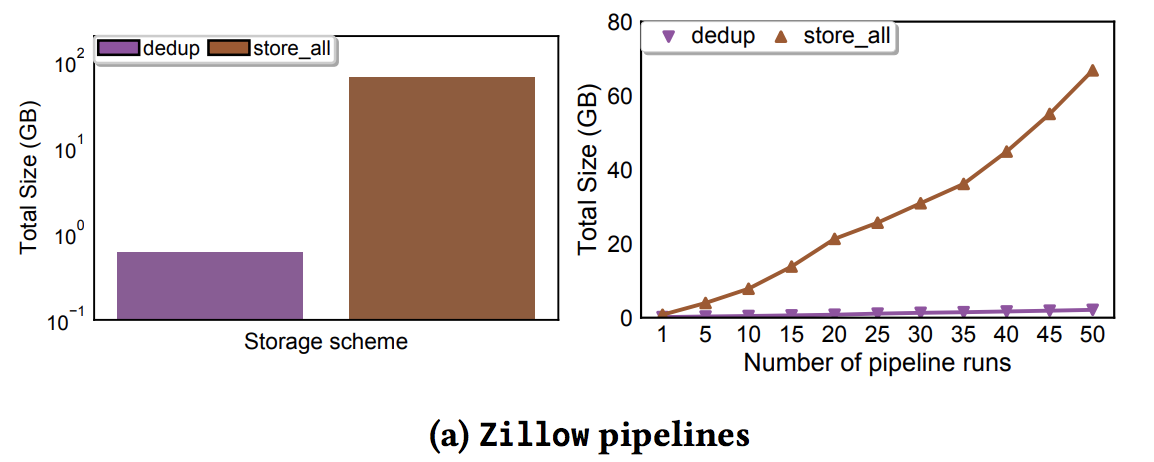
Traditional pipeline has many columns shared between pipelines.
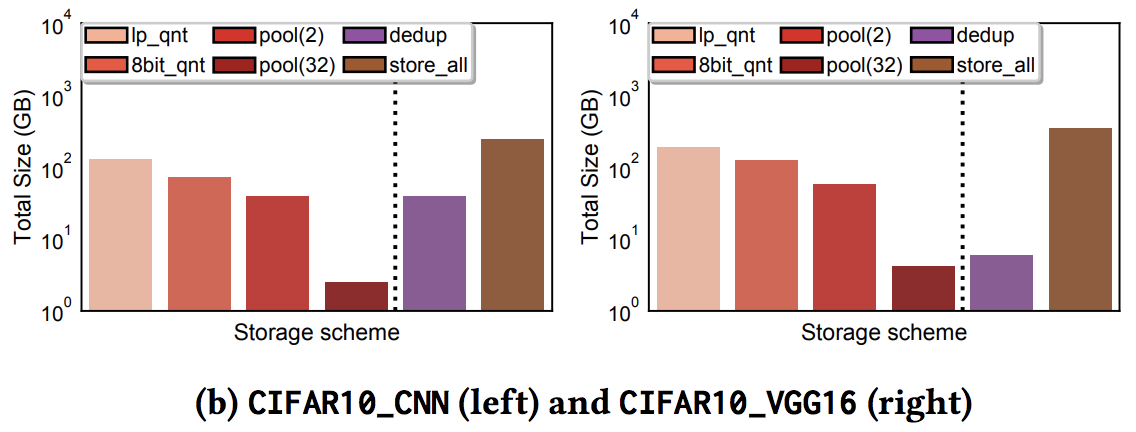
Storage gain pattern
Input 170MB, 10 epoch Store All: 242/350GB
Reducing storage footprint is more essential for DNN
Does quantization affect accuracy?
There's no visual difference between full precision, LP_QT, KBIT_QT(k=8) and POOL_QT, but KBIT_QT(k=3) and THRESHOLD_QT shows clear discrepancies.

Does quantization affect accuracy?
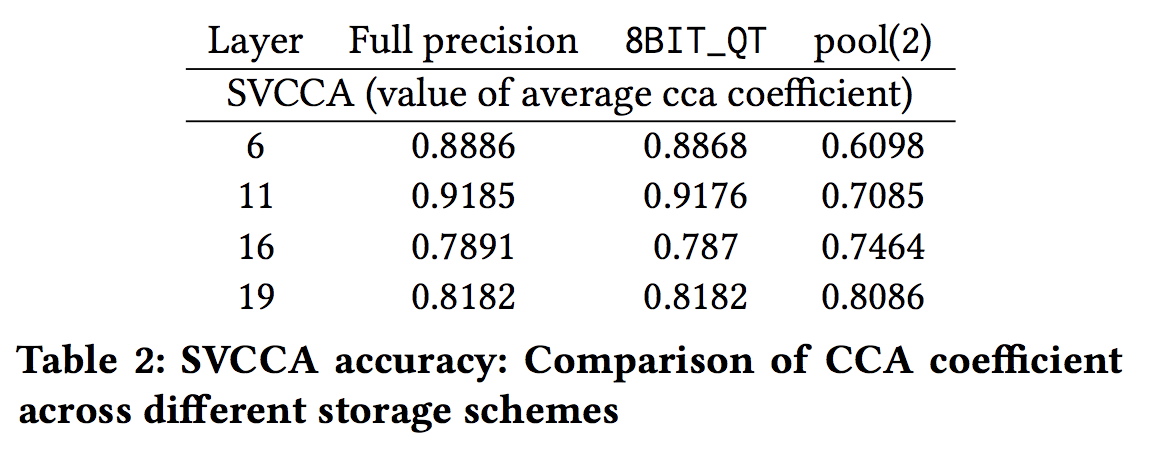
While 8Bit_QT shows nearly no difference comparing to Full precision, it needs 6X more time and 1.5X storage comparing to pool(2).
The effect of adaptive materialization
We set γ to 0.5s/KB (i.e., trade-off 1 KB of storage for a 0.5s speedup in query time)
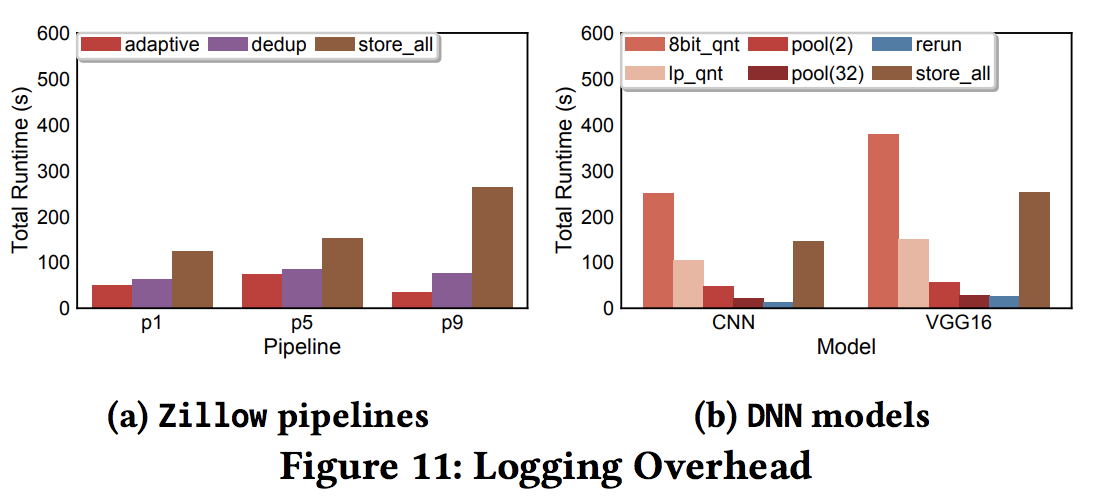
MISTIQUE overhead
Pipeline: speed is correlated to data written
DNN: comparing to training time (>30mins), the overhead of logging is acceptable