Data science:
Analyse & traitement de données
Nicolas Rochet
2024
Quelles tâches ?
Modéliser les données
Trouver des patterns
Résoudre des problèmes
Trouver le plus court chemin
Jouer le meilleur coup
'Simuler' un expert
Identifier des comportements
Détecter des erreurs de mesure
Régression
Classification
Clustering
Statistiques
Simulation
...
IA
Deux approches
Fouille de données
Analyses dirigées
Extraire des connaissances
à partir d'un vaste ensemble de données
Les données & méthodes d'analyses sont choisies en fonction du problème
V
S
Processus
Préparation de données
Traitement
des données
Exploration des données
Modelisation
Résolution de problemes
Recherche de motifs
Statistiques descriptives
Clustering
Gestion des valeurs manquantes
Gestion des outliers
Sélection de features
Analyse exploratoire (EDA)
Quelques étapes génériques
Statistiques "simples"
Décrire/résumer des données
...
Statistique descriptive
quantiles
test de comparaisons
corrélation
Indicateurs univariés
Indicateurs mutli variés
mesures de tendeance centrale
Analyse de la covariance
test d'hypotheses
mesures d'erreur
intervalle de confiance
méthode de plongements
Statistique inférentielle
Déduire des renseignements
à partir d'un échantillon ou d'une population
tests d'adéquations à un modèle
statistiques bayésiennes
test d'indépendance
Statistiques "simples"
test de comparaisons
test d'hypotheses
mesures d'erreur
intervalle de confiance
Statistique inférentielle
Déduire des renseignements
à partir d'un échantillon ou d'une population
tests d'adéquations à un modèle
Statistiques "simples"
L'autre monde: les statistiques bayésiennes
Méthodes univariées
Vérification des données manquantes et outliers
Analyse de distribution de variables
Analyse de tendances: mediane, variance, asymétrie, kurtsosis
Exploration supplémentaire de données par visualisation
...
Comprendre mieux ses données



treemap
barplot
steam graph
nuage de points
violin plot
Méthodes univariées
...
Un résumé des données ne suffit pas pour comprendre ces données !!!
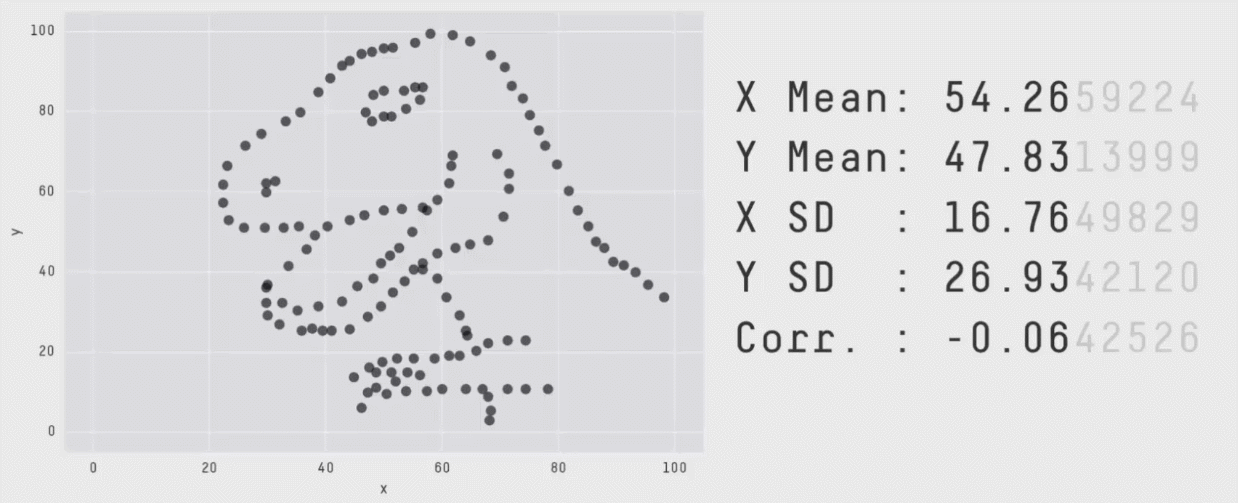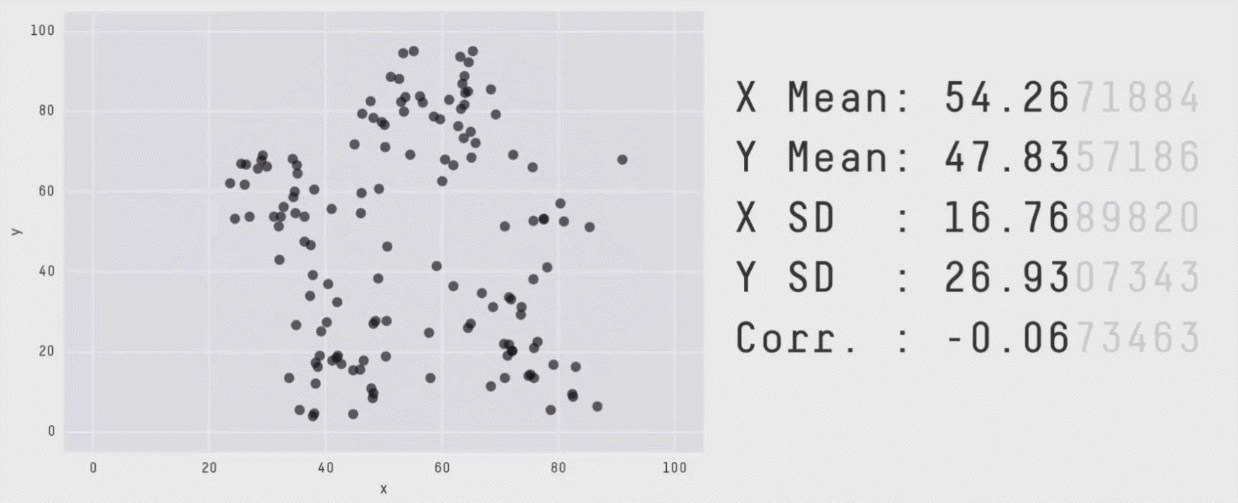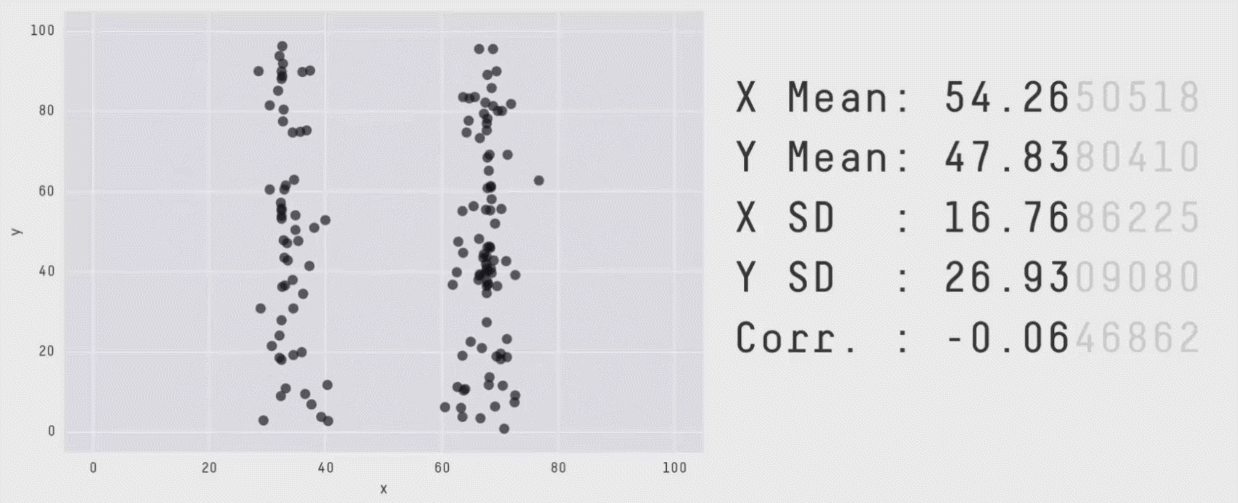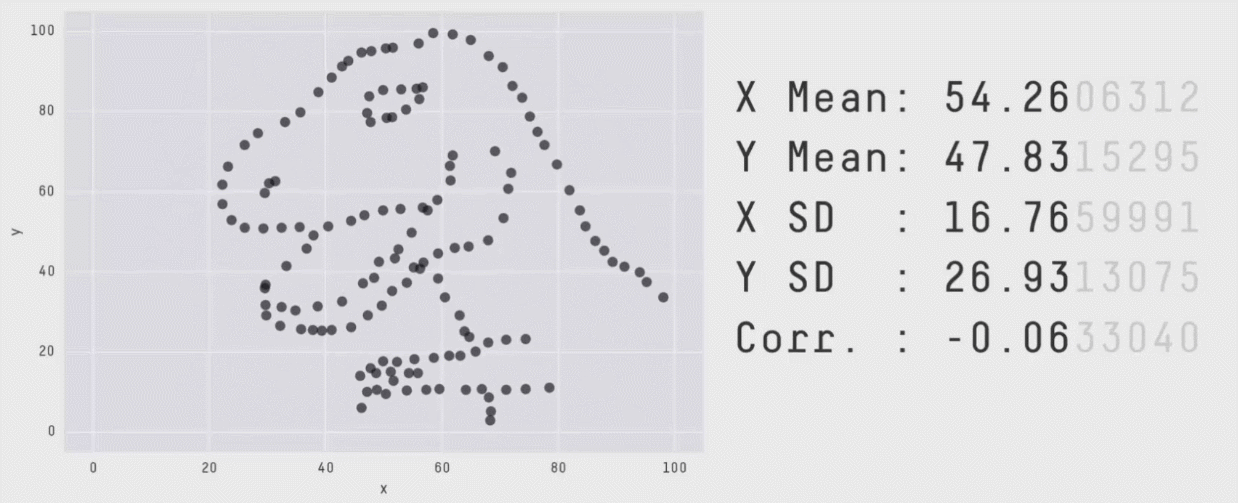
Méthodes multi-variées
Explorer la relation entre les variable
Calculer la matrice de corrélation entre les variables
Méthodes de réduction de dimension
Rechercher des liens non linéaires: polynomes, ...
...
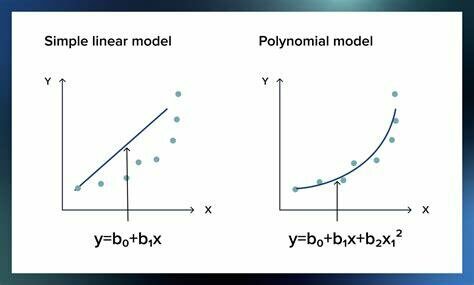
Linéaire :
Non linéaire :
Méthodes automatisées
De plus en plus de paquets permettent une analyse exploratoire plus ou moins automatisée
...
Méthodes automatisées
De l'EDA vers l'autoML
...
Analyser un ensemble de données
Modèles
Patterns
Résolution de problèmes
Modèles vs Patterns
Le domaine de la fouille de données recherche des informations de deux types
Modèles
Patterns
(ou comportements)
Une structure caractéristique qui se manifeste dans un petit nombre d'observations
Un modèle est un résumé global
des relations entre variables, permettant de comprendre des phénomènes, et d’émettre des
prévisions
Modèles
Trouver un résumé global des relations entre variables
...
Modélisation statistique
Modélisation basée sur des règles
régression
classification
Simulations
clustering
réduction dimension
détection d'anomalie
traitement du langage
vision par ordinateur
recommandation
Attention aux modèles !
Un modèle reste une approximation de la réalité
Tous les modèles sont faux, certains sont utiles,
Georges Box
En pratique, l'exploration des données et la connaissance du domaine doivent guider le choix du modèle
Attention aux modèles !
Exemple du sur-apprentissage
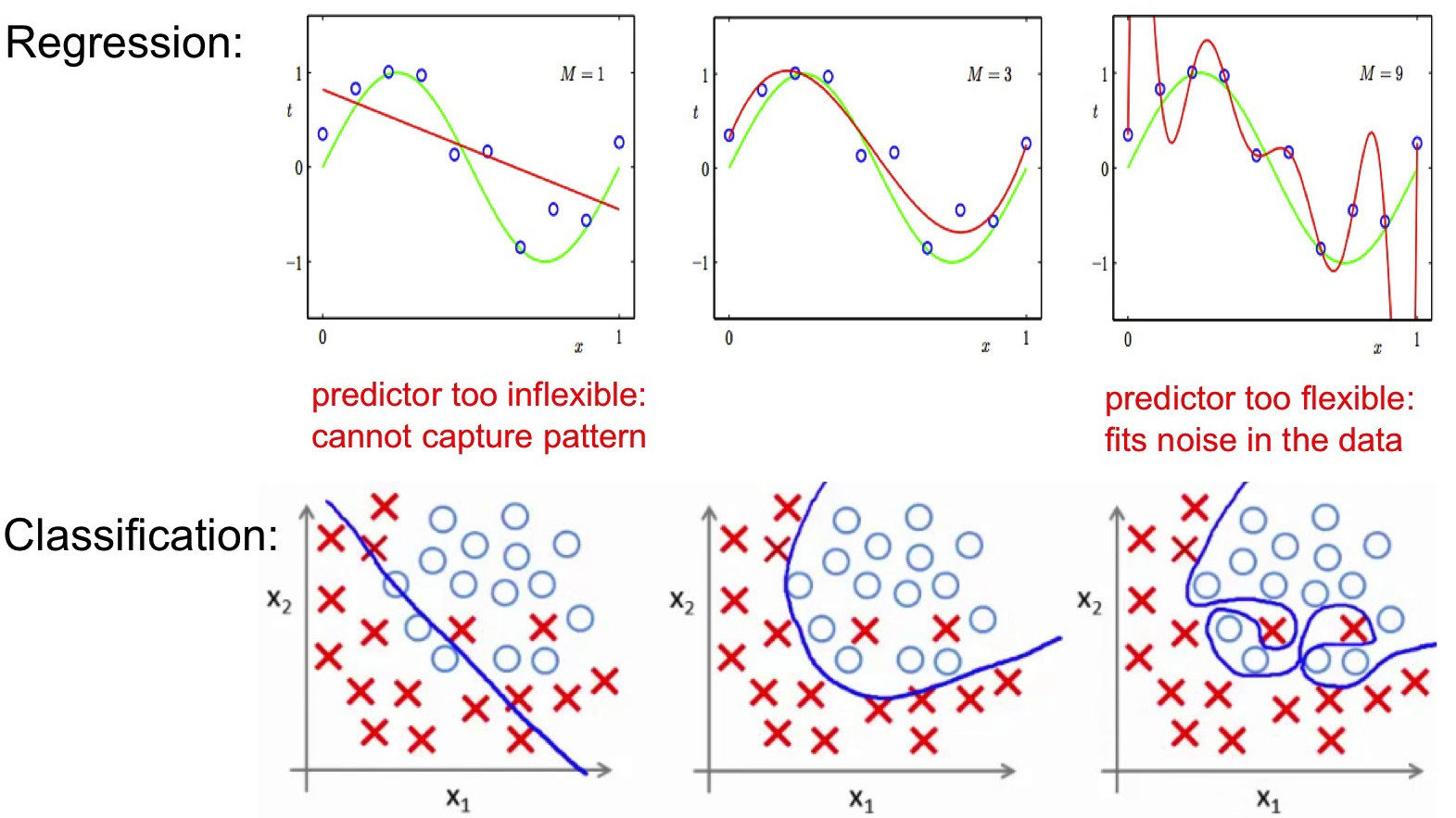
Classification
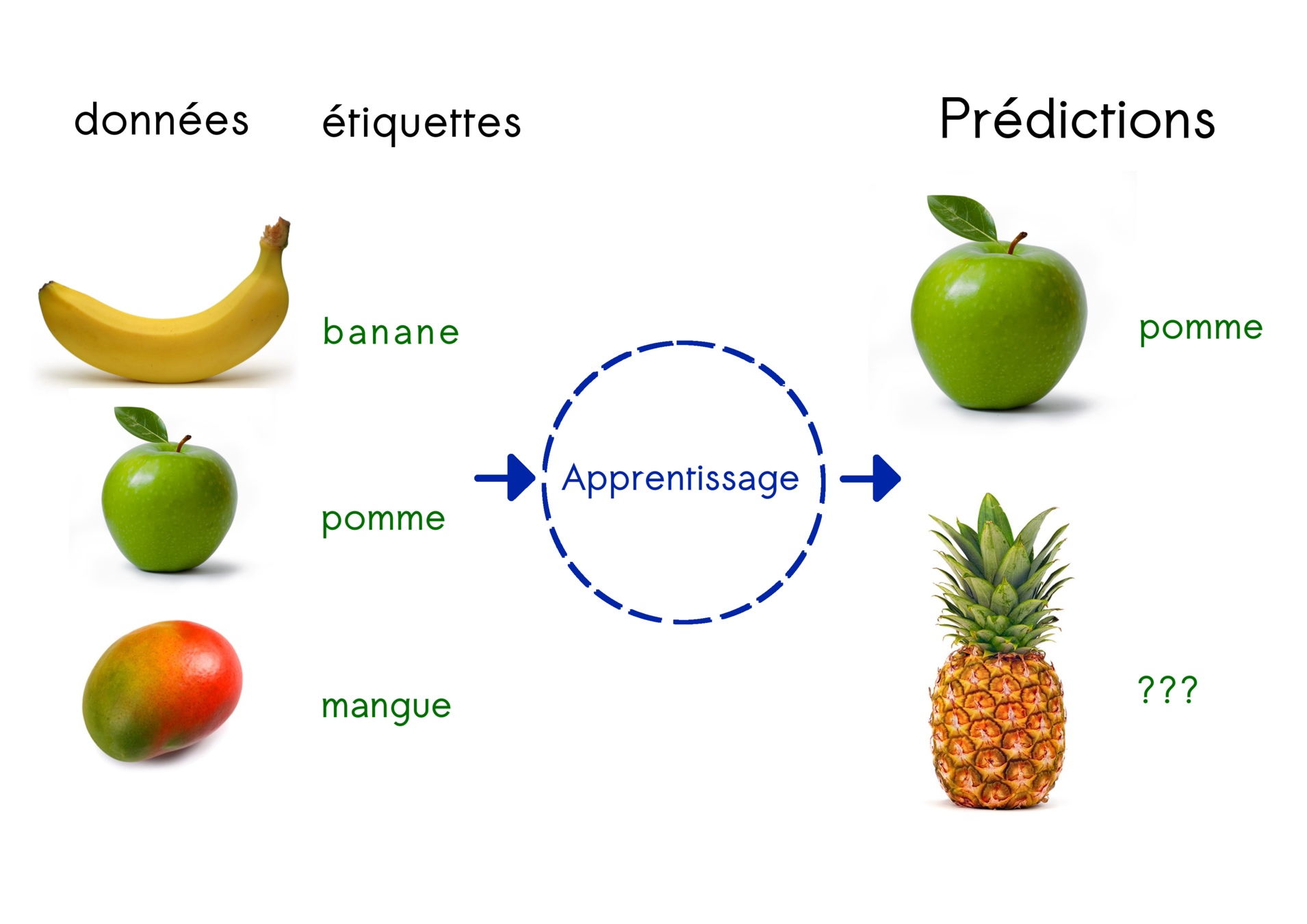
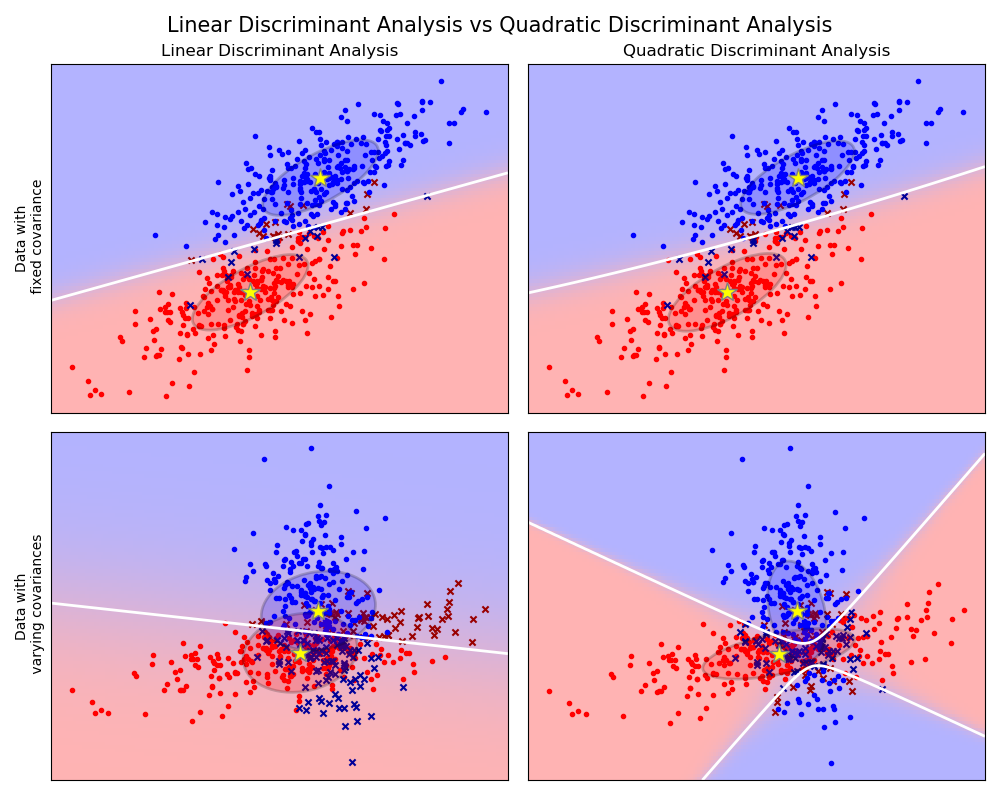
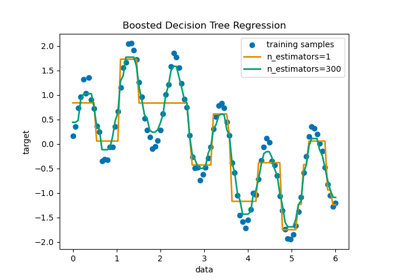
Régression
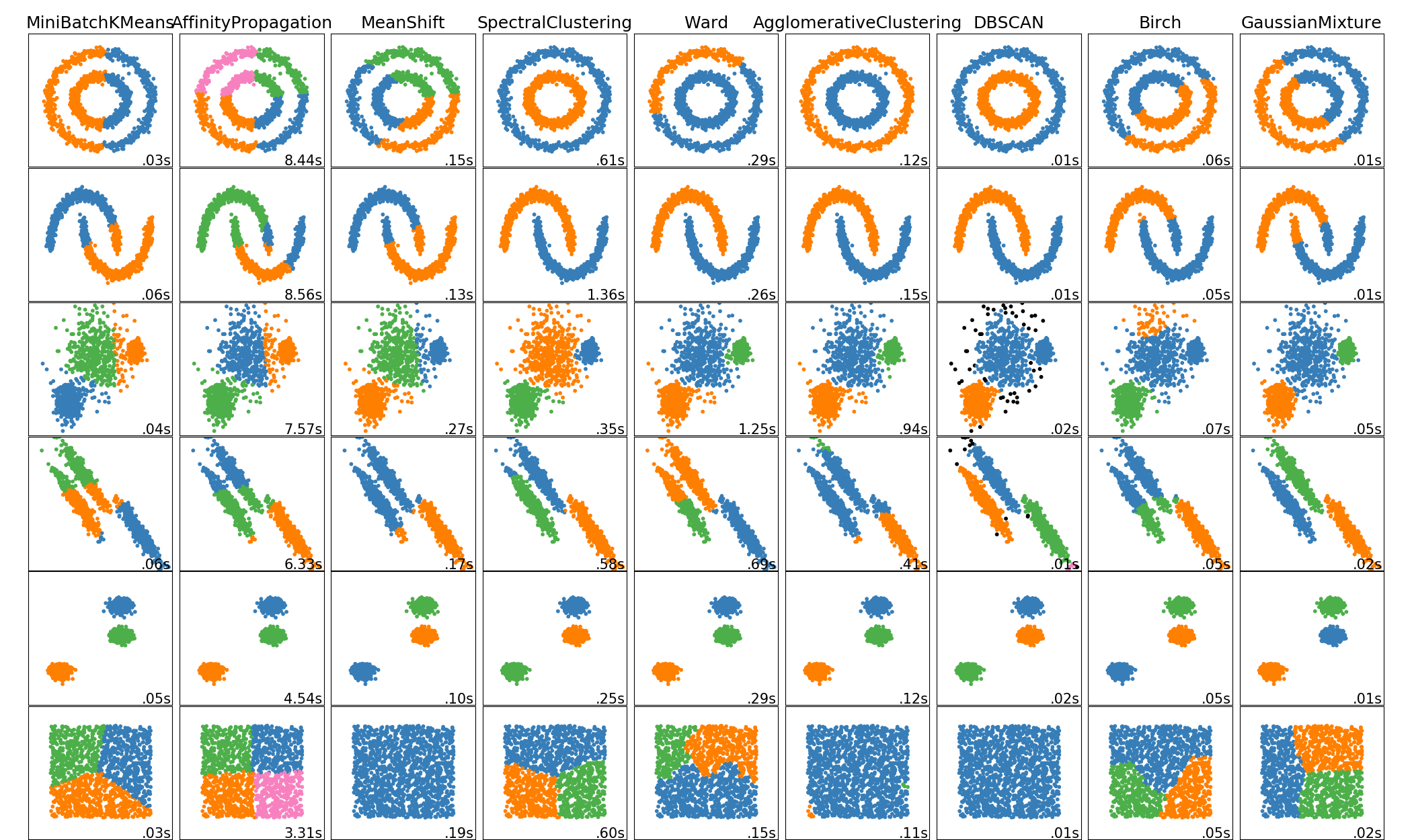
Clustering
Détection d'anomalies

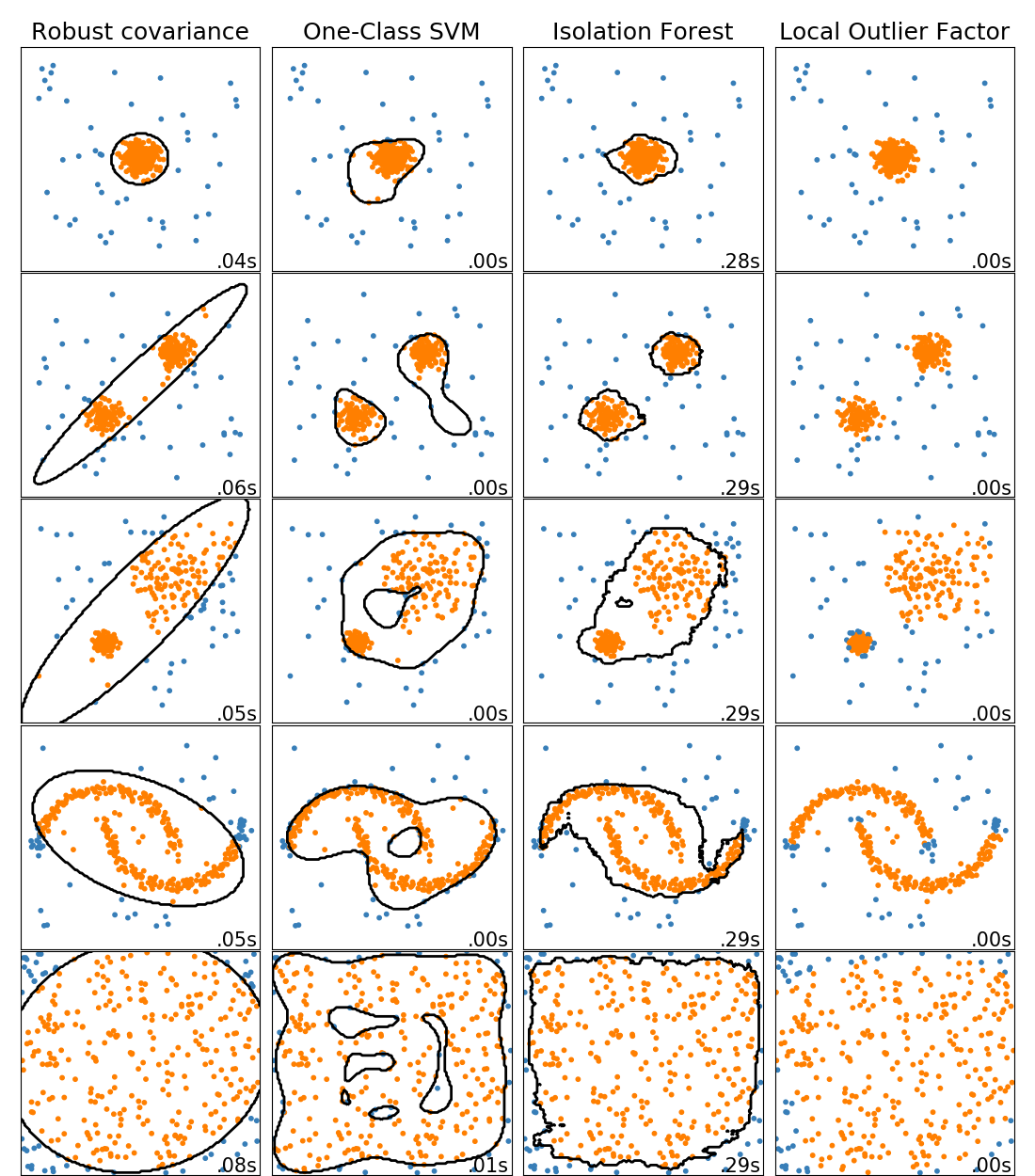
Recommandation
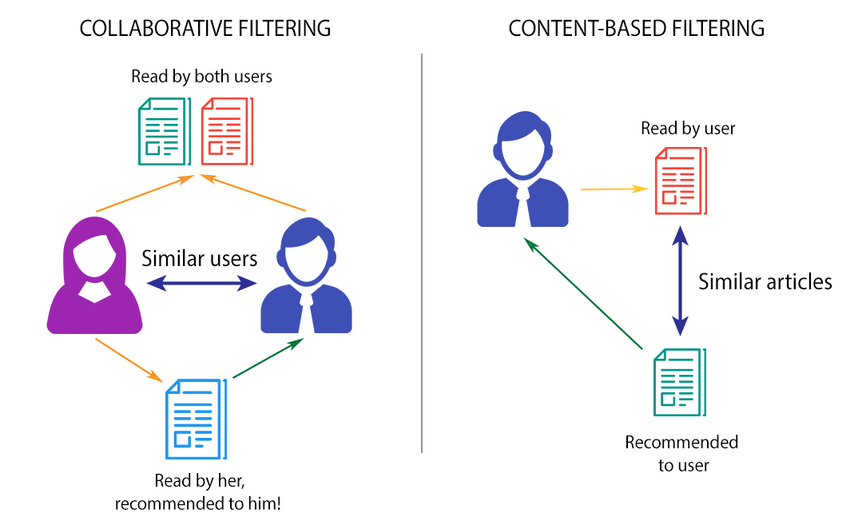
Quelques librairies
Pour les méthodes content based
N'importe quel algorithme de clustering : kNN, Kmeans
Quelques packages génériques
Orientés réseaux de neurones
Pour les méthodes de type collaborative filtring
Patterns
Trouver une structure caractéristique qui se manifeste dans un petit nombre d'observations
Exemples
profils
d'utilisateurs/clients/prospects
erreurs de mesures
...
comportements
caractéristiques
Outils
classification
règles d'associations
...
clustering
Estimation de densité
k-NN
k-Means
Résolution de problèmes
1- Décrire mathématiquement un problème précis
Exemples
Outils
2 - Résoudre ce problème par un algorithme
Trouver le plus court chemin
Jouer le meilleur coup
Algorithmes de parcours de graphe
Simuler les décisions d'un expert
Systèmes experts
...
Amélioration des modèles d'analyse
rechercher une meilleure perfomance et interprétabilité
Sélection de modèles
Définir quelles variables garder pour avoir un modèle parcimonieux
Ajustement du modèle
minimiser le nombre de variables

Réduction de dimension
Méthodes linéaires
Analyse en composante principale
Décomposition en valeur singulières
...
...
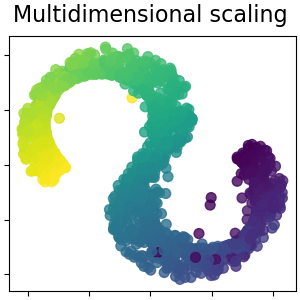
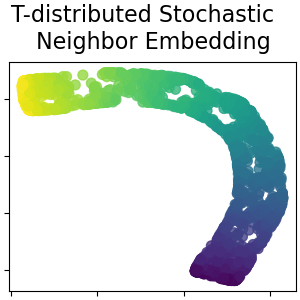
Isomap
MDS
t-SNE
Sélection de modèles
1 - On définit un critère statistique de qualité de performance
2 - On utilise des algorithmes cherchant à optimiser ce critère
Critère d'Akaike (AIC)
Bayesian Information Criterion (BIC)
Statistique de Mallows
Backward
Forward
Stepwise
Features Permutation
Feature engineering
Double intention
feature engineering is another topic which doesn’t seem to merit any review papers or books, or even chapters in books, but it is absolutely vital to ML success. […] Much of the success of machine learning is actually success in engineering features that a learner can understand.
Processus consistant à utiliser la connaissance du domaine pour extraire des features en transformant une partie des données brutes par des méthodes de data mining
Améliorer les performances de vos algorithmes
Rendre le data set plus facilement interprétable (machine et humain)
Scott Locklin, in “Neglected machine learning ideas”
Méthodes ensemblistes
Combiner différents modèles pour obtenir un modèle plus performant
méthodes parallèles
(bagging)
méthodes séquentielles
(boosting)
Stacking / Blending
Méthodes ensemblistes
Inconvénient:
Elles ont tendance à rendre le modèle final difficilement interprétable
Interpétabilité
Evaluer le poids relatif de chaque variable sur les performances
Méthodes agnostiques du modèle
Méthodes spécifiques
classer les coefficients d'une régression
Méthode LIME
Méthode SHAPLEY
Interpétabilité
Exemples
Analyse exploratoire
Tache de classification
Tache de régression
Clustering
Cas d'usage spécifique
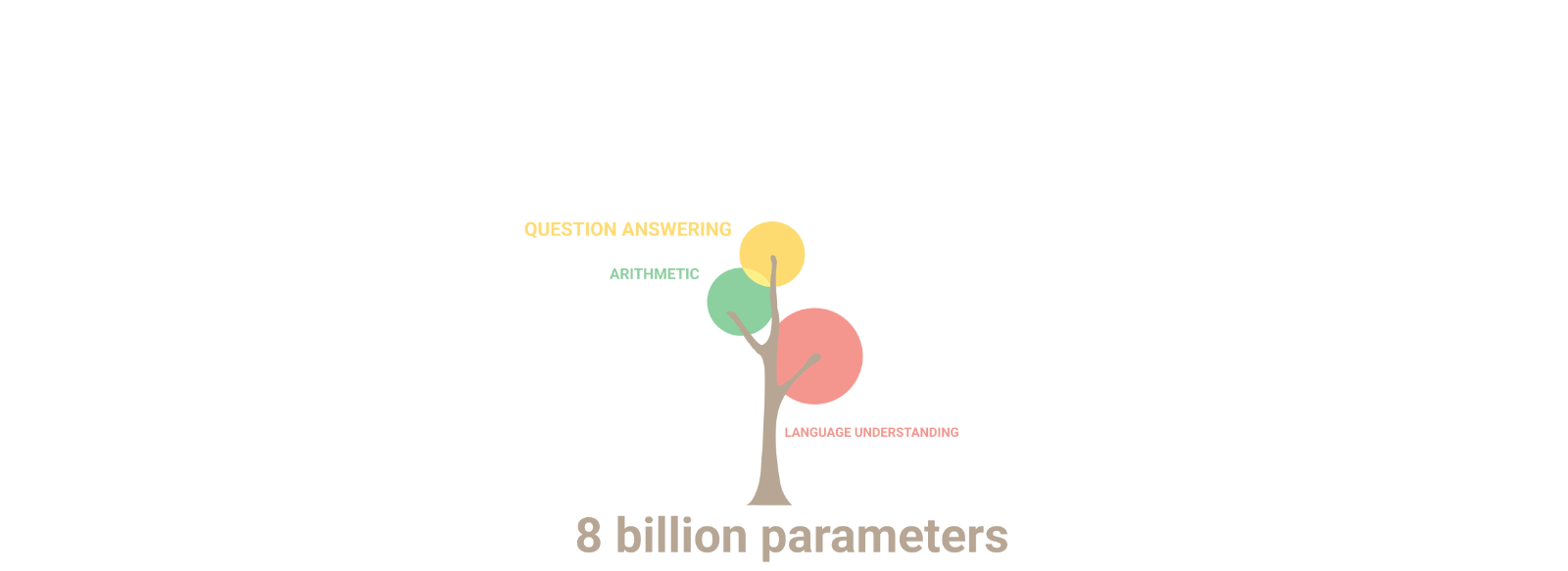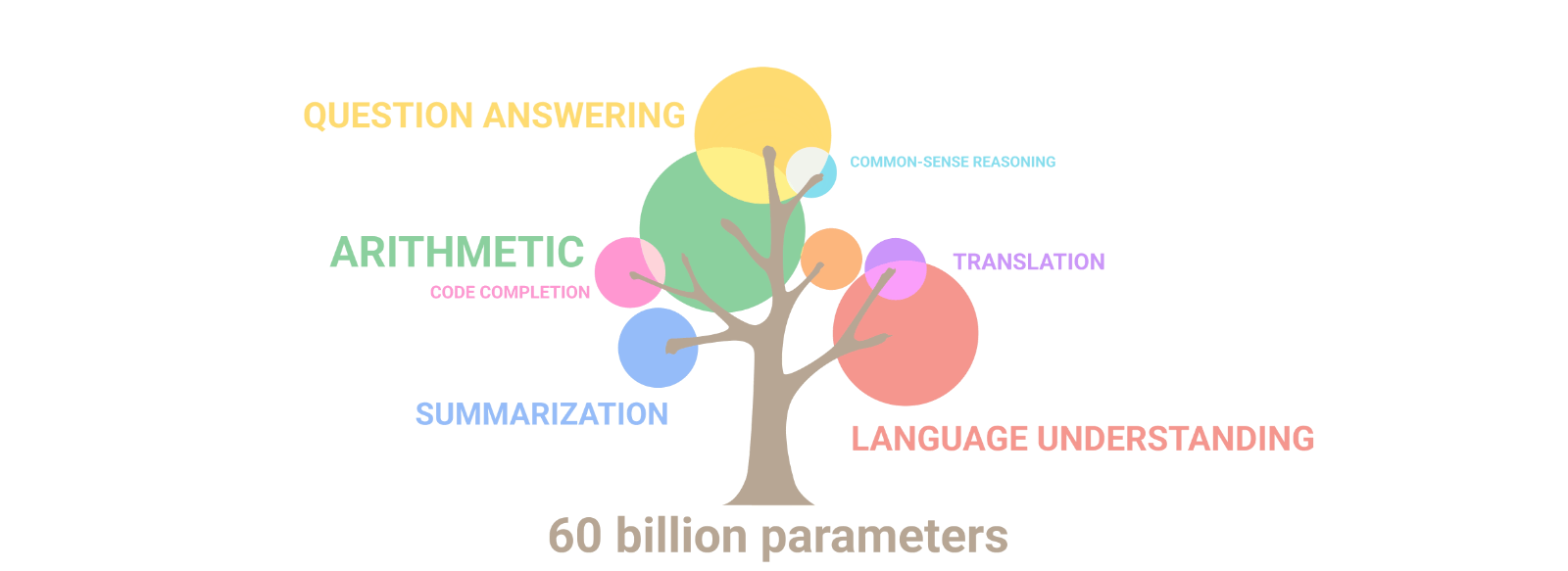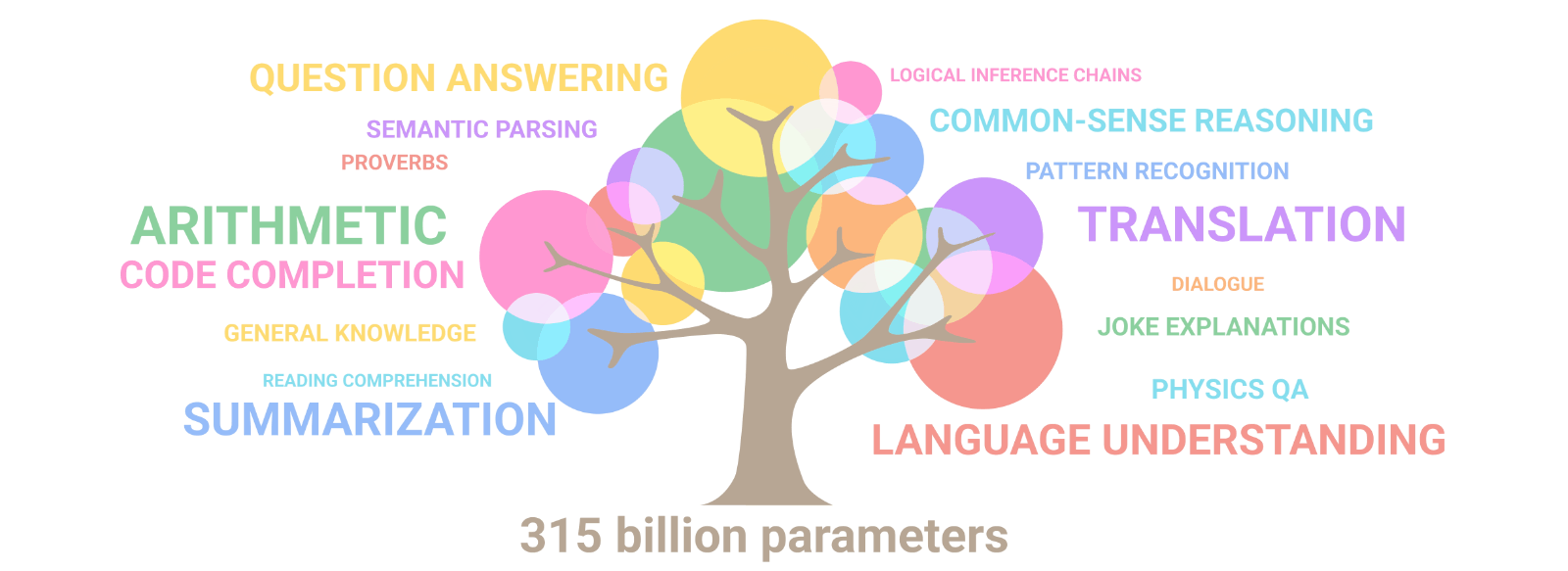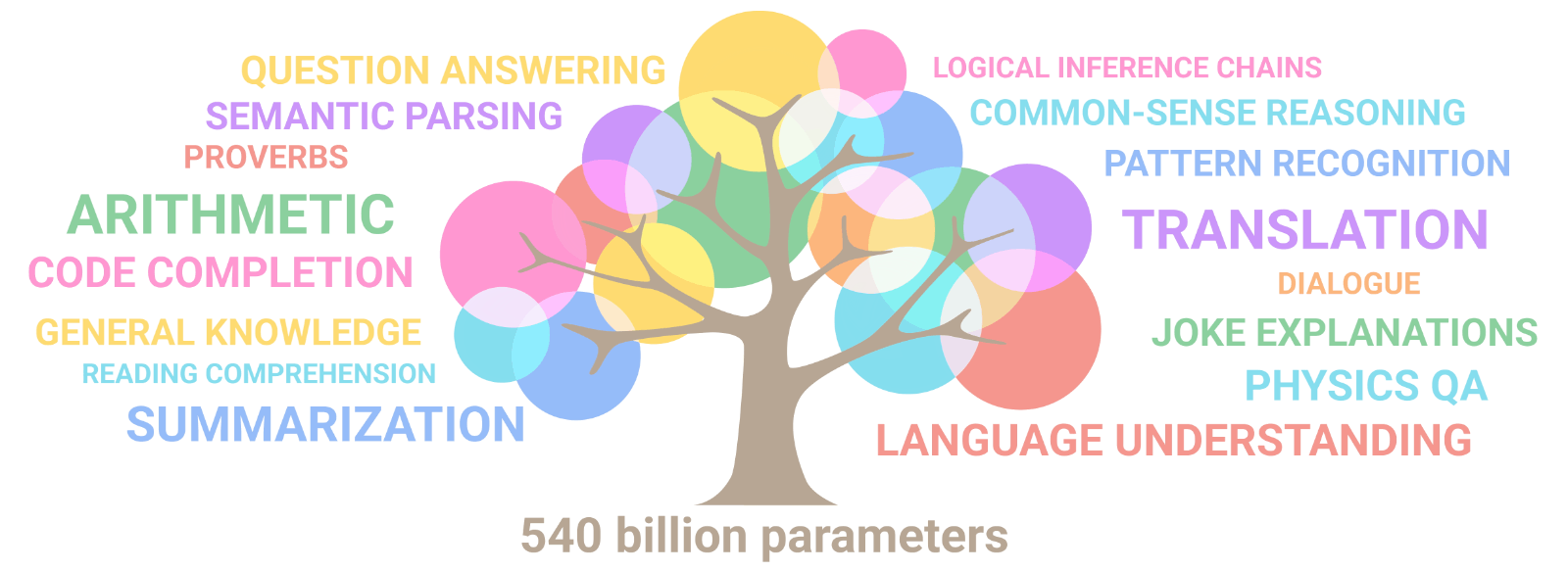
Les capacités multi-taches des Large Langage Models