Fondamentaux du Machine Learning
Nicolas Rochet
2025
Disciplines de l'IA


Une brève histoire de l'IA
50-56
>2011
93-2011
87-93
80-87
74-80
56-74
Naissance
de l'IA
1er hiver
L'age d'or
2e age d'or
2e hiver
maturité
discrète
Essor du
Deep Learning
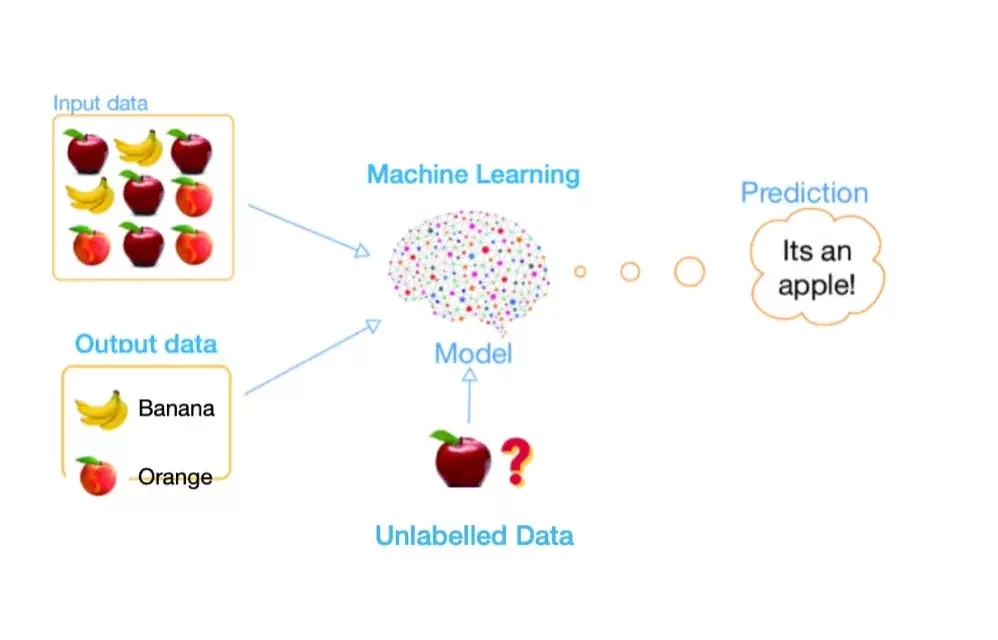
Définition
Machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to "learn" (e.g., progressively improve performance on a specific task) from data, without being explicitly programmed
From Arthur Samuels (source : Wikipedia)
Définition
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E"
From Tom M,Mitchel
Zoom sur les IAs génératives
IAs génératives ?
Depuis quelques années les progrès de la recherche ont abouti à des IAs capables de générer des données réalistes
Des images
vidéos
dessins
illustrations
photo realistes
...
Du texte
Code
paragraphes
questions / réponses
Listes
résumés
...
Les Large Language Models (LLM)
Des sons
voix
musique
...
De très gros réseaux de neurones
Entrainés très longuement sur des jeux de données gigantesques ...
... à prédire chaque prochain token d'un texte
Le réseau apprend des représentations complexes (embeding)
Exemple simplifié de la génération de texte
Conception & Entraînement
"L'apprentissage automatique est une branche de l'IA
Bonnes capacités de généralisation



Le réseau entrainé a appris des représentations généralisables
Exemple simplifié de la génération de texte
Inférence
Génération de texte token par token
Ré-entrainement sur des données spécifiques
Sélectionner un ensemble de documents à donner en contexte

fine tuning
En tant qu'expert de la data science programmant en python ...
contexte : prompt
Retrieval Augmented Generation
+
IAs génératives de texte
Les modèles de fondation ouverts (les plus connus)

Falcon
Claude

Llama 3
Large Langage Model Meta AI
IAs génératives d'images
Leurs capacités
Inpainting
Outpainting
Image-to-image
Prompt-to-image
Modifier l'intérieur d'une image
Etendre l'extérieur d'une image
Générer un image à partir d'une image
Générer un image à partir d'une instruction textuelle
IAs génératives d'images
DALL-E
Stable diffusion
MidJourney
Groupe CompViz

Les plus connues
IAs génératives de vidéos

IA génératives de sons
Exemple : Stable audio
Générer du son à partir d'une instruction texte (prompt)
Pas de ML sans données !
Acquisition
des données
Préparation des
données
Traitement des données
Besoin
Problème à résoudre
Compréhension des données
Data Science
Collecte de données
Préparation de donnes
Traitement
des données
Déploiement
Exploration des données
Modelisation
Identification de pattern
Besoin
Problème à résoudre
Réalité
Communication
Visualisation
Rapport
produit/service
Prise de décisions
données
nettoyées
Algorithmes
Data mining
Acquisition
des données
Préparation des
données
Traitement des données
Déploiement
Besoin /
Problème à résoudre
Compréhension des données
Modelisation
Identification de pattern
Evaluation
Compréhension du
domaine
Inspiré de la méthode CRISP
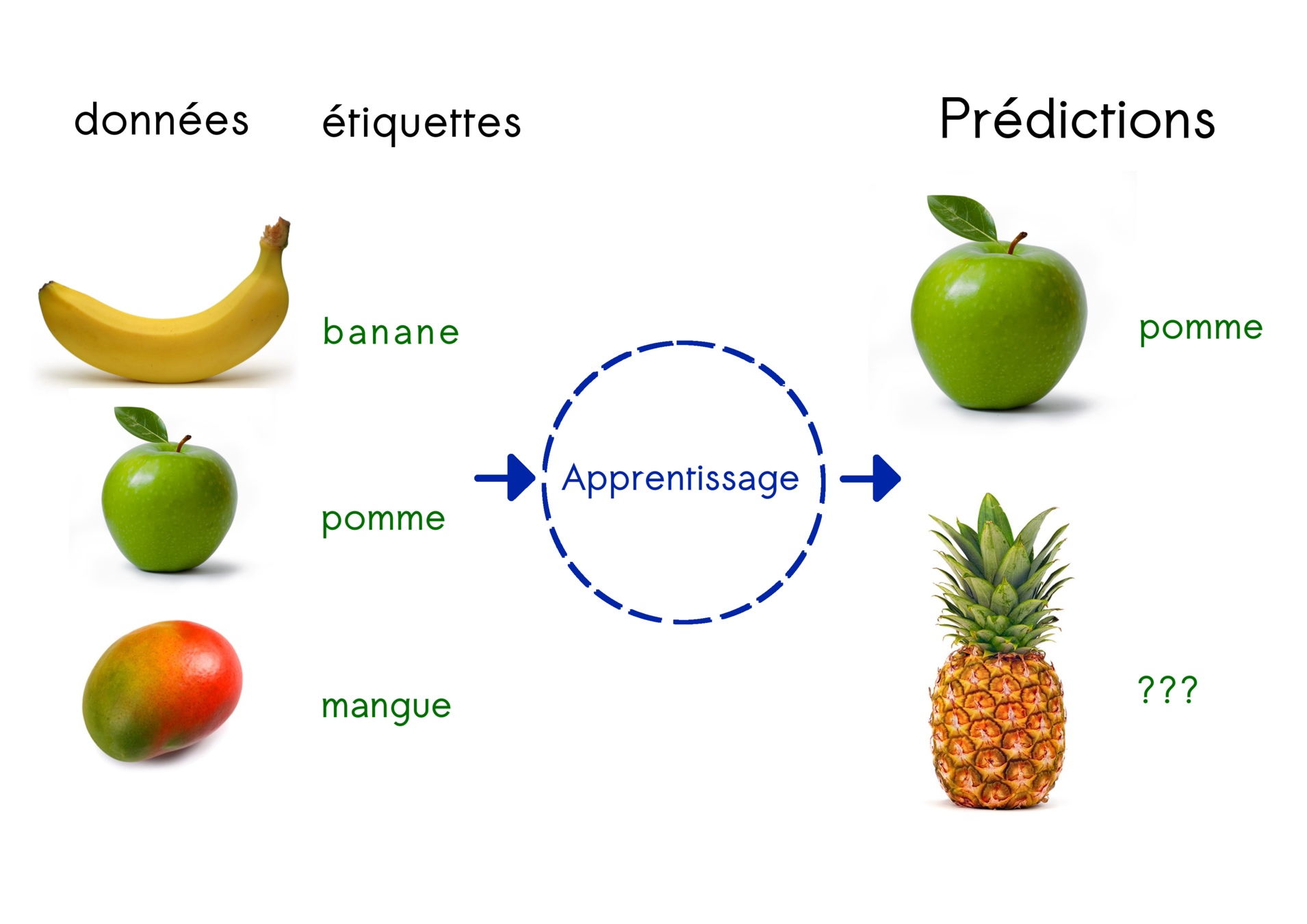
Catégories d'apprentissage
Apprentissage supervisé
Apprentissage auto-supervisé
Apprentissage non supervisé
Apprentissage par renforcement
Apprentissage par transfert
Apprentissage semi-supervisé
Catégories d'apprentissage
Active learning
Apprentissage semi-supervisé
Pool-based approaches
Stream-based selective sampling
Membership query synthesis scenario
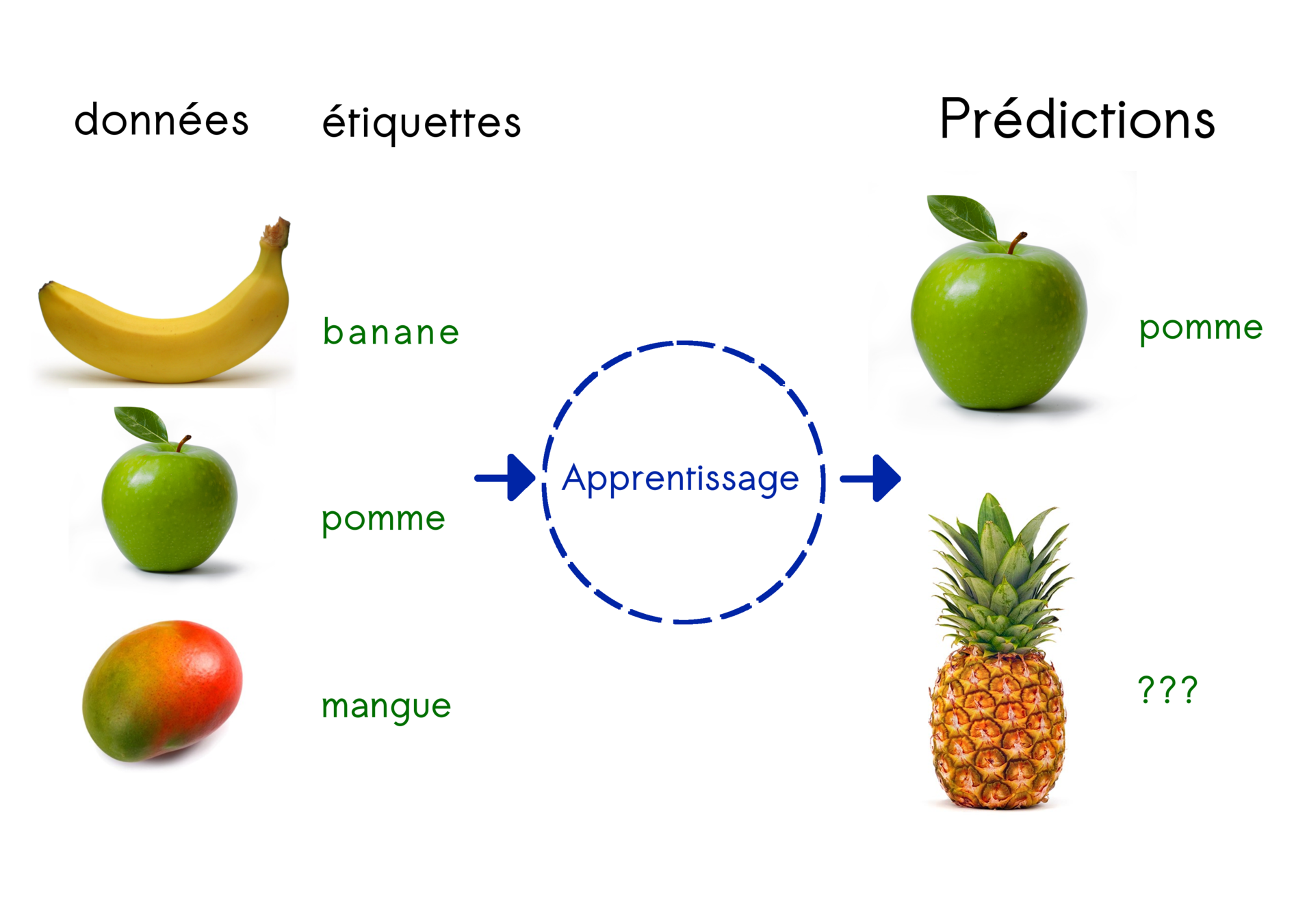
Apprentissage supervisé
Principe :
trouver la règle générale qui relie données et labels
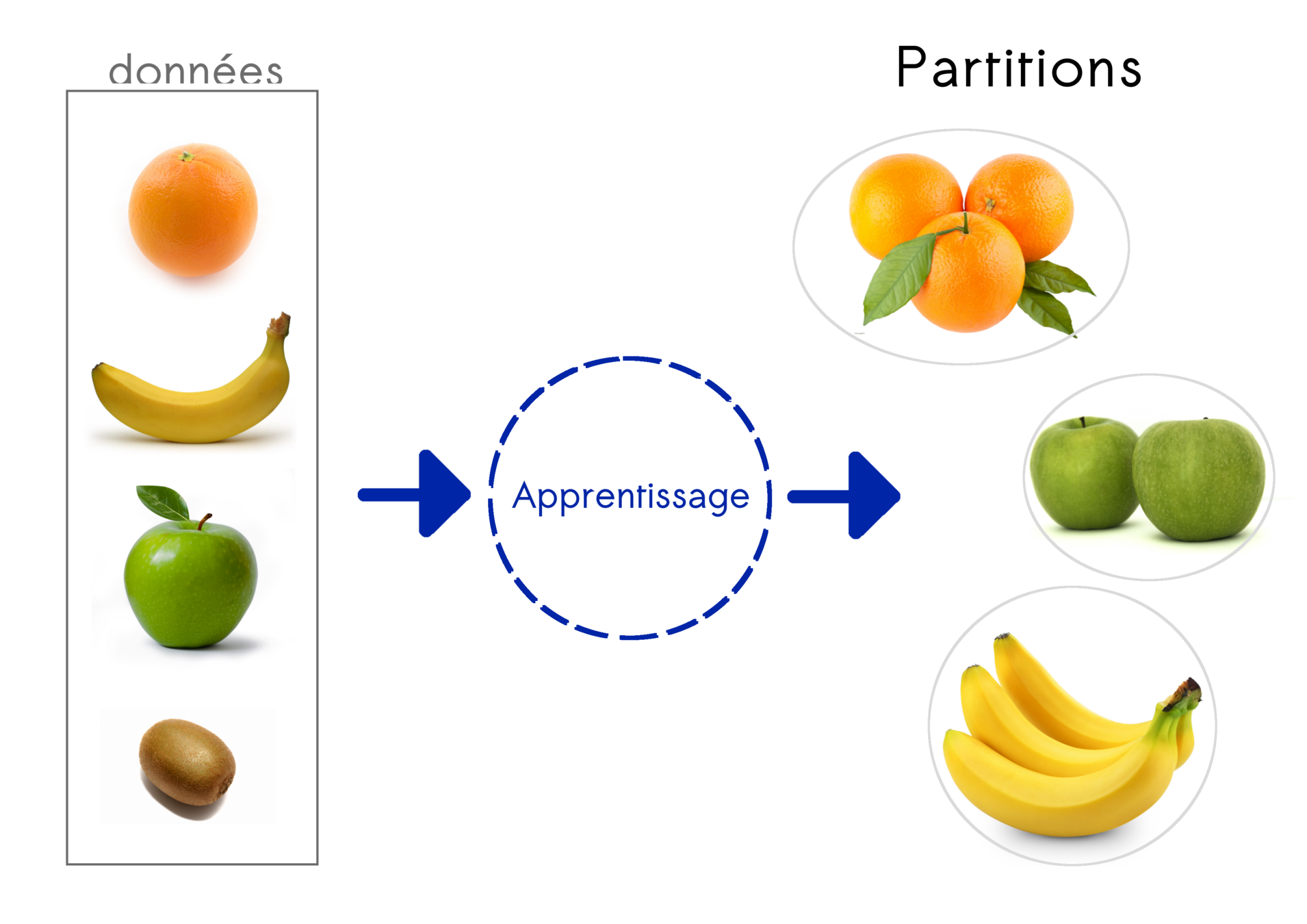
Apprentissage non supervisé
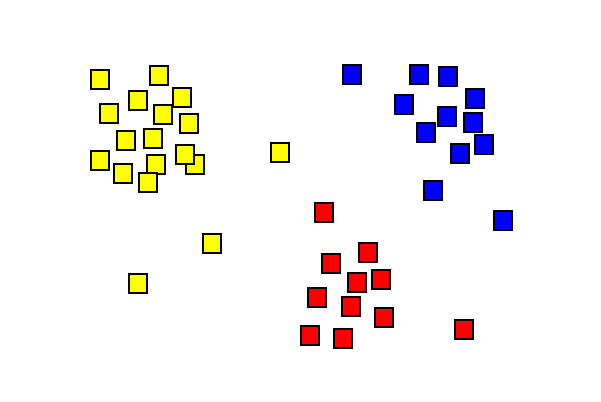
Identifier des groupes (clustering)
Estimer la distribution de données
Estimer des relations entre les données
Méthodes de plongement
...
Réduction de dimensions
Embedding
Identifier des données abbérantes
Analyse de la covariance
Traitement du langage
Topic modeling
Apprentissage non supervisé
Pas de labels !!!
Performances généralement inférieures au cas supervisé
Pas toujours de loss fonction
Identifier des groupes (clustering)
Clustering
Méthodes de plongements
Glove
Word2vec
Principal Component Analysis (PCA)
Singular Value Decomposition (SVD)
Independant Component Analysis (ICA)
Sentence2vec
Isomap
Multi Dimensional Scaling (MDS)
t-SNE
Locally Linear Embeding (LLE)
...
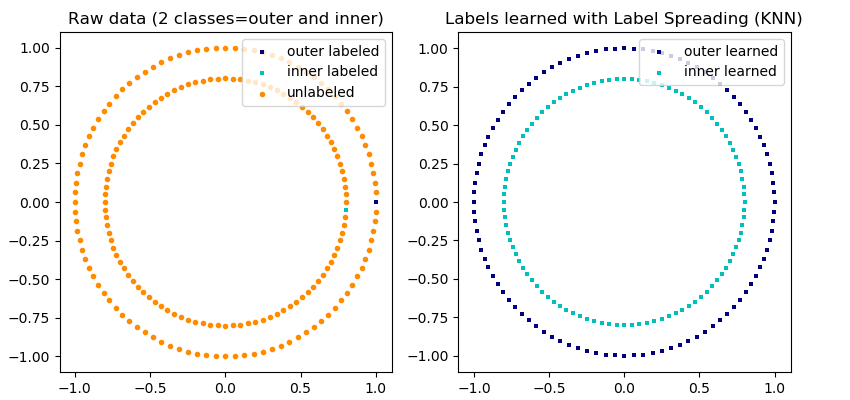
Apprentissage semi-supervisé
Principe : trouver une structure dans les données mais avec une grande quantité de données non labellisées
Apprentissage semi-supervisé
Active learning
Principe :
Procédure dans lequelle l'algorithme peut interroger le superviseur pour obtenir de nouvelles données

Apprentissage auto-supervisé
Principe : apprendre de manière supervisée en utilisant une partie de l'information comme label
self supervised learning
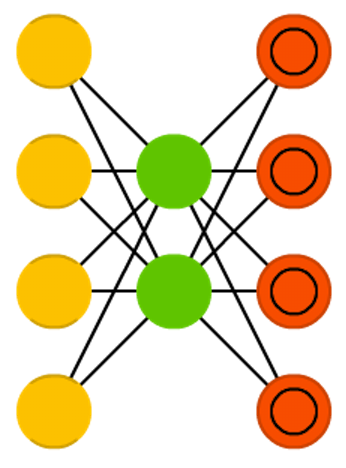
Exemple canonique : l'auto-encodeur
Tâche : prédire ces propres entrées
On utilise souvent une tâche prétexte
Apprentissage auto-supervisé
self supervised learning
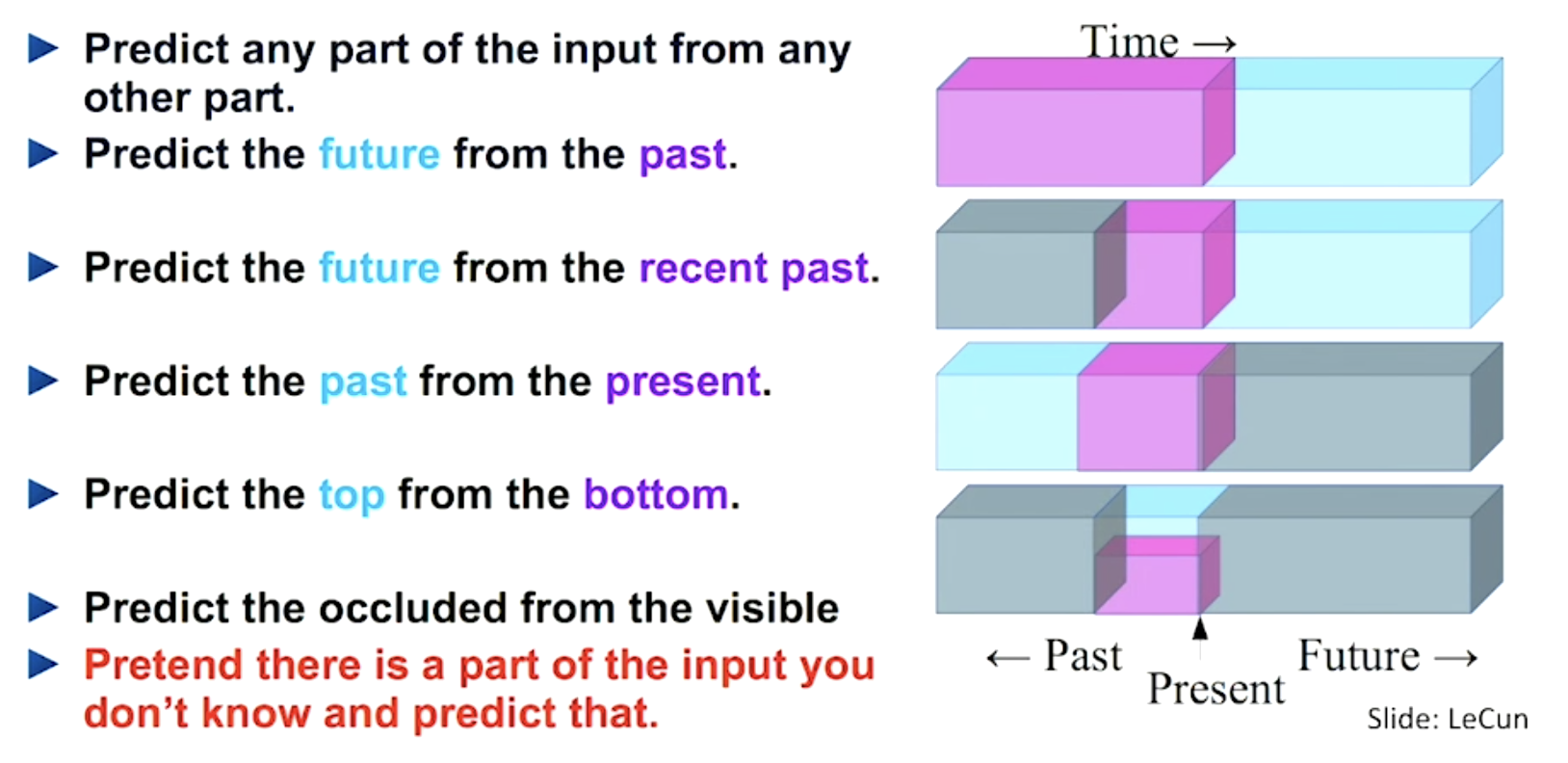
Exemple avec le traitement de séquence
A l'origine des General Langage Model !
Apprentissage auto-supervisé
self supervised learning
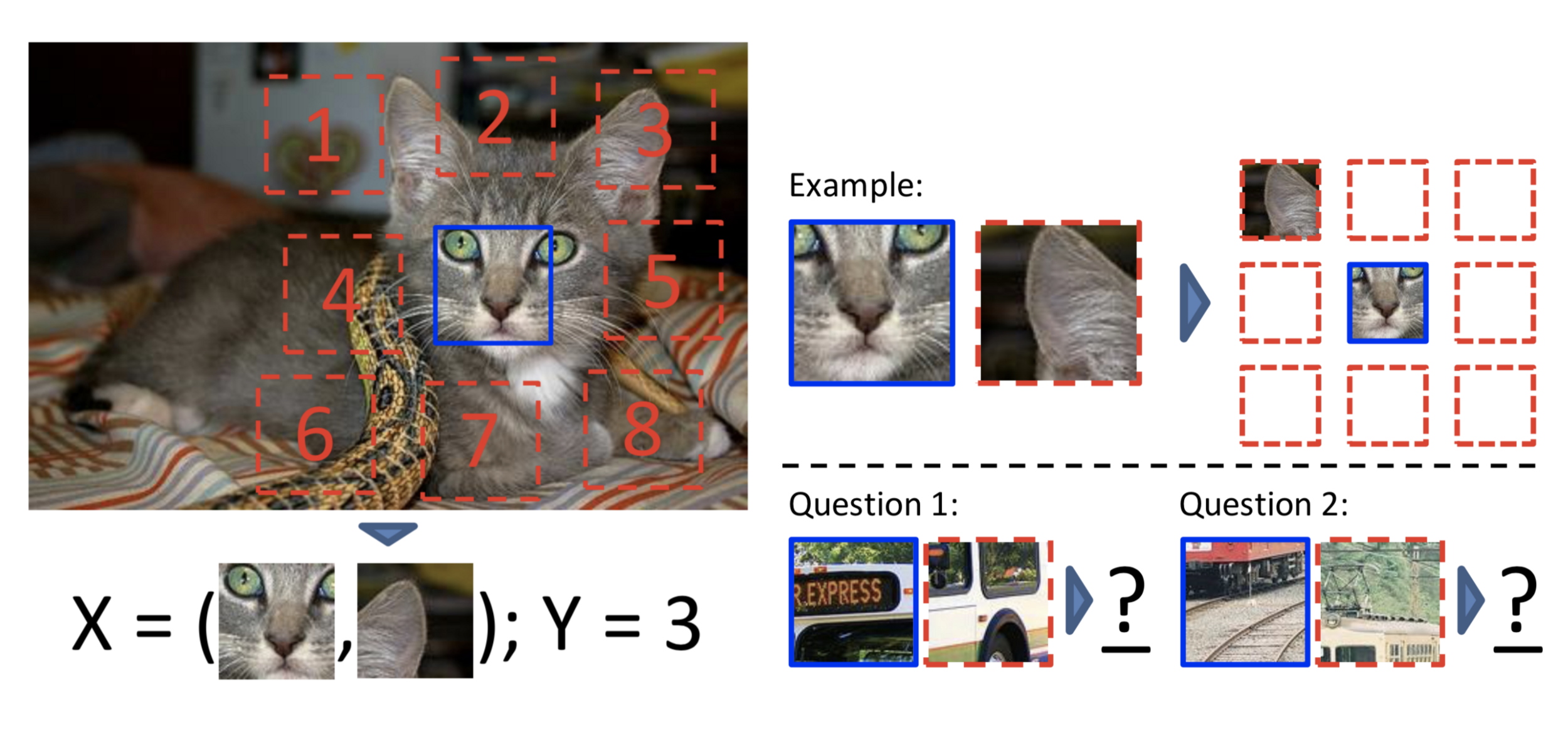
Exemple en vision par ordinateur
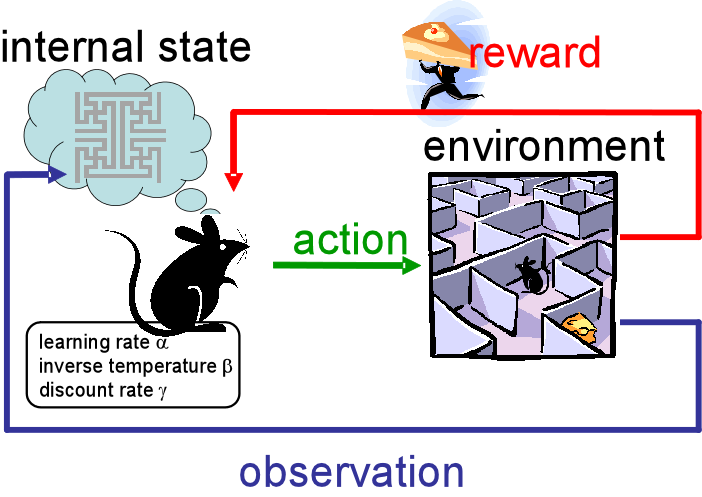
Apprentissage par renforcement
Principe :
Un agent apprend les actions à realiser sur son environnement en maximisant une récompense
Apprentissage par transfert
Principe :
Appliquer des connaissances apprise sur une tâche antérieure, sur de nouvelles tâches
Mini jeu:
Devinez les types d'apprentissages dans ces applications
Catégoriser ou détecter un objet
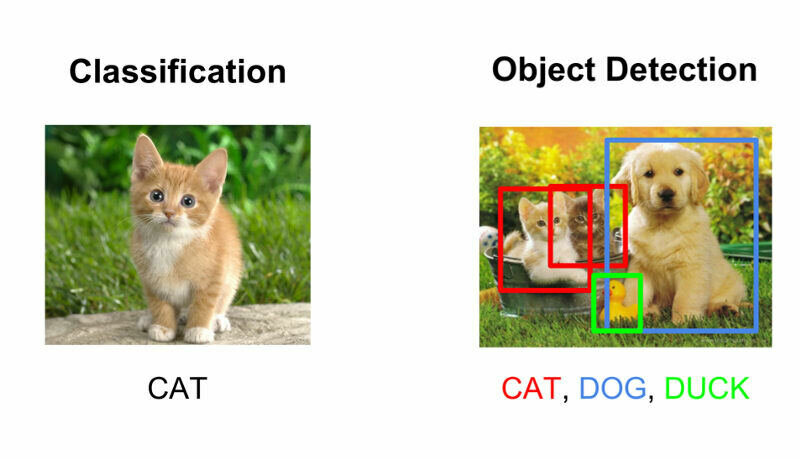
Apprentissage supervisé
détection
catégorisation
Apprentissage par transfert
Prédire une série temporelle
Apprentissage supervisé
Segmenter une image
Apprentissage non supervisé

Modèle de Nvidia pour la segmentation
Détecter une anomalie
...
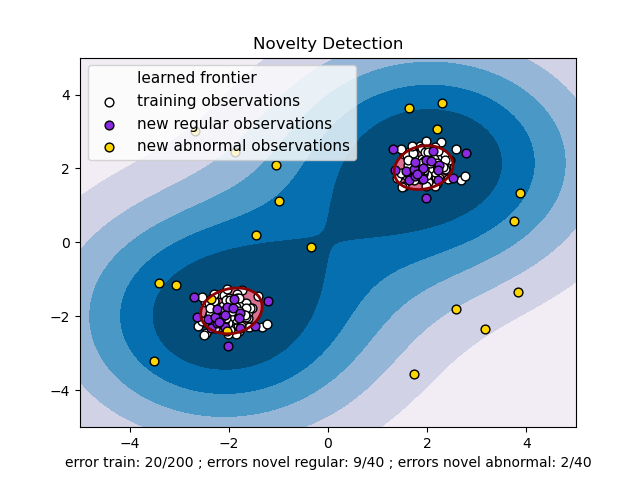
Apprentissage par non supervisé
Générer du texte
...
Apprentissage supervisé ou auto-supervisé
Générer de l'image

Apprentissage supervisé ou auto-supervisé
transfert de style (2015)
Modifier le style dans une image/vidéo
transfert de style vidéo et sur les simulation (2019)
Apprentissage supervisé
Générer de l'image à partir de texte
...
DALL.E 2
Stable diffusion
Jouer à des jeux de plateaux


Apprentissage par renforcement
Les tâches classiques du machine learning
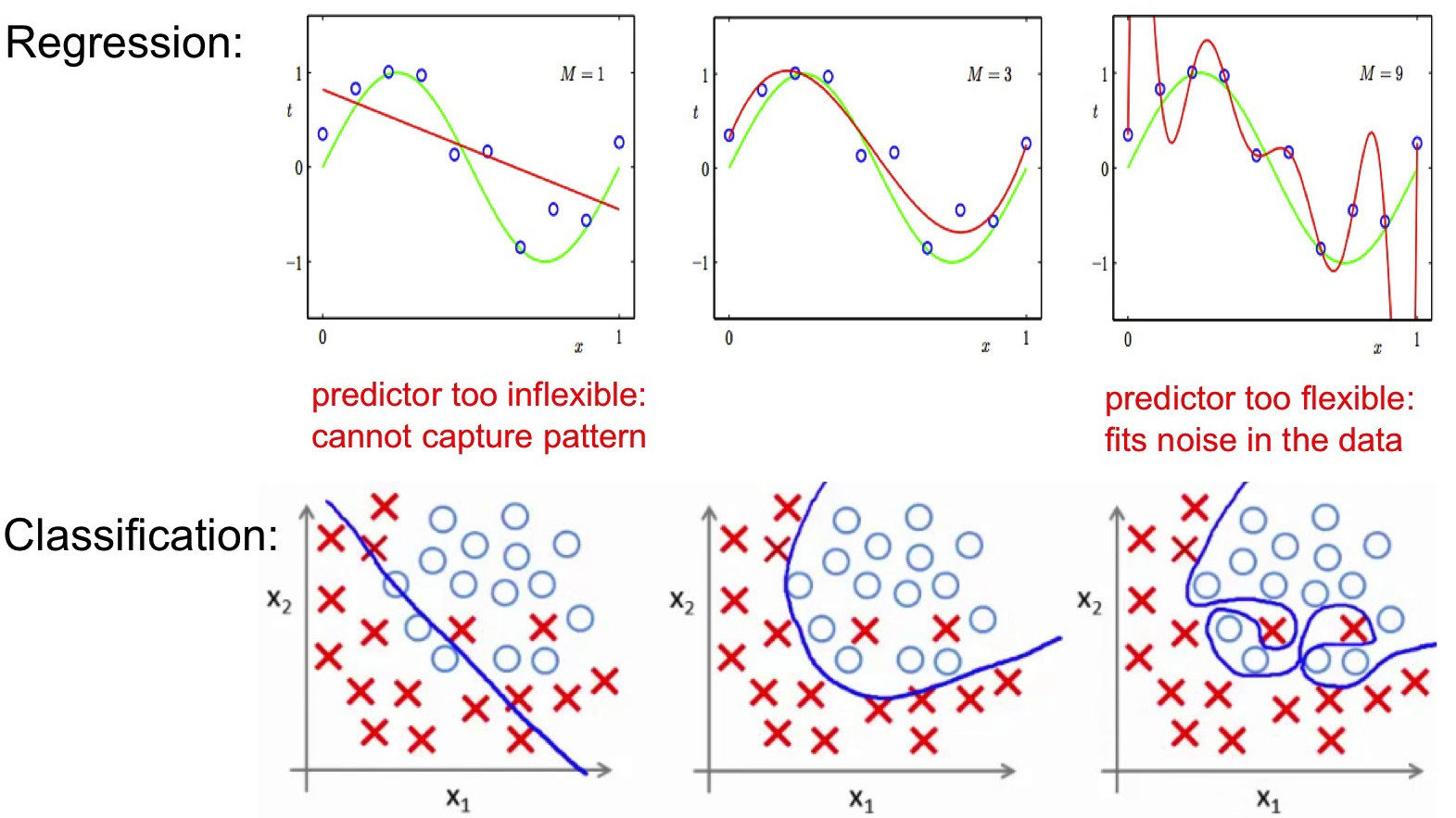
Classification
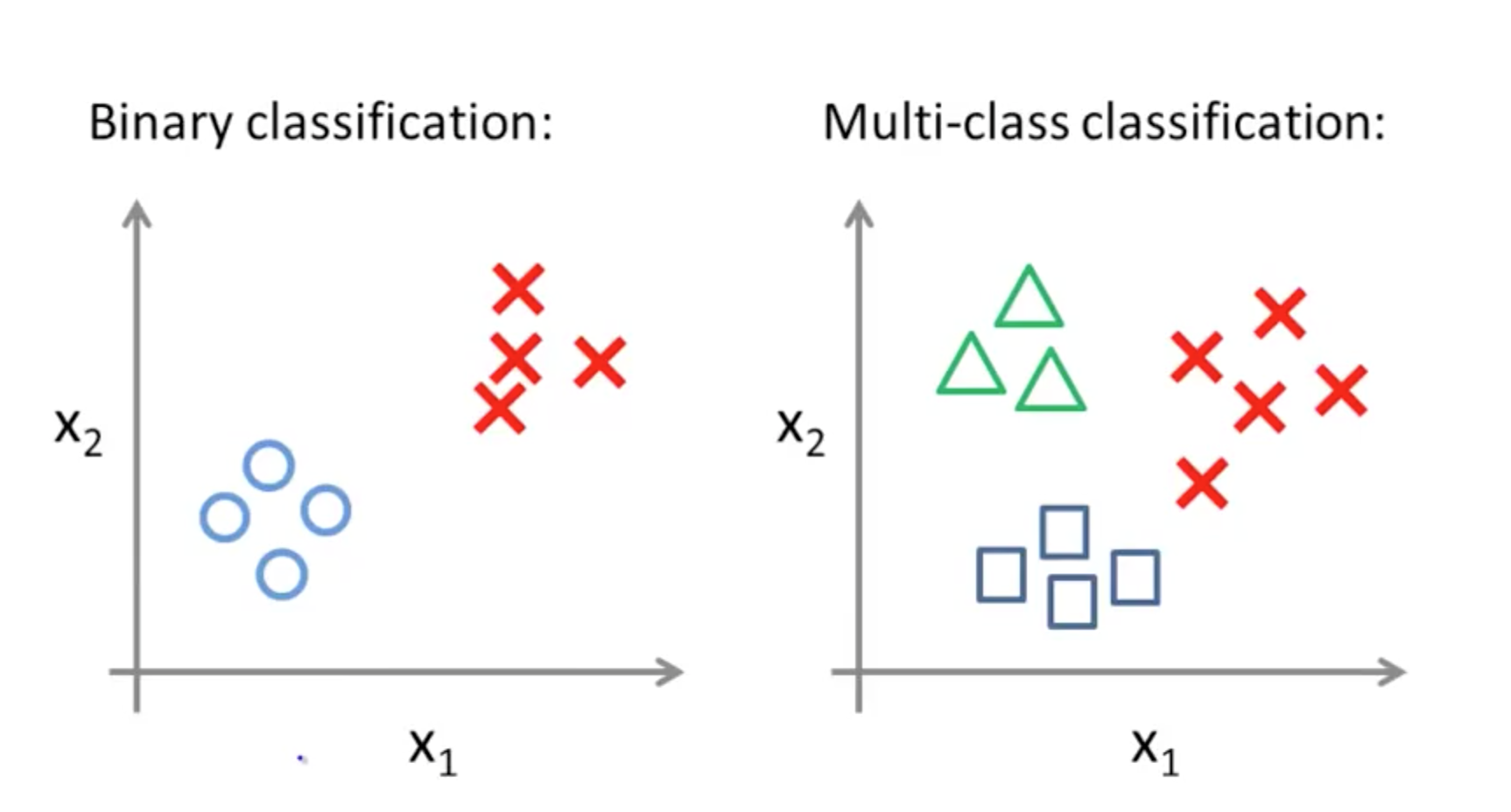
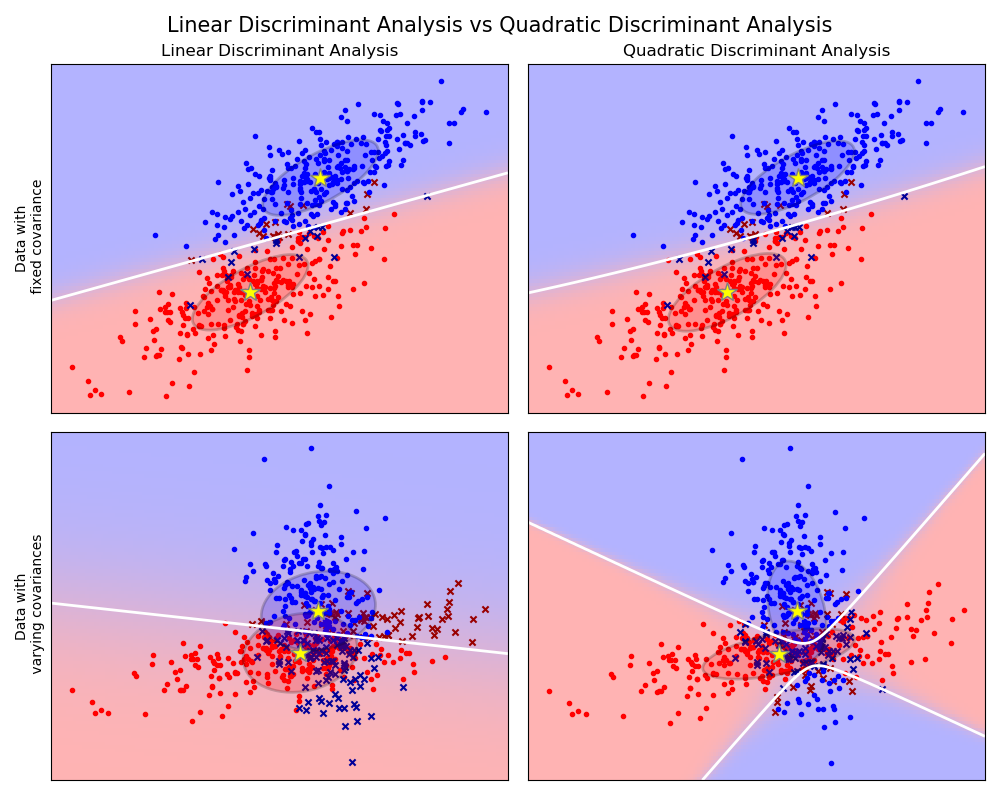
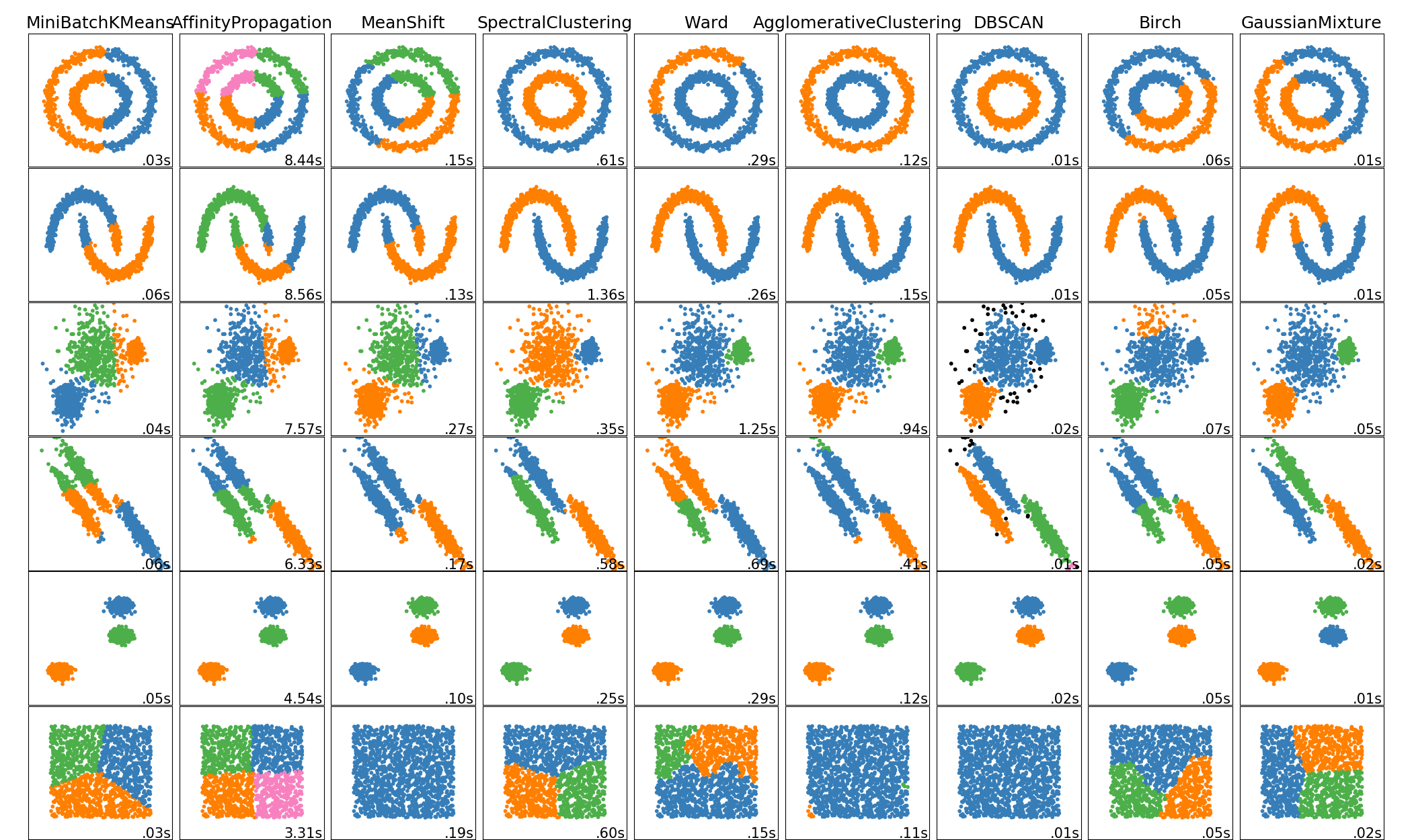
Classification
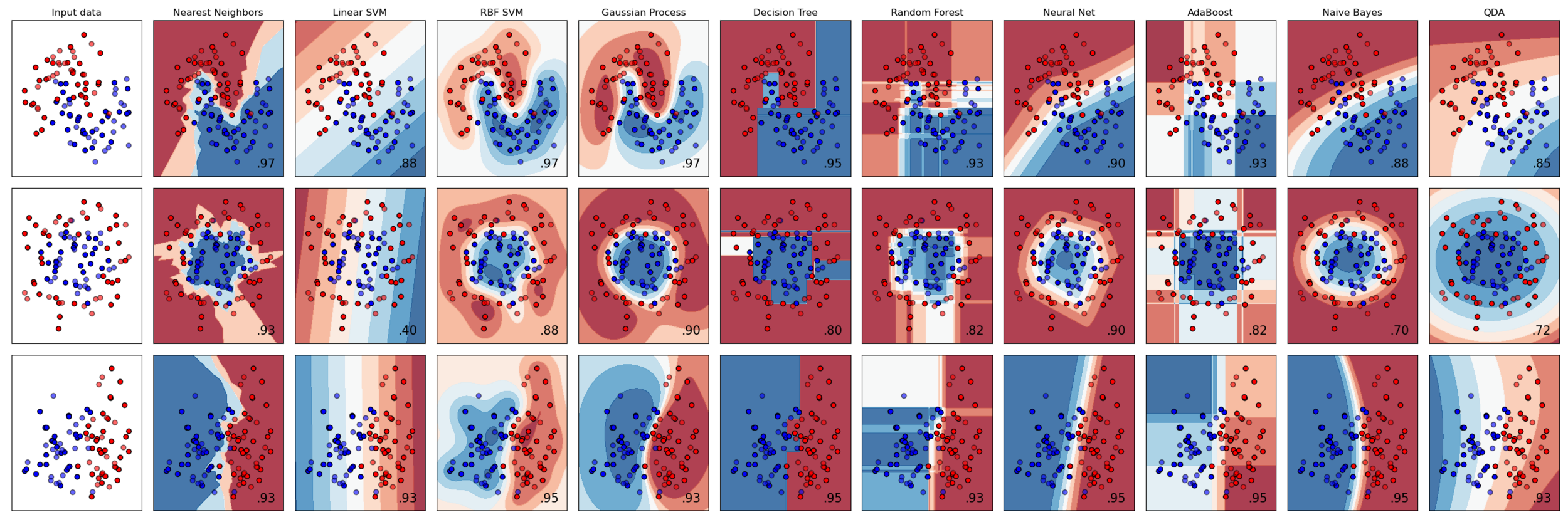
Intuition concernant les différentes frontières de décision de plusieurs algorithmes
Régression
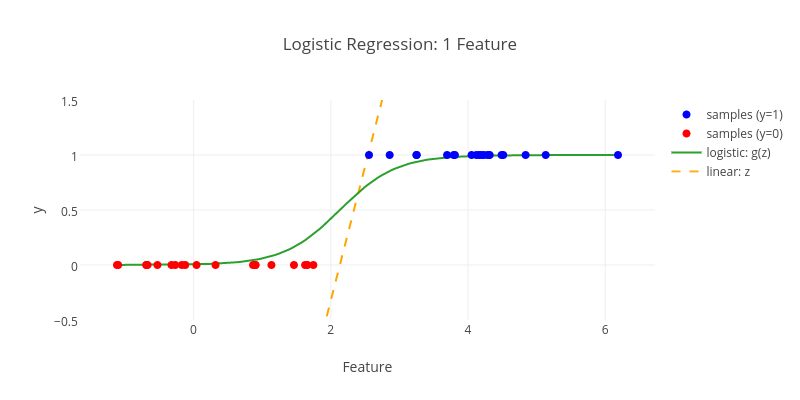
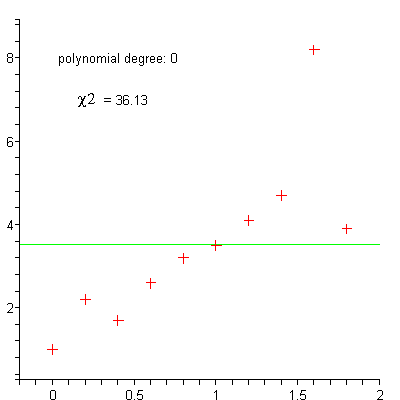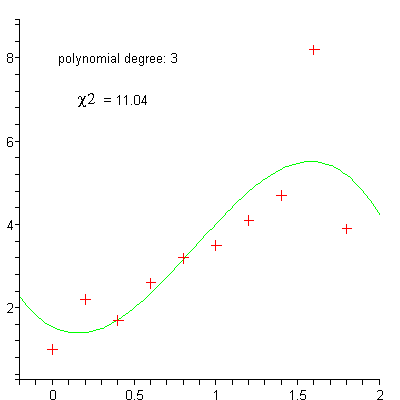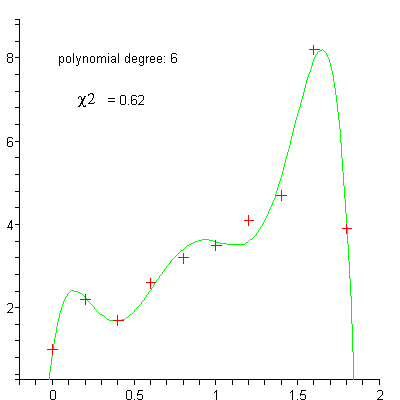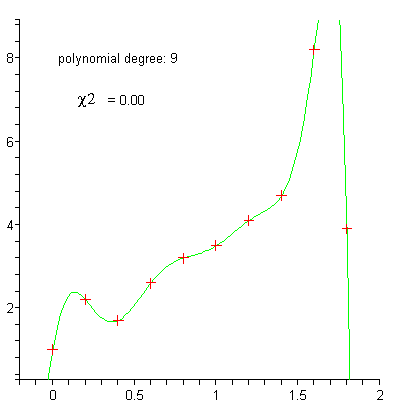
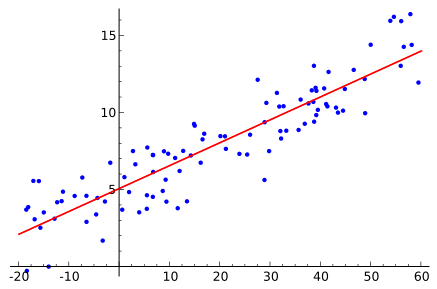
linéaire
logistique
polynomiale
Clustering

Domaines d'application
Quelques domaines d'applications
Traitement de
l'image et du son
Traitement
du
langage naturel
Systèmes de
recommandation
Systèmes
prédictifs
Aide à la
décision
Robotique
planification
d'actions
Quelques domaines métiers
INDUSTRIE
FINANCE
COMMERCE
MEDECINE
ARTISTIQUE
MEDIA
TRANSPORT
...
Maintenance
prédictive
Robots
Gestion de flux
Scoring de crédit
Détection de fraude
Trading automatique
Marketing prédictif
Analyse de sentiment
Découverte de traitements
Prédictions de succès ou récidive
Anticipation de pannes
Robots cuisiniers
Robots
Design génératif
Synthèse de sons
Synthèse d'image
Gestion de ressources
Aide au diagnostic
Véhicules autonomes
Résumé automatique
Ecriture automatique
Recommandation de produits
Recommandation de
contenus
légendage
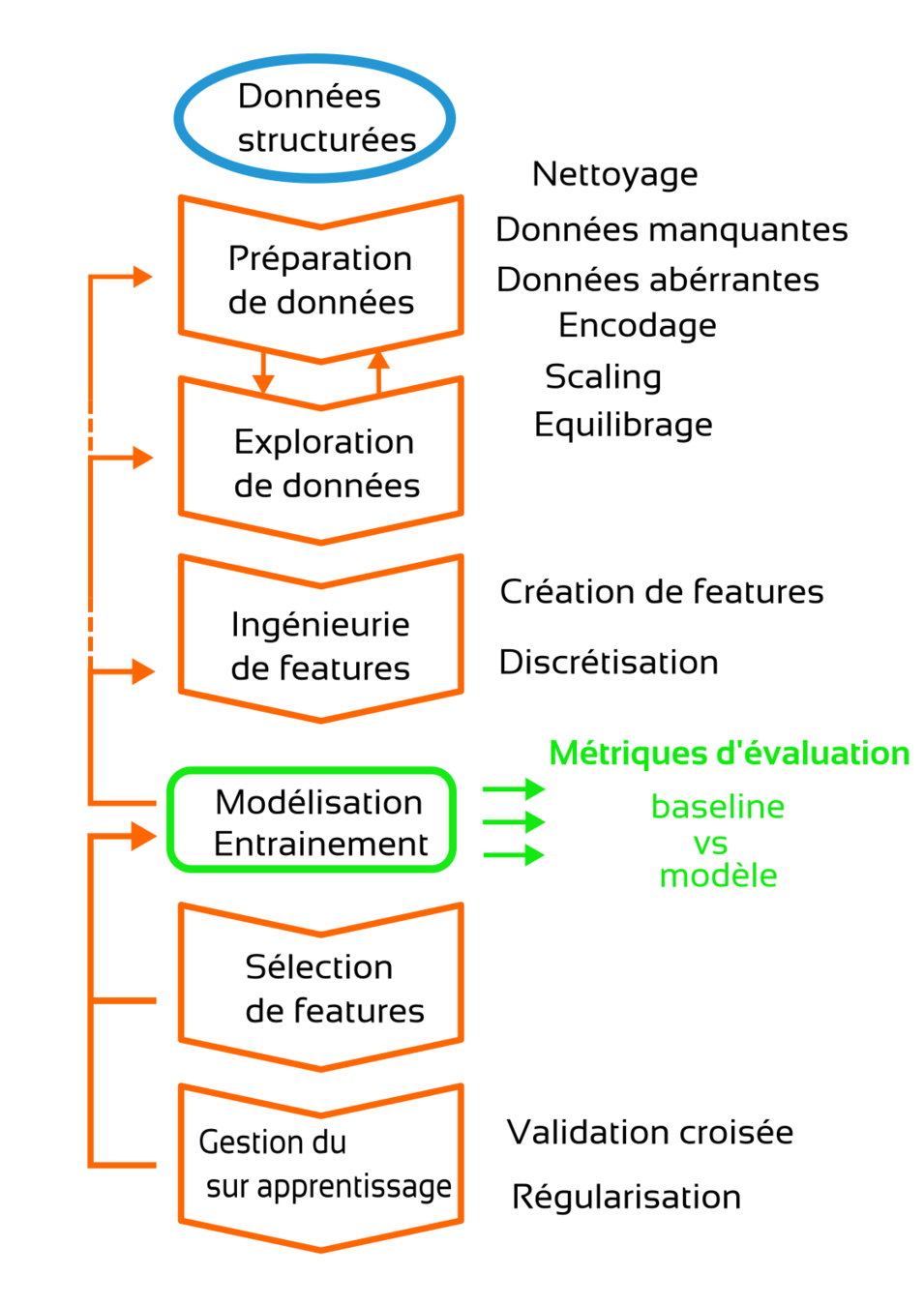
Principes fondamentaux
Etapes de traitement canoniques
Modélisation & entrainement
Choix d'un modèle
Optimisation des paramètres
Modelisation
Entraînement
Model(paramètres, hyperparamètres, ...)
Model.fit(X, y)
paramètres optimaux
paramètres vs hyper paramètres
Paramètres
Hyper paramètres
Valeurs apprises pendant l'apprentissage
Fixée à priori
par le data scientist
Ex: les coefficients d'une régression
Ex: le nombre de couches dans un réseau de neurones
Optimisation des
paramètres
Quasiment tous les algorithmes en machine learning ont des paramètres internes à régler pour donner de bons résultats !
"tuning"
Objectif: minimiser une fonction de coût / d'erreur
L'espace des paramètres comme une "vallée"
Objectif: trouver les Wi qui minimisent J

...
méthodes des moindres carrés
régressions
descente du grandient
réseaux de neurones
méthodes de boosting
Méthodes spécifiques
Elles ne sont applicables qu'a certains types d'algorithmes
Grid Search
Random Search
Bayesian Search
Evolutionnary Search
...
Méthodes généralistes
Applicables à tout types d'algorithme
Halving Search
Optimisation
Choix d'un modèle
Optimisation des paramètres
Modelisation
Entraînement
Optimisation des hyperparamètres
paramètres optimaux
hyper paramètres optimaux
GridSearch.fit (model, grille, X, y)
model = Model(paramètres, hyperparamètres, ...)
Métrique d'évaluation
A choisir en fonction de la tâche et de ses caractéristiques
...
accuracy
score F1
précision/rappel
aire sous la courbe ROC
erreur quadratique moyenne
pourcentage de variance expliquée
distances
inter-clusters
Classification
Régression
Multilabel
Clustering
erreur de couverture
mesures d'homogeneïté des clusters
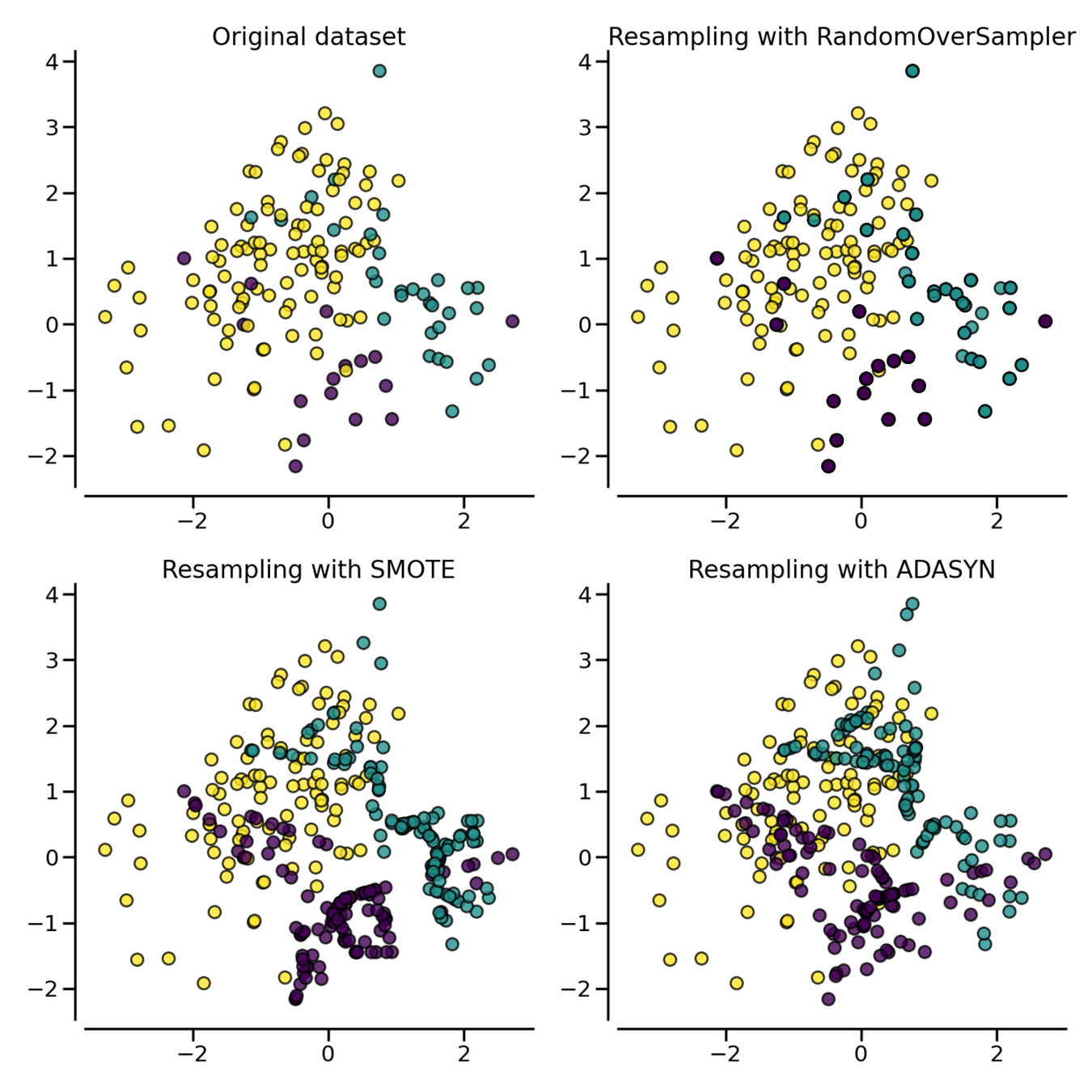
Attention aux données déséquilibrées !
Métrique d'évaluation
Dummy estimators ?
Evaluer les perfomances de son modèle par rapport à une baseline
Toujours prédire une constante ou la médiane
Toujours prédire la classe la plus fréquente
Garder l'esprit critique concernant ses résultats !
...
limitations de l'apprentissage automatique
Compromis biais / variance
bias / variance trade off
Le problème consiste à "régler" l'algorithme pour qu'il apprenne avec suffisamment de précision tout en gardant de bonnes performances sur des données qu'il n'a jamais rencontré (sa capacité à généraliser ses résultats)
Compromis biais / variance
bias / variance trade off
Erreur attendue
calculée sur le jeu de test
Variance de l'estimateur de f
Carré du biais l'estimateur de f
erreur irréductible
"écart entre modèle et réalité des données"
"capacité à estimer f avec le moins variabilité lorsque le dataset change"
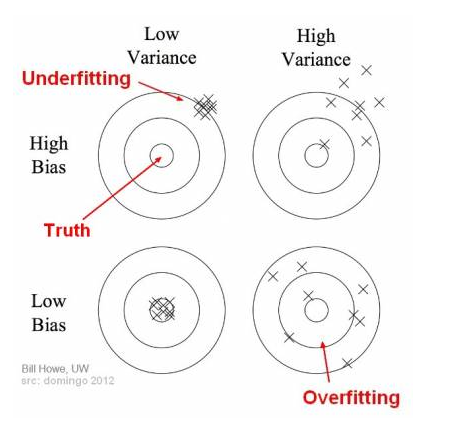
Compromis biais / variance
BIAIS
"écart entre modèle et réalité des données"
VARIANCE
"capacité à estimer f avec le moins variabilité lorsque le dataset change"
Compromis biais / variance
fléau de la dimension
Problème qui apparaît quand notre dataset contient beaucoup de variables par rapport au nombre d'observations
...
...
...
variables
observations
Plus de détails dans cet article
fléau de la dimension avec k-NN

Théorème No free lunch pour l'apprentissage supervisé
Suivant certaines conditions, la performance de tous les algorithmes est identique en moyenne
Conséquence: il n'y pas d'algorithme ''ultime" qui donnerait toujours les meilleurs performances pour une tâche donnée
Les problèmes "incalculables"
Classe de problèmes qui ne peuvent pas être résolus dans un temps raisonnable, c'est à dire qui ont une forte complexité algorithmique
Quelques solutions à ces limitations
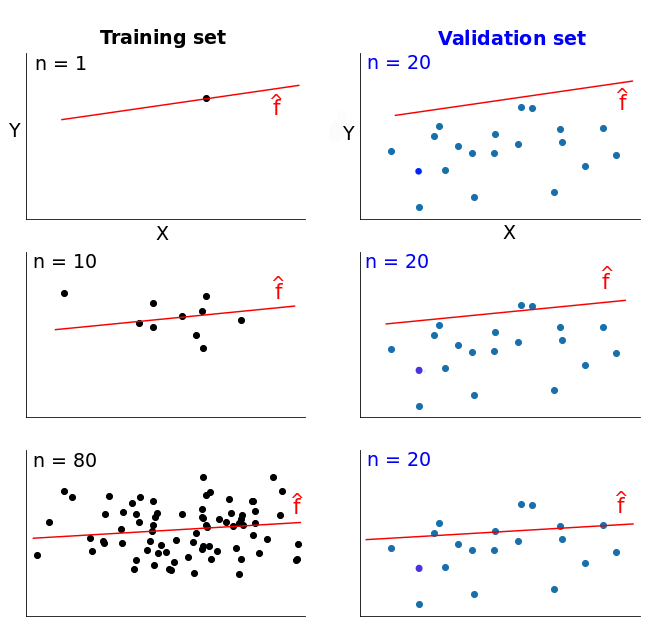
Partition des données
Intérêt : prévenir les risques de sur apprentissage en partionnant le dataset
On échantillonne les données en trois parties:
data set
test
apprentissage & validation
validation
test
apprentissage
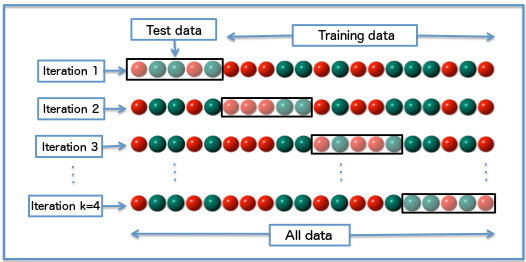
Intérêt: partitionner le data set itérativement en différents échantillon
Validation data
Partition des données
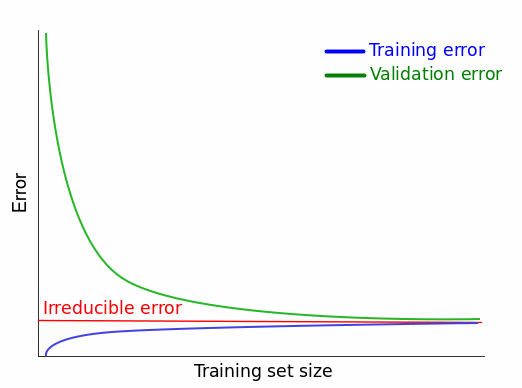
Compromis biais / variance
courbes d'apprentissage en fonction de la complexité
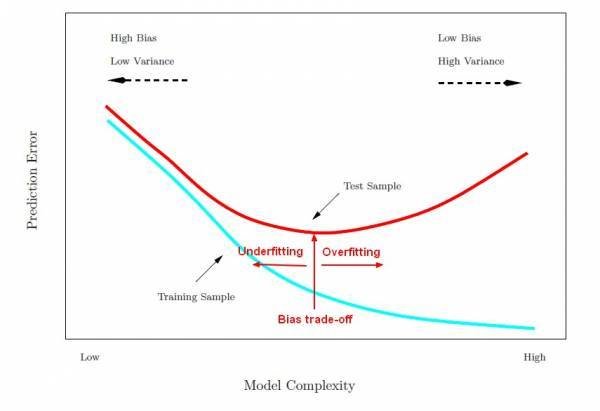
Intérêt : diagnostiquer l'état de ce compromis

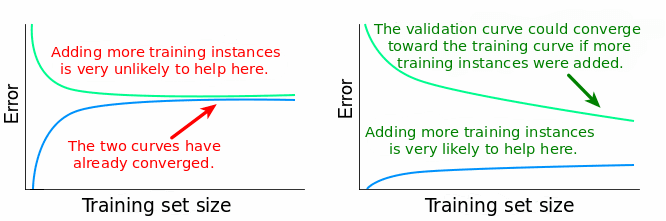
Dans la pratique on peut observer des comportements différents
Interpréter les courbes d'apprentissage
Dans la pratique, le comportement de ces courbes peut être difficile à diagnostiquer
Quelques ressources pour vous aider :
Exemples de quelques cas problématiques
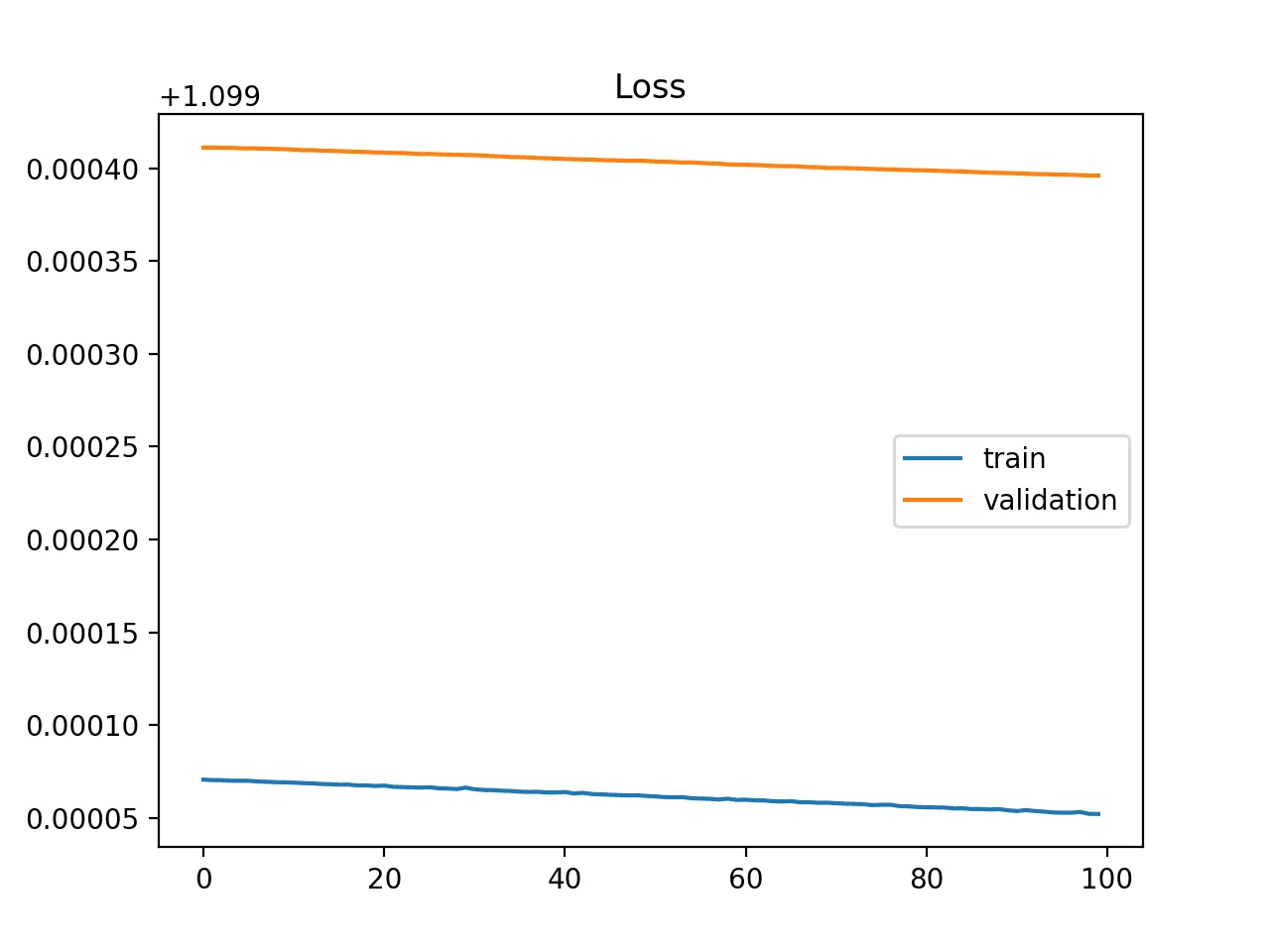
Sous apprentissage probable
La courbe de loss de train est plate ou des valeurs élévée
Exemples de quelques cas problématiques
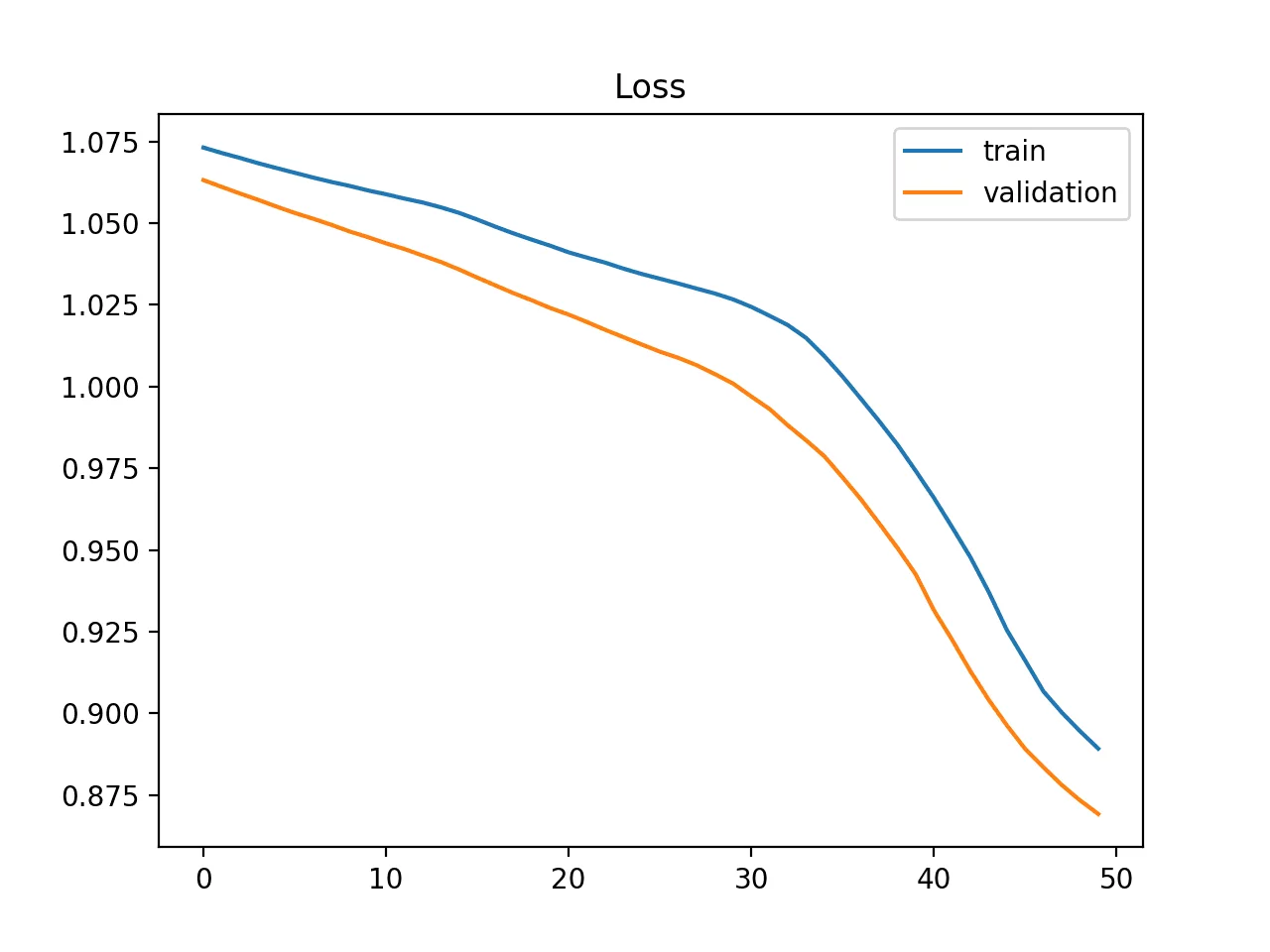
Sous apprentissage probable
La courbe loss de train continue de diminuer à la fin du graphique
Exemples de quelques cas problématiques
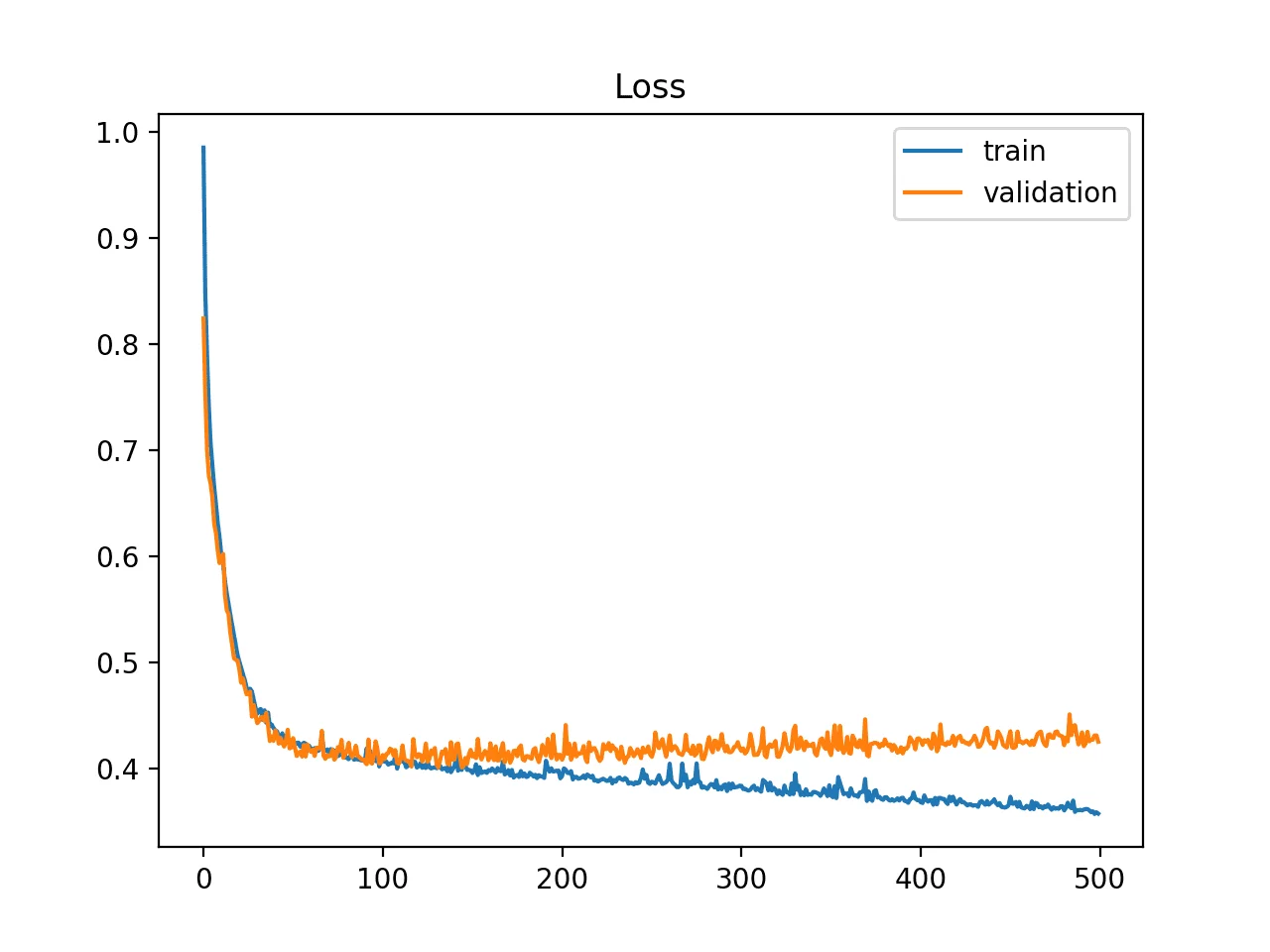
Sur apprentissage probable
La courbe loss de train continue de diminuer
La courbe loss de validation finit par stagner ou augmenter
Exemples de quelques cas problématiques
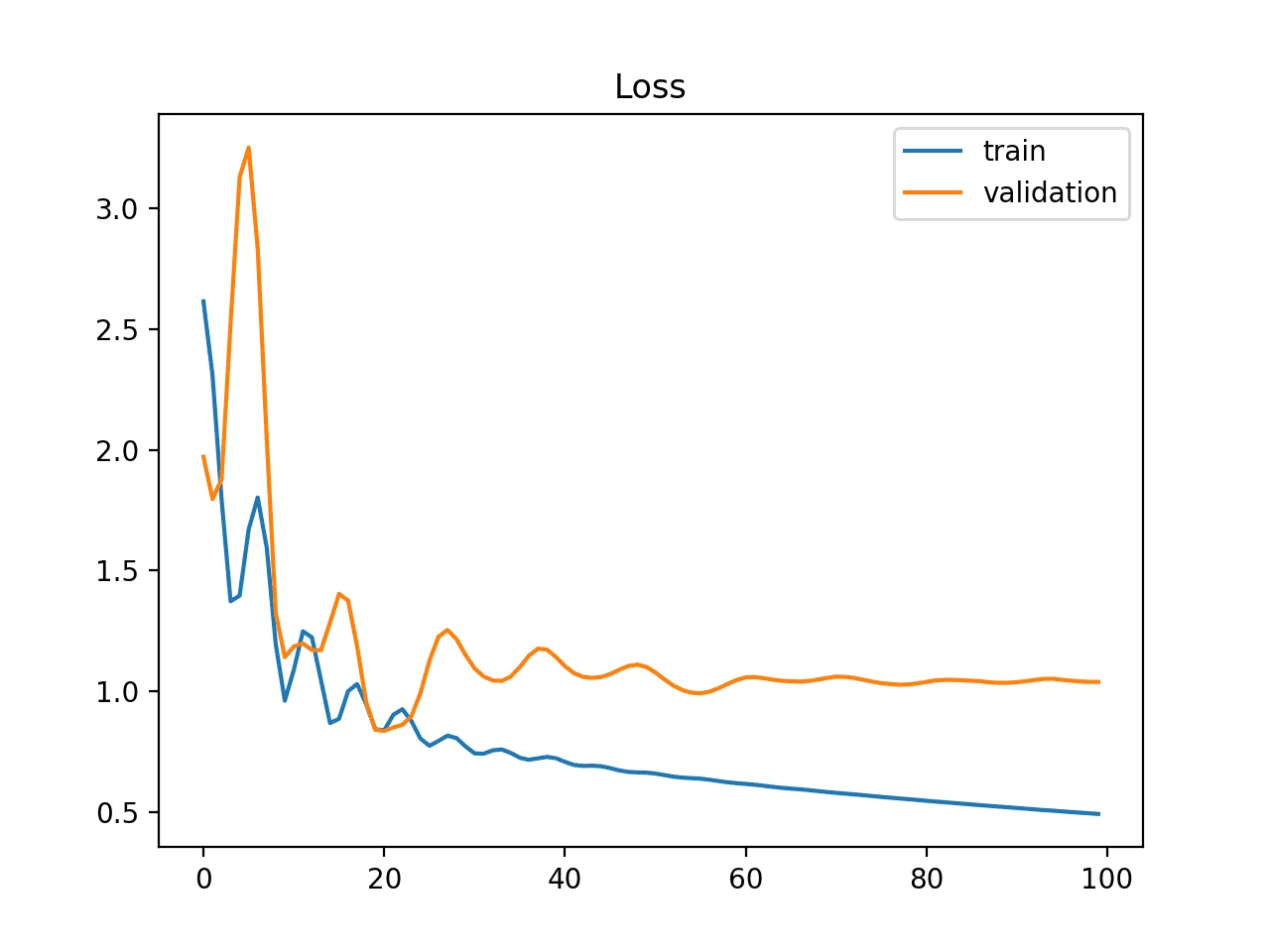
Data set de train probablement non représentatif
Les deux courbes de loss dominuent mais présentent un écart
Exemples de quelques cas problématiques
Data set de validation probablement non représentatif
La courbe de loss de train est cohérente mais la courbe validation est bruitée
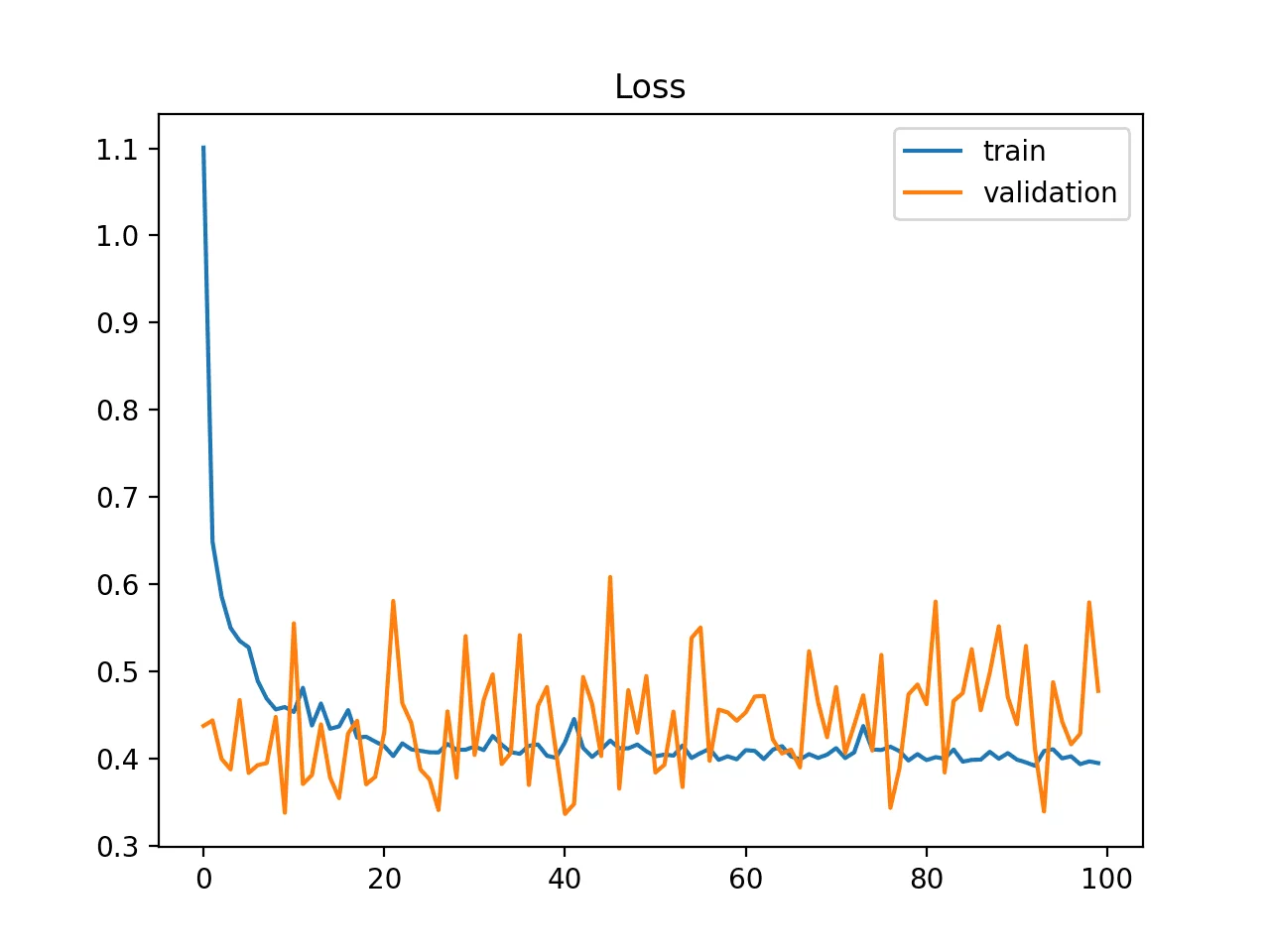
Exemples de quelques cas problématiques
Data set de validation probablement non représentatif
La courbe de loss de validation est inférieure à celle de train
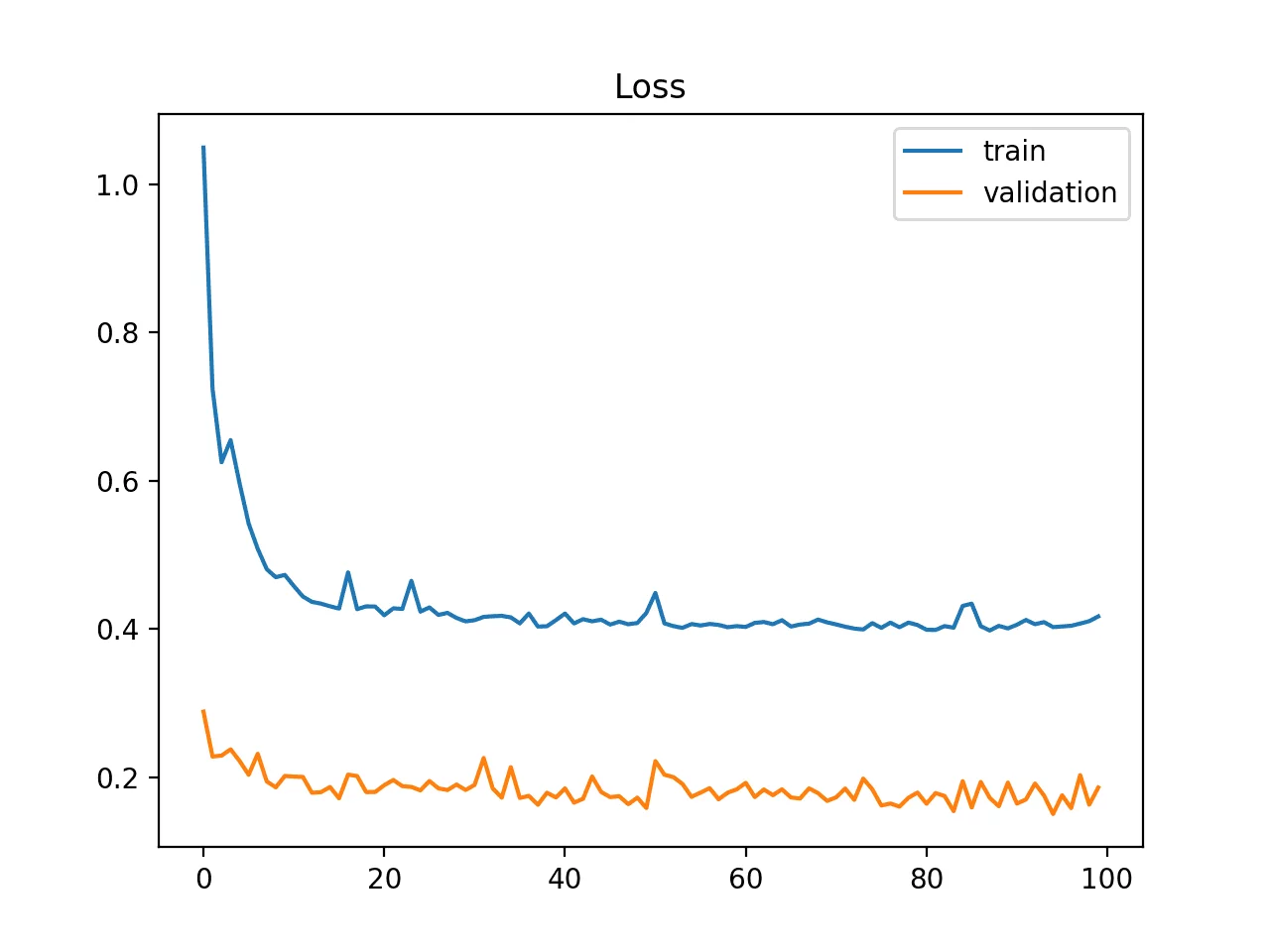
Un ajustement probablement correct
Les deux courbes diminuent
jusqu'a un point de stabilité montrant un faible écart
La courbe de loss du jeu de train est inférieure à celle de validation
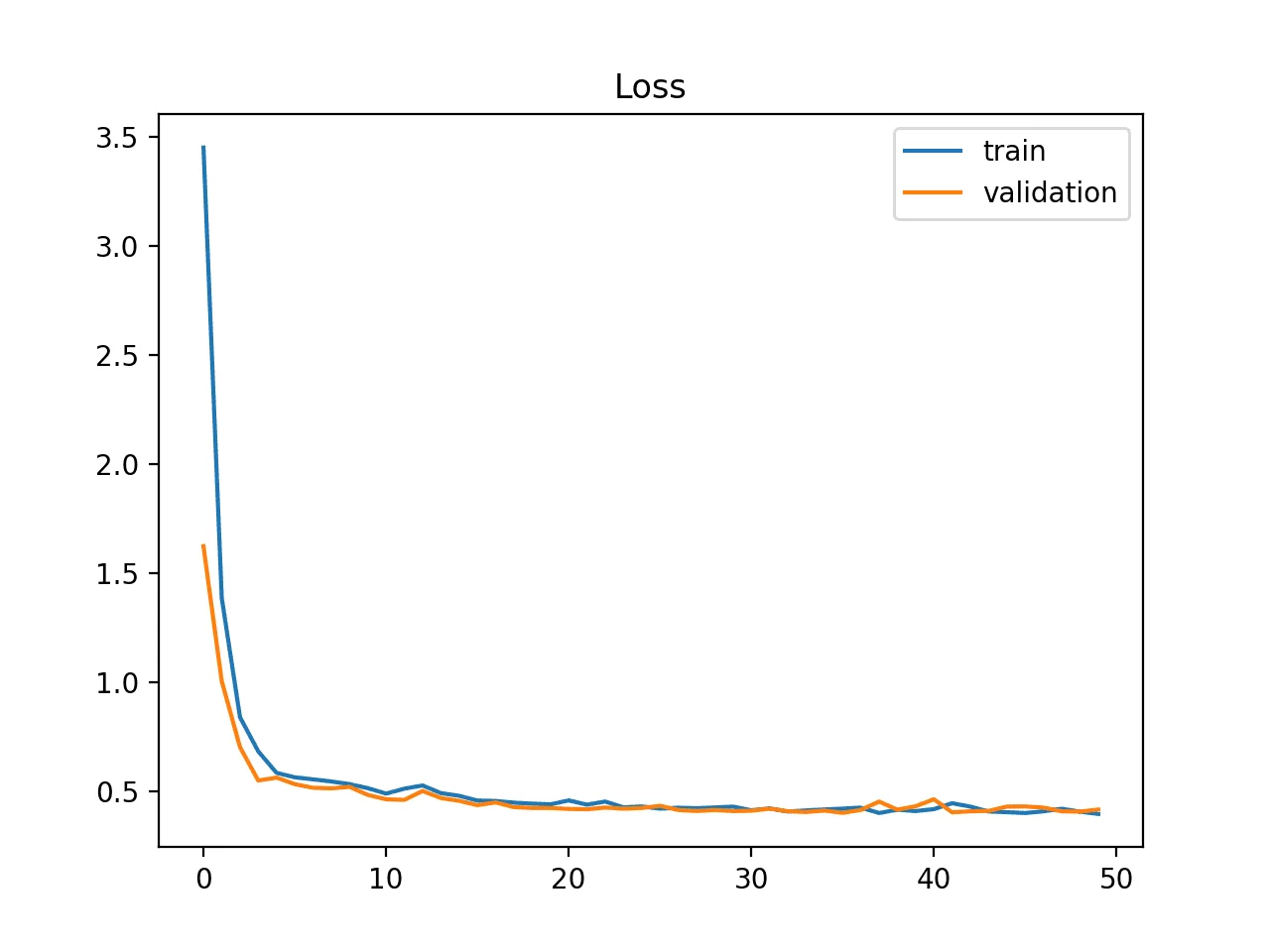
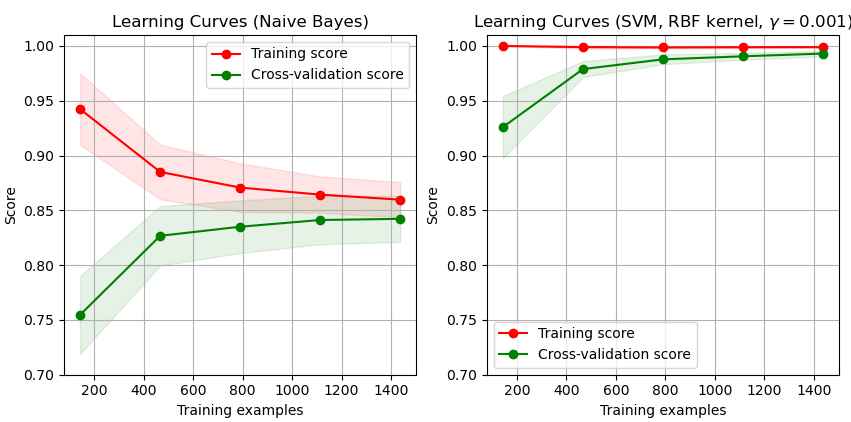
Courbes d'apprentissage
en fonction de la taille du data set
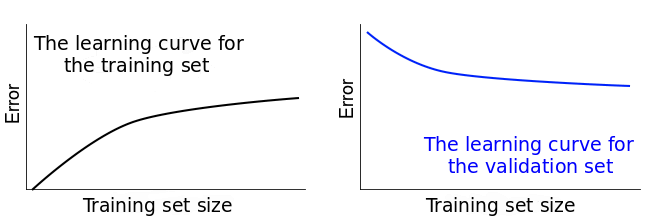
Intérêt : diagnostiquer l'état de ce compromis
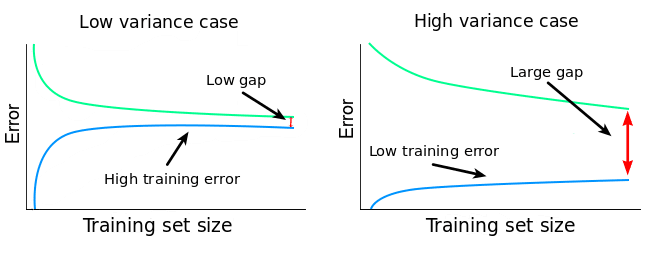
Le compromis : minimiser variance et biais
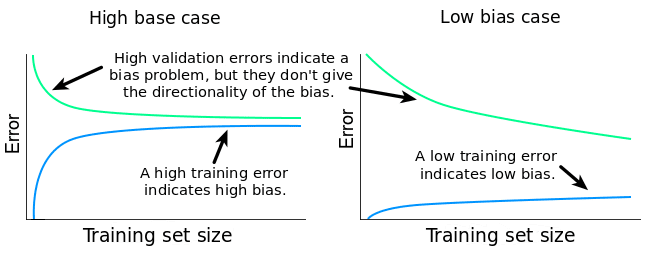
High biais case
Deux situations possibles
fort biais, faible variance
modèle trop rigide
faible biais, forte variance
sous apprentissage probable
modèle trop flexible
sur apprentissage probable
faible biais
faible variance
Le compromis biais - variance idéal
Exemple avec données réelles
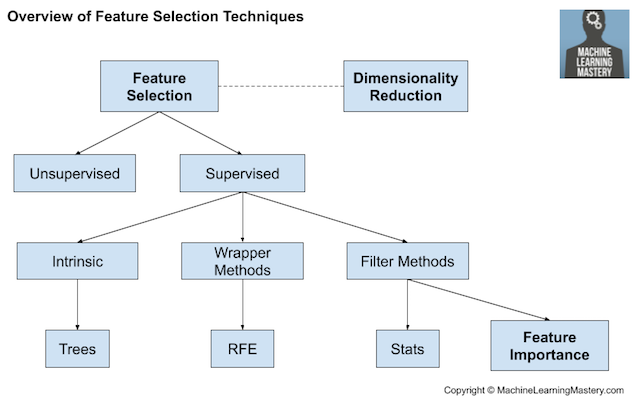
La sélection de modèle/features
Sélectionner dans le dataset le minimum de features qui contribue le plus aux bonnes performances
Threshold Methods
...
Intrinsic methods
Objectif : réduire la complexité du modèle
Wrapper methods
correlations
information gain
...
threshold methods
recursive feature elimination
hierarchical selection
LASSO
Ridge
...
Domain knowledge
Ne s'applique que sur le jeu d'apprentissage pas sur le jeu de test --> risque de data leakage
Pièges a éviter :
A appliquer pendant chaque fold de la cross-validation en même temps que l'entaînement du modèle
La sélection de modèle/features
En pratique, on conseille k=5 ou k=10
La sélection de modèle/features
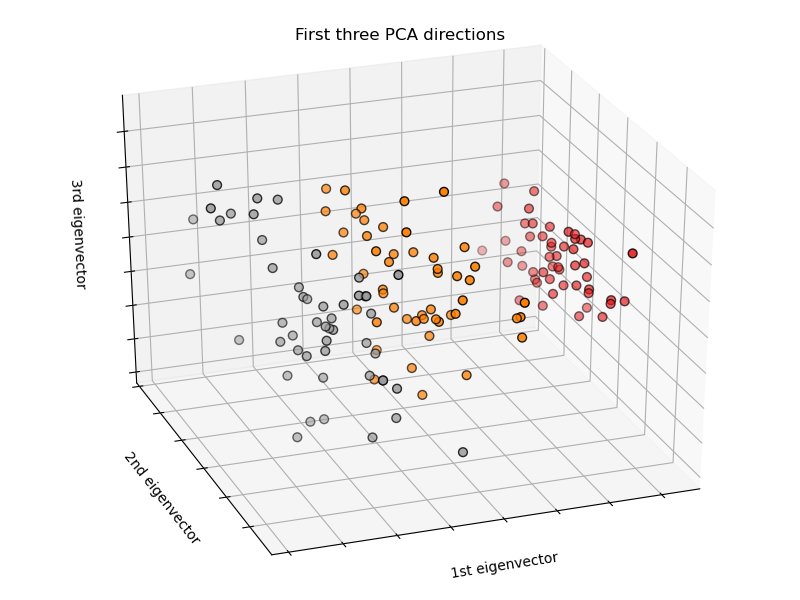
La réduction de dimensionnalité
Principe:
Réduire le nombre de variables du dataset en les recombinant en moins de variables plus complexes mais plus informatives
Très souvent effectuée par l'intermédiaire d'un plongement ou apprentissage de variété
La réduction de dimensionnalité
Exemples de méthodes populaires
La réduction de dimensionnalité
Augmentation de données
Transformer ou enrichir les données existantes
Rajouter plus de données
données métiers, open data, scraping ...
Feature engineering :
créer des nouvelles variables
enrichissement (annotations, méta données, ...)
transformations (déformations d'images, ...)
La régularisation
Idée: contraindre des valeurs de coefficients pour limiter leur variations
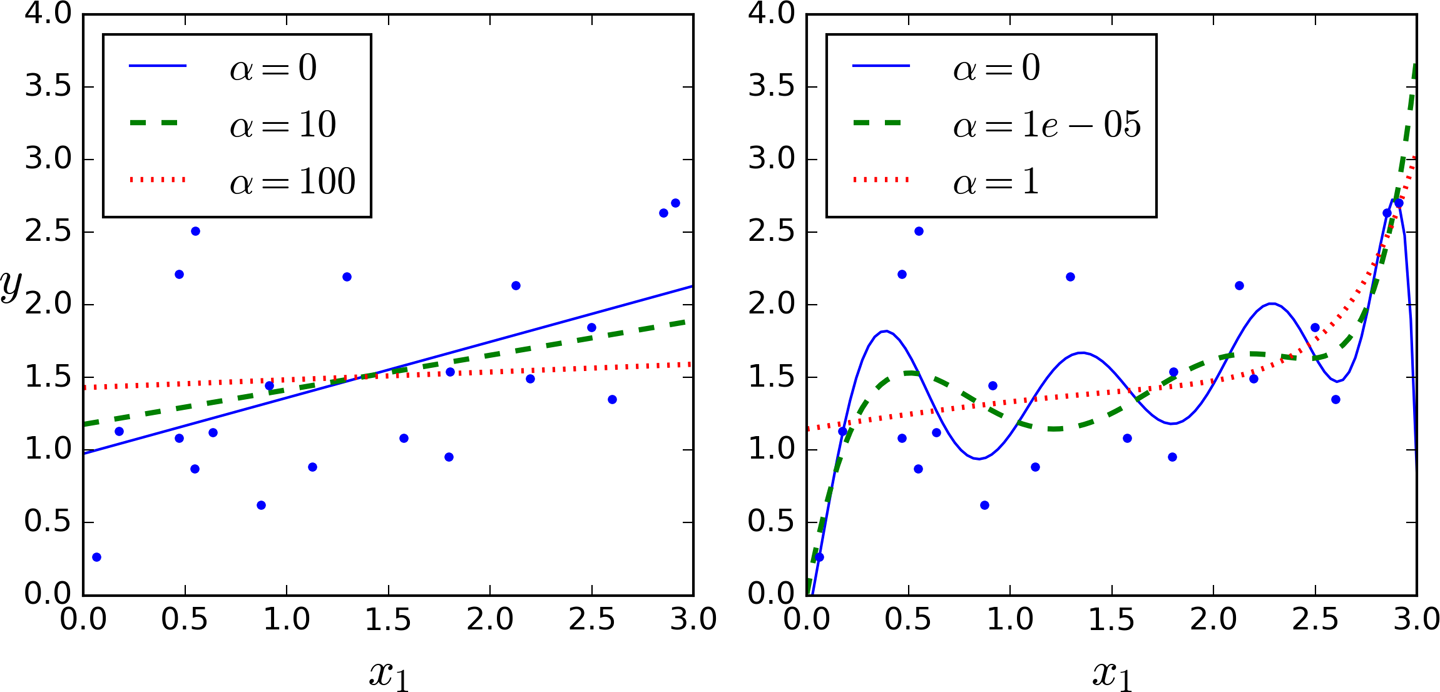
régression linéaire
régression polynomiale
Utiliser des méthodes ensemblistes
méthodes parallèles
méthodes séquentielles
méthodes parallèles simple
bagging
boosting
gradient boosting
Stacking
Combiner différents modèles pour obtenir un modèle plus performant
Attention aux erreurs communes
Oubliez l'optimisation !
L'essence du Machine Learning est de trouver les meilleurs paramètres qui minimisent la fonction de perte
La plupart des librairies vous permettent d'utiliser les algorithmes de machine learning avec des paramètres par défaut :
from sklearn.tree import DecisionTreeRegressor
regressor = DecisionTreeRegressor(random_state=0)
regressor.fit(X_train, y_train)
Par exemple, si vous écrivez ce code avec un Decision Tree :
Si votre algorithme ne comprend pas de méthode d'optimisation, vous devez à minima utiliser une méthode de GridSearch !
Attention au data leakage !
C'est un phénomène qui survient lorsque vous utilisez ,pendant un entraînement, des informations auxquelles votre algorithmes ne devrait pas avoir accès
Par ex, en utilisant dans les features des informations de la cible :
Attention au data leakage !
C'est un phénomène qui survient lorsque vous utilisez ,pendant un entraînement, des informations auxquelles votre algorithmes ne devrait pas avoir accès
Ou bien en oubliant d'appliquer le split des données avant les traitements :
appris
Attention au data leakage !
C'est un phénomène qui survient lorsque vous utilisez ,pendant un entraînement, des informations auxquelles votre algorithmes ne devrait pas avoir accès
Appliquer le split des données avant les traitements :
appris
appliqué
appliqué
Intuitions de quelques algorithmes populaires
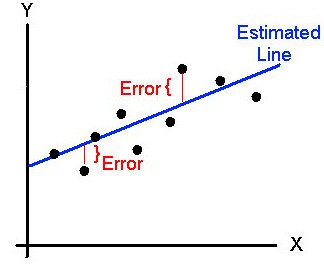
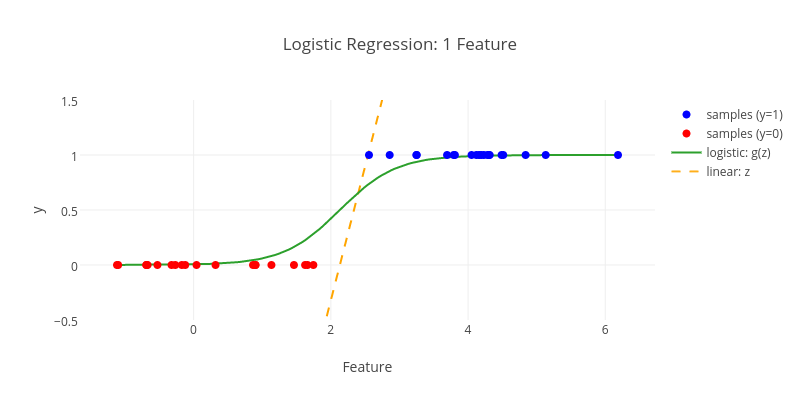
Régression linéaire & logistique
Séparateur à Vaste Marge (SVM)
Support Vector Machine
Maximise la distance entre une frontière de décision et différentes classes d'échantillons

Arbres de décisions
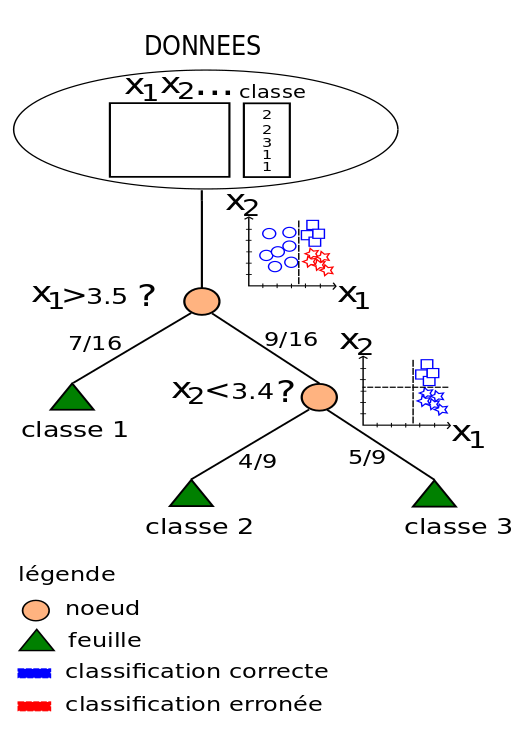
Principe:
trouver une règle la plus optimale pour partitionner les données en "clusters" homogènes
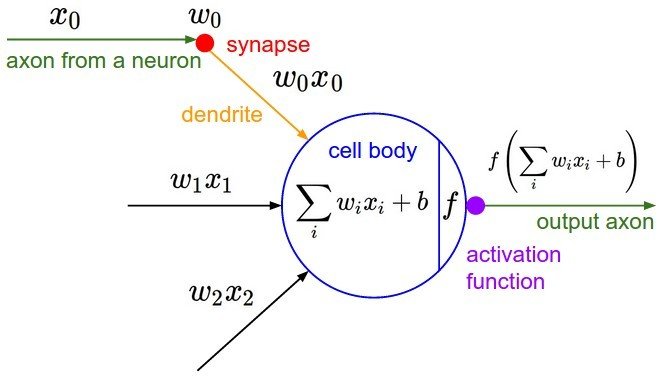
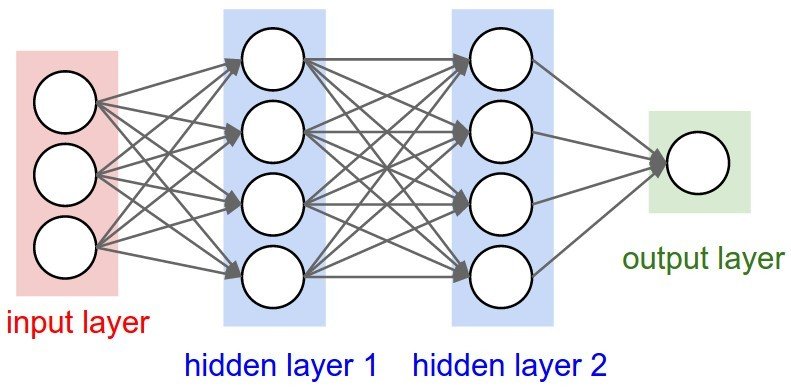
Réseau de Neurones
K-means





Ressources & outils
Logiciels
Scikit-learn
TensorFlow
Torch / PyTorch
H2O.ai
Spark MLlib
KNIME
RapidMiner
Weka
CNTK
Microsoft Azure ML
Amazon Machine Learning
Neural Designer
...
Google Cloud AI
SAS
Python
Scala
Julia
Kaggle
Langages
FRAMEWORKS
Plateformes
No-code
Copilot
Assistants
GPT playground
Matériel
GPU
TPU
Cloud
CPU
...
Ecosystème Hadoop
Stockage distribué
calcul distribué
Base de données SQL, NoSQL
BIG DATA
CALCUL
Microsoft Azure ML
Amazon Machine Learning
Google Cloud AI
OVH
Data warehouse
Data mesh
Data Lake
Considérations éthiques
Considérations éthiques
Nécessité d'encadrer l'IA par de l'éthique
Envisager l'IA comme un compagnon de l'Humain plutôt qu'un remplaçant