Fondamentaux du Machine Learning
Nicolas Rochet
2025
Fondamentaux du Machine Learning
Résumé
Définition
Machine learning is a field of artificial intelligence that uses statistical techniques to give computer systems the ability to "learn" (e.g., progressively improve performance on a specific task) from data, without being explicitly programmed
From Arthur Samuels (source : Wikipedia)
Définition
"A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E"
From Tom M,Mitchel
Catégories d'apprentissage
Apprentissage supervisé
Apprentissage semi-supervisé
Apprentissage non supervisé
Apprentissage par renforcement
Apprentissage par transfert
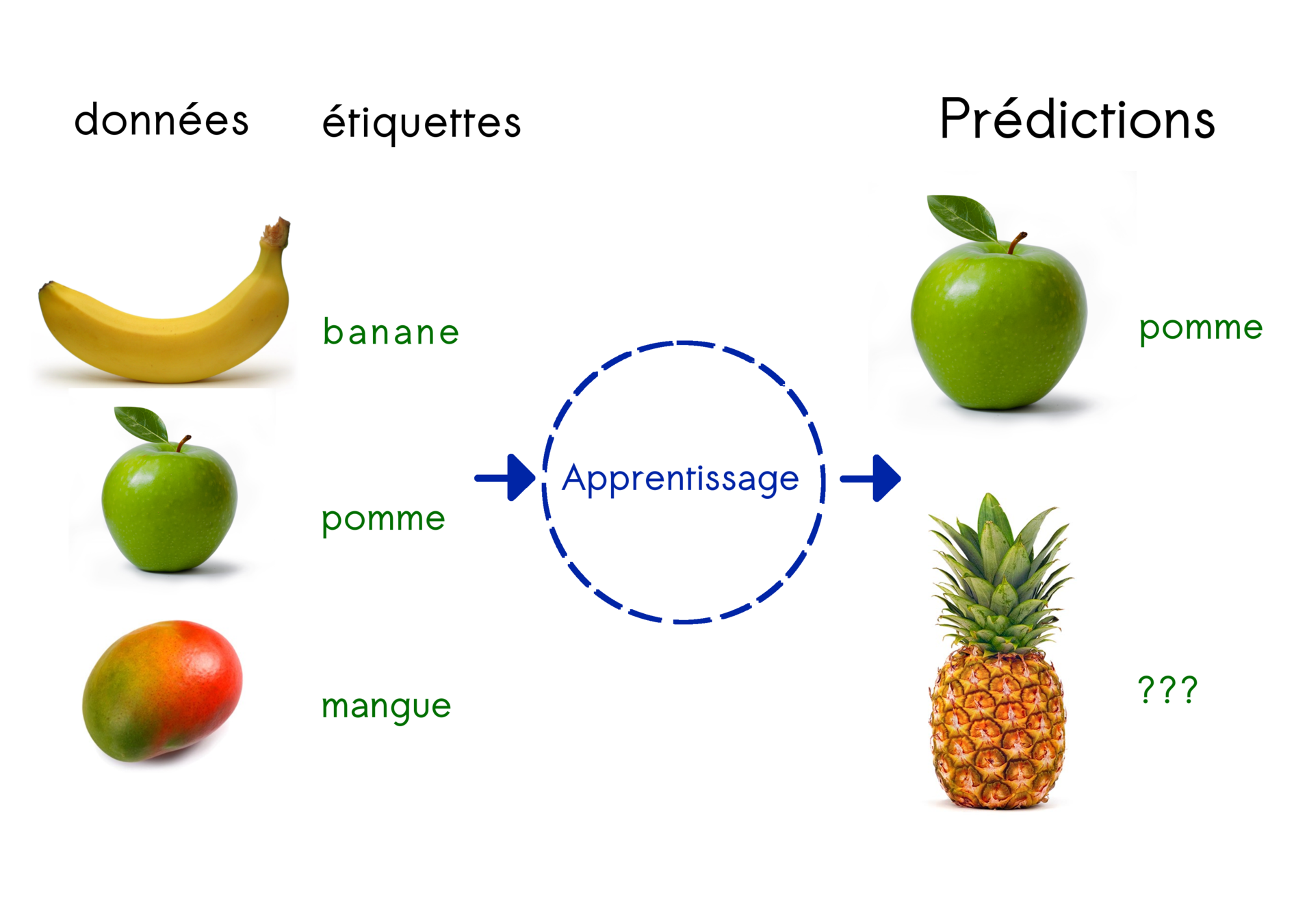
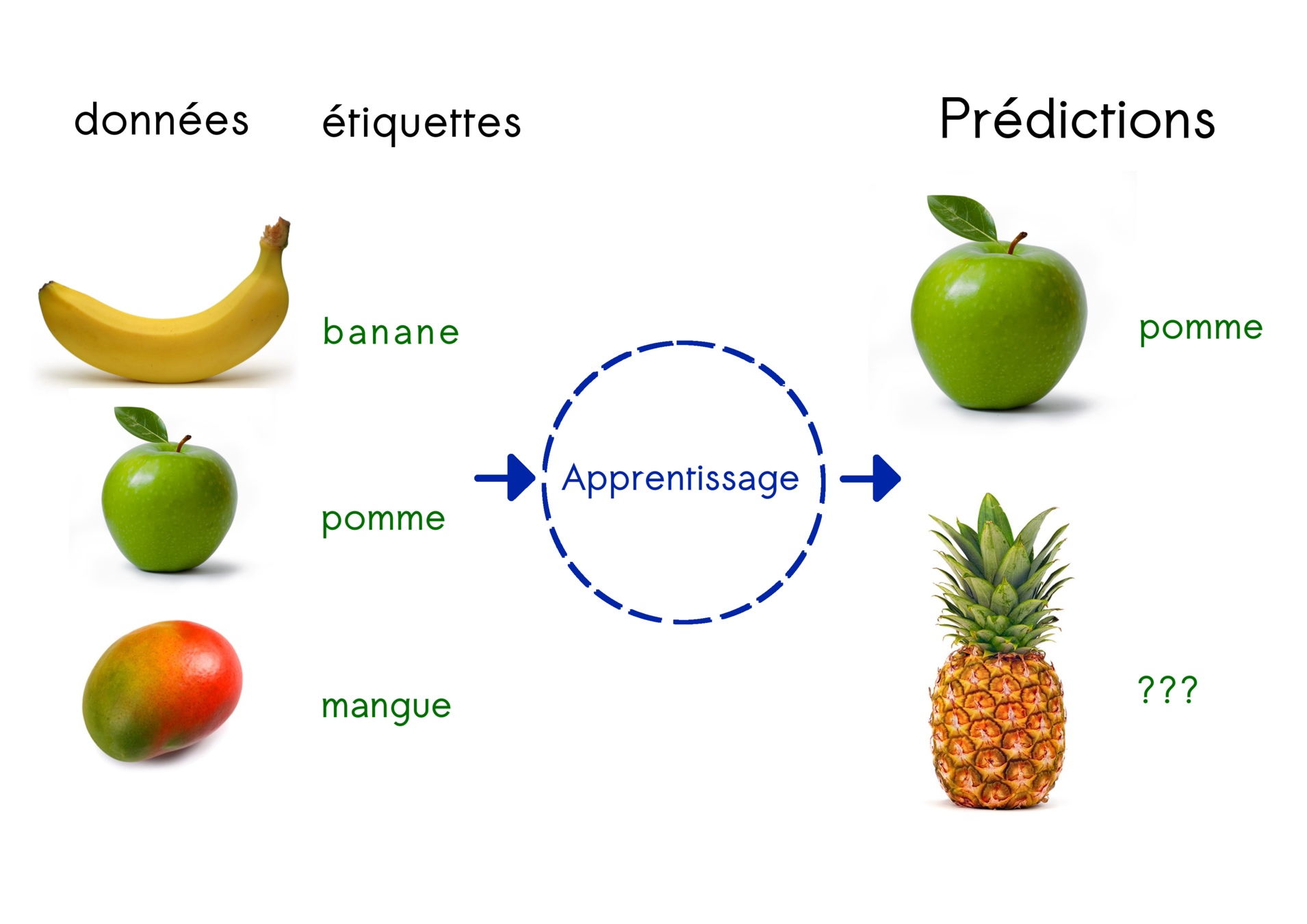
Apprentissage supervisé
Principe :
trouver la règle générale qui relie données et labels
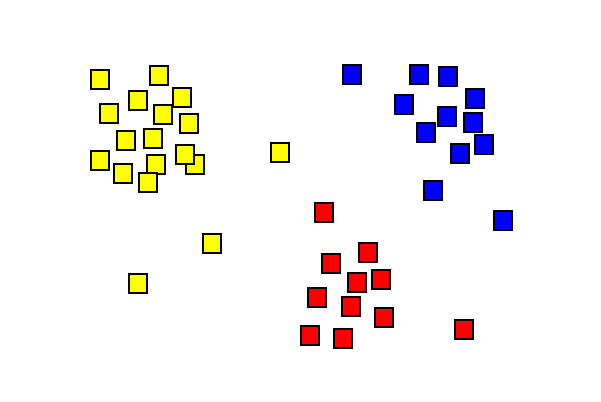
Apprentissage non supervisé
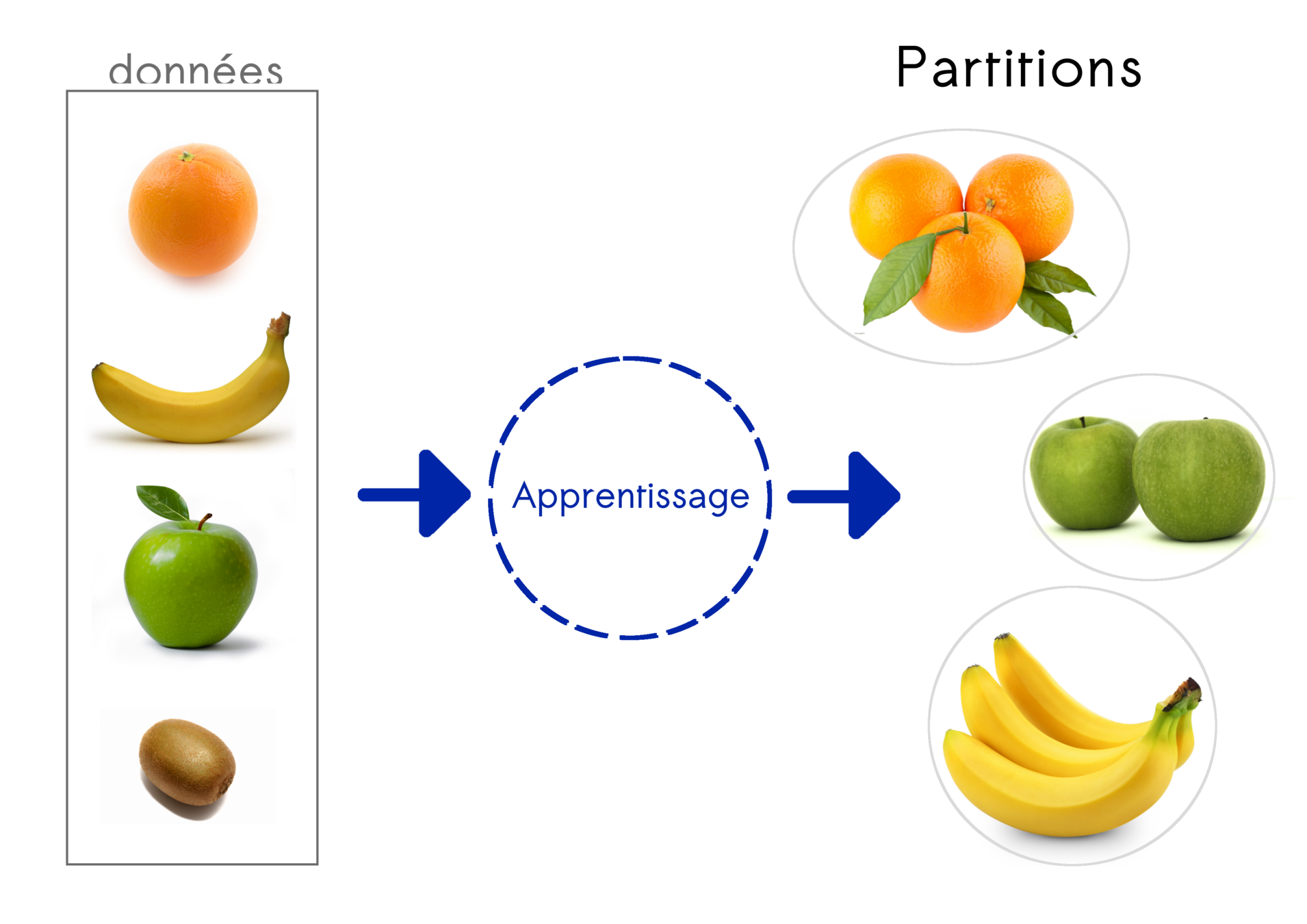
Identifier des groupes (clustering)
Estimer la distribution de données
Estimer la covariance dans les données
Identifier des données abbérantes
Réduire le nombre de variables
...
Apprentissage non supervisé
Identifier des groupes (clsutering)
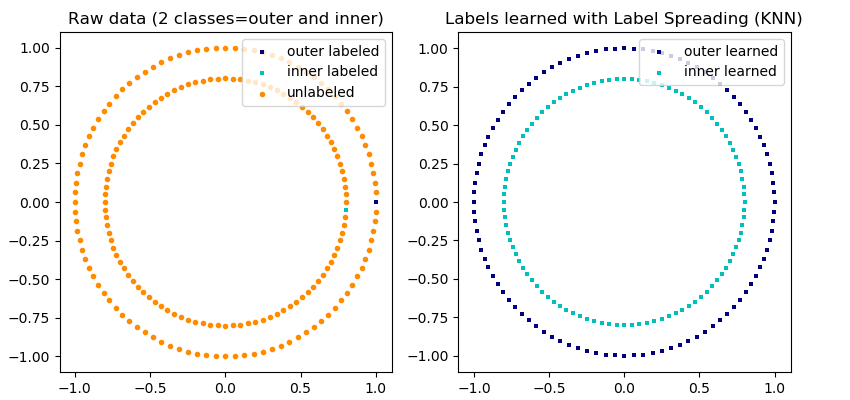
Apprentissage semi-supervisé
Principe : trouver une structure dans les données mais avec une grande quantité de données non labellisées
Active learning
Principe :
Procédure dans lequelle l'algorithme peut interroger le superviseur pour obtenir de nouvelles données

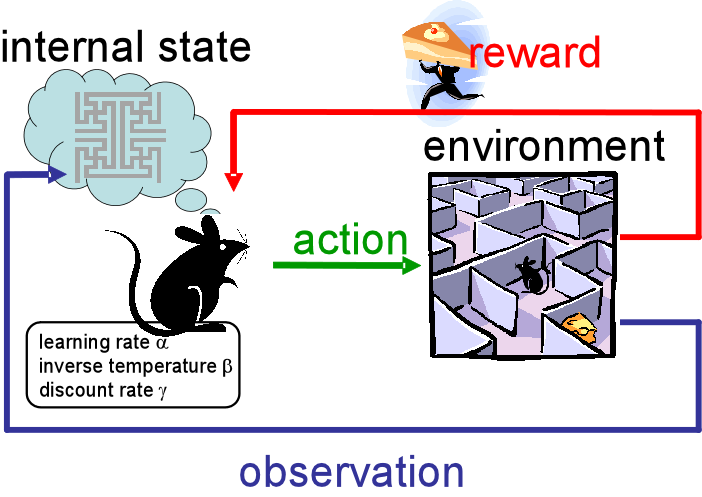
Apprentissage par renforcement
Principe :
Un agent apprend les actions à realiser sur son environnement en maximisant une récompense
Apprentissage par transfert
Principe :
Appliquer des connaissances apprise sur une tâche antérieure, sur de nouvelles tâches
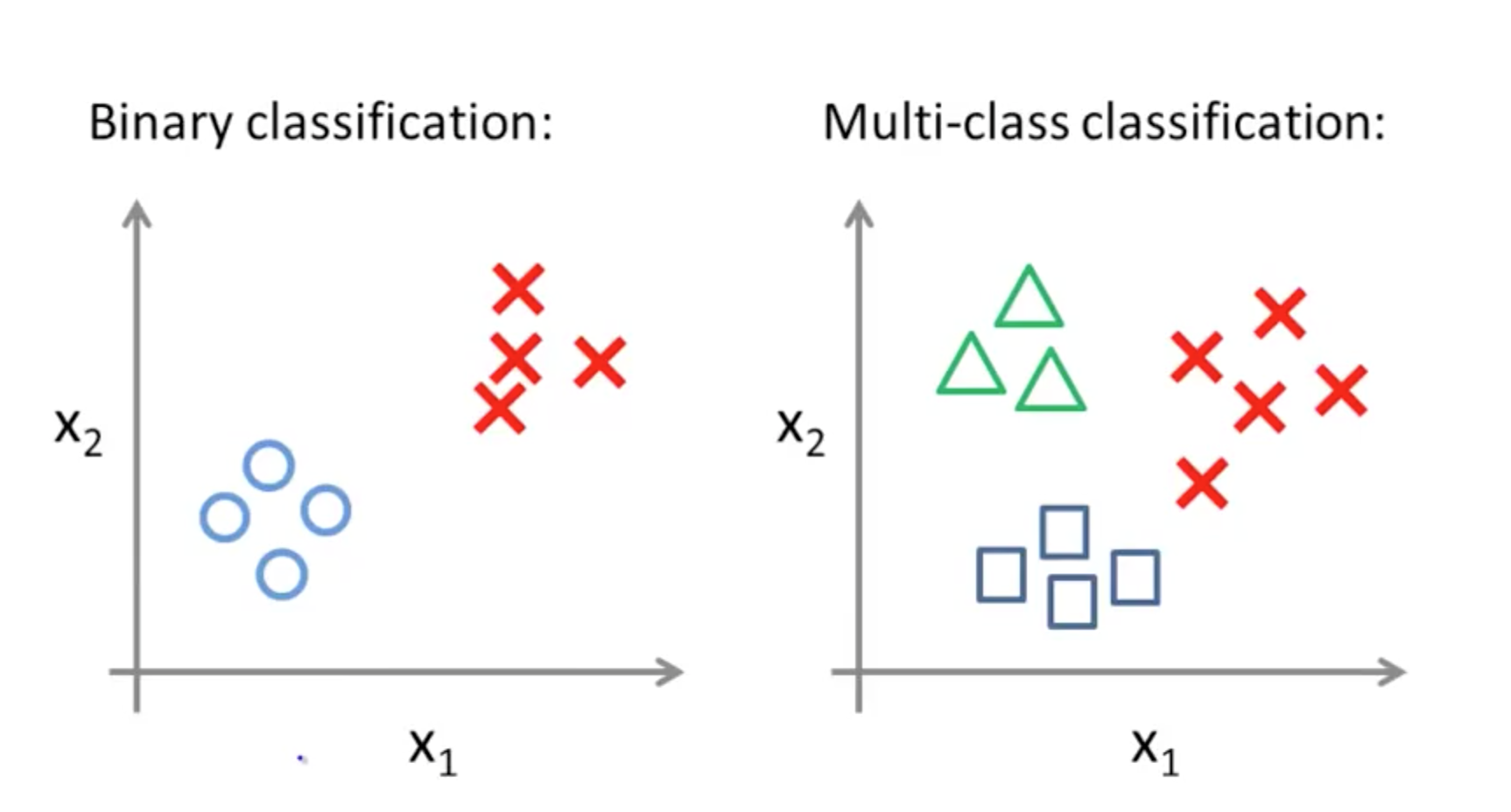
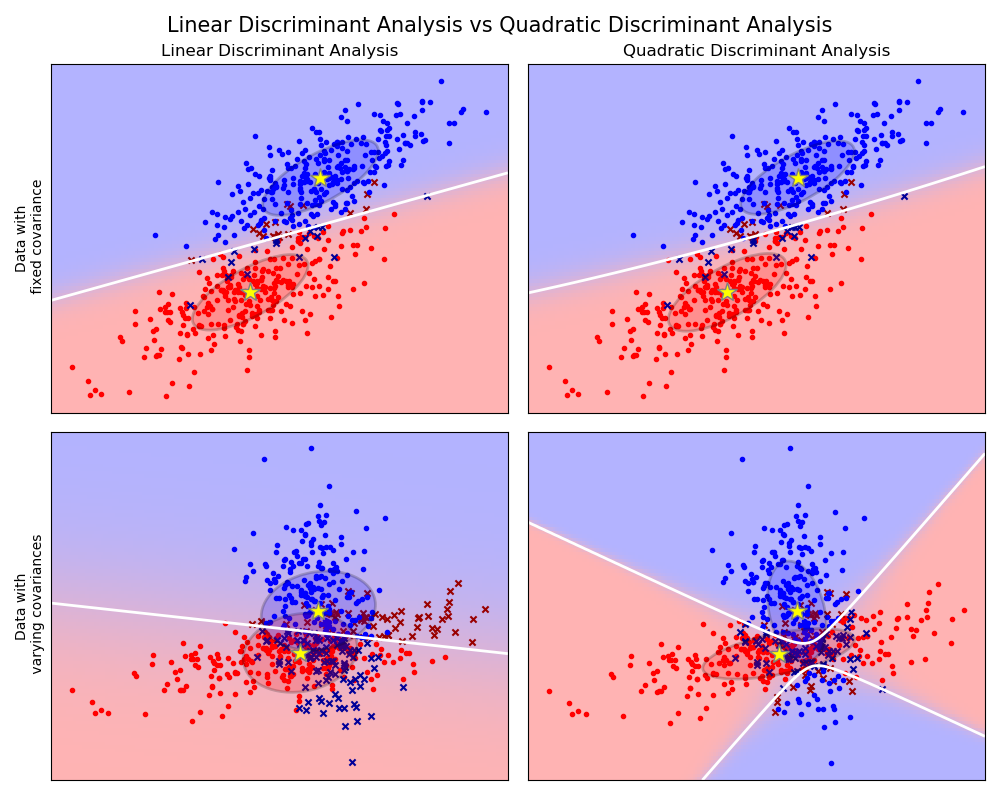
Les principales tâches du machine learning
Classification
Régression
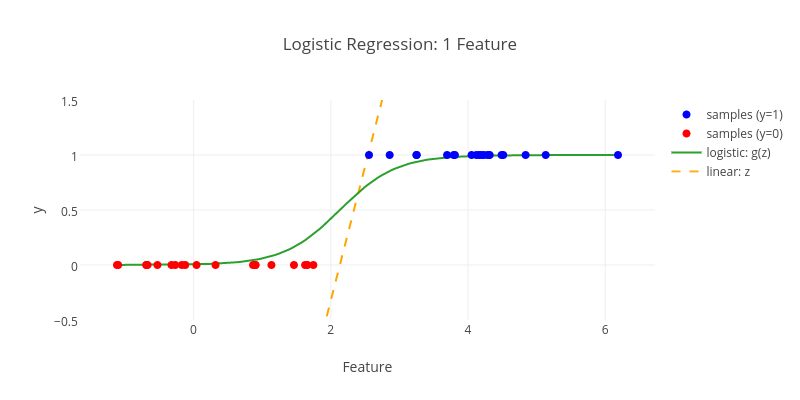
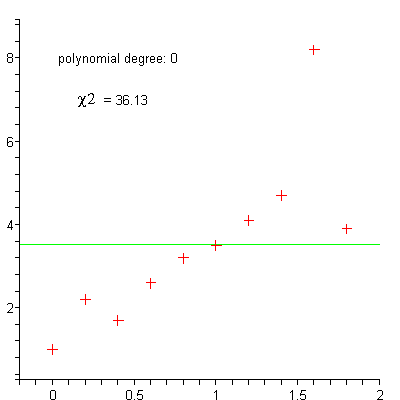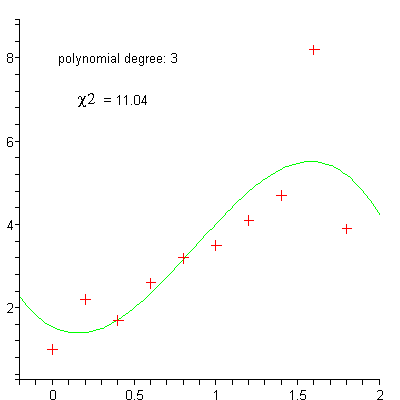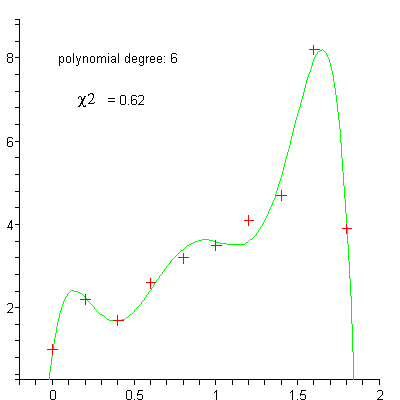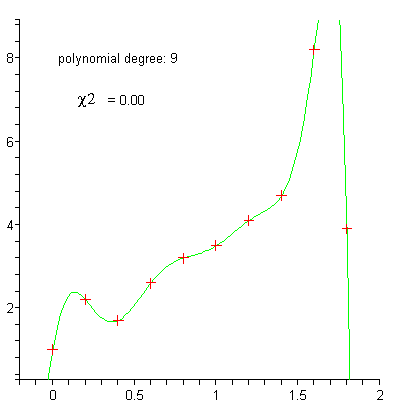
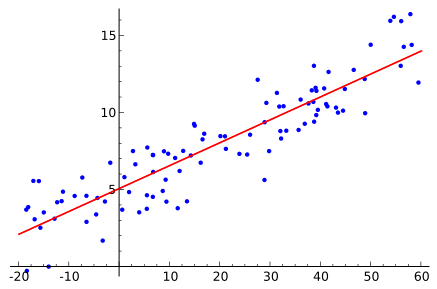
linéaire
logistique
polynomiale
Clustering

Principes fondamentaux
Data science:
Préparation des données
Gestion des données manquantes
Gestion des données abbérantes
Normalisation
Formatage des donnée (matrices)
Réduction de dimensionalité
...
Optimisation des
(hyper) paramètres
Quasiment tous les algorithmes en machine learning ont des paramètres internes à régler pour donner de bons résultats !
"tuning"
Objectif: minimiser une fonction de coût / d'erreur
paramètres vs hyper paramètres
Paramètres
Hyper paramètres
Valeurs apprises pendant l'apprentissage
Fixée à priori
par le data scientist
Ex: les coefficients d'une régression
Ex: le nombre de groupes K
pour un K-means
Quasiment tous les algorithmes en machine learning ont des paramètres internes à régler pour donner de bons résultats !
Objectif: minimiser une fonction de coût / d'erreur
Certaines méthodes d'optimisations sont assez spécifiques:
...
méthodes des moindres carrés
régressions
descente du grandient
réseaux de neurones
méthodes de boosting
Quasiment tous les algorithmes en machine learning ont des paramètres internes à régler pour donner de bons résultats !
Objectif: minimiser une fonction de coût / d'erreur
Sans hypothèses à priori, utilisez des méthodes généralistes :
Grid Search
Random Search
Bayesian Search
Evolutionnary Search
Gradient-based Optimisation
...
Métrique d'évaluation
accuracy
score F1
précision/rappel
aire sous la courbe ROC
erreur quadratique moyenne
pourcentage de variance expliquée
information mutuelle
...
limitations de l'apprentissage automatique
Compromis biais / variance
bias / variance trade off
Le problème consiste à "régler" l'algorithme pour qu'il apprenne avec suffisamment de précision tout en gardant de bonnes performances sur des données qu'il n'a jamais rencontré (sa capacité à généraliser ses résultats)
Compromis biais / variance
bias / variance trade off
Erreur attendue calculée sur le jeu de test
Variance de l'estimateur de f
Carré du biais l'estimateur de f
erreur irréductible
"écart entre modèle et réalité des données"
"capacité à estimer f avec le moins variabilité lorsque le dataset change"
Compromis biais / variance
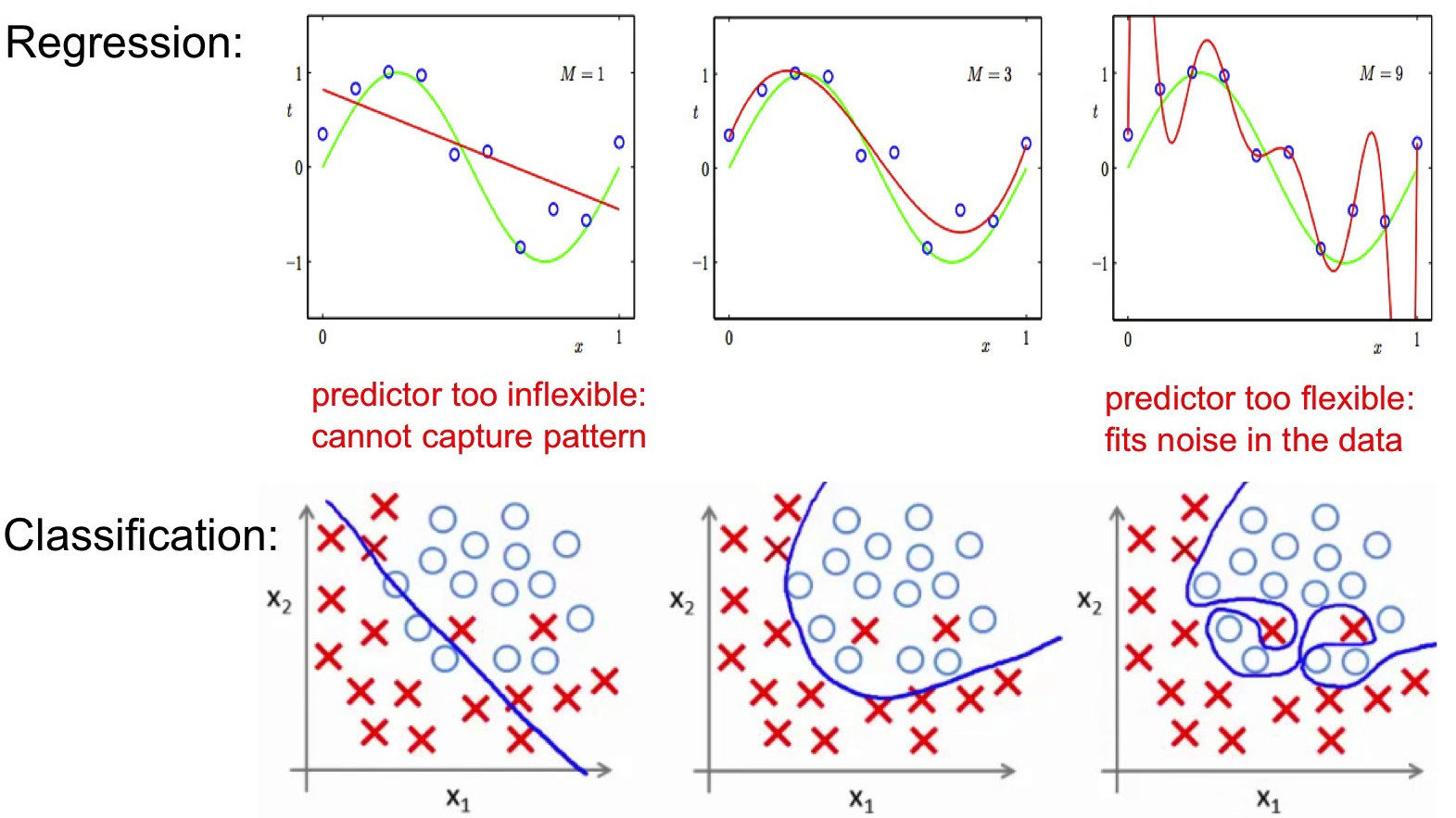
Compromis biais / variance
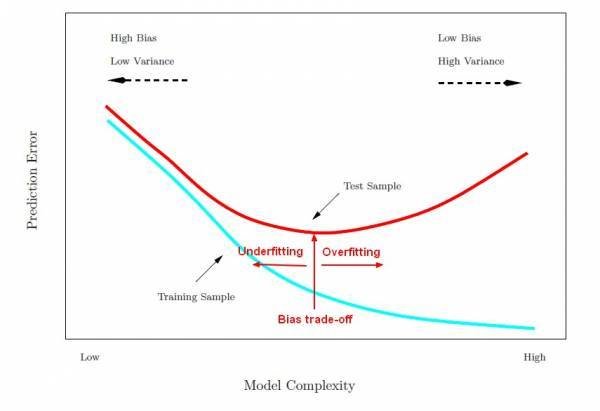

Dans la pratique on observe souvent une double descente de gradient avec un pic d'erreur au milieu
fléau de la dimension
Problème qui apparaît quand notre dataset contient beaucoup de variables par rapport au nombre d'observations
...
...
...
variables
observations
fléau de la dimension avec k-NN

Théorème No free lunch pour l'apprentissage supervisé
Suivant certaines conditions, la performance de tous les algorithmes est identique en moyenne
Conséquence: il n'y pas d'algorithme ''ultime" qui donnerait toujours les meilleurs performances pour un dataset donné
Les problèmes insolubles
Classe de problèmes qui ne peuvent pas être résolus dans un temps raisonnable, c'est à dire qui ont une forte complexité algorithmique
Quelques solutions à ces limitations
Validation de modèle
Problématique: évaluer les performances de généralisation d'un modèle en évitant le sur apprentissage
On échantillonne les données en trois parties:
data set
test
apprentissage & validation
validation
test
apprentissage
Validation de modèle
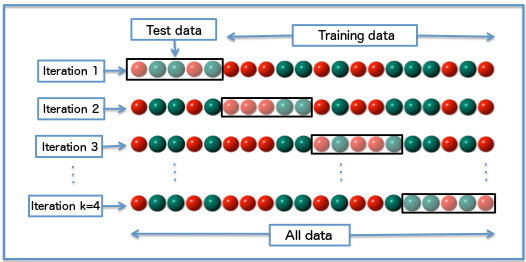
Problématique: évaluer les performances de généralisation d'un modèle en évitant le sur apprentissage
La sélection de features
Sélectionner dans le dataset le minimum de features qui contribue le plus aux bonnes performances
Threshold Methods
...
Intrinsic methods
Objectif : réduire la complexité du modèle
Wrapper methods
correlations
information gain
...
threshold methods
recursive feature elimination
hierarchical selection
LASSO
Ridge
...
Domain knowledge
La sélection de features
Ne s'applique que sur le jeu d'apprentissage pas sur le jeu de test --> risque de data leakage
Pièges a éviter :
A appliquer pendant chaque fold de la cross-validation en même temps que l'entaînement du modèle
La régularisation
Idée: contraindre des valeurs de coefficients pour limiter leur variations
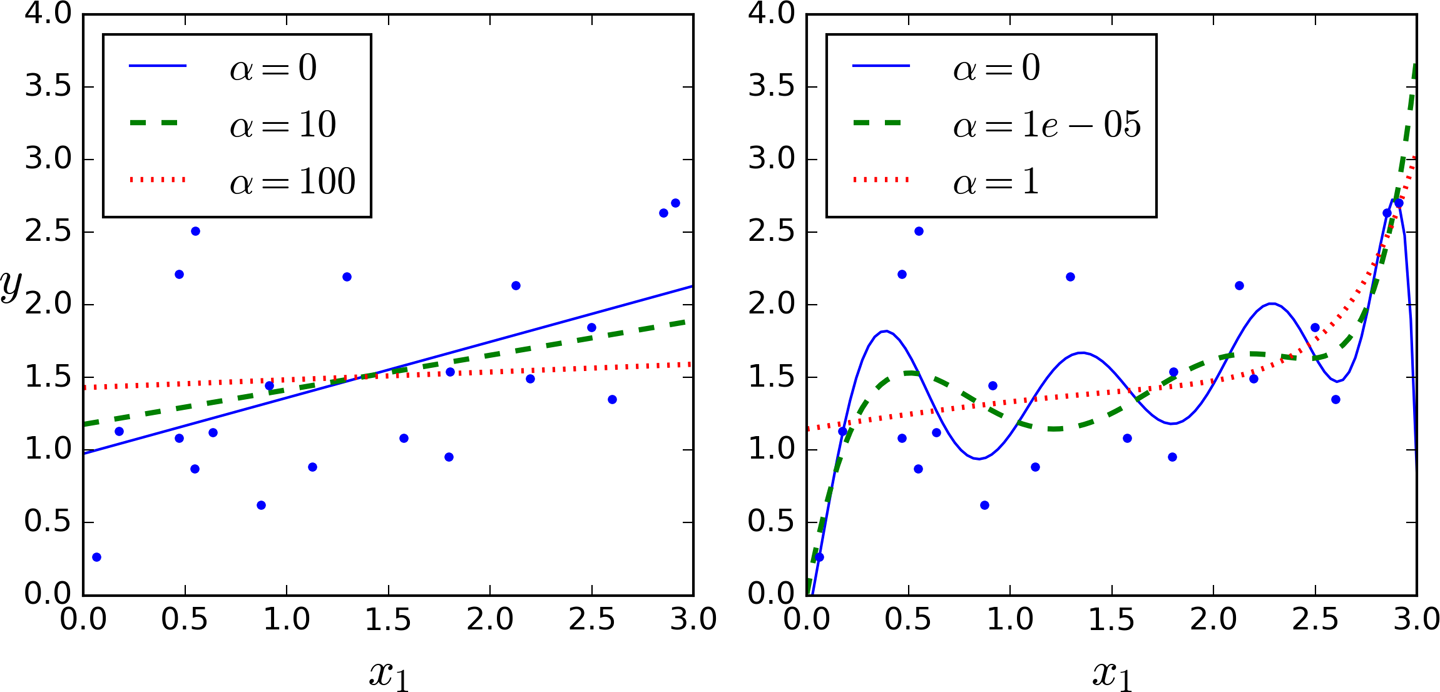
régression linéaire
régression polynomiale
Augmentation de données
Transformer ou enrichir les données existantes
Rajouter plus de données
données métiers, open data, scraping ...
Feature engineering :
créer des nouvelles variables
enrichissement (annotations, méta données, ...)
transformations (déformations d'images, ...)