Très brève Introduction
au
Deep Learning
Nicolas Rochet 2026
Activité participative
Quels mots vous évoquent Deep Learning ?
IA: Une définition simplifiée
Ensemble de théories et techniques qui confèrent à des machines la capacité d'accomplir des tâches attribuées aux être intelligents
Une brève histoire de l'IA
50
>2011
93-2011
87-93
80-87
74-80
56-74
Naissance
de l'IA
1er hiver
L'age d'or
2e age d'or
2e hiver
maturité
discrète
Essor du
Deep Learning
>2019
Explosion
IA gen
Disciplines de l'IA
IA GENERALE
Systèmes Experts
RAISONNEMENT
REPRESENTATION DES CONNAISSANCES
Planification
NEURO SYMBOLIQUE
Apprentissage profond
APPRENTISSAGE AUTOMATIQUE
INTELLIGENCE SOCIALE
Modèles Génératifs
LLMs
VLMs
SYSTEMES MULTI AGENTS
Prise de décision
Apprentissage par renforcement

ROBOTIQUE
VISION PAR ORDINATEUR
TRAITEMENT DU LANGAGE
RESOLUTION DE PROBLEMES
Quelques domaines d'applications
Traitement de
l'image et du son
Traitement
du
langage naturel
Systèmes de
recommandation
Systèmes
prédictifs
Aide à la
décision
Robotique
Optimisation
& planification
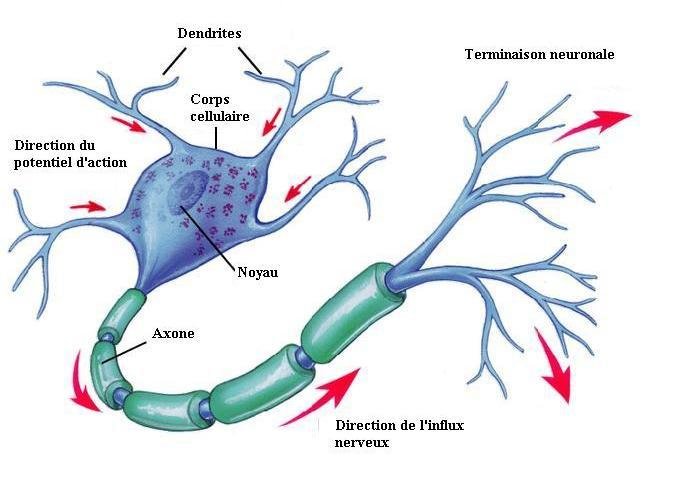
Le point de départ : le neurone
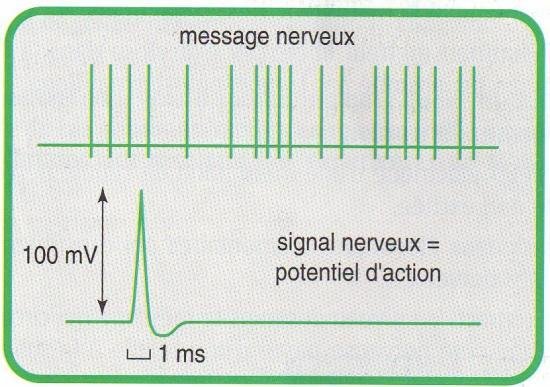
Une réponse en tout-ou-rien
réponse 0 ou 1
Neurone biologique
Neurone
artificiel
axone
sortie
potentiel d'action
fonction d'activation
fonction de transfert
corps cellulaire
poids
synapses
dendrites
entrées
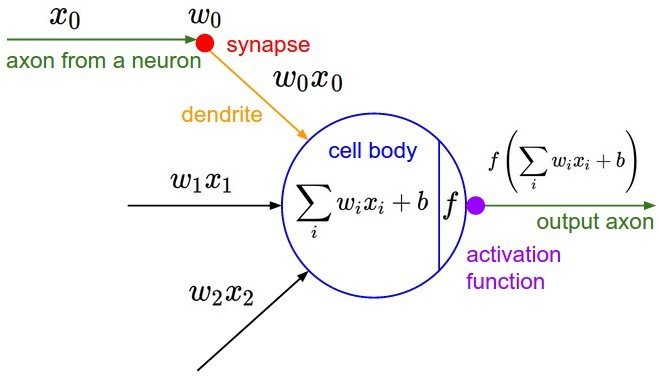
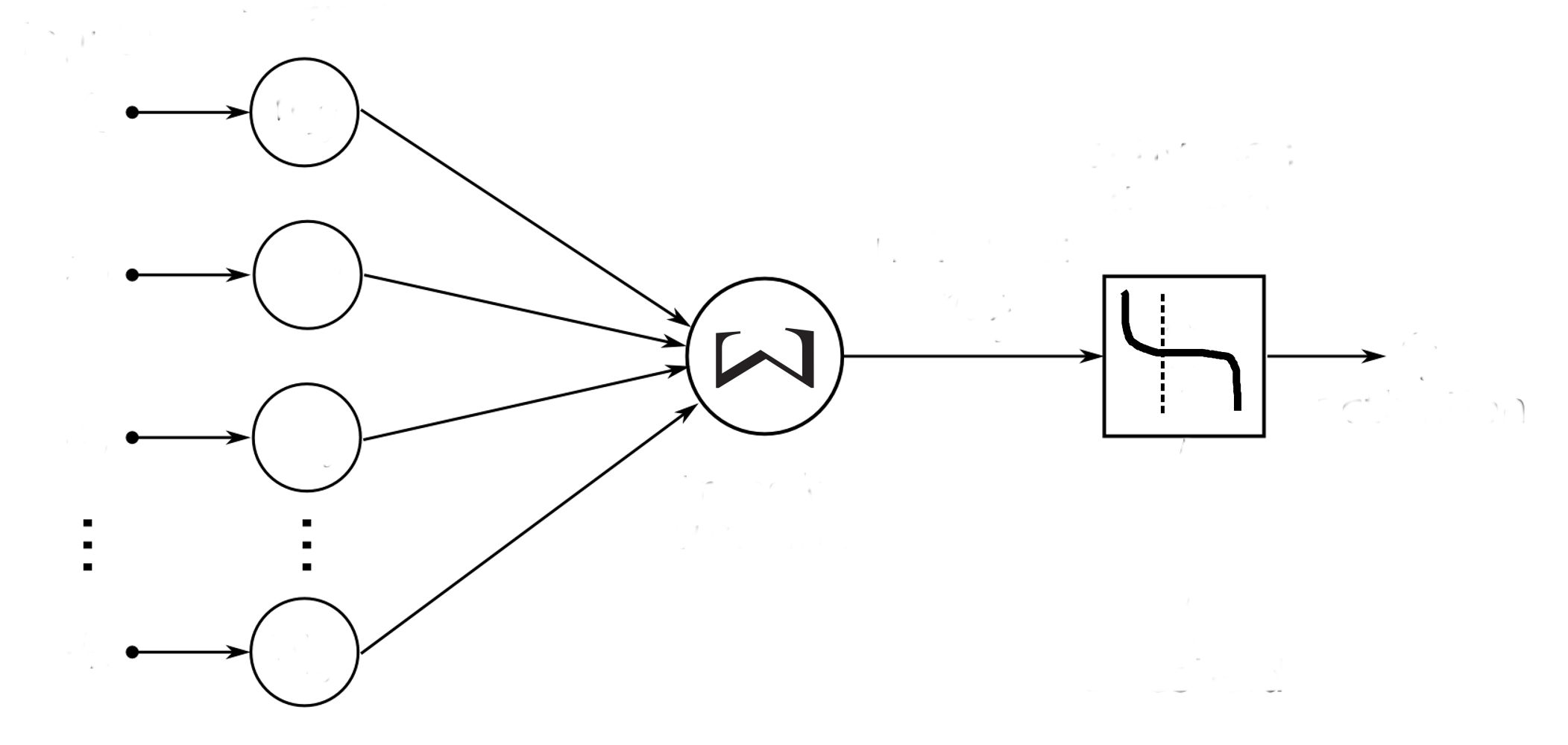
Le neurone formel
Mc Culloh & Pitts 1943
Le perceptron multi-couche
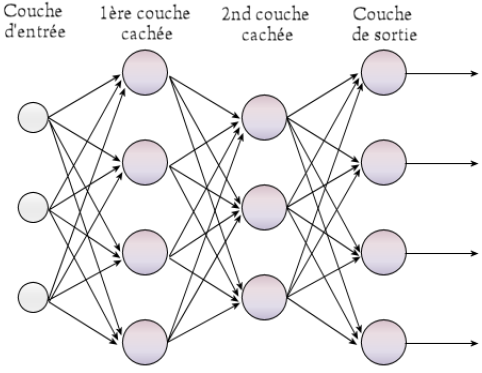
Rosenblatt 1957
Comment ça fonctionne ?
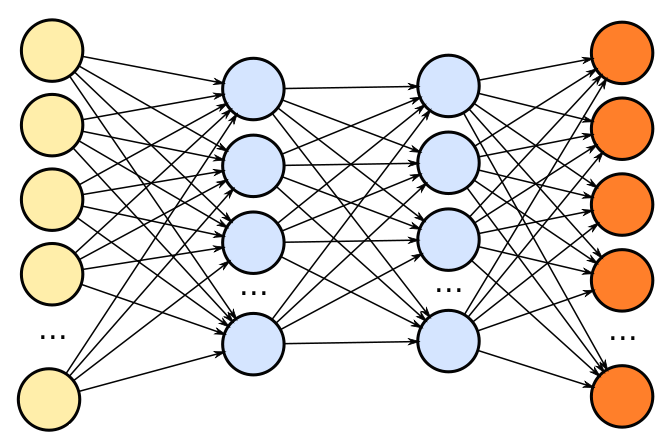
Entrées
Sorties
resultats
attendus
Erreur
retro-propagation
fonction de perte
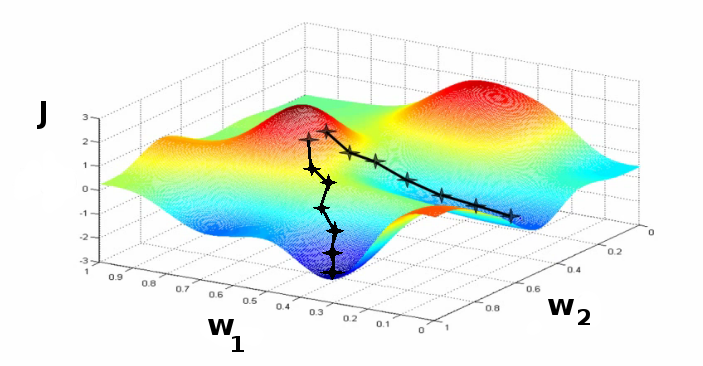
La descente de gradient
1. Fixer les poids w initiaux du réseau
2. Répéter jusqu'à ce qu'un minimum de la fonction de coût J soit obtenu :
a. Mélanger aléatoirement les observations
b. Pour chaque observation faire :
w = w - a . gradient(J)
Une jungle de réseaux de neurones
Auto encodeur
Réseau récurrent (RNN)
Réseau convolutif (CNN)
Réseau adversarial (GAN)
Paramètres & hyper-paramètres des réseaux
Nombre de neurones par couche
Nombre de couches cachées
fonction d'activation
poids
biais
Paramètres
Hyper paramètres

initialisation
des poids
fonction de coût (loss)
... d'autres hyper-paramètres
Nombre de neurones par couche
Nombre de couches cachées
vitesse d'apprentissage
nombre d'iterations
taille des batch
dropout
...
...
...
batchs de données
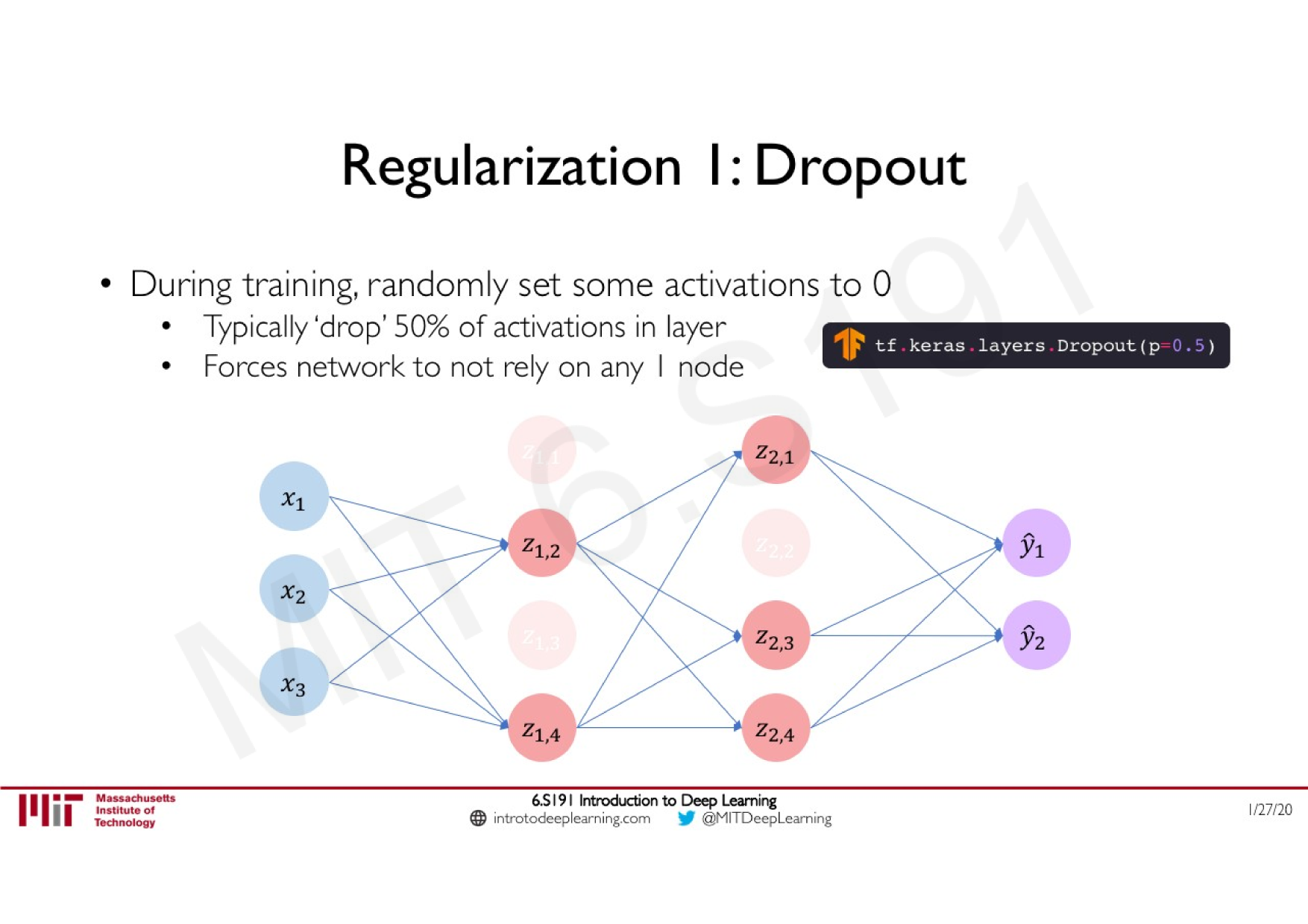
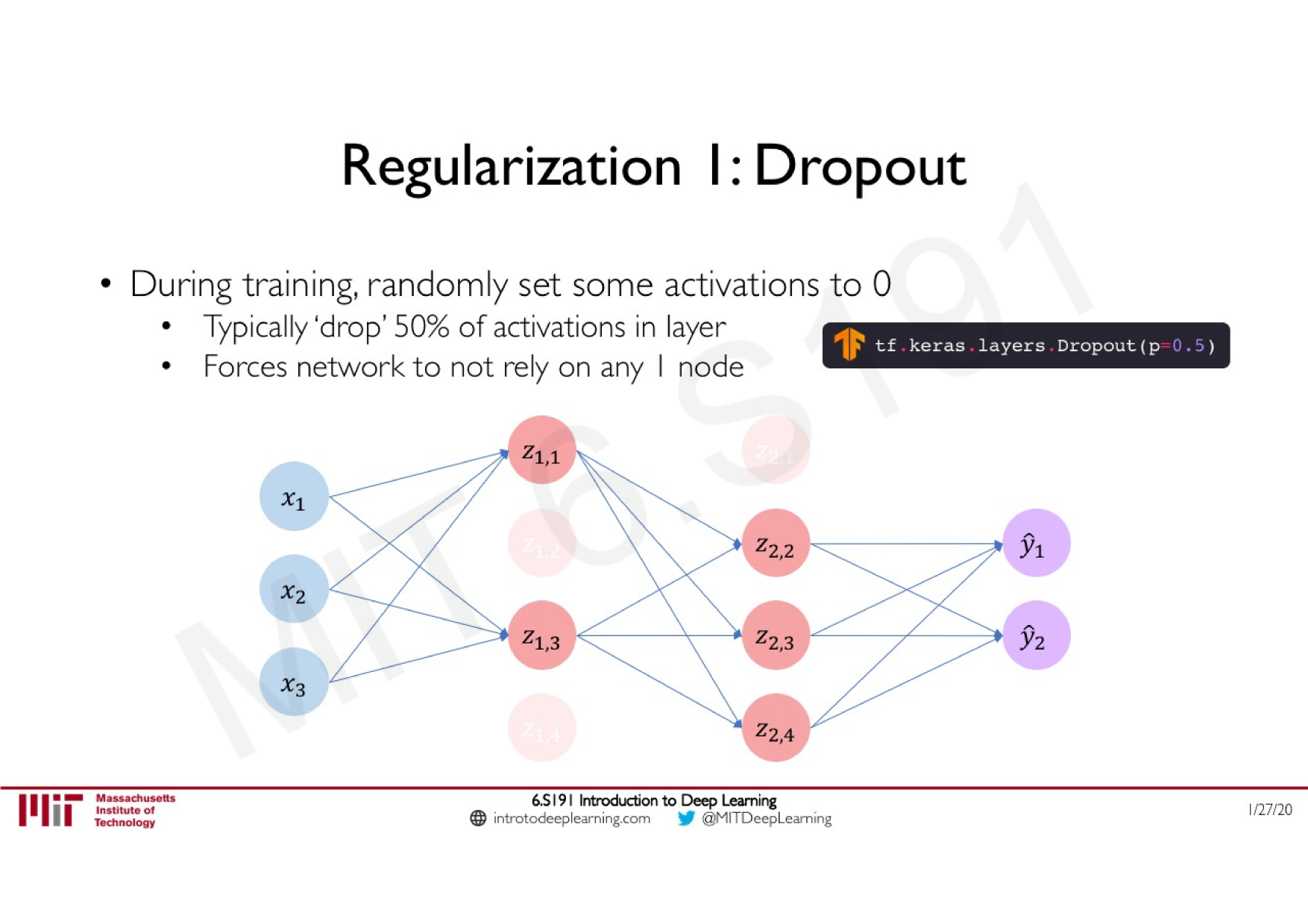
La régularisation par dropout
Idée: "éteindre" aléatoirement pendant l'apprentissage une proportion de neurones
dropout
retro-propagation
Spécificités du Deep Learning
Propriété des réseaux de neurones
Différents types de 'cellules'
Deep Reinforcement Learning
Convolutif
Différents types d'architectures
récurrent
à mémoire
Combiner à d'autres méthodes
Convolution
CNN
RNN
Autoencodeur
GAN
LSTM
ResNet
Deep Recomander systems
...
Transformers
Mécanismes d'attention
Approche End-to-End
sélection
de features
extraction automatique
de features
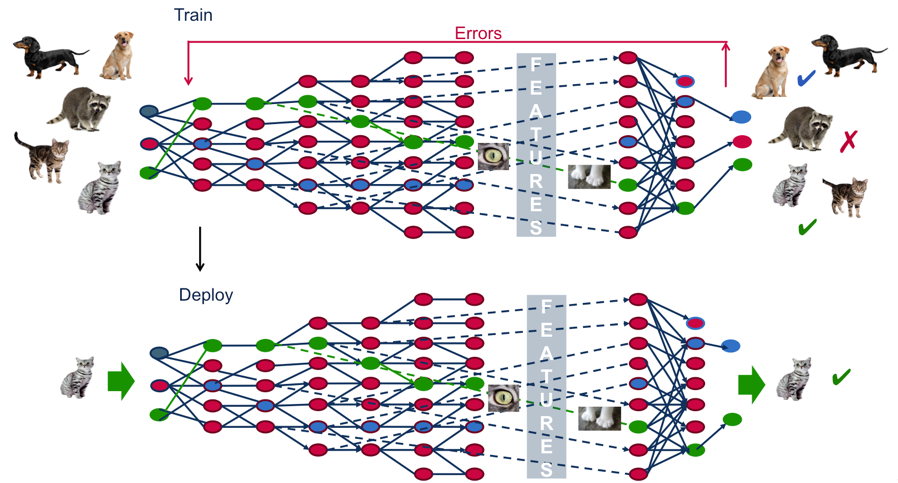


Apprentissage par transfert & fine tuning facilité
sélection
de features
Universalité des réseaux denses
Attention : Cela ne garantit pas de trouver les paramètres optimaux pour obtenir la précision voulue de cette approximation
Des modèles peu interprétables
Du fait de leur architecture qui tend à être de plus en plus profonde (un très grand nombre de paramètres), ce sont des modèles difficilement interprétables
Ressources & outils
Code & logiciel
Scikit-learn
TensorFlow
Torch / PyTorch
H2O.ai
CNTK
Microsoft Azure ML
Amazon Machine Learning
...
Google Cloud AI
Python
JavaScript
Lua
Matériel
GPU
TPU
Cloud
CPU
...
Ecosystème Hadoop
Stockage distribué
calcul distribué
Modèle de calcul
BIG DATA
CALCUL
Microsoft Azure ML
Amazon Machine Learning
Google Cloud AI
OVH
Cuda