Introduction
au Traitement Automatique du Langage Naturel (TALN)
Nicolas Rochet
2025
Activité participative
Quels mots vous évoquent le traitement du langage ?
Connectez vous pour participer:
IA
Linguistique
langage ecrit
langage parlé
statistique
machine learning
TALN / NLP
Informatique
deep learning
Définition
.... pour "comprendre" le contenu de corpus de documents
Domaine visant à analyser par des moyens informatiques des données du language naturel
tweets
messages de forums
e-mails
articles
livres
...
enquêtes
paroles
chansons
discours
recettes
conversations
Applications & cas d'usages
Principales applications
Text & speech processing
Natural Language Understanding
Lexical
semantics
Syntactic
analysis
Relational semantics
Discource
Natural Language Generation
Morphological analysis
Principales applications
Natural Language Understanding
Natural Language Generation
Automatic Summarization
Dialogue management
Grammatical error correction
Machine translation
Question answering
Music generation
Text generation
Voice synthesis
Principales applications
Text & speech processing
Optical Character Recognition
Speech recognition
Speech segmentation
Text-to-speech
Speech-to-text
Word segmentation
Principales applications
Morphological analysis
Lemmatization
Morphological segmentation
Part of speech tagging
stemming
Principales applications
Syntatic
analysis
Grammar induction
Sentence parsing tree
Sentence breaking
Principales applications
Lexical
semantics
Distributionnal semantics
Sentiment analysis
Named entity recognition
Terminology extraction
Word sense disambiguation
Entity linking
Principales applications
Relational semantics
Relationship extraction
Semantic parsing
Principales applications
Discourse
Coreference
resolution
Argument mining
Topic segmentation
Implicit semantic
role labelling
Topic segmentation
Recognizing textual entailment
Discourse analysis
Travailler sur des données textuelles
Comment transformer le corpus en données numériques ?
Données textuelles
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Phasellus ac nunc tristique, maximus enim eget, sodales neque.
texte 1
Aenean lobortis ornare diam, nec pellentesque odio viverra at.
texte 2
Corpus
Données numériques
variables
...
...
observations
La représentation bag-of-words
Transformer une collection de documents en tableau de
données numériques
(sans nécessiter de connaissances sur le domaine étudié)
Résultat :
vecteur de fréquence des tokens
...
...
documents
La représentation bag-of-words
Transformer une collection de documents en tableau de
données numériques
(sans nécessiter de connaissances sur le domaine étudié)
1. Segmenter les N-grams en tokens
2. Compter la fréquence d'apparition de ces tokens dans chaque document
3. Appliquer une normalisation optionnelle
Etapes :
Exemple de bag-of-words
1. Imaging databases can be huge
4 documents (Coelho & Richert, 2015)
2. Most imaging databases save images permanently
3. Imaging databases store images
4. Imaging databases store images. Imaging databases store images. Imaging databases store images
Comptage de la fréquence des tokens (ngram = 1)
documents
| imaging | databases |
can |
get |
huge |
most | save |
images |
permanently |
store |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 |
|---|
| 2 |
| 3 |
| 4 |
Limitations
Certains mots ne sont pas intrinsquément porteur de sens
suppression des stop-words
documents
| imaging | databases |
can |
get |
huge |
most | save |
images |
permanently |
store |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 |
|---|
| 2 |
| 3 |
| 4 |
Certains mots ont le même contenu sémantiques
racinisation & lemmatisation
Term Frequency -Inverse Document Frequency (TF-IDF)
Le comptage ne tient pas compte de la fréquence d'apparition totale
Le contexte n'est pas encodé !
Remarques sur bag-of-words
Sa dimensionnalité est
souvent très élevée
Le tableau de données issus de bag-of-words est particulier:
Elle contient beaucoup de zéros
la réduction de dimension est un enjeu crucial
utiliser des représentation sous forme de sparse-vector pour économiser la mémoire
Un prétraitement dédié
Suppression de caractères spéciaux
dictionnaire de mots courants
Suppression des stop-words
#$%&\'{}*+
...
the
your
is
...
Un prétraitement dédié
Racinisation
garder la même racine morphologique
playing, played, plays
play
Lemmatisation
garder la même forme sémantique
am, are, is
be
La vectorisation des tokens
Term Frequency
(TF)
Term Frequency -Inverse Document Frequency
(TF-IDF)
Fabrication de vecteurs des tokens capables d'encoder le sens contenu dans les documents
On compte la fréquence d'appararition des tokens
1-gram
2-gram
...
Tokens
On divise cette fréquence par le nombre de documents dans lequel le token apparait
databases
imaging databases
| imaging | databases |
... |
|---|---|---|
| 1 | 1 | |
| 1 | 1 | |
| 1 | 1 | |
| 1 | 1 |
documents
| 1 |
|---|
| 2 |
| 3 |
| 4 |
| imaging | databases |
... |
|---|---|---|
| 1/4 | 1/4 | |
| 1/4 | 1/4 | |
| 1/4 | 1/4 | |
| 1/4 | 1/4 |
documents
| 1 |
|---|
| 2 |
| 3 |
| 4 |
... au dela du bag-of-words
Word embedding
Les vecteurs sont crées par des modèles prenant en compte,
pour chaque token, le contexte des autres tokens
La proximité sémantique entre deux mots est capturée par la distance entre deux vecteurs encodé
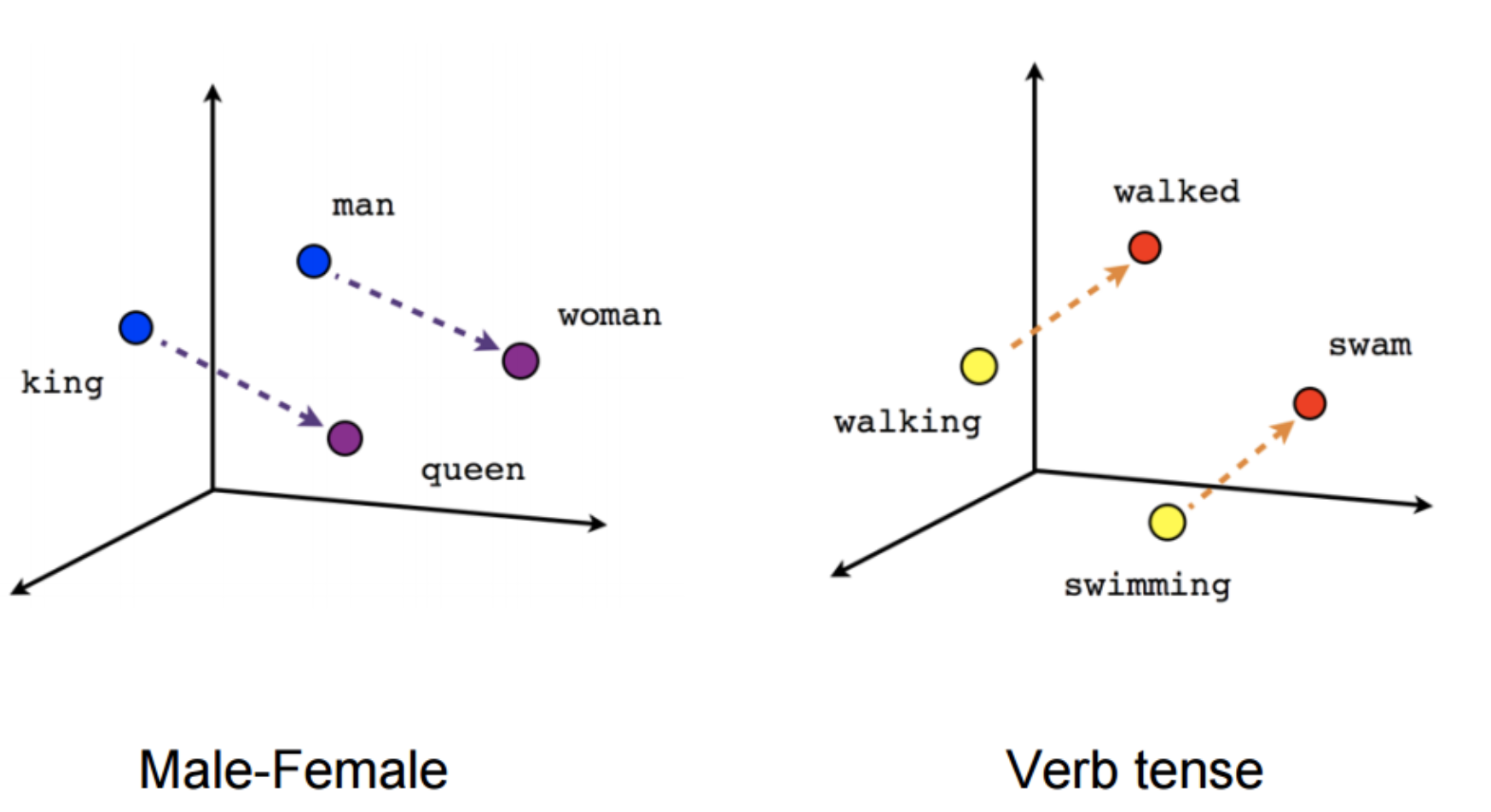
Propriété en sortie
Différents types d'embedding
Word embedding
Sentence embedding
Document embedding
...
MTEB
Les modèles classiques en NLP
Basé sur le RNN simples
les CNN 2D & 1D
RNN, LSTM & GRU
RNN bidirectionnels
Transformers
Voir cours NLP
Modèles séquence-to-sequence
Modèles de ML simple
Encodeurs seq2seq
Travailler sur des données audios
Approches classiques
Utiliser des modèles pour spécialisés dans le traitement de séquences
Réseaux Récurrents : RNN, LSTM, GRU, ...
Modèles basés sur les transformers et le mécanisme d'attention : GPT, Bard, LLama ...
Approches classiques
Travailler sur des données spectrales
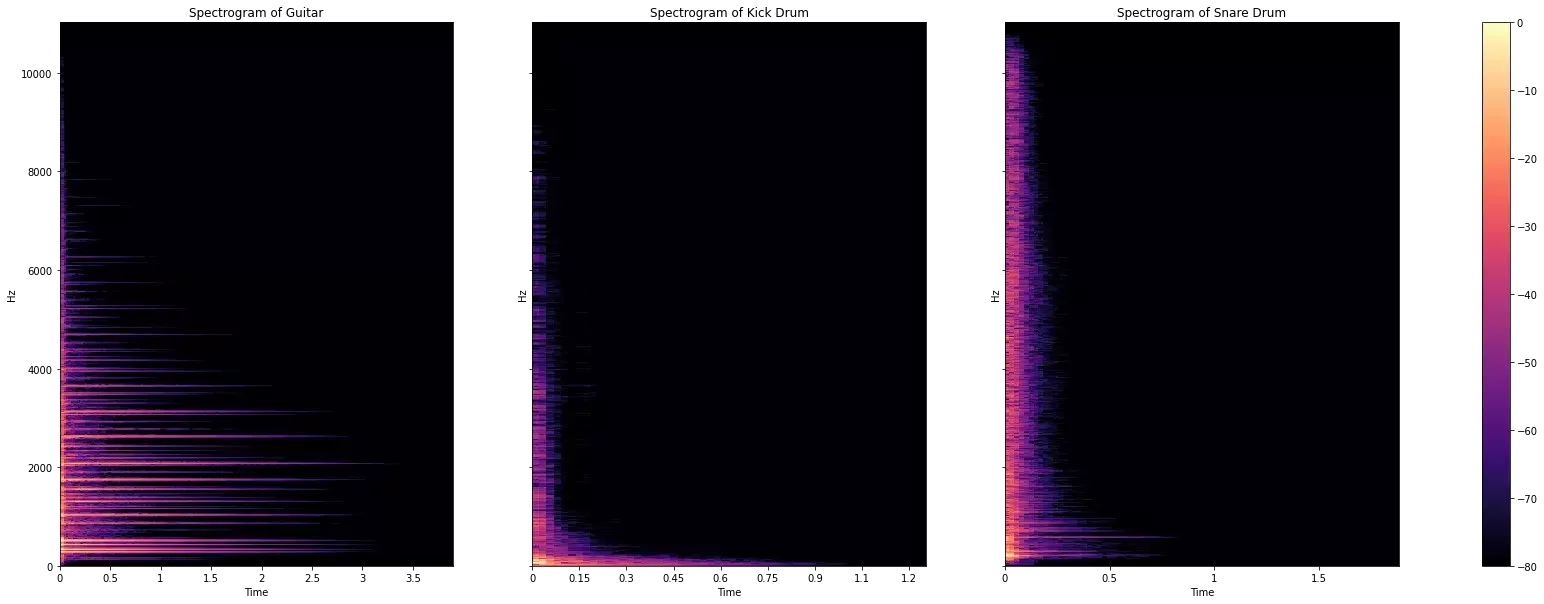
Exemple de spectrogrammes d'après mlearnae
... avec des modèles de vision par ordinateur
CNN, Vision Transformers, ...
Focus sur les
Large Language Models
Les transformers
Utilisent le mécanisme d'attention
Ajouter slides cours MIT : Key Search Value
modeles de fondation
De très gros réseaux de neurones
Entrainés très longuement sur des jeux de données gigantesques ...
... à prédire chaque prochain token d'un texte
Le réseau apprend des représentations complexes (embeding)
Exemple simplifié de la génération de texte
Conception & Entraînement
"L'apprentissage automatique est une branche de l'IA
Bonnes capacités de généralisation



Le réseau entrainé a appris des représentations généralisables
Exemple simplifié de la génération de texte
Inférence
Génération de texte token par token
Ré-entrainement sur des données spécifiques
Sélectionner un ensemble de documents à donner en contexte

fine tuning
En tant qu'expert de la data science programmant en python ...
contexte : prompt
Retrieval Augmented Information
+
Des IAs aux capacités multi-tâches
...
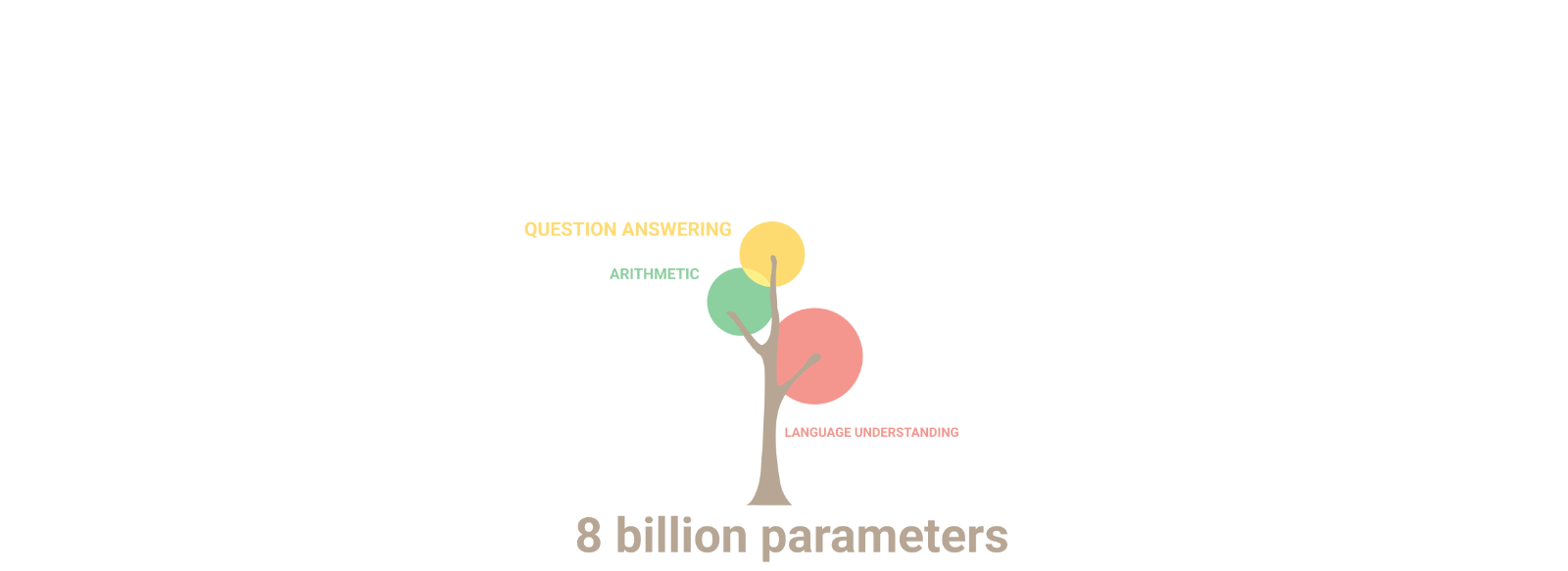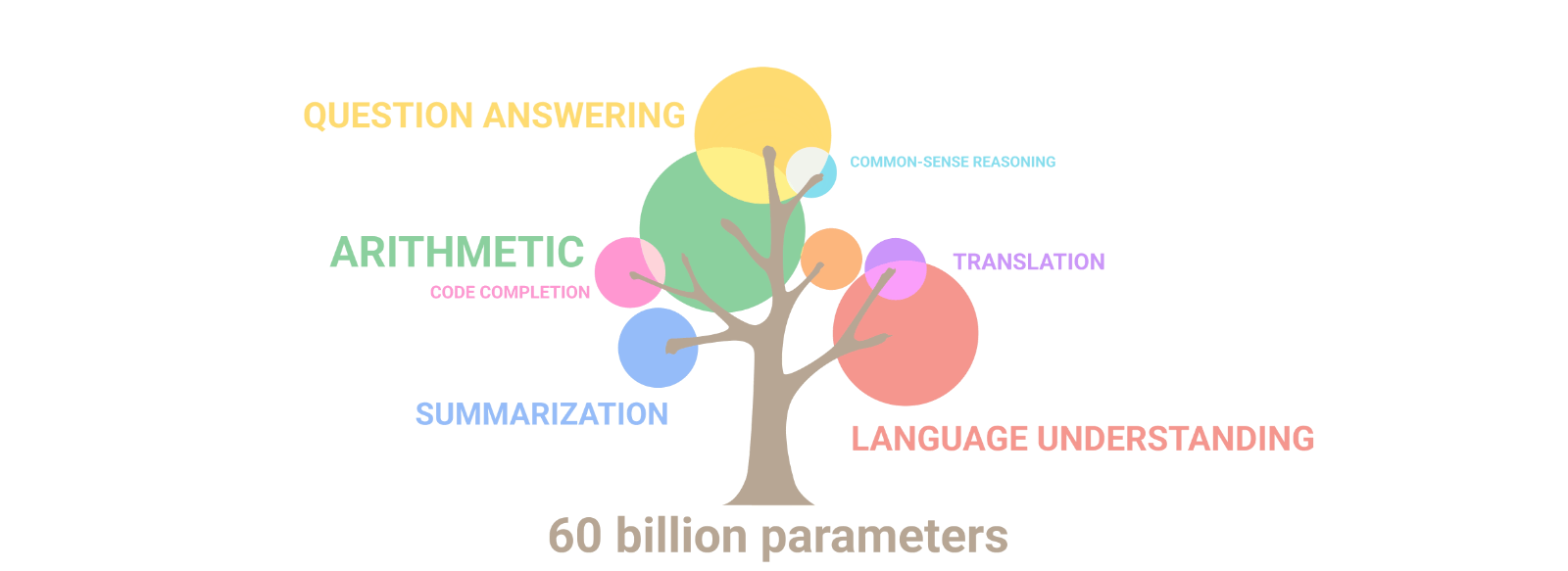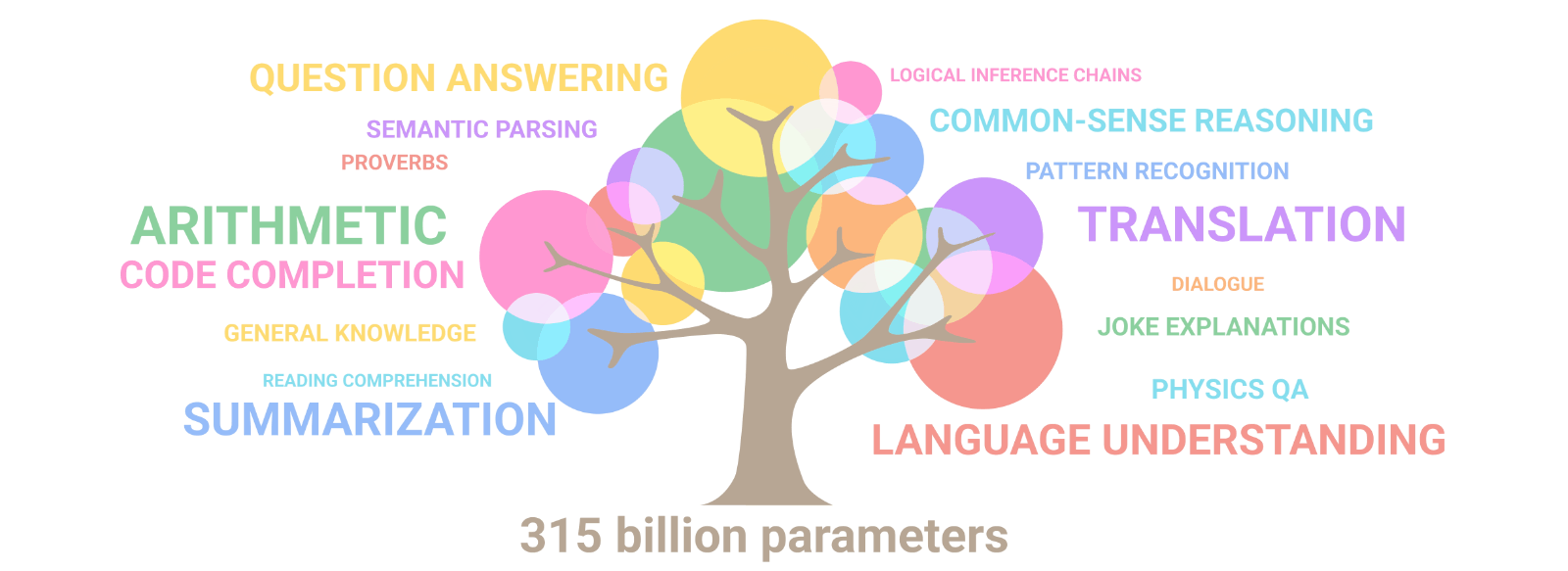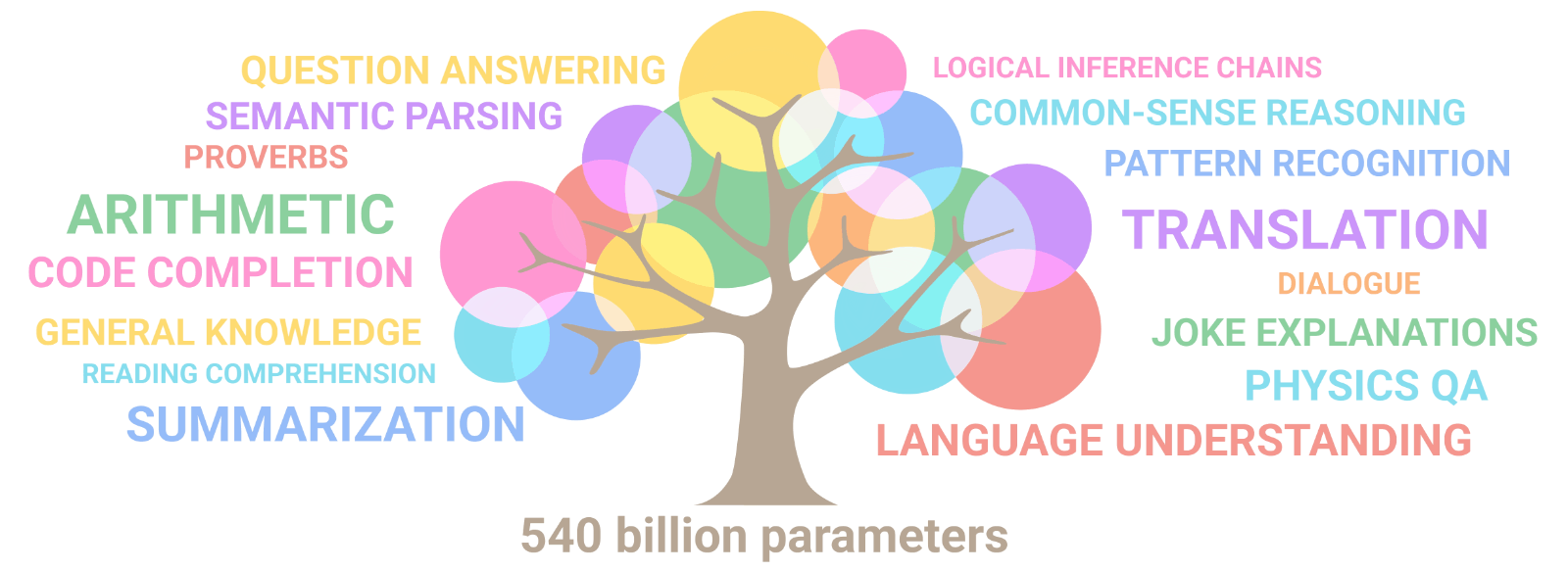
Une galaxie de LLMs
...